
基于区块链共识激励机制的新型联邦学习系统
2024-01-25 12:20黄大荣
信息安全学报 2024年1期
米 波,翁 渊, 黄大荣, 刘 洋
基于区块链共识激励机制的新型联邦学习系统
米 波1,翁 渊1, 黄大荣1, 刘 洋1
1重庆交通大学 信息科学与工程学院 重庆 中国 400074
随着云存储、人工智能等技术的发展, 数据的价值已获得显著增长。但由于昂贵的通信代价和难以承受的数据泄露风险迫使各机构间产生了“数据孤岛”问题, 大量数据无法发挥它的经济价值。虽然将区块链作为承载联邦学习的平台能够在一定程度上解决该问题, 但也带来了三个重要的缺陷: 1) 工作量证明(Proof of Work, POW)、权益证明(Proof of Stake, POS)等共识过程与联邦学习训练过程并无关联, 共识将浪费大量算力和带宽; 2) 节点会因为利益的考量而拒绝或消极参与训练过程, 甚至因竞争关系干扰训练过程; 3) 在公开的环境下, 模型训练过程的数据难以溯源, 也降低了攻击者的投毒成本。研究发现, 不依靠工作量证明、权益证明等传统共识机制而将联邦学习与模型水印技术予以结合来构造全新的共识激励机制, 能够很好地避免联邦学习在区块链平台上运用时所产生的算力浪费及奖励不均衡等情况。基于这种共识所设计的区块链系统不仅仍然满足不可篡改、去中心化、49%拜占庭容错等属性, 还天然地拥有49%投毒攻击防御、数据非独立同分布(Not Identically and Independently Distributed, Non-IID)适应以及模型产权保护的能力。实验与论证结果都表明, 本文所提出的方案非常适用于非信任的机构间利用大量本地数据进行商业联邦学习的场景, 具有较高的实际价值。
联邦学习; 区块链; 共识算法; 模型产权保护; 投毒攻击
1 引言
大数据驱动的人工智能技术有助于在整体上生成高精度泛化模型, 但在实际应用过程中却往往存在着数据来源不足的状况[1-2]。作为一种新兴的机器学习框架, 联邦学习(Federated Learning, FL)可以在节点数据孤立的情况下实现分布式模型训练, 在一定程度上解决机器学习过程中的数据稀缺问题。此外, 由于这种方案[3]能够在人工智能模型的训练过程中将数据离线, 因而也具有数据隐私保护和节省带宽的能力。随着智能边缘设备的普及和性能提升, 移动网络的计算能力不断增强, 联邦学习在智慧交通[4]、智慧城市[5]、商业数据挖掘[6-7]等领域都得到了广泛的应用。目前联邦学习已经与很多行业相融合, 且在区块链、模型水印等技术的促进下不断赋予新的功能[8], 对实际生活产生了良好的经济效益和社会价值。
在信息化时代, 大数据背景下的数据隐私问题愈来愈受到人们的关注。由于数据与生活、生产的关联性日益增强, 隐私泄露问题必然会遭到社会的广泛抵制, 信息价值开发和敏感数据保护之间的矛盾正不断显现[9]。例如, 2020年12月, “明星健康宝照片泄露”事件中大量用户个人数据被非法贩卖, 引起我国公安机关的高度警觉和公众的广泛讨论。2017年6月1日起实施的《中华人民共和国网络安全法》指出不得泄露、篡改用户数据, 且自2020年以来《数据安全法》、《个人信息保护法》相继出台, 这也充分说明了国家对数据隐私保护的重视。
针对机器学习中存在的数据安全风险, 学者提出了一系列的隐私保护方案, 主要包括联邦学习、多方安全计算(Secure multiparty computation, SMPC)[10-11]、同态加密(Homomorphic encryption, HE)[12-13]和差分隐私(Differential privacy, DP)[14-15]这几类主流技术, 其中联邦学习采用的分布式离线训练方法能够在隐私保护的同时有效节省通信及计算资源, 非常适用于数据量大、数据源分布广、信息敏感度高的场景。
联邦学习的概念最初出现于文献[16], 逐步演化为纵向联邦学习[17]、横向联邦学习[18]和联邦迁移学习[19]三种基本框架。其中, 纵向联邦学习主要适用于参与方数据记录大量重合的场景, 而横向联邦学习主要考虑节点间数据特征基本相同的情况, 当参与方的样本空间有部分重叠但特征不尽相同时联邦迁移学习则更为适合。在算力不均衡的可信任环境中, 上述三类方案往往采用C/S(客户/服务器, Client/ Server)模式予以实现。正是因为充分利用了吞吐量高、性能优异的设备作为中心节点, C/S模式相较于分布式学习具有训练效率更高、利益分配更均衡、本地数据更安全等优势。然而, 在非信任环境下, C/S模式的联邦学习方法极易遭受身份伪造、数据篡改、拒绝服务(Denial of Service, DoS)等攻击的威胁。为解决这些信任问题, 文献[20]提出一种基于区块链的联邦学习方案, 将抽象的可信服务节点实例化为分布式的共识激励机制; 文献[21]将联邦学习中的梯度作为一部分贡献, 结合Algorand共识协议提升了激励的公平性。文献[22]中通过降低联邦学习中的交互参数以保证用户的匿名性从而降低收到攻击的风险。
图1展示了基于链上共识的联邦学习整体框架。该框架中的节点可同时或分别扮演数据提供者和区块挖掘者两种角色。所有参与者在本地数据集上完成子模型的训练, 随后将其上传至随机选择或投票选举出来的矿工。矿工负责对所有本地模型进行验证与融合, 然后根据PoW或PoS共识机制产生新的区块。这些区块要负责记录矿工的挖矿奖励和数据提供者的贡献奖励, 并存储模型更新后的参数。随后, 参与者将聚合后的模型再次下载, 不断地重复上述过程直至得到满意的全局机器学习模型。由此可见, 这种机器学习方法的本质在于间接的数据共享和有效的合作激励, 因此共识算法的可靠性和奖励机制的公平性会直接影响整个系统的性能。

图1 基于区块链的联邦学习框架
Figure 1 A federated learning framework based on blockchain
尽管基于共识的联邦学习方法有助于建立起参与节点间的广泛信任, 但现有方案仍普遍存在着以下三方面的缺陷:
1) 资源浪费问题。文献[23]指出, 将区块链作为联邦学习过程中数据和模型的载体, 主要是为了保证相关信息能够被可靠地记录及追溯。然而, 由于PoW[24]、PoS[25]等“挖矿”行为与联邦学习过程的收敛性并无直接关联, 共识机制的引入会直接导致大量算力和带宽被浪费。
2) 节点活性问题。在实际生产环境中, 节点数据和计算资源都是具有一定经济价值的。在某一节点发起联邦学习的模型训练后, 其他节点可能会因为利益的考量而拒绝或消极合作, 甚至会因为竞争关系投入虚假数据对模型进行干扰, 最终导致全局模型无法使用或训练过程无法收敛。
3) 攻击手段的多样性问题。尽管联邦学习领域正不断引入各种新的机制来对抗日益多样化的攻击手段, 但大都针对片面的安全目标[26]。与传统机器学习所面临的威胁类似, 模型攻击[27]、投毒攻击[28]、后门攻击[29]、推理攻击[30]等方法在联邦学习中也主要是对数据隐私和全局模型进行破坏。事实上, 联邦学习在一定程度上具有数据隐私保护的特性。因此, 安全机制的实现不应当以攻击手段为驱动, 而需要将数据保密性和模型准确性作为根本目的。
联邦学习的商业场景往往具有参与节点数量少、合作关系松散耦合的特点。此外, 非信任分布式环境的物理脆弱性和攻击来源的多样性极有可带来节点丢失、数据污染、模型篡改等隐患, 从而导致训练过程因无法准确收敛而失败。为此, 本文将针对节点数量有限、数据吞吐量大、互信程度低的跨企业分布式场景, 结合区块链及水印技术来构造一种全新的共识激励机制, 从而解决联邦学习中算力浪费、奖励不均以及鲁棒性弱的问题。总体而言, 其基本思想是借助区块链的一致性记录能力以及模型水印的版权保护机制, 将模型训练分发到多个节点上并行执行, 每轮结束后多个矿工将分别对收集到的本地模型进行聚合, 并根据评价准则在链上达成模型准确度和参与者贡献度的共识, 由此产生新的区块, 不断迭代直至获得期望的全局模型。在具体的实施过程中, 参与训练的节点会将自身的水印嵌入到梯度模型中用于证明所做出的贡献。为了争夺写入权限, 所有融合节点将利用所接收到的梯度构造一个能够让大多数节点都认可的全局模型。最终, 达成共识的全局模型将会由它的创造者写入区块。基于上述策略, 本文将Paxos共识协议[31]中的投票理念与联邦学习相结合, 构造出一种新型共识协议Paxos Federated Consensue(PFconsensue), 并通过高鲁棒性水印融合算法的设计, 最终形成一套可证明完备的联邦学习共识激励机制。
本文的贡献主要在以下几个方面:
1) 基于联邦学习的共识协议。将联邦学习的训练过程作为节点“挖矿”环节, 使消耗的资源转换成具有经济价值的人工智能模型。同时, 模型聚合采用去中心化与性能投票的方式进行, 克服了联邦学习中Non-IID[32]与投毒攻击所造成的全局模型性能下降的缺点, 实现了联邦学习与区块链技术的优势互补。
2) 公平的区块链共识激励机制。为提高联合训练的参与度, 依靠高鲁棒性模型水印技术和参数距离算法, 实现了公平的节点贡献度分配, 可以更好地刺激节点参与模型训练过程。在模型聚合环节, 将区块的写入权奖励给最优模型的创造者, 也能够充分地保证节点积极参与模型聚合。可见, 该区块链系统在本地训练和模型聚合两方面均保证了参与节点的活性。
3) 系统的整体完备性证明。从理论上了证明了共识算法的正确性, 并通过形式化方式分析了共识算法在拜占庭环境下的容错能力。同时, 通过实际数据的分布情况抽象出相应的约束条件, 分别讨论了该系统组成部分在实际环境中运行的有效性与稳定性。此外, 对系统的整体安全性也进行了充分的证明。
4) 实验仿真及分析。利用计算机模拟验证了共识协议的有效性。根据实际采集的“重庆市实时交通流”数据在多台设备间部署共识决策环境, 验证了本方案在现实环境中的可行性及准确性。此外, 基于系统性的区块链仿真, 进一步展示了本方案对联邦学习中潜在威胁的抵抗力。
2 系统整体模型
由于区块链具有不可篡改、易追溯和去中心化等优势, 与联邦学习相结合能够极大程度地克服联邦学习中所潜在的风险。对此, 本章节将基于PFconsensue协议、模型水印等技术构造整体的区块链系统, 并给出实际环境中的安全性形式化定义。
2.1 系统框架设计
当前已有部分研究人员将区块链用于解决联邦学习在非信任环境中的安全协同训练问题。文献[33]中选取区块链上的可靠节点来参与联邦学习, 并通过差分隐私技术以保证训练数据的安全。文献[34]则将联邦学习过程中的全局数据组织成“全局模型状态树”, 作为交易内容存储到区块链中。而文献[35]也类似地利用区块链存储联邦学习过程中的各种模型参数, 该方案还可以借助其他边缘设备来分担训练能耗。然而, 由于以上方案皆未考虑模型所具有的知识产权特性, 可能产生模型盗用现象, 也将导致参与方发生产权纠纷。另一方面, 依附于区块链的联邦学习会因为共识过程而造成大量的资源浪费, 导致节点参与度下降。为了解决上述两个问题, 本文设计了图2所示的联邦区块链结构。在该结构中, 链上记录的数据主要包括: (1) 上一个区块的Hash; (2) 融合后的模型参数; (3) 构造融合模型所使用的局部梯度集合; (4) 基于评价准则的产权奖励; (5) 下一轮训练的优化目标。

图2 本文区块链系统结构
Figure 2 The structure of the blockchain system in this paper
在协议开始时, 参与节点将会从区块链上获取公开发布的初始模型及训练目标, 并在本地训练出包含水印的梯度模型。随后, 节点会将梯度模型通过Gossip协议[36]进行广播, 并在收到足够的梯度信息后尝试通过聚合算法得到聚合模型。最后, 聚合模型会传送至各个节点进行评测, 投票产生的最优模型和下一轮协议的优化目标将被同时写入新的区块。考虑到数据的防篡改问题, 除分布式存储外还将借助Hash链式结构和最长链原则[37]来确保区块链的持久性。值得一提的是, 本方案在设计区块数据结构时将各个节点的梯度模型一并记录在区块上,这样可以确保聚合模型的可信度。
就节点活性而言, 由于区块链上的聚合模型保留有各参与方的梯度模型水印, 他们可以据此对调用该模型的第三方收取知识产权费。与此同时, 高鲁棒水印融合技术的使用还能够有效防止公开模型被盗用。可见, 该方案能够充分激励各个节点参与联邦学习过程。
更进一步地, 本文对上述区块链的整体构架进行如图3所示的逻辑刻画和分层设计。节点之间主要负责构造区块链数据服务, 而第三方只需通过API接口发布模型需求或对模型进行调用。
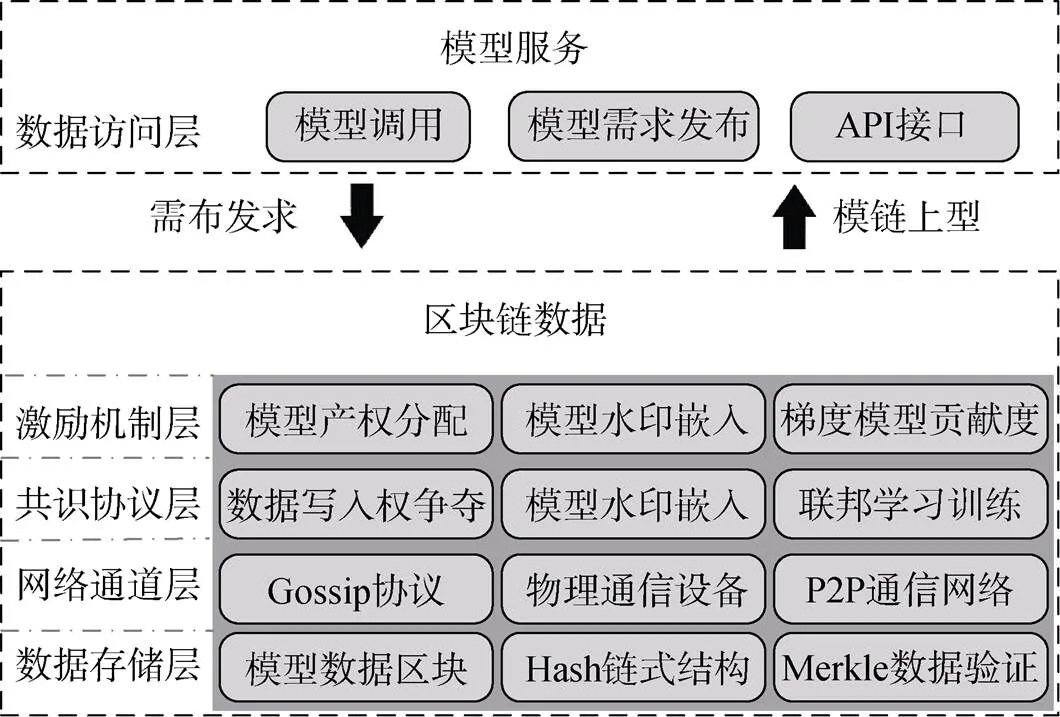
图3 本文区块链框架设计
Figure 3 The blockchain framework of this paper
2.2 攻击模型及安全定义
区块链能够解决联邦学习的中心化问题, 联邦学习则实现了区块链上的数据隐私保护。为确保本文设计的方案能够可靠运行, 首先对其性能与安全进行形式化定义, 后面章节也将围绕这些定义进行阐述及论证。
本文提出的联邦学习共识算法PFconsensus主要用于解决分布式环境下的数据一致性问题。PFconsensus协议的攻击环境和安全性定义如下。
定义1. 拜占庭攻击环境.

定义2.待融合梯度模型.
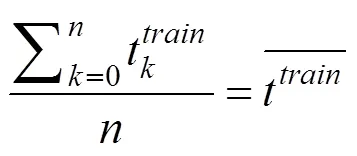

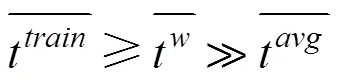
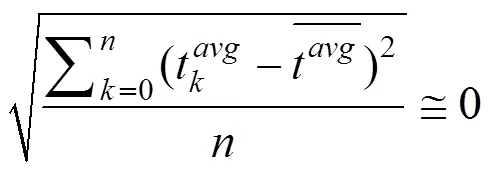
这四个条件能够保证在拜占庭环境下至少存在一个诚实节点正确地执行共识, 从而避免因性能差异或共谋等原因将所有诚实节点排除在共识过程之外。其中, 式(2)能够保证诚实节点在承诺打分阶段至少接收到个正确的梯度模型, 而式(3)保证了聚合后的模型集合中必然包含一个正常的聚合模型。具体分析将在后面给出。
定义3.拜占庭环境下共识协议的安全性.

本文将联邦学习算法作为模型训练的基本框架, 但为保证去中心化后仍然能够正常工作, 还需考虑如下额外因素及需求。
定义4.投毒攻击节点.
定义5.去中心化环境中联邦学习算法的有效性.
针对区块链上联邦学习算法的有效性问题, 本文方案需满足以下性质:
(2) 最终上链的聚合模型与中心化联邦学习方案在准确性方面的差异可忽略。
最后, 对区块链的整体安全性做如下定义:
定义6.拜占庭环境下区块链的整体安全性.
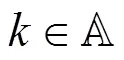
3 基于区块链的联邦学习共识激励机制
针对上述对拜占庭攻击环境的定义, 本章节将先引入模型水印技术来保证联邦学习过程中的模型产权证明。进一步的, 将详细介绍PFconsensue协议的运行过程。最终, 通过上链模型数据和模型水印设计了一种公平的激励机制。该机制能够在保证节点数据隐私的同时维持参与节点的训练积极性。
3.1 FedIPR模型水印
在设计PFconsensue共识算法时, 需确保网络中数据传输的可靠性, 并维护模型版权对融合过程的鲁棒性, 为此需要构造适应的数字签名和模型水印方案。由于在共识激励的过程中需要对联邦学习产生的梯度模型进行交叉验证, 本文考虑结合FedIPR模型水印与数字签名算法来保证模型的唯一性。此外, 在对聚合模型进行产权证明时, FedIPR算法也能提供一个可信的结果来保证激励机制的公平。FedIPR算法最初由Fan等人[38]提出, 它能够通过调整模型的目标函数, 同时植入白盒水印与黑盒水印, 本文构造类似的水印植入过程如下:

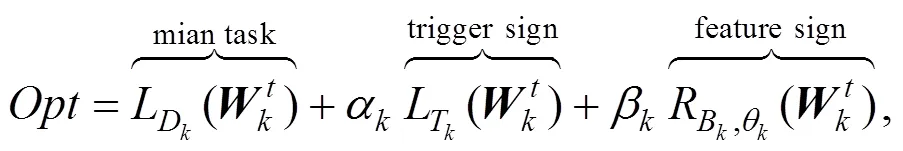

(3) 模型聚合算法将采用梯度平均策略(Federated Averaging):
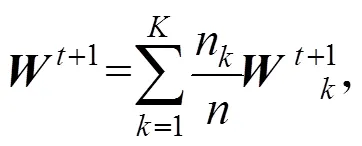


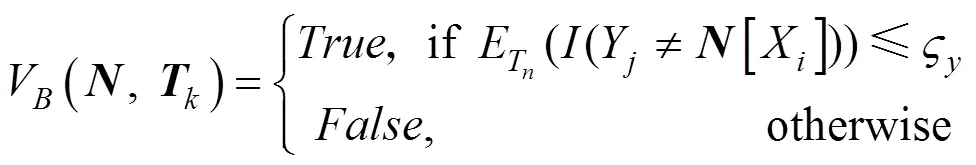
上述算法的正确性与鲁棒性已经在文献[38]中得到了验证。本文中实验也表明该算法在分布式联邦学习环境下具有很好的鲁棒性, 能够满足定义1中对签名算法的要求。

3.2 PFconsensus联邦共识算法
最早提出的联邦学习算法是一种基于C/S框架的中心化服务, 每个用户需要传输各自的梯度模型给服务器, 而服务器会利用他们的梯度模型进行聚合并返回给客户端进行迭代训练。该结构极易导致拒绝服务攻击, 因而有学者通过结合区块链中的智能合约, 将其改造为去中心化方案。为避免无谓的能耗, 本文将联邦学习算法本身作为共识, 并结合区块链与水印技术在一定程度上解决联邦学习中的Non-IID及投毒问题。该算法的核心在于通过对比聚合模型的性能来达成一致, 主要可以概括为模型性能筛选和共识写入两个部分。
本文将参与共识过程的角色分为三种: proposer、acceptor以及learner(acceptor和learner的角色互斥)。其中, proposer是数据的产生和发送者, acceptor表示数据的接收者和模型性能的裁决者, learner作为数据的最终写入者。
1) 模型筛选阶段:
a. 本地模型训练: proposer会发布模型的基本结构, 并初始化参数。随后, acceptor会利用本地数据对proposer的初始模型进行训练并在植入模型水印后将其广播。
b. 模型聚合: proposer在收集到梯度模型后, 利用Federated Averaging算法对模型进行聚合并微调, 得到聚合模型后将其广播。

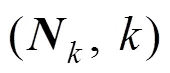
2) 共识阶段:
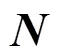
本文所提出的PFconsensus协议利用了聚合模型的性能优劣来选取最终的共识内容, 聚合过程的随机性与模型性能的有界性使得一段时间内只存在一个proposer。相比于原始paxos协议中产生多个proposer的现象, 本文方案避免了活锁的出现。此外, 在保证去中心化特性的同时, 该算法也高效地利用了分布式设备的资源来优化训练及验证过程。各个节点利用本地数据集对聚合模型进行性能评测的方式, 促使被投毒、普适性弱的聚合模型难以被大多节点所接受, 在一定程度上解决了Non-IID问题及模型投毒问题。
以上述方案为基础, 下面进一步对PFconsensus协议在区块链环境中的实现进行了更为详细的设计。首先, 为了保证PFconsensus正常运行, 需根据区块链应用的实际情况定义以下函数(1表示是, 0表示否):
根据PFconsensus协议, 区块链的运行主要包括模型生成和竞争写入算法两个部分。首先对模型的生成算法进行设计:
15 END FOR
在梯度模型生成后, 各个节点需要对网络中的聚合模型进行评价, 并筛选出全局性能最好的模型。最终, 生成该最优聚合模型的节点将指定下一轮协议的模型初始参数。算法2a、2b将具体描述如何实现筛选并达成共识。
算法2a.模型评价及写入权限争夺。
18END FOR
算法2a表明当节点作为一个proposer时, 会进行对聚合模型的评价并争夺区块的写入权限。算法2a可以与算法1在节点上并发执行, 当proposer在算法2a中转换为learner角色后, 将停止执行这两个, 其目的在于确保模型数据写入区块时唯一。
算法2b.共识及区块写入算法。
8 END FOR
算法2b的目的是确定大多数节点皆认为是最优模型并已做好写入区块链中的准备。从算法2a、2b可以发现, 若节点由proposer转化成learner角色, 将会失去发布新模型和竞争写入权限的能力, 可能因时延而导致模型无法得到一半以上节点的认定, 从而协议失败。为此, 需要设计活性算法以解决该问题。
算法3.活性算法。
5 END FOR
8 END FOR
当节点转换成一个learner角色后将运行算法3, 这可以防止由于大部分节点被激发成为learner后所出现的死锁现象。
3.3 参与者贡献度评价算法
通常评价联邦学习中梯度模型对最终模型的贡献度时, 往往会将其梯度模型从最终模型中剔除, 将剔除后模型在测试集上的性能差异作为贡献值。然而, 由于在分布式的竞争环境下往往不存在普遍认可的测试集, 因此本文将设计一种利用梯度模型和最终模型参数距离来换算贡献度的方法。该方法能够在各节点数据隐私得到保护的同时获取一个令人信服的贡献度指标。
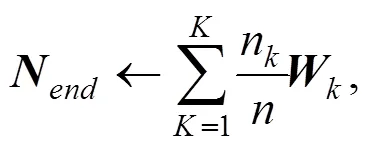
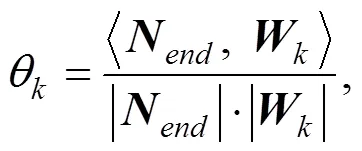

通过计算聚合模型和不同梯度模型之间的夹角大小即可衡量它对整体的贡献度。
4 系统正确性及安全性分析
如果上文所设计的系统能够满足2.2节中所给出的安全性和有效性定义, 则说明本文的整体系统在实际运行中是安全有效的。在本章节中, 将先结合共识协议的活性对第三章中所设计的PFconsensus协议进行正确性分析。此后, 将围绕2.2节中的攻击模型和安全性定义对本文所设计的区块链系统进行安全性和有效性的形式化证明。
4.1 PFconsensus协议正确性分析
PFconsensus协议在本质上是基于聚合模型的性能来争夺写入权, 主要包括模型性能筛选和共识达成两方面的内容。下面将围绕该协议在攻击环境下的节点活性及共识结果的唯一性来进行讨论。
显然算法2a、2b可满足以上设定, 但为了保证在当前轮得到唯一的聚合模型, 需要在PFconsensus协议中引入下面的约束条件:
约束1.任意learner节点只能认定唯一的聚合模型。
断言1.在约束条件1下, 每一轮协议中不存在两个不同的。
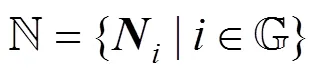
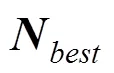

证明. 假设某一轮协议未产生出任何的, 则存在一半以上的节点选择了不同的性能最优模型, 这与约束1a矛盾, 因此断言3成立。
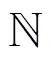


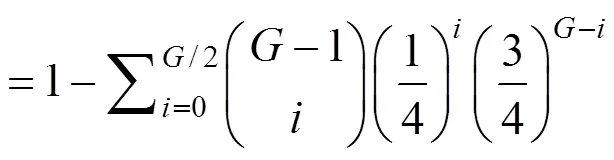
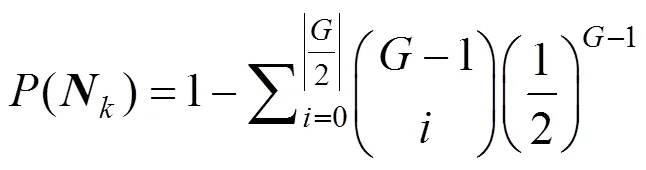
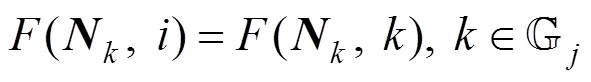

由此得证。

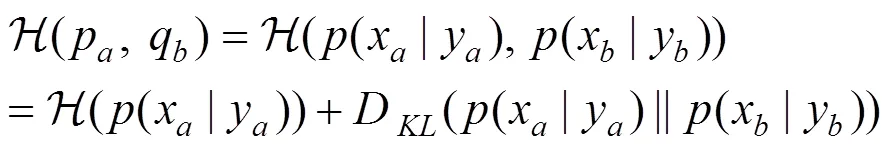
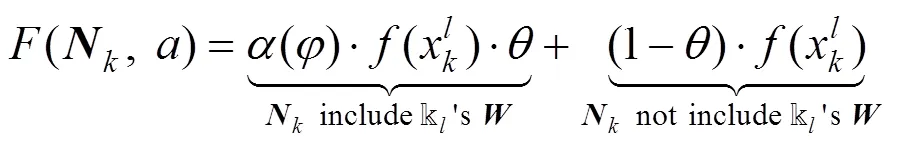
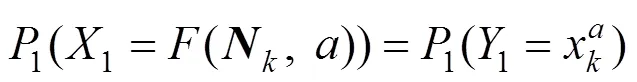
当模型被第二个节点(记为)进行评价, 由于梯度模型的选取方式要求评价结果与前一个节点相关, 因此得到:
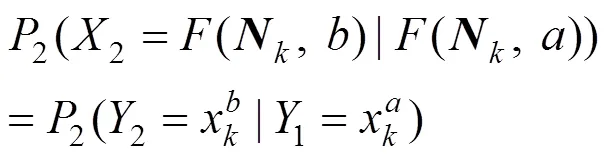
假设梯度模型的选取方式已知, 相应地在算法1中引入如下设定。


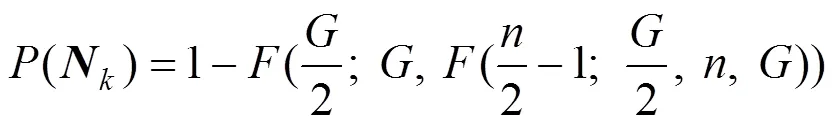
进一步可以得到:




至此, 证明完成了协议的正确性并推导出协议执行的通信复杂度。
4.2 PFconsensus安全性分析

为便于讨论, 下面将拜占庭节点从整体上划分为宕机节点与恶意扰乱节点两种身份。显然, 某一节点不可能扮演两种身份。
定义7.宕机节点.
断言4.在拜占庭节点扮演宕机身份时, PFconsensus协议满足安全性。
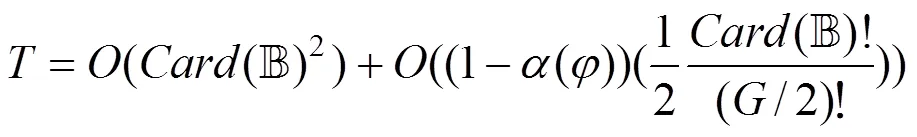
在实际情况下, 拜占庭节点更可能扮演恶意扰乱节点。因此, 下面将考虑拜占庭节点扮演恶意扰乱节点时的安全问题。
定义8.恶意扰乱节点.
断言5.在拜占庭节点扮演恶意扰乱身份时, PFconsensus协议满足安全性。
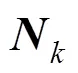
在上面的论证中, 拜占庭环境中的节点被分割成两种互补类型进行论证, 且已证明本文协议在这两种条件下皆满足定义6。结合这两种攻击情况, 可以得到如下结论。
断言6.在任意拜占庭环境下, PFconsensus协议能满足定义6中的安全性要求。
4.3 联邦学习算法有效性分析
联邦学习算法在嵌入到PFconsensus协议后, 应保证模型性能不低于对应的中心化方案, 并确保去中心化场景下抵抗投毒攻击的能力。因此, 下面将对本文联邦学习算法在去中心化环境中的有效性进行分析和论证。

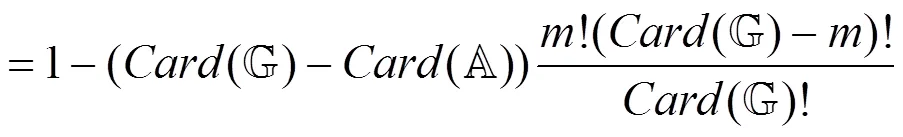
为降低上述概率, 下面在算法1的基础上引入额外的约束条件。
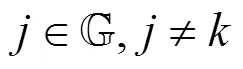

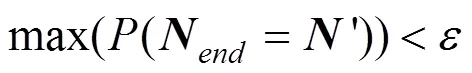

就模型性能而言, 本文在协议设计的过程中采用式(9)作为聚合算法, 该算法与常用的联邦学习算法[1]相同。因此, 在FedIPR水印的使用不影响全局模型性能的条件下, 本文方案能够在去中心化环境中满足联邦学习算法的准确性要求。
4.4 联邦学习区块链系统安全性分析
(1) 上一个区块的哈希;
下面首先对区块的合法性判断进行定义。
定义9.合法区块.
(5) 所在链满足最长链原则。
从系统的整体结构而言, 所采用的签名机制、散列算法、水印技术必然要满足以下给定的几个条件:

图4 区块数据
Figure 4 Data on the block
条件3.本系统采用的模型水印算法具有较高的鲁棒性, 强行去除后会损坏模型的保真度。
为清晰描述拜占庭环境下联邦学习区块链的整体安全性要求, 文中方案的安全性将被拆分为下面几个断言来进行论证。
5 仿真结果


表1 关键词说明

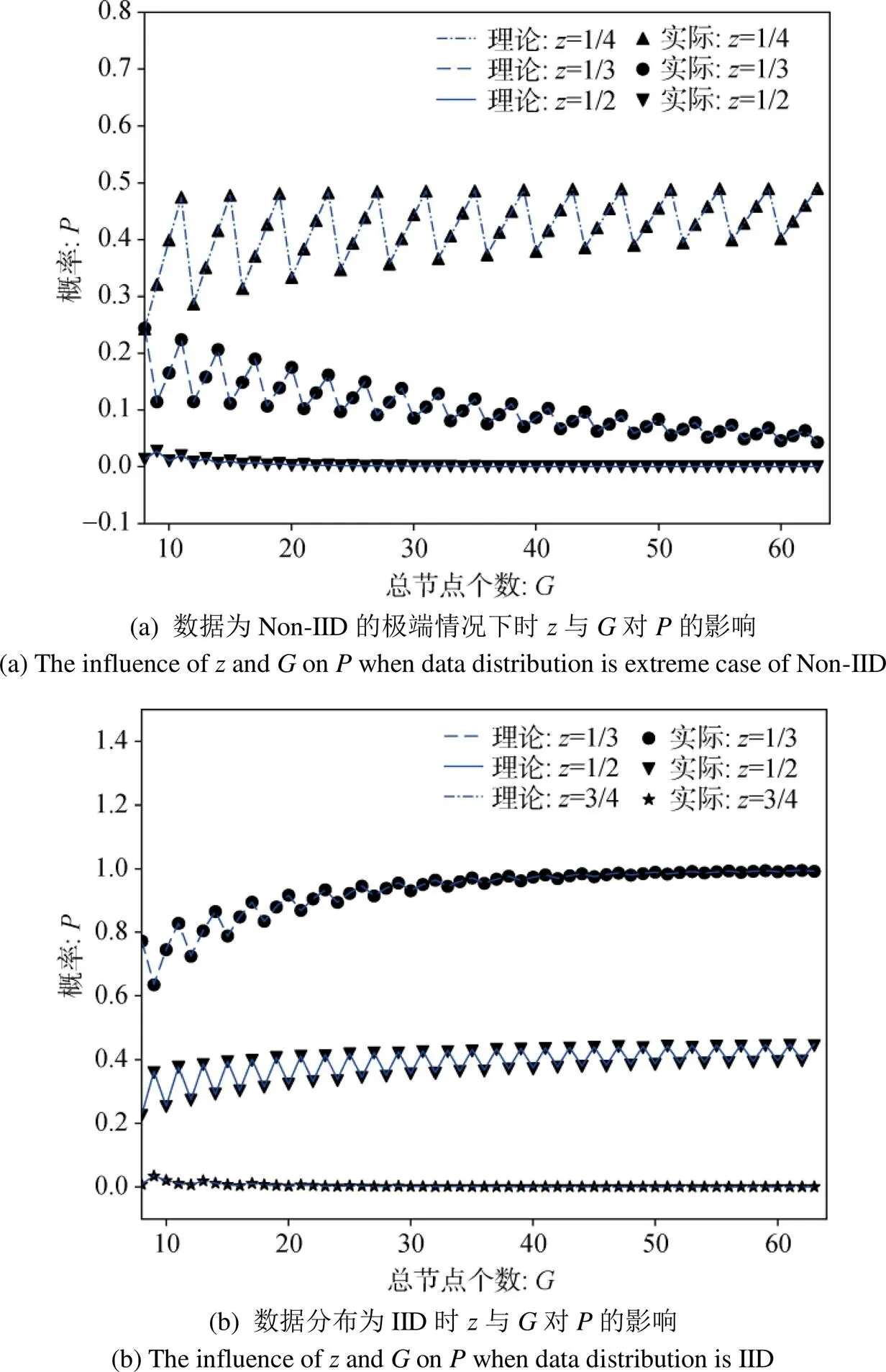
图5 不同数据分布下z与G对P的影响
Figure 5 The influence ofandonby different data distribution
将同样的评价函数用于计算机器学习模型的精确度指标(ACC与F1的加权和), 可以进一步分析该系统在实际应用中的节点打包情况。
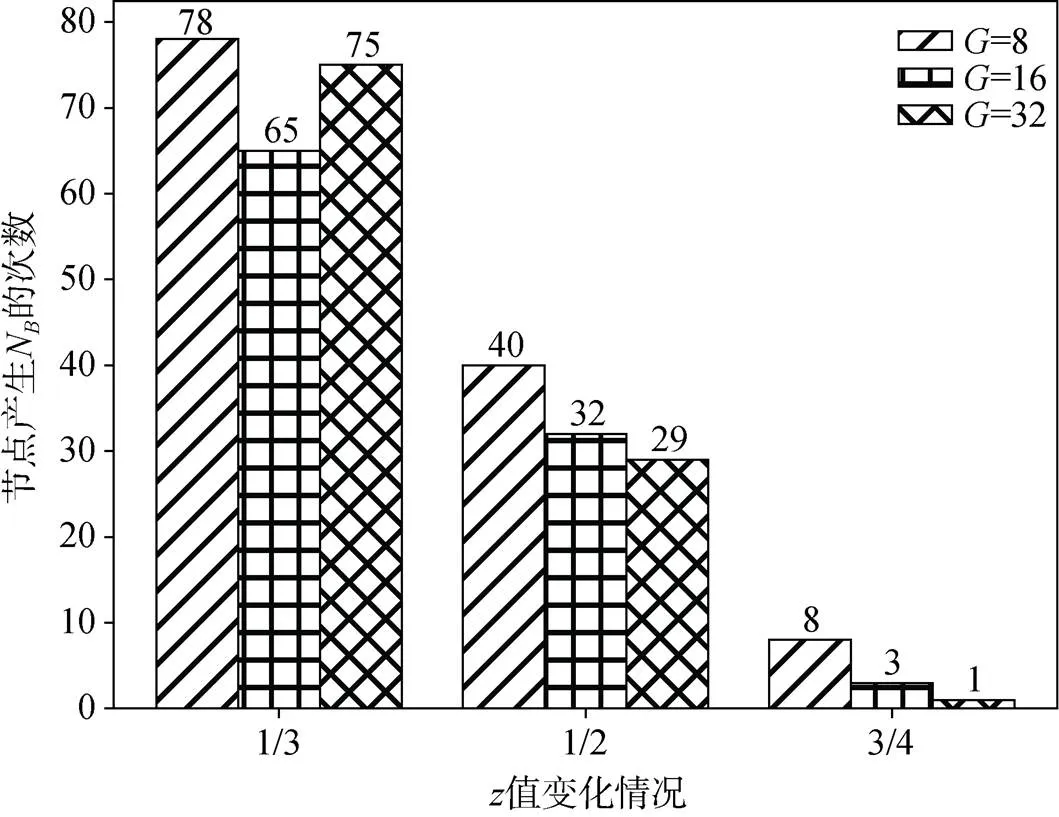
图6 在实际模型性能对比条件下节点产生NB的情况
Figure 6 The situation of any node generatingNin the case of actual model performance comparison
通过观察图7可以发现, 区块链出块所需通信次数符合式(27)的规律。以上结论反映了第四章理论分析的正确性, 但不足以说明本文联邦学习区块链的可行性能。
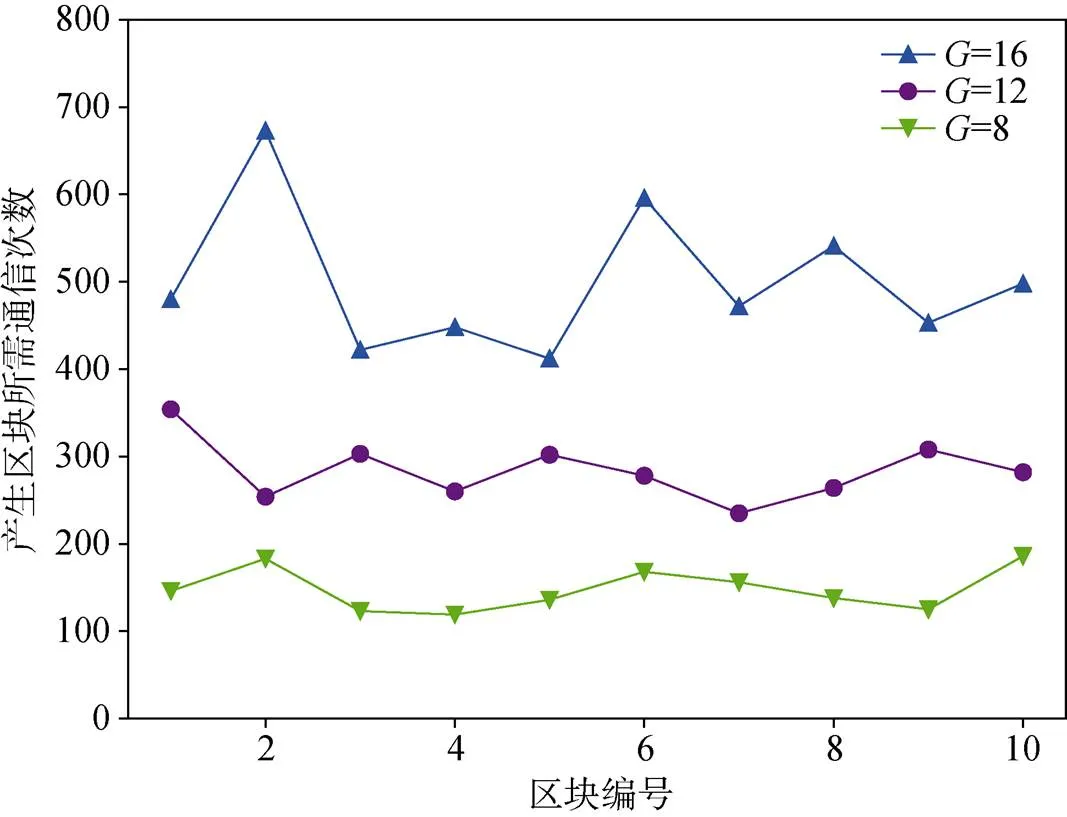
图7 产生新区块的通信次数变化情况
Figure 7 The times of communications required to generate a new block
图8描述了各个节点模型在共同测试集下准确率与F1的加权和变化情况。可以发现在同一段时间内, 争夺到上链权限的聚合模型性能表现最为优秀。该实验结果说明本方案在实际运行过程中符合PFconsensus协议中对上链模型的性能假设与协议的正确性。
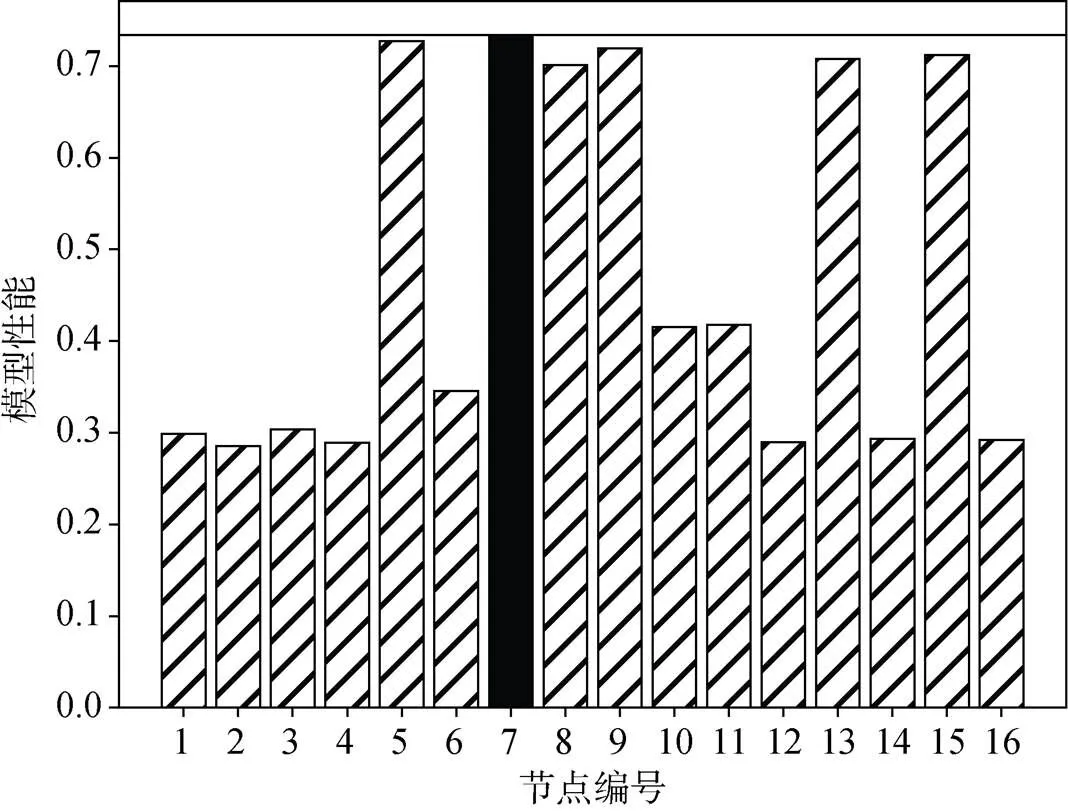
图8 各节点产生模型性能对比(全黑表示上链模型)
Figure 8 Performance comparison of models generated by each node (The all black bar indicate winding models)
进一步的, 本文对比了本方案中联邦学习的效率性能与C/S方案下的效率性能。得到图9所示的模型性能情况。
图9中分别记录了PFconsensus协议方案与C/S模式方案下的联邦学习在准确率和F1上的差别, 其中PFconsensus协议方案针对统一个目标任务连续迭代了9次模型, 而C/S模式方案下同样也持续迭代了9次模型。从图9中可以看出本文方案与基于C/S模式的联邦学习方法在性能上相近, 符合本文对区块链模式下的训练性能要求。同时, 为了证明本文区块链方案能够符合定义5, 本文测试了其在投毒节点个数为0到/2条件下的性能变化, 并对比在C/S方案下的表现。
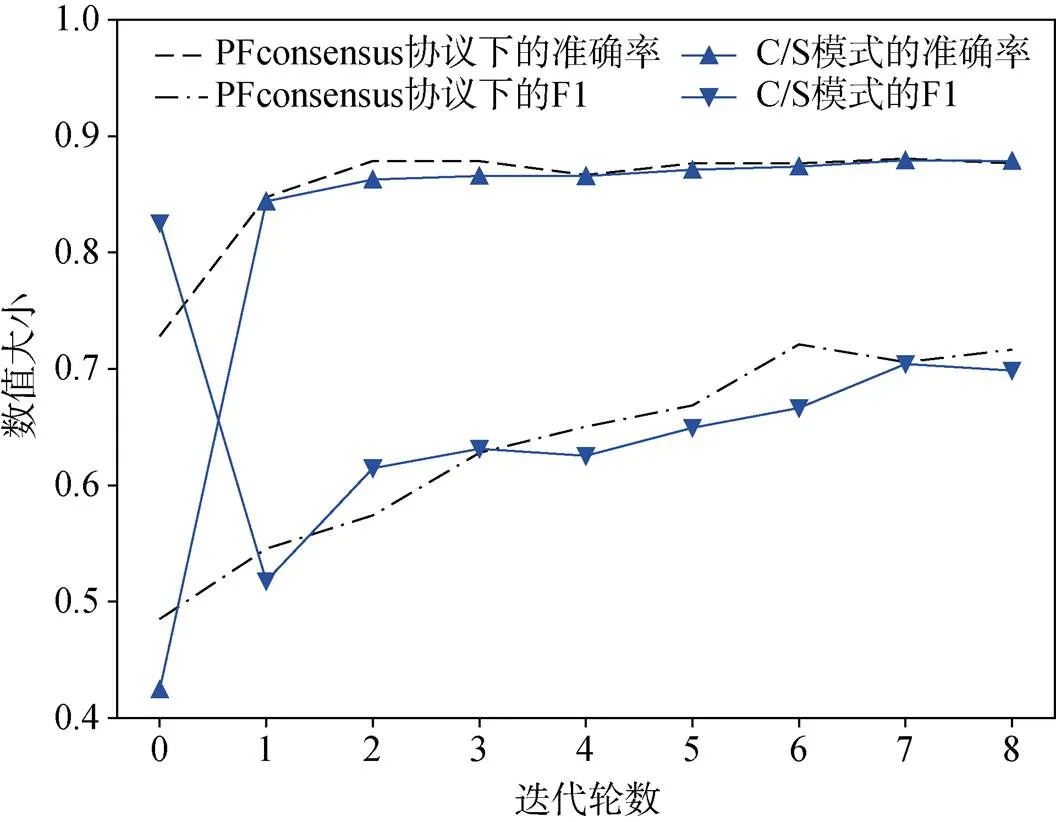
图9 本文方案与C/S方案下联邦学习过程的性能变化对比
Figure 9 The performance change of the federated learning process under the scheme in this paper and the C/S scheme
图10表明了本文的模型投票筛选机制在投毒节点少于/2时依然能够得到不包含投毒梯度的聚合模型, 而在C/S方案下的聚合模型性能则会受投毒节点个数的增长导致性能直线下降。
图11表示该卷积模型在应对投毒攻击时, 其协议在迭代后依然能够完成收敛, 并能够得到与无投毒环境下相近的准确率。在投毒攻击下, 该方案比文献[20]中的方案具有更强抵御能力, 并在能源的利用上更为环保。

图10 本文方案与C/S方案下聚合模型性能受投毒节点个数的影响(其中G=16)
Figure 10 The performance of the aggregation model under this scheme and the C/S scheme is affected by the number of poisoned nodes (=16)
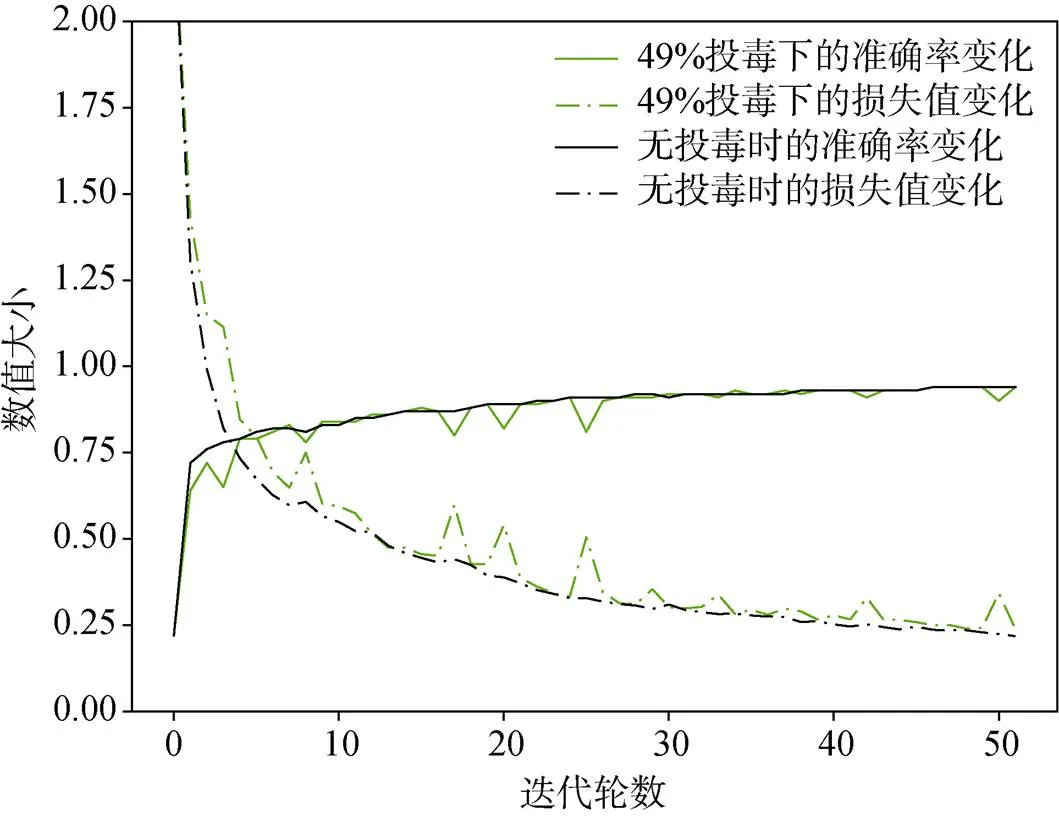
图11 本文方案在投毒环境下与无毒环境下训练MNIST数据模型的情况
Figure 11 The situation of training the MNIST data model in the poisoning environment and the non-toxic environment

表2 本文方案与文献[20]方案对比
通过仿真实验可以看到, 本文所提出的联邦学习共识激励机制比直接将区块链作为联邦学习平台资源利用率更高。基于本地数据进行全局模型的性能进行评测不仅能够有效保护参与者的数据隐私性, 也能够更好地解决联邦学习中的Non-IID问题。此外, 本文所采用的水印融合方案能够使模型在上链后帮助完成节点的行为追溯和贡献度分配, 充分激励不同的数据持有者参与训练。将联邦学习本身融入区块链共识激励机制可以获得众多优势, 包括: (1) 去中心化架构能够有效地保证联邦训练过程的稳健性; (2) 基于本地数据的模型性能评价能够很地解决Non-IID问题; (3) 模型水印技术能够有效地对节点行为和贡献进行记录; (4) 利用模型训练替代传统挖矿算法能够充分缓解资源浪费的问题; (5) 对上链模型采用协同性能筛选的方式可以抵御包括投毒攻击在内的各种联邦学习威胁。
6 结论
本文为商业领域普遍存在的“数据孤岛”问题提供了一个完备的解决方案。联邦学习虽然能够在一定程度上保证商业数据的隐私性与可用性, 但采用中心化的架构极易招致拒绝服务、推理攻击、模型投毒等威胁。本文将联邦学习嵌入到区块链共识协议当中, 并借助水印融合技术, 克服了模型协同训练过程中所存在的资源浪费与消极产与等问题。为验证本文方案的可行性及安全性, 专门针对分布式联邦学习场景下的数据分布和系统规模进行了理论分析, 其结果也通过了以最优模型产生概率、共识难度、模型性能、通信复杂度以及知识产权配额等为指标的实验验证。
后续研究将针对实验过程中所发现的缺陷进行, 包括: (1) 由于各个节点都会参加训练过程, 而只有一半节点能够得到最终模型的知识产权, 因而需要进一步优化该系统的奖励制度; (2) 针对推理攻击, 如果在训练过程中对模型梯度进行差分隐私保护可能会影响传输效率及最终模型的准确率, 所以有必要更进一步引入梯度隐私保护机制, 并在解决链上数据可追溯性与机密性之间的矛盾。
[1] Yang Q A, Liu Y, Cheng Y, et al. Federated Learning[J]., 2019, 13(3): 1-207.
[2] Li W, Chai Y B, Khan F, et al. A Comprehensive Survey on Machine Learning-Based Big Data Analytics for IoT-Enabled Smart Healthcare System[J]., 2021, 26(1): 234-252.
[3] Rathore M M, Shah S A, Shukla D, et al. The Role of AI, Machine Learning, and Big Data in Digital Twinning: A Systematic Literature Review, Challenges, and Opportunities[J]., 2021, 9: 32030-32052.
[4] Yuan H T, Li G L. A Survey of Traffic Prediction: From Spatio-Temporal Data to Intelligent Transportation[J]., 2021, 6(1): 63-85.
[5] Jiang J C, Kantarci B, Oktug S, et al. Federated Learning in Smart City Sensing: Challenges and Opportunities[J]., 2020, 20(21): 6230.
[6] Hosseini S, Sardo S R. Data Mining Tools -a Case Study for Network Intrusion Detection[J]., 2021, 80(4): 4999-5019.
[7] Lee E, Jang Y, Yoon D M, et al. Game Data Mining Competition on Churn Prediction and Survival Analysis Using Commercial Game Log Data[J]., 2019, 11(3): 215-226.
[8] Zeng S Q, Huo R, Huang T, et al. Survey of Blockchain: Principle, Progress and Application[J]., 2020, 41(1): 134-151. (曾诗钦, 霍如, 黄韬, 等. 区块链技术研究综述: 原理、进展与应用[J]., 2020, 41(1): 134-151.)
[9] Papadimitriou P, Garcia-Molina H. Data Leakage Detection[J]., 2011, 23(1): 51-63.
[10] Bogetoft P, Christensen D L, Damgård I, et al. Secure Multiparty Computation Goes Live[C]., 2009: 325-343.
[11] Evans D, Kolesnikov V, Rosulek M. A Pragmatic Introduction to Secure Multi-Party Computation[J]., 2018, 2(2/3): 70-246.
[12] Wood A, Najarian K, Kahrobaei D. Homomorphic encryption for machine learning in medicine and bioinfor-matics[J]., 2020, 53(4): 1-35.
[13] Kuang F, Mi B, Li Y, et al. Multiparty Homomorphic Machine Learning with Data Security and Model Preservation[J]., 2021, 2021: 166-179.
[14] Hassan M U, Rehmani M H, Chen J J. Differential Privacy Techniques for Cyber Physical Systems: A Survey[J]., 2020, 22(1): 746-789.
[15] Sen A A A, Eassa F A, Jambi K, et al. Preserving Privacy in Internet of Things: A Survey[J]., 2018, 10(2): 189-200.
[16] Kairouz P, McMahan H B, Avent B, et al. Advances and Open Problems in Federated Learning[J]., 2021, 14(1/2): 1-210.
[17] Liu Y, Kang Y, Xing C P, et al. A Secure Federated Transfer Learning Framework[J]., 2020, 35(4): 70-82.
[18] Huang Y T, Chu L Y, Zhou Z R, et al. Personalized Cross-Silo Federated Learning on Non-IID Data[EB/OL]. 2020: arXiv: 2007.03797. https://arxiv.org/abs/2007.03797.pdf
[19] Zhu H Y, Zhang H Y, Jin Y C. From Federated Learning to Federated Neural Architecture Search: A Survey[J]., 2021, 7(2): 639-657.
[20] Zhu J M, Zhang Q N, Gao S, et al. Privacy Preserving and Trustworthy Federated Learning Model Based on Blockchain[J]., 2021, 44(12): 2464-2484. (朱建明, 张沁楠, 高胜, 等. 基于区块链的隐私保护可信联邦学习模型[J]., 2021, 44(12): 2464-2484.)
[21] Zhang J H, Li X W, Zeng X, et al. Cross Domain Authentication and Key Agreement Protocol Based on Blockchain in Edge Computing Environment[J]., 2021, 6(1): 54-61. (张金花, 李晓伟, 曾新, 等. 边缘计算环境下基于区块链的跨域认证与密钥协商协议[J]., 2021, 6(1): 54-61.)
[22] Zhao B, Fan K, Yang K, et al. Anonymous and Privacy-Preserving Federated Learning with Industrial Big Data[J]., 2021, 17(9): 6314-6323.
[23] Pokhrel S R, Choi J. Federated Learning with Blockchain for Autonomous Vehicles: Analysis and Design Challenges[J]., 2020, 68(8): 4734-4746.
[24] Qu X D, Wang S L, Hu Q, et al. Proof of Federated Learning: A Novel Energy-Recycling Consensus Algorithm[J]., 2021, 32(8): 2074-2085.
[25] Li Y Z, Chen C, Liu N, et al. A Blockchain-Based Decentralized Federated Learning Framework with Committee Consensus[J]., 2021, 35(1): 234-241.
[26] Wang Y C, Tian Y Y, Yin X Y, et al. A Trusted Recommendation Scheme for Privacy Protection Based on Federated Learning[J]., 2020, 3(3): 218-228.
[27] Luo Z P, Zhao S Q, Lu Z, et al. Adversarial Machine Learning Based Partial-Model Attack in IoT[C]., 2020: 13-18.
[28] Chacon H, Silva S, Rad P. Deep Learning Poison Data Attack Detection[C]., 2020: 971-978.
[29] Liu Y F, Ma X J, Bailey J, et al. Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks[EB/OL]. 2020: arXiv: 2007.02343. https://arxiv.org/abs/2007.02343.pdf
[30] Rahman M A, Rahman T, Laganière R, et al. Membership Inference Attack Against Differentially Private Deep Learning Model[J]., 2018, 11: 61-79.
[31] Lamport L. Paxos Made Simple[J]., 2001, 32(4): 51-58.
[32] Sattler F, Wiedemann S, Müller K R, et al. Robust and Communication-Efficient Federated Learning from Non-I.i.d. Data[J]., 2019, 31(9): 3400-3413.
[33] Lu Y L, Huang X H, Dai Y Y, et al. Blockchain and Federated Learning for Privacy-Preserved Data Sharing in Industrial IoT[J]., 2020, 16(6): 4177-4186.
[34] Majeed U, Hong C S. FLchain: Federated Learning via MEC-Enabled Blockchain Network[C]., 2019: 1-4.
[35] Peng Z, Xu J L, Chu X W, et al. VFChain: Enabling Verifiable and Auditable Federated Learning via Blockchain Systems[J]., 2022, 9(1): 173-186.
[36] Handelman D. Gossip in encounters: The transmission of information in a bounded social setting[J]., 1973, 8(2): 210-227.
[37] Bonneau J, Miller A, Clark J, et al. SoK: Research Perspectives and Challenges for Bitcoin and Cryptocurrencies[C]., 2015: 104-121.
[38] Fam L, Li B, Gu H, et al. FedIPR: Ownership verification for federated deep neural network models[EB/OL]. 2021: ArXiv Preprint ArXiv:2109.13236.
[39] Zhu H Y, Jin Y C. Multi-Objective Evolutionary Federated Learning[J]., 2020, 31(4): 1310-1322.
[40] Li X C, Zhan D C. FedRS: Federated Learning with Restricted Softmax for Label Distribution Non-IID Data[C]., 2021: 995-1005.
[41] Poupard G, Stern J. Security Analysis of a Practical “on the Fly” Authentication and Signature Generation[M].. Berlin, Heidelberg: Springer Berlin Heidelberg, 1998: 422-436.
A Novel FL System Based on Consensus Motivated Blockchain
MI Bo1, WENG Yuan1, HUANG Darong1, LIU Yang1
1School of Information and Engineering, Chongqing Jiaotong University, Chongqing 400074, China
With the advancement of technologies such as cloud storage and AI (artificial intelligence) in recent years, the value of data has experienced significant growth. However, the exorbitant costs associated with communication and the intolerable risks of data leakage have given rise to a pervasive issue of “data isolation” among institutions, rendering a substantial portion of data unable to realize its full economic potential. Although using blockchain as a platform for federated learning can solve this problem to a certain extent, it also brings three primary shortcomings: 1) traditional consensus processes like PoW (proof of work) and PoS (proof of stake) remain largely disconnected from the federated learning training process, resulting in substantial wastage of computational power and bandwidth; 2) nodes may decline to participate actively in the training process or even disrupt it due to self-interest considerations, driven by competitive dynamics; 3) in open environments, data traceability during the model training process is challenging to establish, consequently diminishing the cost of attack for potential malevolent actors. Our study manifested that, instead of relying on traditional consensus mechanisms such as PoW and PoS, combining federated learning and model watermarking technology can make the consensus algorithm more fair and reliable. It can avoid the waste of computing power and unbalanced rewards thanks to federated learning, and the innovative consensus mechanism not only retained the properties of immutability, decentralization, and 49% byzantine fault tolerance but also naturally resisted 49% poisoning attack, adapted Non-IID (not independent and identically distributed) dataset and protected intellectual property. Both experimental and empirical evidence unequivocally demonstrate that the proposed solution in this study is exceptionally well-suited for scenarios involving non-trusting institutions collaboratively leveraging large volumes of local data for commercial federated learning, thereby holding substantial practical value.
federated learning; blockchain; consensus algorithm; intellectual property protection; poison attack
TP309.2
10.19363/J.cnki.cn10-1380/tn.2024.01.02
翁渊, Email: wengyuan980930@mails.cqjtu.edu.cn。
本课题得到中国国家自然基金(No.61903053), 重庆市科教委项目(No. KJCX2020033), 上海市信息安全综合管理技术重点实验室开放课题(No. AGK2020006)资助。
2022-05-05;
2022-08-20;
2023-09-26

米波 博士, 重庆交通大学信息科学与工程学院教授, 博士生导师。研究领域包括密码学、区块链、智能交通、车载自主式网络等。Email: mi_bo@163.com
翁渊 于2019年在重庆交通大学计算机通信专业获得学士学位。现在重庆交通学校计算机与科学专业攻读硕士学位。研究领域为密码学、人工智能。研究兴趣包括区块链、同态加密。Email: wengyuan980930@mails.cqjtu.edu.cn

黄大荣 博士, 重庆交通大学信息科学与工程学院教授, 博士生导师。研究领域包括车联网安全容错控制、交通系统可靠性控制。Email: drhuang@cqjtu.edu.cn
刘洋 博士, 重庆交通大学信息科学与工程学院副教授, 研究生导师。研究领域包括形式化验证、信息安全和数据处理等。Email: liuyang13@cqjtu.edu.cn
猜你喜欢
小学生学习指导(当代教科研)(2021年6期)2021-05-23
家庭影院技术(2020年10期)2020-12-14
科学(2020年5期)2020-11-26
马克思主义哲学研究(2020年1期)2020-11-26
科学(2020年6期)2020-02-06
人大建设(2019年12期)2019-11-18
家庭影院技术(2019年7期)2019-08-27
传媒评论(2018年4期)2018-06-27
现代企业文化(2018年13期)2018-06-09
发明与创新(2015年17期)2015-02-27

- 信息安全学报的其它文章
- 面向深度学习模型的可靠性测试综述
- 基于集成学习技术的恶意软件检测方法