
一种面向移动端应用的实时目标检测算法
2024-02-25 14:11彭强强黄璜
应用科技 2024年1期
彭强强,黄璜
1. 北京航天自动控制研究所,北京 100039
2. 北京科正平工程技术检测研究院有限公司,北京 100007
目标检测算法是计算机视觉领域的基本任务之一,主要解决目标对象分类及目标位置预测等问题,是许多计算机视觉任务及相关应用的基础与前提,广泛应用于安保、图像检测及自动驾驶等领域[1−2]。为取得更高的识别率,深度神经网络模型朝着越来越复杂的方向研究,而大多数复杂的网络模型无法应用在真实场景或部署在移动设备中,因此高效的目标检测模型具有非常高的研究价值。通常情况下,轻量级目标检测网络通过减少网络结构来降低训练后模型大小,从而使得网络模型能够更好地部署在移动设备中,在不影响准确率的情况下适应更多的应用场景。常见的轻量级网络主要包括YOLOv3-Tiny[3]、 YOLOv4-Tiny[4]、MobileNet[5]、MobileNet V2[6]、ThunderNet[7]、ShuffleNet V1[8]、ShuffleNet V2[9]等,其中,YOLO系列算法[10−12]将复杂的目标检测任务利用回归来解决,达到精度与速度之间的平衡。YOLOv3-Tiny 及YOLOv4-Tiny 网络在原YOLO 系列的基础上进行结构上的简化,以牺牲一定的检测精度为代价,极大地提高了检测速度。此外,在训练后的模型大小相近下,ShuffleNet 系列的检测准确率通常比MobileNet 的表现更好。ShuffleNet V1 采用了分组卷积和深度可分离卷积,在减少了模型的参数量以及运算量的同时保证检测的精度,但过多分组卷积的使用将会加重设备内存的负担;ShuffleNet V2 摒弃了分组卷积的方法,转而采用了ChannelSplit 操作,进一步提升了模型准确率并解决了设备内存的问题,然而存在参数冗余以及空间信息丢失的问题。此类模型大多是利用修改和优化网络模型结构来减少网络的复杂度,但多数轻量级网络无法兼顾特征图中目标的全局及局部的上下文信息,感受野较为有限,从而降低了网络模型的检测精度。
2020 年,一种轻量化的网络模型NanoDet 被提出,该模型通过集成多种性能强劲的网络模型,可同时兼顾精度和参数量,能够较好满足应用实时性的要求。但存在以下问题:一是NanoDet对大目标检测效果明显,但在特征提取的过程中容易忽视小目标,从而导致存在部分物体漏检的可能;二是轻量化骨干网络模型在特征传递的过程中网络结构以及卷积核的选择并不完善,易损失部分感受野,且模型的泛化能力较差。
针对上述问题,本文在NanoDet 的基础上提出一种面向移动端应用的实时目标检测网络:双注意力机制NanoDet 网络(double attention module nanodet,DAM-NanoDet)。首先,设计一种轻量化且高效的混合注意力模块,利用双池化方法同时提取通道特征,增加网络对局部区域的关注度,更好地捕捉通道维度之间的依赖关系,并将空间注意力模块在长宽方向进行拆分,减少模型的计算量;其次,修改骨干网络的结构,引入空洞卷积,增强模型的感受野。由实验结果可知,本文算法在嵌入式及移动端设备的检测中更为流畅和高效,整体性能和效率优于已有的YOLO 系列等算法,具有较强的可移植性、实时性、鲁棒性和实用价值。
1 双注意力机制NanoDet 网络
1.1 NanoDet 简介
NanoDet 是一个开源的实时目标检测模型,其整体结构如图1 所示,包括轻量化的主干网络(backbone)、 路径聚合网络 (path aggregation network,PAN)以及轻量化检测头(head)。其网络结构简单、检测速度快,因此适合在嵌入式设备及移动端部署。
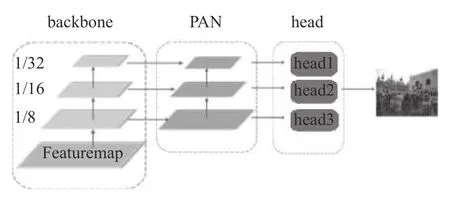
图1 NanoDet 目标检测网络模型
1.2 ShuffleNet V2 骨干网络
在NanoDet 网络模型中,可供选择的骨干网络包括MobilNet 系列、 GhostNet[13]、 ShuffleNet V2 以及EfficientNet[14]等。其中ShuffleNet V2 在保证精度的同时模型参数量最小,对移动端的推理也较为友好。因此,综合平衡网络的精度、计算量及权重等因素,本文选择ShuffleNet V2 作为骨干网络。由图1 所示,在NanoDet 结构中,去掉ShuffleNet V2 最后一卷积层,将提取的8、16、32 倍下采样的特征图作为后续路径聚合网络的输入。
1.2.1 ShuffleNet V2 基本单元的改进
在ShuffleNet V2 中包含2 个步长为1 的基本单元以及步长为2 的下采样单元,方法上保留了ShuffleNet 中的通道划分、通道混洗及深度可分离卷积等操作。其中深度可分离卷积包括逐点卷积的通道对齐以及卷积核为3×3 的深度卷积。相比于常规方法,ShuffleNet V2 基本单元的计算成本更低,而目标检测通常环境较为复杂,降低检测成本同时会损失部分的检测精度,导致模型精度不佳。因此,为了兼顾模型的精度与计算量,本文提出了一种改进的ShuffleNet V2 基本单元,如图2(b)所示。
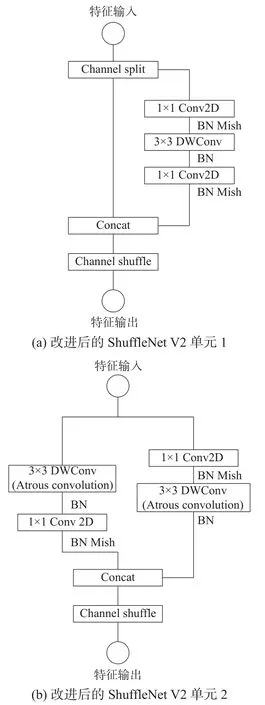
图2 改进的ShuffleNet V2 单元
首先,ShuffleNet V2 单元1 结构保持不变,将ShuffleNet V2 单元2 中3×3 的深度卷积替换为空洞率为2 的空洞卷积,在保证参数量不增加的同时加强模型的感受野。其次,在该结构的右分支中1×1 卷积并不改变通道维度,只起到特征融合的作用,多层卷积将导致结构冗余且泛化能力较差。因此,为进一步减少模型的计算量以适应移动端的部署,去掉右分支最后一层的1×1 卷积,可以在保留模型泛化能力的同时减少模型的参数量。最后,ReLU 激活函数虽然计算复杂度较低且网络训练收敛较快,但是ReLU 的函数曲线不平滑,易致使神经元在训练时“坏死”。因此,在ShuffleNet V2 单元中摒弃ReLU 函数,用曲线更为平滑且可以保留小部分负值的Mish[15]函数,Mish 函数公式为
Mish 激活函数与ReLU 相似,无上界但有下界,但Mish 函数相比于ReLU 保留了部分负值,从而规避了模型中少数神经元在反向传播时失效的情况[16]。因此,更为平滑的Mish 函数可使得特征信息传递到较深的网络中更加容易,模型更加容易训练,从而达到增强模型泛化能力的目的。
1.2.2 注意力机制
近年来,注意力机制在计算机视觉领域逐渐涌现出了巨大的潜能,通过对特征图的不同区域或通道进行加权,使得神经网络对特征图每个区域侧重不同,从而提升网络的特征提取能力。当今许多注意力机制的改进都致力于提升网络的复杂性以提供更强大的性能[17−18],但同时也会降低模型的实时性[19]。针对上述问题,本文在ECANet 的基础上设计,提出一种轻量化高效注意力模块(lightweight efficient attention module, LEAM)。该结构主要包含通道注意力模块和空间注意力模块,两者采用串联方式。图3 为该轻量化高效注意模块示意。
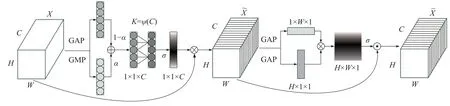
图3 轻量化高效注意力模块
如图3 所示,本文提出的LEAM 通道注意力模块在ECA-Net 的基础上改进挤压操作,由此获得自适应权值。首先,在改进的ECA-Net 中通过全局平均池化(global average pooling,GAP)操作获取全局的特征信息,但对于目标特征较少或者目标较小的情况,只关注全局信息会导致损失部分局部特征,而全局最大池化(global max pooling,GMP)操作则能弥补这个损失。因此本文同时引入了2 种池化方法,在捕获通道维度依赖关系的同时获取目标的全局与局部的特征信息,从而辅助优化检测效果。特征图经过GAP 与GMP 获得2 个维度为1×1×C 的通道特征后,将不同维度的通道特征进行加权,具体为
式中:XC为加权后通道特征,fA为GAP 操作,fM为GMP 操作,α为加权通道因子。
为避免通道互相独立,在随后的ECA 模块基于权重共享的思路,引入自适应卷积核大小为k的一维快速卷积并通过sigmiod 获取通道的权重,以降低模型的复杂度并提高计算效率,自适应卷积核大小k由下式决定:
式中|t|odd为最近的奇数t。
在目标检测网络中引入通道注意力子模块对各通道赋予不同的权值,提升了重点关注信息在特征中的权重,从而达到提升模型感受野的目的,对大目标的检测效果有较为显著的提升。而小目标物体的检测效果依赖于空间区域的关注度。通过引入空间注意力机制捕捉全局作用域中任意区域的关系,但内存与计算量随之提升。
针对上述问题,本文设计了一种改进的空间注意力子模块与上述通道注意力子模块进行串联,在减少模块计算量的同时改善网络对小目标的检测效果,如图4 所示。
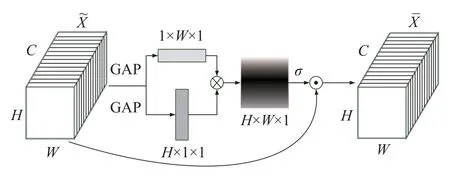
图4 改进的空间注意力模块
首先,对通道注意力子模块输出的特征图进行宽、高2 个方向的全局平均池化,得到大小为1×W×1 及H×1×1 的2 个特征向量。将2 个特征向量通过矩阵乘法生成H×W×1 的二维特征图,最后通过与输入特征图加权逐点相乘的方式得到通道空间注意图。对空间注意力机制的改进进一步减少了内存的占用和计算负担。
1.2.3 改进的NanoDet 骨干网络
图5 为NanoDet 改进前后骨干网络对比图。本文所提的骨干网络模型结构如图5(b)所示,在ShuffleNet V2 的基础上引入LEAM 注意力机制,并将ShuffleNet V2 单元2 替换为改进后的ShuffleNet V2 单元2;使用Mish 激活函数替代ReLU 激活函数,并为更好融合通道注意力摒弃最大池化层,而使用卷积核大小为3×3、步长为2 的深度分离卷积,丰富骨干网络提出的特征。
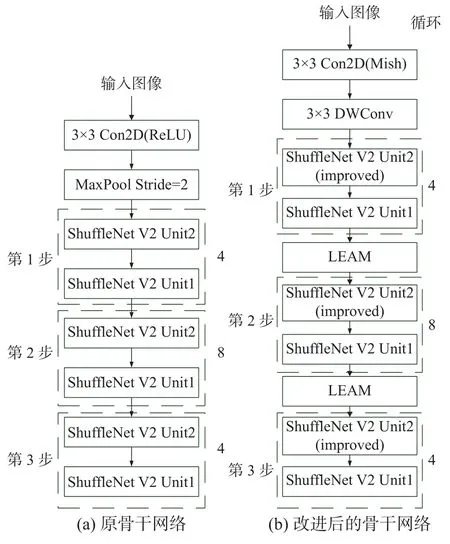
图5 NanoDet 改进的骨干网络对比
1.3 路径聚合网络
路径聚合网络使用了步长为2 的卷积将高层含丰富的语义信息的特征图下采样。首先为了简化模型使其轻量化,舍弃PAN 中的所有卷积,只保留从NanoDet 骨干网络输出后的1×1 卷积来实现特征通道的维度对齐,且在路径聚合网络中的上、下采样均用插值进行替代。最后,与YOLO不同,选择将多尺度的特征图利用相加的方式进行融合,因此极大减小了特征融合模块的计算量。
1.4 轻量化检测头
检测头采用了FCOS 系列的共享权重检测头,即利用相同卷积对多尺度特征图预测检测框,然后每一层使用一个可学习的尺度因子作为系数,并对检测框进行缩放。其优点是能够将检测头的参数量降低4/5。但对于轻量化模型,其模型通过中央处理单元(central processing unit,CPU)推理计算,共享权重失去了加速的意义,且在检测头非常轻量的情况下,模型的检测能力还会进一步降低,因此,在NanoDet 中一层特征对应一组卷积。此外,FCOS 检测头计算量较大,在边框回归和分类上一共有8 个256 通道的卷积。为最大程度的轻量化,选择深度可分离卷积,并且减少卷积的堆叠数。将256 维压缩至96 维,减少网络计算量的同时获得并行加速的能力,轻量化处理后的检测头如图6 所示。

图6 轻量化检测头
2 仿真实验与结果分析
2.1 实验环境与设置
实验以Pytorch 深度学习框架为基础,编程语言为Python3.7,软件环境为Linux 平台,操作系统为Ubuntu18.04。模型训练在GPU 型号为NVIDIA GeForce GTX 1 660 Ti 上的设备进行,显存为8 G。测试使用的CPU 型号为Intel(R) Core(TM) i7-9750H。在实验中,设置检测阈值为0.5,训练迭代次数为100 次,初始学习率设置为0.02。
2.2 实验环境与设置
本文在MS COCO(common objects in context)数据集上[20]完成对改进网络的训练、验证和测试,MS COCO2017 数据集是微软在2017 年整理的一个用于检测识别的数据集,此外还提供目标分割和对图像的语义文本描述信息。数据集总共有90 个类别且包含3 个部分,其中,train-2017 为训练集,共有11 万余张训练图片;val-2017 为实验的验证集,共包含5 000 多张图片样本;test-2017 则共有4 万余张图片样本为测试集。
2.3 实验环境与设置
在目标检测领域中,检测精确度P和召回率R是2 个基本的指标。精确度和召回率是根据以下4 个指标来计算:
1)真正类(true positive,TP)NTP:模型预测为正的正样本;
2)真负类(true negative,TN)NTN:模型预测为正的负样本;
3)假负类(false negative,FN)NFN:模型预测为负的负样本;
4)假正类(false positive,FP)NFP:模型预测为负的正样本。
因此,精确度P的计算公式为
召回率R的公式为
平均精确度(mean average precision, mAP)mAP为
式中:P(R)为在不同的置信度阈值下,由检测精确度和召回率所构造的曲线, 而AP(average precision)为模型的均值精度,即P(R)曲线与坐标轴围起来的面积,对数据集中的所有类别求平均即得到mAP。为了分析检测网络对不同尺度目标的检测效果,COCO 数据集还使用了APS、APM、APL这3 个指标分别表示对小目标、中目标和大目标的mAP 值。本文实验主要使用上述指标衡量模型的检测性能。
2.4 实验结果与分析
在对检测模型各模块进行轻量化后,得到了本文的目标检测模型。在输入分辨率为320×320及426×426 的情况下选取test2017 的数据集进行测试。表1 列出了本文目标检测算法与其他模型的对比,所有数据均在CPU 设备上获得。

表1 在分辨率320×320 下本文目标检测算法与其他模型的性能对比
由表1 可知,DAM-NanoDet 算法在COCO2017数据集上输入分辨率为320×320 的测试中,mAP 达到了23.2,模型参数量相较于原NanoDet算法提升了0.22 M,网络延迟有较小增加,但检测精度有显著提升。由对比可知,本文算法在小目标及大目标的校测效果上提升明显,综合效果好于原NanoDet、ThunderNet、YOLO-Nano 等轻量级网络模型。整个模型每秒浮点运算次数(floatingpoint operations per second,FLOPS)仅有1.06 B,模型的参数量仅为1.17 MB,复杂度较低。
由表2 可知,DAM-NanoDet 算法在COCO2017数据集上输入分辨率为416×416 的测试中,mAP 达到了25.6,相比原算法提高了2.1 个百分点,AP50 及AP75 明显高于其他算法,效果好于原NanoDet 算法以及YOLO 系列的轻量级模型。整个模型FLOPS 仅有1.52 B,模型的参数量仅为1.17 MB在有效减小应用程序体积的条件下,17.64 ms的延迟同时保证在移动端部署的检测速度。

表2 在分辨率426×426 下本文目标检测算法与其他模型的性能对比
2.4.1 PC 端实验结果
图7 和图8 分别为本文所述目标检测算法在COCO2017 数据集上和安卓手机端对目标的检测结果。

图7 改进NanoDet 模型目标检测效果

图8 安卓手机端目标检测结果
图7 为PC 端的4 组目标检测效果图。从图7中可以明显看出,本文算法在大、中、小目标中都有较高的检测精确度,且在目标存在严重遮挡的情况下依旧能准确地检测出目标。
2.4.2 算法在移动端的部署实验
移动端实验的硬件条件为Redmi K30 Pro 智能手机,配高通骁龙865 处理器,运行内存为8 GB。安卓手机端目标检测结果如图8 所示。从图8 中可以看出本文检测算法能够很好地定位目标并识别出物体的类别,具有较高的定位准确度和较好的检测效果。安卓手机端的平均检测帧率可以达到60 帧/秒以上,能够满足实时性要求。
3 结论
为了满足目标检测在移动端部署条件下对于目标检测算法中实时性以及准确性的要求,本文提出了一种可部署在移动端的实时目标检测算法。
1)考虑到目标检测的实时性及计算复杂度等要求,设计了一种轻量化高效注意力模块,增强了特征通道信息以及空间信息的表达能力,在计算量及精度之间保证更好的平衡。
2)改进了骨干网络的结构,加强网络的泛化效果,得到了一个兼顾精度、速度和体积的检测模型。实验结果表明,本文算法相比YOLO 系列模型参数量更低且准确度更高,更适合部署在移动端设备上。 在未来的研究中,还需要进一步结合先进的深度学习技术在目标检测效率以及模型的训练速度上进一步研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
专用汽车(2016年1期)2016-03-01
