
基于高阶信息的网络相似性比较方法*
2024-02-21 13:12:46陈浩宇徐涛刘闯张子柯詹秀秀3
物理学报 2024年3期
陈浩宇 徐涛 刘闯 张子柯 詹秀秀3)†
1) (杭州师范大学复杂科学研究中心,杭州 311121)
2) (浙江大学数字沟通研究中心,杭州 310058)
3) (浙江大学传媒与国际文化学院,杭州 310058)
1 引言
大多数实际的复杂系统都可以表示成复杂网络,从细菌、细胞和蛋白质系统,到人类关系网络,甚至再到大型的互联网和万维网[1,2].近年来,研究各种复杂网络结构的相似性已经成为一个流行且跨学科的主题,目前在社会科学[3]、医学[4]、生物学[5]和计算机科学[6]等领域得到了广泛应用.比较网络之间的相似性在当今社会发展中扮演着不可或缺的角色[7–11].例如,在医学领域[12],研究人员可以利用基因网络比较不同组织之间的相似性,以此发现与疾病相关的基因和信号通路;在生物领域[13],通过相似性方法来比较不同生物体或不同条件下的蛋白质相互作用网络,可以发现共享的功能模块以及关键的蛋白质节点;在社交领域[14],利用相似性比较不同社交网络中的社区结构,从而揭示社区的划分和特征.
网络比较问题最初源于图同构[15,16]问题,也被称为图匹配[17]或网络对齐[18],其研究的本质在于判断两个图中的节点集是否存在一对一映射的关系[19,20].通过比较网络的结构拓扑性质来量化网络之间的异同性,例如边密度、度分布和节点距离分布[21]等较为简单的拓扑结构特征,或者网络社区结构[22]、光谱熵[23,24]等更为复杂的拓扑结构特征[25–27].例如,Koutra 等[28]提出了一种基于Matusita 距离来度量网络节点亲和力矩阵之间的相似度方法;De Domenico 和Biamonte[29]提出了一套基于谱熵的网络比较信息理论工具;Schieber 等[30]通过考虑节点之间的最短路径距离的概率分布,高效量化了网络之间的差异;Chen 等[31]提出了一种基于节点可通信性序列和谱熵的比较方法;Liu 等[32]提出了基于遗传算法和模型选择的机器学习的网络比较方法.这些方法的基本思想都是选取网络特定的拓扑性质,并选择特定的熵度量来比较网络的异同[33].然而,单独选取特定的拓扑性质无法充分捕获网络的全局结构信息.因此,我们引进了网络节点的高阶聚类系数,并通过构建节点的高阶聚类系数分布和最短路径分布,再基于两个分布之间的Jensen-Shannon 散度[34]来度量网络节点连通异质性.该方法在综合考虑网络全局性质重要性的同时,也兼顾了网络局部的拓扑结构的影响.
本文的其余部分结构如下: 第2 节介绍本文用到的相关概念,提出基于高阶信息的网络相似性比较方法,并且介绍网络比较的常见基线算法;第3节是实验部分,分别在人工合成网络和真实网络上评估了此方法;第4 节是总结与展望,并为今后的网络比较工作提供了全新思路.
2 基于高阶信息的网络相似性方法
2.1 基本定义
符号定义为了方便讨论,将网络统一记为G=(V,E),节点集合V和边集合E分别表示为V={v1,v2,···,vN},E={ek=(vi,vj),k=1,···,M|vi,vj∈V},其中N和M分别表示网络G中节点和边的数量.根据网络中节点与边的隶属关系,构建邻接矩阵AN×N,具体而言,当节点vi和节点vj有连边时,Aij的值为1;否则为0.此外,构建网络中节点的邻居集Q={q1,q2,···,qN},其中qi为节点vi的邻居集合,|qi| 为节点vi的邻居个数.
2.2 高阶聚类系数
聚类系数是一种描述网络拓扑结构的指标,它反映了节点周围邻居之间相互连接的紧密程度,且可以衡量网络中节点的聚集程度.然而,在真实网络中,由于节点间最短路径长度较短且聚类系数较大,且这样的局部特征不能充分描述节点周围邻居之间的高阶联系,往往导致无法捕捉网络中局部拓扑结构性质的差异.为了解决这个问题,本文引入了一种更高阶的聚类系数定义[35],在标准聚类系数的基础上进行了扩展.
传统标准聚类系数只考虑三角形子图的数量来度量网络中节点的聚集程度,而高阶聚类系数则进一步考虑了更高阶的子图,从而能够更准确地刻画节点邻居间的联系,捕捉到网络中的更复杂的拓扑结构.它能帮助我们理解网络的聚集性和功能模块,从而提高网络的鲁棒性和可靠性,这对于研究网络的演化过程具有重要意义.例如,在分析社会团体网络时,有利于发现更为复杂的关联模式,揭示群体内部的交互模式和组织形式[36].
首先定义Ei(x) 为网络中去除vi以及对应的连边后vi的邻居中距离为x的节点对的数量.因此,si(x) 定义为去除节点vi之后,其邻居之间距离为x的节点对的比例,表达式为
本文 称si(x) 为 关于节点vi的x-阶聚类系数,根据x数值的改变,可以定义任意阶聚类系数.因此,对于网络中的所有节点可以构建一个完整的网络节点高阶聚类系数分布矩阵S={S1,S2,···,SN}.具体来说,节点vi的聚类系数分布为Si={si(x)|1 ≤x≤N-1}.由于在计算节点vi的聚类系数分布时会在网络中移除该节点,因此新生成的网络直径最大可能值为N-2 .其中si(x)(1 ≤x≤N-2) 为节点vi的x-阶聚类系数值,而Si的最后一列值si(N-1) 为节点vi的邻居之间不存在路径的节点对的比例.
图1 给出了高阶聚类系数的一个例子,其中图 1(a)是一个由7 个节点构成的小网络,在此网络中去除节点v1及其相应的连边后可得到图1(b).计算图1(b)中节点v1的邻居之间的距离可得矩阵,如图1(c)所示,例如节点v2和节点v6之间的距离为3.由图1(c)的距离矩阵可以进一步计算节点v1的距离分布,结果如图1(d)所示,即阶数为1 的聚类系数为s1(1)=0.4,阶数为2 的聚类系数为s1(2)=0.3,以此类推,阶数为5 的聚类系数为s1(5)=0 .值得注意的是,因为节点v1的每两个邻居间都存在路径,因此阶数为6 的聚类系数s1(6)=0.
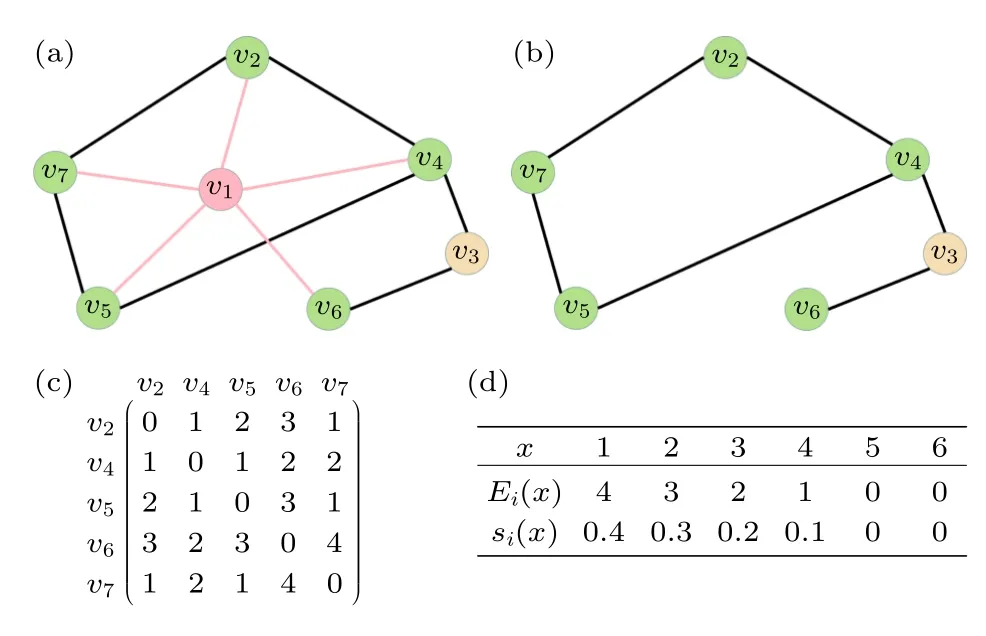
图1 网络高阶聚类系数计算示意图 (a)节点 v1 及它的邻居形成的网络;(b)去除节点 v1 后的网络;(c)图1(b)所示网络 中节 点 v1 的邻 居之间的距 离矩阵;(d)节点 v1 的 高阶聚类系数分布Fig.1.Illustration of the calculation of the higher-order clustering coefficient: (a) A network formed by nodev1 and its neighbors;(b) network after removing node v1 ;(c) distance matrix between neighbors of node v1 in the network shown in panel (b);(d) the higher-order clustering coefficient distribution of node v1 .
2.3 基于高阶信息的网络相似性算法
首先定义节点的距离分布,即一个网络节点间距离分布矩阵由P={P1,P2,···,PN}表示,每个节 点vi的距离分布向量 为Pi={pi(x)|1 ≤x≤d+1},其中pi(x) 表示与节点vi距离为x的节点的比例,而pi(d+1) 则表示与节点vi不存在路径的节点的比例,d为网络直径.
节点vi的高阶聚类系数分布和距离分布分别考虑了vi的邻居之间的聚集程度以及vi与网络中其他节点的距离远近,以下综合这两种分布来定义网络的相似性算法.首先,因为d+1 ≤N,可以将距离分布Pi通过补零的方式变成一个N-1 阶向量.然后定义网络G的高阶信息分布Ti={γSi,(1-γ)Pi},且Ti的维数为 1×(2N-2),其中γ∈[0,1],可以调节Si和Pi在Ti中所占的比例,γ越大,表示分布里面更注重高阶聚类系数信息,如果γ趋于0 表示更注重距离信息.
给定网络G以及其上的高阶信息分布T,根据Jensen-Shannon 散度来定义网络节点散度NND(network node dispersion):
式中J(T1,T2,···,TN) 表示N个节点分布的Jensen-Shannon 散度,其表达式为
其中ti(j) 是高阶信息分布Ti的第j列的具体数值;而µj为N个节点分布第j维的平均值,其表达式为网络 NND 衡量了网络节点连通异质性的大小,其值越大表示网络中节点连通异质性越大,反之亦然.
网络之间的相似性给定网络G和G′,可以使用以下公式来计算两者在结构上的相似性DHC(G,G′),表达式为
网络结构相似性DHC由两个部分组成.第1 部分考虑了网络中节点的平均连通性,其中J(µG,µG′)表示两个网络的平均距离分布的Jensen-Shannon散度,µG={µj|(1 ≤j≤2N-2)},它包含了基于节点高阶聚类系数和节点间距离分布的信息,从而捕捉了网络的全局结构性质;第2 部分考虑了节点之间的异质性,即网络中局部的结构性质.其中参数β 用于调节它们的权重.如果两个网络之间的DHC值越小,说明它们的结构相似性越大;反之,DHC值越大,说明它们的结构相似性越小.
图2 给出一种基于高阶信息的网络相似性比较方法计算流程图,用于比较网络G和G′.图 2(a)展示了网络G和G′的结构,其中G是一个全连通网络,而G′是一个含有一个孤立节点的网络.通过以下步骤计算这两个网络之间的相似性,具体过程如图2(b)和图2(c)所示: 首先,计算节点的高阶聚类系数分布和节点的距离分布;然后,根据(2)式和(5)式计算两个网络之间的相似性.最终,得到网络G和G′之间的DHC值为0.39.
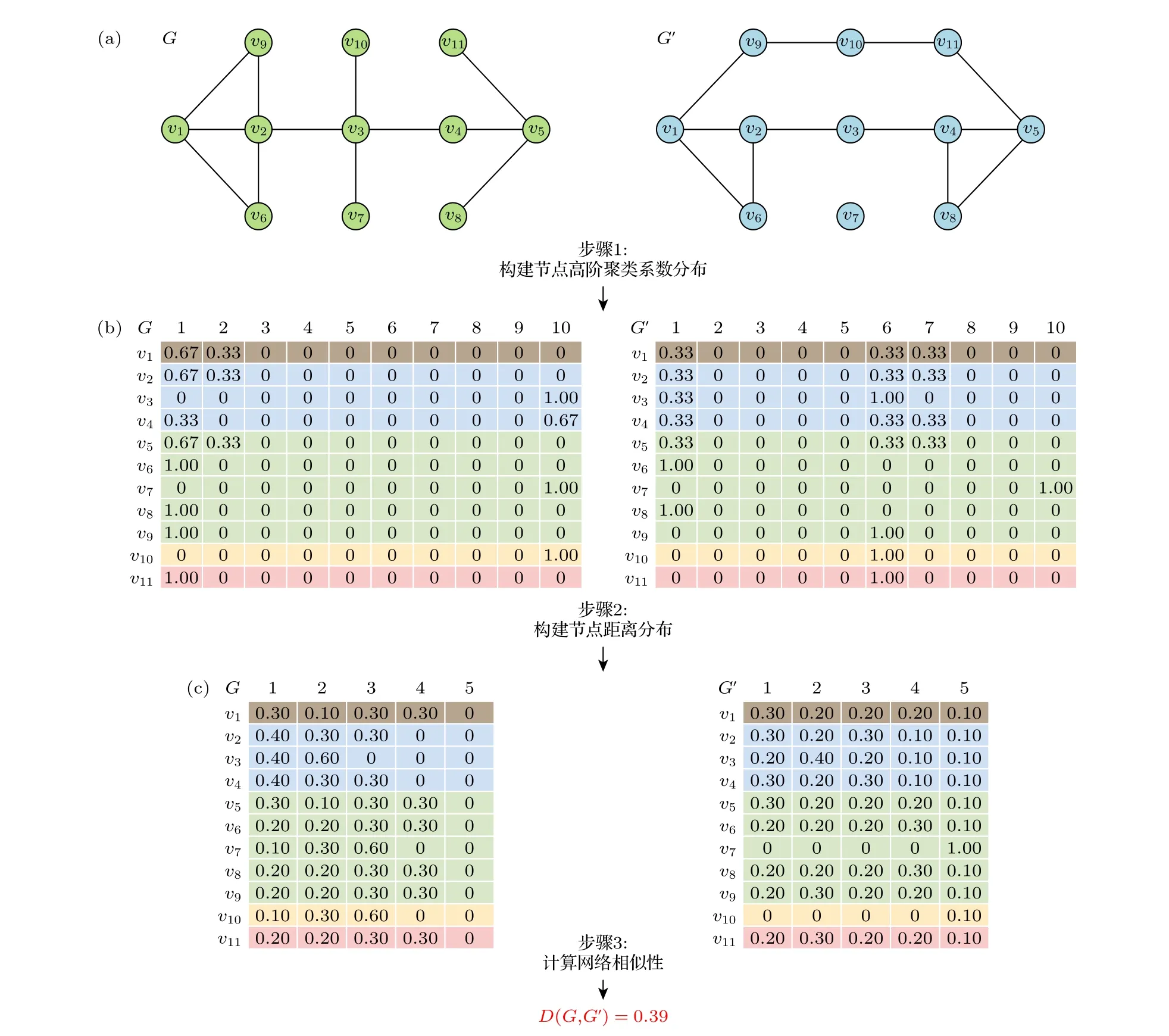
图2 基于高阶信息的网络比较方法计算流程示意图 (a)给定两个拥有 11 个节点的网络G 和 G′ ,其中G 有 14 条边,G′ 有12 条边;(b)如何计算基于高阶信息的网络相似性的示例,包含了节点高阶聚类系数分布和节点距离分布;(c)网络相似值的计算,其中β=0.5Fig.2.Schematic diagram of calculation flow of network comparison method based on high-order information: (a) Given two networks G and G′ with 11 nodes,G has 14 edges and G′ has 12 edges;(b) an illustration of how to compute the network similarity based on higher-order information,including the distribution of node higher-order clustering coefficients and node distance distribution;(c) calculation of the network similarity value DHC ,where β=0.5 .
2.4 基线算法
基于距离分布的网络相似性方法[30]
根据上述节点vi的距离分布Pi={pi(x)},由距离分布和Jensen-Shannon 散度定义两个网络G,G′的相似性比较算法:
DSP共基于3 个距离的概率分布,第1 项表示以平均距离分布(即µG和µG′)为特征的差异性,第2项表示网络节点分散度的差异性,第3 项则是网络α-中心性分布的差异,且Gc是G的补图.这里
式中,J(P1,···,PN) 是N个节点距离分布的Jensen-Shannon 散度;w1,w2,w3和α 是可调参数,且满足w1+w2+w3=1 .本文设置权重w1=w2=0.45 和w3=0.1 来进行网络相似性比较.
基于可通信性序列熵的网络相似性方法[31]
通过构造网络可通信性矩阵C来测量节点之间的通信能力,其定义如下:
其中Cij表示为节点vi和vj之间的可通信性,它反映了网络中节点之间的信息传递能力.假设L={L1,L2,···,LM}是标准化的可通信性序列,其中
(1 ≤y≤M,1 ≤i≤j≤N和M=N(N+1)/2),L序列的香农熵H(L) 定义如下:
给定两个网络G和G′,归一化可通信性序列分别由LG和给出.按升序对中的值进行排序,并获得新的可通信序列为.因此,基于可通信性序列熵的网络相似性被定义为DC(G,G′):
基于拉普拉斯特征值的网络相似性方法[37]
该方法通过构造网络拉普拉斯矩阵,并利用邻接矩阵和度矩阵的特征值计算得到光谱距离.通过比较网络的光谱距离差异性,该方法能够更全面地表示网络的拓扑结构,从而选择更具稳定性的比较方式.基于拉普拉斯特征值的网络相似性被定义为DM(G,G′):
其中λ 和λ′分别为两个网络中拉普拉斯矩阵的特征值.
3 实 验
3.1 人工合成网络比较
为了验证本文提出的方法在量化网络相似性方面的能力,进行了参数β 和γ的敏感性分析,旨在展示基于高阶信息的网络比较方法的鲁棒性.在实验中选择用WS 网络和BA 网络来测试方法的鲁棒性,其中网络的平均度均为10.WS 网络中选取重连概率为p=0.3,而BA 网络中选取每一步的加边数m=5 .图3(a)和图3(c)中的每一个点分别表示N=1000 的WS 网络与N= [1500,5000],间隔为500 的WS 网络相似性值 (DHC),不同参数β 和γ的取值分别对应不同颜色的曲线.图3(b)和图3(d)对相同规模的BA 网络进行了类似的分析.由图3(a)—(d)可以看出,WS (或BA)网络与节点数相差小的网络相似性更大,且β (或γ)并不会影响曲线的趋势.此外,图3(a)和图3(b)显示β 的值越大网络差异性就越明显,因此在后续的所有实验分析中将β 设置为1.从图3(c)和图3(d)可以观察到,两种不同人工合成网络下当γ=0.7时(即在高阶信息分布中较注重高阶聚类系数的拓扑信息),得到的相似性效果最为显著.因此后续的所有实验分析都将γ设置为0.7.

图3 人工合成网络下(WS,BA)的参数敏感性分析 (a)不同参数β 下 N=1000 的WS 网络与 N=[1500,5000],间隔为500,重连概 率 p=0.3 的WS 网络之 间的相 似性;(b)不同 参数β 下 N=1000 的BA 网络与 N=[1500,5000],间 隔为500 的BA 网络之间的相似性,其中每个BA 网络每一步加边数 m=5 ;(c)不同参数γ 下WS 网络之间的相似性,参数与(a)图一样;(d)不同参数γ 下BA 网络之间的相似性,参数与(b)图一样.所有的结果均基于100 次实验的平均值Fig.3.Parameter sensitivity analysis of synthetic networks generated by the WS and BA model: (a) Similarity between the WS network of N=1000 and the WS networks of N=[1500,5000] with the interval is 500 under different parameters β,where the probability of rewiring p=0.3 ;(b) similarity between the BA network of N=1000 and the BA networks ofN=[1500,5000]with an interval of 500 under different parameters β,where each BA network adds edges at each step with number of m=5 ;(c) similarity between WS networks under different parameters γ,the parameters are the same as with those in panel (a);(d) similarity between BA networks under different parameters γ,the parameters are the same as those in panel (b).All results are based on an average of 100 realizations.
图4 在由模型生成的人工网络上(即ER,WS,BA 网络)对比了提出的基于高阶信息的网络比较方法与其他基线方法在网络相似性上的性能,其中网络规模统一设置为N=1000 .在ER 模型中,通过重连概率p∈{0.1,0.3,0.5,0.7,0.9}构造网络;在WS 模型中,通过相同重连概率构造网络,且平均度均为10;在BA 模型中,通过每一步的加边数m∈{2,3,4,5,6}构造网络.图4(a)—(d)给出了DHC,DSP,DC和DM等4 种方法在ER 网络上的性能比较.直观上来讲,由相似重连概率生成的网络的相似性会比较高,而重连概率相差较大的网络的相似性差距较大.由结果可知,DHC能够很好地展现这一结论,而DSP方法在p≤0.5 表现比较好,但是p≥0.5 的网络之间的相似性差别不大.同样,DC和DM分别 在p≥0.3 和p≥0.5 无法区分由 不同重连概率生成的网络.此外,在WS 和BA 网络上,基于高阶信息的网络比较方法DHC也能够很好地区分不同参数生成的网络,而DSP无法区分p≥0.5 的WS 网络和m≥4 的BA 网络.DC无法区 分p≥0.5 的WS 网络和m≥3 的BA 网络.虽然DM能够区分不同概率p(或不同加边数m)下的WS (或BA)网络,但是其相似性的数值与直观的理解是相反的.例如,在WS 网络上,直观上来讲,p=0.1 的WS 网络与p=0.5 的WS 网络的相似性应该大于p=0.1 的WS 网络与p=0.7 (或p=0.9)的WS 网络的相似性,但DM给出的数值恰恰相反.此外,在BA 网络上DM的性能与WS网络相似.DHC和DSP相比,同时应用了节点的距离分布来比较网络,不同的是DHC考虑了节点的高阶聚类系数,这表明高阶聚类系数这一拓扑性质能够帮助比较不同结构的网络.综上所述,与其他方法相比,基于高阶信息的网络比较方法能够很好地区分由不同参数生成的ER (或WS,BA)网络.
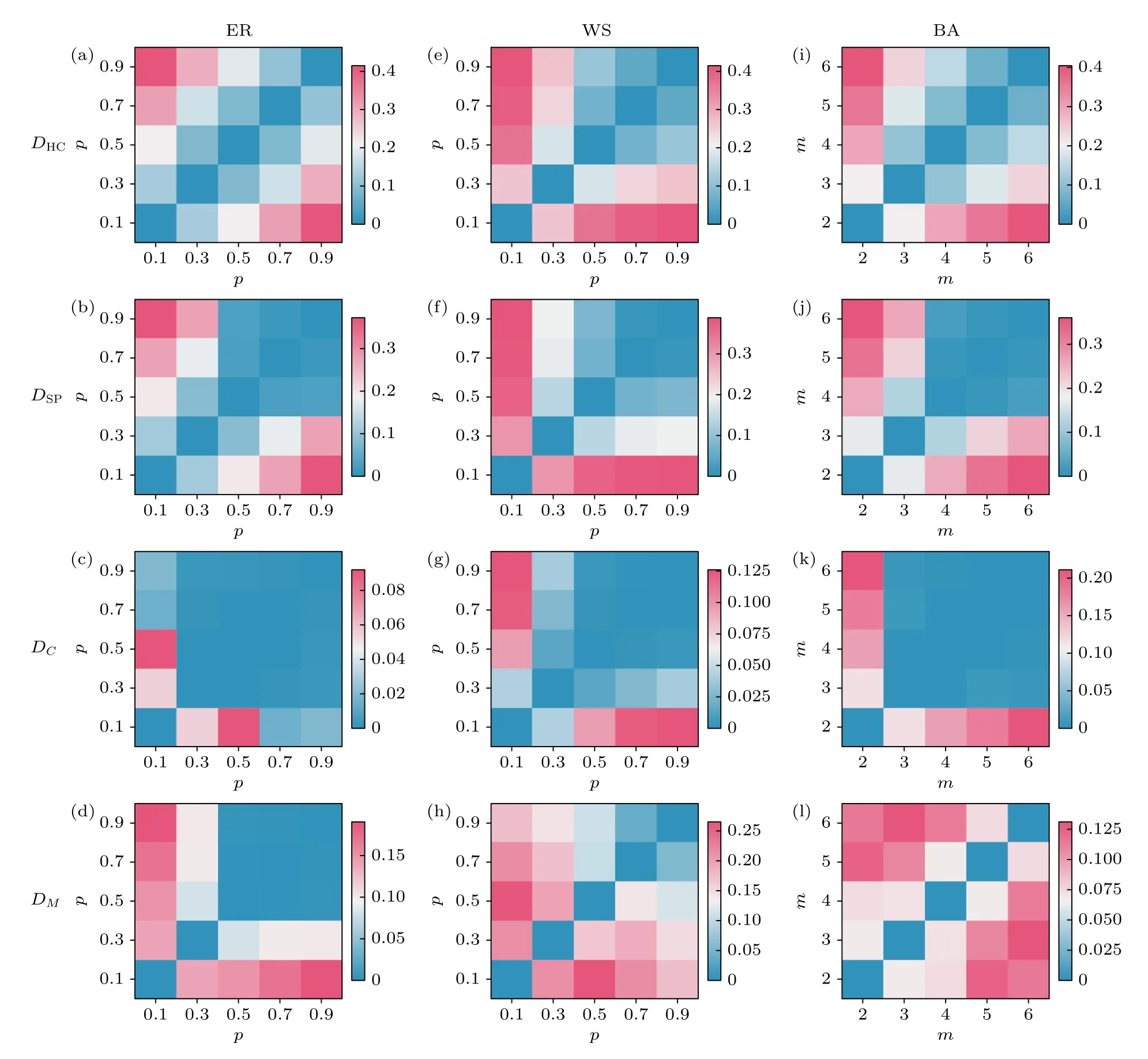
图4 四种相似性方法在人工合成网络上的效果评估(网络规模均为 N=1000) (a)—(d)不同重连概率p 下ER 模型生成的每对网 络的相似性,其 中相似性方法分 别为 DHC ,DSP ,DC 以及 DM ;(e)—(h)不同重连概 率p,平均度为10 下WS 模型生成的每对 网络的相似性,其中相似性方法分别为 DHC ,DSP ,DC 以及 DM ;(i)—(l)不 同加边数 m ∈{2,3,4,5,6} 下BA 模 型生成的 每对网 络的相似性,其中相似性方 法分别为 DHC ,DSP ,DC 以及 DM .所有的结果均基于100 次 实验的平均值Fig.4.Effectiveness of four similarity methods in comparing synthetic networks.The network size is set to N=1000 : (a)–(d) Similarity between each pair of networks generated by the ER model under different rewiring probabilities p,where the network comparing methods are DHC ,DSP ,DC and DM ;(e)–(h) similarity between each pair of networks generated by the WS model with different rewiring probabilities p and an average degree of 10,where the network comparing methods are DHC ,DSP ,DC and DM ;(i)–(l) similarity between each pair of networks generated by the BA model under different edge numbersm ∈{2,3,4,5,6}added at each time step,where the similarity methods are DHC ,DSP ,DC and DM .All results are based on an average of 100 realizations.
图5 给出了4 种由模型生成的人工合成网络上的进一步研究,对比了提出的基于高阶信息的网络比较方法与其他基线方法在网络相似性方面的表现.这4 种网络分别是K-regular 网络、WSC (通过1%重连边的K-regular 网络生成得到)、WSK(通过10%重连边的K-regular 网络生成得到)和BA 网络(每一步的加边数m=5),其中网络规模统一设置为N=1000 ,|E|=5000,平均度为10.由4 种网络的生成方式可知,K-regular 网络与其他3 种网络的相似性由高到低分别是WSC,WSK和BA,而本文提出的基于高阶信息的方法DHC结果符合这一结论.此外,DHC在比较不同模型生成的网络相似性方面表现出明显的效果差异,并且具有较小的误差范围;而DSP方法在K-regular 网络和WSC (WSK)、K-regular 网络和BA 网络比较中结果非常相近,表明该方法不能有效区分这些网络之间的相似性;DC方法在4 种网络比较上大体趋势上正确,但总体效果不够明显;DM则在Kregular 网络和WSC 网络以及K-regular 网络和WSK 网络比较中得出的相似性与实际情况相反,且实验结果存在较大的误差和波动,缺乏稳定性.
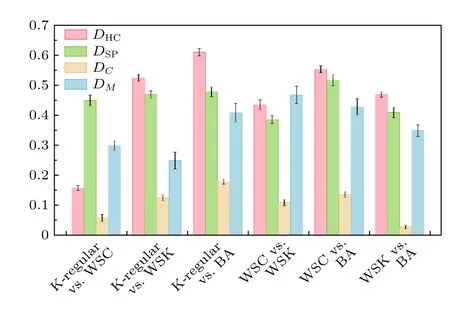
图5 分别使用 DHC ,DSP ,DC 和 DM 这4 种方法对4 种人工合成网络(K-regular,WSC,WSK 和BA)进行相互比较.所有的结果均基于100 次实验的平均值Fig.5.Comparison of the four synthetic networks,i.e.,Kregular,WSC,WSK,and BA,by using four methods of DHC,DSP ,DC and DM .All results are based on an average of 100 realizations.
3.2 真实网络比较
进一步在来自多个领域的12 个真实网络上评估了基于高阶信息的网络比较方法的有效性.这12 个真实数据集的具体描述如下: Chesapeake网络是美国河口切萨皮克湾的中盐营养网络,节点表示一组生物体,例如浮游植物或纤毛虫,边表示碳交换;Windsurfers 网络描述了1986 年秋季南加州风帆冲浪者之间的人际交往网络;Contiguous网络描述了美国的48 个相邻州和哥伦比亚特区,边表示两个州共享边界;Jazz 网络是爵士音乐家之间的合作网络;Infectious 网络是2009 年在都柏林科学展览馆举办的“INFECTIOUS: STAY AWAY”展览期间的一个面对面的接触网络;Yeast 和Metabolic 网络分别是蛋白质相互作用网络和线虫的代谢网络;Rovira 网络是位于西班牙加泰罗尼亚南部塔拉戈纳的Rovira i Virgili 大学的一个电子邮件通信网络;Petsterc 和Petster 网络描述了网站用户之间的友谊和家庭联系网络;Irvine 网络是加州大学Irvine 分校学生在线社区用户之间的消息传递网络;Pgp 网络是一种基于Pretty Good Privacy (Pgp)算法的用户交互网络.表 1 展示了这些数据集的全部拓扑结构信息,包括了节点数N、边数 (|E|)、平均度 (Ad)、平均路径长度 (Avl)、网络密度 (Ld)、聚类系数 (C) 和直径 (d) .

表1 真实网络的拓扑结构性质,其中N 为节点数,|E| 为边数,Ad 为平均度,Avl 为平均路径长度,Ld 为网络密度,C 为聚类系数,d 为直径Table 1. Topology properties of the real networks,where N is the number of nodes,|E| is the number of edges,Ad is the average degree,Avl is the average path length,Ld is the network link density,and C is the clustering coefficient,and d is the diameter.
图6 给出了12 个真实网络与对应的零模型之间的相似性.对于一个特定的网络,本文考虑了3 种不同的k阶零模型,分别记作Dk1.0 ,Dk2.0 和Dk2.5[8].其中,零模型的k值表示网络拓扑结构保留的程度.具体来说,当k=1.0 时,生成的网络保留了原始网络的度序列;当k= 2.0 时,在重连过程中保持了度序列和度相关性属性不变;当k=2.5时,则保留了原始网络的聚类谱属性.也就是说,k越大保留的原始网络的性质越多,即零模型与原始网络越相近.如图 6 所示,本文基于高阶信息的网络比较方法DHC在不同的网络上比较了原始网络与其零模型的相似性,结果表明随着k值的增加,真实网络与其随机化网络之间的相似性趋向于变大,即k越大表明随机化后的网络与原始网络共享的拓扑属性越多.这说明本文的方法能够很好地区分原始网络和零模型之间的不同.
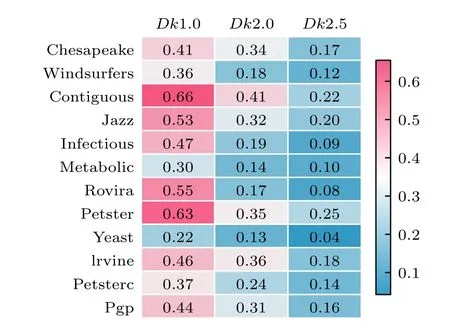
图6 真实网络与其零模型生成的网络相似性.考虑了具有不同k 值(1.0,2.0 和2.5)的 Dk 零模型,图中的值表示DHC 的值的大小.所有的结果均基于100 次实验的平均值Fig.6.Similarity between real networks and their null-models.We considered the Dk null model with different values k (1.0,2.0,and 2.5),and the values in the figure indicate the value of DHC .All results are based on an average of 100 realizations.
图7 给出对真实网络以及经过扰动后的网络进行比较的过程.扰动的过程如下: 对于给定的网络,随机添加或删除一定比例的边f∈[-0.9,0.9],然后比较原网络与扰动后网络之间的相似性.其中,正值的f表示添加边的过程,负值的f表示删除边的过程.直观上来讲,网络扰动程度越大(|f|越大),原网络与扰动后网络的相似性就越小.实验结果显示DHC在删边和加边的过程中都能保持良好的上升趋势,即 |f| 越大,原网络与扰动后的网络相似性越小.相比之下,从图7 可以看出,DSP,DC和DM这3 种方法只在删边时能较好地反映网络结构变化,在添加边时效果欠佳.例如,在网络Chesapeake 上,随着 |f| 的增大,DSP,DC和DM的值变化都很小,也就是说在这3 种方法下,无论增加多少边,原网络与增边后的网络相差不大,这与事实不符.此外,在其他网络上,与DHC相比,这3 种方法都或多或少不能合理地表示出网络的相似性.主要原因在于,DM主要依赖于邻接矩阵和度矩阵,而忽略了高阶结构信息;DSP则无法同时考虑网络的全局结构特征和局部结构特征.综合来说,基于高阶信息的网络比较方法DHC在网络扰动中展现出良好的性能,能够更全面地反映网络的结构变化.
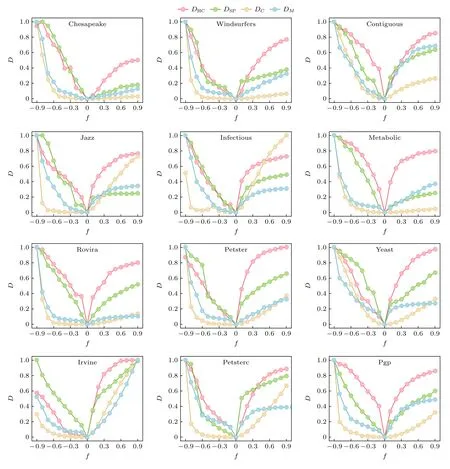
图7 原始真实网络和经过扰动后生成的网络之间的相似性,其中f 的负值对应于给定比例的边的随机删除过程,正值表示随机增边的过程.所有的结果均基于100 次实验的平均值.Fig.7.Similarity between the original real network and the network after perturbation,where negative values of f correspond to the deletion of |f| fraction of edges and positive values of f indicate the addition of f fraction of edges.All results are based on an average of 100 realizations.
4 总结与展望
本文提出了一种利用基于高阶信息的网络相似性比较方法DHC,来弥补现有网络相似性比较算法的不足.具体而言,首先计算每个节点的高阶聚类系数分布和节点间距离分布,然后使用分布的Jensen-Shannon 散度来度量网络距离分布的异质性,从而得到不同网络之间的相似性.
DHC在不同人工合成网络(ER,WS,BA)上均展示了良好的性能,并在12 个具有不同拓扑性质的真实网络扰动上也保持了稳定性.此外,将该方法与网络比较领域内一些具有代表性的基线算法(DSP,DC,DM)分别在人工合成网络和真实网络上进行了性能对比,也取得了令人满意的结果.未来,我们也希望将其扩展到更多类型的网络,如有向网络[38]、超网络[39]和时序网络[40]等.
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
河北画报(2020年8期)2020-10-27 02:54:20
电子测试(2017年15期)2017-12-18 07:19:27
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
智能系统学报(2015年4期)2015-12-27 09:38:39
天津师范大学学报(自然科学版)(2015年2期)2015-03-11 18:46:50
电子设计工程(2015年6期)2015-02-27 12:04:53
