
面向车辆边缘计算的任务合作卸载
2024-02-02 09:29鲁蔚锋印文徐费汉明
工程科学与技术 2024年1期
鲁蔚锋,印文徐,王 菁,费汉明,徐 佳*
(1.南京邮电大学计算机学院,江苏南京 210023;2.江苏省大数据安全与智能处理重点实验室,江苏南京 210023;3.国铁吉讯科技有限公司,北京 100081)
近年来,物联网相关技术和自动驾驶技术已经成为研究的一大热点[1]。随着车联网相关技术的不断更新和发展,终端车辆具备了计算、通信和缓存的功能,这些技术在智能车辆网络方面发挥着关键性的作用[2]。考虑到车联网中实际的资源拥有情况,单一的路边单元可能无法满足终端设备的各项资源需求,造成了不必要的时延和能量的损耗,通过结合车联网中的合作任务卸载机制可以有效地提高系统的资源利用率,减轻网络流量负担,进一步降低时延。
目前国内外有很多研究车联网中通信、计算和缓存资源的联合分配问题[3–5]以及由云边端组成的3层分布式系统中的卸载问题[6–8]。Fan等[9]结合了基站的缓存和计算资源,设计了一种资源管理算法,指导基站联合调度计算卸载和数据缓存分配。Zhou等[10]结合车联网的计算、通信和缓存资源,设计了一种新颖的以信息为中心的异构网络框架,该框架支持边缘计算中的内容缓存和计算。Zhou等[11]研究了动态多用户移动边缘计算系统中计算卸载和资源分配的联合优化,不仅考虑到任务的延迟约束还考虑异构计算任务的不确定资源需求。Xue等[12]将非正交多址(NOMA)技术引入MEC系统中,提出了一种用于子信道分配的低复杂度次优匹配算法。Zhao等[13]考虑时延敏感型任务的卸载问题,将该问题建模为传输功率、子载波和计算资源分配联合优化,通过一个迭代算法顺序处理,通过等价参数凸规划获得最优解。Kuang等[14]研究MEC中协同计算任务卸载和资源分配联合问题,通过对计算卸载决策、协同选择、功率分配进行分别建模从而最小化系统时延。Dong等[15]设计了一种新型节能的主动复制机制,采用延迟率计算跟随车辆作为主车辆的备份,保证了系统的可靠性。Zhu等[16]采用多智能体深度强化学习的方案,考虑了多车辆环境的不确定性,使车辆能够做出卸载决策以获得最优的长期奖励。Zhu等[17]提出了一种新型的移动边缘服务器机制,把边缘服务器部署在移动车辆上形成车载边缘,共同优化车辆的最优路径规划和系统的资源分配方案。Liu等[18]用博弈论的方法解决时延敏感型任务的传输调度优化问题,在不同终端用户之间设计一个合理的非合作博弈,来找到最优的卸载方案。
目前已有的研究通常以时延和能耗作为约束条件来最小化系统总成本或最大化系统效用从而提出各种方案来解决优化问题,没有以最小化系统时延为目标,不能满足低时延的需求。考虑到车联网中实际的资源拥有情况,路边单元和边缘服务器相对于云服务器来说,计算能力和存储能力不足。单一的路边单元可能无法满足终端设备的各项资源需求,导致不必要的时延和能量损耗。本文通过结合车联网中的合作任务卸载机制可以有效地提高系统的资源利用率,减轻网络流量负担来降低时延,不仅充分研究了车辆边缘计算系统中的通信模型和计算资源分配问题,还考虑到车联网中停泊车辆和路边单元实际的资源拥有情况,设计了对应的合作集群来协作终端设备完成任务的计算卸载,利用系统的空闲资源提高系统计算能力,以减少系统时延为目标设计算法。本文的主要贡献包括3个方面:
1)设计了一种改进k聚类算法来划分不同的路边单元合作集群,不仅根据地理位置来划分,还考虑了实际的计算负载状况;
2)设计了一种任务合作卸载算法,充分利用了路边单元和停泊车辆空闲的可用资源,实现了系统的负载均衡;
3)应用不同数据集的实验结果表明,本文提出的算法可以找到有效的任务卸载方案。
1 系统模型
1.1 3层系统架构
如图1所示,将车联网中的任务合作卸载系统模型分为3层,分别为云服务器层、路边单元合作集群层和停泊车辆合作集群层。云服务器层位于远距离的云端数据中心,与边缘服务器和路边单元之间通过有线链路进行通信。路边单元合作集群层位于更加靠近终端设备的网络边缘,位于同一合作集群的路边单元之间可以进行X2通信[19]。停泊车辆合作集群层主要位于现实场景中的一些停车场,通过与边缘服务器之间的无线通信协助完成任务的计算,来拓展边缘服务器的计算能力。
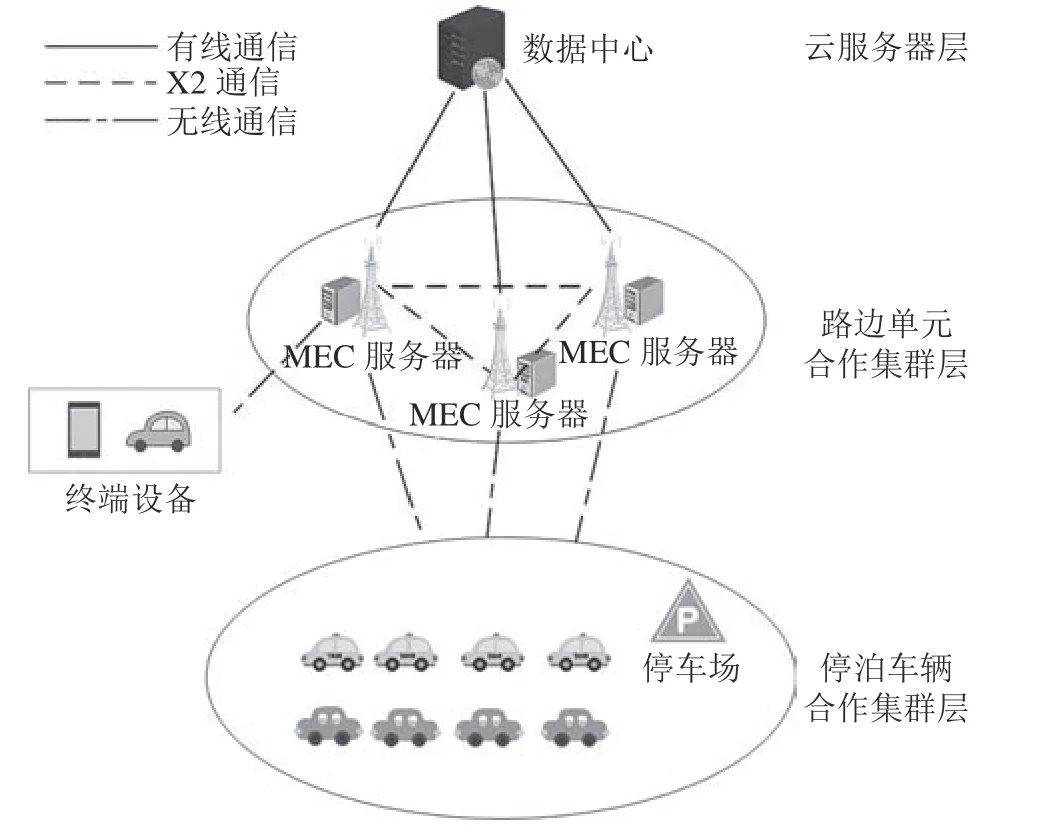
图1 3层系统架构Fig.1 Three-tier system architecture
系统中所有路边单元的集合为G,将所有路边单元划分为 ϑ个合作集群,一个路边单元的合作集群表示为:M⊆G。为了最小化路边单元之间的通信时延,通过距离来进行集群的划分。同时为了提高合作集群的高效性,允许一个路边单元属于多个不同的合作集群。每个路边单元m的计算资源为fm,代表路边单元m的计算能力,整个合作集群M的计算资源为FM=。停泊的车辆集合为PV,每个停泊车辆i∈PV的空闲计算资源为fi,则整个停泊车辆合作集群的计算资源为FV=
车联网中终端设备的集合为J,每一个终端设备j∈J会通过无线链路连接到与它最近的路边单元,连接到同一路边单元m的终端设备集合表示为Jm∈J。对于每一个终端设备j的计算任务用三元组表示aj=(z j,cj,bj),∀j∈J,其中,z j、cj、bj分别表示任务数据量大小、计算任务所需要CPU圈数和任务时延限制。
1.2 合作集群
本文利用改进的k聚类算法[20]来进行路边单元合作集群的划分,提出了路边单元合作集群划分算法,将路边单元集合G划分为 ϑ个合作集群,使各集群的聚类平方和最小,即以下目标函数最小:
式中,Md为第d个路边单元合作集群,每个路边单元m至少属于一个合作集群,并且=G,ϕ(m)为路边单元m所属合作集群的平均聚类中心,可表示为:
式中,Am为路边单元m所在的合作集群集合,md为其中每个合作集群的聚类中心。
一些固定停靠车辆的区域都可以看作是一个停泊车辆合作集群,比如路边的停车位、商场的停车场等。所有停泊车辆的空闲资源共同构成整个合作集群的可用资源。当多个终端设备接入到同一路边单元时,用来表示每个终端设备j在路边单元m中的资源分配情况,其中,为计算资源分配,为通信资源分配。
1.3 通信模型
终端设备的任务可以在本地计算也可卸载计算,系统计算卸载模型一共分为4种情况,如图2所示:
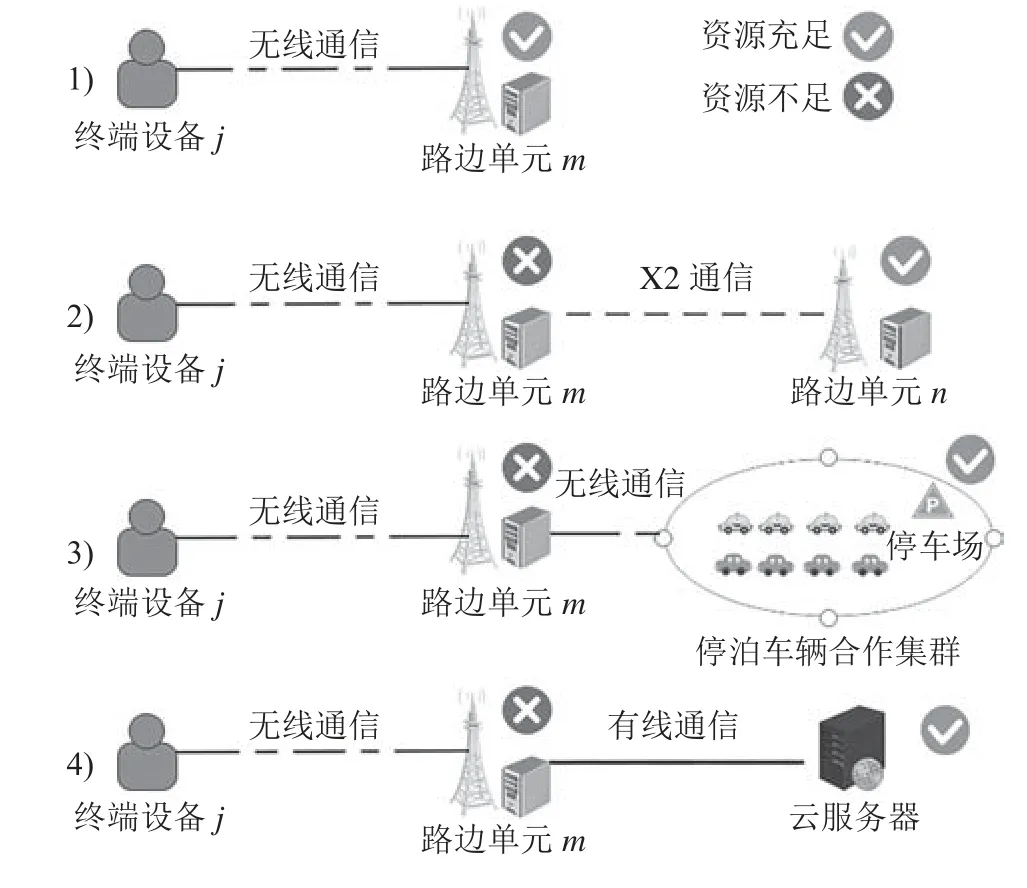
图2 计算卸载模型Fig.2 Computational of fload model
1)当终端设备关联的路边单元m资源充足时,终端设备j会通过无线通信将任务卸载到路边单元m计算。终端设备j到路边单元m的无线通信速率为:
由此可得,终端设备j卸载任务到路边单元m的传输时延为:
2)当路边单元m的资源不足无法满足终端设备的需求时,路边单元m会将任务aj通过X 2通信传输给资源充足的路边单元n,m和n位于同一路边单元合作集群,可以协同完成任务的计算。
路边单元m到n之间的传输时延为:

1.4 计算模型
相比于边缘服务器,终端设备的计算能力有限,在选择任务的计算卸载决策时要考虑终端设备的资源拥有情况。终端设备j将任务在本地计算的时延为:
式中,fj为终端设备j的CPU本地计算能力(即每秒CPU的圈数)。
本地计算的CPU能耗为:
式中,v为一个常量参数,跟终端设备的CPU硬件结构相关[21]。
则任务aj在终端设备j总共的本地计算时延为:
式中: τj代表当终端设备j资源不充足时,任务在设备本地等待处理的平均等待时间。∈{0,1}代表终端设备j资源是否充足的标识变量,即当tj>bj或者Ej>时,=0;当资源充足时,=1。
任务进行计算卸载时首先会卸载到离终端设备最近的路边单元m,再根据当前路边单元资源是否充足来决定任务在路边单元m计算还是借助路边单元合作集群计算。
当多个终端设备接入到同一路边单元时,路边单元m分配给终端设备j的计算资源为:

任务aj卸载到路边单元m的总执行时延为传输时延与计算时延之和:

1.5 问题的定义
本文的优化目标是最小化任务执行的总时延,任务执行的总时延包括任务本地计算时延和任务卸载计算时延,故可以定义系统目标函数:

约束1代表路边单元分配给接入终端设备的通信资源限制;约束2代表每个路边单元m的计算资源限制;约束3和约束4代表任务只能在一个地方执行。
目标函数和约束条件中包含多个非连续的0~1决策变量{x,y},并且多个0~1变量之间存在耦合关系,导致了这个优化问题是混合整数非线性规划问题,并且这个问题是NP难的。
定理1优化问题是NP(非确定性多项式时间)难的。
假设目标函数只包含一个0~1决策变量x,则可看作是一个0~1背包问题[22],由于0~1背包问题是一个典型的NP难问题,而优化问题比0~1背包问题更加复杂,所以优化问题也是个NP难问题。因此,在第1.3节中设计了具体的算法来求解这个优化问题。
2 算法设计
2.1 路边单元合作集群划分算法
路边单元合作集群划分算法是一个不断迭代的过程,首先选取 G个合作集群中心,然后根据路边单元和这些合作集群中心的欧式距离,找到每个路边单元所属的合作集群。再根据式(1)更新合作集群的中心,不断重复上述步骤,直到满足某个终止条件。

算法1给出了路边单元合作集群划分算法的详细步骤,步骤1随机选取 ϑ个初始合作集群中心;步骤2~5对于每个单元m,计算其与每个合作集群中心的距离,距离哪个集群中心近,就划分到对应的合作集群中,得到初始的合作集群;步骤7重新计算ϑ个集群的中心;步骤8根据新的集群中心重新归类每个单元m属于的集群;步骤9-14是看算法是否满足指定的终止条件,如果满足3个终止条件中的任意一个,则直接返回最终的路边单元合作集群算法结束,如果不满足则回到步骤7继续迭代。
2.2 任务合作卸载算法
为了方便描述,将优化目标函数表示为minF(x,y)的形式。考虑到目标函数求解的复杂性,采用块连续上界最小化(BSUM)[23]的分布式迭代优化方法来求解,BSUM方法的核心思想是将整个优化变量拆分为多个变量块,通过迭代的方法,在固定其他变量块的同时,来优化单一的变量块,直到达到预定的精度阈值(上限)。利用BSUM方法求解优化问题首先要解决两个问题,一个是目标函数的非凸问题,一个是0~1变量的非连续问题。
为了解决目标函数的非凸问题,通过添加平方惩罚项定义目标函数的近似上界函数,在每次迭代优化过程中,不直接对目标函数进行求解,而是对它的近似上界函数F求解。文献中[23]已经证明优化近似上界函数的方法是合理的,优化原始目标函数的近似上界函数可以保证原始目标函数是严格下降的。其中对应变量x和y的近似上界函数分别为Fx和Fy:
式中, ξ为一个大于0的惩罚参数,x∗代表在当前迭代中固定变量y而得到的最优解,y∗代表在当前迭代中固定变量x而得到的最优解。
为了解决0~1变量的非连续问题,将变量x和y线性松弛成0到1之间的连续变量,则可以定义2个变量的可行解空间为:
在每次迭代t时,通过求解目标函数的近似上界函数来得到当前的最优解,即在第t+1次迭代时用以下方式来更新x和y的值:
由于最终求解出的优化变量是0到1之间的连续变量,所以需要把它们重新变为0~1变量,借助阈值舍入技术[24]来将松弛后的变量重新变回一个0~1变量。这里举例说明阈值舍入技术,假定一个求解后的优化变量∈X和一个舍入阈值σ ∈(0,1),则对应变量的取值为:
上述的阈值舍入技术同样也可应用于变量y,然而通过阈值舍入后得到的解可能会超过系统的通信资源和计算资源限制。所以将近似上界函数变成为新的舍入问题F+wγ,即对式(20)的约束条件2和3进行以下调整:
式中, γρ和 γf分别为通信资源和计算资源可容忍的最大误差值,总误差γ=γρ+γf,w为总误差的权重参数, γρ和 γf分别表示为:
对应问题F和它对应的舍入问题F+wγ,可以根据整性间隙的值来评估舍入技术的优劣,根据文献[24]中对整性间隙的定义和证明,可以得出以下结论:
定理2(整性间隙)给定一个问题F它对应的舍入问题F+wγ,对应的整性间隙为:
整性间隙是用来衡量松弛后的优化问题和原优化问题之间的相关性。当整性间隙 β(β ≤1)越接近1时,说明对应的舍入技术越好。
算法2路边单元合作集群划分算法。
输入:所有路边单元的计算资源fm,所有车辆的计算资源fi;

算法2展示了任务合作卸载算法的具体步骤和过程。步骤1~7表示每个终端设备j∈J首先会根据自身资源的拥有情况来判断任务是在本地计算还是卸载计算。对于每个卸载到路边单元m的计算任务aj,执行步骤8~22来找到最优的卸载决策。步骤9表示初始化t=0 和 ε , ε是一个很小的正数,用来保证算法收敛到 ε最优解[24],具体解释在定理2中做出说明。步骤10表示找到一个初始可行解,步骤11~16代表算法的迭代过程,在每次迭代的过程中通过求解式(23)和(24)来不断更新x和y,直到,来保证收敛到 ε最优解。步骤17表示通过阈值舍入技术求解舍入问题+wγ,得到对应的0~1决策变量x(t+1),y(t+1)。步骤18~20表示计算当前问题的整性间隙β ,如果 β ≤1代表当前的舍入方案是可行的,输出最优的卸载决策x∗,y∗。
定理3(收敛性)BSUM算法收敛到 ε最优解的时间复杂度为O(lg(1/ε)),是一个次线性收敛。
算法 ε的最优解xε∈X代表:xε∈{x|x∈X,F(x,y)-F(x∗,y)≤ε},其中,F(x∗,y)是目标函数针对于变量x的全局最优值。
3 实验仿真
3.1 实验参数设置
基于Python3.0的环境进行实验仿真,为了验证本文路边单元合作集群划分算法的有效性,采用全球基站开放数据库中的基站位置真实数据[25],共包括全球5万多个基站的相关数据,模拟现实场景中路边单元合作集群的划分。聚类算法的精度阈值设为0.005,最大的迭代次数设为3000。为评估任务合作卸载算法的各项性能,假设每个路边单元附近有20~50个终端用户,每个终端用户大约每分钟产生一个计算任务,车辆的计算资源在0.5到1.0 GHz之间,路边单元的计算资源在2到5 GHz之间,云层的计算资源认为是无穷大的,任务的数据量大小在2到6GB之间,任务的时延限制在0.5到10 s之间。
3.2 实验结果分析
图3是250个基站聚类之前的实际位置。图4是通过路边单元合作集群划分算法聚类之后的效果。
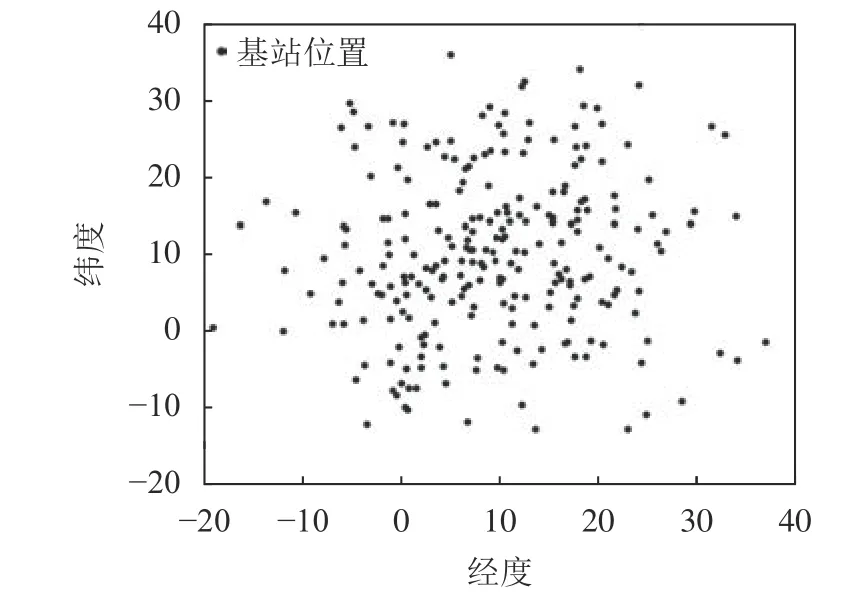
图3 基站位置Fig. 3 Base station location
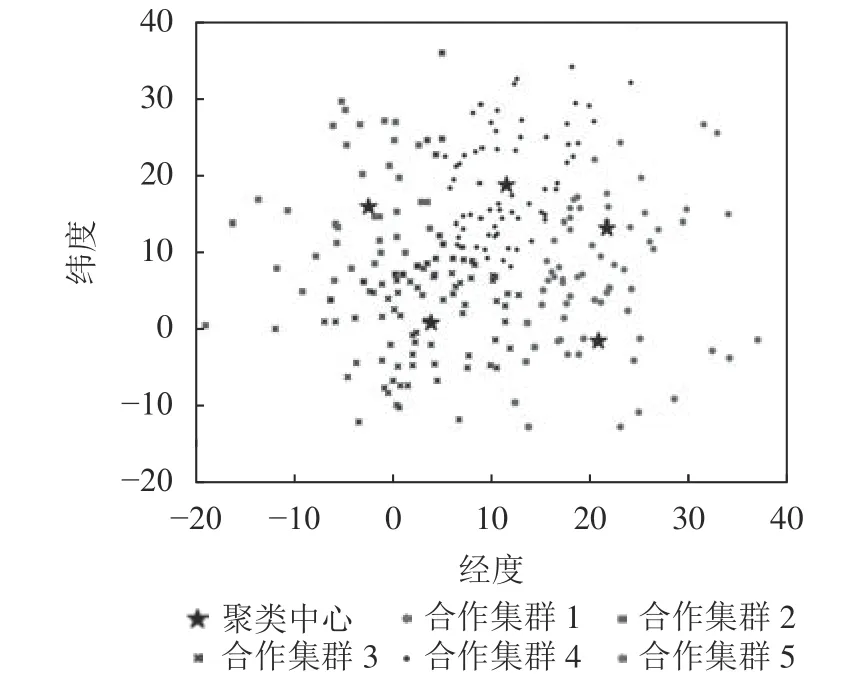
图4 聚类效果Fig. 4 Clustering effect
从图4可以看出,本文提出的算法将所有的基站划分为了5个不同的合作集群,每个聚类中心一般都位于所有合作集群的中心,并且集群之间可以相互覆盖,证明了本文算法的有效性。
为了证明提出的任务合作卸载算法的优越性,将本方案的实验结果与只本地计算、只卸载计算、无缓存队列、联合优化方案[9]和无合作卸载进行对比,无合作卸载方案是指路边单元之间不存在卸载任务的合作计算;联合优化方案是指考虑到本地处理能力和卸载能力,集中优化移动边缘计算中的联合资源分配。图5展示了在不同终端用户数量和不同路边单元数量下系统总时延的变化曲线,这里的系统总时延就是优化的目标函数。从图5(a)可以看出,本文提出的合作任务卸载方案在不同终端用户数量下系统总时延都要低于其他4种方案,可以降低23%的系统时延,说明本文方案可以有效地降低系统任务处理的总时延。从图5(b)可以看出,在不同路边单元数量下,本文方案也能发挥出很好的性能。当路边单元数量达到50左右时,本文方案、只卸载计算和无合作卸载的总时延变化都趋于稳定,说明在当前的系统状态下,此时的路边单元数量刚好达到系统平衡点,路边单元合作集群有着充足的计算资源,可以很好地完成所有任务的卸载计算。

图5 不同情况下总时延的变化Fig. 5 Variation of total delay in different situations
图6展示了在不同终端用户数量和不同路边单元数量下系统吞吐量的变化曲线,这里的吞吐量指的是系统每秒钟所能处理的数据量。从图6(a)可以看出,本文提出的方案在不同终端用户数量下都有着优于其他方案的系统吞吐量,相比之下,本文方案能提升28%的吞吐量性能,是因为本文提出的任务合作卸载不仅考虑了终端用户和路边单元的资源负载情况,还借助了合作集群之间的空闲计算资源,提高了系统的资源利用率。从图6(b)可以看出,本文方案在不同路边单元数量下也同样有着较高的系统吞吐量,系统吞吐量的提升在路边单元数量40到60之间更为明显,是因为在路边单元数量较多时,仅依靠单一的路边单元进行计算卸载已经无法满足系统的计算卸载需求,更需要考虑不同路边单元之间的协同计算。
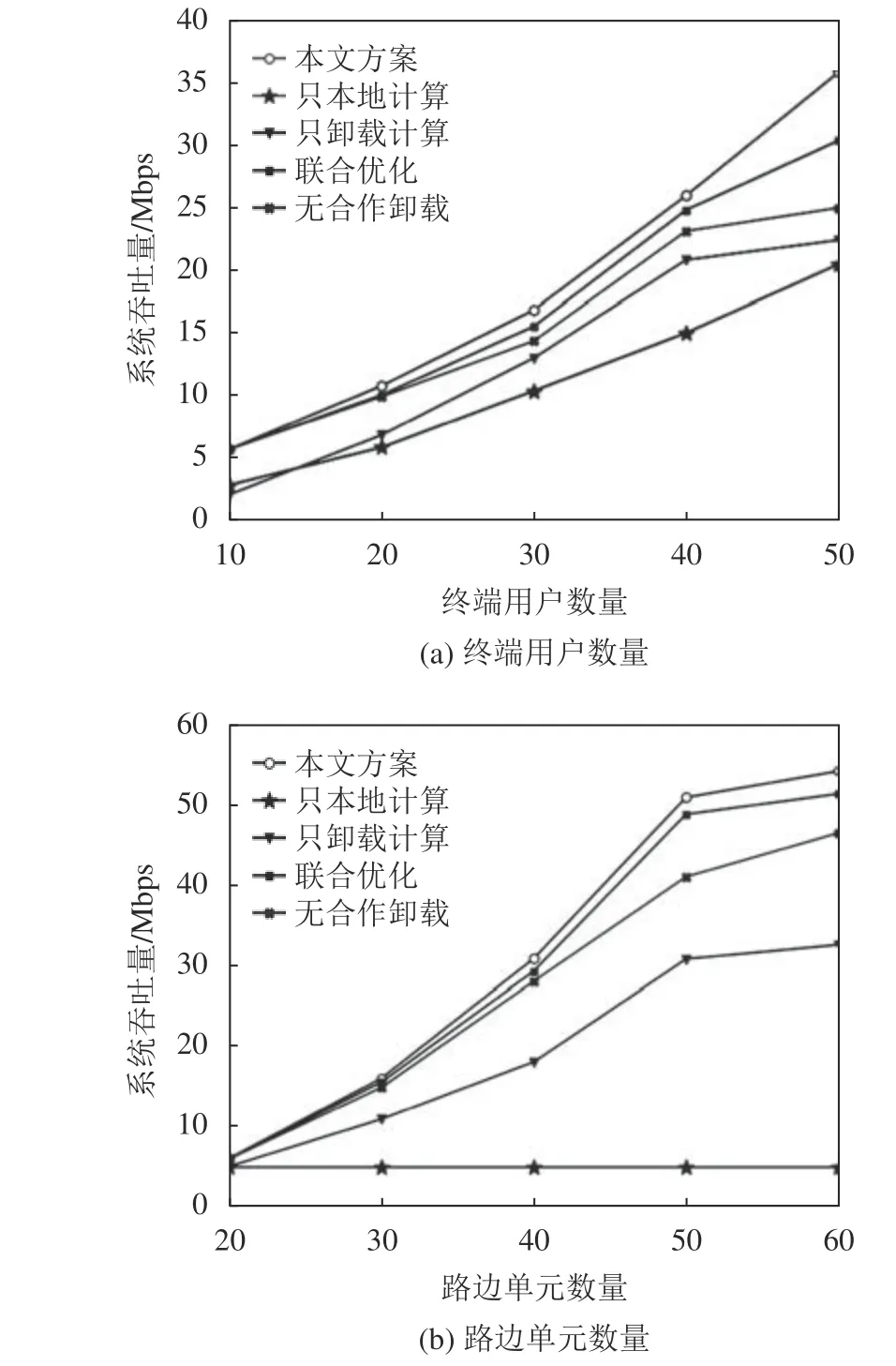
图6 不同情况下系统吞吐量的变化Fig.6 Variation of system throughput in different situations
4 结 论
本文对车辆边缘计算构建了一个3层架构,并提出了一种车辆边缘计算中的任务合作卸载机制,通过划分路边单元合作集群和停泊车辆合作集群,来协助终端设备完成任务的计算卸载,充分利用了系统的各项资源,降低了终端用户任务的处理时延。通过实验验证了路边单元合作集群划分算法的有效性,和其他方案的对比实验发现,本文提出的方案可以降低23%的系统时延,并且能提升28%的系统吞吐量。
未来的工作包括3个方面:1)多种通信模式:本文目前的研究主要考虑的是车辆和路边单元之间的V2I通信,可以结合V2V、V2X等多种通信模式,充分利用系统的各项资源来研究车联网中的任务卸载调度过程。2)停泊车辆的激励机制:在停泊车辆协助完成任务的计算卸载时,考虑到现实中的停泊车辆不会主动贡献自己空闲的计算资源,可以结合博弈论的相关研究,设计出合理的任务卸载激励机制,激励停泊车辆来完成任务的卸载计算。3)卸载方法优化:由于车辆边缘计算中路况的复杂性以及车辆的高移动性,现实场景中系统需要实时获取车辆周围信息,可尝试将在线算法与本文方案结合以满足现实需求。
猜你喜欢
科学技术创新(2021年18期)2021-06-23
微型电脑应用(2019年10期)2019-10-23
铁道通信信号(2019年4期)2019-10-10
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
电子制作(2016年15期)2017-01-15
系统工程与电子技术(2016年7期)2016-08-21
铁道通信信号(2016年3期)2016-06-01
