
Self-supervised recalibration network for person re-identification
2024-02-29 08:22ShaoqiHouZhimingWangZhihuaDongYeLiZhiguoWangGuangqiangYinXinzhongWang
Defence Technology 2024年1期
Shaoqi Hou , Zhiming Wang , Zhihua Dong , Ye Li , Zhiguo Wang ,*,Guangqiang Yin ,**, Xinzhong Wang
a Shenzhen Institute of Information Technology, Shenzhen, 518172, China
b University of Electronic Science and Technology of China, Chengdu, 611731, China
c Kash Institute of Electronics and Information Industry, Kashi, 844099, China
Keywords: Person re-identification Attention mechanism Global information Local information Adaptive weighted fusion
ABSTRACT The attention mechanism can extract salient features in images,which has been proved to be effective in improving the performance of person re-identification (Re-ID).However, most of the existing attention modules have the following two shortcomings:On the one hand,they mostly use global average pooling to generate context descriptors, without highlighting the guiding role of salient information on descriptor generation, resulting in insufficient ability of the final generated attention mask representation; On the other hand, the design of most attention modules is complicated, which greatly increases the computational cost of the model.To solve these problems, this paper proposes an attention module called self-supervised recalibration (SR) block, which introduces both global and local information through adaptive weighted fusion to generate a more refined attention mask.In particular, a special"Squeeze-Excitation" (SE) unit is designed in the SR block to further process the generated intermediate masks, both for nonlinearizations of the features and for constraint of the resulting computation by controlling the number of channels.Furthermore, we combine the most commonly used ResNet-50 to construct the instantiation model of the SR block,and verify its effectiveness on multiple Re-ID datasets,especially the mean Average Precision(mAP)on the Occluded-Duke dataset exceeds the state-of-the-art(SOTA) algorithm by 4.49%.
1.Introduction
Target recognition is an indispensable key technology for the construction of smart city and national defense.As we all know,pedestrians are the main bodies of various activities,so the accurate identification of pedestrians has always been a hot direction in the field of target recognition.The term concept of "Person Reidentification (Re-ID)" was coined in 2005 to address the problem of matching pedestrians across different scenes.In simple terms,it is to match pedestrians appearing in a certain camera with the same pedestrians appearing in other cameras.The emergence of Re-ID technology makes up for the defect that pedestrian identity is difficult to determine due to the lack of face information in surveillance scenarios, which has important application value in the fields of target precision attack,evidence collection of the forensic department, the operation of unmanned supermarket and intelligent security.However,due to the different parameters of different cameras and the variable monitoring environment, pedestrian images are vulnerable to factors such as illumination, viewing angle,blur,and occlusion,which makes the customization of Re-ID technology face great challenges at the beginning.
With the rapid development of deep learning, since 2016,scholars have begun to apply this technology to the large-scale dataset of Re-ID and have made great progress [1].It is well known that network engineering has been one of the most important deep learning techniques, as well-designed networks ensure significant performance gains in various applications including Re-ID.From AlexNet [2] to residual-type architecture[3,4],neural networks have become deeper and deeper,which can provide rich representation.Following a similar line of thought,GoogLeNet [5] showed that width is another important factor in improving model performance.Zagoruyko et al.[6] proposed a wide residual network based on the ResNet architecture and proved in the CIFAR benchmark that a 28-layer ResNet with increased width can outperform an extremely deep ResNet with 1001 layers.
In addition to the above means, some studies have shown that by integrating the learning mechanism into the network, it is helpful to capture the correlation between features, and the representation generated by convolutional neural networks can be strengthened.Based on this, many scholars propose that network design can learn from human visual function, that is, learning to choose "key things" for attention, and selectively ignore those things that are not interested in Ref.[7].Inspired by this,scholars at home and abroad began to introduce "attention mechanism" into network training, and it has highlighted its effectiveness in many tasks, including sequence learning [8,9], image localization and understanding [10,11], image captioning [12,13] and lip reading[14].A central theme of deep model research is to find more powerful feature representation,and the attention mechanism can capture the attributes and features that are more discriminative for a given task in the image through weight allocation, and achieve the purpose of suppressing the interference information.For example, if the gender of pedestrians is classified, the focus of model learning should be the target "whether there is long hair","whether there is a skirt" and so on.
The commonly used attention mechanisms can be divided into two categories: spatial attention and channel attention.Spatial attention aims to focus on two-dimensional space and extract salient features of pedestrians and other targets by finding the relevance of image context.Channel is dedicated to building the dependence relationship between channel features and improving the information weight of key channel features.The originator of channel attention is SENet[15]proposed by Momenta company in 2017, which learns to use global information to selectively emphasize the importance of channel information and suppress less useful features.Based on SENet, Woo et al.[16] proposed an attention module CBAM based on convolution block, which not only adds spatial attention mechanism, but also introduces max pooling as a supplement to SENet’s use of average pooling to generate attention masks.Since then, on the basis of SENet and CBAM,a large number of classical researches on channel attention and spatial attention have appeared in the field of computer vision[17-19], and led to the application of attention mechanism in the field of Re-ID[20-22].However,the existing channel attention and spatial attention modules basically have the following shortcomings:
(1) Most attention modules choose global average pooling to generate weight descriptors for each feature map’s channel or spatial location.Although the integrity of global information is preserved,it does not highlight the guiding role of saliency information on descriptors.
(2) Even though the fusion of max pooling and average pooling is adopted, the fusion method is very violent, either direct Add or Cat, which does not give full play to the supervision role of network learning on the generation of attention masks,ignoring the difference in the importance of different descriptor information to different tasks.
(3) The design of most attention modules is too complex,which greatly increases the computational cost of the model.
In view of the above problems, our experiments find that explicitly modeling the interdependence between channel features of feature map can significantly improve the expression ability of network,and this effect is more obvious than that of spatial feature.On this basis,we start from the channel relationship and adopts the method of "local and global information fusion" to design a selfsupervised recalibration (SR) block (see Fig.1), which can supervise the generation of the optimal attention mask through its own training process and thus self-adaptively recalibrate the feature response of the channel direction of the feature map through the generated mask.In the recalibrated feature information, the proportion of the invariant feature under the pedestrian cross-scene in the whole recognition information is enhanced,thus improving the representation quality of the network generation.
On the one hand, the attention mask of the SR block also incorporates local information descriptors in addition to the global information descriptors.In particular, different from the conventional approach of direct fusion, SR block allows the network to adaptively weight two different descriptors through training, so that the model can be task-oriented to achieve the purpose of enhanced learning.On the other hand,a small"Squeeze-Excitation"(SE) unit is designed in the SR block, which can transfer features through the "Squeeze-Excitation" operation.It can not only perform nonlinear processing on features, but also control the number of channels in the feature map, thus significantly constraining the computational cost of the model.
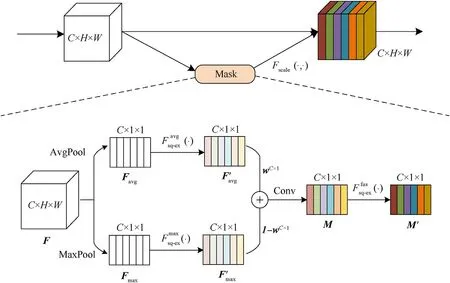
Fig.1.Overall structure of SR block.
In summary,the main contributions of our paper are as follows:
(1) Propose a simple and effective channel attention module named SR block, which can effectively improve the expressive ability of CNN;
(2) The effectiveness of the SR block is verified through a large number of ablation experiments;
(3) By inserting the SR block of this paper into ResNet-50,we get the instantiated model SR-ResNet-50, and verify that it has achieved significant performance improvements on multiple Re-ID datasets.
The rest of the paper is organized as follows: Section 2 introduces some related work;Section 3 describes the proposed selfsupervised recalibration network (SRNet), which involves the design details of the SR block;Section 4 illustrates the datasets and evaluation indicators adopted in this paper, and presents various experimental designs and analysis of results;Finally,Section 5 gives the conclusion of this paper.
2.Related work
In recent years, many new methods combining depth framework and attention mechanism have emerged in Re-ID task, and they have achieved excellent performance on the Re-ID dataset.For example,Jiang et al.[23]proposed a cross-modal multi-granularity attention network (CMGN) in 2020, which can learn the common features of different modes and map them to the same feature space, thus solving the problem of cross-modal pedestrian matching under infrared and visible light.In the same year, Zhu et al.[24] proposed a curriculum enhanced supervised attention network (CE-SAN) to solve the problem of pedestrian misalignment.The CE-SAN aims to train the attention module under supervision, it links local and global branches together to better emphasize key information and exploit discriminative features.In 2021, Ning et al.[25] proposed a joint weak saliency mechanism and attention-aware model (JWSAA) for the background bias caused by significance detection bias, which makes the model gradually focus on all valuable regions of pedestrian features by weakening the high-response features.Then, Zhang et al.[26]proposed a hybrid-attention guided network with multiple resolution features to ensure the spatial alignment of feature maps at different stages during feature fusion.In addition,Sun et al.(2021)[27]cascaded spatial-level attention block(SAB)and channel-level attention block(CAB)to form a multi-level-attention block(MAB),which is used to extract the robust features of pedestrians across scenes.In the latest work in 2022, Tan et al.[28] proposed a multihead self-attention network (MHSA-Net).MHSA-Net can adaptively obtain key local information from pedestrian images and eliminate unimportant noise information, significantly improving the performance of Re-ID under occlusion conditions.In addition,in order to take into account model performance and computational complexity, Chen et al.[29] proposed an attention aware feature learning framework, which can carry out supervised training without changing the structure of the Re-ID model.
3.Self-supervised recalibration network
This section contains four parts:First,subsection 3.1 introduces the overall architecture and design ideas of SR block; Then, in subsections 3.2 and 3.3, two key design schemes in SR block are elaborated respectively; Finally, subsection 3.4 details the instantiation model for SR block.
3.1.Self-supervised recalibration block
As shown in Fig.1,the SR block is a computing unit.The specific process of feature map recalibration is as follows:
Step 1.Given an intermediate feature mapF∈RC×H×Was input.In order to take into account the integrity and specificity of the feature map information of each channel,the SR block uses average pooling and max pooling,respectively,to aggregate the spatial information of the input feature map,and generate two different spatial context descriptorsFavgtheFmax.
whereu(i,j) represents the pixel value at the feature map coordinate(i,j).
Step 2."Squeeze-Excitation" operation is carried out for the two feature maps respectively (see Section 3.2 for details) to further process the features and improve the nonlinearities of the model while controlling the computational load.
In the equation,twoFsq-ex(·)have the same operation process but do not share parameters.
Step 3.The two intermediate masksandare multiplied by weight factorswC×1and (1C×1-wC×1) for adaptive weighted fusion (see subsection 3.3 for details), and the fused mask passes through a composite convolutional layer (see Fig.2) further processes the feature details to obtain the hybrid maskM.
In the equation,·is the multiplication by channel;⊕represents the channel-concat operation;-represents the subtraction by channel.In the actual training process, the weight factors are broadcast(replicated) in the spatial dimension, so that the program can perform element-by-element operations.
Step 4.The hybrid maskMuses the same form of "Squeeze-Excitation"operation as the second step to perform fine processing of features to obtain the final maskM'.

Fig.2.Structure of composite convolutional layer in SR block.
Step 5.The channel attention maskM' is multiplied channel-bychannel with the input feature map to generate the recalibrated feature map.
where ⊗represents element-wise multiplication.Similarly, in the actual training process, the attention maskM' will first be broadcast (replicated) correspondingly along the space dimension(H×W) of feature map, changing from dimensionRC×1×1toRC×H×W.
The above is the whole process of the input feature map by the SR block.It can be seen that the SR block processes the features in a more detailed manner.In particular, the generation of the weighting factor and the final mask of the SR block completely depends on the adaptive learning of the network.During the training process,the model supervises the selection of parameters,so that the model can independently decide the weight allocation of the average pooling mask and the max pooling mask.To be clear,the design details in each processing step of the SR block in this paper are as follows.
(1) In Step 1, based on the generality of average pooling, this paper introduces max pooling as a supplement to global spatial information, which aims to use the important clues about unique object features collected by max pooling to infer more refined channel attention;
(2) The use of weight factorswC×1and (1C×1-wC×1) in Step 2 allows the model to have more autonomy in the selection of mask descriptors.On the basis of empirical evidence (see the ablation experiments in subsection 4.4), we find that letting each corresponding channel learn a mutual exclusion mechanism ofand1-(i=1,2,3,…,C)can make the generated hybrid masks more specific and representative;
(3) TheFsq-ex(·)operation in Steps 2 and 4 will further enhance the feature richness of the intermediate mask, and its"Squeeze-Excitation" operation can effectively control the amount of computation;
(4) The fusion method of the two weighted masks in Step 3 is channel-concat rather than element-add to avoid feature confusion caused by direct addition, and it’s also proved in this paper that channel-concat is a special form of elementadd, which can be converted to each other under certain conditions (see subsection 4.4 for the corresponding proof);
(5) In Step 3,the operation details of the composite convolution layer are shown in Fig.2.In addition to processing features,it also has the function of channel compression, which is responsible for halving the channels of fused mask.In particular,we place the batch normalization(BN)layer after the activation function ReLU, because the non-negative response of ReLU will cause the weight layer to be updated in a suboptimal way, which is also verified in the ablation experiments.
3.2."Squeeze-Excitation" operation
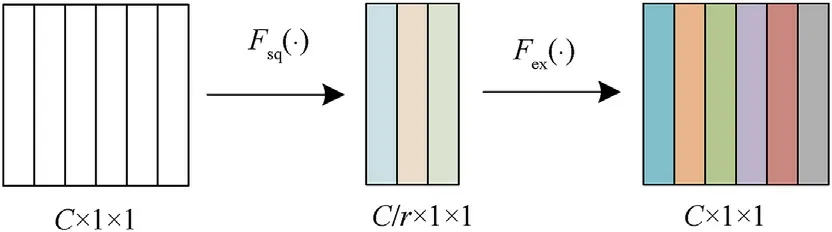
Fig.3.Schematic diagram of Fsq-ex(·).
"Squeeze-Excitation"operationFsq-ex(·)is a design used in this paper to trade off the accuracy and computational complexity of the model.As shown in Fig.3,it can control the channel dimension by adjusting the "scaling factor"r(rdefaults to 16, which will be discussed in the ablation experiment), thereby increasing or decreasing the capacity of the model.
Fsq-ex(·)consists of two series operations ofFsq(·)(squeezing)andFex(·) (exciting).Fsq(·) is responsible for compressing the number of channels of the attention descriptor to 1/rof the original.AfterFex(·),the channels is restored.That is,given the descriptorsFavgandFmax, the process of calculating the intermediate masksandis as follows:
Given a hybrid mask M,the process of calculating the final mask is
The meanings of each symbol in the equation are the same as those defined in subsection 3.1.
Through the "Squeeze-Excitation" operation, the channel dependencies of the attention mask are fully interacted, which also greatly reduces the computation of subsequent filters.It should be noted that although the same form of operation has been performed,the parameters of the threeFsq-ex(·)functions in Fig.1 are not shared, and the details are shown in Fig.4.

Fig.4.Detailed structure of Fsq-ex(·): (a) (·); (b) (·); (c)(·).
As can be seen from Fig.4 above,except for(·),the basic unit of each "Squeeze-Excitation" operation is the composite convolution layer as shown in Fig.2, and the Conv1d in each composite convolutional layer is a one-dimensional convolution of size 1 × 1 (essentially equivalent to the fully connected layer).Among them, the joint use of the filter Conv1d and the activation function ReLU enables the model to fully learn the nonlinear interaction between the channels of feature map,and the BN layer is responsible for constraining the data distribution while accelerating the convergence of the SR block.In(·), we use the sigmoid function to map the value of the attention mask to the(0,1)interval.
In short,the detailed calculation process of the three"Squeeze-Excitation" operations in the SR block is
whereRdenotes the activation function ReLU; σ denotes the Sigmoid function; * denotes matrix multiplication;Wsq∈RC/r×C,Wex∈RC/r×C; Other parameters are the same as those defined in Section 3.1.
3.3.Adaptive weighted fusion
In order to make each channel attention mask take into account both global semantic information and local semantic information,we specially adopt a weighted method to adaptively fuse two different intermediate masksand(see Fig.1).As shown in Fig.5,supposewherei= 1,2,…,C.Then the calculation equation of the fusion mask is
In the equation,pi,qi∈(0,1) andpi+qi= 1, the mutual exclusivity of the two allows the hybrid mask to autonomously learn the importance of global information and local information according to the Re-ID task,and then determine the weight vectors P andQ.
In the actual training process of the model, since the network can only learn real parameters, this paper cleverly introduces the softmax function to constrain the parameters learned by the network to the interval (0,1).Which is
At this point,the network learning of the weight vectorsPandQis transformed into the learning of two real vectorsXavgandXmaxrespectively.
3.4.Instantiated model
The SR block can be flexibly inserted into standard backbones such as VGGNet and ResNet,or serve as an efficient replacement for other plug-and-play modules.For a fair comparison, we integrate the SR block into the most widely used ResNet-50, and conduct experiments with this as the research object.ResNet-50 is the most classic backbone that gives consideration to both "depth" and"accuracy" of the network, it’s composed of multiple residual blocks stacked according to certain rules.As the basic unit of ResNet-50,the residual block contains two parts:"residual branch"and "identity mapping branch".The authors He et al.[3] believe that if the optimization objective function approximates an identity map, it will be easier to learn to find the disturbance (i.e., the residual)to the identity map than to relearn a new mapping function.Therefore, adding "identity mapping branch" can effectively alleviate the network degradation problem caused by the increase of depth.
As shown in Table 1, we insert the SR block after the nonlinear operation and before the summation of the "identity map branch"and call it the SR-ResNet (see Fig.6).Similarly, other variants that integrate SR blocks with InceptionNet[30],ResNeXt[4],MobileNet[31], and ShuffleNet [32] can be constructed by similar schemes above.For the concrete example of SRNet,Fig.7 shows the detailed description of ResNet-50 and SR-ResNet-50.It should be noted that the experiment in this paper will be carried out around the instantiation model SR-ResNet-50.
4.Experimental results and analysis
This section contains four parts: Subsection 4.1 introduces the datasets and evaluation indicators used in the experiments; Subsection 4.2 describes the loss function and some specific parameter settings;In subsection 4.3,we focus on testing the performance of the model before and after instantiation; Then, in subsection 4.4,several groups of ablation experiments were set up to verify the effectiveness of each design scheme of SR block; Subsection 4.5 shows the comparison between the proposed algorithm and the advanced algorithm, highlighting the superiority of the overall model; Finally, in subsection 4.6, some inference results are visualized to facilitate intuitive understanding of the effect of the model before and after improvement.
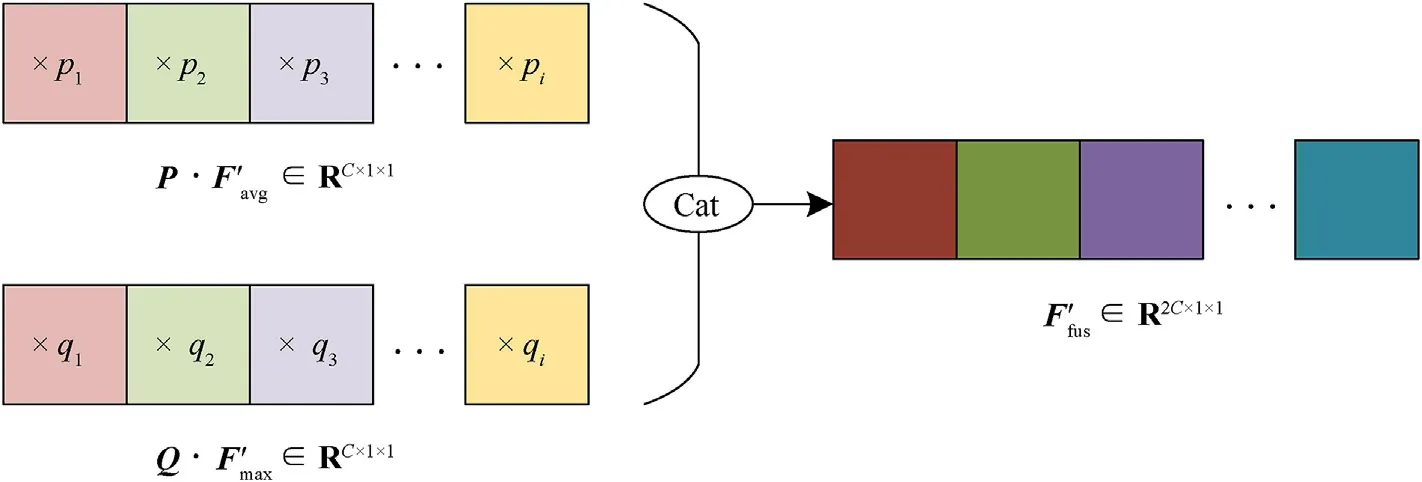
Fig.5.Schematic representation of adaptive weighted fusion in SR blocks.
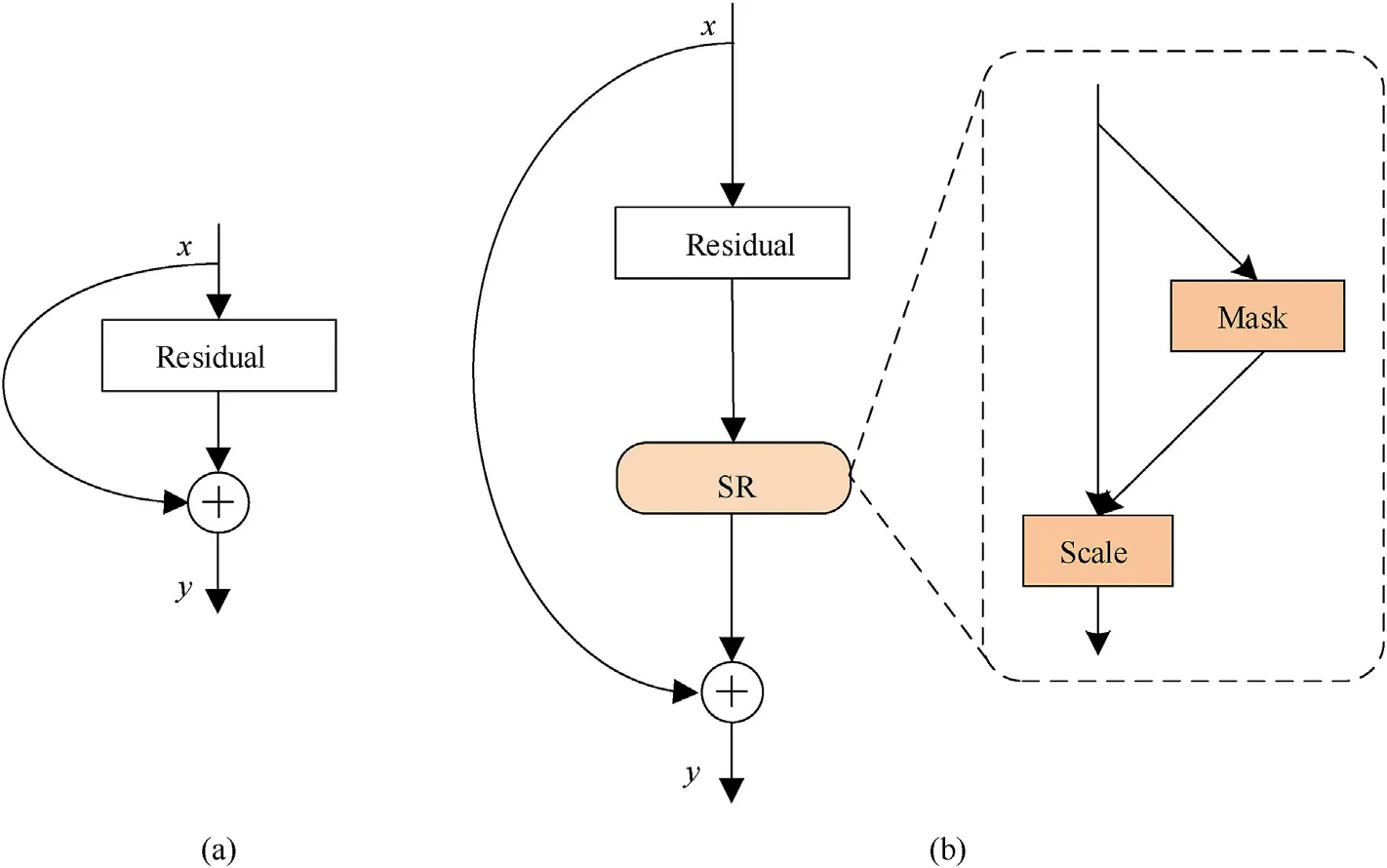
Fig.6.Integration scheme of SR block and ResBlock: (a) ResBlock; (b) SR-ResBlock.

Table 1Detailed configuration of ResNet-50 and SR-ResNet-50.

Fig.7.Image display of pedestrians in Market1501.
4.1.Datasets and evaluation indicators
4.1.1.Datasets
The datasets used in the experiments in this paper include two regular datasets Market1501[33]and DukeMTMC-reID[34],and an occlusion dataset Occluded-Duke [35].
Market1501 is an authoritative dataset collected on the campus of Tsinghua University in summer,constructed and made public in 2015, as shown in Fig.7 for a sample of pedestrian images.Market1501 contains a total of 1501 pedestrian IDs and 32,668 detection frames captured by 6 cameras (including 5 high-definition cameras and 1 low-definition camera).Each pedestrian is captured by at least 2 cameras and may have multiple images under one camera.Among them, the training set has 751 pedestrian IDs,including 12,936 images; the query set has 750 pedestrian IDs,including 3368 images;the gallery set has 19,732 images with 750 pedestrian IDs,and the IDs of the gallery set is the same as that of the query set.
DukeMTMC is a large-scale multi-target multi-camera pedestrian tracking dataset constructed in 2016.It provides a large HD video dataset recorded by 8 simultaneous cameras,with more than 7000 single-camera trajectories and more than 2700 individual pedestrians, as shown in Fig.8 for a sample pedestrian images.DukeMTMC-reID is a Re-ID subset of DukeMTMC and provides human-annotated bounding boxes containing 16,522 training images for 702 pedestrian IDs,2228 query images from an additional 702 pedestrian IDs, and a gallery containing 1110 pedestrian IDs and 17,661 images.
In order to fully demonstrate the superior performance and transferability of the proposed algorithm,we introduce the difficult dataset Occluded-Duke, which is the largest dataset for occluded Re-ID so far.Occluded-Duke is constructed from DukeMTMC-reID by leaving occluded images and filtering out some overlapping images, and all its query images and 10% of gallery images are occluded pedestrian images, as shown in Fig.9 for a sample of pedestrian images.Specifically, the training set of Occluded-Duke contains 15,618 images, covering 702 pedestrian IDs; The test set contains a total of 1110 pedestrian IDs,including 2210 query images and 17,661 gallery images.In particular,the directory structure and naming of the Occluded-Duke dataset is the same as DukeMTMCreID.
4.1.2.Evaluationindicators
The evaluation of all Re-ID algorithms in this paper includes two general evaluation indicators:the Cumulative Match Characteristic(CMC) of Rank-1 and the mean Average Precision(mAP).
Rank-1 represents the probability that the image ranked first in gallery search results is the target, also known as the first hit rate;Similarly, Rank-k represents the probability that the topkgallery images retrieved from each query image contain the correct target.In terms of practical tasks, the most meaningful metric is Rank-1.
mAP is a comprehensive evaluation, taking into account both Precision and Recall.Precision refers to the proportion of true examples among all retrieved samples that are considered to be correct targets; However, Recall refers to the proportion of retrieved as true examples among samples that are actually correct targets.The two are used as vertical and horizontal coordinates respectively to form aP-R curve, and the area under the curve is called Average Precision (AP), which is the integral sum of the precision at different recall points,as shown in Eq.(11).The larger the value of AP, the higher the average accuracy of the algorithm.
In general,the query image set contains multiple samples with different IDs to be retrieved.AP after arithmetic average based on the number of samples is called mAP, namely
wheremrepresents the total number of samples in the query set;iis theith sample to be retrieved in the query set.
In addition to the accuracy indicators Rank-1 and mAP,we also add the computational load indicator GFLOPs (Giga Floating-point Operations) for comprehensive evaluation of the model.
FLOPs represents the number of floating-point operations(that is,one GFLOPs is equal to 109floating-point operations),which is a key indicator for measuring the time complexity of the model,and it comes from the paper [36] in ICLR 2017.In the convolutional neural network, the computational load of the model is mainly concentrated in the convolutional layer and the fully connected layer.Specifically, the theoretical calculation of the FLOPs for the convolutional layer and the fully connected layer is shown in Eqs.(13) and (14), respectively.
In the equation,kwandkhrepresent the width and height of the convolution kernel respectively;kw×kh×Cinrepesents the amount of multiplication;kw×kh×Cin-1 repesents the amount of addition; +1 represents the offset;w×h×Coutrepresents the number of elements in the output feature map;wandhrepresent the width and height of the output feature map, respectively.

Fig.8.Image display of pedestrians in DukeMTMC-reID.

Fig.9.Image display of pedestrians in Occluded-Duke.
whereninrepresents the number of input features (that is, the number of neurons);at the same time,ninrepresents the amount of multiplication operations,nin-1 represents the amount of addition operations;+1 represents the bias;noutrepresents the number of output features.
4.2.Experimental settings
4.2.1.Lossfunction
In this paper, Triplet Loss [37] is selected as the metric loss function (also known as distance loss function) while the Softmax Loss is selected as the classification loss function during training.In the metric loss function, a target sample, a positive sample and a negative sample are given.Among them, the target sample has the same label as the positive sample and a different label from the other negative sample.The Triplet Loss is calculated by taking the three samples into the following equation:
wheredpis the distance between the target sample and the positive sample;dnis the distance between the target sample and the negative sample; α is the threshold of Triplet Loss.The goal of Triplet Loss is to pulldpcloser anddnfarther through training optimization, as shown in Fig.10.
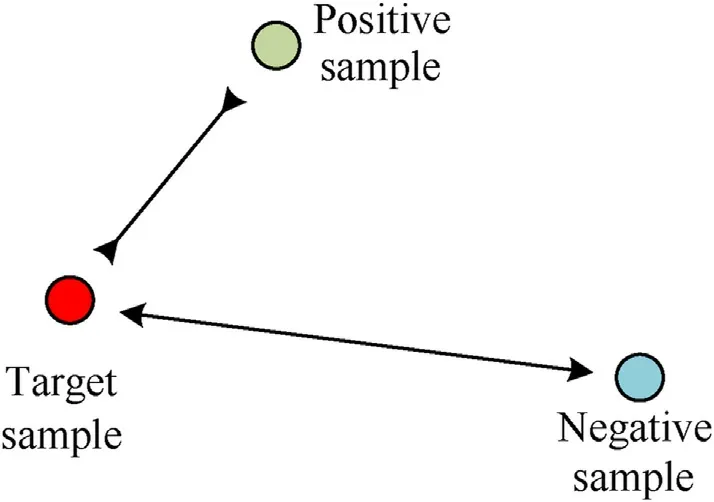
Fig.10.Schematic diagram of Triplet Loss.
Softmax Loss is a loss function combined with Softmax function and Cross-entropy Loss.The function of the Softmax function is to map the output values of multiple neurons calculated by the network to the interval (0,1), thereby giving the predicted probability that the target sample belongs to each category.The Crossentropy Loss is a way to measure the difference between the predicted value of the model and the actual value based on the Softmax function,and the two are widely used in various classification tasks.
Supposexrepresents the target sample andmrepresents the number of categories.Then the calculation formula of the Softmax function is
The equation for calculating Cross-entropy Loss is
In the equation,p(xj) andq(xj) represent the predicted probability and true probability that the target samplexbelongs to categoryj, respectively;Lcrossis the Softmax Loss value of the samplex.
If there arensamples in a batch, the calculation equation of Softmax Loss is
4.2.2.Parametersettings
In order to ensure the consistency of the experimental results,the experimental process in this paper is carried out in the same software and hardware environment.The computing platform is a linux system of version 5.4.0, using a single GTX 1080Ti graphics card(memory is 11G),Pytorch version is 1.6.0,CUDA version is 10.1,and Python version is 3.7.7; During the training process, the training set is uniformly scale to 256×128 size,and perform data enhancement operations such as horizontal flip(probability is 0.5),pixel filling(padding is 10),and random erasure(probability is 0.5);The training batch is set to 64, including 16 randomly selected Pedestrian IDs,4 images are randomly sampled for each ID;The loss functions used for training are described in subsection 4.2.1,where the classification loss function is Softmax Loss(regularized by label smoothing with eps= 0.1),the metric loss function is Triplet Loss,and the Cosine function is used for distance calculation; The training process uses the adam optimizer to update the modelparameters, momentum is set to 0.9, and weight decay is set to 0.0005;The learning rate adopts a multi-step learning strategy,and the initial learning rate is set to 0.00035.When the iteration reaches 40th and 90th epochs,the learning rate is reduced to 0.1 times of the original one in turn,and the training process is stopped after 120 epochs; For testing process, the test set is also scaled to 256 × 128.

Table 2Accuracy of SR-ResNet-50 and ResNet-50 on three different datasets.
4.3.Performance of instantiated model
We first test the instantiated model SR-ResNet-50 on three Re-ID authoritative datasets.As shown in Table 2, compared with ResNet-50,SR-ResNet-50 has significantly improved accuracy on all three datasets.On Market1501 dataset, SR-ResNet-50 is 1.55%higher on Rank-1 and 2.19%higher on mAP than ResNet-50;On the DukeMTMC-reID dataset, the accuracy of SR-ResNet-50 is also significant,with the Rank-1 reaching 88.51%and the mAP reaching 77.91%, which are 2.15% and 1.45% higher than the 86.36% and 76.46% of the ResNet-50 respectively.In the occlusion scene, SRResNet-50 algorithm shows strong robustness, its Rank-1 and mAP are increased from 49.73% to 43.33%-55.70% and 48.29%,which are increased by 5.97%and 4.96%,respectively.The necessity of explicitly modeling the interdependence between channel features is fully demonstrated.
In addition to the accuracy improvement, the paper also measured the average training speed and average inference speed of SR-ResNet-50 on the above three different datasets to be as high as 206 FPS (i.e.Frames Per Second) and 562 FPS, respectively.Of course,in order to further prove the advantages of the proposed SR block, we conduct relevant experiments in terms of model computational complexity.Specifically, we selected four highly cited attention mechanisms such as CBAM [16], EPSA [38], GAM[39] and SK [40] to replace our SR block, and tested their performance on the Market1501 dataset.Firstly, as can be seen from experiments 1-5 in Table 3, the computational cost of other attention mechanisms except CBAM-ResNet-50 is much higher than SR-ResNet-50.In particular, the GFLOPs (taking a single color pedestrian image of 256×128 pixels as input)of SK-ResNet-50 and inference speed of GAM-ResNet-50 reach 118.202 and 8.740 ms/f(millisecond/frame),respectively.Then,experiments 5 and 6 show that SR-ResNet-50, compared with the pure ResNet-50, has achieved a good trade-off between improved accuracy and increased computational cost (only increases by 0.052 and 0.497 ms/f on GFLOPs and Inference speed, respectively).
4.4.Ablation experiments
In order to further prove the influence of using different configurations on the SR block, we conduct a series of ablation experiments on the instantiated model SR-ResNet-50 to explore the optimal design of the SR block in seven aspects,including effect of max pooling, scaling factor, weighting method, fusion method, order of components in the composite convolutional layer, different stages and integration strategy.It should be emphasized that, to accommodate the control-variable method, all ablation experiments only show the test results on the single dataset Market1501(other datasets are also found to have semantic homology in this paper), and all experiments adopt the same experimental settings as described in subsection 4.2.In particular, this paper supports a practical exploration of the various ablation strategies proposed for different computer vision tasks, which means that the design techniques of SR-ResNet-50 model (including SR block) may vary depending on the task.
4.4.1.Effectofmaxpooling
First, we conduct experiments to verify the effect of max pooling.As shown in Table 4, after deleting the max pooling branch in the SR block, the Rank-1 and mAP of SR-ResNet-50 decreased by 0.54% and 1.31% respectively despite saving the computing cost of 0.045 GFLOPs.It can be analyzed that the specificity cues introduced by the max pooling can help the SR to infer finer attention mask, which is an indispensable supplement to global spatial information.
4.4.2.Scalingfactor
The existence of "Squeeze-Excitation" operation makes the capacity and computational cost of SR block easier to adjust.As can be seen from Table 5, with the increase of the scaling factorr, all indicators have significantly different changes.The value of accuracy indicator Rank-1 is robust in a certain range (fluctuating around 95.00%), while the other accuracy indicator mAP shows a trend of increasing first and then decreasing.Different from Rank-1 and mAP, the computational complexity of the model gradually decreases with the increase ofr.Whenr= 16, the mAP reaches the maximum value of 88.30%, which is 0.27% higher than that when the channel is not scaled (r= 1), and the computation load is also reduced from 4.219 GFLOPs to 4.105 GFLOPs (reduced by about 2.7%).At this time, Rank-1 also approaches the maximum value of 95.46% with only 0.03% accuracy difference.

Table 3Performance comparison of different attention mechanisms on the Market1501 dataset.

Table 4Performance comparison of SR-ResNet-50 before and after introducing the max pooling.

Table 5Effect of different r on model performance.
Comprehensive analysis shows that the reduction of model complexity will not monotonically improve the performance,and a good balance between accuracy and computational complexity can be achieved whenr= 16.
4.4.3.Weightingmethods
In subsection 3.3,the weighting method adopted by SR block is introduced in detail,and in order to prove its rationality,all variants of the weighting method are compared experimentally.As shown in Fig.11,from the form,the weighting factor has two kinds:vector(with the same dimension as mask)and coefficient.For each form,the value of each element in the weighting factorsPandQhas three relations:pi,qi∈R;pi,qi∈(0,1);pi,qi∈(0,1)andpi+qi=1.In this paper, pairwise combination of the form of weighting factors and value relations is carried out to obtain a total of six combinations, and the six combinations are verified one by one.
It can be clearly seen from Table 6 that the third group of experiments has the best accuracy,and the fifth group of experiments has the worst accuracy, but the computational complexity of the model remains unchanged.That is, compared with "P,Qare coefficients,pi,qi∈(0,1)", when "P,Qare vectors,pi,qi∈(0,1) andpi+qi= 1", SR-ResNet-50 achieves 0.72% and 0.51% improvement in Rank-1 and mAP, respectively, on the Market1501 dataset.In particular, comparing experiments 2 and 3, it can be seen that when"pi+qi=1",the Rank-1 and mAP of the model are increased from 94.92%to 88.10%-95.43%and 88.30%,respectively,indicating that there is indeed a"mutual exclusion"relationship between the max pooling mask and the average pooling mask in the Re-ID task,and this mutually exclusive relationship can be adjusted autonomously through network training;In addition,experiments 3 and 6 show that the performance indicators of SR-ResNet-50 when"P,Q are vectors"are better than those of SR-ResNet-50 when"P,Q are coefficients",which fully proves that the above"mutual exclusion"relationship is different in different channels.
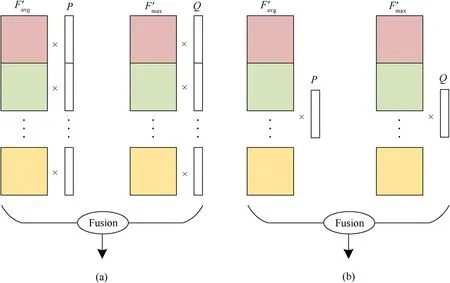
Fig.11.Schematic diagram of the weighting method of SR blocks: (a) The weighting factors are vectors; (b) The weighting factors are coefficients.

Table 6Effect of different weighting methods on model performance.
4.4.4.Fusionmethods
Element-add and channel-concat are two commonly used feature fusion methods in deep learning.The method of Add is equivalent to the assumption that the feature maps of the corresponding channels of two input features are semantically similar,which is widely used in many models, especially in the ResNet series.When the relationship between the two-branch input features is not clear, Cat can splice the two inputs along the channel dimension,so as to achieve the purpose of allowing the network to autonomically learn the two-branch feature fusion method.InceptionNet [5] and DenseNet [41] are typical representatives of this fusion method.
However, in practical application, the two fusion methods can be transformed into each other theoretically through certain processing [42].As shown in Fig.12, two input branches A and B are fused by Cat and then processed by convolution layer, which is equivalent to A and B being processed by convolutional layer and then performing add operation.Mathematically, it can be expressed as
where * denotes matrix multiplication, which is the convolution operation; Cat(·,·) represents the merging of channel directions;Wrepresents convolutional layer,brepresents bias; ⊕ indicates that the elements are added.
From Eq.(19), givenWandb, it’s easy to find the equivalent combination ofW1andW2,b1andb2, that is, two independent convolutional layers.It should be noted that, except for changing the fusion method, the structures of other network layers in the experiment remain the same.It can be seen from Table 7 that compared with the fusion method of element-add,the accuracy of Rank-1 and mAP is increased from 94.98% to 88.10%-95.43% and 88.30%,respectively,with a slight increase in the computation load.This coincides with the above analysis, indicating that channel merging is more robust to the fusion of two-branch input features with unknown relationships.
4.4.5.Componentorder
In Fig.2 and subsection 3.2,we elaborate several times that the component order of composite convolutional layer in the SR block is set as Conv1d-ReLU-BN(C-R-B).Scholars have different opinionson whether the BN layer should be placed in front of or behind the nonlinear activation layer ReLU:Ioffe[43],the original author of the BN layer technology, believes that it should be placed before the nonlinear layer, because the role of the BN layer is to smooth the input distribution of the hidden layer,so as to achieves the purpose of facilitating gradient propagation; However, Chen et al.[44]believe that BN layer should not be placed before ReLU,because the non-negative response of ReLU will make the weight layer updated in a suboptimal way.

Table 7Effect of different fusion methods on model performance.
We argue that the BN layer should be placed before or after the ReLU is related to the specific task and network structure.On the one hand, where BN layers are placed is dependent on the nonlinear activation function used (e.g., the difference between ReLU and Sigmoid); On the other hand, since most convolutional neural networks use a cyclic superposition of C,B,and R layers(e.g.-C-B-R-C-B-R-),the two ways should be equivalent to some extent.Therefore, the pros and cons should also be subject to the specific experimental conditions.
As shown in Table 8 (R-B-C and R-C-B combinations are not discussed here because the nonlinear layer cannot directly process features), compared with other combinations, the composite convolutional layer in the order of C-R-B has the best performance.According to the experimental results of the first and second groups,no matter the index Rank-1 or mAP,for the re-ID task using ReLU activation function, the model with BN layer after the nonlinear layer has better accuracy.The combination effect of the third group B-R-C was the worst,with a difference of 1.01%in Rank-1 and 1.58% in mAP compared with the third group.The analysis shows that using BN layer to process the feature map directly will seriously destroy the correlation of the original information, and the subsequent non-negative response of ReLU function will cause further loss of the feature map information.
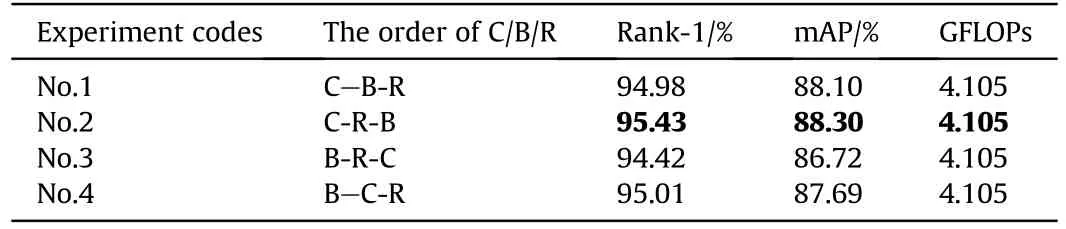
Table 8Effect of different orders of C/B/R in composite convolutional layers on model performance.
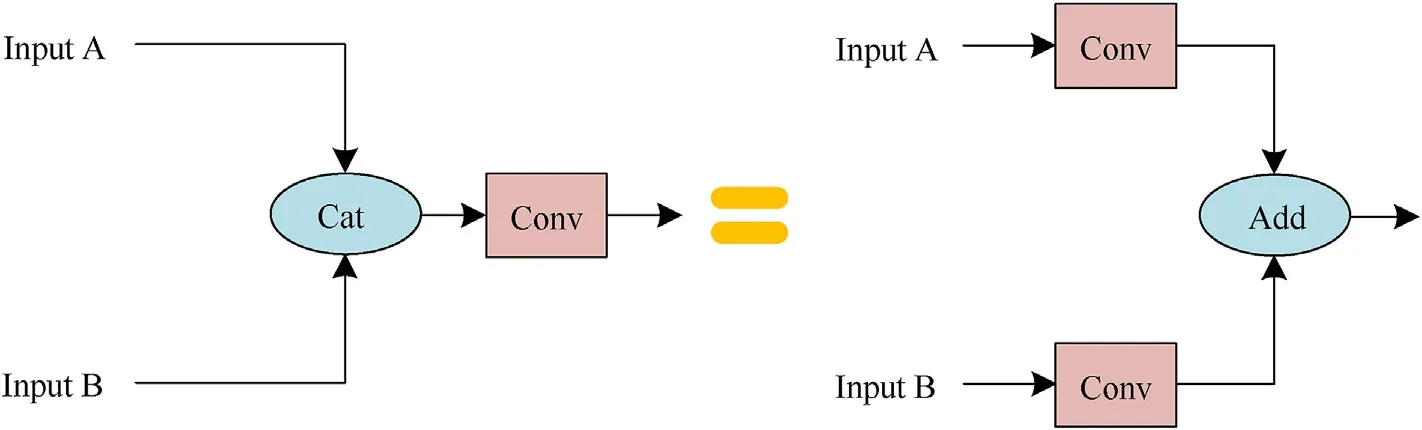
Fig.12.Equivalent schematic diagram of the fusion method of Cat and Add.
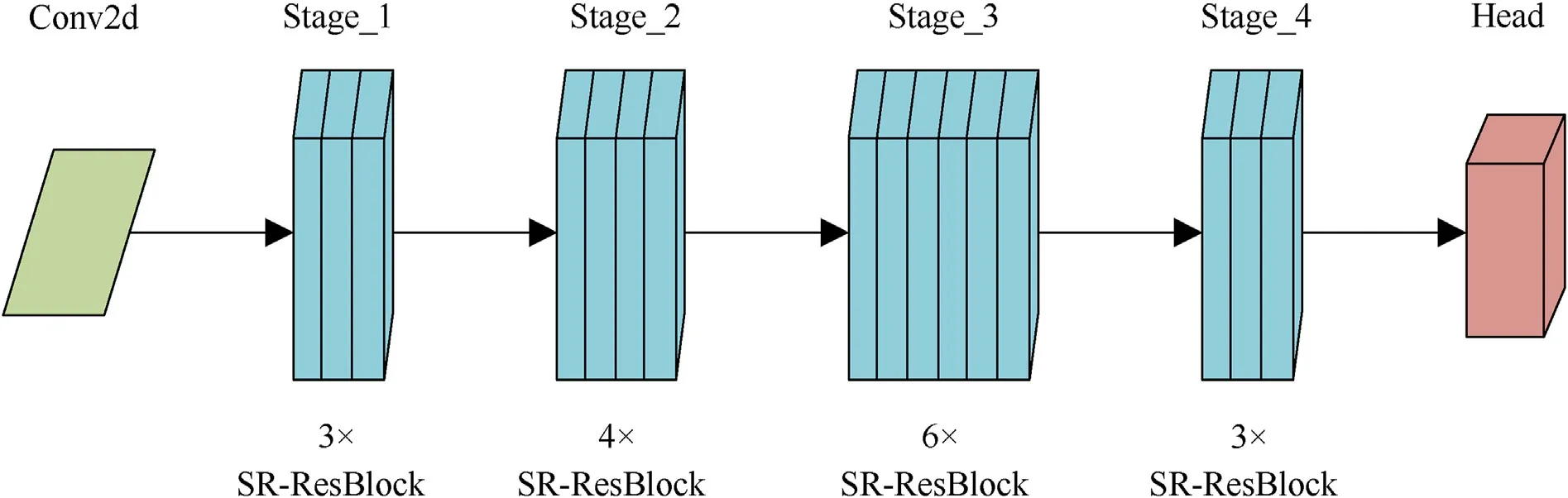
Fig.13.Network structure of SR-ResNet-50.

Table 9Effect of different stages of SR block insertion on model performance.
4.4.6.Differentstages
In order to explore the performance of SR blocks on different stages of the ResNet-50, we insert the SR blocks into Stage_1--Stage_4 of the ResNet-50 in turn, and obtain five different models SR-ResNet-50_Stage1,SR-ResNet-50_Stage2,SR-ResNet-50_Stage3,SR-ResNet-50_Stage4 and SR-ResNet-50 (indicating that SR blocks are inserted in all four stages, as shown in Fig.13), respectively.
As can be seen from Table 9,the performance of the model first increases and then decreases as the SR block is inserted deeper into the network.According to experiments 2-5,SR-ResNet-50_Stage2 has the best effect in four different stages,reaching 95.28%of Rank-1 and 88.01% of mAP; Compared with SR-ResNet-50_Stage2, the performance of model SR-ResNet-50_Stage4 is significantly decreased,with only 94.33%of Rank-1 and 86.51%of mAP,and the Rank-1 and mAP are decreased by 0.95% and 1.5%, respectively.At the same time, the computational complexity increases by 0.029 GFLOPs,which corresponds to the phenomenon that the deeper the network is, the more channels there are.
Looking across the first five sets of experiments,SR blocks lead to performance gains when introduced at each stage of the model.Moreover,from the experiment 6,it is known that the performancegains generated by the SR blocks at different stages are complementary, in the sense that they can be effectively combined to further improve the performance of the network.
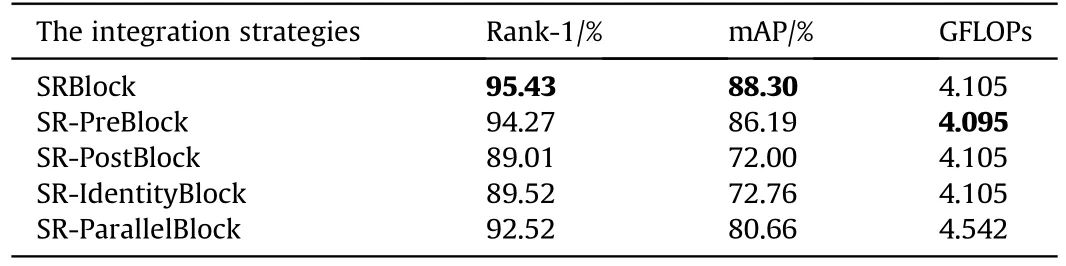
Table 10Effect of different integration strategies of SR blocks on model performance.
4.4.7.Integrationstrategies
Finally, in addition to the proposed SR block, four variants are considered in this paper,as shown in Fig.14:(c)SR-Pre,where the SR block is moved before the residual unit; (d) SR-Post, where the SR block is moved after the summation with the identity branch(after ReLU); (e) SR-Identity, where the SR block is placed on the identity connection,parallel to the residual unit;(f)SR-Parallel,The SR block is a separate branch,which is parallel to both the identity connection and the residual unit.
Table 10 shows that, except for the standard SRBlock, other integration strategies of the SR block lead to the degradation of the model performance.Compared with the standard SRBlock, SRPostblock has the most significant performance degradation, with the Rank-1 and mAP are only 89.01% and 72.00%, respectively,which are 6.42%and 16.3%lower than the standard SRBlock on the same indicator.For SR-Parallelblock,Rank-1 and mAP also decrease significantly,to 92.52%and 80.66%,respectively,compared with the standard SRBlock.In addition,SR-ParallelBlock is much higher than the standard SRBlock in terms of computation complexity, which increases from 4.105 GFLOPs to 4.542 GFLOPs, with an increase of 10.6%.Taken together,standard SRblock is the best way to integrate SR block in the Re-ID task.
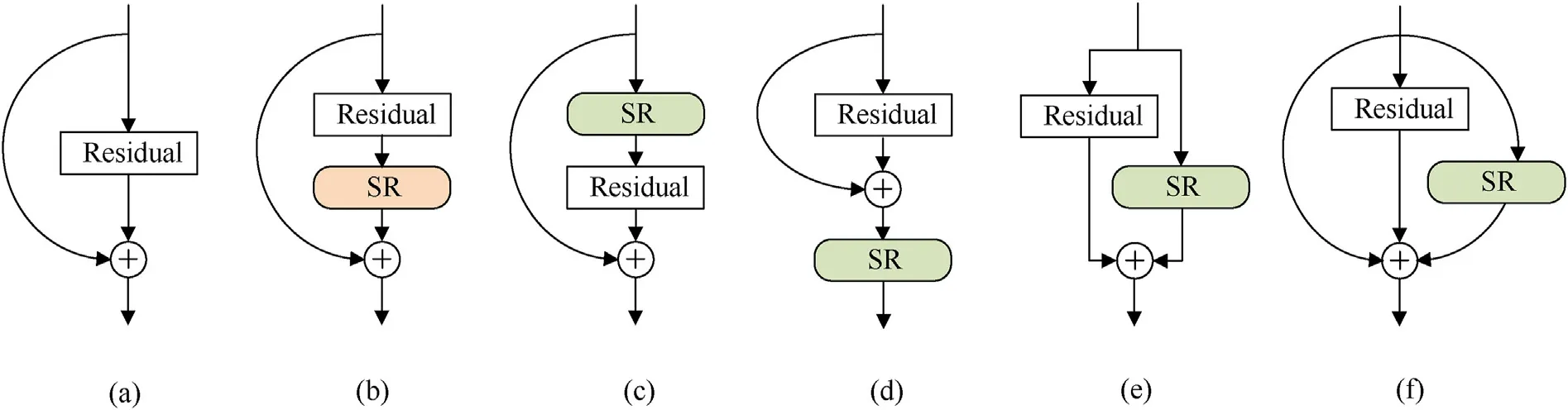
Fig.14.Schematic diagram of the integration strategy for SR blocks: (a) ResBlock; (b) SRBlock; (c) SR-PreBlock; (d) SR-PostBlock; (e) SR-IdentityBlock; (f) SR-ParallelBlock.
4.5.Algorithm comparison experiments
In order to prove the superiority of the proposed algorithm,we selected a series of advanced algorithms for Re-ID task from 2018 to 2022 for comparison,including two literatures in 2018 such as PAN[45]and PCB[46],and three literatures in 2019 such as AANet[47],CAMA[48]and OSNet[49].REDA[50]and CAP[51]were published in 2020, CBN [52], GPS [53] and CAL [54] were published in 2021,and MHSA-Net[28]and DAAF-BOT[29]were published in 2022.So that adds up to 12 different algorithms,the selection principles are as follows:
(1) Their structures are all based on convolutional neural networks;
(2) They are representative algorithms in different Re-ID genres;
(3) Experiments were carried out on Market1501 and DukeMTMC-reID datasets at the same time, and evaluation indicators Rank-1 and mAP were used.
As can be seen from Table 11, for the Market1501 and DukeMTMC-reID datasets,the SR-ResNet-50 proposed in this paper outperforms most classical algorithms in performance.Compared with the PAN algorithm, the performance of SR-ResNet-50 is significantly improved on the two datasets.The Rank-1 and mAP on Market1501 exceed 13.23%and 24.9%,respectively,and the Rank-1 and mAP on DukeMTMC-reID also exceed 16.92% and 26.40%respectively;For the MHSA-Net algorithm in 2022,the mAP of SRResNet-50 in this paper still has 4.30%and 4.81%advantages on the two datasets respectively;Of course,for the state-of-the-art(SOTA)CAL, SR-ResNet-50 still has a slight gap of 0.07% in Rank-1 of Market1501.However,it should be noted that the SR-ResNet-50 in this paper does not make other improvements except backbone,nor does it add any fancy training techniques(such as Re-rank,etc.).In this paper,Re-rank post-processing technology was added on the basis of SR-ResNet-50, and experiments show that it can easily surpass all the algorithms listed above, but it is meaningless to do so.From this level, the performance of SR-ResNet-50 is very competitive.
Next, we explore the generalization ability of SR-ResNet-50 on the occlusion dataset Occluded-Duke.It can be clearly seen from Table 12 that SR-ResNet-50 far exceeds other algorithms whetherit’s the indicator Rank-1 or mAP; For the most advanced HOReID,SR-ResNet-50 still outperforms by 0.6% and 4.49% on Rank-1 and mAP,respectively.The above fully proves the robustness of the SRResNet-50 in the occlusion scene, indicating that feature recalification is also beneficial to model the saliency information of pedestrians.
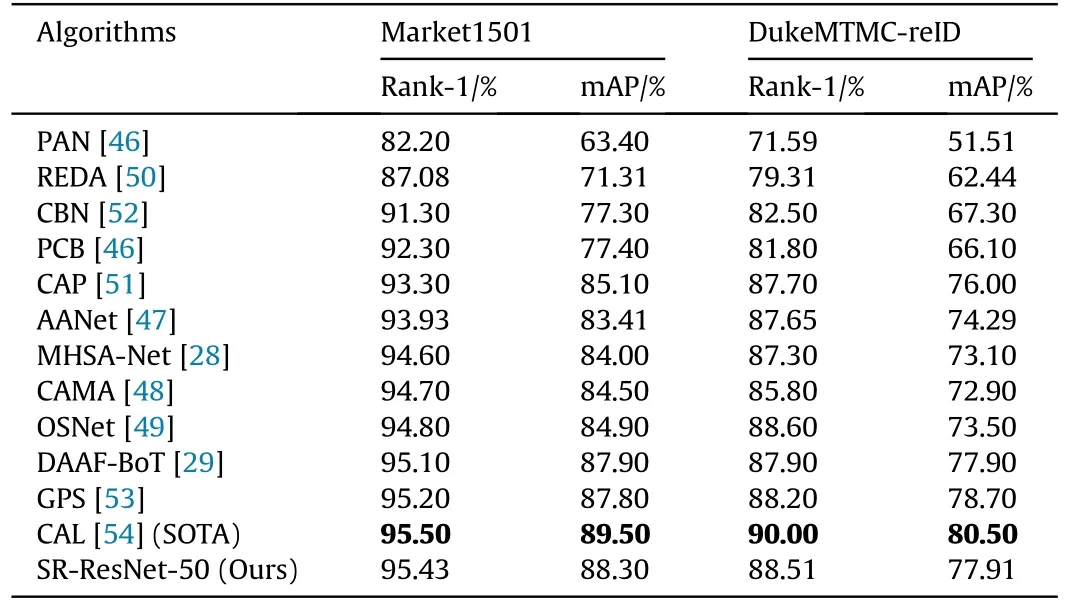
Table 11Accuracy comparison of SR-ResNet-50 and advanced algorithms on the regular datasets.

Table 12Accuracy comparison of SR-ResNet-50 and advanced algorithms on the Occluded-Duke dataset.

Table 13Accuracy comparison of SR-ResNet-50 and advanced algorithms on the MSMT17 dataset.
The results are shown in Table 13.Firstly,compare experiments 7 and 8,we can find that the Rank-1/mAP of ResNet-50 embedded with SR block is improved by 5.47%/3.75% compared with the original one,which proves that the improvement effect of SR block on model performance is still effective on MSMT17 dataset.Next,we select several advanced algorithms tested on the MSMT17 from 2019 to 2022 for comparison.From experiments 1-6 and 8, it can be seen that the our SR-ResNet-50 has certain advantages in accuracy.However,for the most advanced PNL algorithm,SR-ResNet-50 still has a large gap.Of course, this also provides us with an inspiration for the next step, which is that the performance of models that only embed simple enhancement modules can be further improved by adopting multi-aspect improvements or employing multiple training skills.
4.6.Visualization results
In order to directly reflect the actual retrieval performance of the model, we randomly select 3 query images for testing, and select the Top10 matching results according to the similarity from high to low.As shown in Fig.15,the first row of matching results for each query comes from the ResNet-50,while the second row comes from the proposed SR-ResNet-50 in this paper.As we can clearly see, a "yellow box" indicates a correctly matched target, while a"blue box" indicates a wrong match.Specifically, each retrieved instance is labeled as "201.243/false/cam0", where "201.243" indicates the similarity between the matched image and the query image, and "false" indicates that they are not the same ID (i.e., a wrong match)."cam0" means that the matched image originates from camera"0".

Fig.15.Display of some matching results between SR-ResNet-50 and ResNet-50.
From the presentation in Fig.15,we can find that the number of correct targets and ranking of SR-ResNet-50 in this paper are basically better than that of ResNet-50(baseline),and it has certain adaptability to complex environments such as blur, occlusion, and background interference.
5.Conclusions
In this paper, we propose a self-supervised recalibration network with plug-and-play SR block as the core, aiming at"improve performance + control computation load" for the Re-ID task.On the one hand, the SR block improves the representation ability of the model by explicitly modeling the interdependence between channel features, different from other channel attention modules,the channel recalibration factor of the SR block fuses both the global average information and local saliency information,and can autonomously recalibrate the feature response of the channel direction by means of channel weighted;On the other hand,the SR block regulates the channel dimension of the feature map through the designed SE unit, which effectively constrains the computational cost generated by the model.In particular, we integrate the SR block into ResBlock to build a new SR-ResNet-50 and take this as the research object.A series of ablation experiments and comparison experiments show that SR-ResNet-50 has better performance advantages on both regular dataset and occlusion dataset (especially the mAP exceeds the SOTA algorithm by 4.49% on the Occluded-Duke dataset), which plays a certain reference value for other computer vision tasks.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This work was supported in part by the Natural Science Foundation of Xinjiang Uygur Autonomous Region (Grant No.2022D01B186 and No.2022D01B05).

- Defence Technology的其它文章
- The interaction between a shaped charge jet and a single moving plate
- Machine learning for predicting the outcome of terminal ballistics events
- Fabrication and characterization of multi-scale coated boron powders with improved combustion performance: A brief review
- Experimental research on the launching system of auxiliary charge with filter cartridge structure
- Dependence of impact regime boundaries on the initial temperatures of projectiles and targets
- Experimental and numerical study of hypervelocity impact damage on composite overwrapped pressure vessels