
Depth-Guided Vision Transformer With Normalizing Flows for Monocular 3D Object Detection
2024-03-04 07:43:56CongPanJunranPengandZhaoxiangZhang
Cong Pan , Junran Peng , and Zhaoxiang Zhang ,,
Abstract—Monocular 3D object detection is challenging due to the lack of accurate depth information.Some methods estimate the pixel-wise depth maps from off-the-shelf depth estimators and then use them as an additional input to augment the RGB images.Depth-based methods attempt to convert estimated depth maps to pseudo-LiDAR and then use LiDAR-based object detectors or focus on the perspective of image and depth fusion learning.However, they demonstrate limited performance and efficiency as a result of depth inaccuracy and complex fusion mode with convolutions.Different from these approaches, our proposed depthguided vision transformer with a normalizing flows (NF-DVT)network uses normalizing flows to build priors in depth maps to achieve more accurate depth information.Then we develop a novel Swin-Transformer-based backbone with a fusion module to process RGB image patches and depth map patches with two separate branches and fuse them using cross-attention to exchange information with each other.Furthermore, with the help of pixel-wise relative depth values in depth maps, we develop new relative position embeddings in the cross-attention mechanism to capture more accurate sequence ordering of input tokens.Our method is the first Swin-Transformer-based backbone architecture for monocular 3D object detection.The experimental results on the KITTI and the challenging Waymo Open datasets show the effectiveness of our proposed method and superior performance over previous counterparts.
I.INTRODUCTION
OBJECT detection is a fundamental task in computer vision.With the development of deep learning [1]-[4],significant progress has been achieved in the field of 2D object detection [5]-[10].It also crucial for applications that require 3D spatial information, such as robot perception,mixed reality, and autonomous driving.Most existing 3D object detection methods rely on LiDAR sensors to provide depth information [11]-[16].However, such sensors cannot be widely used due to the high computational cost.In contrast,3D object detection relying on cameras infers depth from monocular RGB images of rich semantic information that can be used to boost object classification and localization.For monocular 3D object detection, recovering the bounding boxes of objects in 3D space remains challenging due to the lack of depth cues, making monocular object depth estimation naturally ill-posed.
We conduct pilot experiments in Table I using predictions of representative monocular 3D object detection methods[17]-[19] without depth maps or using depth maps as different auxiliary styles.We compare their 3D object detection performance by substituting sub-task predictions with their corresponding ground-truth values.The table shows that depth estimation is the most crucial sub-task for 3D object detection compared to rotation (Rˆ), horizontal and vertical location(XˆY), and shape (HWˆL) prediction.Inspired by the analysis above, our work focuses on leveraging depth features to guide RGB features for high-quality estimation of 3D properties.
Recent works transform depth maps estimated from off-theshelf depth estimators [20], [21] trained from larger datasets to pseudo-LiDAR representation [19], [22].Then they apply state-of-the-art LiDAR-based detection methods to 3D detection tasks and achieve impressive results on the challenging KITTI3D benchmark [23].However, the performance of pseudo-LiDAR based methods suffers from the gap between inaccurately estimated depth and real-world depth.The depth maps generated from monocular images are often coarse,which leads to worse pseudo point clouds and inaccurate 3D detection results.Meanwhile, LiDAR-based detectors increase the algorithmic complexity of 3D detection heads.Moreover,the generated LiDAR-resembled point cloud data representations discard high-level semantic information from RGB images, which is vital for object classification.
Another line of work directly leverages depth maps to augment the input RGB images [18], [24], [25].They treat the depth maps as assistance to generate depth-aware features to enhance 3D detection performance in a learning style.These approaches use the relative depth relationship instead of absolute depth values, which can be easily generated by a scale transformation of depth maps.It is mainly because coarse andinaccurate absolute depth values are useless in their framework.Nevertheless, even though the multi-modal fusion of RGB images and depth maps uses relative depth values, it still heavily relies on the precision of the estimated depth maps.Furthermore, the multi-modal fusion of these convolutional neural network (CNN)-based methods is limited due to the locally confined receptive fields of convolutional layers in CNN.
Therefore, we propose to solve this task by tackling two issues: 1) Determining how to obtain more accurate depth maps without complex architecture design and more computational consumption; 2) Determining how to find a better multi-modal fusion method for depth maps and RGB images to fully use the generated depth maps.
For the first problem, we use normalizing flows to establish the relationship between the distribution of ground-truth depth values (Zˆ) of the training dataset and the distribution of the corresponding absolute depth values.It is a depth transformation that uses prior knowledge to generate more accurate depth maps, which takes only a few minutes for training on the CPU.For the second problem, we build a cross-attentionbased fusion module using the Swin Transformer [26] as a novel Transformer-based backbone.Considering that the Transformer is better suited for multi-modal fusion due to its global attention mechanism, using the cross-attention mechanism for image-depth fusion helps us to achieve notable improvements on the KITTI dataset [23], especially the largescale Waymo Open dataset [27].Also, with the help of more accurate depth maps processed by normalizing flows, we develop new relative position embeddings in the cross-attention mechanism to re-weight the cross-attention map to boost the fusion of depth maps and RGB images.
Our contributions can be summarized as follows.
1) We establish the relationship between the distribution of the ground-truth depth values (Zˆ) of the training dataset and the distribution of the corresponding absolute depth values with normalizing flows.This depth transformation method,employed as a pre-processing step for the depth maps obtained from off-the-shelf monocular depth estimators, incorporates prior knowledge to enhance the accuracy of the depth maps.
2) We build a cross-attention-based fusion module as a novel Swin-Transformer-based backbone to get better fusion of depth maps and RGB images.
3) We develop new relative position embeddings in the cross-attention mechanism to re-weight the cross-attention map to boost the fusion of depth maps and RGB images with the help of more accurate depth maps processed by normalizing flows.
4) Extensive evaluations on the KITTI and the challenging Waymo Open datasets demonstrate that our proposed NFDVT model outperforms different strong baselines and achieves better performance than previous counterparts.
II.RELATED WORK
A. Image-Based Monocular 3D Detection
Image-based approaches [28]-[31] typically use geometry constraints, including object shape, ground plane, and keypoints.MonoGRNet [31] decomposes the 3D detection problem into sub-tasks, namely 2D object detection, instance depth estimation, 3D localization, and local corner regression.GS3D[30] exploits an off-the-shelf 2D object detector and computes a coarse cuboid for each predicted 2D box to refine detection results.M3D-RPN [17] generates 2D and 3D object proposals simultaneously and proposes depth-aware convolution to improve 3D parameter estimation.SMOKE [32] is a deep architecture that predicts 3D bounding boxes by relying on keypoint estimation as an intermediate task.MonoRCNN[33] proposes a geometry-based distance decomposition to enable interpretability, accuracy and robustness of distance prediction.Homo [34] introduces a homography loss, which leverages geometric interrelationships among objects within a given scene.And it imposes global constraints on the mutual locations of objects by utilizing the homography between the image view and the Bird’s Eye View.
Other works, such as Monopair [35], consider the relationship of paired samples to improve monocular 3D object detection.MonoDIS [36] proposes to improve both training convergence and detection accuracy of 3D detection networks by considering loss disentanglement.Zhanget al.[37] points out the importance of dimension estimation in the recovery of 3D locations.To address this concern, they propose to learn a dimension-aware embedding space and utilize this space to learn representative shape templates to improve dimension estimation.MonoCon [38] proposes to learn auxiliary monocular contexts in training and discard these auxiliary branches for better inference efficiency.
Some methods use external data sources, e.g., Deep-MANTA [39] uses keypoints of vehicles to encode 3D vehicle information.LPCG [40] generates pseudo labels from unlabeled LiDAR point clouds and then trains the monocular 3D detectors with the pseudo-labeled data and benefits from the augmented training set.
B. Depth-Aware Monocular 3D Detection
An alternative solution for improving monocular 3D detection performance is to introduce depth information.Existing depth-aware monocular 3D object detection methods can be categorized into three types: pseudo-LiDAR based approaches, depth-image fusion-based approaches, and other depthaware approaches.
The pseudo-LiDAR based methods [19], [22], [24], [41],[42] first perform an off-the-shelf monocular depth estimation,such as DORN [20] or BTS [21], and lift the input image to a point cloud representation, which is called a pseudo-LiDAR point cloud.Then they predict oriented 3D bounding boxes using a point-cloud-based 3D object detector.Mono3D-PLi-DAR [41] observes that noise in the pseudo-LiDAR hinders 3D detection performance and uses the instance mask instead of the bounding box frustum lifting.Pseudo-LiDAR++ [22]points out that pseudo-LiDAR relies heavily on the quality of depth estimation and therefore more accurate depth estimation can be implemented to aid pseudo-LiDAR methods with the help of a stereo network architecture.DD3D [43] uses a large private dataset DDAD15M for depth pre-training to transfer effective information between depth estimation and 3D detection.
Some works are dedicated to improving 3D detection performance by fusing depth maps and RGB images in a learning style with traditional convolutional neural networks(CNNs) [18], [25], [44], [45].D4LCN [18] carefully learns dynamic-depthwise-dilated kernels from depth features to integrate with image context.CaDDN [45] predicts categorical depth distributions to generate accurate bird’s-eye-view representations and then uses a BEV detection network for 3D detection.
Other depth-aware methods, such as DEVIANT [46], propose depth equivariant networks built with scale equivariant steerable blocks to solve the depth translation issue in the projective manifold.DID-M3D [47] reformulates the instance depth to the combination of instance visual depth and instance attribute depth and performs data augmentation based on the decoupled instance depth.MonoDDE [48] proposes a depth solving system with a depth selection and combination strategy to fully use visual clues from subtasks for monocular 3D object detection.
Compared with the methods mentioned above that use offthe-shelf monocular depth estimators, our method introduces a depth prior by normalizing flows, thereby achieving more accurate depth maps.Training a model that processes depth images by normalizing flows only requires the CPU and takes only a few minutes, without complex architecture design and additional computational consumption.Moreover, unlike the methods mentioned above that fuse depth maps and RGB images with CNNs, our emphasis is on learning good depth maps and RGB images fusion networks via the global attention mechanism of the vision transformer.Meanwhile, more accurate depth maps obtained by normalizing flows can be used to conduct new relative position embeddings to aid the cross-attention-based fusion module.
C. Vision Transformer
A transformer with the fundamental component of a selfattention mechanism was first applied in the natural language processing (NLP) field and achieved great success [49], [50].Recently, with the capability of capturing long-range dependencies, transformer architecture has been successfully leveraged in computer vision tasks, such as image classification[51]-[53], object detection [54], [55], semantic segmentation[56], [57], and other vision-related tasks [58]-[61].However,transformers have limited applications in 3D object detection tasks.MonoDTR [62] is the first method using a transformer encoder-decoder structure to model the relationship between context- and depth-aware features for the monocular 3D object detection task.Our NF-DVT method utilizes the hierarchical architecture of the Swin Transformer [26] to extract various scales of image features while fusing depth information, which was extracted from the pre-trained depth estimator and refined with normalizing flows.
D. Normalizing Flows
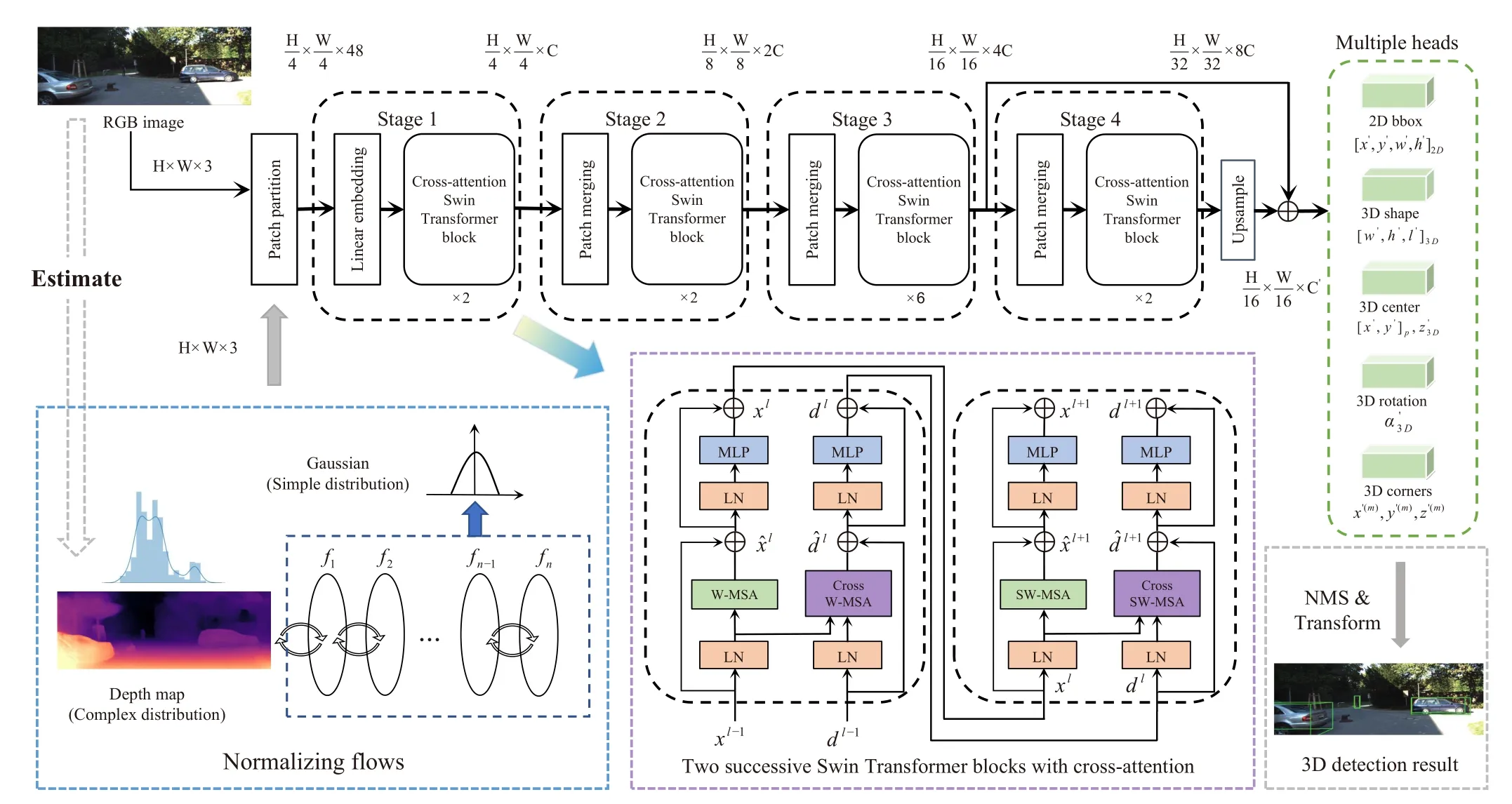
Fig.1.The overall framework of our proposed approach.The depth map is first estimated from the RGB image and refined by building priors in instance depth estimation using normalizing flows.Then the RGB image and the depth map are fed into the Swin Transformer (tiny version, referred to as Swin-T) with cross-attention to extract features.Finally, multi-heads are attached for 3D bounding box estimation with non-maximum suppression (NMS).W-MSA and SWMSA are multi-head self-attention modules with regular and shift windowing configurations, respectively.Cross W-MSA and Cross SW-MSA are W-MSA and SW-MSA modules with cross-attention.
A normalizing flow [63] describes the transformation of a probability density through a sequence of invertible mappings.Normalizing flows can transform a complex data point into a simple Gaussian Distribution or vice-versa.Some recent works utilize normalizing flows to build priors in vision tasks,such as density estimation [64], [65], image, audio, and video generation [66]-[68] and 3D human pose estimation [69]-[71].Reference [69] proposes a regression paradigm, named residual log-likelihood estimation (RLE), that leverages normalizing flows to estimate the underlying distribution and boosts human pose estimation.In this paper, we integrate the prior distribution of the ground-truth depth values into the distribution of estimated depth maps with normalizing flows to assist the depth-image fusion module.
III.METHODOLOGY
A. Framework Overview
As shown in Fig.1, our framework consists of three key components: a depth map extractor and processor with normalizing flows, a cross-attention-based transformer backbone with depth-guided relative position embedding, and a 2D-3D detection head.Specifically, we utilize BTS [21] as the depth map estimator and use neural spline flows (NSF) [72] to build priors into the generated depth maps.As for a transformerbased backbone, we use the Swin Transformer [26] (tiny version, referred to as Swin-T), which is pre-trained on ImageNet-1K classification dataset [73].
B. Depth Map Preprocessing
First, we achieve the absolute depth valuedby projecting the3Dcenter location[x,y,z]3dincamera coordinates into the image planegiven aknown projectionmatrixK∈R3×4as
where [x,y,z]3drepresents the horizontal position, height, and depth of the 3D center of each object in camera coordinates,and [x,y]pis the projection of the 3D point in the 2D image plane.With the same coordinate [x,y]pin the depth map, we can achieve the pixel depth and convert it to absolute depth valuedwith a scale.There is a one-to-one correlation between the ground-truthz3dand absolute depth valued.
As shown in Fig.2, we observe that there is a certain relationship between the distribution of ground-truthz3dand the distribution of corresponding absolute depth valued.To model this specific relationship, we use the NSF auto-regressive density estimator, which is fully differentiable and has an analytic inverse.
A normalizing flow models input data x as the output of an invertible, differentiable transformation f of noise u
The probability density of x under the flow is obtained by a change of variables
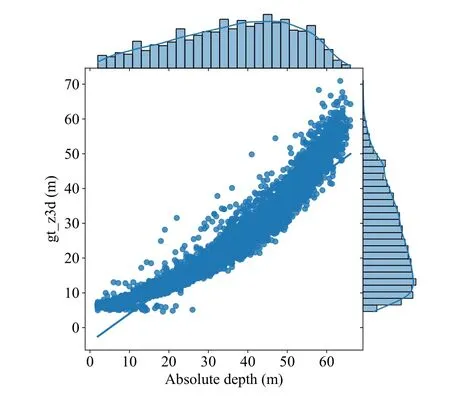
Fig.2.The illustration of the relationship between ground-truth z3d distribution of training dataset and corresponding absolute depth d distribution.The vertical axis is the distribution of ground-truth z3d (gt_z3d) of the training dataset and the horizontal axis is the distribution of corresponding absolute depth values.
Given a dataset D={x(n)}, the flow( is )trained by maximizing the total log-likelihoodlogpx(n)with respect to the parameters of the transformation f.All flows in our module use a standard-normal noise distribution.We also constrain the distribution of the absolute depth valuedand the distribution of the ground-truthz3dafter transformation through theL1loss, making the two distributions similar in order to introduce more accurate depth prior information for the depth maps.To sum things up, the overall transformation loss using normalizing flows is
Fig.3 shows the distribution of the ground-truth depthz3din the blue curve and the distribution of the generated absolute depth valuesdin the red curve before and after transformation using NSF.We use only three simple fully connected neural networks in the coupling transform of NSF, which is easy to train and is suitable for one dimension situations.We can see that, after transformation, the generated distribution of absolute depth valuesdis more similar to the distribution of the ground-truthz3d.With the help of normalizing flows, we can model distributions with complex and introduce flexible priors into depth maps.
C. Depth-Guided Transformer
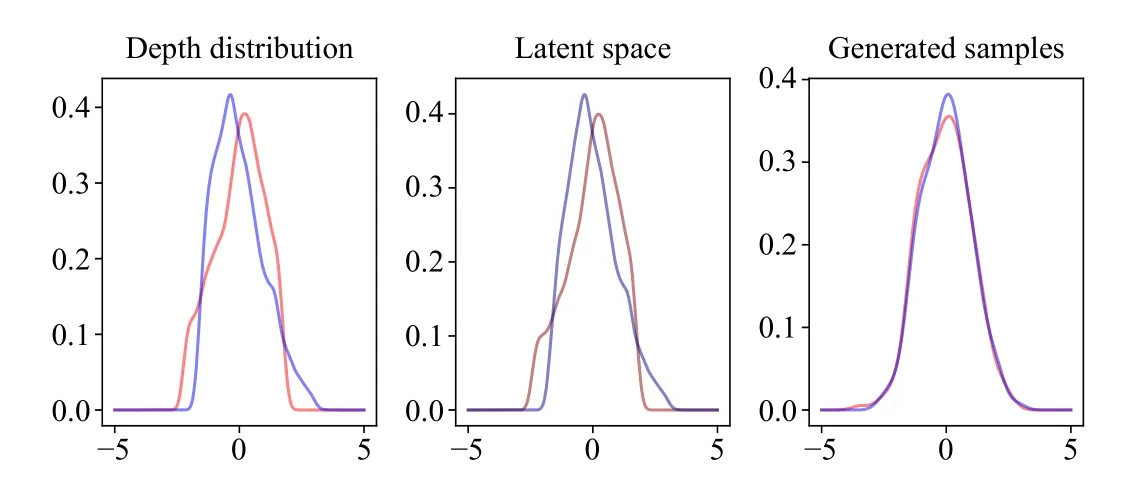
Fig.3.The illustration of the distribution of the ground-truth depth z3d(blue curve) and the distribution of absolute depth d (red curve) before and after transformation through normalizing flows.
In CNN-based architecture, attention modules are used to fuse different modal features.However, its empirical design cannot guarantee the discriminative ability of the model and the local receptive fields of convolutional layers is not able to fully capture the object context in the condition of perspective projection and occlusion.The trend of using cross-attentionbased transformers to model multi-modal fusion starts to show initial traction as transformers took the computer vision field by storm since mid-2020.Transformers are more suitable to perform the job of multi-modal fusion due to the global attention mechanism.In this paper, we extend a popular vision transformer, called the Swin Transformer [26], that serves as a general-purpose backbone for computer vision.Following the same pipeline, we use the tiny version of the Swin Transformer (Swin-T), which has 4 stages.Meanwhile, we upsample the last layer and then fuse it with the third layer to obtain a larger field of view and keep the network stride at 16.Different from Swin Transformer, we formulate our backbone as a two-branch network: one is the feature extraction network from RGB images, and the other is the depth-guided feature fusion network.
1)Depth-Guided Cross-Attention: Nevertheless, simply using revised Swin-T as our backbone gives rise to worse performance compared to ResNet50, which will be shown in the ablation study component in Section IV-F.This is mainly due to insufficient training images in the KITTI dataset since the transformer-based network is data-driven.Then we propose a cross-attention module (two successive Swin Transformer blocks with cross-attention in the bottom half of Fig.1) to solve this problem.There are two types of attention mechanisms in each Transformer block, self-attention for the image branch and cross-attention for the image-depth branch.In selfattention, the queryQ, keyK, valueVinputs are the same,whereas in cross-attentionQis a different modal from that forKandV.In computing self-attention, we follow [26] to each head in computing similarity:
whereQ,K,V∈RM2×nare thequery,keyandvaluematrices;nis thequery/keydimension;B∈RM2×M2is the relative position bias, andM2is the number of patches in a window.Similarly, the cross-attention mechanism for computing similarity is formulated as follows:
whereQdis thequerymatrix of the depth map andKimg,Vimgare thekeyandvaluematrices of the image feature map.
2)Depth-Guided Relative Position Embedding: As shown in Fig.4, the depth values of two arbitrary positionsiandjare different in the same local window.Positionjis closer to positioniand positionkis further away from positioni.It is intuitive that attention similarity should be greater the closer the distance is, and smaller the further the distance is.So we use the cosine of the depth difference as the weight coefficient.Then the cross-attention can be formulated as follows:
wherejandkrepresent different positions.

Fig.4.An illustration of a window for self-attention in the Swin Transformer architecture.A local window consists of 7 patches.i, j, k represent different patches.
D. 2D-3D Detection Head
Inspired by [17], we utilize 2D-3D anchors with priors as our default anchor boxes.And the proposed framework is based on the region proposal network (RPN) with 2D-3D anchors.The RPN locates the predefined anchors at every spatial location of the feature map; the detection head then regresses to the positive samples.
2D-3D Anchor: Equation (1) represents the 3D-to-2D projection.Firstly, 2D anchors [x,y,w,h]2Dare defined on the 2D space for the 2D bounding box.[x,y]Prepresents the 2D location projected from the 3D center in the image plane.Then for each anchor, the default values of the 3D parameters are the mean statistics calculated from the corresponding priors in the training dataset.Specifically, we use 12 different scales ranging from 32 to 384 pixels and 3 aspect ratios (0.5, 1.0, 1.5) to define a total of 36 anchors.We then project all 3D ground truth boxes to the 2D space and calculate its intersection over union (IoU) with each 2D anchor and assign the corresponding 3D box to the anchors that have an I oU ≥0.5.Then the 3D[z,w,h,l,α]3Dparameters are the statistics across all matching 3D ground truth boxes, which denote 3D object center depth,physical dimension, and rotation, respectively.Note that in practical implementation, we use a minimum enclosing rectangle of the projected 3D box as our ground truth 2D bounding box.
Formulation: Following [18], we utilizenato represent the number of anchors andncto represent the number of classes.Our detection head predicts 35+ncparameters for each posi-

Losses: The network loss of our framework is formed as a multi-task learning problem composed of a classification lossLc, a 2D regression lossL2D, a 3D regression lossL3Dand a 2D-3D corner lossLcorner.For the classification loss, we employ the cross-entropy loss
For both 2D and 3D regression, we use theSmoothL1regression losses
The total loss is formulated as
where γ =0.5 in all experiments.
IV.EXPERIMENTS
A. Dataset and Evaluation Metrics
We evaluate our proposed framework on the challenging KITTI [23] and Waymo Open datasets [27].
KITTI dataset consists of three tasks: 2D detection, 3D detection, and bird’s eye view (BEV).The KITTI dataset is divided into 7481 training samples and 7518 testing samples.The training samples are commonly divided into atrainset with 3712 samples and avalset with 3769 samples following[83].For a fair comparison with other baseline methods, we evaluate our NF-DVT method on thetestset by training our model on both thetrainandvalsets and evaluate on thevalset by training our model on only thetrainset.The evaluation is separated by difficulty settings (Easy, Moderate, and Hard)and by object classes (Car, Pedestrian, and Cyclist).Results on the KITTI dataset are evaluated using precision-recall curves with the IoU threshold of 0.5 or 0.7.The 3D object detection and 3D localization performances are evaluated by AP3dand APbev, respectively.Following [36], we use the 40 recall positions-based metric A P|R40.
The Waymo Open Dataset is another large-scale challenging dataset for autonomous driving.The official protocol provides 798 training sequences and 202 validation sequences from different scenes, and 150 test sequences without labels.Following PCT [82], we only use the data from the front camera for monocular 3D object detection.We sample one frame out of every three frames from the 798 training sequences (52 386 images) and use all the 202 validation sequences (39 848 images).The evaluation is separated into two difficulty settings through different numbers of lidar points contained in the bounding box: samples with equal or less than 5 points are classified as “LEVEL_2”, and others are classified as“LEVEL_1”.Results on the Waymo open dataset are evaluated using mean average precision (mAP) and the mean average precision weighted by heading (mAPH).Different distances (0-30 m, 30-50 m, 50 m-∞) to the sensor are also considered in the evaluation.
B. Details on Baselines
In order to make a fair comparison with the existing stateof-the-art methods and illustrate that our model can be plugged into different 3D object detectors as a backbone, we use anchor-based method D4LCN [18] and anchor-free based method MonoFlex [80] as our base models, respectively.Note that all the ablation studies on KITTI and experiments on the Waymo open dataset are implemented on an anchor-based baseline.
Anchor-Based Method: D4LCN [18] is a one-stage anchorbased method that leverages a set of pre-defined 2D-3D anchors to derive the estimated 3D boxes.Our proposed method replaces the convolutional backbone with a depth vision Transformer (DVT) module for feature extraction,which concurrently fuses depth maps and regresses object properties on these feature maps.
Anchor-Free Based Method: MonoFlex [80] is a one-stage anchor-free based method, which utilizes multiple branches to predict 2D bounding boxes, orientation, dimension, depth, and keypoints.As it operates as an anchor-free detector, the representative box’s location is automatically assigned as the 3D projected center in the heatmap head without the need for selection.Following this architecture, we introduce a Transformer-based backbone to extract image features and fuse depth maps.Finally, multiple heads are employed on these feature maps to regress object properties.
C. Implementation Details
We use the tiny version of Swin-T as our backbone to extract features from RGB images and depth maps, which has 4 stages with [2, 2, 6, 2] block numbers for each stage.For the KITTI dataset, similar to [85], we double the training set by utilizing images both from the left and right RGB cameras(only RGB images from the left camera are used in thevalandtestsets).We generate both the left and right depth maps using [21].The input images are scaled to 384×1280 with horizontal flipping and photometric distorted data augmentation.Non maximum suppression (NMS) with an IoU threshold of 0.4 is used on the network output in 2D space.Following [17], we use a hill-climbing post-processing step to optimize 3D rotation α.The network is optimized by stochastic gradient descent (SGD) with a momentum of 0.9 and a weight decay of 0.0005.We use the “one-cycle” learning rate policy and set the base learning rate to 0.01.
Following PCT [82], we utilize the AdaBins [86] monocular depth estimator, trained on the Waymo Open dataset, to derive depth maps for the Waymo Open dataset.The input images are scaled to 640×960 with horizontal flipping and photometrically distorted data augmentation.The network is optimized by AdamW [87] optimizer with the initial learning rate as 3e-4 and weight decay of 1e-5.
As for normalizing flows, we use NSF [72], which has a tractable Jacobian determinant and can be inverted exactly in a single pass.The neural network in our practical implementation consists of 3 fully connected (FC) layers, followed by atanhactivation function.The network is optimized by Adam with a learning rate of 0.005 and trained for 10 000 iterations.
D. Results on the KITTI Dataset
Results of Car category on KITTItestset.Table II shows the results of our NF-DVT method on the KITTItestset compared to the state-of-the-art monocular methods with or without depth as an extra input.For AP|R40on thevalset, our method exceeds two baselines by a large margin and surpasses existing methods on 3D object detection and bird’s eye view tasks for theCarcategory under easy, moderate and hard levels.Specifically, compared with the recently proposed DEVIANT [46], our model based on MonoFlex achieves 2.54%, 2.49%, and 2.11% gains on the easy, moderate, and hard settings with an 0.7 IoU threshold for 3D detection task,respectively.Furthermore, our method based on MonoFlex improves with respect to recently proposed DID-M3D [47](using extra data) by 0.02%, 0.66%, and 0.25% gains on the three difficulty settings for the 3D detection task, which is superior in Moderate and Hard, but with minimal gain in Easy.Since our model improves the accuracy of the depth map by normalizing flows; thus, the depth estimation of distant objects is better, thereby improving the 3D detection results of distant objects, which is demonstrated with the significant improvement under the moderate and hard settings.As previous methods like DID-M3D have already estimated the depth of close objects accurately, the improvement of our model under such a setting is not obvious.
Results of Car category on KITTIvalset.Table III illustrates the performance of our model on the KITTIvalset for better comparison, including different tasks and IoU thresholds.As our work is aimed at achieving more accurate depth maps and better modeling of fusion of depth maps and RGB images, our approach is mainly compared to D4LCN [18],which carefully designs a local convolutional network to learndynamic-depthwise-dilated kernels for images with the guidance of depth maps.Though the results are higher in their paper [18], we show our replicate results with their provided official code and parameters in Table III with a star sign.Specifically, our method improves with respect to D4LCN*by 1.4%/2.11% for 3D/BEV detection under the moderate setting at 0.7 IoU threshold.Moreover, compared with the recently proposed DEVIANT [46], our method based on Monoflex achieves 0.97%, 1.88%, and 0.8% gains on the easy, moderate, and hard settings with a 0.7 IoU threshold for 3D detection tasks, respectively.Finally, our method outperforms all existing advanced methods under different tasks and IoU thresholds.
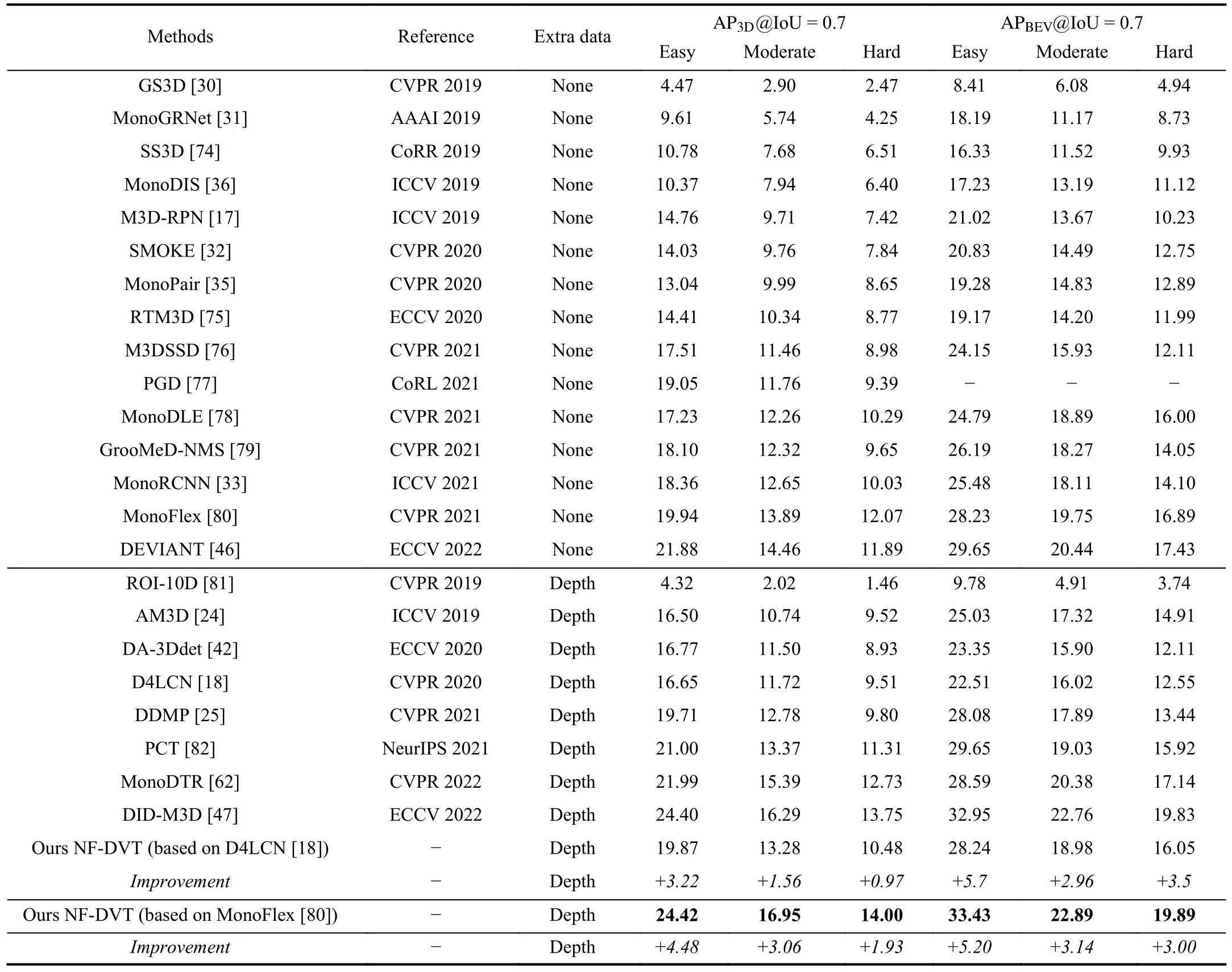
TABLE II AP|R40 SCORE ON TEST SET OF 3D OBJECT DETECTION AND BIRD’S EYE VIEW FOR THE CAR CATEGORY WITH IOU ≥ 0.7.BEST RESULTS ARE MARKED IN BOLD
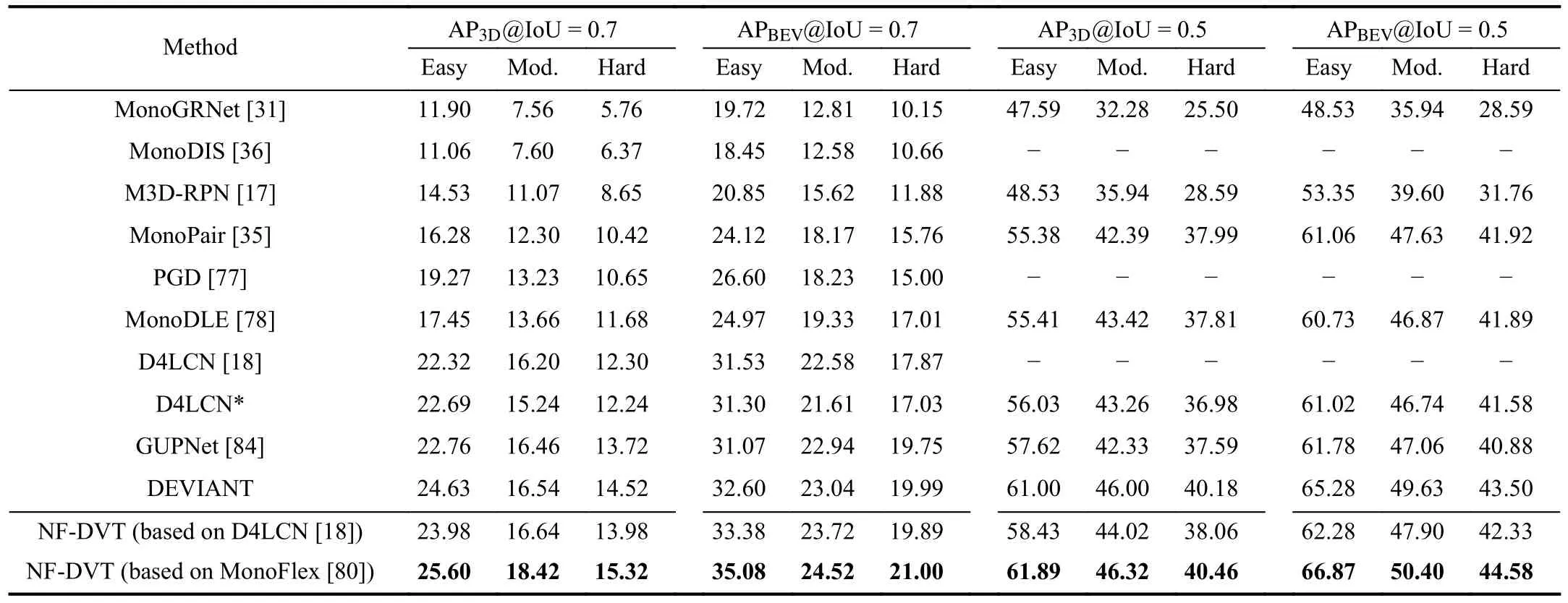
TABLE III AP|R40 SCORE ON VAL SET OF 3D OBJECT DETECTION AND BIRD’S EYE VIEW FOR THE CAR CATEGORY.“*” INDICATES OUR REPLICATE RESULTS FOR D4LCN [18] WITH OFFICIAL CODE AND CONFIGURATION.BEST RESULTS ARE MARKED IN BOLD
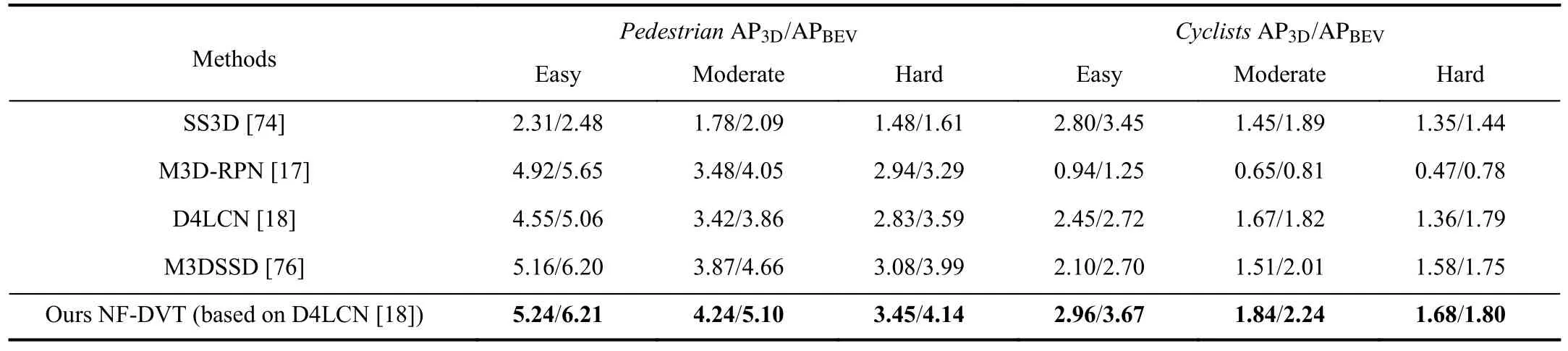
TABLE IV PERFORMANCE OF 3D OBJECT DETECTION AND BIRD’S EYE VIEW FOR PEDESTRIANS AND CYCLISTS ON TEST SET,AT 0.5 IOU THRESHOLD.BEST RESULTS ARE MARKED IN BOLD
Results of Pedestrian/Cyclist on KITTItestset.We further show the evaluation results of Pedestrian and Cyclist on the KITTI test dataset in Table IV.The Pedestrian and Cyclist categories are much more challenging than the Car category for monocular 3D object detection due to their small scale.Our method outperforms existing advanced arts both on 3D object detection and localization tasks to some degree.
E. Results on the Waymo Open Dataset
Table V shows the results of our NF-DVT method for the vehicle class on the challenging Waymo Open validation dataset.We also compare the proposed method to the current state-of-the-art methods with or without depth as an extra input in the table.Our proposed method yields improvement over most of the recent approaches.Compared to the baseline method M3DRPN [17] without an extra input, our proposed method achieves 2.41%/2.31% mAP gains in LEVEL_1/LEVEL_2 under an IoU threshold of 0.7, respectively.Compared to the second-best approach DEVIANT [46], our proposed method achieves 0.07%/0.12% mAP gains in LEVEL_1/LEVEL_2 under an IoU threshold of 0.7, respectively.And under an IoU threshold of 0.5, our proposed method achieves 0.34%/0.95% mAP gains in LEVEL_1/LEVEL_2, respectively.Although our method gives worse results than DEVIANT [46] at distances from 0-30 m, our results are better at distances from 30-50 m and 50 m-∞.This indicates that our method perceives objects far from the camera better and can achieve better performance overall.
F. Ablation on Different Components
To explain how much improvement each component of our NF-DVT approach provides, we perform ablation studies on the KITTIvalset for thecarcategory.The main results are shown in Table VI.We observe that: 1) Simply using Swin-T as the backbone without depth maps cannot achieve better performance compared to the baseline using ResNet50 (a→b), which is mainly because the number of images in the KITTIvalset is too small.The transformer-based feature extractor is more suitable for training large-scale datasets.2)The model using Swin-T as the backbone to fuse image and depth maps with cross-attention outperforms the baseline (b→c) by a large margin (+ 5.58 for moderate), which demonstrates the effectiveness of transformer-based multi-modal fusion for monocular 3D object detection.3) Our transformerbased backbone for depth-image fusion is more effective than the CNN-based backbone (c → results of D4LCN* shown in Table III).4) The proposed depth-guided relative position embedding module (c → d) can achieve remarkable improvement on the 3D detection task (+ 0.66 under an easy level, +0.5 under a moderate level and + 0.57 under a hard level).5)By comparing setting (d → e), we find that the normalizing flows can effectively introduce priors into depth information and then improve overall performance, e.g., 0.46 point improvement under a moderate level.
Moreover, to explain how our proposed method improves the baseline method M3DRPN [17] on the Waymo Open dataset, we perform ablation studies on the Waymo Openvalset for thecarcategory in Table VII.Most of the observations are consistent with those on KITTI.In addition, we also find that owing to the increased volume of data contained within the Waymo Open dataset, the Transformer model demonstrates superior performance in comparison to the conventional Convolutional model (a → b).
G. Ablation on Different Depth Estimators
To explore the impact of different depth estimators on the performance of our methods and make a fair comparison between our proposed NF-DVT and existing methods, we extract depth maps using two different methods DORN [20]and BTS [21].Table VIII illustrates the evaluation results on the KITTI Eigen split (KITTI provides the dataset [90] with 61 scenes from “city”, “residential”, “road” and “campus” categories.And existing works for monocular depth estimation commonly use a split proposed by Eigenet al.[91] for training and testing).It can be seen that BTS outperforms DORN with a narrow margin in both the 0-80 m capturing range and 0-50 m capturing range.
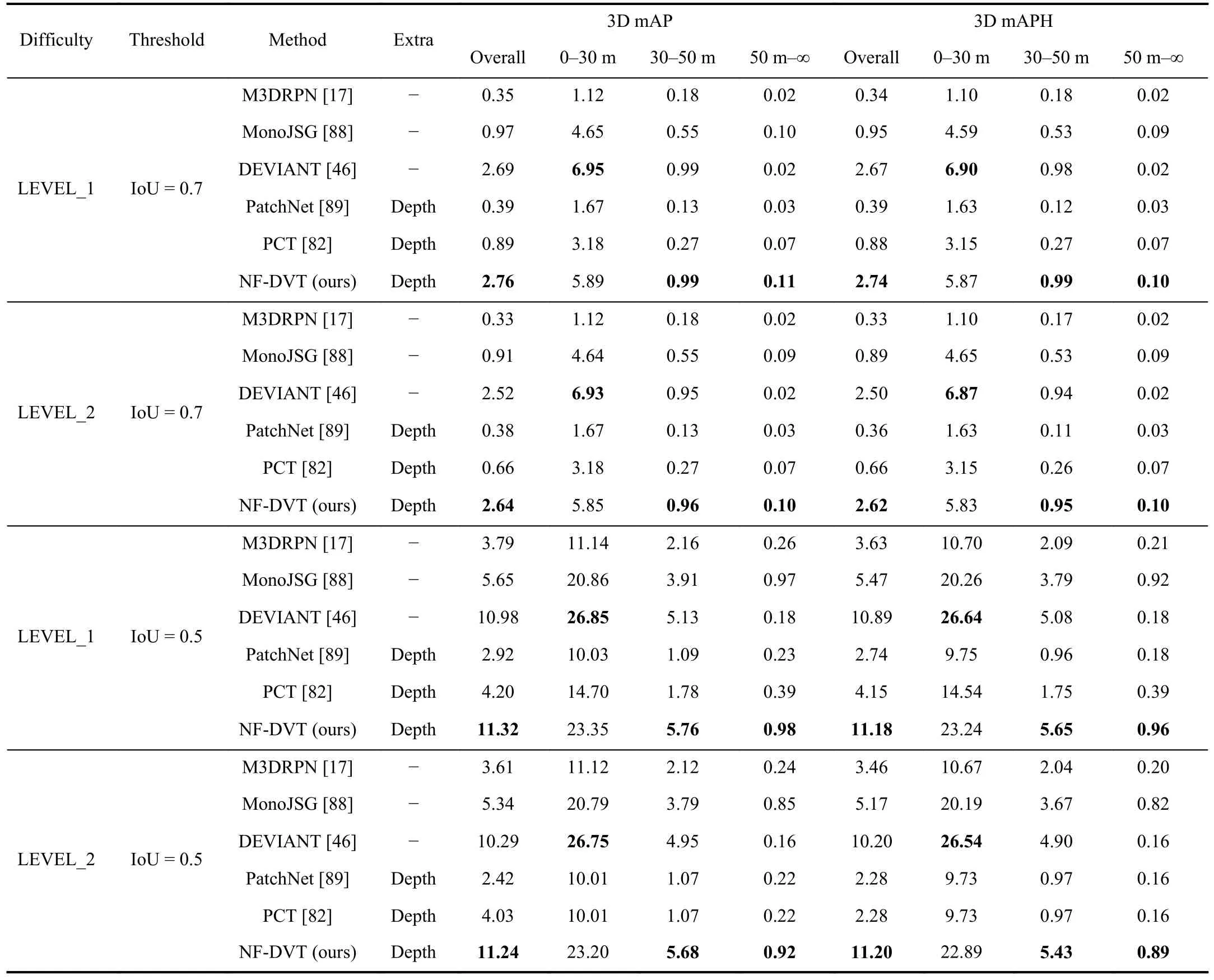
TABLE V EXPERIMENTAL RESULTS ON THE WAYMO OPEN VALIDATION SET.WE EVALUATE ON VEHICLE CATEGORY WITH 3D MAP AND 3D MAPH METRICS UNDER IOU THRESHOLD OF 0.7 AND 0.5, RESPECTIVELY.“LEVEL_1” DENOTES THE EVALUATION OF THE BOUNDING BOXES THAT CONTAIN MORE THE 5 LIDAR POINTS.“LEVEL_2” DENOTES THE EVALUATION OF ALL OF THE BOUNDING BOXES.THE BEST RESULTS ARE MARKED IN BOLD
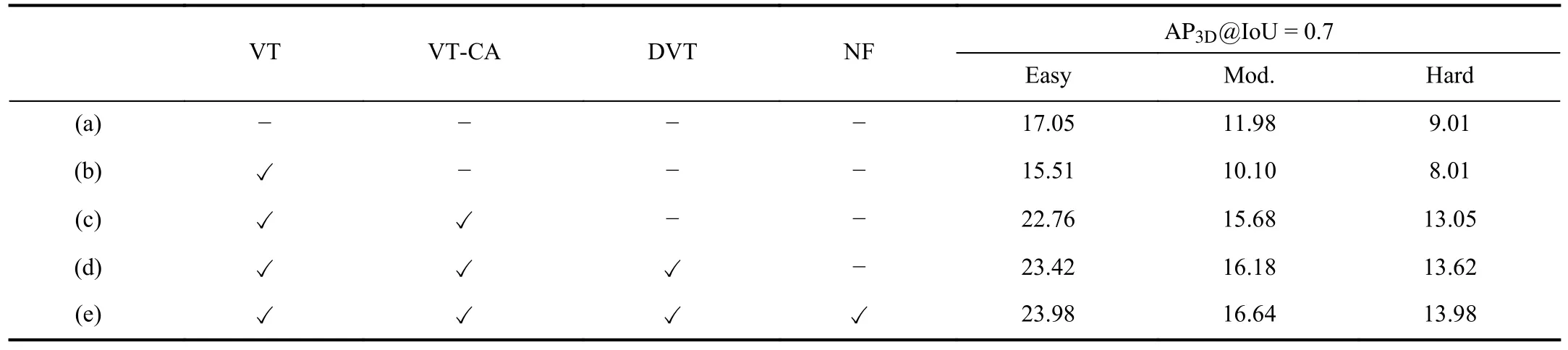
TABLE VI ABLATION STUDIES ON THE KITTI VAL SET FOR THE CAR CATEGORY.VT IS THE VISION TRANSFORMER, CA IS THE CROSS-ATTENTION TRANSFORMER, DVT IS THE DEPTH-GUIDED VISION TRANSFORMER AND NF IS THE NORMALIZING FLOW.THUS (A) USES RESNET50 AS THE BACKBONE WITHOUT DEPTH MAPS.(B) USES USING SWIN-T AS THE BACKBONE WITHOUT DEPTH MAPS.(C) USES SWIN-T AS THE BACKBONE WITH IMAGE-DEPTH CROSS-ATTENTION.(D) USES THE SWIN-T BASED CROSS-ATTENTION TRANSFORMER WITH DEPTHGUIDED RELATIVE POSITION EMBEDDING.(E) USES USING NORMALIZING FLOWS TO INTRODUCE PRIORS INTO DEPTH INFORMATION
The evaluation results on the KITTI validation dataset of the 3D object detection task are shown in Table IX.It shows that our proposed NF-DVT method outperforms D4LCN [18] with a significant margin under different depth estimators.Specifi-cally, our NF-DVT method improves D4LCN* by 1.36%/1.4% under the moderate setting at a 0.7 IoU threshold when using DRON and BTS as depth estimators, respectively.Meanwhile, compared to DORN, depth maps generated by BTS bring limited gains (0.08% under moderate setting) in performance on 3D object detection.

TABLE VII ABLATION STUDIES ON THE WAYMO OPEN DATASET VAL SET FOR THE CAR CATEGORY.VT IS THE VISION TRANSFORMER, CA IS THE CROSS-ATTENTION TRANSFORMER, DVT IS THE DEPTH-GUIDED VISION TRANSFORMER AND NF IS THE NORMALIZING FLOW.THUS (A) USES RESNET101 AS THE BACKBONE WITHOUT DEPTH MAPS.(B) USES SWIN-T AS THE BACKBONE WITHOUT DEPTH MAPS.(C) USES SWIN-T AS THE BACKBONE WITH IMAGE-DEPTH CROSS-ATTENTION.(D) IS THE SWIN-T BASED CROSS-ATTENTION TRANSFORMER WITH DEPTH-GUIDED RELATIVE POSITION EMBEDDING.(E) USES NORMALIZING FLOWS TO INTRODUCE PRIORS INTO DEPTH INFORMATION
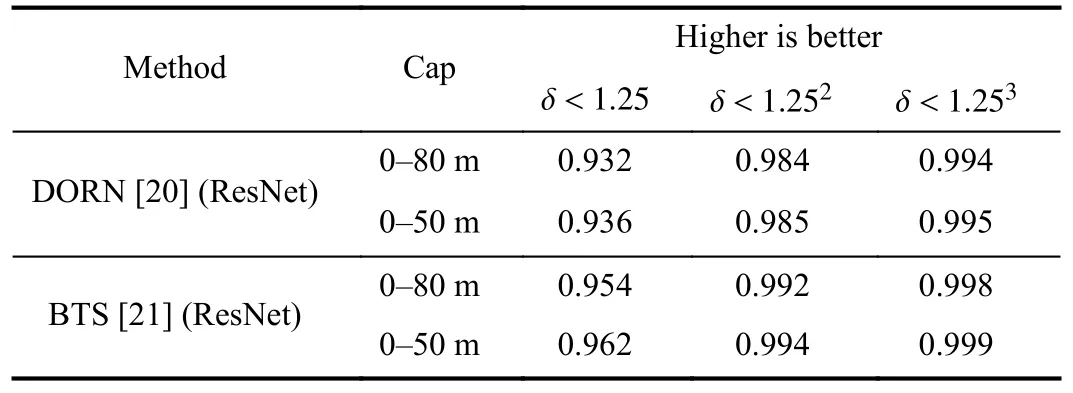
TABLE VIII PERFORMANCE OF DIFFERENT DEPTH ESTIMATORS ON EIGEN KITTI
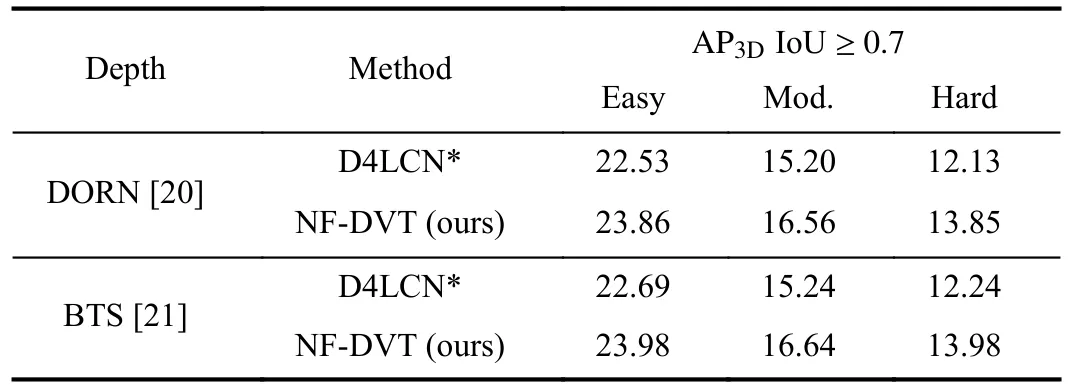
TABLE IX COMPARISON OF DIFFERENT DEPTH ESTIMATORS ON THE VAL SET OF 3D OBJECT DETECTION FOR THE CAR CATEGORY.D4LCN*REPRESENTS OUR REPLICATE RESULTS FOR D4LCN [18]WITH OFFICIAL CODE AND CONFIGURATION.ALL RESULTS ARE GIVEN BY AP|R40
H. Ablation on Different Backbones
In Table X, we conduct various experiments with different backbones to see the effectiveness of the transformer-based backbone.Note that we use D4LCN [18] as our baseline when constructing a CNN-based backbone.To build Swin-based architecture without extra input data, we substitute the ResNet by Swin Transformer [26].Furthermore, we only implement the cross-attention transformer when utilizing depth maps as extra input for the transformer-based architecture.
Swin-S and Swin-B are versions approximately 2× and 4×the model size and computational complexity of Swin-T,respectively.The architecture hyper-parameters of these model variants are:
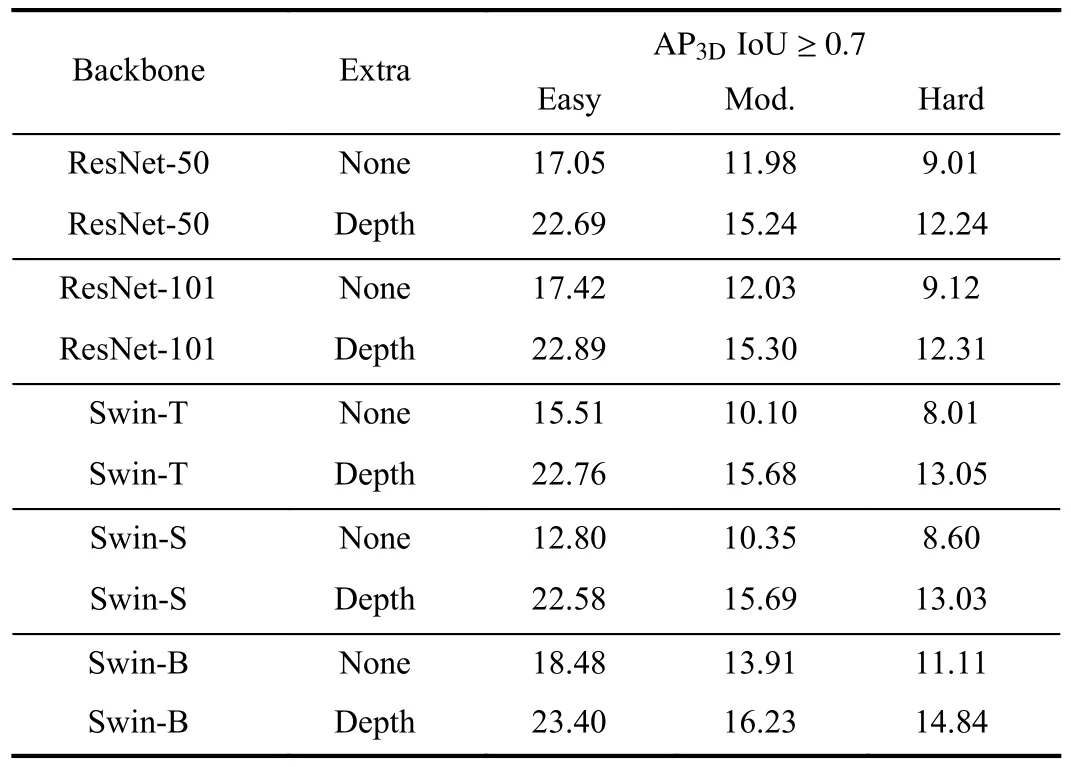
TABLE X AP|R40 SCORE OF DIFFERENT BACKBONES WITH OR WITHOUT THE HELP OF DEPTH ON THE VAL SET OF 3D OBJECT DETECTION FOR THE CAR CATEGORY
- Swin-T:C=96 , layer numbers = {2,2,6,2};
- Swin-S:C=96, layer numbers = {2,2,18,2};
- Swin-B:C=128 , layer numbers = {2,2,18,2};
whereCis the channel number of the hidden layers in the first stage.The complexity of Swin-T and Swin-S are similar to those of ResNet-50 and ResNet-101, which is mentioned in[26].
From the result, we can see that the performance improvement is very limited when using more hidden layers in the backbone (ResNet-50 → ResNet-101 and Swin-T → Swin-S)with or without depth maps.However, the most significant improvement is made by increasing the channel numberCin the transformer-based backbone (Swin-S → Swin-B).Swin-B improves with respect to Swin-S by 3.56%/0.54% under the moderate setting with and without extra input, respectively.Moreover, simply using a transformer-based network instead of a CNN-based network as the backbone results in worse performance for the 3D detection task.Additionally, still achieve improvements after image-depth fusion with the cross-attention mechanism.When using the depth map as an extra input,Swin-T improves with respect to ResNet-50 by 0.44% under the moderate setting and Swin-S improves with respect to ResNet-101 by 0.39% under the moderate setting.
I. Ablation on Different Transformer-Based Backbones
As shown in Fig.5, we build a new framework using the transformer encoder-decoder structure [49], [54] to verify the effectiveness of our proposed method.The framework mainly consists of four components: the backbone, transformer encoder module, transformer decoder module and the 2D-3D detection head.We use ResNet-50 [1] as backbones with a network stride factor of 16 to extract features from RGB images and depth maps.Similar to [54], the self-attention mechanism in the transformer encoder module is used to enhance the image features.And the transformer decoder module is the same as the standard structure in [54], except that the object query is the depth feature maps.The predefined 2D-3D anchor-based detection head is the same as mentioned before.
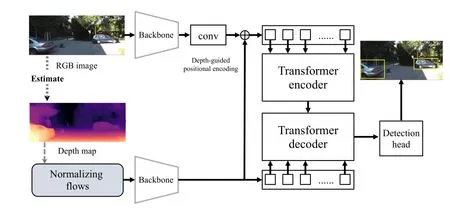
Fig.5.The new framework of our proposed approach when using a transformer encoder-decoder structure [49].
In Table XI, we conduct ablation experiments on KITTI validation set using the new framework.The results show that our proposed depth-guided positional encoding and depth map enhancement with normalizing flows are still effective under a new transformer-based structure.
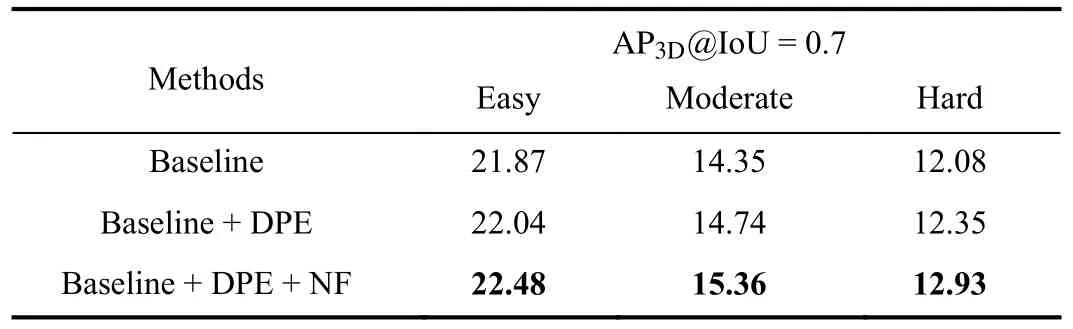
TABLE XI PERFORMANCE OF OUR PROPOSED NF-DVT ON THE KITTI VALIDATION SET WHEN USING OTHER TRANSFORMER-BASED BACKBONES.DPE MEANS DEPTH-GUIDED POSITIONAL ENCODING AND NF MEANS USING NORMALIZING FLOWS TO BUILD PRIORS IN DEPTH MAPS
J. Ablation on Inference Speed
In Table XII, we show the runtime and performance of the CNN-based method with or without depth as extra input(D4LCN and MonoFlex) and our transformer-based method(DVT and NF-DVT) on a single RTX 2080Ti GPU.For engineering considerations, the time consumption of depth estimation and normalized flow modules is taken into account in both the CNN-based model (D4LCN) and our transformerbased model (DVT and NF-DVT), resulting in a much slower inference speed than a model without additional input like MonoFlex.
The results illustrate the trade-off of our model in speed and performance.Firstly, the results show that our NF module for depth map preprocessing only brings a 3 ms increase during inference, which is almost negligible but will bring performance improvement.Moreover, our NF-DVT method with the Swin-T backbone achieves better performance and faster inference speed than D4LCN with the ResNet-101 backbone.Finally, the inference speed of our model can also be improved with a faster base model.For example, our NFDVT-MonoFlex model is 40ms faster than the NF-DVTD4LCN model.
K. Qualitative Results
Qualitative visualization on KITTI validation dataset is presented in Fig.6.The prediction 3D bounding boxes of our model are shown in the images.It can be seen from the results that our model is effective for large objects such as acarand small objects such as apedestrian.For better visualization, we also provide the results in a bird’s-eye-view and 3D space,which demonstrate that our proposed model can recover object distances and predict the rotation of objects accurately.
Some failure cases of our proposed NF-DVT method on the KITTI validation dataset are provided in Fig.7.We provide two possible cases, i.e., 1) small objects with apedestrianandcyclist, 2) and severely truncated objects close to the camera.These two scenarios are still challenging for the current monocular 3D object detection methods.
Moreover, qualitative visualization of the Waymo Open Dataset validation set is presented in Fig.8.The results suggest that our proposed model is capable of achieving accurate predictions in complex environmental conditions, including varying weather patterns (sun, rain and fog) and different times of day (Day and Night).Nevertheless, the model’s predictive capacity seems to falter in the case of truncated objects and distant entities situated beyond a 30 m range.This setback is consistent with earlier research and presents a formidable challenge for future investigations.
V.CONCLUSION
In this paper, we propose a novel depth-guided vision transformer framework with normalizing flows (NF-DVT) for monocular 3D object detection.We use normalizing flows to build priors in pixel-wise depth maps to achieve more accurate depth information.Then we develop a novel transformerbased backbone with a fusion module based on cross attention for the depth map and RGB image with two separate branches and then fuse them with a cross-attention mechanism to exchange information with each other.Meanwhile, we re-weight the original relative position embeddings in the cross-attention module with the help of the refined depth maps.Extensive experiments on the KITTI dataset and largescale Waymo Open dataset show the effectiveness of our proposed method and superiority over previous state-of-the-art monocular-based methods.

Fig.6.Qualitative results on KITTI validation dataset.The ground truths and our prediction results are in green boxes and red boxes, respectively.We provide (a) 3D bounding boxes in camera-view images; (b) projections of the 3D bounding boxes in bird’s-eye-viewl; and (c) 3D bounding boxes in 3D space.
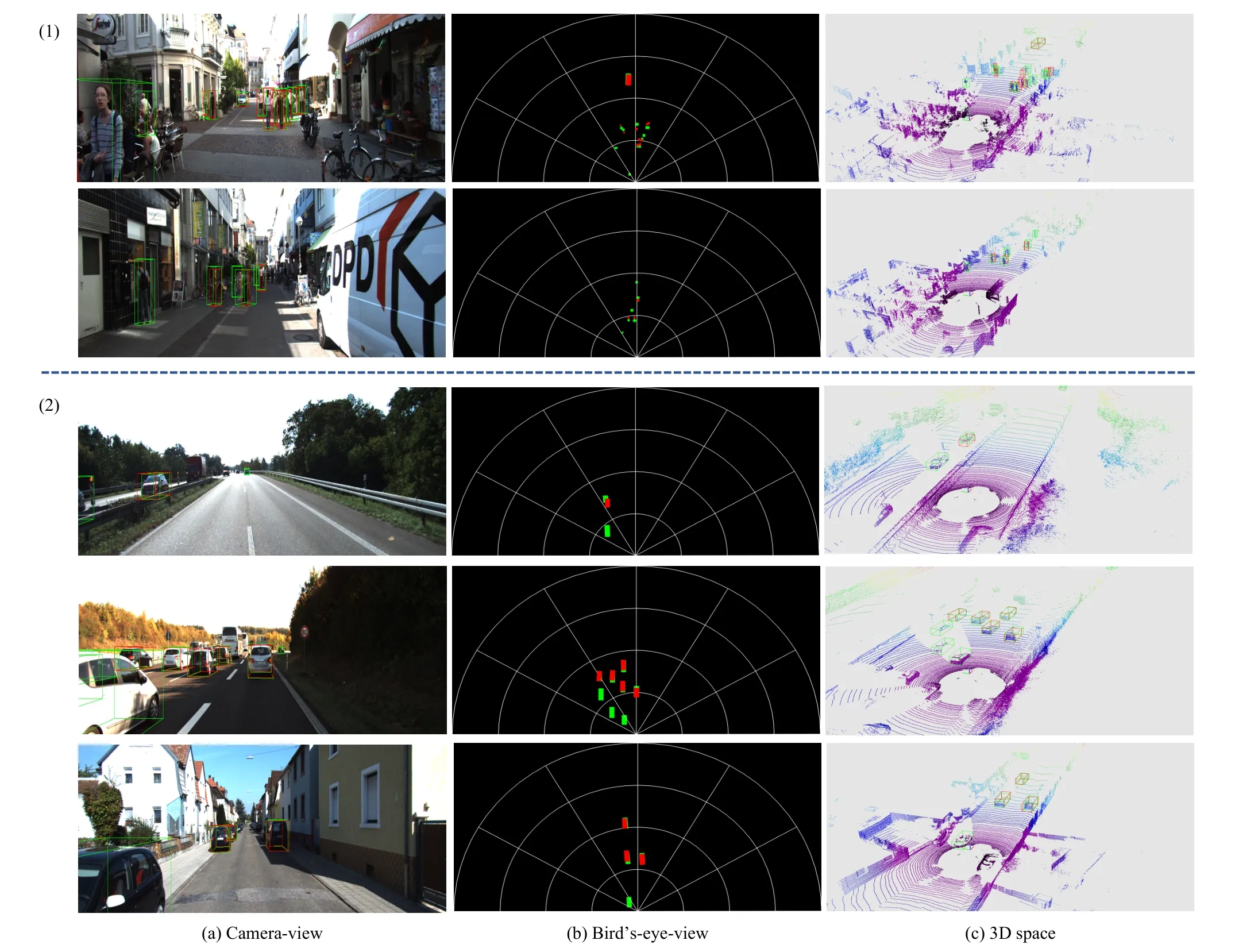
Fig.7.Visualization of failure cases of our proposed NF-DVT method on KITTI validation dataset.The ground truths and our prediction results are in green boxes and red boxes, respectively.We provide two possible cases: 1) Small objects pedestrian and cyclist; 2) Severely truncated objects close to the camera.
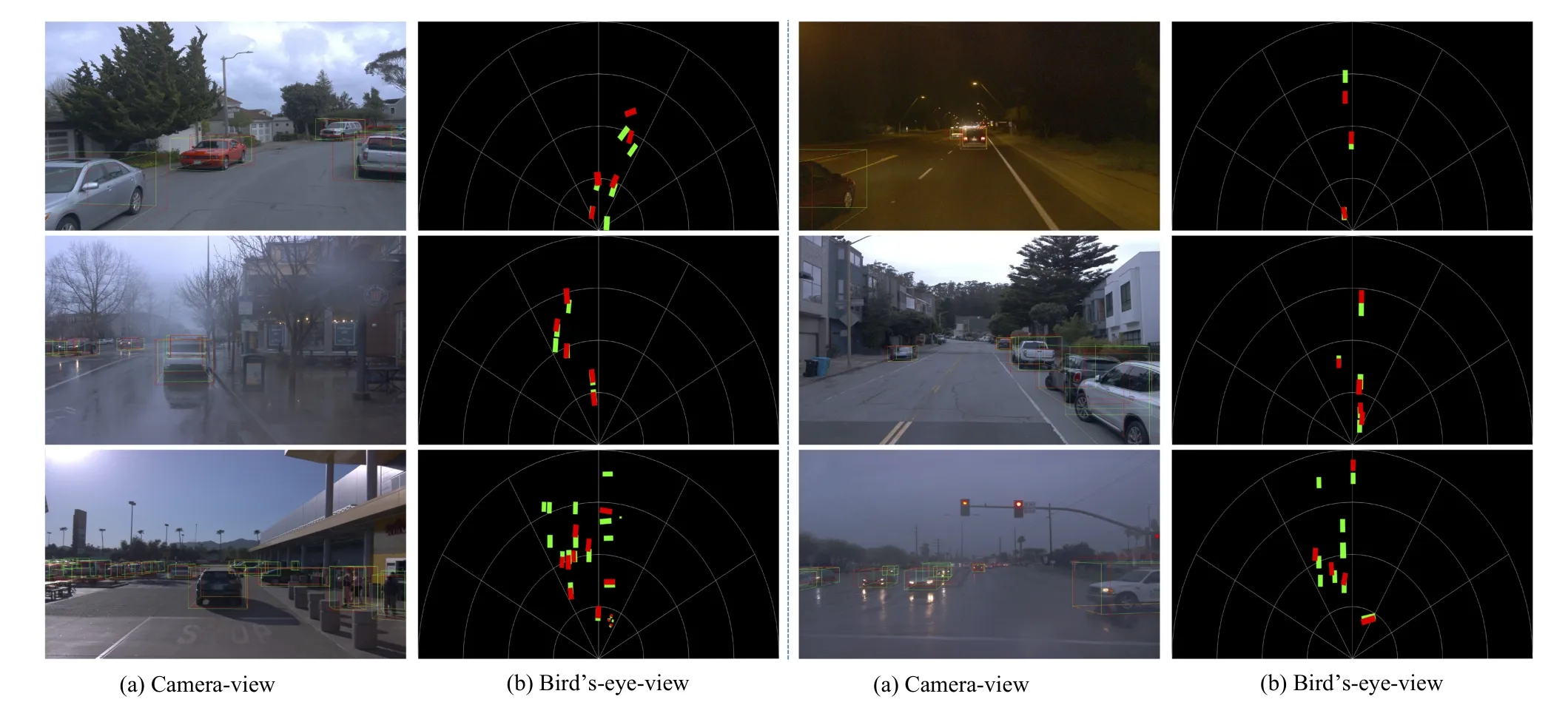
Fig.8.Qualitative results on the Waymo Open Dataset validation set with varying weather patterns (sun, rain and fog) and different time of day (Day and Night).The ground truths and our prediction results are in green boxes and red boxes, respectively.We provide (a) 3D bounding boxes in camera-view images;and (b) projections of the 3D bounding boxes in bird’s-eye-view.
 IEEE/CAA Journal of Automatica Sinica2024年3期
IEEE/CAA Journal of Automatica Sinica2024年3期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Set Stabilization of Large-Scale Stochastic Boolean Networks: A Distributed Control Strategy
- Dendritic Deep Learning for Medical Segmentation
- Achieving 500X Acceleration for Adversarial Robustness Verification of Tree-Based Smart Grid Dynamic Security Assessment
- Communication-Aware Mobile Relaying via an AUV for Minimal Wait Time: A Broad Learning-Based Solution
- Simulation Analysis of Deformation Control for Magnetic Soft Medical Robots
- Multi-Timescale Distributed Approach to Generalized-Nash-Equilibrium Seeking in Noncooperative Nonconvex Games