
模糊规则在神经网络预测模型中的应用前景
2024-01-26 03:06:54刘雪娇
科技和产业 2023年24期
华 龙, 齐 冲, 刘雪娇
(1.北京市轨道交通运营管理有限公司, 北京 100070; 2.北京市地铁运营有限公司通信信号分公司, 北京 100082)
在使用实际的日照强度数据,依托神经网络,基于气象数据可以使太阳能发电系统输出功率的预测精度达到4.37%[1]。对于使用实际的日照强度,是基于对日照强度日趋完善的各类模型[2]而进行的一种假设。而建立预测模型的初衷则是利用比较容易入手的天气预报数据,寻找可以根据少量数据进行预测的方法。因此,在不进行人为减少误差的前提下,进一步探寻改善模型精度的方法则是未来的研究方向。
在已构建的神经网络模型中,引入模糊规则[3],对云量数据重新定义。通过云量数据的改善进而影响日照强度的精度,达到提高整体预测模型精度的目的。
1 研究背景
1.1 背景分析
全球“碳中和”战略背景下,光伏行业发展潜力巨大。太阳能作为可再生能源的重要组成部分,拥有诸多优势,是中国乃至世界未来新能源发展的主要趋势,长期发展空间广阔。
根据国际能源署[4]的报告,全球可再生能源发电能力在2020-2026年将增长60%,总发电量达到4 800 GW,其中太阳能光伏发电将占到增长量的60%。到2026年,可再生能源将占全球新增发电量的95%。
因此,开展太阳能发电量预测研究具有重要的现实意义。该研究有助于更好地了解太阳能发电量的影响因素和变化规律,为太阳能发电的规划和调度提供科学依据,促进可再生能源的发展和可持续发展目标的实现。
1.2 预测分析
在早前的预测手段中,可以确定日照强度对发电量的预测精度起到决定性作用。在日照强度确定的情况下,最好的结果误差仅为4.37%。从而可以得到为了预测第二天的发电量,使用预报数据,特别是预报的日照强度,将大大提高预测结果的精度。
在后续作为输入量加入的云量数据,导致预测精度增加了约2.13%的误差,但从预测曲线图中可以看到预测曲线的近似并没有发生明显的变化。这被认为是云量数据自身的误差引起的。
1.3 预测改进方法
由于所使用的云量数据从每3 h的数据简单地按照每1 h进行修改。因此,云量数据本身会产生一些误差。大量的资料表明,在预测中加入模糊理论会使预测结果有所改善[5]。
在本次的建模中,在云量数据的处理过程中加入模糊规则,在全面考虑模糊的基础上,探讨提高预测精度的可能性[6]。
2 模糊逻辑
模糊逻辑(Fuzzy Logic)是1965年由加州大学伯克利分校罗特菲·扎第(Rotfy Zaday)产生的模糊集合衍生出来的一种多值逻辑,其特点是真值取0到1的值,不像古典逻辑那样局限于“真”和“假”这两个值。模糊逻辑被应用于从控制理论(模糊控制)到人工智能等各个领域。
模糊逻辑,与“真实程度”相对应。基本应用程序可以表征连续变量的部分范围。例如,模糊应用程序由输入层、推理层、组合层和输出层四个层组成。对模糊系统的输入构成第一层。在下一层中,通过输入创建模糊集合,并将其结合在一起,如式(1)中的规则所示。
Rule: Ifxisaandyisb, thenz=f(x,y)
(1)
式中:a和b是模糊集合的前项;z是其结果。由基于模糊逻辑的规则输出凝聚构成组合层。最后,结果是非模糊的,在输出层生成,是一个非模糊的值。
神经网络具有强大的非线性映射能力,能够自适应地处理复杂的输入、输出关系。然而,传统的神经网络模型通常缺乏对不确定性的处理能力,这使得它们在处理复杂实际问题时可能受到限制。
模糊规则基于模糊集合理论和模糊逻辑,能够有效地处理不确定性问题。模糊规则的优点在于它们可以表达不确定的边界和模糊的规则,这使得它们在处理某些复杂的实际应用场景时具有优势。
在神经网络中引入模糊规则,可以有效地提高神经网络对不确定性的处理能力[7]。例如,可以将模糊规则用于构建模糊神经网络,这可能有助于提高神经网络的鲁棒性和自适应性。
另外,模糊神经网络也为模糊规则的应用提供了新的可能性。例如,通过构建多层的模糊神经网络,可以将复杂的模糊规则编码到网络的权重和结构中,从而实现更为复杂的模糊逻辑运算[8]。
在所提案的模型中,模糊逻辑被用来识别不同的云量。定义基本的模糊规则如式(2)所示。
Rule:If cloud cover isA, and solar radiation is
Band temperature isC, then use NNA,B,C.
(2)
式中:A为云量数据;B为日照强度;C为气温;NNA,B,C为A·B·C条件下的神经网络。云量数据包括晴天、多云、阴天三个。日照强度为在各自云量下对应的数值,气温是预测时间的平均气温。
3 太阳能发电量预测方法
3.1 预测数据
考虑数据的质量将直接影响到预测结果的准确性,再通过对设备所收集的数据进行筛查、选择,确定最优数据组。
所选择的数据是从2014-2015年两年间每小时的天气信息和云量信息。输入数据为气温(℃)、日照强度(kW/m2)、云量信息等,输出数据为发电量(kW/h),学习时间为2014年1月1日至2015年12月29日,测试时间为2015年12月30日和12月31日。目标是次日每小时的发电量。
3.2 云量数据
云量是指云在天空中所占的比例。根据气象局定义分为从“0”到“10”的11个阶段,0~4定义为晴,5~8定义为多云,9~10定义为阴天。
实际的云量数据使用气象局发布的每3 h的云量数据。由于学习和测试数据都是以1 h作为基数的,所以为了使数据达到相同的标准,对云量数据进行了修正。
对于修正的方法,假设3 h中云量是恒定的,选用开始时间的数据(表1)。
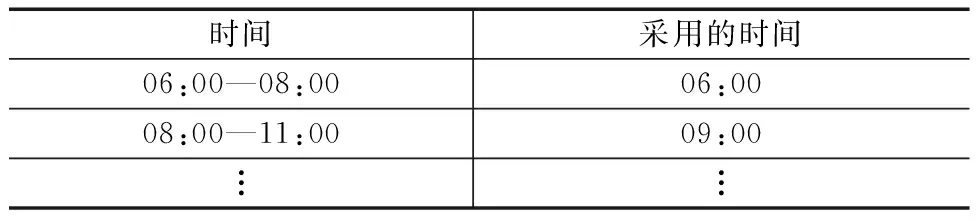
表1 修正后的各小时实际的云量
3.3 模糊规则模型
三个模糊集被定义为晴天、多云和阴天,这些都是基于典型的云量等级。如图1所示,左侧表示晴朗模糊集合,中间表示部分多云模糊集合,右侧表示多云模糊集合。
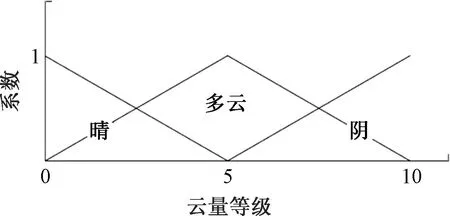
图1 模糊集合
由图1可知,云量为2时,云量为晴天模糊集合的对应值为0.6,多云模糊集合的对应值为0.4,阴天模糊集合的对应值为0。在各模糊集合之间,基于各条件下的神经网络,来预测未来时间的太阳能发电量。
3.4 神经网络模型
这次使用的神经网络是RBF神经网络(radial basis function network,RBFN)。天气信息将晴天、多云、阴天作为天气信息的输入量,将云量的等级作为云量的输入量,建立一个神经网络。
虽然对云量等级进行了划分,但因不同等级间的边界问题,使得预测结果仍然存在不确定性。因此,在预测过程中,需要对云量的定义进行综合的考虑,即对云量数据进行模糊处理。
整个模糊过程,将云量的级别输入晴天、多云、阴天的模糊集合,根据模糊规则定义的云量的级别作为云量进行输入,将所有的输入量输入神经网络,通过去模糊化后作为输出进行输出。
如上述的流程一样,发电量的预测是根据气温、日照强度和云量信息,通过不同的神经网络进行学习,预测第二天的发电量。
4 仿真结果
4.1 仿真环境概况介绍
为了验证有效性,添加经过模糊处理的云量信息,进行仿真。在仿真模型建立的过程中,采用一种利用神经网络从气象信息(温度和云量)预测第二天太阳能发电系统输出的方法,如表2所示。
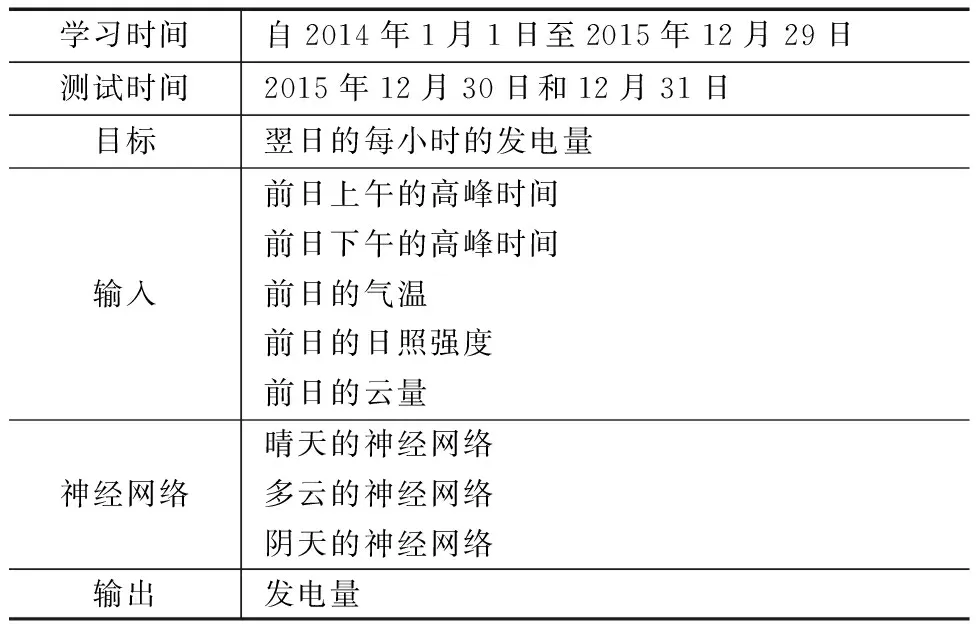
表2 基于模糊云量信息的仿真信息
考虑到应用的可行性,选用常见的PC机作为操作平台,操作环境如下。
OS: Windows 7 SP1 64-bit。
处理器: Intel(R) Core(TM) i7-4710MQ 2.50 GHz。
内存:16 GB。
仿真软件为MatlabR2013a(8.1.0.604)及Neural Network Toolbox Version 8.0.1 (R2013a) 13-Feb-2013。
4.2 结果分析
根据简单的模糊规则,预测结果的误差为16.64%。近似曲线如图2所示。
而早前的预测模型[1]中,未经模糊处理的模型预测精度为16.86%,近似曲线如图3所示。
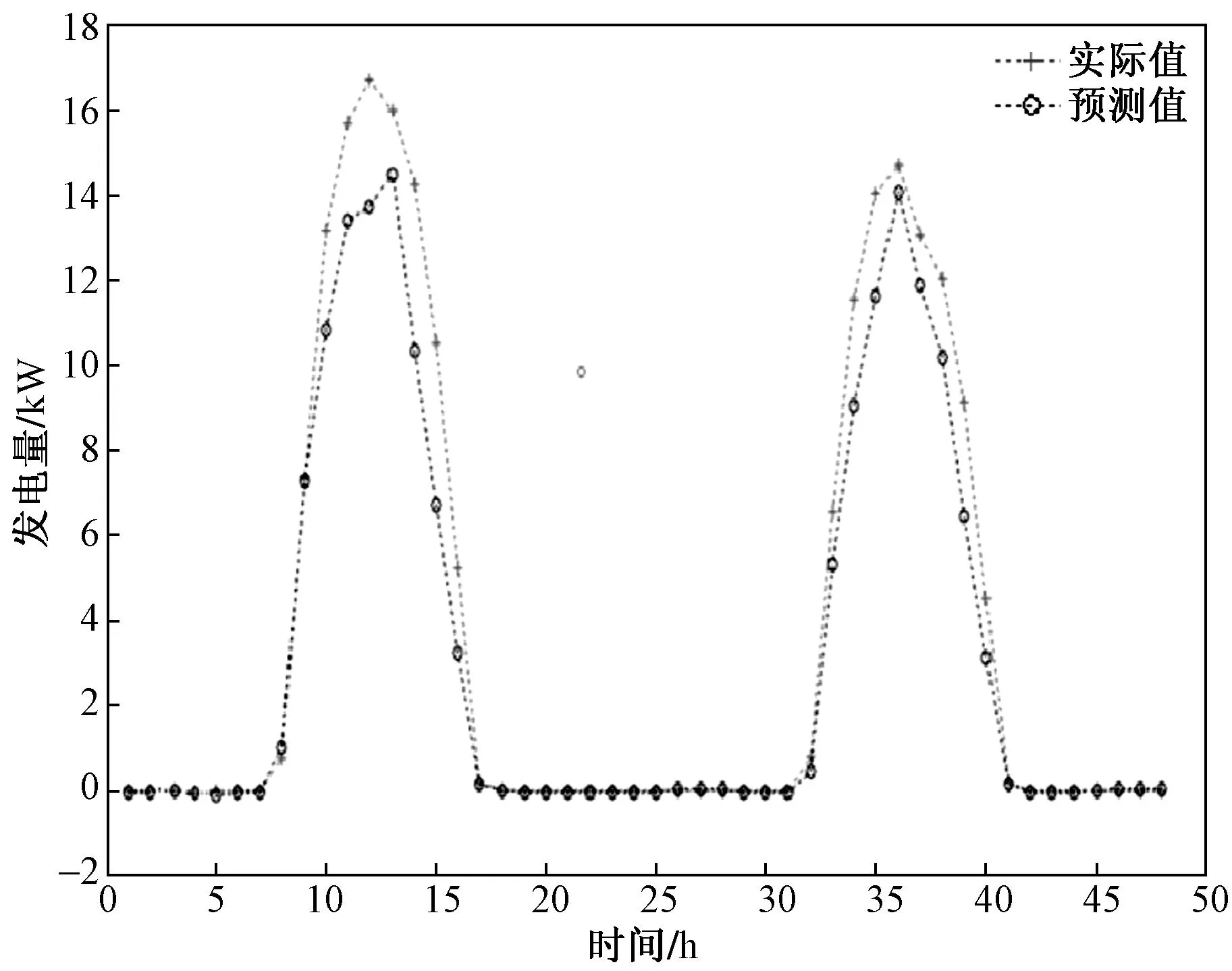
图3 基于云量数据的太阳能发电量预测仿真结果
与图3的16.86%相比,加入了模糊处理的预测精度相较之前相差无几,仅提高了0.22%。这种结果可能是由于数据集的特性或者模型的限制,使得模糊处理的效果并不明显。例如,可能无法完全捕捉到天气变化的复杂性,或者无法完全解决数据的不确定性和噪声等问题。此外,天气状况的不同也可能影响预测的准确性,例如在某些特定的情况下,模型的预测可能会更准确。在对预测模型进行验证的时候也可以发现相较于多云和阴天,晴天的情况下预测精度会有较大幅度的提高,这是因为晴天的天气状况相对较为稳定和可预测,因此模型可以更好地学习和模拟这种规律性。
尽管预测精度的提高并不显著,但模糊规则的加入对预测曲线的形状和近似程度产生了较大的影响。这主要是因为模糊规则的加入能够更好地处理诸如云量数据中对于晴天、多云、阴天等定义的不确定性和模糊性,使得更接近真实的天气状况,从而在预测曲线中生成更为平滑和准确的预测曲线。因此,可以认为加入了模糊处理的模型更好。
在实际的预测系统中,不同的天气状况会对预测结果产生影响,这些天气状况很难用精确的数值来描述。在这种情况下,加入模糊规则可以帮助模型更好地理解和处理这些复杂的、不确定的情况,从而提高预测精度。
从预测的结果中也可以看到,在后续的改善中进一步探索更有效的模糊处理方法,并增加历史的数据量,可以让模型更好地处理天气预测中的不确定性和模糊性,相信预测精度是可以提高的。同时,对于预测模型来说,通过对比,认为本提案手法对太阳能发电预测的精度是有改善的。
5 结论及未来的发展方向
5.1 结论
针对太阳能发电输出的预测,基于天气预报数据的预测方法,主要是利用太阳能发电和天气之间的相关性,通过分析历史数据和天气预报的数据,预测未来的太阳能发电的输出量。这种方法的优点是相对简单易行,对于硬件的要求并不苛刻。通过采用不复杂的手法、活用比较容易入手的天气预报数据、能够根据少量数据进行预测的方法等为目的,进行了大量的仿真实验,研究了适用于太阳能发电系统的输出预测方法。由此,在将来大量引进太阳能发电的电力系统中,也能够保持供求平衡,维持稳定性。
而且,从少数数据中,可以不考虑太阳光发电设备的设置状况和太阳能电池板和功率调节器的特性,根据得到的云量和日照强度来预测太阳能发电的输出。
鉴于此,本文提出了利用模糊神经网络作为载体,利用基于云量数据的模糊规则,模糊神经网络能够将云量数据分解为晴天、多云和阴天三个部分,然后通过神经网络模型使用典型的云量等级来进行预测,最后再将晴天、多云和阴天三个部分合并得到最终预测结果。这种方法对于处理具有不确定性和模糊性的云量数据特别有效,能够提高预测的准确性。从结论上也可以看到,在加入了模糊规则后,新的神经网络预测模型结果与早前的预测模型相比具有更好的预测性能,应进一步深入研究。
5.2 未来的发展方向
5.2.1 每3 h的预测
由于所使用的云量数据基于气象局每3 h发布一次的数据,之后为方便预测从每3 h的数据简单地按照每1 h进行修改。因此,云量数据本身可能会产生一些误差。在后续的改善中,将以每3 h为单位进行预测,从而探究提高预测精度的方法。
5.2.2 模糊规则的完善
从结果来看,将模糊逻辑与神经网络算法结合可以使整个系统更加有效,预测结果可以得到一定程度的改善。通过增加模糊规则的数量,以覆盖更多的输入情况。对于无法处理某些边界情况,可以添加额外的规则来处理。再者,对于现有较为简单的模糊规则,可以细化它们以更好地适应各种输入。总的来说,模糊规则的完善的改进是一个持续的过程,需要不断地根据实际应用场景和需求进行调整和优化。
5.2.3 输入选择的改进
为了提高预测精度,可以尝试在每3 h的数据中加入更多的输入数据。可以尝试加入与天气相关的特征,如最高温度、最低温度、降雨量、湿度和风速等,或者是调整神经网络的层数、每层的神经元数量、学习率等模型参数。这些特征可以用于训练预测模型,以进一步提高预测精度。但考虑到模型学习过程中对计算资源的要求,在实践中,需要根据具体的问题随时调整特征选择和模型选择,以保证精度的同时减少计算资源。
5.2.4 多模型融合
归功于近年来技术的快速发展,采用人工智能、机器学习等方法后,目前短期负荷预测的研究已经越来越广泛。
闫静[9]提到了基于Fisher信息的在线支持向量回归模型具有更高的预测精度,更适用于短期负荷预测尤其是超短期负荷预测。刘阿慧[10]也证明了所提深度学习组合模型能高效挖掘光伏数据间潜在的非线性关系,在光伏发电区间预测方面具有优越性。
在确保对每个模型都有充分了解下,规避模型的过度拟合,将不同的预测模型进行融合,可以提高预测的准确性和稳定性,这将是未来预测技术的发展方向。
猜你喜欢
农业灾害研究(2022年5期)2022-08-12 05:36:12
气象科技(2022年2期)2022-04-28 09:35:46
矿山安全信息(2022年34期)2022-04-07 10:22:51
作文周刊·小学一年级版(2020年20期)2020-09-02 07:17:56
中国煤炭(2020年2期)2020-01-21 02:49:28
水电站设计(2018年3期)2018-03-26 03:52:32
作文评点报·低幼版(2018年2期)2018-02-09 16:18:14
现代农业科技(2018年1期)2018-02-03 16:32:58
小学生作文·小学低年级适用(2016年4期)2017-01-16 11:00:53
电站辅机(2016年4期)2016-05-17 03:52:38
