
基于高光谱成像技术的涌泉蜜桔糖度最优检测位置
2024-02-05 09:06:42刘爱伦邹吉平卢英俊刘燕德
中国光学 2024年1期
李 斌,万 霞,刘爱伦,邹吉平,卢英俊,姚 迟,刘燕德
(华东交通大学 智能机电装备创新研究院 水果智能光电检测技术与设备国家与地方联合工程研究中心,南昌 330013)
1 引言
涌泉蜜桔产于浙江东南沿海地带,以果肉细嫩、皮薄易剥、无核、甜度高等特点深受人们喜爱,更是有“天下一奇,吃桔带皮”的美誉。浙江临海市常年种植蜜桔面积可达20 万亩,蜜桔年产量近30 万吨,涌泉作为临海蜜桔的核心产区,年产量约占其整个市蜜桔总产量的1/4。涌泉蜜桔曾多次获得省部级优秀奖、浙江省名牌产品和中国名牌产品称号。随着物流和电商行业的兴起,涌泉蜜桔也被销往全国各地[1]。近年来,随着涌泉蜜桔产量的增加以及人们消费水平的逐渐提高,人们对蜜桔的品质方面的要求越来越严格。蜜桔含糖量的高低直接影响其口感和价格,因此,糖度是衡量其品质的一个重要指标[2-3]。此外,在对采摘后的蜜桔进行无损检测和分级时,其糖度也是重要参考指标之一。如何快速、准确和稳定地对其糖度进行检测和分级是当前蜜桔产业待解决的问题之一。在蜜桔的生长过程中,受生长环境的影响,其不同部位的糖度分布不同,因此在检测过程中,若不考虑检测位置则会对蜜桔糖度无损检测产生较大的影响,导致蜜桔的品质分级不够准确,所以有必要寻找出蜜桔糖度的最优检测位置,从而提高蜜桔糖度的无损检测精度[4-5]。
近年来,高光谱成像技术作为新一代光电检测技术,它集成像技术与光谱技术两者于一身,可以同时获取被检测对象的光谱和空间信息[6-7]。与其他研究方法相比,利用高光谱成像技术可以更全面、更深入且更具体地了解被检测对象[8-11]。该技术在农产品品质检测领域有着很大的潜力,现如今已被广泛应用于柑橘[12]、苹果[13]、猕猴桃[14]、葡萄[15]、茶叶[16]等农产品的内部品质检测。Liu[17]等在赤道部位建立了脐橙可溶性固化物(Soluble Solids Content,SSC)含量的预测模型,其预测集相关系数Rp 为0.90。许丽佳[14]等利用高光谱成像技术对猕猴桃糖度进行无损检测。选择猕猴桃赤道位置进行糖度检测,其最优预测模型的预测集相关系数Rp 为0.839。Yang[18]等采用传统的破坏性方法,将番茄切块榨汁后测量其SSC 含量,经过高度和重量两个生理特征进行补偿后的最优SSC 预测模型的Rp 为0.91。以上研究并未考虑糖度检测位置对模型精度的影响,故所建立模型的精度不高。与此同时,也有部分学者就水果不同部位的糖度预测模型进行了研究。介邓飞[2]等利用高光谱技术对柑橘花萼、果梗和赤道部位进行检测,建立了不同部位糖度的预测模型,研究发现花萼部位对应的糖度预测模型效果最好,其预测集相关系数达到0.950。袁琳[19]等利用近红外反射光谱对网纹瓜的不同部位进行光谱采集,并与对应部位的糖度结合建立了三个局部和全局PLSR 预测模型,研究发现全局模型预测效果最佳,其预测集相关系数Rp 为0.889 5。以上两位学者均采用PLSR 模型作为预测模型,未进行多种模型对比分析。
考虑到目前针对涌泉蜜桔不同部位的糖度预测模型的研究鲜有报道。本文利用高光谱成像技术对涌泉蜜桔糖度最优检测位置和最优糖度预测模型进行研究,分别测定蜜桔花萼、赤道、果茎3 个部位的糖度,并结合这3 个部位相应的光谱信息建立其局部糖度预测模型。在此基础上,将3 个部位的平均光谱与平均糖度信息相结合,建立其全局模型。采用4 种预处理方式(SNV、MSC、Baseline、SG)和两种建模方法(PLSR、LSSVM),分析比较找出蜜桔不同部位的最佳预处理方式。然后,通过特征波长筛选(CARS、UVE)进一步优化模型,从而提高其预测精度。最后,比较蜜桔各部位优化后的最佳糖度预测模型,找出蜜桔糖度的最优检测位置和预测模型。该研究结果不仅可以为蜜桔分级处理提供理论依据,而且可以为涌泉蜜桔检测分级的加工设备研制提供一定的研究基础。
2 实验材料与方法
2.1 实验材料
本研究选用涌泉蜜桔作为实验样本,购买于南昌水果市场,所选涌泉蜜桔大小接近,形状规则且外观完好。将买来的涌泉蜜桔进行检查和筛选,选取120 个涌泉蜜桔洗净并逐个编号,在室温为20 °C,相对湿度为60%的环境下储存24 小时后采集蜜桔的光谱数据,避免温度对结果的影响。蜜桔花萼、赤道和果茎图像如图1 所示。

图1 涌泉蜜桔不同部位图像Fig.1 Images of different parts of Yongquan honey oranges
2.2 实验装置与光谱数据采集
本次实验装置为高光谱成像光谱仪,装置示意图如图2 所示。该系统主要由相机(C8484-05G 型,Hamamastu,日本)、光谱仪(ImSpector V10E 型,Specim,芬兰)、镜头、卤素灯(DECOSTAR51 MR16 型,OSRAM,德国)、位移平台和计算机组成。本研究采集的光谱波长范围为390.2~981.3 nm,分辨率为3.3 nm。光谱采集装置需要提前预热30 min,在实验正式开始前,还要对试验装置的各项参数进行调整,本次实验曝光时间设置为6 ms,检测速度为20 mm/s。每个实验样品均需采集花萼、果茎和赤道部位的光谱数据。
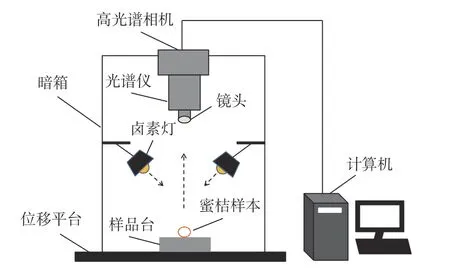
图2 高光谱成像装置示意图Fig.2 Schematic diagram of the hyperspectral imaging device
由于高光谱相机存在暗电流和光源亮度分布不均匀现象,导致采集到的蜜桔不同部位的高光谱图像易受其影响,因此,在对光谱数据进行处理之前,需要对其原始光谱图像的反射率进行黑白校正。首先将镜头遮住,进行扫描,将得到的全黑图像作为黑色参考图像,再取下镜头遮盖物,对白色校准板进行扫描得到白色参考图像。利用两种参考图像进行校准,校准公式如下:
式中:Ir为原始光谱图像;Iw为全白参考光谱图像;Id为全黑参考光谱图像;I为校准后的光谱图像。利用SpectraVIEW 软件对蜜桔的高光谱图像进行黑白校正,然后通过ENVI4.5 软件提取蜜桔不同部位的光谱数据,在蜜桔不同部位选择一个矩形感兴趣区域(ROI),计算出ROI 区域的平均光谱值。
2.3 不同部位糖度的测量
将蜜桔的糖度值作为预测模型的真值,对蜜桔样本采集光谱后,进行糖度理化指标的测定。通过温度补偿糖度计(型号PAL-1,Atago Co,Tokyo,Japan)测量其糖度值。该仪器的糖度测量范围为0-53%OBrix。使用前用蒸馏水对糖度计进行零点校正。在蜜桔不同部位上切取果肉进行榨汁,将果汁滴入糖度计中进行测量,每测完一个部位后都要用蒸馏水进行清洗,重复3 次测量取平均值,作为该部位的最终糖度值,取3 个部位糖度值的均值作为全局的糖度值。
2.4 光谱预处理
在采集原始光谱信息时,易受到外界干扰,从而出现随机噪声和表面散射等现象,导致提取的光谱数据中存在许多干扰信息,对模型的精度和稳定性有显著影响[20]。对光谱进行预处理能够消除这些不利影响,从而提高其信噪比。本研究中采用了SNV、MSC、Baseline 和SG 四种预处理方式,针对蜜桔不同部位的光谱信息挑选出最适合的预处理方式。
2.5 特长波长筛选
由于全光谱波长数据量很大,并且存在着大量的无信息波长,导致数据处理极其缓慢。因此,有必要通过算法提取出最具有代表性的波长,以构建更具稳定性和鲁棒性的糖度含量预测模型,并简化建模过程。本研究采用的波长筛选方式为竞争性自适应重加权算法(CARS)和无信息变量消除法(UVE)。
其中,CARS 算法主要是利用自适应重加权采样技术和指数衰减函数从构建的PLS(Partial Least Squares)子集模型中选出回归系数绝对值较大的变量,然后通过交叉验证选取RMSECV(Root Mean Square Error of Cross Validation)最小的子集中的变量作为特征波长[21-22]。UVE 是一种基于PLS 回归系数稳定性分析的变量选择方法。它用于消除无用信息变量或冗余光谱变量[23]。其基本思想是将偏最小二乘回归系数作为波长重要性的衡量指标。
2.6 预测模型的建立及其评价
利用Kennard-Stone(KS)方法将120 个涌泉蜜桔样本进行分类,其中校正集为90 个,预测集为30 个。分别建立蜜桔花萼、果茎、赤道和全局的PLSR 和LSSVM 模型。偏最小二乘回归(PLSR)是一种线性回归方法。该方法在普通多元回归的基础上融合了主成分分析和典型相关的分析方法,可解决变量之间的多重共线性问题[21]。最小二乘支持向量机(LSSVM)是一种非线性回归算法。该算法解决了经典SVM(Support Vector Machines)中复杂的二次优化问题,计算的复杂程度有所降低。非线性LSSVM 预测模型对光谱和SSC 中可能存在的非线性扰动有较好的鲁棒性[20]。模型性能主要是通过建模集相关系数Rc、预测集相关系数Rp、建模集均方根误差RMSEC 和预测集均方根误差RMSEP 4 个指标来评价,其中Rp 和Rc 越接近1 且RMSEC 和RMSEP 越小,则表明该模型既精度高又稳定[24]。
3 结果与分析
3.1 涌泉蜜桔不同部位的光谱分析
本研究选择390.2~981.3 nm 范围内的光谱进行分析。取蜜桔3 个局部位置光谱的平均值作为其全局光谱。蜜桔赤道、果茎、花萼和全局的原始光谱如图3(a)(彩图见期刊电子版)所示。由图3(a)可以看出所有光谱曲线的变化趋势十分相似,在650~900 nm 波段范围内,吸收峰不太明显,波峰和波谷之间没有剧烈起伏。为了更加直观地观察和比较蜜桔不同部位的光谱信息,计算得到蜜桔不同部位的平均光谱曲线,如图3(b)(彩图见期刊电子版)所示。由图3(b)可知,4 条光谱的光谱强度之间存在明显差异,赤道位置的反射率高于其他部位。这可能与光的穿透深度和蜜桔内部糖度分布不均匀有关。从蜜桔赤道到花萼再到果茎,果皮厚度依次增大,光的穿透深度逐渐减小。同时这也表明光谱的检测位置会对光谱值产生影响。这一结论与先前研究者在对哈密瓜、西瓜和苹果不同部位进行光谱分析时给出的结论一致[20]。

图3 涌泉蜜桔光谱曲线。(a)不同部位的原始光谱曲线;(b)不同部位的平均光谱曲线Fig.3 Spectral curves of Yongquan honey orange.(a) Original spectral curves of different parts;(b) average spectral curves of different parts
3.2 涌泉蜜桔不同部位的糖度测量结果
120 个涌泉蜜桔样本不同部位糖度值的分布情况如表1 所示。由表1 可知,花萼、果茎、赤道、全局的糖度平均值分别为15.2、14.2、14.5 和14.6OBrix,标准差分别为1.39、1.52、1.37和1.34OBrix。其中,蜜桔花萼部位糖度值大于果茎和赤道部位的糖度值,果茎部位的糖度值最低,说明蜜桔内部糖度分布是不均匀的。这种现象可能是由于不同部位中各种糖(蔗糖、葡萄糖、果糖)的含量不同导致的[25]。

表1 涌泉蜜桔不同部位的糖度统计分析结果Tab.1 Statistical analysis of the sugar content of different parts of Yongquan honey orange
3.3 涌泉蜜桔不同部位的全变量模型比较
为了比较不同建模方法之间的模型性能,此次研究采用了PLSR 和LSSVM 两种建模方法分别建立了蜜桔花萼、果茎和赤道部位的局部糖度预测模。为了更进一步评估其局部模型的性能,同时建立一个全局糖度预测模型作为对比。采用SNV、MSC、Baseline 和SG 对光谱进行预处理。基于不同模型和预处理方法的局部糖度预测模型和全局糖度预测模型的建模效果如表2 和表3 所示。

表2 基于不同预处理方法的涌泉蜜桔糖度检测PLSR模型比较Tab.2 Comparison of PLSR models for detecting the sugar content of Yongquan honey orange based on different pretreatments
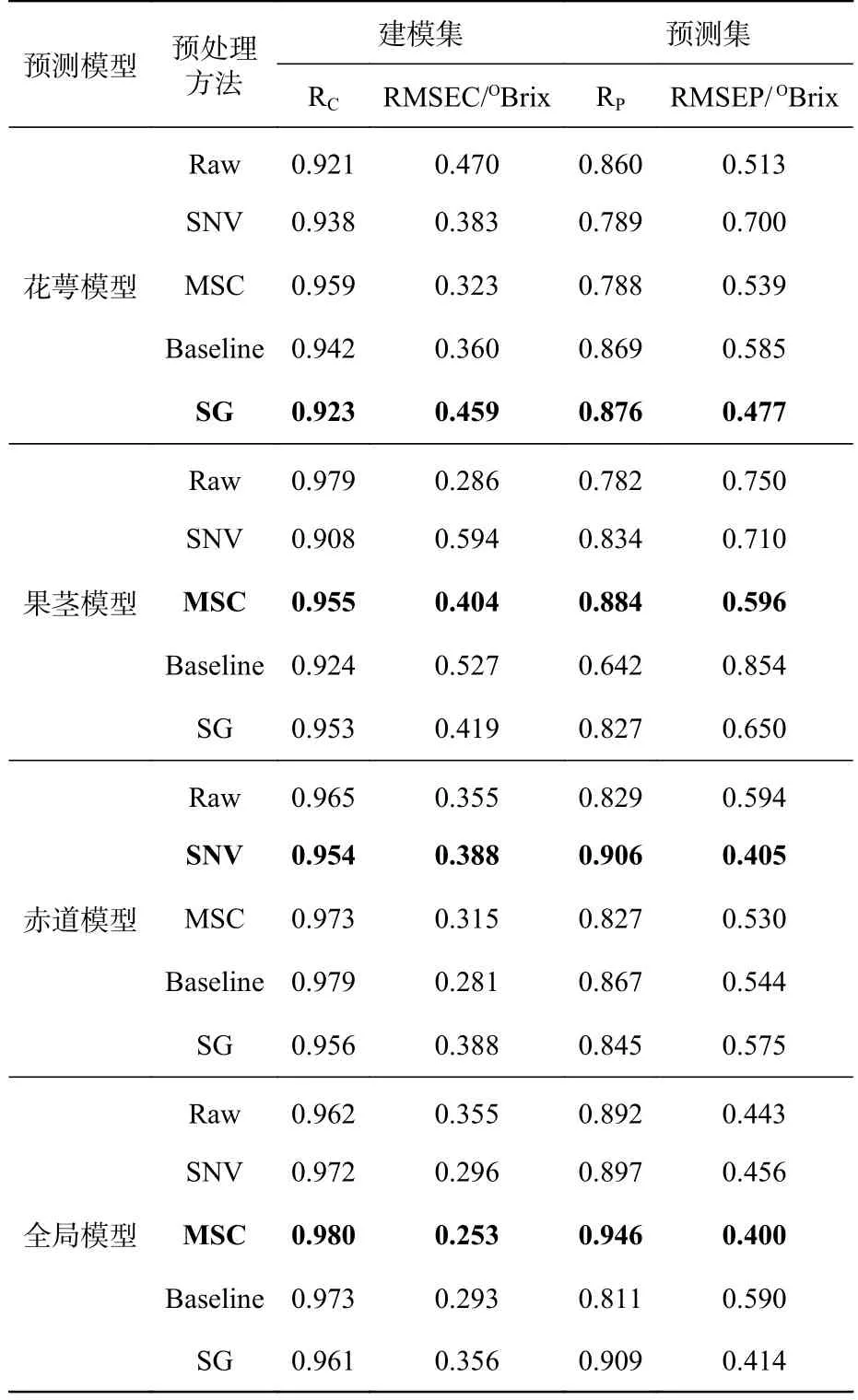
表3 基于不同预处理的涌泉蜜桔糖度LSSVM 模型比较Tab.3 Comparison of LSSVM models for detecting the sugar content of Yongquan honey orange based on different pretreatments
由表2 可知,对于花萼部位模型来说,SGPLSR 模型预测效果更佳,其模型Rp为0.898,RMSEP 为0.436OBrix。对于果茎部位模型来说,预测效果最好的模型是Baseline-PLSR 模型,其预测集相关系数Rp为0.913,RMSEP 为0.468OBrix,与花萼部位的模型相比,其预测效果更好。对于赤道部位,SNV-PLSR 模型的预测效果最好,预测集相关系数Rp为0.936,RMSEP 为0.37OBrix。比较花萼、果茎和赤道的最优PLSR模型可以发现,赤道部位最优模型的Rp最高,预测效果最好。为了更加全面地探索出涌泉蜜桔糖度的最优检测位置,将蜜桔花萼、果茎和赤道部位的光谱信息取平均值,并与其对应部位的平均糖度相结合,建立其全局模型。从全局PLSR模型分析结果看,经过MSC 预处理后的PLSR模型预测效果最好,其Rp为0.934,RMSEP 为0.435OBrix。其与赤道部位的SNV-PLSR 模型预测集的相关系数相近。表明两个模型的预测效果差不多。
基于不同预处理方式建立蜜桔不同部位和全局LSSVM 预测模型的预测结果如表3 所示。由表3 可知:对于蜜桔花萼部位,在其LSSVM 模型中,经SG 预处理后的模型最佳,其Rp为0.876,RMSEP 为0.477OBrix;对于蜜桔果茎部位模型来说,经MSC 预处理的LSSVM 模型预测效果最佳,其Rp为0.884,RMSEP 为0.596OBrix;对于蜜桔赤道部位的LSSVM 模型来说,最佳预处理方式为SNV,其最佳糖度预测模型的Rp为0.906,RMSEP 为0.405OBrix。与其他两个部位最佳预测模型相比,依旧是赤道部位预测模型的预测效果更佳。这可能是因为赤道位置比其他位置的日照时间长且温度高,使得该部位的糖度比较高。对全局的LSSVM 模型进行分析可知,MSC-LSSVM 模型是最优模型,其Rp为0.946,RMSEP 为0.400OBrix。
3.4 基于涌泉蜜桔不同部位特征变量的模型比较
由于全光谱中存在着大量冗余信息且波长之间存在相互干扰,数据量大导致处理速度缓慢且建模过程复杂。利用算法提取出包含更多有效信息的特征波长,可以降低光谱数据的维数,加快建模速度及提高模型精度。本文选择的特征波长算法有CARS 和UVE。
3.4.1 CARS 特征波长筛选
以蜜桔果茎部位为例,波长筛选过程和结果见图4 和图5(彩图见期刊电子版)。图4 为特征波长的选择流程,设置MC 采样次数为100。图4(a)表明随着采样次数的增加,选择波长变量数逐渐减少,减少速度为先快后慢。图4(b)表明,随着采样次数的增加,RMSECV 值先减小后增加,当采样次数为38 次时,RMSECV 达到最低值;当采样次数小于38时,RMSECV 值缓慢减小,表明原始光谱中所含的冗余信息被剔除;当采样次数大于38 次时,RMSECV 值开始上升,则表明光谱中有效特征波长被剔除,模型性能变差。因此,选择经过38 次采样得到的变量作为建立果茎部位糖度预测模型的特征变量[26]。根据3.3 的结论,在蜜桔果茎部位模型中,两种模型最佳预处理方法分别为Baseline 和MSC 预处理,利用CASR 算法对两种预处理后的光谱数据中的变量进行筛选,筛选后的特征波长位置和数量如图5 所示。分别筛选出32 和37 个特征变量,分别占全波段的18.9%和21.9%。

图4 CARS 果茎部位特征波长选择过程。(a)变量数变化;(b)交叉验证均方根变化;(c)回归系数变化Fig.4 Selecting process of the characteristic wavelength of the fruit stem part by CARS.(a) Changes in number of variables;(b) changes in the RMSECV;(c) changes in regression coefficient
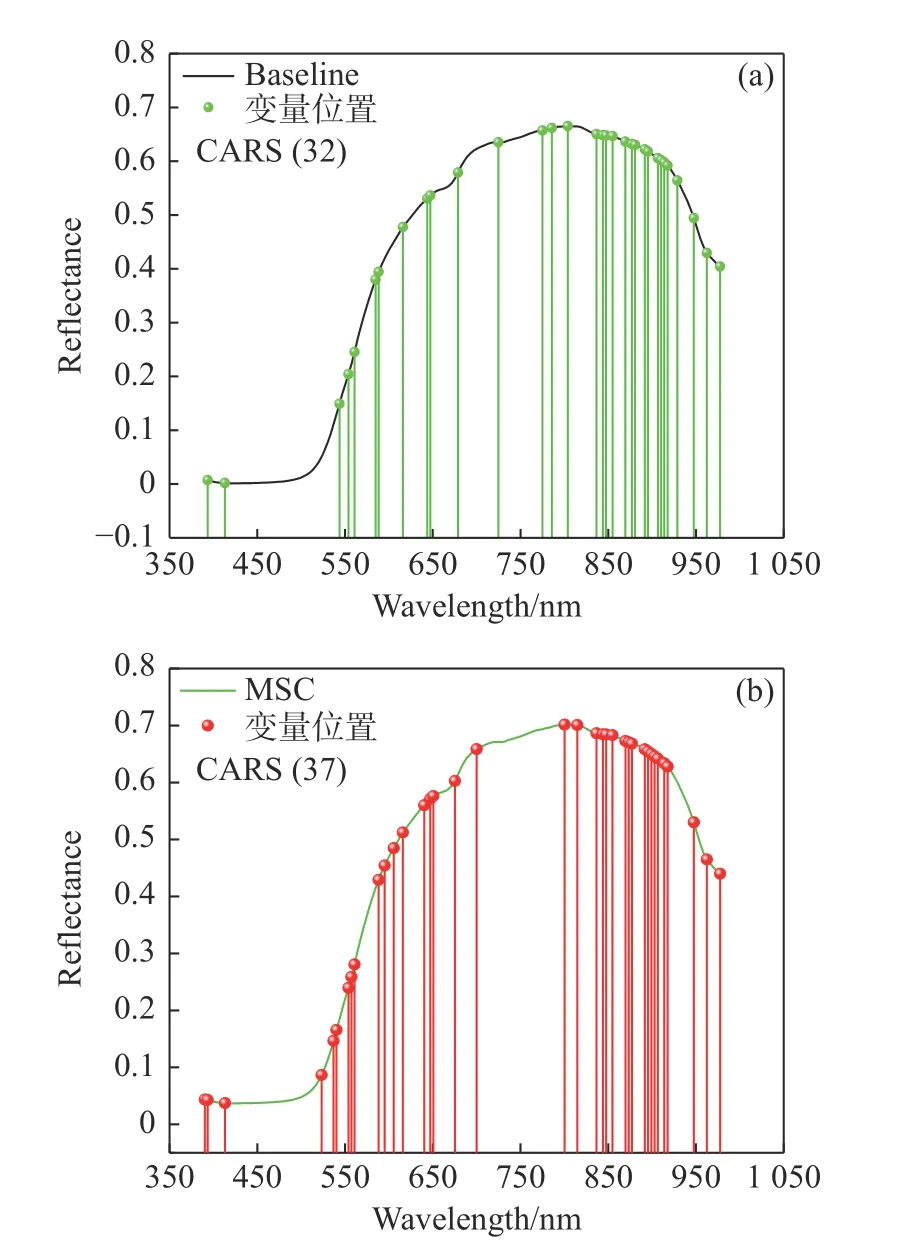
图5 两种预处理方法基于CARS 算法果茎部位特征波长位置图。(a)Baseline;(b)MSCFig.5 Location map of the characteristic wavelengths in the fruit stem part based on the CARS algorithm corresponding to the pretreatments (a) Baseline and(b) MSC
利用CARS 算法对蜜桔花萼部位、赤道部位和全局光谱数据进行特征波长筛选,波长筛选过程与果茎部位类似。根据3.3 结论可知,对于花萼部位、赤道部位和全局模型,最佳预处理方式分别为SG、SNV 和MSC。对预处理后的花萼部位光谱、赤道部位光谱和全局光谱分别进行特征波长筛选。筛选出的特征波长位置和数量如图6 所示。从图6 可以看出,不同部位对应的特征波长位置和数量均不相同。这表明不同部位糖度的光谱特征信息是不同的。分别筛选出了48、24 和34 个特征变量建立蜜桔糖度预测模型。它们分别占全波段的28.4%、14.2%和20%,大部分特征波长位于650~900 nm 之间。
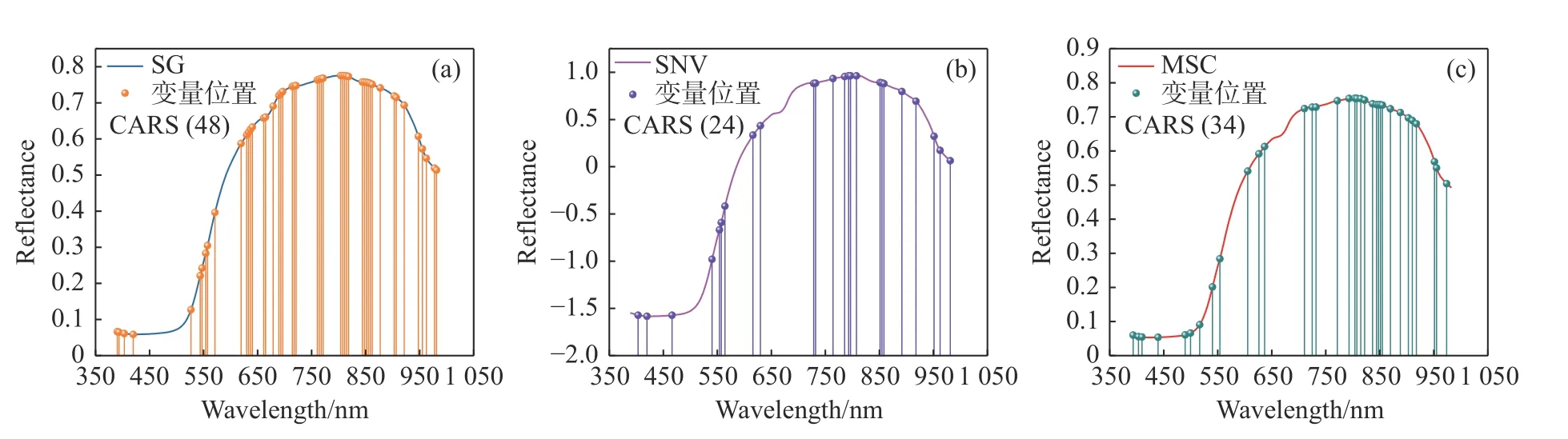
图6 各部位基于CARS 算法特征波长位置图。(a)花萼;(b)赤道;(c)全局Fig.6 Location maps of the characteristic wavelengths based on CARS algorithm.(a) Calyx;(b) equator and (c) global
3.4.2 UVE 特征波长筛选
以果茎部位特征波长筛选过程为例,图7(彩图见期刊电子版)为UVE 筛选后的稳定性值图。图中蓝竖线的左侧为169 个原始波长,右侧引入相同数量的随机变量。上下两条虚线分别代表最大和最小截止阈值。两截止阈值中间的变量需剔除,两线之外的变量则为特征变量。果茎部位的两个最优模型分别为Baseline-PLSR 和MSCLSSVM 模型。利用UVE 算法对果茎部位两个最优模型中的全变量进行筛选,筛选出的特征波长位置和数量如图8(彩图见期刊电子版)所示,由图8 可知,UVE 算法从果茎部位两个最佳模型的全变量中分别筛选出了41 个和69 个特征变量,分别占全波段的24.3%和40.8%。
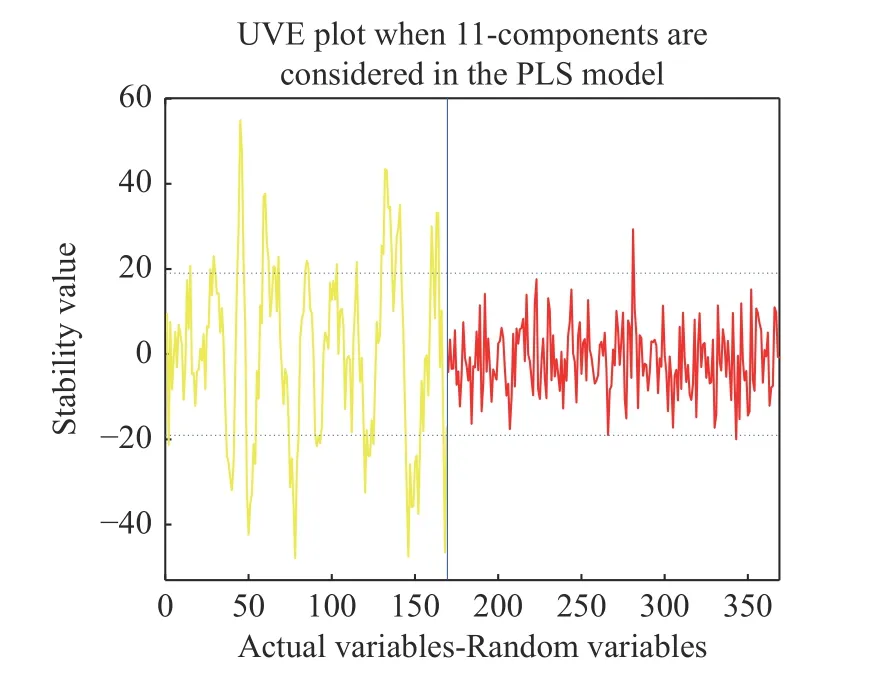
图7 UVE 筛选后果茎部位的稳定性值图Fig.7 Stability values of the fruit stem part after UVE screening

图8 两种预处理方法下,基于UVE 算法果茎部位特征波长位置图。(a)Baseline;(b)MSCFig.8 Location maps of characteristic wavelengths in the fruit stem part based on the UVE algorithm corresponding to (a)Baseline and (b) MSC
用同样的方法分别对蜜桔花萼部位、赤道部位和全局最佳模型中的全变量进行特征波长筛选。筛选后的特征波长位置和数量如图9(彩图见期刊电子版)所示。由图9 可知,利用UVE 算法进行特征波长筛选后,分别筛出了42、58 和29 个特征变量,分别占全波段的24.9%、34.3%和17.2%,大多数波长位于700~950 nm之间。

图9 基于UVE 算法特征波长位置图。(a)花萼;(b)赤道;(c)全局Fig.9 Location maps of the characteristic wavelengths of the UVE-based algorithm.(a) Calyx;(b) equator and (c) global
3.5 基于CARS 和UVE 筛选的不同部位特征波长的模型比较
根据3.4.1 中的特征波长筛选结果,分别建立蜜桔花萼、果茎、赤道和全局的PLSR 和LSSVM糖度预测模型,预测效果如表4 所示。由表4可知,进行特征波长筛选后,大部分模型的预测效果都有所提升。对于蜜桔花萼部位模型,SGCARS-PLSR 模型预测效果最佳,其Rp为0.918,RMSEP 为0.400OBrix;对于蜜桔果茎部位模型,Baseline-CARS-PLRS 模型预测效果最好,其Rp为0.922,RMSEP 为0.424OBrix;对于全局模型,其最优模型为MSC-CARS-LSSVM 模型,其Rp为0.955,RMSEP 为0.395OBrix。以上模型经过特征波长筛选后与之前模型相比,预测精度都有所提高。表明CASR 算法剔除了原始光谱中的干扰信息,基于筛选后的特征波长建立的模型预测效果更好。然而,对于蜜桔赤道部位模型在经过特征波长筛选后,其最佳模型为SNV-CARSPLSR 模型,其Rp为0.914,RMSEP 为0.400OBrix,与筛选前的SNV-PLSR 模型比较,其预测精度有所下降,预测集相关系数从0.936 下降到0.914。说明CARS 算法将蜜桔赤道部位光谱数据中跟糖度有关的信息剔除了。
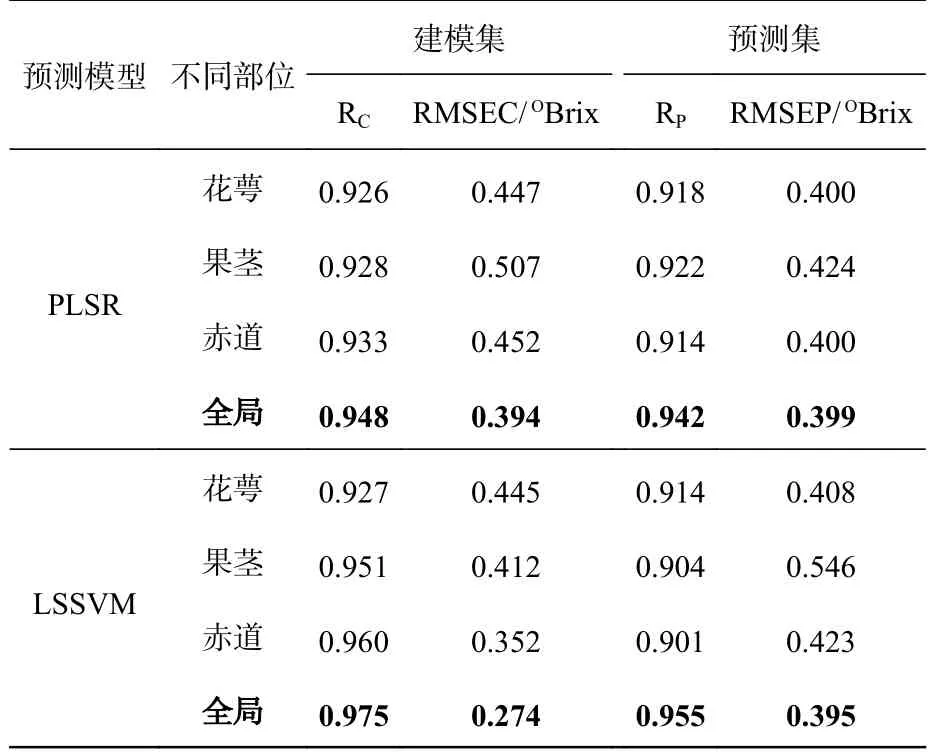
表4 基于CARS 特征波长筛选后蜜桔不同部位的PLSR和LSSVM 模型比较Tab.4 Comparison of PLSR and LSSVM models for different parts of honey oranges after CARS characteristic wavelengths screening
根据3.4.2 中的特征波长筛选结果,分别建立蜜桔花萼、果茎、赤道和全局的PLSR 和LSSVM糖度预测模型,预测结果如表5 所示。从表5 可以看出,对于花萼部位的两个最优模型来说,筛选后建立的模型精度都有一定程度的下降。这表明UVE 算法去除了与糖度有关的变量。对于果茎部位模型,筛选后的最佳预测模型为MSCUVE-LSSVM 模 型,其Rp为0.896,RMSEP 为0.575OBrix,与其筛选前的MSC-LSSVM 模型相比,预测精度有所上升,但是其PLSR 模型筛选后预测精度有所下降。相比于前面两个部位的模型,赤道部位和全局的最佳预测模型筛选前后的预测效果相差无几。表明UVE 算法没能有效的去除赤道和全局模型中的无效变量。由此可知,UVE 算法并不适合蜜桔糖度预测模型的优化。
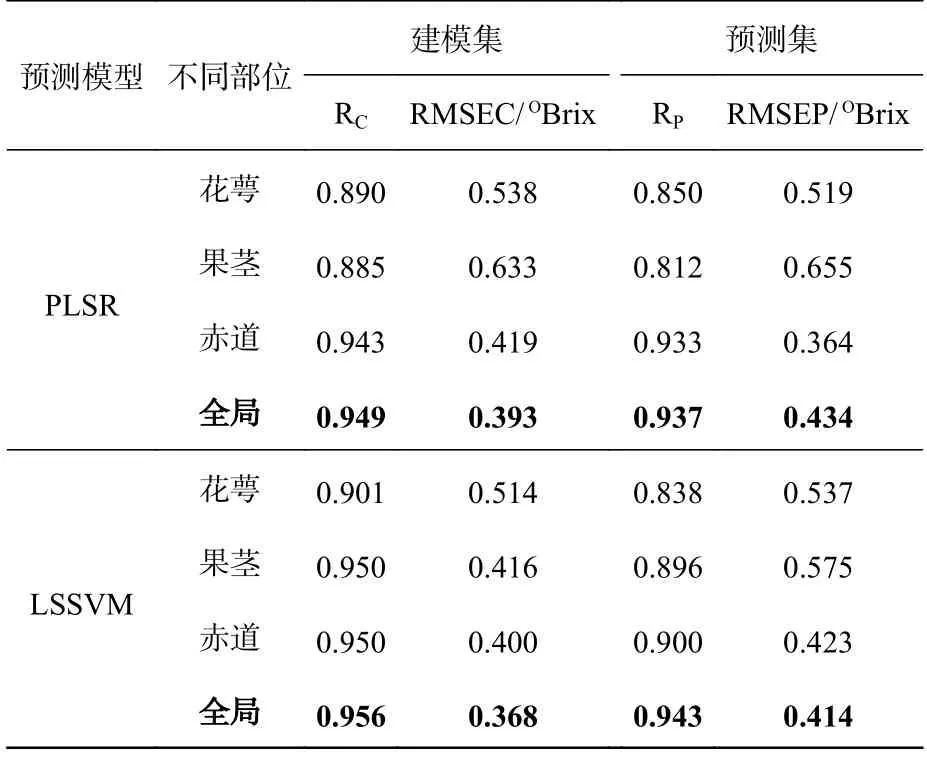
表5 基于UVE 特征波长筛选后蜜桔不同部位的PLSR和LSSVM 模型比较Tab.5 Comparison of PLSR and LSSVM models for different parts of honey oranges after UVE characteristic wavelengths screening
综合比较蜜桔花萼部位、果茎部位、赤道部位和全局的PLSR 模型和LSSVM 模型,对于PLSR模型,预测效果最好的是赤道SNV-PLSR 模型和全局MSC-CARS-PLSR 模型,两者对比可以发现全局模型预测效果更好。同样对于LSSVM 模型,最优模型是花萼部位SG-CARS-LSSVM 模型和全局MSC-CARS-LSSVM 模型,对比之下依旧是全局模型预测效果更好。图10(彩图见期刊电子版)是两个全局最优预测模型MSC-CARS-PLSR和MSC-CARS-LSSVM 对涌泉蜜桔糖度含量的预测结果。从图10 可知,MSC-CARS-LSSVM 模型中样本点比MSC-CARS-PLSR 模型中样本点更加均匀和集中分布在拟回归线周围,表明全局MSC-CARS-LSSVM 模型的预测效果更佳。综上所述,基于全局数据建立的非线性糖度预测模型更加稳定且预测更准确。
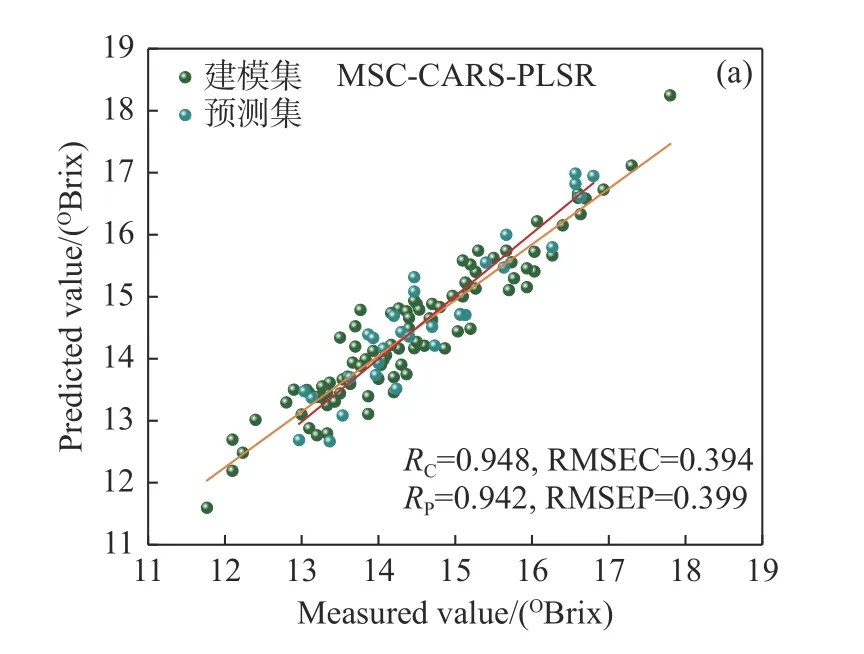
图10 涌泉蜜桔糖度含量预测模型(a)MSC-CARS-PLSR和(b)MSC-CARS-LSSVM 的散点图Fig.10 Scatter plots of the Yongquan honey oranges sugar content prediction models (a) MSC-CARSPLSR and (b) MSC-CARS-LSSVM
4 结论
为了得到涌泉蜜桔糖度最佳检测位置和最佳糖度预测模型,利用高光谱技术分别采集了涌泉蜜桔花萼、果茎、赤道3 个部位的光谱数据,并分别测定对应部位的糖度,然后,分析比较了蜜桔3 个局部和全局的糖度预测模型。采用4 种预处理方式(SNV、MSC、Baseline、SG)和两种建模方法(PLSR、LSSVM)进行建模。对比发现蜜桔不同部位所建的预测模型之间有较明显的差异,花萼部位的最优模型预测性能明显低于果茎和赤道部位的最优模型预测性能,赤道部位SNVPLSR 模型和全局MSC-LSSVM 模型对整个蜜桔糖度预测效果比较好,最佳模型的预测集相关系数Rp可达0.946。上述结果表明不同的预处理方法和建模方法对其糖度预测效果有影响。为了进一步提高模型的预测性能同时消除冗余变量,利用CARS 和UVE 算法对蜜桔3 个局部和全局的光谱数据进行特征波长筛选,并分别对筛选后的光谱数据建立PLSR 和LSSVM 模型。对用特征波长建立的模型进行对比分析后发现,最佳糖度预测模型为全局MSC-CARS-LSSVM 模型,其Rp为0.955,RMSEP 为0.395OBrix。其次是赤道部位的SNV-PLSR 模型,其Rp为0.936,RMSEP为0.37OBrix。两个模型的预测精度均很高且接近,因此可以将赤道部位作为涌泉蜜桔糖度最佳检测位置。上述研究结果同时表明,对于大多数模型来说,经过UVE 算法筛选后的模型预测精度不如用CARS 算法筛选后的模型预测精度,但是对于涌泉蜜桔赤道部位的模型来说,采用CASR算法进行波长筛选后,模型预测效果会变差,采用UVE 算法进行特征波长筛选后模型与筛选前模型预测效果相差无几。因此,在接下来的工作中将重点研究不同的波长筛选算法对蜜桔不同部位的糖度预测模型的影响。除此之外,本次研究中仅使用3 个局部信息仍不能代表整个样本信息,所以下一步将通过获取整个样本区域更加全面的信息来评估本研究结果是否可靠,进一步优化模型。
猜你喜欢
今日农业(2022年13期)2022-09-15 01:19:22
江西农业(2021年14期)2021-12-06 16:06:02
科学导报(2021年63期)2021-09-29 12:38:50
杭州师范大学学报(社会科学版)(2021年4期)2021-08-06 06:40:32
现代园艺(2017年23期)2018-01-18 06:57:41
中国糖料(2016年1期)2016-12-01 06:49:07
中国品牌(2016年4期)2016-08-19 08:51:22
文学少年(原创儿童文学)(2016年16期)2016-02-28 17:50:17
分析化学(2015年6期)2015-06-18 10:37:24
作文评点报·低幼版(2014年15期)2014-06-25 14:18:42

- 中国光学的其它文章
- Design of all-optical logic gate based on two-dimensional photonic crystal
- All-solid-state acousto-optic mode-locked laser operating at 660 nm
- Stimulated brillouin scattering in double-clad thulium-doped fiber amplifier
- Optical simulation design of surface mounted device beads for wide beam and high uniformity display
- 用于紫外光谱仪的探测器温度控制系统
- TDLAS 气体激光遥测高灵敏光电探测电路设计