
基于循环神经网络的工程专业语义智能分析方法研究
2024-01-24 10:10:18师玲萍
电子设计工程 2024年2期
师玲萍
(西安铁路职业技术学院,陕西西安 710026)
随着我国铁路运输系统的不断发展,相关的学术交流及技术沟通越发频繁,该领域内专业术语的翻译质量也亟需进行相应提升。而作为专业性较强的学科,该专业的词汇中有诸多日常使用的词组均被赋予了全新的意义,这便要求翻译人员具有一定的专业知识基础。但由于大多数人员并不具备专业背景,故容易造成一词多译、词义缺失以及直译等现象的发生。
为了弥补翻译工作者在文献翻译过程中存在的不足,机器翻译技术[1-2]应运而生。该技术利用算法将源语言转换为目标语言,同时其对主要语种的翻译质量与人工翻译相差较小。传统机器翻译算法包括模板匹配(Match Template)[3]、统计学算法[4]及评分筛选[5]三种。但这三种算法的学习能力较差,无法根据语料数据集的变化对翻译质量进行更新。随着深度学习(Deep Learning,DL)[6-8]的发展和应用,现代机器翻译算法可从语料库中不断学习新的特征来完善自身功能。文中基于循环神经网络(Recurrent Neural Network,RNN)对专业英语词汇进行分析,进而提升翻译质量,并满足翻译需求。
1 模型构建
1.1 编码器-解码器框架
自然语言处理(Natural Language Processing,NLP)通常将编码器-解码器[9-10]作为算法框架,其符合语言数据的特征,即序列化。该算法框架如图1所示。
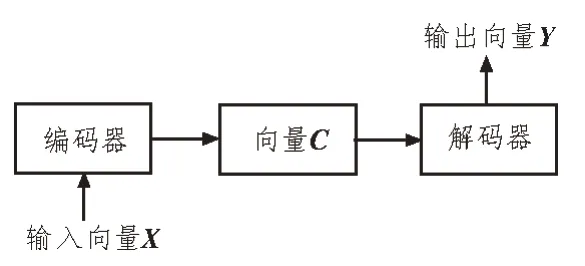
图1 编码器-解码器算法框架
图1 中,第一个结构是编码器(Encoder),其作用是编码源语言,以形成固定向量;第二个结构则是解码器(Decoder),其负责解码编码器输出的向量,并形成目标语言,且两者间通过上下文向量C进行连接。而输入向量X与输出向量Y可表示为:
当前时刻的目标单词向量yt以概率形式输出,具体如下所示:
1.2 循环神经网络模型
循环神经网络(RNN)[11]由神经单元及反馈因子循环组成,其结构示意如图2 所示。与传统神经网络有所不同,循环神经网络中的输入变量会互相影响,这也符合语料数据的特点。
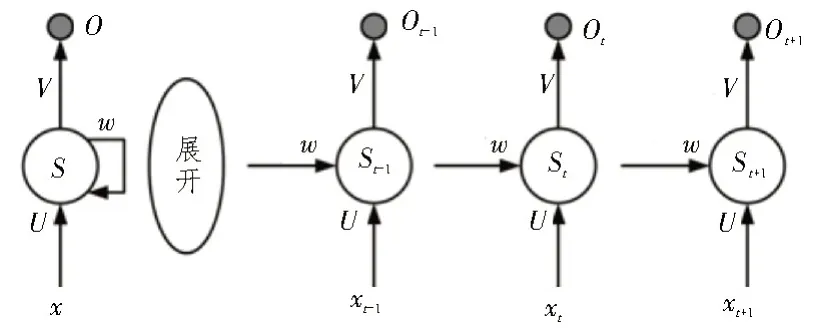
图2 循环神经网络结构示意图
在RNN 模型中,输入层为语料数据构成的向量,S为中间隐藏层,O为输出层。U、w和V分别为输入、隐藏及输出层的神经元参数。
但由于RNN 模型在处理大量数据时使用雅克比矩阵(Jacobian Matrix)次数过多,会遇到梯度异常的问题,从而导致训练效果的收敛性较差。因此,采用长短期记忆网络(Long Short-Term Memory,LSTM)来对该情况进行改善。通过对前置状态的选择性遗忘,以保证数据收敛的一致性。
LSTM 利用输入门、输出门与遗忘门来对记忆状态进行更新。该网络的结构示意图如图3 所示。
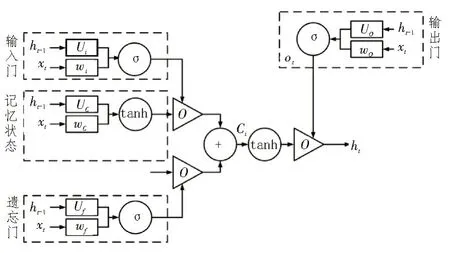
图3 LSTM结构示意图
遗忘门的传递函数可表示为:
在LSTM 模型中,输入门对状态信息进行更新,再通过σ函数更新控制信息。其中,it为控制信息,ht-1是上层输出值,xt为输入值,则为状态信息。由式(6)-(8)即可得到最新的单元格状态Ct,具体计算过程可表征为:
其中,*代表卷积运算,b为相应的偏置数值。
1.3 多头注意力机制
注意力机制(Attention Mechanism)[12]是一种衡量多输入数据关联程度的算法,该算法起源于图像处理领域。经过多年的研究,在其基础上改进的多头注意力机制(Multi-Head-Attention)可应用于机器翻译领域,并帮助模型更好地理解上下文含义。
注意力机制的输入端为单词向量,根据输入的单词向量能生成三个子向量,分别为查询向量Q、键向量K及值向量V。注意力机制的公式可表示为:
其中,dk为向量K的维度;Softmax 为分类器,可将单词向量的影响度进行归一化。
权重在每一个子向量中的反馈是不同的,为了能在任意维度对子向量权值进行优化,该文采用多头注意力机制进行改进。其将原本的数据维度空间切分成为n份的子空间,并在子空间中对Q和K的相似度加以计算,由此便可减少单个子向量的维度,且最终进行综合。多头注意力机制结构如图4所示。
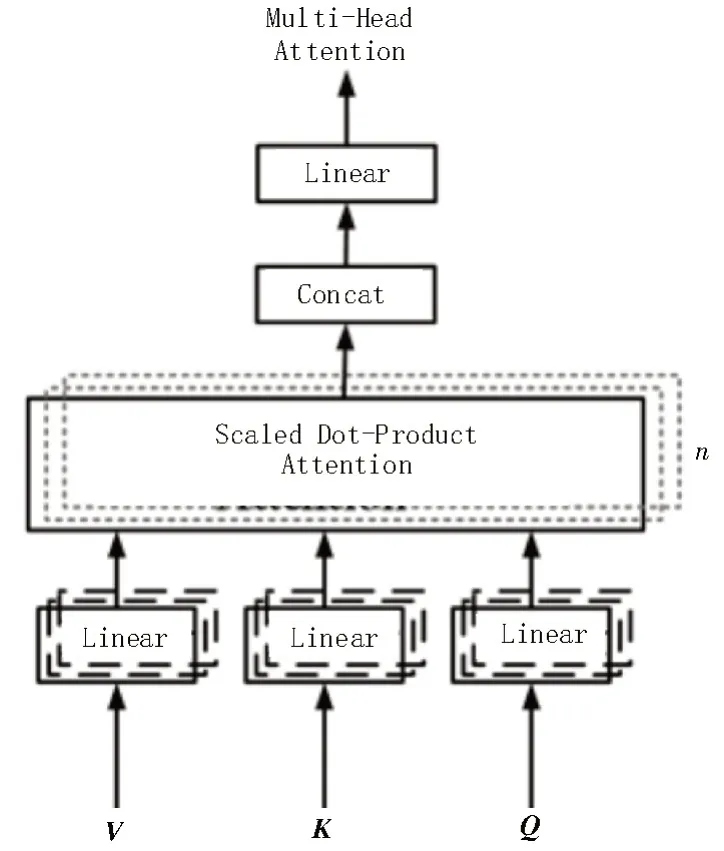
图4 多头注意力机制结构
1.4 基于编-解码器的机器翻译模型
该文基于编码器-解码器框架进行机器翻译模型的设计,该模型由编码器、解码器、输入层及输出层四部分组成。具体模型结构如图5 所示。
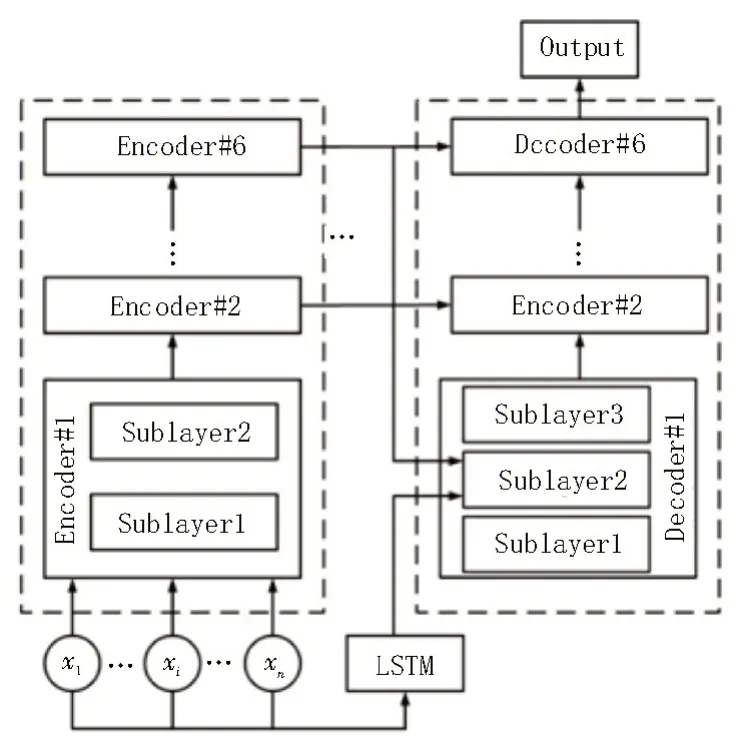
图5 机器翻译模型结构
如图6 所示,该文设计模型的编码器模块共有六层,且每一层均有两个子编码层。其中第一个子编码层中包含有多头注意力模块和逻辑计算模块,用来计算注意力值;第二个子编码层则是全连接模块,同时还在该层中加入了残差模块,以完成模块的传递。

图6 模型编码器示意图
子层的输出可表示为:
解码器部分则使用了三个子解码层,第一个子解码层使用多头注意力模块,第二个子解码层对应的是上下文模块的输入,第三个子解码层则为全连接模块。模型解码器示意图如图7 所示。

图7 模型解码器示意图
由于输入的数据类型为包含有铁道车辆专业词汇的英文语句。因此针对某些具有特定含义的单词,还需对其进行语义训练,从而提高编解码器模型的翻译准确度与流畅度。
在输入模块的设计中,文中将LSTM 和多头注意力机制相结合,再对专业英语词汇进行训练,进而将共同作用的结果作为输出。基于LSTM 的输入数据训练模块如图8 所示。

图8 基于LSTM的输入数据训练模块
可以看到,输入的句子被分解为单词向量[x1,x2,…,xj-1,xj],单词向量同时经过LSTM 模块及编码器模块,最后共同输出作为解码器的输入数据。由此,较好地兼顾了LSTM 和注意力机制的特性。注意力机制所关注的是源语言与目标语言之间的特征相似程度,但其忽略了句子之间单词的关系。而LSTM 可获取句子间单词的结构关系,并将该关系传输至上层。因此,二者结合即可生成质量更高的译文。
1.5 评估标准
最优线性无偏(Best Linear Unbiased Evaluation,BLUE)评估是目前最常用的译文质量评价标准。该标准基于N元模型(N-gram)建立,可将BLUE 值看作模型输出与实际译文间的加权匹配程度,其可用概率值pn表示。而BLEU 模型的匹配度计算则如式(11)所示,且BLEU 值越高,表明算法性能越优。
式中,BP 为惩罚项,其可根据句子的长短进行取值,则有:
2 算法测试
2.1 测试环境
该翻译语料集合使用了WMT2020 作为训练语料集与部分验证语料集。为验证算法的工程应用能力,从互联网抓取了1 000 条与特定专业英语有关的语料集作为算法验证语料集。实验环境配置与样本数据说明如表1 所示。

表1 实验环境配置与样本数据说明
2.2 实验测试
实验代码部署在GPU 中,并利用TensorFlow 框架[13-14]进行代码测试。对比算法选择了RNN、BiLSTM[15]及BiLSTM+GAN 算法[16],训练语料集的数量则分别为1 万、5 万和10 万条,训练数据集运行10次后取平均BLEU 值。测试结果如表2 所示。

表2 不同算法的测试结果
由表2 可看出,对比其他机器翻译算法,该文算法在所有数量的训练集下表现均最为优异。且在训练语料为10 万条的情况下,与对比算法中性能较好的BiLSTM+GAN 算法相比,该文算法的BLEU 值提升了2.7。同时还可看出,随着训练集数量的增多,各算法的BLEU 值均有显著提升。但训练集数量也并非越多越好,当语料集大于5 万时,算法BLEU值的增长逐渐减弱。由此表明,在训练集语料条数为5 万时,算法可兼具速度与性能。
除了WMT2020 语料集合外,文中还选择了对应的铁道与车辆相关专业语句来进行翻译。并将所提算法与机器翻译算法的结果进行对比,结果如表3所示。

表3 专业术语翻译结果对比
由表3 可知,当句子中包含专有含义词汇时,例如coupler、multiple unit,常规含义为耦合器与多单元,而在学科专业英语中则表示车钩、动车组。在对该类词汇进行翻译时,该文算法能准确地完成句子翻译,而网络翻译则无法对专业词汇进行翻译。此外在句子整体翻译的流畅性上,该文算法相较网络翻译也较优。由此证明,该文算法能对相关专业词汇进行准确、流畅地翻译。
3 结束语
文中研究了一种基于循环神经网络的专业英语词汇机器翻译算法。该算法以编码器-解码器为框架,使用改进的RNN 算法和多头注意力机制对输入语料数据进行训练。编-解码器均有六层结构,每层都包含有多头注意力机制和全连接层。实验测试中,该文算法的BLEU 值在对比算法中为最优,且对专业英语语料地翻译也较为准确、流畅,证明其具有良好的应用价值。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
海外华文教育(2016年1期)2017-01-20 08:21:58
电子器件(2015年5期)2015-12-29 08:42:24
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
