
基于机器视觉的煤矿巷道人员定位研究
2024-01-25 02:47:22刘世平王利军
矿山机械 2024年1期
王 端,刘世平,王利军
国家能源神东煤炭公司乌兰木伦煤矿 内蒙古鄂尔多斯 017200
煤 矿智能化是煤炭行业实现智能、高效开采的必由之路,煤矿井下人员的精确定位是煤矿安全生产的重要保障[1]。我国的煤矿开采方式多为井工开采,煤矿巷道内广泛存在大量可燃性气体及煤尘,成为制约煤矿人员定位问题的一大技术瓶颈。
近年来,国内外专家学者针对煤矿巷道人员识别、定位方法进行了大量的研究。郭瑜[2]研究了基于智能手机系统平台和 ZigBee 技术的人员定位系统,提升了人员定位系统的抗干扰能力;张海军等人[3]设计了一种煤矿井下超宽带 (UWB) 人员定位系统,采用一种联合定位算法解算标签位置坐标,提高了定位精度;李胜利等人[4]使用卡尔曼滤波方法改进超宽带定位系统,提升了在视距和非视距条件下的定位精度;李东辉[5]利用无线网络对矿井骨干网络进行部署,实现了井下人员的精确定位。其中,基于射频卡的人员定位技术[6]是目前井下应用最广泛的技术,其原理为通过巷道内大量布置的读卡设备读取作业人员携带的射频卡,但无法测距及精确定位;基于移动网络、WiFi 的人员定位技术[7-9],测距误差较大,难以实现精确定位;超宽带技术定位精度虽可精确至厘米级,但现有的 UWB 定位卡设备成本较高[10-11],并未在井下得到应用。
为进一步改善针对煤矿巷道内人员精确定位问题[12-14],笔者重点研究了 YOLOv5 目标检测算法,并提出了一种基于改进 YOLOv5 的煤矿巷道人员定位模型。通过自制的巷道人员数据集训练井下人员识别模型,利用 SE 注意力机制提升模型对人员的感知程度,结合双目深度相机捕捉人员相对相机的三维坐标,最后将训练得到的模型应用于巷道人员定位。
1 基于机器视觉的人员定位方法
1.1 人员智能识别与定位流程
煤矿巷道人员智能识别与定位流程如图1 所示。首先,使用 Python 程序对巷道内人员活动视频图像进行切片处理,在 Anaconda 虚拟环境下通过标注软件 LabelMe 对人员图像进行逐张标注,并通过数据增强技术丰富原始人员数据集;然后,在目标检测 YOLOv5 框架的有效特征层中加入 SE 注意力机制模块,得到 SE-YOLOv5 模型;最后,利用 SEYOLOv5 模型在人员定位测试集中对人员进行识别,通过坐标转化公式对双目相机获得的人员深度值进行求解,得到人员中心点相对相机的三维坐标。
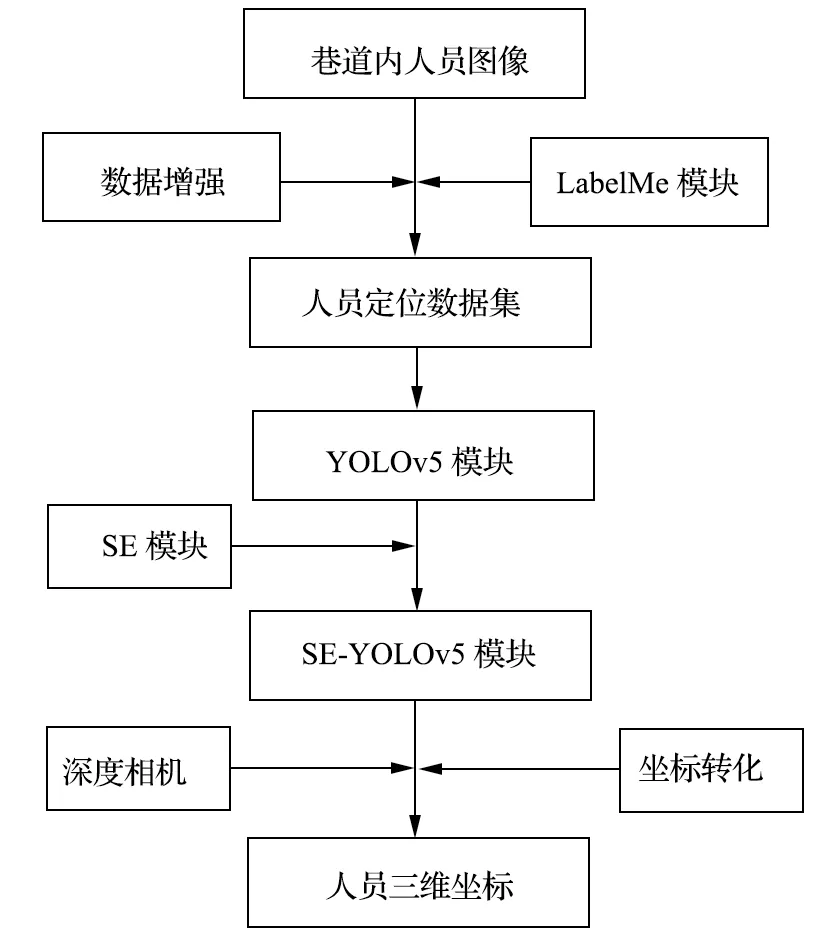
图1 煤矿巷道人员智能识别与定位流程Fig.1 Intelligent identification and positioning process for personnel in coal mine roadway
1.2 SE-YOLOv5 模型构建
1.2.1 SE 模块融入设计
由于煤矿巷道内存在大量煤粉和水雾,导致人员图像分辨率不高、模糊不清,且巷道内环境复杂,在卷积神经网络计算过程中易丢失人员的图像信息,导致人员检测效果不佳。为提升人员图像信息在整张图像信息中的关注度,降低特征图的通道数以增大模型对图像的整体感受视野,笔者使用 SE 注意力机制增加网络对通道权重数值的学习,然后将学习的结果重新赋值给原先的特征通道,最终有效解决了由于图像特征图和通道数的比例不同给模型计算过程产生的损失问题。
注意力机制可以增强有效特征信息,抑制无效信息,有效提升神经网络的检测性能。SE 注意力机制自动学习图像特征权重,具备“即插即用”的优良性质,其结构如图2 所示。
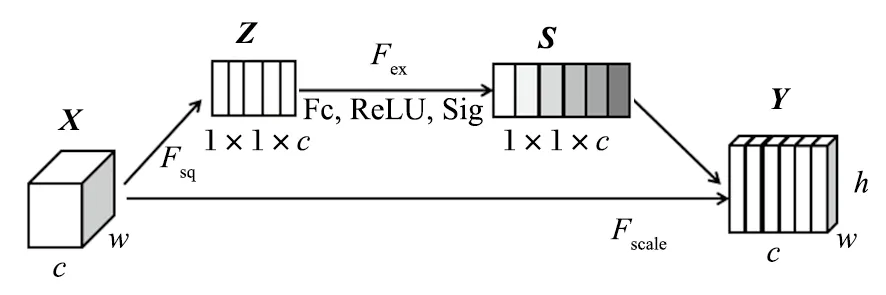
图2 SE 模块结构Fig.2 SE module structure
图2 中,X、Y表示特征图的输入和输出;c、h、w分别代表通道数和高、宽。该模块由 3 部分组成,分别是挤压部分 (SQ 网络)、激励部分 (EX 网络)、缩放网络 (SCALE 网络)。
其中,挤压部分对特征图输入X做全局池化操作,得到一个具有感受图像全局视野功能的 1×1×1的一维矩阵。在实际操作中,将 SE 模块增添在卷积模块之后,也就是第 2 个 C3 和第 3 个 C3 模块之间,实现将不同的权重值赋给不同图像特征层的目的;相对应地,在 SPP 层网络之后也加入该 SE 注意力机制模块,旨在强化融合后的全部特征。
1.2.2 YOLOv5 模型部署
YOLOv5 是目标检测领域最流行的网络,作为一种直接预测目标位置和类别的一阶段算法,具有模型尺寸小、本地部署成本低、高精确度与灵活性的特点。其主要由输入网络、特征提取网络、特征融合网络、输出网络组成。经 YOLOv4 发展而来,YOLOv5具备以下进步点:输入网络内采用 Mosaic 方式简化特征尺寸为 640×640×3 的 RGB 图像,锚框机制通过重复迭代更新,能够更快找到锚框的最佳数值;特征提取网络是由卷积模块 Conv、C3、SPFF 等模块组成的 CSPDarknet53 网络、Focus 网络对图像进行切片操作,可有效减少运算过程的参数值,提升了运算速度完成不同池化层的图像特征提取;特征融合部分沿用 YOLOv4 的 FPN+PAN 的特征融合方式,结合两个方向的检测层进行参数加聚操作,有效提高了密集目标场景下的检测效果,并将融合后的目标图像特征输入输出网络;输出网络的输出结果包含目标的位置、类别和置信度,可实现 80×80、40×40、20×20 不同尺度目标的位置预测。与 YOLOv4 相比,YOLOv5 更适用于煤矿井下的部署应用。因此,选择 YOLOv5 作为煤矿巷道人员定位的基础算法。SE-YOLOv5 模型结构如图3 所示。

图3 SE-YOLOv5 网络结构Fig.3 SE-YOLOv5 network structure
2 基于机器视觉的人员定位方法
2.1 数据集构建
利用巷道内布置的监控摄像头获取到巷道内人员图像,在 Anaconda 虚拟环境下使用 LabelMe 标注软件对人员图像进行逐张标注,并命名为 person,得到包含有人员位置的 json 格式文件,再通过格式转化程序得到适用于 YOLOv5 的 txt 格式输入文件。通过数据增强操作对巷道人员图像进行缩放、剪切、旋转等物理操作,可有效扩充数据集内图像数量,进而提升模型的综合性能。选取包含 1 200 张巷道人员的数据集,按照 7∶3 划分为训练集和测试集。数据增强效果图如图4 所示。

图4 数据增强效果Fig.4 Data enhancement effect
试验模型训练、测试使用的硬件环境为 Intel(R)Core(TM) i7-9750H CPU@2.60 GHz 处理器、NVIDIAGTX 1660Ti 显卡;软件环境为 Windows 操作系统下 Pytorch1.8.1 深度学习框架。模型训练过程中,学习率设置为 0.000 01,批尺寸为 16,迭代次数为 300。
2.2 模型评价指标
采用目标检测领域的精确率P、召回率R、FPS作为模型性能的评价指标,原始的 YOLOv5 模型与笔者提出的 SE-YOLOv5 模型检测性能对比情况如表1所列。其中,精确率表征模型的分类能力;召回率表征模型对待检测目标的检测能力;FPS为单位时间内图像填充的帧数,表示模型的检测速度。
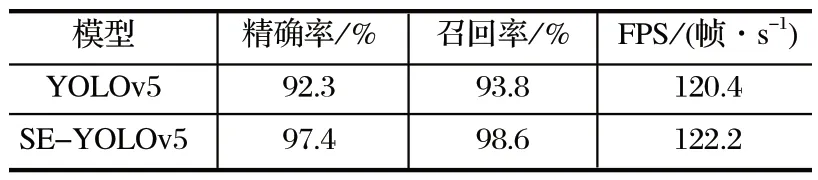
表1 模型改进前后性能对比Tab.1 Performance comparison before and after model improvement
式中:TP为正样本被正确检测出来的数目;FP为负样本被检测为正样本的数目;FN为未被检测出来的数目。
由表1 可以看出,SE-YOLOv5 模型相对于原始 YOLOv5 模型的精确率、召回率分别提高了 5.1、4.8 个百分点,检测速度基本保持不变,说明 SEYOLOv5 模型改进方式能在不影响检测速度的前提下有效提升检测精确率。
2.3 模型效果验证
为验证 SE-YOLOv5 模型的人员检测效果,利用改进前后的 2 种模型对测试数据集进行检测试验,选取部分检测结果,如图5 所示。

图5 煤矿巷道人员检测效果对比Fig.5 Comparison of personnel detection effects in coal mine roadway
由图5 结果可知,原始 YOLOv5 算法存在有检测人员失败、漏检的情况,而 SE-YOLOv5 模型能够检测成功,并且具有较高的置信度。这是因为 SE 注意力机制模块增强了图像内目标人员在整张图像内的像素占比,且提升了人员图像的特征信息,受到更多的关注,在一定程度上可以避免漏检、错检的情况。
3 应用效果
为验证 SE-YOLOv5 模型的实际应用效果,将煤矿巷道内的摄像头 IP 作为程序输入,进行实时检测。基于机器视觉 SE-YOLOv5 模型的煤矿巷道人员定位系统如图6 所示。利用 PyQt 编程语言编写煤矿巷道人员定位系统交互界面,设置提前训练好的人员定位模型作为权重文件,固定 IP 的摄像头视频流作为输入,具备手动调节模型、信号输入、置信度以及检测前后的对比显示功能。当成功检测到人员后,通过坐标转化公式求解出 person 区域中心点相对于深度相机的三维坐标。巷道人员定位坐标如表2 所列。
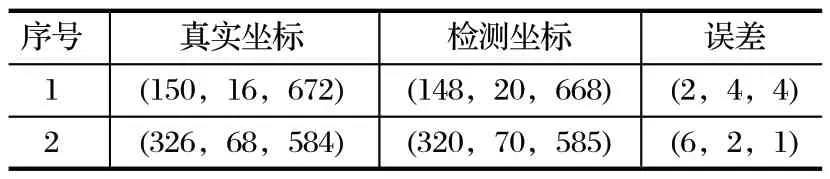
表2 煤矿巷道人员定位坐标对比Tab.2 Comparison of personnel positioning coordinates in coal mine roadway
4 结论
(1) 在原始机器视觉 YOLOv5 框架的卷积模块之后加入了注意力机制 SE 模块,有效解决了巷道内复杂背景、人员被遮挡条件下图像特征信息丢失的问题。
(2) 相较于 YOLOv5 模型,SE-YOLOv5 模型的精确率提升了 5.1 个百分点,具有更高的检测能力。
(3) 将改进后得到的 SE-YOLOv5 部署于煤矿巷道人员定位系统中,能够快速识别人员,并且能够显示计算后人员相对于相机的三维坐标。
猜你喜欢
矿产勘查(2020年9期)2020-12-25 02:54:06
导航定位与授时(2020年5期)2020-09-23 03:05:00
铁道通信信号(2020年9期)2020-02-06 09:16:06
知识经济·中国直销(2018年3期)2018-04-12 06:43:37
工业设计(2016年4期)2016-05-04 04:00:23
江西煤炭科技(2015年1期)2015-11-07 03:06:32
学习月刊(2015年1期)2015-07-11 01:51:12
山西焦煤科技(2015年7期)2015-02-28 19:51:13
现代企业(2015年8期)2015-02-28 18:55:34
现代企业(2015年6期)2015-02-28 18:51:50
