
基于YOLOv2 目标检测算法和K210 芯片的智能压板状态识别系统
2024-01-31 13:23:28陈业宏
电子制作 2024年2期
陈业宏
(广东粤电枫树坝发电有限责任公司,广东河源,517000 )
0 引言
在日常巡检过程中,运行人员需要对发电机、变压器、线路等保护装置进行检查,其中根据当时机变和线路的运行方式检查压板相应的投退情况是非常重要的项目。由于在厂房中保护装置台数众多、压板数量繁多,且压板类型容易造成混淆,而巡检人员常常处于人数不足的状态,难免会因为在高温、高噪声的工作环境下引起精力不集中,产生失误导致的错检、漏检。为了帮助避免上述情况发生,本文提出一种通过人工智能识别算法来检查压板投退状态并进行图像和文字显示的工具。
针对压板状态识别的技术,先前已有学者采用神经网络和机器视觉的方法,先对图像进行预处理,然后针对压板三个状态:投入、退出、备用的不同特征进行提取,最后根据特征匹配输出大于阈值的结果。这种方式虽然简单、容易实现,但由于现场光线干扰和拍摄图像与特征模板匹配时产生畸变的问题,导致最终检测分类速度慢且结果与实际具有较大偏差。
基于以上出现的问题,本文基于对不同类型的压板不同状态表现的研究,采用YOLOv2 目标检测算法,采集不同颜色、种类的压板进行三种状态的特征提取,导入算法进行多次训练,并通过调整参数进行对比验证,得到现场识别效果较好的目标检测模型,证明基于YOLOv2 目标检测算法和K210 芯片的智能压板状态识别系统的可行性和有效性。
1 系统框架
本系统使用搭载K210 芯片的Maix Bit 最小系统板,采用型号为OV2640 的广角摄像头和2.4 寸彩色屏幕。将提前训练好的模型(.kmodel 文件)烧录到芯片0x300000 地址上,在0x00000 和0X1a0000 地址上烧录最新版本的模型驱动固件以及最小系统固件(均为bin 文件);使用摄像头采集压板图像,识别压板是否处于投入、退出或者备用的状态;摄像头所拍摄图像以及识别结果可以显示在LCD 屏幕上。
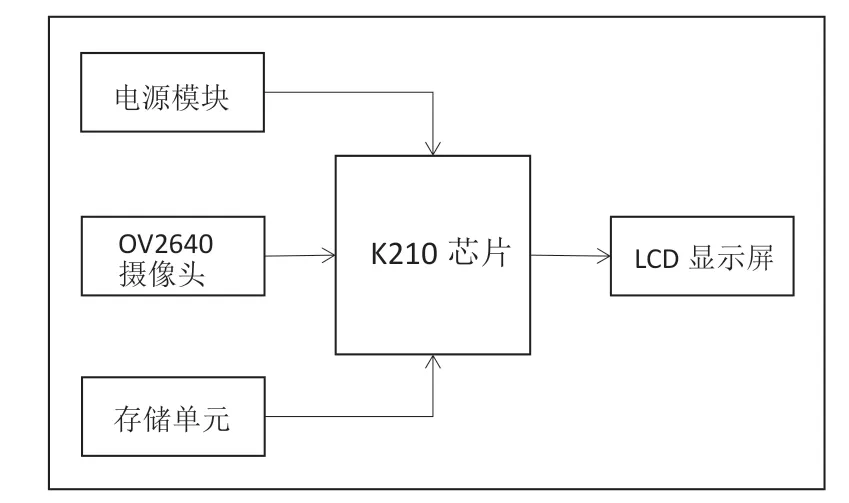
图1 系统硬件结构框图
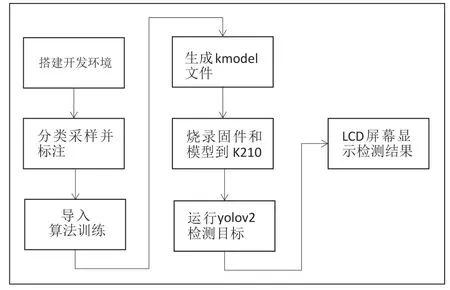
图2 系统开发流程框图
2 目标检测算法的比较和原理
与经典的目标检测算法,例如R-CNN、Faster-RCNN等相比,YOLO 算法更具有实时性的优势。由于YOLOv1 算法采用单次循环检测的方式,对尺寸小、密度高的目标定位存在较高的位置误差,而YOLOv2 在引入Darknet-19 网络和Anchor box 之后,通过多尺度特征的比对来提高检测精度和稳定性。在精确性方面,可以利用Anchor box 和多尺度特征提取提高压板检测的准确性,同时适当增加样本数量,保证良好的训练效果和检测准度。可以对物体进行实时检测,以图片作为输入,将识别目标的位置和置信度作为输出,能够在保持原有较高的检测速度的基础上,提高目标检测的准确率,而目标检测的主要任务无非就是两个:分类和定位。
■2.1 分类原理比较
在分类过程中,R-CNN 采用选择性搜索的方式产生候选框,再使用分类器对每个候选区域进行特征提取,使用预先训练的CNN 提取区域的特征,最后采用线性回归的方法来判断候选物体的类别,这种方式速度较慢,且容易造成数据丢失。Fast R-CNN 虽是利用整图一次性提取候选框的方式,在整个识别分类的过程中使用了2 个不同的CNN 网络结构进行特征提取,导致速度依然不够理想。YOLOv1 是一个end-to-end 的检测分类算法,即将目标检测任务转化为回归问题。它采用全卷积神经网络将整个图像作为输入,同时预测多个边界框和类别,仅使用1 个CNN 网络就能输出目标物体的置信度得分和类别得分,最后通过非极大值抑制(NMS)筛选最终检测结果,检测分类速度高达45~155帧/秒,缺点在于定位精度不够高。而YOLOv2 在模型中去除全连接结构,不再使用滑动搜索方式进行特征提取,取而代之的是使用卷积层和池化层对最后的结果进行预测,对每个候选区域预测一个独立的类别,同时引入Anchor box 的概念对不同尺度和比例的目标边界框进行预测,然后同样使用非极大值抑制(NMS)筛选检测结果,在YOLOv1 的高速度的基础上进一步提高检测准度。
■2.2 定位原理比较
在定位过程中,在R-CNN 是采用选择性搜索的算法对候选区域进行划分。选择性搜索是一种基于图像分割的算法,通过将图像分割成若干个像素块,并将相似度较高的像素块来合并形成候选区域。对于每个候选区域,R-CNN 使用预训练的CNN(如AlexNet 或VGG)对候选区域进行特征提取,然后使用支持向量机(SVM)或线性回归器进行目标分类和边界框回归,从而实现目标定位。Fast R-CNN 通过RoI (Region of Interest) pooling 层将选择性搜索生成的候选区域映射到固定大小的特征图上,并将每个RoI 映射为相同大小的特征向量。然后,这些RoI 特征向量传入全连接层用于目标分类和边界框回归,最后经过非极大值抑制(NMS)筛选出结果。在目标定位方面Fast R-CNN 比R-CNN更高效。YOLOv1 是通过直接回归目标边界框的位置实现定位的,将整个图像划分为网格,并预测每个网格的多个边界框。每个边界框由五个值组成:中心坐标(x,y)、宽度(w)、高度(h)以及目标置信度得分和多个类别得分。通过预测这些值,YOLOv1 可以定位目标的位置和大小。YOLOv2 则是在YOLOv1 的基础上引入Anchor box 来预测边界框的位置,模型再训练检测之前已经适应不经切换的高分辨率输入。Anchor box 作为在各类目标检测的网络模型中作为先验框的存在,每次训练都会将输入的图片分成S*S 的方格,每个方格围绕中心生成5 个Anchor box,先验框与目标框进行一个交并比IOU 的计算得到阈值,小于阈值的归属于背景区域,大于阈值的归属于目标区域,经过K-means 聚类之后的数据产生归一化,回归产生的框就是bounding box。先验框的应用可以简化识别问题,使网络模型更容易学习;bounding box 作为检测目标的位置参数,能提取出目标边界框左上角坐标[tx,ty]以及宽高[tw,th]。由bounding box 得到预测结果的转换公式如下:
其中cx,cy 是grid cell 在feature map 左上角的坐标,Pw,Ph 是Anchor box 相对原图的宽高。
3 系统主要硬件和模型训练过程
■3.1 勘智K210 芯片简介
本设计使用勘智K210 芯片作为该系统的主控,兼顾数据处理、图像处理等功能。该芯片采用RSIC-V 架构,具备双核64 位处理器,搭载FPIOA 可编程阵列,并配备丰富的外设接口,包括UART、SPI、I2C、PWM、GPIO 等。可根据不同需求结合不同的编程语言,能够实现神经网络计算、人脸识别、特征检测等功能,具有低功耗、低价格、高性能的特点,其高效的AI 加速和图像处理能力,加快终端感知数据处理,并减少数据传输压力,可广泛应用于工业、园区等场景的智能识别系统。

表1 K210芯片性能参数表
■3.2 模型文件训练过程
本系统主要以Mx_YOLOv3 开源工具作为本地模型训练平台,配合其他工具完成训练集的制作和文件类型的转换。
(1)训练集制作和标注
首先,通过采取摄像头拍摄的方式收集生产现场环境下保护装置屏面压板的图像数据,也可以从工业场景或模拟器中获取。为提高摄像头在不同场合光线下的识别成功率,以及从不同角度拍摄压板返回重叠不规则特征图像导致识别失败的情况,采取环境、光线、角度多样化进行采样,且采样数量比例保持均衡的策略,确保图像质量良好,包含不同尺寸、状态和颜色的压板。
然后是对图片进行预处理,这个步骤能够有效减少计算复杂度,提高模型训练效率。通过图像的大小归一化、调整、裁剪和增强等操作,以确保图像具有一致的尺寸和质量。此处使用图形转换工具将训练集处理为像素448×448、jpg 格式的方格图片,并对压板图像进行锐化,减少曝光面积等调整。
最后是标注和文件标签。对于每张图像,需要标注其中的压板位置和类别信息。通常使用边界框来标注压板的位置,即在图像中用矩形框框出压板的边界。标签文件中保存着标注信息,其中包含压板的位置(边界框坐标)和类别。此处根据压板在不同状态下的特征进行框图标注,使用LabelImg 工具分别对训练集中投入、退出、备用的压板框选出来进行标注,生成的xml标签文件则是供程序读取信息。
(2)模型训练和参数选择
配置好开发环境后,在Mx_YOLOv3 平台中选择物体识别—YOLOv2 模型,相关参数设置参考表2。
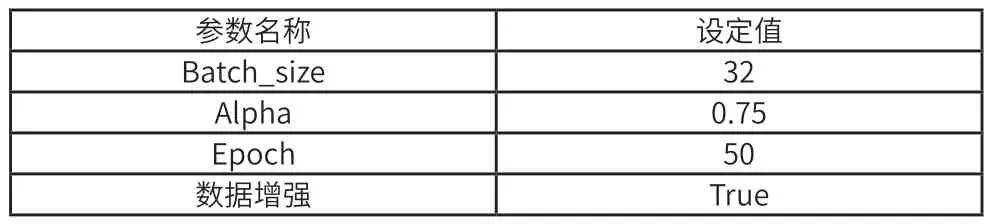
表2 YOLOv2训练参数设置表
合理的Batch_size 数值能够保证最大限度利用电脑内存,提高训练速度,常见的设定值有32、64、128 等。Alpha 数值的设定则需要根据数据集的特点进行调整,如果Alpha 值过小,目标框的尺寸可能变小,导致漏检的问题。在训练中选择合适的Alpha 值来保证目标框大小与图像尺寸之间的比例适当,从而得到更好的训练效果。Epoch 是指整个训练集的训练次数,通常设置在30~100 之间,一般来说损失函数loss 明显收敛以及平均精度mAP 趋于稳定之后,说明模型基本达到充分训练的程度,此时应当防止训练次数过多导致过拟合问题。
(3)文件转换和烧录
为了适配K210 芯片上的神经网络加速器,需要将训练好的模型文件,包括模型参数、权重和结构等信息重新编码,转换成特定格式的k210model 文件。在Mx_YOLOv3平台进行模型训练,完成后自动生成tflite 模型文件,使用NNCase0.1.0 工具将tflite 文件转换为k210model 文件。
由图3 可知,K210 内部Flash根据功能和作用主要分成三大区域:固件区、模型区和文件系统区,将相应文件在起始地址偏移量开始烧录即可。固件区通常烧录用于系统启动的驱动程序和用户编写的应用程序。模型区实际上是K210 芯片特有的AI RAM 存储器,能够快速加载和处理模型文件。

图3 K210 内部Flash 分区结构图
4 功能实现及优化
■4.1 驱动摄像头
K210 最小系统板上集成了摄像头处理单元(DVP)及摄像头排线接口,支持OV2460、OV2560 等多种摄像头,支持RGB565 像素格式、QVGA 帧面尺寸、亮度、饱和度、自动增益模式设置。OV2460 是一款具有200 万像素的CMOS 图像传感器,在K210 芯片固件上相应的摄像头驱动程序。摄像头将采集的图像数据传输到处理单元进行预处理,然后作为输入传递到YOLOv2 模型中进行目标检测。在完成摄像头初始化配置后测试摄像头能够稳定运行。
■4.2 初始化YOLOv2
调用kpu.load(0x300000)加载模型文件,并将返回值填入YOLOv2 初始化函数kpu.init_yolov2(kpu_net,threshold,nms_value,Anchor_num,Anchor),其中kpu_net 即kpu.load 的返回值,threshold 为输出门限值,nms_value 为输出交并比门限值,Anchor_num 为Anchor 锚点数,Anchor为模型训练前计算出来的锚点参数。
■4.3 测试效果及优化
图4、5、6是训练模型优化前对模型进行测试的识别结果,明显看出识别准确率不高,且有的样本仍然识别失败,无法正确框出检测目标。分析图7 的loss 曲线图发现经过50 次Epoch 之后loss(蓝色)、val_loss(橙色)曲线总体单调递减呈收敛趋势,数值处于0.6~0.8 之间,但局部区域出现明显震荡,存在过拟合现象,应考虑增加样本数量、减少特征无关像素的占比、提高训练集和测试集的关联等等。

图4 优化前压板投入状态测试效果

图5 优化前压板退出状态测试效果

图6 优化前备用压板测试效果
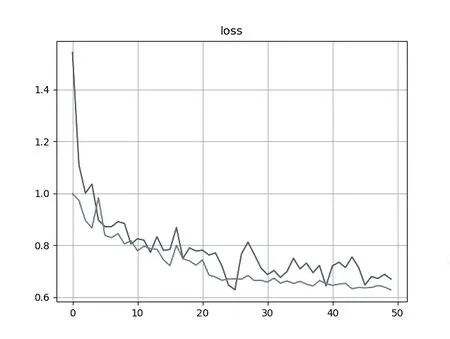
图7 优化前loss、val_loss 曲线图
如图8 所示,在采取一系列措施进行模型优化后,loss(蓝色)、val_loss(橙色)的曲线均呈收敛趋势,且无明显起伏,经过30 次Epoch 之后数值均小于0.1。由图9、10、11模型测试效果可看出,识别成功率和准确率明显提高。
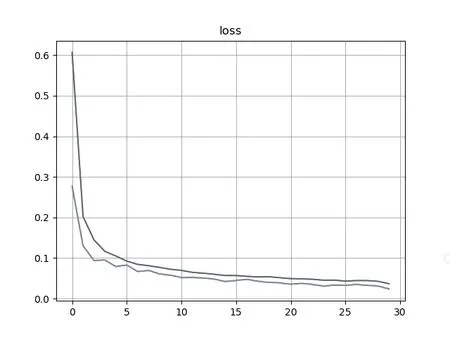
图8 优化后loss、val_loss 曲线图

图9 优化后压板投入状态测试效果

图10 优化后压板退出状态测试效果

图11 优化后备用压板测试效果
■4.4 上机测试效果
图12、13、14 是对三种不同状态的压板进行实物识别之后在LCD 显示屏反馈的效果,图12 是压板投入图像,左下角显示“yaban_on 0.8325”代表压板投入状态的概率为83.25%;图13 是压板退出图像,左下角显示“yaban_off0.9398”代表压板退出的概率为93.98%;图14 是备用压板图像,左下角显示“yaban_none 0.9081”代表此为备用压板的概率是90.81%。

图12 压板投入状态检测结果

图13 压板退出状态检测结果

图14 备用压板检测结果
5 结束语
本文研究了一种由K210 芯片、OV2640 摄像头和LCD彩色显示屏组成的智能压板状态识别系统设计。该系统设计简洁、资源利用率高,通过摄像头对生产环境下保护装置屏面的压板进行图像采集,输入到训练好的YOLOv2 算法模型中能够有效针对压板投退状态进行检测识别,并将结果显示在LCD 屏幕上。经过多次现场识别测试,目前可以快速、准确显示多个角度下压板的不同状态。未来将以提高单次识别保护装置的压板界面的速度为导向,采用算力更大,性能更强的人工智能模块和检测算法,提高真实场景下单台保护装置压板状态的检测速度和准确率。
猜你喜欢
中学生数理化·八年级物理人教版(2023年4期)2023-05-05 07:29:28
橡塑技术与装备(2022年12期)2022-12-12 06:42:28
中国交通信息化(2022年9期)2022-10-28 06:14:40
汽车工程师(2021年12期)2022-01-18 06:02:43
发明与创新(2016年23期)2016-10-13 02:16:14
湖北工业大学学报(2016年5期)2016-02-27 13:14:51
汽车维修与保养(2015年8期)2015-04-17 03:32:59
云南电力技术(2014年1期)2014-06-23 02:44:12
河南科技(2014年10期)2014-02-27 14:09:18
中国信息化·学术版(2013年7期)2013-09-03 06:32:24
