
基于改进YOLOv5s的鱼雷检测算法
2024-02-02 13:58甘文洋朱大奇
兵器装备工程学报 2024年1期
崔 陈,甘文洋,朱大奇,2
(1.上海海事大学 智能海事搜救与水下机器人上海工程技术研究中心, 上海 201306; 2.上海理工大学 上海市水下工程检测专业技术创新服务平台, 上海 200093)
0 引言
鱼雷虽然是一种传统的海战利器,因其隐蔽性强,威力巨大,操作方便且攻防兼备,在现代海战,尤其是在反潜作战中,鱼雷发挥的作用仍然无可比拟[1]。所以,如何防御鱼雷的攻击也就成为了各国海军重点研究的一个课题。对于任何一种先进的反鱼雷技术而言,最重要的就是能够尽可能早地检测出来袭鱼雷,发现得越早,对于采取反鱼雷措施的时机就越有利。
针对鱼雷等水下目标检测的方法,主要分为两大类。第1类是基于传统手工特征的水下目标检测算法,第2类是2012年开始兴起的基于深度学习的水下目标检测算法。第2类算法随着GPU计算能力的提升而逐渐成熟。由于基于深度学习的目标检测算法在目标检测中的实时性更好,提取特征的鲁棒性更强,所以相比基于传统手工特征的目标检测算法具有更快的速度和更高的准确度[2]。
随着深度学习和目标检测算法的飞速发展,基于各种水下目标检测算法的实验和改进方法层出不穷。Sung等[3]和Redmon[4]将YOLO (you only look once)应用于水下目标检测,然后在NOAA水下数据集上进行训练和测试,最终的分类准确率为93%。Gupta等[5]通过将SSD,Faster RCNN和YOLOv3-tiny等当时的主流检测模型用于识别鱼雷等军事用途,实验证明YOLOv3-tiny性能优于其他检测模型。Cai等[6]和Yang等[7]分别将改进的 YOLOv3 (you only look once version 3)[8]模型应用于水下目标检测中,进一步提高了检测模型的性能。Chen等[9]将改进的YOLOv4 (you only look once version 4)[10]模型应用到水下目标检测中,其检测的平均精度AP50相较于原始模型提升了11%。
在2020年6月,Jocher[11]提出了YOLOv5 (you only look once version 5)检测算法。YOLOv5会通过数据加载器传递每一批训练数据,并同时增强数据训练。另外,YOLOv5是自适应锚定框,且用Sigmoid激活函数替代了复杂度较高的Mish激活函数,使识别的速度和精度达到了一个新高度。谢晓竹等[12]通过修改激活函数、使用多尺度特征融合和增大尺度摄像头的方法来提高YOLOv5的检测性能,但在一定程度上会增加网络结构的复杂程度,对检测速度不利。Li等[13-14]通过改变YOLOv5模型的卷积模块来减少参数量并且将Ghost bottleneck替换掉原始网络中的BottleneckCSP模块的方法,以此来提高鱼雷等水下航行器的检测速度,但其检测精度有所降低。
水下光学视觉图像,通常来说其可视距离是很短的,但相较于传统的鱼雷检测,基于光学视觉的鱼雷检测有着明显优势:① 可在短时间内检测处理大量图像数据,检测速度更快;② 在图像中有干扰或噪声的情况下不易影响检测的精度,检测精度更高;③ 能够适应比如多种光照条件、遮挡和旋转等多种复杂场景;④ 不依赖于检测目标的形状和大小;⑤ 能够检测快速移动的目标。
考虑到深海中光线暗,环境特别复杂,检测难度很大,而且对于鱼雷这种致命武器的漏检率、误检率、检测精度和速度都有着更高的要求,所以提出了一种基于改进后的YOLOv5s鱼雷检测算法,在降低漏检率和误检率的同时,提高深海中鱼雷检测的精度和速度。
1 YOLOv5算法原理
YOLOv5网络结构模型主要由输入端(Input)、主干层(Backbone)、颈部层(Neck)和预测输出端(Prediction)共4个基础部分组成。其中,Conv是卷积操作;SPPF (spatial pyramid pooling-fast) 为空间金字塔池化,可以将任意大小的特征图转换成固定大小的特征向量;CBL模块由Conv、BN和SiLU激活函数组成;Concat是通道拼接,经卷积操作后实现特征融合。YOLOv5的结构如图1所示。
与YOLO系列的前几个版本相比,YOLOv5在网络结构上做了优化和改进。其中,输入端主要改进了Mosaic数据增强、自适应锚框计算和自适应图片缩放这3个功能,提高了目标的检测效果和推理速度。主干层最重要的改进是引入了Focus结构和CSP结构。Focus结构执行的是切片操作,可以将输入进YOLOv5模型中640×640×3的图像经过切片和卷积操作后变成320×320×32的特征图;CSP结构一共有2种,CSP1_X结构应用于主干层,CSP2_X结构则应用于颈部层。YOLOv5的颈部层在FPN(feature pyramidnetwork)[15]和PAN(path aggregation network)[16]结构的基础上做了一些改进,CSP2_X结构参考了CSPNet的设计,增强了模型的特征融合能力。预测输出端最大的改进就是采用了非极大值抑制(non-maximum suppression,NMS),其作用是用来删除多余的候选框,为每一个目标输出最佳的边界框,提高模型的检测性能。

图1 YOLOv5结构图
2 改进的YOLOv5s算法
YOLOv5模型是在YOLOv3模型的基础上改进而来的,其中包括了YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 4种基本模型。4种基本模型中,YOLOv5s的网络结构最简单,检测速度最快。如果将该模型应用于FPGA等硬件平台,则速度可能会更快。所以选择改进YOLOv5s模型来保证检测的速度和精度。
2.1 可分离视觉转换器SepViT
近年来,视觉转换器[17-18]在一系列计算机视觉任务中取得了巨大成功,在主要领域的性能已经超过了卷积神经网络。然而,这些性能通常是以增加计算复杂性和参数数量为代价的,而且这些算法通常需要昂贵的GPU计算能力来使用,并且也很难部署在移动设备上。
可分离视觉转换器[19]通过在平衡计算成本的同时保持准确性来解决这一挑战。将主干层网络的最后一层C3模块替换为SepViT模块,增强了模型的特征提取能力,优化了网络全局信息的关系。在SepViT模块中,逐层自注意力和逐点自注意力可以减少计算,并在窗口中实现局部信息通信和全局信息交互。首先,将分割的特征图的每个窗口视为其输入通道之一,并且每个窗口包含其自己的信息,然后对每个窗口标记及其像素标记执行逐层自注意力(DWA)计算。DWA的操作如下:
DWA (f)=Attention (f·WQ,f·WK,f·WV)
(1)
式(1)中:f为特征标记,由窗口标记和像素标记组成;QW、KW和VW为3个线性层,用于自适应关注中的查询、键和值计算。DWA操作完成后,使用逐点自注意力(PWA)计算在窗口之间建立连接,并通过层标准化(LN)和Gelu激活函数生成注意力图。PWA的操作如下:
PWA (f,wt)=Attention (Gelu (LN (wt))·WQ,
Gelu (LN (wt))·WK,f)
(2)
其中,wt表示窗体令牌。那么,SepViT模块可以表示为:
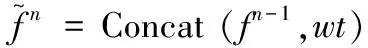
(3)
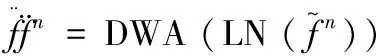
(4)
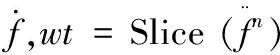
(5)

(6)
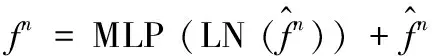
(7)
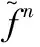
2.2 ECA注意力机制
在网络模型中添加注意力模块,可以有效减少无效目标的干扰,通过加强特征信息的利用率,从而可以提高目标的检测精度,所以引入了高效通道注意力机制(efficient channel attention,ECA)[20]。ECA模块是一个轻量级的注意力模块,它不需要改变网络的整体框架结构,只是作为一个模块添加到主干层中。同时,它避免了降维,以有效的方式捕捉跨通道的交互信息[20]。ECA模块虽然只涉及少量参数,它却可以带来显著的性能提升。虽然融入ECA模块的YOLOv5s网络深度有所增加,但其检测精度会明显提高。
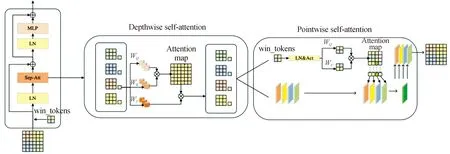
图2 SepViT模块的整体结构
针对YOLOv5s模型的结构特点,共设计了3种融合方式,分别是在其主干层(Backbone),颈部层(Neck)和预测输出端(Prediction)融入ECA模块,标记为YOLOv5s-B,YOLOv5s-N以及YOLOv5s-P,以便对模块输出的特征进行更深入的优化和学习。针对水下目标检测中存在的诸多问题,改进后的网络具有较好的性能,因为它可以更精确地提取图像特征。ECA模块的基本结构如图3所示。

图3 ECA模块的网络结构
ECA模块首先在输入维度为H×W×C的特征图上通过全局平均池化提取特征,从而获得1×1×C的全局感受野。经过自适应卷积核1D进行卷积操作,使每层的通道和相邻的通道进行信息交互,共享权重,其中权重的多少取决于卷积核k的大小,k的计算公式如式(8)[20]。最后经Sigmoid函数处理,将更新的权重乘以输入特征图生成新的特征图。

(8)
式(8)中:γ和b代表线性拟合非线性参数,这里γ设置为2,b设置为1;C代表特征通道的尺度,|t|odd表示离t最近的奇数。
2.3 颈部层的改进
相较于例如Faster R-CNN,SSD,YOLOv3-tiny以及YOLOv4-tiny等其他主流检测算法,YOLOv5s网络结构上更为复杂,且在2.2节中提到, ECA模块虽然只是作为一个轻量级的注意力模块加入到YOLOv5s模型中来提高检测的精度,但是其一定程度上也会增加网络的深度,从而降低模型的检测速度。
为了使检测模型同时兼顾鱼雷检测的精度和速度,通过改进模型颈部层的网络结构来实现,使模型得到进一步的优化。YOLOv5s中的路径聚合网络(PANet)通过上采样和下采样的方式使特征图获得精准的语义信息和位置信息,可以大大提高目标检测任务的精度[16]。但是PANet也有着很大的计算量,影响检测的速度。然而双向特征金字塔网络(BiFPN)采用跨尺度连接来去除PANet中对特征融合贡献较小的节点,并在同一级别的输入和输出节点之间添加额外的连接[21],可以使检测网络模型实现简单且快速的多尺度特征融合。在实验中,使用单层结构的BiFPN代替PANet以保证检测速度。其工作原理对比如图4所示。
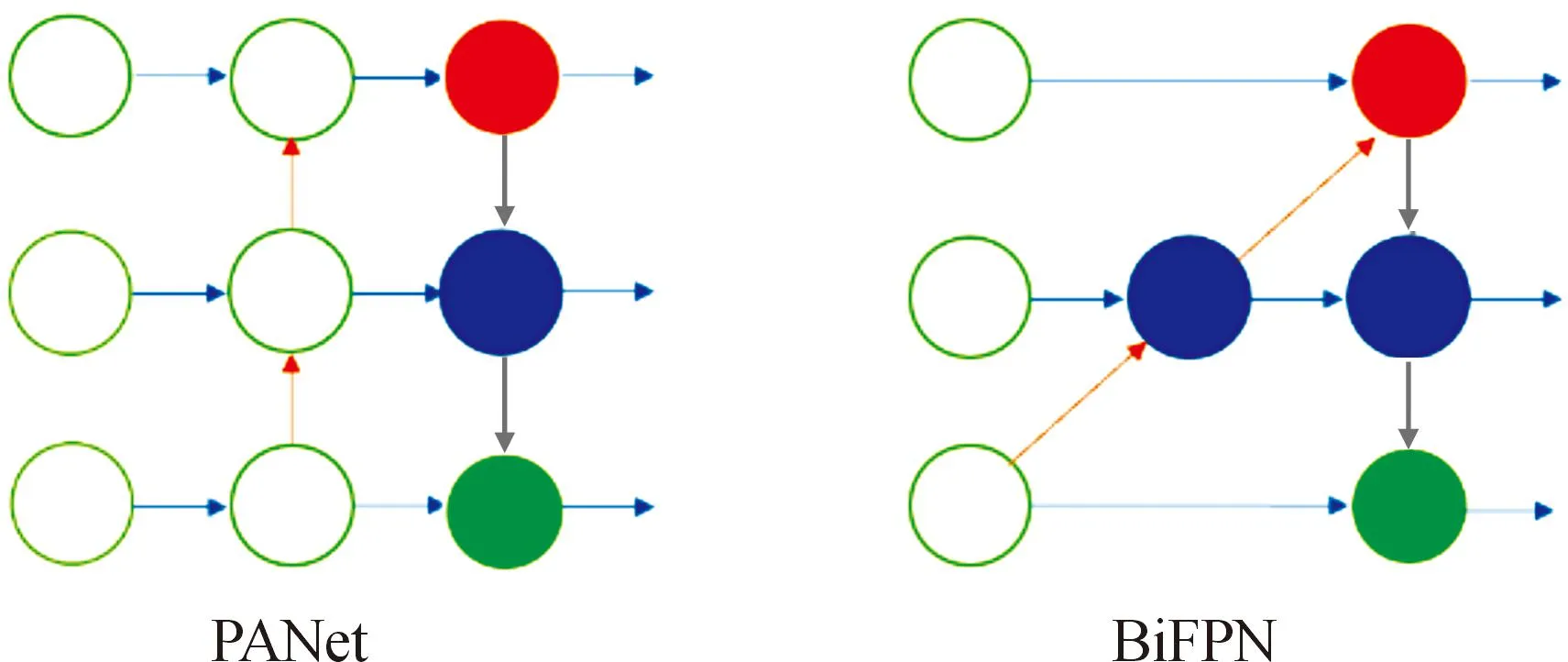
图4 PANet和BiFPN的对比
2.4 损失函数的选取
目标检测模型在执行检测任务时,首先需要识别出待检测目标,然后进行定位。在此过程中,损失函数可以使检测模型的定位更准确,从而提高检测的精度。一个优秀的回归定位损失应该考虑3个几何参数:重叠面积,中心点距离和长宽比。引入中心点距离和长宽比2个参数后,形成了完全IoU Loss (complete IoU Loss,CIoU Loss)[22]。CIoU优化了DIoU[23]的不足,考虑到了检测框尺度的损失和长和宽的损失,这样预测框就会更加地符合真实框,从而提高识别的准确率[22]。如式(9)—式(11):
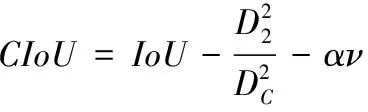
(9)
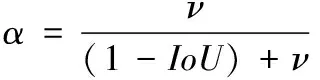
(10)

(11)
其中,D2为预测框与目标框的中心点距离;DC为最小外接矩形对角线长度;ωgt/hgt和ω/h分别为预测框与目标框的长宽比。
3 实验与结果分析
3.1 实验数据集
通过对自建数据集进行数据扩充,以满足数据集的数量要求。数据扩充方式多种多样,常见的有水平镜像和垂直镜像、旋转一定的角度、放大和缩小、改变其明亮度、添加噪声和图像平移等。扩充后的数据集有1 900张鱼雷图像。数据扩充前和扩充后的部分数据集如图5所示。

图5 数据集示例
利用开源标注工具LabelImg对数据集中的鱼雷进行标注工作,标注完成后利用Python代码将数据集按8∶1∶1的比例划分为训练集、验证集和测试集,即训练集1 520张,验证集190张,测试集190张。
3.2 实验
3.2.1实验环境
本实验模型的搭建、训练和测试均在PyTorch深度学习框架下完成。具体的计算机配置和实验环境如表1所示。

表1 实验运行环境
3.2.2评估标准
在目标检测领域中,常用查准率(precision,P)、查全率(Recall,R)和均值平均精度(mean average precision,mAP)来评估模型性能的优劣。计算公式如式(12)—式(14):

(12)
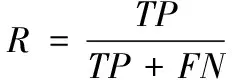
(13)
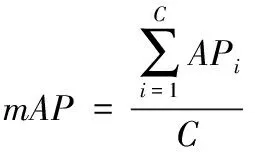
(14)
其中,TP(true positive)、FP(false positive)和FN(false negative)分别表示正确、错误和没被检测出的鱼雷数量,AP表示P-R曲线与坐标轴围成的面积,C取值1。
3.2.3漏检率和误检率测试实验
为了验证在YOLOv5s网络模型中使用SepViT模块可以降低鱼雷的漏检率和误检率,故分别将原始的网络YOLOv5s和改进了的网络YOLOv5s-SepViT进行漏检率和误检率测试实验。测试结果见表2。
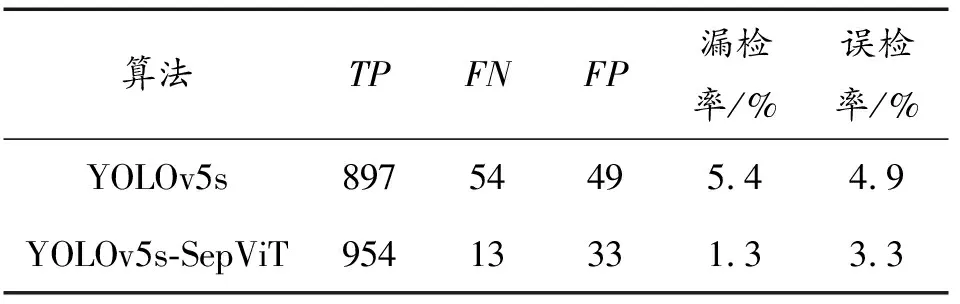
表2 漏检率和误检率测试结果对比
参与测试的图像共选取500张,其中包括鱼雷1 000枚。从表2可以看出,融合了SepViT的YOLOv5s网络在漏检率和误检率上都有很大改进,分别为1.3%和3.3%,较原始网络降低了4.1%和1.6%。
3.2.4ECA模块融合对比试验
为了验证将ECA模块融入到YOLOv5s网络模型的哪一部分可以得到更高的检测精度,故首先进行融合对比试验。实验结果如表3所示。

表3 融合ECA模块的结果对比
训练过程中,可在PyCharm中的命令控制终端运行命令调用TensorBoard工具查看模型的参数。由实验结果可知,YOLOv5s-P在查准率Precision和查全率Recall上较未改进的YOLOv5s模型有一定提升,但是其均值平均精度mAP值不升反降,效果不佳。虽说YOLOv5s-N在3项指标上都有提升,但是其性能还是不及YOLOv5s-B,故将ECA注意力模块融合到YOLOv5s模型的主干层中构成YOLOv5s-ECA-BiFPN鱼雷检测模型,如图6所示。

图6 YOLOv5s-ECA-BiFPN结构图
3.2.5主流算法对比实验
为了验证改进了的检测算法YOLOv5s-ECA-BiFPN有着更高的性能,故在相同的实验环境和数据集下进行对比实验。参与对比实验的算法都是当前主流的目标检测算法,分别为Faster R-CNN,SSD,YOLOv3-tiny,YOLOv4-tiny,YOLOv5s以及改进了的YOLOv5s算法YOLOv5s-ECA-BiFPN。各种参与对比实验算法的查准率Precision、查全率Recall和均值平均精度mAP的数值如表4所示。

表4 不同模型检测精度结果对比
将不同模型的best权重文件放在detect.py文件里进行推理测试实验。各算法具体的检测效果对比图如图7所示。
3.3 结果分析
从模型训练完成后的参数中可以看出,改进了的鱼雷检测算法YOLOv5-ECA-BiFPN对于鱼雷检测的性能是最高的,相对于其他主流算法,不管是检测精度还是检测速度,都有很大的提升。相较于其基础检测算法YOLOv5s,改进了的YOLOv5-ECA-BiFPN算法检测帧率提高了11 FPS,达到了83 FPS,其检测用时为5.3 ms,在各种参与实验的算法中也为最快,且其均值平均精度mAP从93.3%提高到了97%,故改进的算法在鱼雷检测的速度和精度上都有一定提升。
各种参与对比实验算法的具体检测速度如图8所示。

图7 检测效果对比

图8 各种检测模型速度结果对比
3.4 视频检测效果
考虑到在实际的鱼雷检测任务中,鱼雷都是以动态的目标出现的,故还需要进行视频推理测试来验证改进了的YOLOv5-ECA-BiFPN检测模型的动态目标检测效果。对鱼雷推理视频的几个关键帧进行截图,具体的推理结果如图9所示。以此可见,本文中改进的算法在鱼雷实时监测上获得了理想效果。

图9 视频检测效果示例
4 结论
通过融入ECA注意力机制,使用双向特征金字塔网络和可分离视觉转换器模块的方法改进YOLOv5s网络结构,降低了误检率和漏检率,提高了深海鱼雷检测的速度和精度:
1) 检测速度达83 FPS,较原来的YOLOv5s算法提高了11 FPS。
2) 均值平均精度mAP达97.0%,较原来的YOLOv5s模型提高了3.7%。
本文中改进的算法虽然在深海鱼雷的检测精度和速度上有一定提升,但对于快速移动的远距离来袭鱼雷的实时检测还有很大进步空间。因此如何准确又快速地识别出高速移动的远距离来袭鱼雷是下一步研究的重点。
猜你喜欢
小学生学习指导(小军迷联盟)(2023年3期)2023-03-27
小猕猴智力画刊(2022年4期)2022-05-25
小哥白尼(军事科学)(2021年8期)2021-11-22
中学生百科·大语文(2021年4期)2021-05-12
小哥白尼(军事科学)(2020年8期)2020-05-22
电子制作(2018年11期)2018-08-04
发明与创新(2016年5期)2016-08-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
海洋世界(2014年2期)2014-02-27
