
视频流环境下基于深度学习的动作识别
2024-01-31 13:23:26严倩倩
电子制作 2024年2期
严倩倩
(西安职业技术学院,陕西西安,710077)
0 引言
近些年来,神经网络在图像分类领域取得了不凡的成绩,并随着研究的深入提出了很多新的网络模型,比如双流网络、卷积神经网络CNN[1](Convolutional Neural Network)、循环神经网络RNN[2](Recurrent Neural Network)等。
双流网络由光流网络和RGB 网络并行组成,需要同时处理图像序列和光流图像,对计算资源要求较高,且两个网络的融合方式和策略的不同也会对性能产生较大的影响。CNN 分为2D CNN 和3D CNN,2D CNN 经常被用于处理和分析二维数据(比如图像),只能提取空间特征;3D CNN可以同时提取时空特征,但是训练模型时需要更多的计算资源和更大的数据集,会出现计算复杂度高、内存消耗大等问题,并且随着网络层数的增加会出现梯度消失和梯度爆炸问题。残差网络ResNet[3](Residual Network,ResNet)是一种特殊类型的卷积网络,允许信息在网络中容易地进行流动,有助于解决层数增加而网络性能越差的问题。
RNN 引入循环结构来对序列中先前的信息进行建模,用于处理序列数据,但是在处理长序列时可能会遇到梯度消失或爆炸问题,为了解决传统的RNN 问题,引入门控机制来控制信息的流动和遗忘,代表模型有长短期记忆网络LSTM(Long-Short Term Memory)和门控循环单元GRU[4](Gated Recurrent Unit),而GRU 较少的门控数量使得它在某些情况下对于处理较短序列的任务来说是一个更轻量级的选择。
视频流环境下的动作识别是目前各位学者的重要研究方向,其识别包括时空两个维度的特征提取[5],使用单一网络很难取得良好的识别效果,因此很多学者会融合多个模型的特点提出新的网络模型。为了解决传统网络模型层数增加,网络性能更差的问题,以及更好地获取到视频之间的上下文信息,本文提出了一种基于残差网络(Residual Network,ResNet)与GRU 的动作识别模型G-ResNet。
1 时空特征提取
■1.1 空域特征提取ResNet
2015 年Kaiming He 等人在论文《Deep Residual Learning for Image Recognition》中提出残差网络ResNet,其通过引入残差块和跳跃连接,解决了深度神经网络退化的问题。残差网络的基本结构如图1 所示。

图1 残差结构
从图1 中可以看出相比于之前增加了一个恒等映射,这样便很好的解决了由于网络层数的增加而带来的网络梯度不明显的复杂问题,因此残差网络可以把网络层数做的很深。到目前为止网络的层数可以达到上千层,同时又能保证很好的训练效果;并且简单的层数叠加也并未给整个网络的训练增加额外的参数,与此同时也提高了网络训练的效果与处理数据的效率。本文进行空间维度特征提取的网络是ResNet 34,该网络的具体参数如表1 所示。
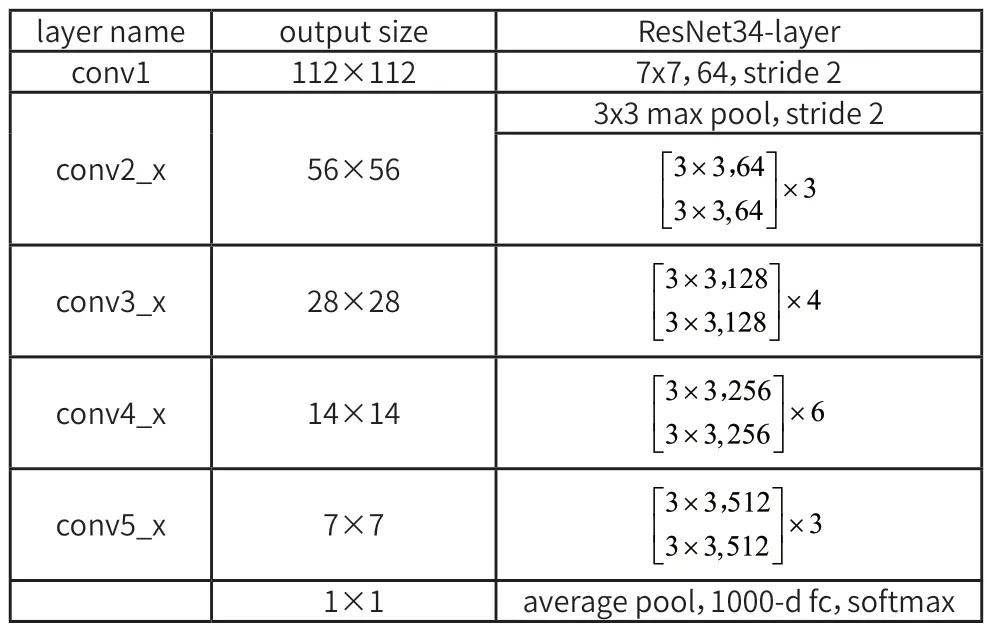
表1 ResNet34网络结构参数表
■1.2 时域特征提取GRU
2014 年Cho 等人在论文《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》中提出GRU,其能够建立视频序列间的依赖关系,在时间序列问题方面表现良好。本文使用GRU 进行时序特征的提取,该网络主要包括两个门模块,更新门决定了过去时刻的隐藏状态对当前时刻的影响,重置门决定了过去时刻的隐藏状态在当前时刻所需的重置程度。GRU 的结构图如图2 所示。
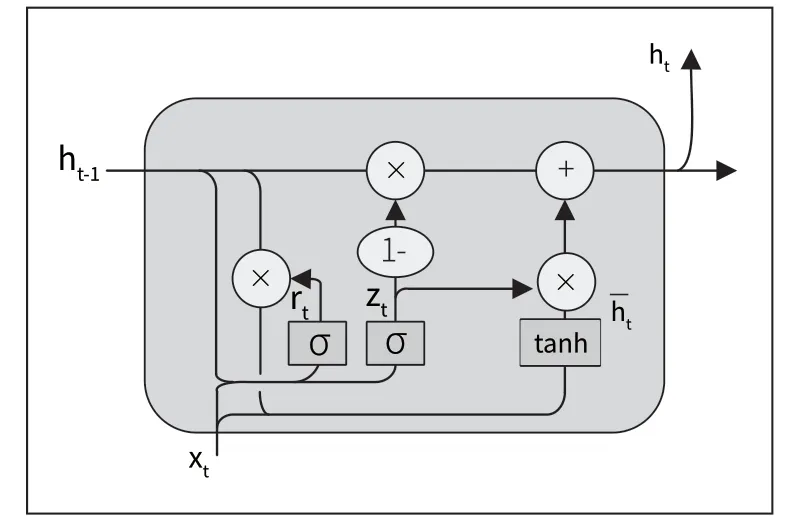
图2 GRU 门控循环单元结构
在图2 中,zt代表更新门,rt代表重置门。其中zt的取值范围是0 到1,值越接近于0 说明越依赖于过去的隐藏状态,而忽略当前的信息;值越接近于1 说明会更多的利用当前的输入信息来更新隐藏状态。rt的取值范围是0 到1,值越接近0 说明过去的信息越倾向于被丢弃;值越接近于1 说明越倾向于保留更多的过去信息。根据图2 的GRU 单元结构图,则前向传播公式为:
在上述的公式中,[ ]表示两个向量相乘,*表示矩阵的乘积。
GRU 网络的分类模型如图3 所示。
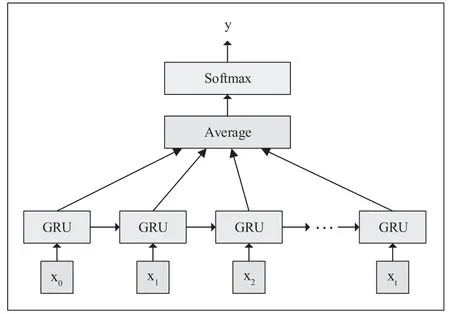
图3 GRU 分类模型
在图3 中,x1、x2...为输入层,即特征向量,使用GRU进行特征提取,对提取到的特征进行加权操作,然后对加权之后的特征进行全连接操作,最终得到分类预测结果。
2 网络模型G-ResNet
■2.1 模型设计
本文的G-ResNet 网络模型包含两大基本构成:图像的空间特征提取模块、帧之间的时序信息提取模块。视频动作识别算法整体框架如图4 所示,首先进行视频帧提取,对进行图像预处理,然后利用深度残差网络ResNet34 提取深层空间特征,GRU 网络获取视频的时序信息,对G-ResNet 模型进行训练,最后使用训练好的模型完成视频流的动作识别。

图4 基于G-ResNet 网络的动作识别算法框架
对于视频流中动作的识别,本文采用ResNet34 与GRU 结合的方式进行,首先将图像视频输入到ResNet34中提取空间维度特征;然后将提取到的特征输入到GRU 中,用于时序信息的提取建模;接着对提取到的特征进行加权操作,将加权之后的特征进行全连接操作,最终得到分类预测结果。建立的G-ResNet 网络模型如图5 所示。
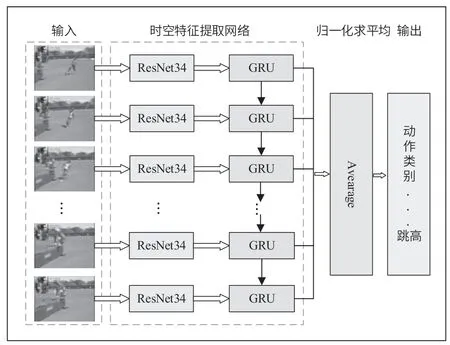
图5 G-ResNet 网络模型结构
■2.2 模型训练损失函数
损失函数CrossEntropy(交叉熵损失函数)在计算损失时会将预测值和真实值直接比较,要求预测值必须无限接近真实标签的one-hot 编码形式,然而one-hot 编码会导致网络评估时对于类别的预测非常自信,忽略其他类别的可能性,会使得模型对于噪声或者异常样本过度敏感;而SmoothCrossEntropy(标签平滑交叉熵损失函数)通过对标签平滑来缓解这种情况,它将one-hot 编码转化为概率分布,这样每个类别不再是非此即彼,可以取到介于0 到1 之间的值,这样的操作可以增加模型对于不确定性的鲁棒性、减少过拟合、提升分类性能。因此在第三次训练时将损失函数CrossEntropy 转换成SmoothCrossEntropy,目的是让预测值向真实结果靠拢。
对多分类问题一般采用Softmax 方法。首先将数据(即视频图像)输入到架构好的网络模型中提取特征,计算出输入数据所属类别的置信度范围,然后使用激活函数Softmax 将输出转化为概率分布,即对应各个类别的概率值,如式(6):
式(6)使用交叉熵函数来计算损失值,其中i表示多类中的某一类,公式为式(7)、式(8):
最后,对预估的概率和分类所属真实概率的交叉熵进行最小化操作,得出最优估计概率的分布,公式如式(9):
在训练过程中,模型会趋向于正确和错误分类相差较大的范围。当样本数据较少时就会出现过拟合现象,而Label Smoothing(标签平滑)通过引入噪声、将标签转化为概率分布形式等操作,达到减少过拟合、缓解标签不确定性的目标,变换过程如式(10):
其中K表示多分类的类别总数,ε是一个较小的超参数。
与之对应,将交叉熵损失函数作如式(11)的改变:
同理,将最优的预测概率分布作如式(12)的改变:
代表任意的实数,最后是经过弱化正、负训练数据输出之间的一个范围差,使模型的泛化效果更强、性能更稳定。
3 实验与分析
实验环境:Intel(R) Core(TM) i7-11390H CPU @3.40GHz的PC 机,Windows11 64 位操作系统,通过xshell 和xftp远程连接服务器基于Ubutun 系统,OpenCV 版本4.2.0,采用Pytorch 框架,Python 开发语言编程实现。使用两个公开的数据集UCF101、HMDB51 验证G-ResNet 网络模型的识别效果。
■3.1 视频数据预处理
(1)图像插值化处理
数据清洗、特征转换、简单缩放等操作都是数据预处理的常用方法,其中数据清洗用于去除噪声、处理缺失值等,确保数据的完整性和一致性;特征转换是通过数学变换将原始特征转换为更具有可分性或表示能力的新特征;简单缩放用于将数值型特征的取值范围缩放到一个较小的区间内。对于单一动作数据而言,其是一组包含时序信息的图像,且每个动作持续的时间也是不一致的,为了方便计算提高效率,需要对图像队列做插值化处理进行缩放,最终选择缩放到16 张。
(2)数据增强
数据增强技术是通过对原始训练数据进行变换和处理,生成新的训练样本来扩充数据集的方法。在网络训练过程中,为了使模型具有更好的鲁棒性、泛化能力和对不同场景的适应能力,需要对数据进行增强。常用的数据增强技术包括平移、旋转、缩放、剪切、增加噪声、弹性变形等,本文对数据增强的具体操作如下:
①图像颜色的增强,包括饱和度、亮度、对比度等。
②图像大小的剪切,偏移中心点,并裁剪出固定大小的区域图像。
■3.2 网络训练策略
G-ResNet 网络模型使用三次训练优化,以达到最优效果,具体网络训练策略如图6 所示。

图6 网络训练策略原理
(1)第一次训练时,输入16 张连续的图像,并将图像缩放至88×88,目的是得到较大的Batch Size,加快模型训练速度,降低训练过程中的噪声影响。接下来对16 张图像使用3D-CONV 进行特征预提取,输入尺寸为(Batch Size,16,88,88),卷积后尺寸为(Batch Size,16×64,44,44),变形为(Batch Size×16,64,44,44),把temestep 维合并到batchsize 维,目的是使用2D-ResNet34进行二维卷积,timestep 维数据则保留到GRU 模块再处理。
(2)第一次训练完成后,将得到的权重值初始化第二次训练的模型。与第一次训练模型不同,将Back-end 模块的1D-conv 替换成GRU,输入图像尺寸为(224×224),以便学习到更多的特征信息,同时固定红框内的模块参数。
(3)使用第二次训练得到的权重来初始化第三次训练的模型,与第二次训练模型不同,将Loss 模块的损失函数CrossEntropy 替换成SmoothCrossEntropy,输入图像尺寸为(256×256),以便学习到更加细微的特征信息。
第三次训练完成后,即可得到G-ResNet 模型。
■3.3 实验结果与分析
针对G-ResNet 模型的训练,本文将数据集UCF101 和HMDB51 以9:1 的比例划分为训练集和测试集分别进行训练、测试,训练过程的损失值和识别准确率变化如图7、图8 所示。
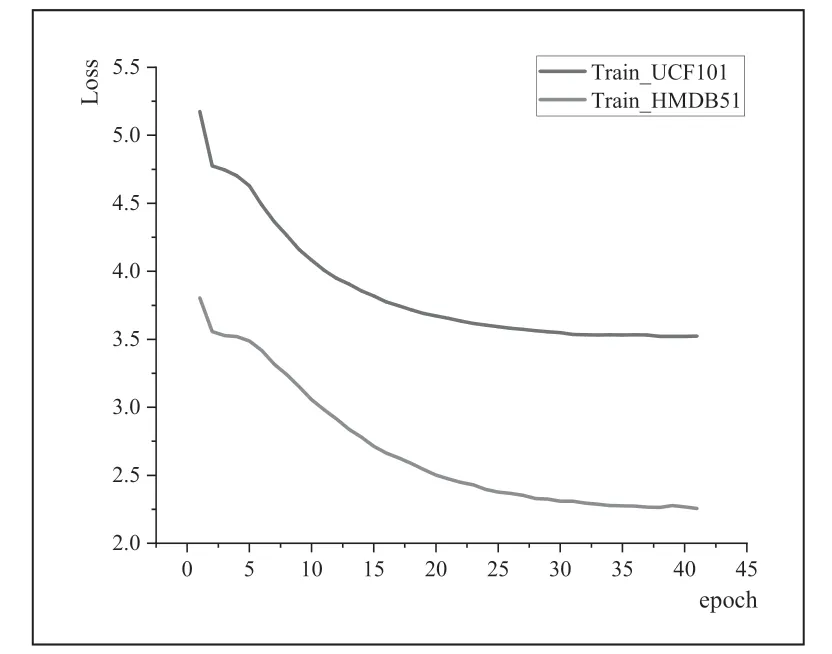
图7 UCF101 和HMDB51 数据集变化损失
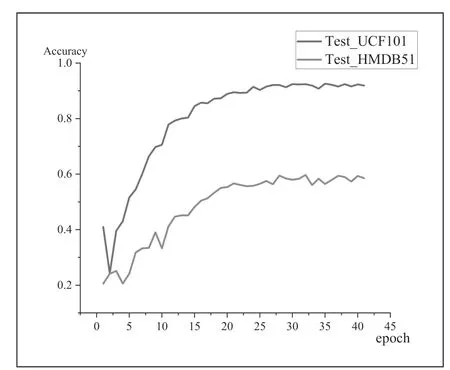
图8 UCF101 和HMDB51 测试集准确率变化曲线
图7 为G-ResNet 模型在UCF101 和HMDB51 在 训练过程中的损失值变化,从图中可以看出,随着训练轮次的增加,损失值不断减小,最终趋于平稳,说明网络模型已经接近了最优解,即分类结果逐渐趋于正确。图8 为G-ResNet模型在训练过程中的准确率变化,从图中可以看出,随着训练轮次的增加,准确率逐渐增加,最终趋于平稳,说明网络模型已经达到相对稳定的性能水平。
为了更加直观的看到G-ResNet 模型性能上的优势,本文将C3D[6]、Veep deep two stream[7]、LRCN[8]、P3D[9]、ST-ResNet[10]等模型在UCF101 和HMDB51 数据集上进行测试,并与G-ResNet 模型进行对比,各模型识别的准确率如表2 所示。
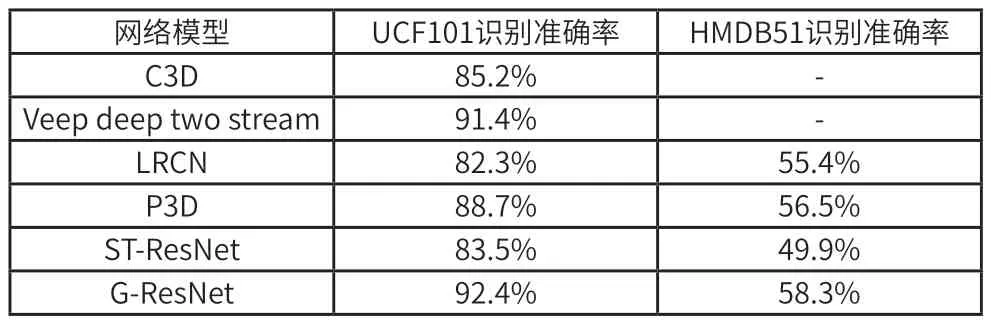
表2 人体动作识别准确率对比
从表2 可以看出,G-ResNet 模型在UCF101 和HMDB51数据集上的识别准确率明显高于其他网络模型,说明基于深度残差网络与门控循环神经网络的G-ResNet 能够很好的应用于视频领域的动作识别。
4 总结
本文提出了一种基于视频流的人体动作识别的网络模型G-ResNet,该模型使用深度残差网络ResNet34 提取空间域特征信息,使用循环神经网络GRU 提取时间域信息进行建模。实验结果表明,G-ResNet 模型在一定程度上提高了识别准确率,但是该方式的对输入图像进行了一系列的裁剪、拉伸操作,改变长宽的比例,可能会导致某些特征不被注意到。在后期的研究中,可以探寻如何在输入任意尺寸图像,或者即使修改了图像的大小,也能提取足够多的特征,提高识别准确率。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
河南科技(2015年8期)2015-03-11 16:23:52
