
融合全局上下文注意力的遥感图像检测方法
2024-03-04 13:19朱文球雷源毅
兵器装备工程学报 2024年2期
廖 欢,朱文球,雷源毅,徐 轲
(湖南工业大学, 湖南 株洲 412000)
0 引言
遥感图像的目标检测技术在军用和民用领域都发挥着不可或缺的作用,具有重要的应用价值。遥感图像目标检测技术旨在复杂的遥感背景图像中找到需要的目标,如飞机、油罐、车辆等[1],并精确地对其进行位置定位和分类。然而,由于遥感图像背景复杂度高、目标尺寸多样性高等特点,使得检测的目标存在过高的误检和漏检问题。传统基于人工提取图像特征,如HoGDetector、DMP算法,其设计复杂、效率以及泛化能力低下。近些年来,深度学习在目标检测中取到了重大的进展。通过构建深度神经网络训练大量数据来学习目标的特征信息,较传统的手工提取特征算法已经取得了更好的精度,并且实现起来更加方便、效率更高。目前,基于深度学习的目标检测算法主要分为2种类型。一类是基于候选框的两阶段目标检测算法,最经典的是Girschick提出的R-CNN[2]、Fast-RCNN[3]和Faster-RCNN[4]算法,其设计复杂、消耗资源多且检测速度较慢;另一类是基于回归的单阶段目标检测算法,具有代表性的是SSD[5]、Retina-Net[6]和YOLO[7-10]系列方法。相较于两阶段目标检测算法,单阶段目标检测算法不仅在在网络设计结构层次方面更加简单,而且在检测精度、速度方面也更优。其中YOLO系列的YOLOv5模型在精度和速度方法具有很高的检测能力,在学术界和工业界都使用广泛。
综上所述,本文中提出一种融合全局上下文注意力机制的遥感图像目标检测算法。在YOLOv5s的6.1版本基础上,设计一种全局上下文注意力机制和YOLOv5中C3结构融合的模块C3_GC,提升网络模型对图像全局特征的捕捉能力;使用VariFocal Loss作为模型置信度和分类损失,以此提高对图像小目标的召回率;采用基于归一化的注意力模块,用来降低图像中不太显著的权重;利用动态卷积在降低模型参数情况下,提升网络模型对目标的检测精度。
1 YOLOv5
YOLOv5根据网络深度和宽度的不同,划分了YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x等4个网络模型,其中YOLOv5s是模型容量、复杂度最小的一个。由于本实验数据集不够大,因此选取YOLOv5s的6.1版本模型作为基础模型,具体结构如图1所示。
YOLOv5s主干网络主要由C3、CBS和SPPF结构组成。C3结构主要借鉴了跨阶段网络CSPNet[11]的思想,将输入特征分为2个部分处理。主干部分通过卷积、归一化和激活函数逐步提取特征,分支仅仅通过卷积层调整通道;通过划分梯度信息,消除了大量的梯度冗余信息。CBS结构由卷积Conv、归一化BatchNorm和激活函数SiLU组成,用于提取模型的特征。SPPF结构将输入特征串行通过多个5×5的最大池化层,再经由CBS网络结构提取堆叠的特征,能够增大网络的感受野,提升网络的表征能力。

图1 YOLOv5s网络结构示意图
YOLOv5s模型沿用了YOLOv4中自顶向下和自定向下的多尺度融合方式,并且引入了CSP结构,然后将特征信息传入到检测层中。
YOLOv5s一共有80×80、40×40和20×20等3个不同尺度的检测层,用于预测大中小目标的类别和位置预测。然后通过非极大值抑制算法等后处理操作,输出置信度分数最高物体的类别信息。
2 模型改进
2.1 融合全局上下文注意力机制
在目标检测领域中,一般通过深度卷积神经网络去提取图像的特征信息。而深度卷积神经网络是基于其局部的像素点进行感知,要想获得长距离的依赖关系,一般通过多次堆叠卷积层来获取。然而,直接重复堆叠卷积层使得模型计算效率低下,且在长距离间会导致信息传递困难,难以优化。

图2 Global Context Modeling网络结构示意图
GC[12]模块由Context Modeling和Transform 2个模块组成,其结构示意图如图2所示。图2中,H和W分别表示特征图的高度和宽,C表示特征图的通道数。输入图像首先通过Context Modeling中1×1的卷积和Softmax操作计算出注意力权重特征图,然后和输入进来的H*W*C进行矩阵相乘,且将每一个通道的特征层内所有值相加得到C*1*1的全局关系。然后,通过Transform结构中,2个1×1的卷积降低参数量,此外还采用了LayerNorm来减少模型优化的难题。最后通过广播机制将H*W*C和C*1*1的全局信息按元素信息进行相加,得到强化图像全局重要信息的输出结果。为了解决长距离信息依赖问题,提出一种融合全局上下文注意力机制的C3模块,命名为C3_GC。图3即为C3_GC模块的结构示意图。
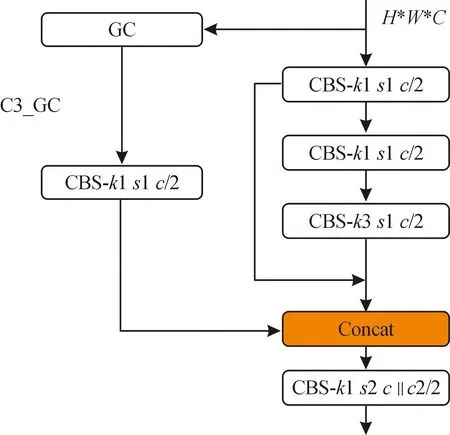
图3 C3_GC网络结构示意图
2.2 Varifocal Loss损失函数
遥感图像目标检测较难的一个问题是图像中目标类别和背景类别极端不平衡,其中检测目标仅仅占很少的图像区域。这会导致网络模型对检测目标的学习效率降低,过多地去关注背景类的特征信息。Focal Loss[13]损失函数可以解决目标类与背景类数据不平衡的问题,定义为

(1)
式(1)中:p是模型预测为目标的概率,取值在0和1之间;y的取值为-1或者1,分别代表背景和或者目标;α为可调节平衡因子;(1-p)γ为目标类调节因子,γ为背景类调节因子。2种调节因子可以提高对难检测、误检的重视程度,且减少简单样本对模型损失的贡献,使得Focal Loss能够解决模型训练时样本数据不均衡的问题。
Focal Loss采用平等对待正负样本的方式,而在实际的目标检测中,正样本对模型的贡献更为重要。因此,提出一种基于binary cross entropy loss的损失函数,命名为varifocal loss[14]定义为:

(2)
式(2)中:p是IACS预测值,表示预测为目标类的得分;q表示分类的条件,对于目标类来说,将其设置为真实框和预测框之间的IOU阈值,否则设置为0,对于背景类来说,q值为0。
如式(2)所示,通过使用γ的因子缩放损失,varifocal loss仅仅减少了负样本的损失贡献,而不会对正样本进行比例的缩放。负样本损失贡献减少,而正样本损失相对来说增大,使模型能够更加关注于目标类的相关特征信息。
2.3 归一化注意力机制
注意力机制一般用于捕捉图像的特征信息,不同的注意力机制是通过不同的关注机制获取图像不同特征维度上的信息。然而,常见的注意力机制缺乏分辨捕捉特征的重要程度,导致提取的特征效率低下。因此,提出一种基于归一化的注意力模块(NAMAttention)。
NAMAttention[15]从空间和通道2个维度去关注图像的特征;较常规注意力机制不同的是,它通过控制比例缩放因子来判断空间或者通道的方差值,以此来表示它们的重要程度。比例缩放因子越大,证明所捕捉图像的空间或者通道特征更加重要,使得网络会更加关注这些特征。
通道注意力机制模块如图4所示,比例因子γi的权重Wi反应出各个通道变化的大小以及通道的重要程度。
由于深度神经网络模型一般随着深度的增加,特征图的通道数会增大,更多的信息存放在通道信息中。因此,这里将NAMAttention的通道注意力机制模块,加入到YOLOv5s的检测头位置,充分获取通道的特征信息。

图4 通道注意力机制
2.4 多维动态卷积
在深度神经网络领域,常规卷积只有一个静态卷积且与输入样本没有建立联系,导致卷积缺乏动态变化性,提取特征效果差。近些年来,动态卷积使用越来越广泛,如DyConv和CondConv,它们在卷积核上添加注意力机制,使卷积核与输入的样本存在紧密关系,赋予了卷积核的动态特性,使模型的精度得到进一步的提高,它们都忽略了输入通道、卷积核空间和输出通道维度的注意力关注。因此,提出一种多维动态的卷积(ODConv)。
ODConv沿着空间、输入通道、输出通道以及卷积核空间的核维度学习更丰富的注意力,且采用更少的卷积核,使其在取得更优性能的同时也能降低计算量。详细结构如图5所示。

图5 多维动态卷积
3 实验结果分析
3.1 实验环境配置
实验环境如表1所示,集成开发工具使用Pycharm。

表1 实验环境配置
3.2 数据集和评价指标
实验使用的遥感数据集是NWPU VHR-10。NWPU VHR-10是一个用于空间物体检测的10级地理遥感数据集,由西北工业大学于2014年发布,拥有650张包含目标的图像和150张背景图像。数据集种类包括田径场、港口、桥梁、飞机、油罐、舰船、汽车、网球场、篮球场和棒球场10个类别。
目标检测领域中,通常使用准确率(Precision)、召回率(Recall)和平均检测精度(mAP)来衡量模型的好坏。

(3)

(4)
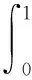
(5)

(6)
式(3)—式(6)中:TP为正确检测出正样本的数量;FN为漏检的正样本数量;FP为误检的负样本数量;AP为单个类别的准确率;mAP为平均检测精度;c代表类别的个数。
3.3 网络训练及参数设置
由于实验数据集的数据量较少,这里选择YOLOv5s作为实验基础模型,且开启Mosaic数据增强。
实验使用ImageNet上的YOLOv5s的预训练权重进行迁移学习。选取数据集中70%样本为训练集,20%样本作为验证集,10%样本作为测试集。实验采用随机梯度下降优化器(SGD),批处理大小(batch size)设置为16,循环次数设置为100个epochs。
YOLOv5s模型训练包括目标框、置信度和分类三大损失,实验改进方法在验证集上的损失率曲线如图6所示。

图6 损失率曲线
模型的损失随着迭代次数的增加而减少,在迭代次数达到80次之后损失值趋于稳定,且接近为0,说明模型训练已达到最优效果。
3.4 结果分析
通过在NWPU VHR-10数据集的验证集上进行了消融实验,来证明改进之后模型的有效性,实验结果如表2所示。
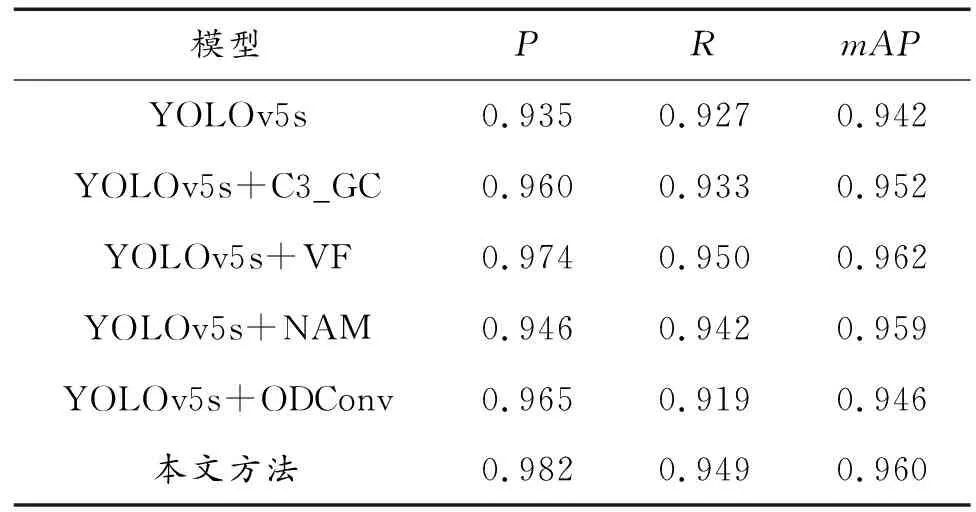
表2 消融实验
进一步对实验表格进行可视化展示,如图7所示。

图7 mAP横向对比
其中,C3_GC代表在C3模块中融合GC全局上下文注意力机制;VF代表varifocal loss;NAM代表的是归一化注意力机制;ODConv代表的是动态卷积。
实验提出改进方法的消融实验结果如表2所示,提出的新模块C3_GC,P、R、mAP分别提升2.5%、0.6%、1%;损失函数改进为VF,P、R、mAP分别提升3.9%、2.3%、2%;采用NAM,P、R、mAP分别提升1.1%、1.5%、1.7%;利用ODConv,P、mAP分别提升3%、0.4%,R下降0.8%;整体的P、R、mAP分别提升了1.8%、4.7%和2.2%。虽然本文中方法的mAP不是最高,但从P、R和mAP综合来看是最优模型。
通过分析数据集图像,提出的C3_GC模块,让骨干网络捕捉到更多的浅层特征信息;使用归一化通道注意力机制,增强网络模型对深层次信息的关注,与SE、ECA等常规注意力机制相对比,mAP提升更高,如表3所示。这些操作都使得模型的平均检测精度更高;改进的多维动态卷积,在不同维度上提取特征图的信息,提升了模型的检测精度,即使召回率有些许下降,但模型的计算量也随之下降,如表4所示。另外varifocal loss 通过突出正样本数据,显著提高了模型的召回率。

表3 注意力机制对比

表4 模型计算量
为了验证实验所改进算法的先进性,同样采用验证集,对算法进行对比实验,将其与主流的目标检测算法进行对比。由表5可知,改进的实验方法获得了最优的mAP值结果。

表5 模型性能对照表
进一步,对所改进方法在测试集的目标检测结果进行可视化展示,图8、图9和图10给出了YOLOv5s和所改进方法在几个典型遥感图像样本上的检测结果示例,其中左图表示原YOLOv5s模型,右图表示改进后的算法模型。从图8可以看出,在高空拍摄下改进后的算法模型能够减少漏检小目标的问题;从图9可以看出,检测目标附近有各种不同的复杂背景信息;通过对比,改进算法在复杂背景下检测的置信度更高,并且能够检测出由于遮挡而被漏检的目标,从而在一定程度上提升了网络模型的检测效果。从图10可以看出,改进后的算法模型能够提升多尺度目标的检测效果。

图8 高空小目标检测效果

图9 复杂背景下检测效果

图10 多尺度下检测效果
4 结论
通过验证集实验数据表明,本文中所改进的方法有效提升了遥感图像目标检测的准确率、召回率和平均检测精度,同时降低了模型的计算量。此外,当前Mosaic4数据增强,虽然能够增加数据样本的多样性,但同时也让小目标的尺寸相对变的更小,会导致模型检测精度、召回率难以有质的提升,后续研究将在不改变目标相对尺寸的前提下,尝试更多的数据增强方式。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年11期)2019-07-04
知识经济·中国直销(2018年8期)2018-08-23
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
数学学习与研究(2017年3期)2017-03-09
第二课堂(课外活动版)(2016年2期)2016-10-21
中国老区建设(2016年1期)2016-02-28
