
基于高频数据PGARCH 模型参数估计
2024-02-13 13:35黄丽燕
合作经济与科技 2024年1期
□文/黄丽燕
(广州大学经济与统计学院 广东·广州)
[提要] 本文使用日内高频数据对PGARCH 模型进行估计:根据日内高频数据构造的波动率代表,探究PGARCH 波动率模型的拟极大似然估计(QMLE)及其渐近分布。模拟研究和实证分析表明:基于高频数据的QMLE 可以减小参数估计的方差,有效地提高估计效率。
引言
波动率作为衡量标的资产价格波动程度的指标,是金融学中的重要概念。准确衡量和预测波动率的大小一直是金融市场的一个热点问题。在传统经济学中,期权定价理论假设了波动率是一个常数,Engle(1982)提出的自回归条件异方差(ARCH)模型则打破了该假设。在此基础上,为了解决ARCH 模型参数限制多和估计困难的问题,Bollerslev(1986)提出了广义自回归条件方差(GARCH)模型。此后,越来越多的GARCH 族模型广泛应用于风险管理、资产配置和投资策略等方面。例如,毛春元和余家华(2013)基于TGARCH 模型对中国石油天然气集团公司股票收益率进行了风险度量。Coenraad 和Sven(2017)将GJR-GARCH 模型和EGARCH 模型应用于南非TOP40 指数的期权定价。Nugroho(2019)应用GARCH-M 模型对道琼工业指数的时变波动率进行了建模。本文中讨论的PGARCH 模型,既是对GARCH 模型在幂次项上的变形,也是由Hwang(2004)提出的PTGARCH(1,1)模型的一种特殊情况。PGARCH 模型增加了波动率的幂次项是一个待估参数的设定,具体模型如下:
其中,待估参数δ>0,ω>0,α>0,β>0。 rn表示某标的资产第n 天的日收益率。σn表示第n 天的波动率,用于衡量资产波动大小,是一个非负的不可观测的变量。{zn}是一组期望为0、方差为1 的独立同分布的随机序列,且zn独立于σs(s<n)。
随着互联网技术的快速发展,高频数据在金融业和其他领域有着广泛的应用。为了提高参数估计精度,Visser(2011)利用高频数据来研究基于波动率代表的GARCH 模型的拟极大似然估计(QMLE),这为如何使用日内高频数据对波动率建模提供了新途径。Fan(2017)将日内数据植入周期GARCH 模型用于季节性波动研究和建模。Podobnik(2004)使用一分钟频率的高频数据来对ARCH-GARCH 模型建模。基于上述研究,本文将运用高频数据来构造波动率代表从而对PGARCH 模型进行QMLE 估计,同时探究参数估计的精度是否有所提升。
一、PGARCH 模型分析
(一)尺度模型。日频的PGARCH 模型是一个离散的随机模型,记录了每日的波动率和收益率数据。为了植入高频数据,需要建立一个连续的日内收益过程,参考Visser(2011)构建尺度模型:首先将交易日的交易时间单位化到区间[0,1]上,u 记为交易时间,u∈[0,1];接着把模型(1)中的离散日收益过程拓展为连续的日内收益过程Rn(u),记录每天的日内收益率;从模型(1)、模型(2),得到以下尺度模型:
可以看出,整合了高频信息的尺度模型(3)~(4)保留了日频PGARCH 模型(1)~(2)相似的结构形式,并且当u=1,Rn(1)=rn,Zn(1)=zn,尺度模型即转化为了日频模型(1)~(2)。Zn(u)依然是期望为0 的、方差为1 的独立同分布的随机变量,并独立于σs(s<n)。
(二)波动率代表。为了更好地估计参数,需要进一步加工日内高频数据。一种可行的方法是引入波动率代表。波动率代表是关于日内高频数据的一元函数,常见的波动率代表有已实现波动率和日内价格极差。一般来说,波动率代表是非负的且满足正齐性,即存在非零常数α 和日内收益率Rn(u)满足:
考虑到每个交易日的波动率是唯一确定的,可以视为常数,则由波动率代表的正齐性及尺度模型(3)和模型(4)得:
那么,整合了高频信息的波动率代表模型可以写为:
其中,μ>0,Z*n是经过标准化的独立同分布的随机序列,E(Z*2n)=1。比较模型(1)~(2)和模型(8)~(9),二者有着相似的结构形式。前者恰好是后者的一个特例,当Hn=|rn|时,模型(8)~(9)可以写成模型(1)~(2)的形式。前者的待估参数为θ=(δ,ω,α,β)′,后者的待估参数为θ*=(δ*,ω*,α*,β*)′ ,二者之间有以下数量关系:
二、参数估计
(一)拟极大似然估计。在进行模型(8)~(9)的估计前,记其参数真值为θ*0=(δ*0,ω*0,α*0,β*0)′ 。参考Pan(2008)和Visser(2011),对模型(8)~(9)采用拟极大似然估计,得到的拟条件对数似然函数及估计量(QLME)分别如下:
根据Pan(2008),为了证明QMLE 估计具有一致性和渐近正态性,需要做出以下基本假设:
1、Z*n服从非退化的对称分布,且存在某些△>0 使得E|Zn|△<+∞和对于任何的μ>0 有
2、参数空间Θ 是R4上的紧凑子集,θ*是Θ 的内点。对于所有的θ*∈Θ,都有李雅普诺夫指数γ(θ*)<0。
3、E(Z*2n)=1,且EZ*4n<∞。
由此可得θ^*的渐近分布:
进一步计算似然函数对待估参数的一阶偏导和二阶偏导:
由于Z*n与σ*n独立,E(Z*2n)=1,结合式(8),矩阵A0和B0内的元素为:
从而,渐近方差阵∑*=A-10B0A-10=Var(Z*2n)G(θ*0)-1。计算矩阵G-1中需要的参数偏导:
记参数θ^*=(δ^*,ω^*,α^*,β^*)′的渐近方差为(σ*2δ,σ*2ω,σ*2α,σ*2β,)′,那么模型(3)~(4)的参数θ^=(δ^,ω^,α^,β^)′的渐近分布分别为:
(二)日频参数θ=(δ,ω,α,β)′的估计。由QMLE 方法估计得到PGARCH 模型参数的估计值θ^*=(δ^*,ω^*,α^*,β^*)′,结合公式(10),即可得到θ的估计。此时,需要计算μ。由等式σ*n=σnμ 可得μ 的一个估计量:
使用不同的波动率代表,估计得到的参数精度是有所差异的。针对这种情况,Visser(2011)提供了一个估计效率的判别策略:估计方法的好坏由模型的残差项Z*2n决定,当残差项方差越小,参数估计的方差也越小,估计越有效。而Z*2n方差大小与MH 值的大小成正比关系。
考虑到σ*n和Z*n的独立性,则有:
显然,c=E(σ4n)/[E(σ2n)]2是一个常数,当我们通过乘以常数c 并省略1 来变换方差方程(24)时,我们可以如下导出MH统计量:
由于式(24)和式(26)成正比关系,寻找参数的渐近方差最小的问题就就转换为最小的统计量MH 问题。此时,MH 值越小,估计精度越高,估计越有效。
三、模拟研究
在本节中,通过模拟研究来检验该方法的实用性:首先对PGARCH 模型进行建模,接着对该模型采用QMLE 估计,最后将估计得到的参数结果分别从偏差(Bias)、标准差(SD)和MH统计量的均值(Mean.MH)的角度来评估QMLE 估计的效果。上述实验重复1,000 次。为了达到模拟的效果,需要模拟日内的标准化随机过程Zn(u),这里使用平稳的Ornstein-Uhlenbeck过程建模:
其中,设置初值Rn(0)=0,日频的PGARCH 模型则对应波动率代表Hn=|rn|。在模拟中,样本量分别设置为500 天、1,000天和1,500 天。于是在一次模拟中MH 的估计值如下:
模拟结果展示在表1。从表1 可以看出,在同一样本量下,与|rn|相比,通过高频的波动率代表RV 估计得到的参数偏差和标准差明显变小,但采用不同的高频RV 估计得到的参数偏差和标准差差异不大,无明显变化规律。比较不同的Mean.MH,通过RV 计算的Mean.MH 值也都比|rn|小。而随着样本量的增大,相同高频的RV 估计的参数偏差和标准差也逐渐减小,这符合一致性和渐近正态性的性质,MH 均值的减小也说明随着样本量的增加估计精度提高。表1 中,样本量N=500 时,Mean.MH 最小值出现在RV10 的情况下,这说明此时的估计最有效。表1 中样本量N=1000 时,Mean.MH 最小值出现在RV5 的情况下,这说明此时的估计最有效。参数估计的标准差最小时,与之对应的Mean.MH 值也最小,说明上一节讨论的最优波动率代表评判标准是合理的。综合来看,引入的高频信息并不是越多估计效果越好,但引入了高频信息的已实现波动率(RV)比日频信息的|rn|的估计效果好,高频数据的使用使得PGARCH模型的估计精度有所提高。(表1)
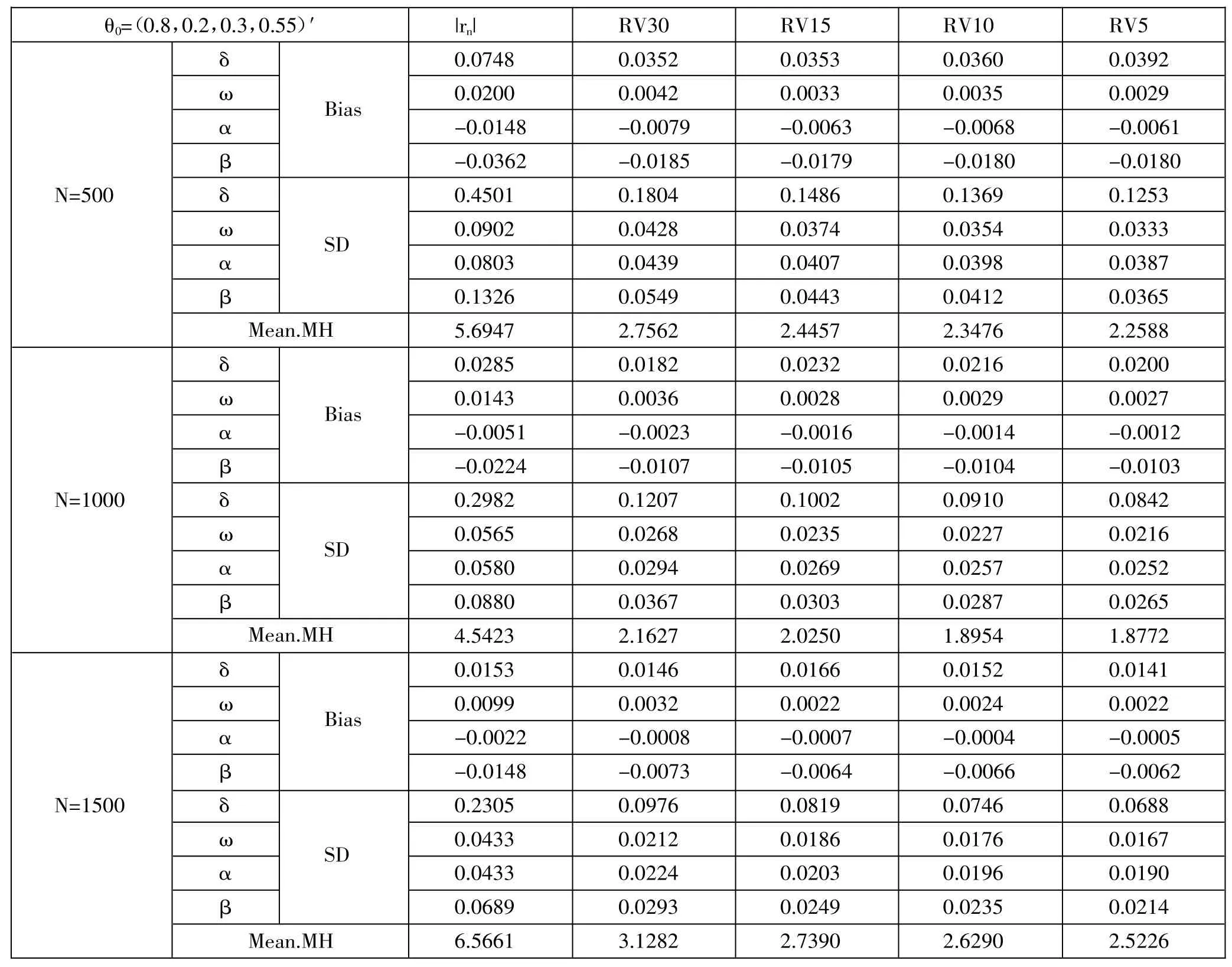
表1 参数估计的偏差、标准差及MH 均值一览表
四、实证分析
在本节中,将上述方法应用到实例,数据源是2008 年4 月28 日到2013 年6 月23 日的沪深300 指数。数据包含1 分钟间隔的收盘价格信息,每天共241 个观测值,一共包含1,272个交易日。记价格序列{Pn(u),u∈[0,1],n=1,2,…,1272},定义第n 天u 时刻的日内对数收益率为:
应用QMLE 方法,采用不同频率的已实现波动率对PGARCH 的估计结果如表2 所示。表2 展示了由不同频率的RV 和|rn|估计得到的参数值和残差项方差。由表2 可知,残差项方差最小的结果是基于RV15 的结果。根据表2,对比基于|rn|和基于RV15 的拟合得到的PGARCH 模型。(表2)
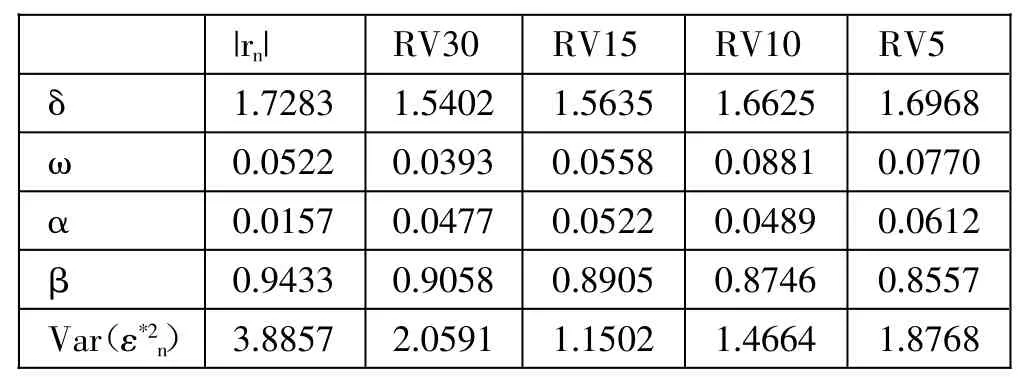
表2 基于不同波动率代表的PGARCH 模型的参数估计一览表
波动率代表为日收益率|rn|时,拟合的PGARCH 模型为:
波动率代表为15 分钟收益率时,拟合的PGARCH 模型为:
图1刻画了基于|rn|估计的波动率和基于RV15 估算的波动率代表的时序图。可以看出,二者的走势相同,整体上15 分钟的波动率比日频的波动率更小,但在峰值二者相差不大。这说明涵盖了高频信息的波动率既能敏锐地捕捉波动率的急剧变化,也能稳定地刻画出波动率相对平缓时期的特征。(图1)
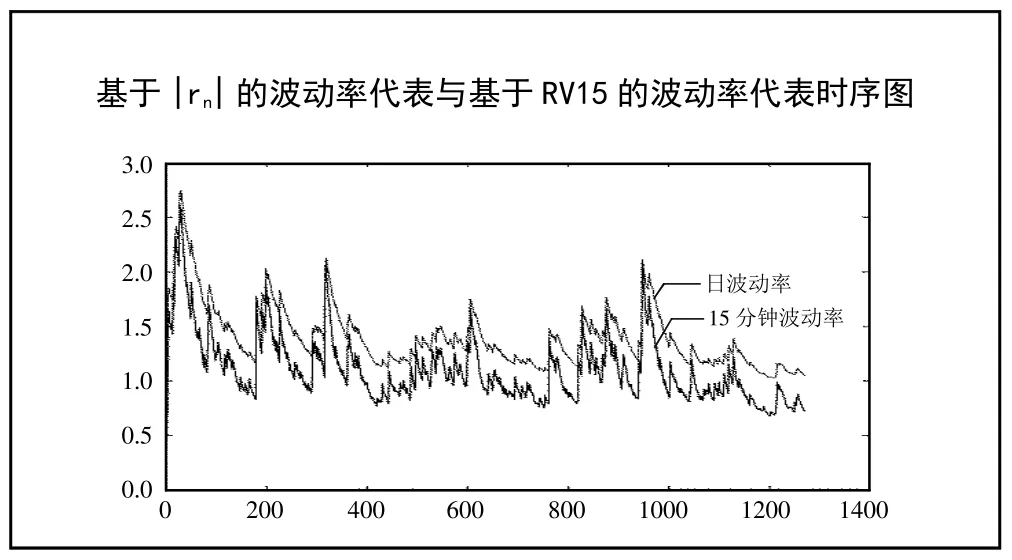
图1 基于|rn|的波动率代表与基于RV15 的波动率代表时序图
结语
在本文中,我们通过波动率代表将高频数据嵌入日频的PGARCH 模型,并对模型进行QMLE 估计,给出估计参数的渐近分布。模拟研究和实证分析证明,引入高频信息有助于提高PGARCH 模型的估计精度。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
内蒙古统计(2021年4期)2021-12-06
当代医药论丛(2021年3期)2021-03-17
测控技术(2018年4期)2018-11-25
上海精神医学(2017年5期)2017-11-29
统计与决策(2017年2期)2017-03-20
数学物理学报(2016年5期)2016-08-24
系统工程与电子技术(2016年2期)2016-04-16
赤峰学院学报·自然科学版(2015年15期)2015-03-21
医学理论与实践(2012年4期)2012-12-09
