
Targeted multi-agent communication algorithm based on state control
2024-02-29 08:24LiyngZhoTinqingChngLeiZhngJieZhngKixunChuDepengKong
Defence Technology 2024年1期
Li-yng Zho , Tin-qing Chng , Lei Zhng , Jie Zhng , Ki-xun Chu ,De-peng Kong
a Department of Weaponry and Control, Army Academy of Armored Forces, Beijing,100072, China
b Unit 92942, Beijing,100161, China
Keywords: Multi-agent deep reinforcement learning State control Targeted interaction Communication mechanism
ABSTRACT As an important mechanism in multi-agent interaction, communication can make agents form complex team relationships rather than constitute a simple set of multiple independent agents.However, the existing communication schemes can bring much timing redundancy and irrelevant messages, which seriously affects their practical application.To solve this problem, this paper proposes a targeted multiagent communication algorithm based on state control(SCTC).The SCTC uses a gating mechanism based on state control to reduce the timing redundancy of communication between agents and determines the interaction relationship between agents and the importance weight of a communication message through a series connection of hard- and self-attention mechanisms, realizing targeted communication message processing.In addition, by minimizing the difference between the fusion message generated from a real communication message of each agent and a fusion message generated from the buffered message, the correctness of the final action choice of the agent is ensured.Our evaluation using a challenging set of StarCraft II benchmarks indicates that the SCTC can significantly improve the learning performance and reduce the communication overhead between agents,thus ensuring better cooperation between agents.
1.Introduction
Fully cooperative tasks, such as coordinated planning of autonomous driving vehicles [1-3], control of multiple autonomous robots[4,5],and scheduling of intelligent warehouse systems[6], occupy most scenes in multi-agent systems (MASs).However,these tasks face the problem of multi-agent cooperation.Recent studies on multi-agent deep reinforcement learning(MADRL)have made certain progress in solving this problem by modeling it as a multi-agent cooperative learning problem.The MADRL uses deep learning (DL) to transform low-level input features to form an abstract high-level representation that is easy to understand and can be used in subsequent tasks so that an agent has the abilities to perceive, abstract, and express the surrounding environment [7].Then, reinforcement learning (RL) is used to maximize the longterm cumulative reward obtained by the agent in the environment to learn an optimal policy for a specific task and thus provide the agent with exploration and decision-making abilities[8,9].
However, in the practical application of the MADRL, due to the limited perception of agents, they cannot obtain the global observation of the environment.Namely, agents can make only local decisions according to their local observation messages and director indirect-interaction messages with other agents.In addition, in the training stage, due to the simultaneous learning of multiple agents in the environment, the actions and policies of each agent affect the other agents,resulting in a non-stationary problem of the environment [10].This problem greatly increases the convergence difficulty and exploration complexity of the algorithm and reduces its stability.At the same time, in fully cooperative tasks, where all agents in the environment share the same global rewards[11],it is difficult to reflect the contribution of each agent’s action to the global rewards accurately, resulting in severe problems of credit allocation and “Lazy Agents” [12].
Recent studies have shown that introduction of a communication mechanism into the MADRL based on cooperative learning can significantly improve the overall performance[13-15].Still,in realworld tasks, many multi-agent tasks cannot be completely decomposed, and agents sometimes need messages from other agents to coordinate their actions effectively.Specifically, if the optimal action-value function of an agent depends on the behaviors of the other agents at the same timestep, the joint action-value function will not be fully factorized and cannot be perfectly represented by algorithms such as the QMIX.In addition, as an important mechanism in the interaction process of multi-agent[16,17], communication can make agents form complex team relationships and not only constitute a set of multiple independent agents.Also, through the communication mechanism, agents can exchange their perspective observations, action policies, intention tendencies, and other messages and use them to make better decisions when an environment is considerable due to various restrictions.Therefore, the introduction of a communication mechanism into the MADRL based on cooperative learning can reduce the learning complexity and improve the representation of the joint action-value function.
However, in an actual decision-making process, a communication message received from other agents is not completely useful.The introduction of redundant messages can affect learning convergence and agents’ interaction and weaken the attention to important agent messages, especially in a large-scale MAS.Moreover,redundant messages can severely affect the update process of agent policies.This paper believes that these problems can be solved by targeting communication messages and objects.In addition, communication is not always needed between agents.First,a communication message continuously observed in an actual environment is highly correlated in time.Second,in environments where the communication is disturbed, the communication bandwidth is limited, the communication medium is shared, and the communication cost is high;thus,the reduction of communication overhead could effectively improve the overall efficiency of the communication system [18].Therefore, this paper believes that only when the environmental state changes significantly or a useful message is observed,for instance, in the case of the emergence or disappearance of enemy targets in a battlefield environment,agents can send their messages.
Aiming at addressing the above-mentioned problems, this paper proposes a targeted multi-agent communication algorithm based on state control(SCTC).By using the gating mechanism based on state control,the SCTC can broadcast communication messages only when the current communication message changes greatly in comparison to the previously broadcasted communication message or when the timestep meets the broadcast cycle.At the same time,thereceivedmessagebufferis used to store the latest communication messages broadcasted by other agents, and the buffered communication messages are used to make decisions.The gating mechanism and message caching mechanism based on state control reduce the communication overhead and make communication robust.In addition, the SCTC determines the interaction relationship between agents and the importance weights of communication messages by areceivedmessageprocessorwith a series connection of the hard- and self-attention mechanisms,realizing targeted communication message processing.In the training phase, to avoid the final action selection result being affected by a buffered message, a regularizer is introduced to minimize the difference between the fusion message generated from a real communication message of each agent and a fusion message generated from the buffer message.In addition, by using parameter sharing and training the joint action-value functionQtot,which includes global statestand joint action,the problems of non-stationary environment and credit allocation are effectively solved.The SCTC is evaluated by experiments on the StarCraft Multi-Agent Challenge (SMAC) benchmark [19].The experimental results show that compared with the state-of-the-art (SOTA)baseline algorithms, the SCTC algorithm can significantly enhance the learning performance through targeted communication and also improve the collaboration between agents.In addition,through the gating mechanism based on state control,the SCTC can eliminate redundant communication information associated with timing, thus effectively reducing the communication overhead.
2.Related work
The MADRL can be divided into three categories depending on the way used to maximize joint rewards.The first category includes the MADRL methods based on independent learning, which directly apply a single-agent deep reinforcement learning-based algorithm to a multi-agent environment and decompose a multiagent learning problem into multiple independent and decentralized single-agent learning problems[10].In this type of method,an agent pays attention only to its state and action when updating the policy and regards other agents as a part of the environment without considering the instability caused by environmental dynamics, which can easily cause policy overfitting [20].
The second category includes the MADRL methods based on collaborative learning.These methods adopt the centralized training with decentralized execution(CTDE)paradigm to evaluate joint policies of all agents in a centralized way during training so as to coordinate agents’behaviors better[21,22].During the execution process, each agent executes separately without direct communication with other agents.According to the evaluation method of joint policies,these methods can be divided into two groups:value function decomposition (VFD) methods and centralized value function (CVF) methods.The CVF methods take advantage of the particularity of the actor-critic (AC) algorithm [23] structure and alleviate the non-stationary problem of an environment to a certain extent by learning a fully-centralized critic and an independent actor of each agent [12,24,25].However, the joint action observation space dimension of a fully-centralized critic network increases exponentially with the number of agents,so it is difficult to obtain a satisfactory large-scale solution, and additional state messages cannot be used during training.For instance, COMA [12] uses a centralized critic network to calculate the differenceAi(s,) in the global return when agents follow the current actor policy and when they follow the default policy,which is then used to evaluate advantages of the agents’current actions over their default actions.This can effectively solve the multi-agent credit allocation problem and reduce the variance of the policy gradient.
The VFD methods mainly consider how to learn a centralized but decomposableQtot, so as to reduce the learning complexity ofQtotby learning an independent individual utility functionQi(τi,ai) [26-29].These methods can use an additional global state message to enhance the expression ability of a mixing network and realize the decomposition ofQtot.However, the decomposition method cuts off the dependence between the decentralizedQi,which results in the uncoordinated and poor random action of an agent in the execution process.The QMIX [27] uses a mixing network with non-negative weights to estimateQtotbased onQiandstso thatQiis monotonic toQtot.The Qatten[28]uses a multihead attention mechanism to approximateQtotand reduce the boundedness caused by the attention mechanism by flexibly adjusting the weights of different headsQi.
The third category introduces a communication mechanism between agents [13-15].The communication mechanism allows agents to dynamically adjust their policies according to their local observations and message received from the other agents, rather than regarding the other agents as a part of the surrounding environment.In this way, the problems of observability and nonstationarity of the environment can be effectively alleviated.However, the success of its policy strongly depends on the availability of the received message.The representative algorithms of this category include the VBC [13], NDQ [14], and TMC [15].The NDQ algorithm [14] introduces two regularizers to maximize the action choice of agents and mutual information between communication messages while minimizing the information entropy between agents, thus reducing the uncertainty of communication messages toQiand achieving the communication information succinctness.The VBC [13] adopts the method of variance control.The VBC first determines whether to communicate based on the confidence ofQi, and then it decides whether to respond to the communication request based on the variance value of an agent’s own communication message, realizing the responsive communication.The TMC [15] reduces the number of hourly messages by introducing regularizers and effectively enhances the robustness to the transmission loss in the message transmission process by establishing a buffer mechanism.
3.Preliminaries
3.1.Decentralized partially observable MDP
In the fully cooperative MADRL,the interaction process between the MADRL and the environment can be modeled as a decentralized partially observable Markov decision process(Dec-POMDP)[30,31].The Dec-POMDP can be defined as a tupleM= <N,S,,P,Ω,O,r,γ >,whereN≡{1,2,…,i,…,n}denotes a finite set of agents,andSis a finite set of global states.Any states,s∈S, contains information required by the system for decision-making.The next states' is uniquely defined by the current system statesand the actionato be taken and does not depend on the previous state and action.AssumeAi∈≡{A1,A2,…,An}represents an action set that an agentican take,whererepresents the joint action set of all agents.At a timestept,each agent receives an independent local observationoi∈Ωiaccording to the observed probability functionO(oi|s,ai).Then, an actionai∈Ai≡{Ai(1 ) , … ,Ai( |A| ) } is selected to form a joint action≡{a1,a2, …,an}.According to the transition functionP(s' |s,),system is transferred to a new states', and a joint rewardr(s,) is obtained.In a decisionmaking periodt= 0,1,2 , … ,T- 1, each agent uses its own local action-observation historical data τi∈Ti≡ (Ωi×Ai)*to construct an independent policy πi(ai|τi).Then, joint policies of agents π :π1×π2× … ×πnare obtained and the expected cumulative joint rewardin the decision-making period is maximized.Further,γ represents a discount factor,and γ ∈[0,1].When γ is close to zero, the focus is on the current reward, but when γ is close to one,the long-term rewards are considered.The advantages and disadvantages of the joint policies π can be evaluated by the joint action-value function, which is defined as.
Team cooperation represents the core of the Dec-POMDP.In the Dec-POMDP, the decision-making process of agents is decentralized, and agents make decisions only based on their local observations independently.Although the cooperation protocol between agents is not explicitly defined in the model, possible actions of agents must be considered in the policy executed by each agent in the decision-making process.
3.2.Deep Q-networks and deep recurrent Q-networks
Deep reinforcement learning (DRL) based on a value function uses a deep neural network to approximate the action-value functionQ(s,a;θi).The optimal policy π*(a|s) =argmaxa∈AQ*(s,a) is obtained indirectly during the iterative process of the action-value function.Deep Q-network (DQN) [9] is representative of the DRL algorithm based on the value function.The DQN uses the experience replay andtargetnetwork.By using the loss minimization function,which is given byLi(θi) =E(s,a,r,s' )~D[ (yi-Q(s,a;θi) )2], the recursive training ofQ(s,a;θi) is performed,where 〈st,at,rt,st+1〉denotes a data sample that has been randomly selected from the replay bufferD, andyi=r+γmaxa'Q(s' ,a' ;θi-);θ-indicates the parameters of thetarget network.During the training phase,θ-is periodically copied from thebehaviornetworkθ, and it is kept unchanged for several iterations.Thebehaviornetworkuses the ε -greedypolicy [32] for sampling to ensure that enough new states are experienced and full exploration is achieved.Thetargetnetworkis evaluated using the greedy policy to ensure that the policy finally converges to the optimal policy.
The Dec-POMDP problem is different from the MDP problem,and its state is partially observable.Therefore, it is very important for an agent to remember the historical information and force the algorithm to have a memory mechanism to store the previously received observation data.The DQN generates actions only based on the current local observationswithout considering prior knowledge.The deep recurrent Q-networks(DRQN)[33]combines the recurrent neural network (RNN) with the DQN.At each timestept, the DRQN uses the recurrent structure of RNN to integrate the current local observationwith the hidden-layer state of RNN at the last step-1 to generate an action-value functionQi(τi,ai)for improving decision-making.
4.Methods
This section introduces the proposed SCTC algorithm in detail.The main idea of the SCTC algorithm is to use the gating mechanism based on state control to reduce the communication overhead and avoid the long-term impact of small changes in communication messages effectively.The selection and weighing of communication messages are realized through the series connection of hard- and self-attention mechanisms.Based on the CTDE paradigm,the joint action-value functionQtot, including the global statestand joint action, is trained to solve the non-stationary problem of the environment and improve training stability.
4.1.Agent neural network design
The agent neural network framework is shown in Fig.1,where it can be seen that it is mainly composed of theactionvaluecombiner,localactiongenerator,localobservationprocessor,sentmessage encoder,receivedmessageprocessor,sentgate, andreceivedmessage buffer.The localobservationprocessorconsists of a multilayer perceptron (MLP) and a gated recurrent unit (GRU) [34].In thelocal observationprocessor, a local observationof an agentiis first processed by the MLP and then fed to the GRU with a hidden state-1 to obtain the central feature vector.Thelocalactiongeneratorand thesentmessageencoderhave the same structure consisting of an MLP, and the only difference between them is that the former uses the ReLU activation function and the latter uses the Leaky ReLU activation function.The output resultof thelocalobservation processoris input to thelocalactiongeneratorto obtain a local actionvalue functionand to thesentmessageencoderto obtain a message.The messageis broadcasted to the other agents when thesentgateis open.Thereceivedmessagebufferis used to store messages broadcast by other agents.When a new messagemjis broadcasted to the channel,thereceivedmessagebufferwill be updated.Thereceivedmessageprocessoruses messageobtained by thesentmessageencoderand buffer messagemj∈-istored in thereceivedmessagebufferas inputs to obtain a fusion message.Bothare input into theactionvaluecombinerto obtain the final individual utility function.
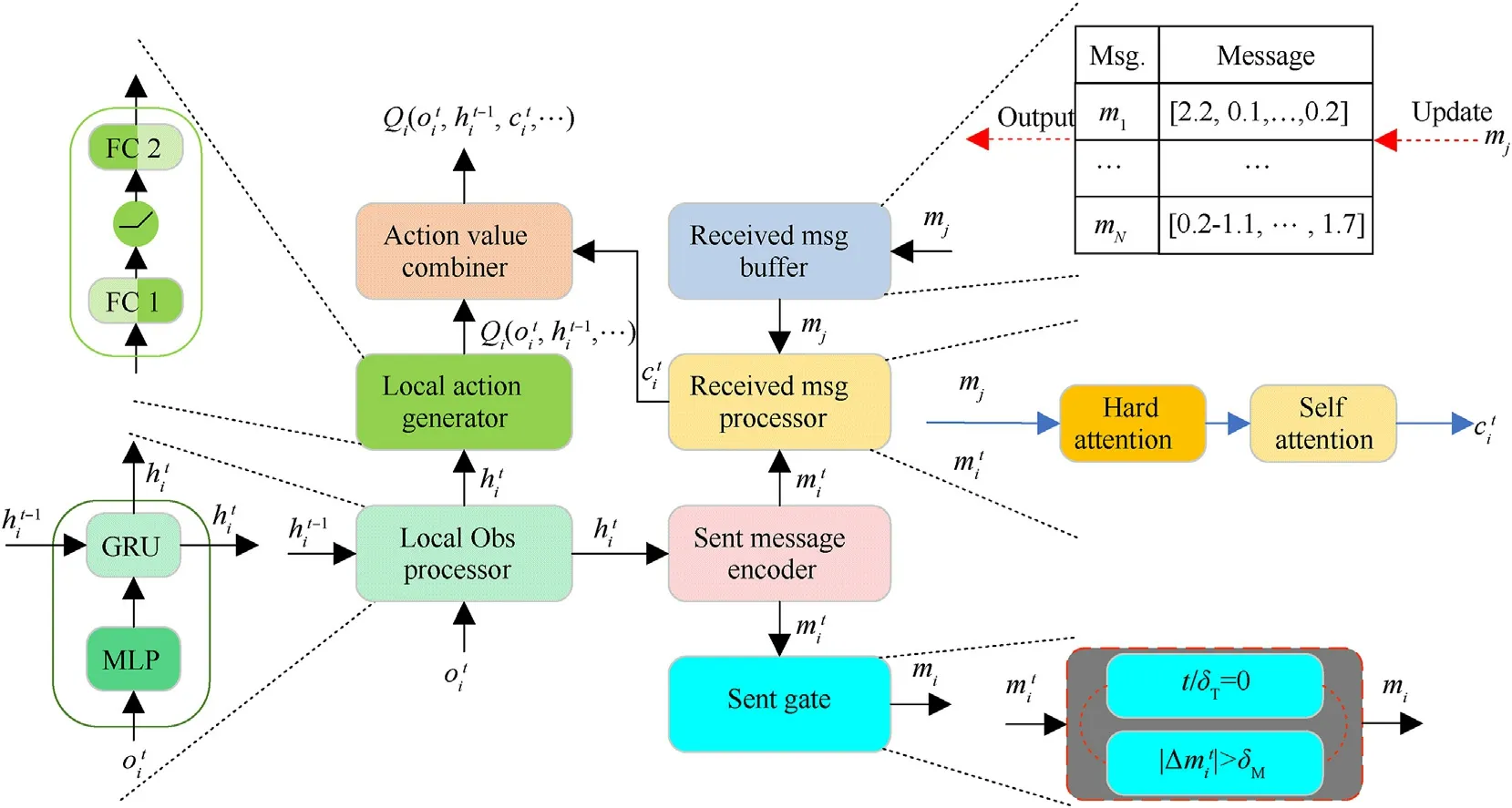
Fig.1.The neural network structure of an agent i.
4.1.1.Communicationprotocoldesignbasedonstatecontrol
To solve the problem of agent communication overhead, this paper proposes a gating mechanism based on state control.Since a message continuously observed in an environment is often highly correlated with time, this study assumes that only when the environmental state changes significantly or a useful message is observed, messages can be broadcasted to the other agents.The Euclidean distancebetween a communication messageobtained by the currentsentmessageencoderand a messagemibroadcasted through the lastsentgate, which is calculated by Eq.(1), is used to determine changes between the sent messages.Whenis larger than the threshold δM,is allowed to be broadcasted by thesentgate.In addition, to prevent thesentgatefrom being closed due to long-term slight changes in a communication messageat the sending end, as well as to prevent a communication messagemifrom not being updated for a long time,timer δTupdating is introduced to open all agents’ sent gates and allow the communication message to be broadcasted.It should be noted that timer δTand communication massage variationcan be simultaneously used to control message transmission.The threshold of timer δTis set such that to allow agents to broadcast their communication messages at the same timestep, but the sent gate state change of each agent is controlled by the communication message variation.Assume thatGatemirepresents the sent gate state of an agent i,where“1”indicates that the sent gate is open, and “0” indicates that the sent gate is closed.The value ofat timestep t can be obtained by Eq.(2).
Inthereceivedmessagebuffer,duetothecommunicationrangeand message transmission loss,a buffer messagemj∈-ithat has not been updated for a long time can affect the decision-making process of an agenti.Therefore,atimerδRisusedtoprocessmessagesinthereceived messagebuffer,whichhavenotbeenupdatedforalongtime.Whent--update >δR,mjin thereceivedmessagebufferwill be set to vector 0,wheretdenotesthecurrenttimestep,and-updateisthe last timestep in thereceivedmessagebufferof an agentiwhen the communication messagemjfrom the agentiwas updated.
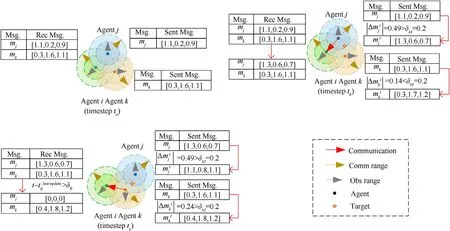
Fig.2.Illustration of the transmission process of a communication message of an agent i; communication between agents j and k is not displayed.
In Fig.2, in the execution stage, the communication message generated by an agent represents a three-dimensional vector.At timestepta, agenticompletes caching of the broadcast communication messagesmjandmkof agentsjandk, respectively.At timesteptb,the target appears in the observation of agentsjandk,which results in changes in the communication messages.Namely,mjis changed from[1.1,0.2,0.9]to[1.3,0.6,0.7],andmkis changed from [0.3, 1.6, 1.1] to [0.3, 1.7, 1.2].The calculation of the communication message variation shows that thesentgateof agentjis open,while thesentgateof agentkis closed.Meanwhile,agentiis between the communication ranges of agentsjandk,andtb-ta<δR.In this case,thereceivedmessagebufferof agentican receive only the communication message broadcasted by agentj.At timesteptc, the communication messages of agentsjandkare further changed, and the calculated communication message variations are all larger than the threshold δM.However, agentiis in the communication range of agentkbut beyond the communication range of agentj.In the period from timesteptbto timesteptc,since thereceivedmessagebufferof agentidoes not update the communication messagemjof agentjfor a long time,i.e.,tc-tb>δR,mjin thereceivedmessagebufferis set to zero.
4.1.2.Targetedcommunicationmessageprocessing
Targeted communication is required to build a complex collaboration policy.Due to the problem of determining which agents are used for message interaction, this paper proposes areceivedmessageprocessorwith a series connection of hard- and self-attention mechanisms to determine the interaction relationship between agents and importance weights of messages.The self-attention mechanism [35] uses the softmax function to determine the weight distribution of related agents.However,in this mechanism,small but non-zero weights can still be assigned to unrelated agents, which weakens the attention degree to important agents.Moreover,this mechanism cannot be used to reduce the number of agents that need to interact directly.The hard-attention mechanism selects a subset from the input element set and makes the model focus only on important elements while completely cutting off the relation with unimportant elements.Therefore,before using the self-attention mechanism to determine the importance distribution of each agent, the hard-attention mechanism is used to determine whether there is an interaction between agents.

Fig.3.Block diagram of the hard-attention mechanism.
Traditional RNN is prone to the exploding and vanishing gradients in the BPTT process [36].Moreover, the network output depends only on the current timestep message and the hidden state message of the last timestep, which constitute the network input,while the input message of the next timestep has no effect on the network output.However, due to the interaction relationship of agents, the weight of the relationship between agentsiandjis affected by messages of the other agents in the environment.Therefore, the Bi-GRU network is used as an encoder in the hardattention mechanism to make full use of messages of all agents in the environment so that to learn the interactionwi,jh∈{0,1 }between agentsiandj.As shown in Fig.3,at timestept,for agenti,the communication messageobtained by the currentsent messageencoderis combined with messagemjin thereceived messagebufferto obtain a feature,which is then used as the input of the Bi-GRU network.In addition, due to the problem that the gradient cannot be propagated back because of the sampling process in the hard-attention mechanism, the Gumbelsoftmax function [37] is used to realize an approximate output of{0,1 } [38].The Gumbel-softmax function is defined as follows:
where viis the probability vector of the network input;gi= -lg(-lg(εi));εi~Uniform(0,1);ρ is the temperature coefficient,which is used for adjusting the size of each dimension of vector to increase the difference between the output values of each dimension,so as to approximately obtain the output of {0,1 }.
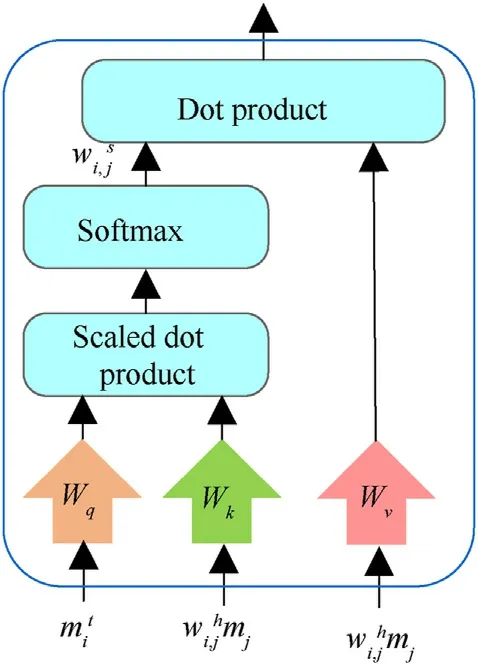
Fig.4.Block diagram of the self-attention mechanism.
The calculation formula of the hard-attention mechanism weightwi,jhis as follows:
whereLinner( · ) denotes a fully connected layer for relational mapping.
The interaction between agents can be determined by the hard attention mechanism, and the Gumbel-softmax function can ensure the gradient transfer.
By using the self-attention mechanism (see Fig.4), the communication messagewi,jhmjof agents with an interaction relationship is weighted.The self-attention mechanism[35]uses a key-value-query model.First, the dot product with scaling is calculated by determining communication messageobtained by the current sentmessageencoderand messagemjstored in thereceivedmessagebuffer, which determined to have an interaction relationship by the hard-attention mechanism.Then, the selfattention weightwi,jsof the communication messagemjof agents with an interaction relationship is obtained using the softmax function.Intuitively,when agentsiandjpredict similar query and key vectors, respectively, the self-attention weightwi,jsis higher.In addition,during the self-attention weight calculation,not only the mutual correlation degreewi,jsof an agent’s message with communication messages of the other agents is calculated but also its self-correlation degreewi,is.In this way, an agent will be focused more on its own observation and behavior when other agents have little influence on his behavior.The final outputof the received message processor represents the dot product of the value vector and self-attention weight, which can be expressed as
whereM∈N, representing a group of agents with an interaction relationship;Wq,Wk, andWvrepresent the embedding layer matrixes of query, key and value, respectively, which are used to project the vectors to different dimensional spaces;dkis the dimensions of key and query vectors.
To determine which message is communicated between agents,the feature extraction is performed for the central feature vectorin the GRU network using thesentmessageencoderto obtain the encoded communication message.Therefore, the communication message is not predefined but learned based on the MLP network representation.In addition, agents are classified into different dynamic groups by the hard-attention mechanism instead of using specific predefined objectives,targeting all or some of the messages, which can represent complex interactions between agents better.At this point,the entire communication architecture is differentiable, and the message vectors can be learned and trained by the backpropagation algorithm.
4.1.3.Simplifiedmessageaggregation
To reduce model complexity and facilitate the calculation process,the dimension of the local action-value functionQi(-1,.)is set to be the same as that of the fusion message,and the local action-value function is used as an input of theactionvalue combiner.Theactionvaluecombinerdirectly calculates, .) andby way of sum to obtain the final individual utility function value.Since the individual utility functionintroduces the communication message,which includes the observation messageand historical messagesfrom the other agents,the action selection can be better performed.In the training stage,the ε-greedypolicy is used forto perform action selection.The communication protocol of an agentiin the SCTC method is shown in Algorithm 1.


4.2.Centralized training
In this study, the CTDE paradigm is employed to learn the decentralized policies of each agent using a centralized network.In centralized training, it is assumed that the learning algorithm can access the historical data on the behavior and global state of all agents.Thus, the joint policies of all agents can be evaluated in a centralized way, thus solving the problem of a non-stationary environment and making learning more stable.In the process of decentralized execution,each agent uses both his own observation message and communication messages from the other agents to select an action in a decentralized way.
As shown in Fig.5(a),a mixing network similar to the QMIX[27]is used to aggregate the individual utility value functionof each agent and generate a joint action-value function.The parameters of the mixing network are obtained by multiple independent HyperNetworks [39] with the global statestas an input,having the structure shown in Fig.5(b).In Fig.5(b),the HyperNetwork ofW1,W2,andb1is composed of an FC layer.However, an absolute activation function is used forW1andW2to ensure that the weights are non-negative values.The parameterb2is generated by a two-layer HyperNetwork with the ReLU nonlinear activation function;Qiis used to representQi; ELU activation function is used to process the combination vector passing throughW1andb1to solve the problem of gradient disappearance.
4.3.Loss function definition
During the calculation of the final outputof thereceived messageprocessor,the communication message is a buffer messagemjfrom thereceivedmessagebuffer, rather than the latest communication messagegenerated by thesentmessageencoderof an agentj(j∈-i).Although the Euclidean distance betweenmjandis small, it can cause wrong selection of the final action.Therefore, a regularizer is introduced in the proposed method to minimize the difference between the fusion message generated from a real communication messageof an agent and the final outputof thereceivedmessageprocessorso that the final action selection result is not affected by the message buffer.
where θ represents the parameter set of all agents’neural networks and mixing network.
The network parameters are updated by minimizing the loss function.The loss function in the training stage is defined by
whereBis the batch size sampled from the experience replay buffer.The behavior network of an agent and ε -greedypolicy are used to select an appropriate action,and data samples are stored in the experience replay buffer., where θ-denotes thetargetnetworkparameter, which is replicated at a fixed timesteps from θ; λcis regularizer’s coefficient.
5.Experimental results
5.1.SMAC evaluation environment
The SMAC [19] is a multi-agent algorithm evaluation environment based on the real-time strategy game StarCraft II.Compared to the SC2LE environment[40],the SMAC focuses more on the finegrained decentralized micromanagement challenges.
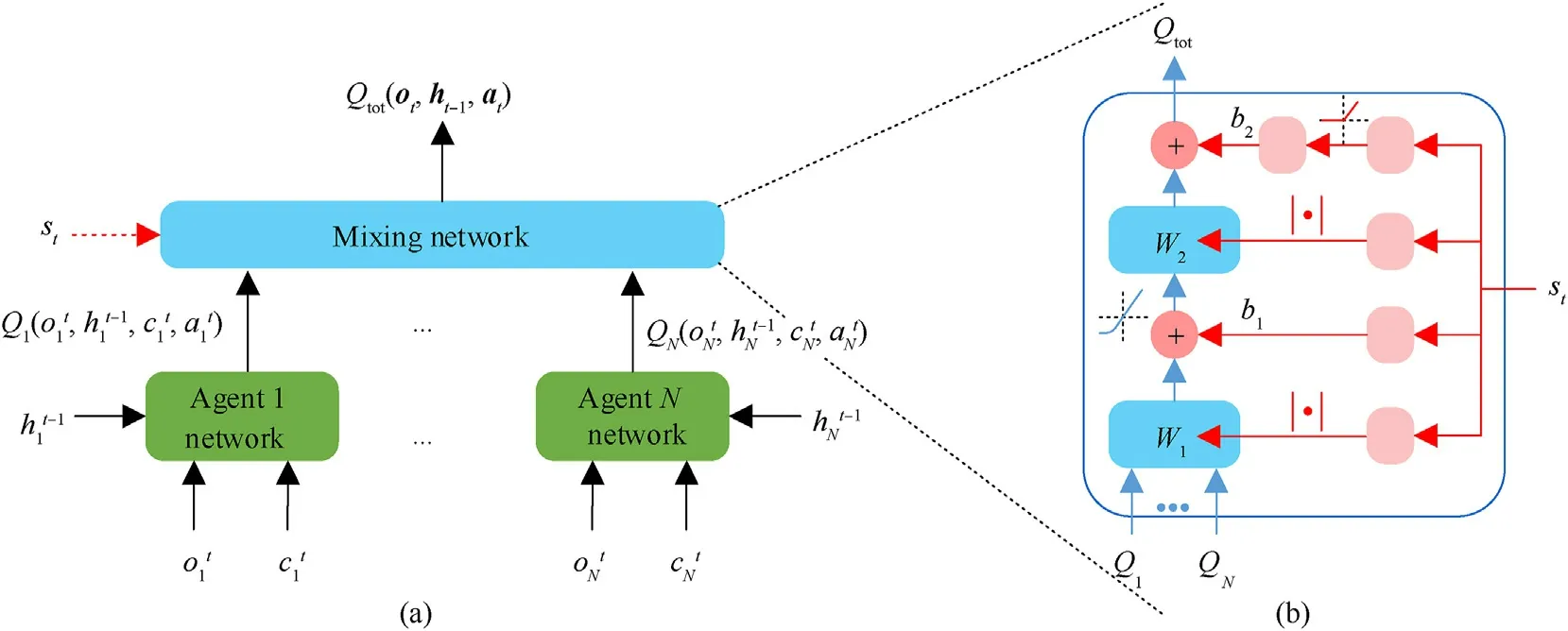
Fig.5.(a) Centralized training framework; (b) The Mixing network structure; the red part denotes the HyperNetwork.
Each scenario in the SMAC environment represents a confrontation between two armies of allied forces controlled by an RL agent and enemy forces controlled by a built-in heuristic AI, where each RL agent controls only a combat unit (see Fig.6).From the RL perspective, the SMAC environment aims to evaluate the ability of independent agents to solve complex tasks by learning cooperative behaviors.First,SAMC is a multi-agent cooperation problem,and its main objective is to control ally units, kill all enemy units, and minimize the total damage suffered by the ally units.Second, the environment is random and partially observable, and the initial position of the combat unit varies in each round.Moreover, each agent can make observations only locally within a limited field of vision centered on the combat unit, which restricts the observations of the allied or enemy units outside the agent’s field of vision.Third,the decision-making space is enormous,and the joint action space varies exponentially with the number of ally units in the environment.
In the experiment, at each timestep, agents received the map information within their field of vision and used a feature vector as input data.The feature vector contained many attributes,including relative distances,relative coordinates(x,y),health points,shields,and unit types of all combat units within the field of vision of the agents.Shields represented additional protection that could be used to block damage and could automatically recover when there was no more damage.An agent could observe the surviving agent allies only within their field of vision and thus could not identify the agent allies outside this field of vision or allies who had died.Therefore, the feature vector of the agent allies that had not been observed was set to zero.Additionally,agents could access the last timestep actions of the other agent allies within their field of vision.The global state vector was used only for centralized training,and it consisted of features of all units on the map.In addition,this vector included coordinates of all agents relative to the map center,observed features of the units, and the last timestep actions of all agent allies.Both the local observation state and the global state were normalized by their maximum values.
The agents’ action space consisted of a set of discrete actions,including the movement direction (east, west, south, or north),attacker ID(enemy_id),stop,and no-op.The dead agents could take only no-op.The surviving agents could move in one of the four directions,namely,east,west,south,or north,with a fixed amount of movement or attack the enemy within the attack range.Automatic firing and response to the enemy fire were prohibited.Medivacs,as medical units,took treatment action[agent_id]rather than attack action [enemy_id].
At each timestep, agents received a joint reward equal to the total damage made to the enemy units.In addition, agents were awarded additional 10 or 200 points for destroying an enemy unit or wining the entire battle,respectively.The rewards were adjusted by proportions to make the maximum cumulative reward be approximately 20 in each scenario.
In this study,the difficulty of enemy AI was set to seven(Super Hard),and the default amount of movement,the field of vision,and the firing distance were set to two, nine, and six, respectively.The SMAC consists of a series of StarCraft II micro battle scenarios that can be divided intoEasy,HardandSuperHardlevels.The simplest VDN [26] can effectively solve the Easy scenarios.Therefore, this study mainly considered asymmetric hard and super hard battle scenarios, such as 8 m_vs_9 m, 3s_vs_5z, Corridor, 6 h_vs_8z,3s5z_vs_3s6z, MMM2, and two communication battle scenarios,such as 1o10 b_vs_1r and 1o2r_vs_4r.Asymmetric battle scenarios were used in the experiments because they are more challenging than symmetric battle scenarios.In addition, in asymmetric battle scenarios, the number of enemy units exceeds the number of agents,and different combat unit types are used.Therefore,in these types of scenarios, in the process of battle, agents must pay great attention to their health points and positions and those of enemy units to protect themselves effectively and kill the enemies.In the communication battle scenarios, the agent must learn how to transmit information and coordinate actions by learning the communication protocol, so as to test the performance of the algorithm in complex scenarios.Table 1.

Fig.6.The screenshots of the training scenes in the SMAC environment.
5.2.Model and hyperparameters setting
The SCTC, SCTC(-h +k), SCTC(-h), and SCTC(-h-s) algorithms were established based on the PyMARL framework [19].The SOTA baseline algorithms, such as TMC [15] and VBC [13], used codes provided by the author with a slight adjustment of hyper parameters.Two NVIDIA GTX 2080 Ti GPUs were used for training.According to the number of agents and the limitations of episodes in scenarios, the training duration of each scenario was roughly 10-28 h.
All agents have the same network structure as agentipresented in Fig.1.To prevent the generation of lazy agents and reduce model complexity, all agents have the same parameters of thelocal observationprocessor,localactiongenerator, andreceivedmessage processor.In thelocalobservationprocessor, the dimension of the hidden layer of the GRU network is 64.The outputs of thelocal actiongeneratorandreceivedmessageprocessorare 32-dimensional.The temperature coefficient ρ of the Gumbel-softmax in the hardattention mechanism is set to 0.01.In centralized training, the HyperNetwork in the mixing network has 32 dimensions.
In the training stage,the ε-greedypolicy is used for exploration.The exploration rate ε is decreased linearly from 1.0 to 0.05 in the first 0.5 M timesteps, and remains unchanged in the subsequent learning process.The reward discount factor is set to γ = 0.99.The data of the latest 5000 episodes are stored in the replay bufferD.The model is saved every 200 episodes training is completed, and thetargetnetworkand replay bufferDare updated.The RMSprop optimizer is used to update the network parameters of the model.The learning rate is set to η =5 ×10 -4;the attenuation factor is set to α = 0.99; the training batch size is set to 32; the test batch size is set to eight.
Firstly, we determined the rough hyperparameter range about sent message change threshold δM, the message sending timing period δTand the received message updatingtimerδRby random test, experience and information statistics.Then, we conducted a comparative experiment in the small hyperparametric space.In order to illustrate the influence of the above hyperparameters on the performance of the SCTC, we used the average value of the median win rate over 32 test games after the last 10 training iterations of 5 training seeds in the training period to evaluate the final performance of the SCTC algorithm.The specific results were shown in Fig.7.Among them,in order to ensure the effectiveness of communication message in thereceivedmessagebuffer, the received message updatingtimerδRwas set to be the same as the message sending timing period δT.In subsequent comparative experiments, the SCTC algorithm used the optimal combination of hyperparameters in Fig.7.
5.3.Verification results analysis
5.3.1.Testwinrateanalysis
The performance of the SCTC was evaluated by the test win rate,which represented the percentage of times that the agents defeated all enemy units within a limited time.Every training included 200 episodes, the training was suspended, and 32 episodes were independently run to test the proposed method.In the test, each agent performed a decentralized greedy policy to select actions.Each experiment included five random seeds.The results are shown in Table 2 and the 95% confidence interval are displayed in Fig.8.
The experimental results showed that the algorithms with communication mechanisms (SCTC, VBC, TMC, and NDQ) in the eight scenarios including 1o_2r_vs_4r和1o_10 b_vs_1r had a significantly higher win rate than the algorithms without communication mechanisms (QMIX, Qatten, and COMA).This indicates that the communication between agents is extremely important in the process of behavior executions.The COMA did not learn a good policy due to the algorithm structure and joint actionobservation space.The QMIX and Qatten used the additional global state message to learn policies but had poor overall performances.The VBC, TMC, and NDQ improved the performance by using communication messages reasonably.The SCTC method achieved an optimal final performance in 7 scenarios except 1o_2r_vs_4r,and obtained the convergence value very close to NDQ algorithm in 1o_2r_vs_4r scenario.However, the SCTC method were more stable.At the same time, it was worth noting that in the 1o_2r_vs_4r and 1o_10 b_vs_1r scenarios, each algorithm quickly reached its own convergence level,and in the 1o_2r_vs_4r scenario,the initial state of the policy had a win rate of about 10%.This is mainly because in these two scenarios,the combat capability of the Allied combat unit is greater than that of the enemy combat unit,so even in the early stage of training, it can still achieve some victory through exploration.There were several reasons for this result.First, in the SCTC method, the gating mechanism and additional regularizers were used to remove the timing redundancy and noise information in communication messages, thereby significantly improving the convergence speed.Second, compared to the VBC,TMC and NDQ communication algorithms, the SCTC used a twolayer attention mechanism to select and weigh the communication messages,thus making agents focused on messages that were important for them while ignoring the unimportant ones.In Section 5.4, a separate ablation experiment, which was designed to analyze the mechanism,is presented.In addition,Fig.9 separately shows the test results of the SCTC method in several easy scenarios,in which the sent message change threshold δMwas set to 0.08,the message sending timing period δTand the received messageupdatingtimerδRwere set to 6.The results showed that SCTC converged within 2 M timesteps in easy scenarios, so SCTC had strong robustness to both easy and complex scenarios.
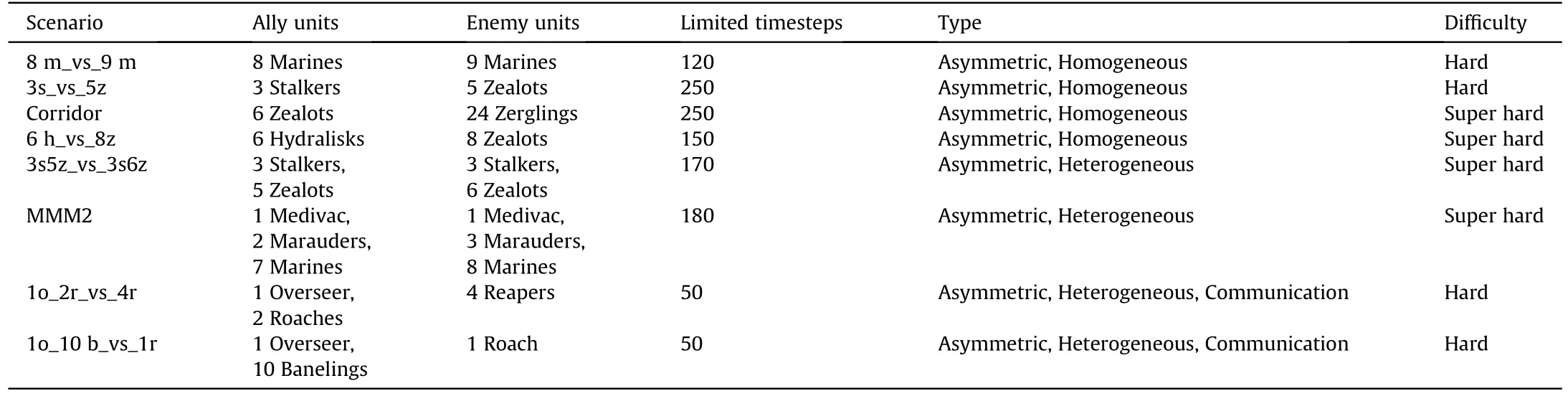
Table 1SMAC challenges.
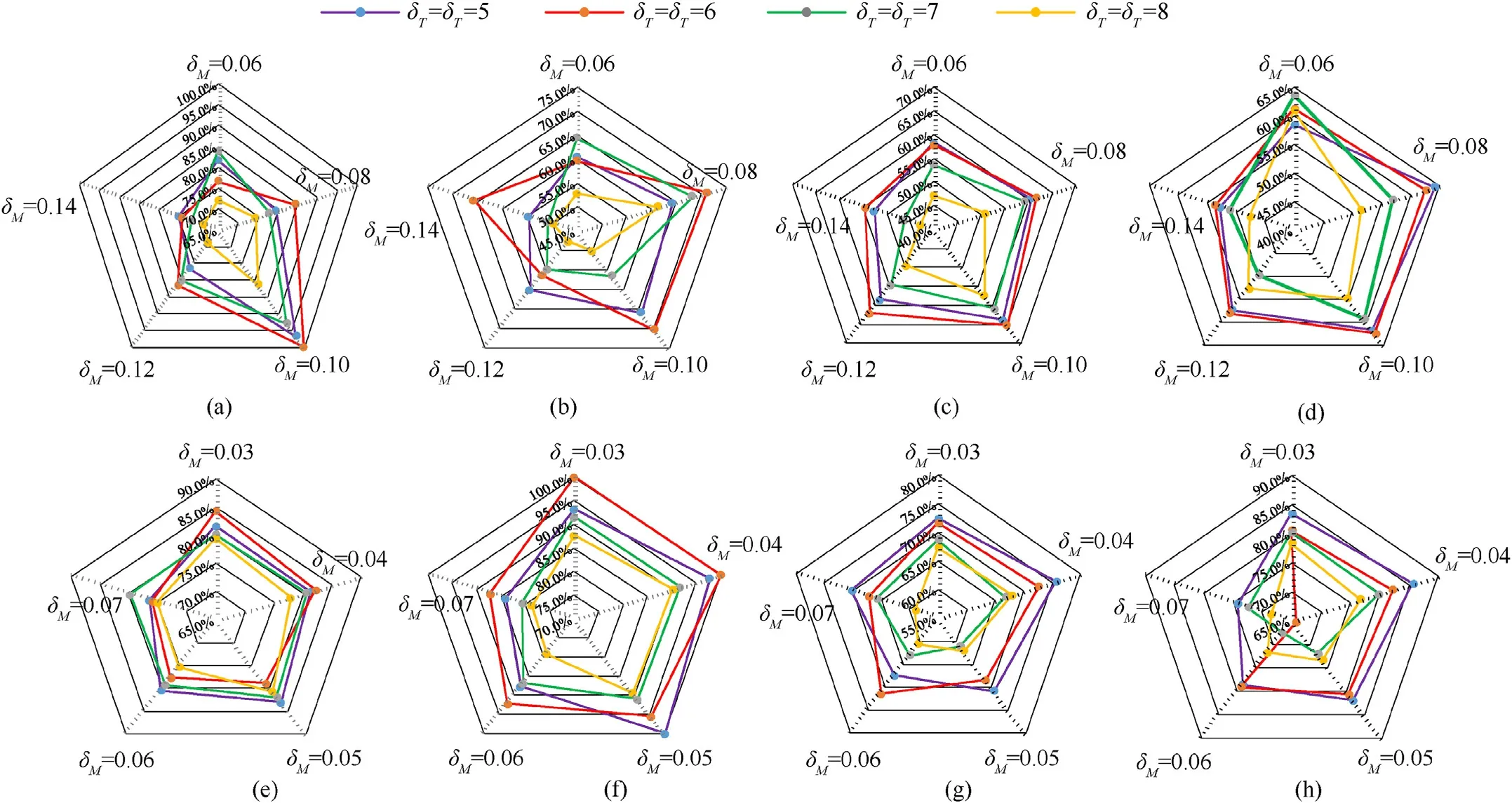
Fig.7.Comparison of final performance of SCTC method with different hyperparameter combinations in different scenarios(The optimal parameter value was indicated in red font in the figure): (a) 8 m_vs_9 m; (b) 3s5z_vs_3s6z; (c) 6 h_vs_8z; (d) Corridor; (e) MMM2; (f) 6 h_vs_8z; (g) 1o_2r_vs_4r; (h) 1o_10 b_vs_1r.

Table 2Median evaluation win rate and standard deviation after the last 10 training iterations on the SMAC scenarios for different methods.
5.3.2.Communicationoverheadanalysis
In the SCTC method, thesentgateandreceivedmessagebufferwere used to reduce the communication overhead, instead of reducing the communication overhead by decreasing the communication message vector dimension or using the adaptive communication message [14].Moreover, in this way, the communication gained certain robustness improvement.The similar methods in VBC algorithm was used to quantify the communication overhead [13].The communication overhead φ was defined as the average number of agent pairs in communication in one timestep,namely
whereptdenotes the number of agent pairs participating in communication at timestept,t∈T, andZrepresents the total number of agent pairs in the system.
It should be noted that the NDQ[14]method uses the approach of truncating useless information in communication messages and simplifying the communication vector to reduce the impact of limited communication bandwidth, which requires agents to communicate fully in each timestep.In addition,in the QMIX[27],Qatten[28],and COMA methods[12],agents only rely on their own observations to make decisions during the execution process, and there is no communication between agents.Therefore, in the communication overhead experiments, the SCTC method was compared only with the VBC and TMC methods.The communication overhead results are shown in Fig.10 and Table 3.
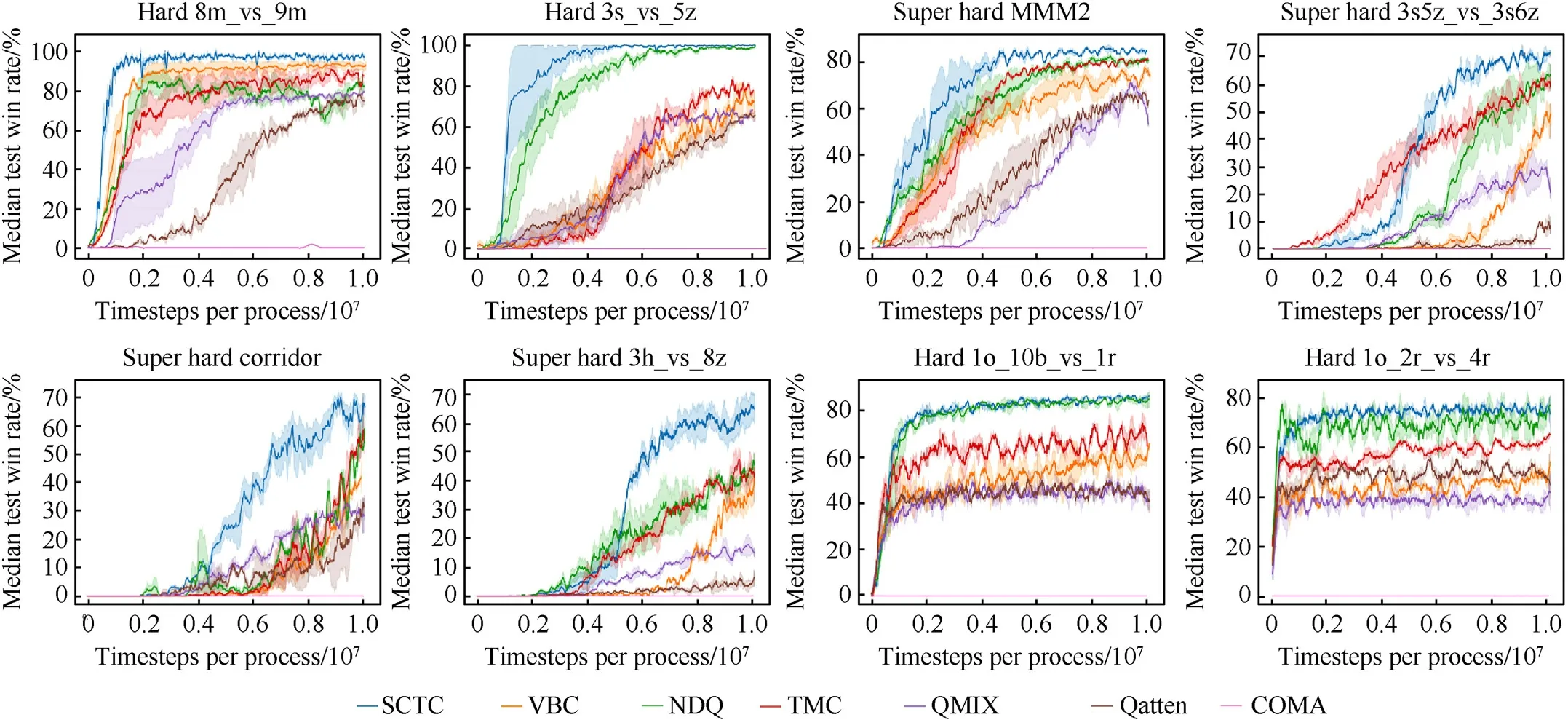
Fig.8.The test win rate results of different methods in the eight scenarios.

Fig.9.The test win rate results of the SCTC method in easy scenarios.
As shown in Fig.10 and Table 3,in most scenarios,the proposed SCTC method could effectively reduce the communication overhead compared to the VBC and TMC methods.For instance, in scenario 3s_vs_5z, Stalkers needed to defeat Zealots by using the strategy of “Kiting.” Thus, intensive communication between Stalkers was necessary to determine attack positions and targets.The results indicated that the SCTC could reduce the communication overhead φ from 38.3 to 23.1%by using the gating mechanism based on state control.However,in scenario Corridor,faced with a large number of Zerglings, Zealots adopts the strategy of grouping to lure the enemy and long-range annihilation.Therefore, the strategy does not rely very much on communication.The VBC method controls the communication based on the variance of agent's own communication message, so the communication overhead in this scenario is small.Considering the situation that the sent message is not updated for a long time,SCTC uses a timer δTto allow the agent to broadcast communication message, so it increases some communication overhead in this scenario.In 1o_10 b_vs_1r and 1o_2r_vs_4r communication scenarios, since only the Overseer knew the position of the enemy at the beginning of each episode,the change of communication message of SCTC and TMC algorithm was small, which did not cause too high communication overhead, while the confidence of VBC algorithm in making decisions based on local observation was low, so the communication overhead reached 63.3% and 56.6%.According to the average communication overhead results in eight scenarios,the SCTC decreased the average communication overhead by 8.0%and 2.1% compared to the VBC and TMC methods, respectively.Therefore, the SCTC could effectively eliminate redundant communication messages associated with timing and reduce the communication overhead by using the gating mechanism based on state control.
5.4.Ablation experiment results analysis

Table 3Specific communication overhead of different methods.
This paper proposes a combination method based on the series connection of the hard- and self-attention mechanisms to weigh the communication messages between agents.To verify the impact of this method on the SCTC performance, an additional ablation experiment was conducted.Based on the SCTC, by adding or deleting related mechanisms, three ablation versions of the SCTC were developed, namely, SCTC(-h +k), SCTC(-h), and SCTC(-h-s).Compared to the SCTC method, in the SCTC(-h), the hardattention mechanism was removed, and only the self-attention mechanism was used to weigh the communication messages of agents.In the SCTC(-h +k), the number of agent communication messages was limited to the basis of the SCTC(-h), and only communication messages of top-kagents according to the selfattention weight values were used; communication message weights of the topkagents were normalized.The SCTC(-h-s)used a simple linear sum method to combine the local action-value functionwith a communication messagemj≠iof each agent.Three scenarios with lower test win rates in Section 5.3.1 were selected for the ablation experiment.The experimental results are shown in Fig.11.In the SCTC(-h+k),kwas about half of the number of agentsN.The hyperparameters in SCTC(-h +k),SCTC(-h) and SCTC(-h-s) are consistent with SCTC.
The experimental results demonstrated that it was very important to select and weigh the communication messages.The SCTC(-h-s), which used a linear sum method to combine communication messages of the agents,could not distinguish the relevance and importance of the communication messages, showing poor performance.The SCTC(-h), which used the self-attention mechanism to weigh the messages of agents, assigned a small weight to the irrelevant agents’ messages, which affected the final performance.However,it should be noted that the convergence speed of this method was fast in the early training period.The SCTC(-h+k)allowed only a fixed number of agents to interact jointly at each timestep, so the interaction of important messages was limited.Therefore,its results were second-best,following those of the SCTC.The SCTC ignored messages of irrelevant agents by using the hardattention mechanism and learned the importance distribution of agent messages in fewer environments.Thus, the case that the importance distributions of all agents’ communication messages were learned directly in a large MAS could be effectively avoided.Moreover, the number of messages interactions between agents could be dynamically adjusted to make the final value more accurate and improve the overall performance.
6.Conclusions
This paper proposes a targeted multi-agent communication algorithm based on state control named the SCTC.The SCTC is based on the CTDE paradigm and uses a gating mechanism based on state control to reduce the communication overhead between agents,thus improving communication robustness.Meanwhile, a doubleattention mechanism with a series connection of the hard- and self-attention mechanisms is used to realize the targeted message processing between agents.The proposed method is verified by experiments on the SMAC benchmark.The experimental results demonstrate that the proposed SCTC method can reduce the communication overhead between agents while improving the learning performance.In the future, the SCTC method could be combined with other value-decomposition methods to obtain a more accurate expression of the joint action-value function.
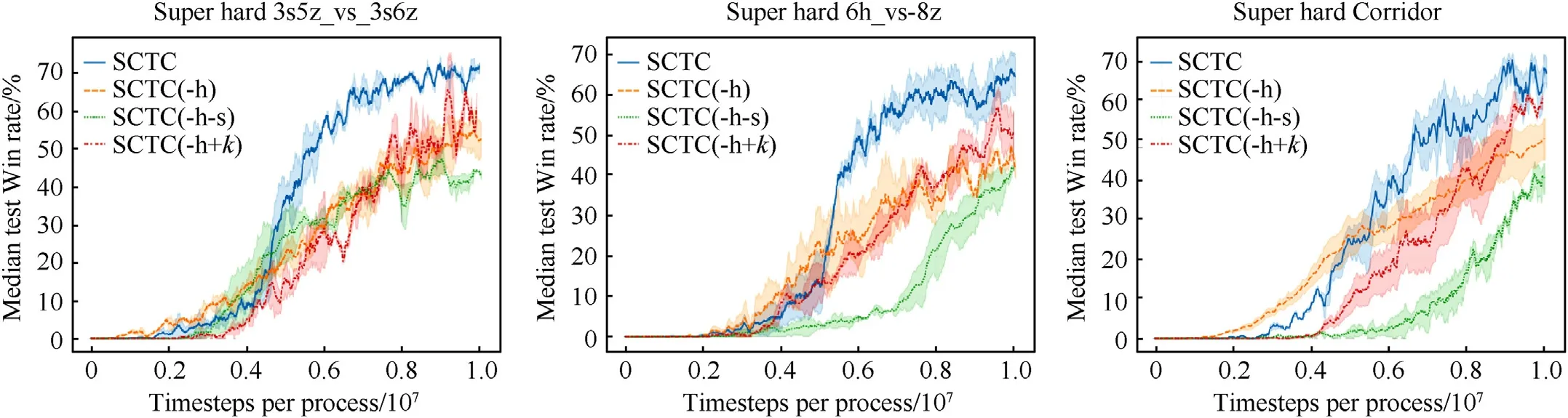
Fig.11.Ablation experiment results of different methods in three super hard scenarios.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.

- Defence Technology的其它文章
- The interaction between a shaped charge jet and a single moving plate
- Machine learning for predicting the outcome of terminal ballistics events
- Fabrication and characterization of multi-scale coated boron powders with improved combustion performance: A brief review
- Experimental research on the launching system of auxiliary charge with filter cartridge structure
- Dependence of impact regime boundaries on the initial temperatures of projectiles and targets
- Experimental and numerical study of hypervelocity impact damage on composite overwrapped pressure vessels