
融合依存句法和实体信息的临床时间关系抽取
2024-01-24 09:20黄汉琴顾进广符海东
计算机技术与发展 2024年1期
黄汉琴,顾进广 ,符海东
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室,北京 100038;3.武汉科技大学 大数据科学与工程研究院,湖北 武汉 430065)
0 引 言
在临床研究方面,从电子健康记录抽取时间关系用于多种应用,如临床问题解答、决策支持系统、临床时间线构建等。这些应用需要清晰的时间顺序做支撑。时间顺序在临床文本中有着重要的作用,很多的临床事件都需要在时间顺序下才彰显意义。
时间关系(TLINK)表示时间表达式和临床事件之间在时间线上的关系。临床事件是与临床相关的任何事件,包括患者的临床概念和医疗事件。时间表达式是指在临床文本中提供有关临床事件的发生时间、时间段、发生频率。现有的TLINK分为4种时间关系,考虑中文临床文本中存在大量的复杂时间和关系,现有的时间关系不能全部表达这些事件之间的关系,该文将时间关系抽取任务扩展。
TLINK抽取任务常用的方法有基于规则,机器,深度学习的方法。基于规则的方法依靠大量的人工抽取句子的语义特征制定规则,需要耗费大量时间且移植性差。近年来,基于深度学习的神经网络模型取得显著的成果,此类模型能自主挖掘出句子的语言特征。
文中数据集采用中文临床抑郁症病例文本,此类文本语义复杂,存在不均衡性,理解文本的语义需要学习全局上下文特征也要关注重要内容的局部特征。Lin等人使用动态或固定窗口来执行局部区域关注[1-2];Bugliarello等人利用语法限制注意力获得更好的关注[3-4]。
两种方法对重要的局部区域进行更多关注得到局部特征再和全局信息融合。在此基础上,借助BERT模型的自注意力机制能从一个句子的众多信息中找到局部重要信息加权处理,该文引入依存句法分析临床文本的局部重要区域,抽取局部重要特征信息和整体句子信息共同学习。
同时考虑时间关系抽取任务学习时间实体和临床事件实体的信息,现有的构造方法大多数使用三段式池化拼接方法来展开[5]。借鉴此方法,该文额外对BERT层的输入嵌入实体类型,并在输出表征对实体信息进行特征交互来获得更全面的实体信息。该文的贡献如下:
(1)针对中文临床文本提出复杂时间关系抽取任务,扩展现有抽取任务的时间关系类型。
(2)为追求全局信息和局部信息的兼具问题,针对临床文本设计依存特征抽取算法,提出将BERT的自注意力层和依存句法分析结合的方法,该模型能在现有的BERT架构上快速嵌入实现。
(3)为获得更全面的实体信息,从BERT表征抽取额外的两个实体信息,结合内积和哈达玛积实现特性交互,使用四段式池化拼接得到关系向量。
1 相关工作
当前时间关系抽取的相关工作与两个共享临床时间关系抽取任务有关:Informatics for Integrating Biology and Bedside(i2b2) challenge[6]和2015年开始的TempEval challenge[7]。自深度学习流行后,应用BI-LSTM,CNN,BERT等深度学习模型抽取时间关系成为主流,以下将介绍这些方法的研究现状。
基于BI-LSTM方法:Juline等人[8]使用BI-LSTM模型融合特征工程抽取包含关系,证明增加经典的特征收集更多信息是有益的方法,他们在[9]收集句子信息额外对每一个实体类型构建特定分类器。Chen等人[10]在自我训练框架内构建语义异构嵌入的循环神经网络,利用基本特征丰富句子信息。这些方法聚集在进一步收集局部信息,丰富模型语义。
基于CNN的方法:Dmitriy等人[11]将XML标签编码关系参数的位置引入CNN模型去提取时间关系,用这种标记成为神经网络的输入,后续的CNN方法输入大多借鉴于此。Chen等人[12]描述了一种单个伪标记表示时间表达式的方式修改了token的标签用于CNN的输入。此类神经网络方法能自动进行特征提取,但是池化层会丢失大量的价值信息,对长距离句子来说,输出的表征难以概括全局信息。
即使以BI-LSTM和CNN为主的方法在时间关系抽取中表现较好,但是和bert为主的预训练语言模型存在一定差距。基于BERT方法,Lin等人[13]在BERT模型上引入全局嵌入来帮助进行长距离关系推理,并通过多任务学习来提高模型性能和泛化性,从而增强模型抽取的效果。Chen等人[2]在BERT模型上开发基于连续标记的固定的句子边界不可知窗口的处理机制,展示了BERT出色的长距离推理能力。近2年的临床关系抽取综述[14-15]都总结了微调BERT及其变体等语言模型在从临床文本中提取关系方面表现最好。为提升下游任务的学习能力,通过具体任务设计简单堆叠模块实现微调。基于此研究思路,该文使用BERT现有架构,通过对自注意力机制层与依存句法结合的方法获取句子的全局信息和局部信息。同时,使用关系抽取中常用的实体特征交互方法获得更多的实体信息。
2 方法与模型
2.1 时间关系抽取任务定义
TLINK时间关系是指电子病历中时间点与临床事件或临床事件与临床事件之间的时序关系。临床文本中存在大量的复杂时间维度,现有的时间关系仅表达这些事件之间的简单时间关系,复杂时间本体定义可以挖掘临床文本中更多的语义信息。该文依据CTO临床时间本体[16]将现有的时间关系抽取中常见的4种时间关系类型扩展为10种时间关系抽取。
病历中的时间点是指带有时间信息的短语,参考现有病历常见的时间表达,根据CTO临床时间本体定义了各种类型的时间语义,将所有时间总分为3种类型:时间点,时间段,时间集合。病历中的临床事件是指病历中有关病情的相关记录和医疗记录,参考现有病历常见的临床事件,该文将临床事件分为疾病,症状,检查,药物,手术、医疗事件,治疗。病历的时间与临床事件分类实例表如表1所示。
参考CTO临床时间本体,设定每一对时间关系的两个实体为A和B。临床事件实体依照时间线记录事件发生的起始时间,结束时间,频率等信息划分为在某一时刻完成这一件事,在某一段时间完成这一件事,在时间集合完成这一件事。使得时间实体和临床事件实体都能在时间维度上进行比较。时间关系为之前,之后,相等,遇见,共同开始,共同结束,相交,包含,全包含,部分包含。所有时间关系的定义如图1所示。根据每张图可以获取每一个时间关系的满足条件,例如时间点实体不可能和别的实体产生遇见,相交,全包含,部分包含这些时间关系。
该文将时间抽取任务定义为:(1)复杂句内时间关系抽取:指的是一个句子里面任意的时间点与临床事件的时间关系或临床事件与临床事件的时间关系都能在10种时间关系中找到答案;(2)复杂句间时间关系抽取:一个句子的医疗事件与相邻句子的医疗事件的时间关系能在10种时间关系中找到答案。后续实验与分析描述根据这两个任务分别标注数据集和训练模型进行实验。
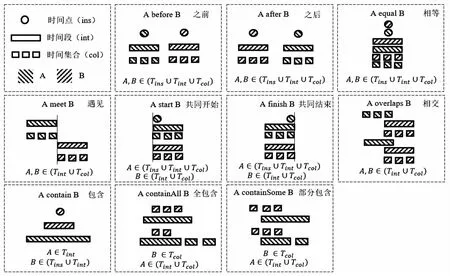
图1 时间关系定义
2.2 DS-EI-BERT模型
该文提出使用BERT预训练模型结合依存句法和实体信息对中文抑郁病临床文本进行时间关系抽取的模型(Enriching bert with dependency synatx and entity information,DS-EI-BERT)。DS-EI-BERT模型结构如图2所示。将输入句子嵌入实体类型,转化成句子输入序列,具体描述在2.2.1节;然后将句子传入依存权重矩阵处理器导出每个句子的依存矩阵,具体描述在2.2.2节;此依存矩阵会引导BERT的12层Transformer编码器层来训练每一层的全局信息和局部信息,具体描述在2.2.3节;然后实体-句子信息层提取出实体信息做特征交互,最后将句子信息和实体信息拼接得到最终输出,使用softmax函数得到最终的时间关系,具体描述在2.2.4节。
2.2.1 句子输入序列
该文的输入采用预训练模型BERT的输入方式。BERT模型的输入可以是单个句子,也可以包含一个句子对(句子A和句子B)。而这两种方式刚好可以对应句内关系和句间关系的输入。BERT预训练参数给出的vocab中有一些特殊作用的标识符,[CLS]标识符放在第一个句子的首位,作为整个句子的语义表示。[SEP]标识符用于分开两个句子,每一个句子结束后会紧跟一个[SEP]标识符。此外BERT输入可以在字符字典设定有意义的标识符,将时间类型和事件类型设置成特殊的标识符。时间分类中,instant的标识符为[INS],interval的标识符为[INT],collection的标识符为[COL]。临床事件分类中,disease的标识符为[DIS],symptom的标识符为[SYM],examination的标识符为[EXAM],medication的标识符为[MED],operation的标识符为[OPE],medical event的标识符为[MEEV],cure的标识符为[CURE]。
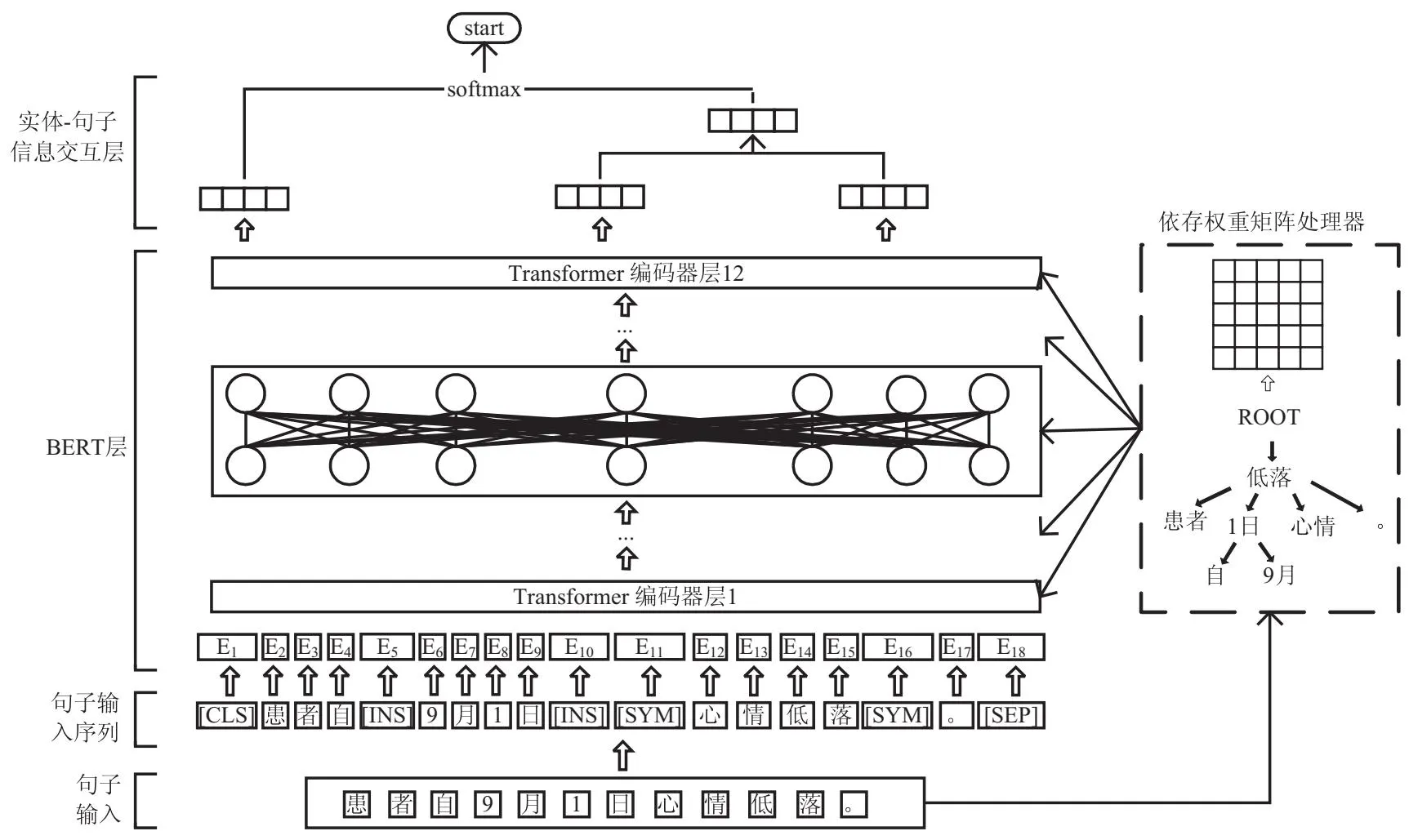
图2 DS-EI-BERT模型结构
举例说明句内的输入模式:“ [CLS]患者自[INS] [INS]9月1日[SYM]心情低落[SYM]。[SEP]”。句间的输入模式:“[CLS]8月服[MED]奥氮平[MED]。[SEP]一月后[MEEV]自行停药[MEEV]。[SEP]”通过这个方式能让模型更好学习两个实体的关系。
2.2.2 依存权重矩阵处理器
为了更好地挖掘句子包含的整体价值,时间关系抽取需要更关注重要的词语,根据现有研究表明,BERT预训练模型中的注意力在训练时会关注不重要的虚词,对重要的局部区域进行更多关注,保证句子中重要的语义被充分学习利用。该文利用依存句法分析获取句子重要的依存特征,然后转化成依存权重矩阵,此矩阵传入BERT每一层的自注意力机制中限制注意力来帮助模型获得更好的关注。
对输入的句子进行依存分析,能将一个句子分析成一棵依存句法树,这棵树的最顶层节点是整个句子的核心词,其他词汇直接或者间接与它产生联系,整个树描述出词汇与词汇之间的相互依存作用。通过依存句法分析得到的依存句法树如图3所示。
参考孙健等人在中文时间关系抽取研究中对依存特征的使用[17],针对不同的关系类别制定句子上重要的依存路径,如表2所示。这些路径上的词汇与关系抽取的两个实体存在直接或者间接的支配与从属的关系,属于语句中语义丰富的词汇。
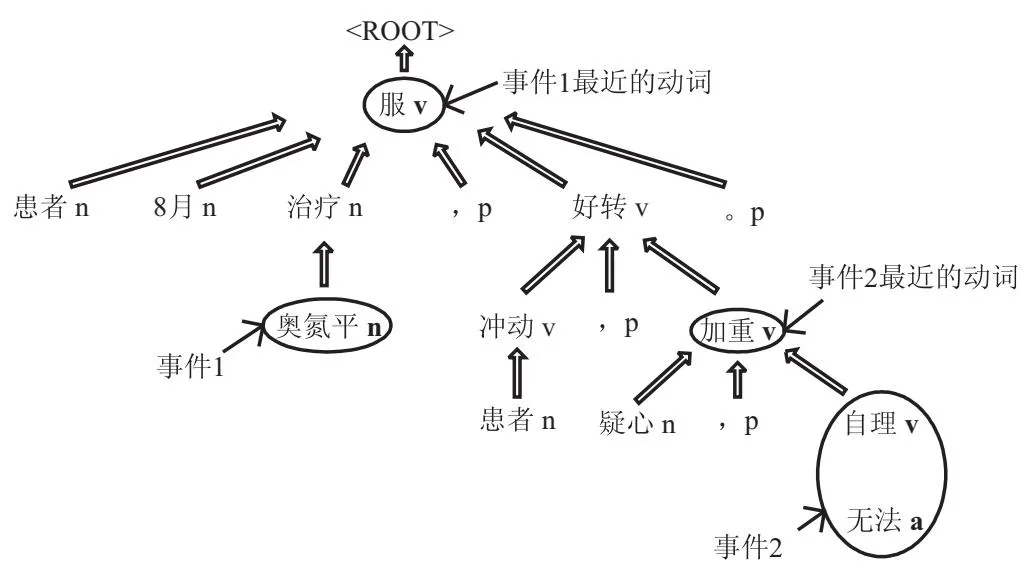
图3 依存句法树
假设一个句子S,句子中的两个目标实体分别为A、B,根据不同的依存特征找到所用路径上面的词汇,把这些词汇的下标做成一个集合Key,这个Key代表的就是这个句子依存特征词的下标集合。图3展示一个句子的依存句法树:A表示“奥氮平”,B表示“无法自理”,根据上表句内事件-事件时间关系的依存特征,从“奥氮平”追溯依存关系得到路径(“奥氮平”->“治疗”->“服”->“好转”->“加重”->“自理”->“无法”),计算所有路径最后得到Key集合[“奥氮平”,“治疗”,“服”,“无法”,“自理”,“加重”,“好转”]。以上假设符合句内关系抽取的情况,句间关系抽取涉及两个句子,则分别得到两个句子的集合Key合并再进行如下计算。
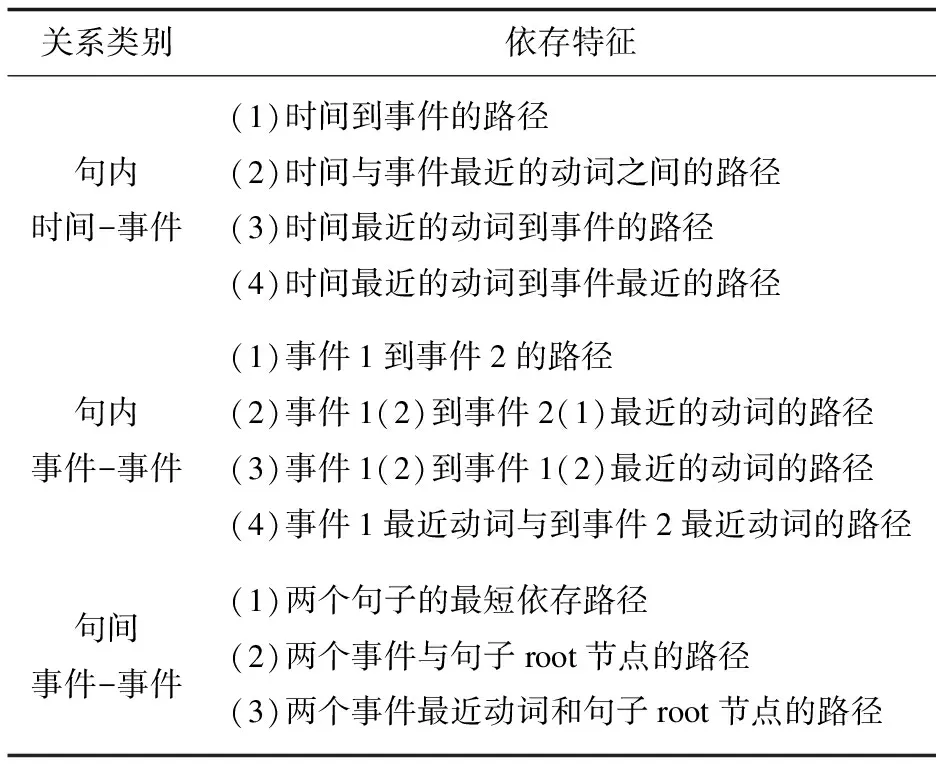
表2 句内/句间依存特征路径
得到这些重要的依存特征词汇集合Key后,将Key中的词汇和BERT输入序列对应,这些序列下标从1到s,如果BERT下标对应的字在Key的词汇中,则将下标记录在keyPoint集合,最后构建一个s×s维的二维数组Ds,这个矩阵的行下标为x,列下标为y,每一行和每一列都包含一个字对其他字是否存在依存关系需要关注的含义,计算如式1所示:
Ds[x,y]=
(1)
2.2.3 Transformer编码器层
不同于田园等人[18]将几种模型拼接一起得到语句更全面的信息,该文利用BERT-BASE模型[4]层层堆叠的12层Transformer编码器层来不断地训练全局有用信息。通过上一节得到的依存矩阵不断强化局部注意力与BERT本身的全局注意力结合,每一层编码器的具体结构如图4所示。
在每一层编码器层中,会计算所有token的3个向量(查询向量Q,值向量V,关键字向量K)。使用Q和K做点积,能得到每一个token需要对其他token关注的权重系数Scoreg,这也是每一层自注意力层的全局attention分数,Scoreg计算公式如式2所示。
Scoreg=Q·KT
(2)
该文还需要获取每一层具有依存句法信息的局部attention分数Scorel,使用依存句法矩阵对Scoreg做点积获取包含句法信息的注意力权重,可以得到任意一个token对其余所有存在依存关系的token的权重和矩阵,Scorel计算公式如式3所示。
Scorel=Ds·Scoreg
(3)
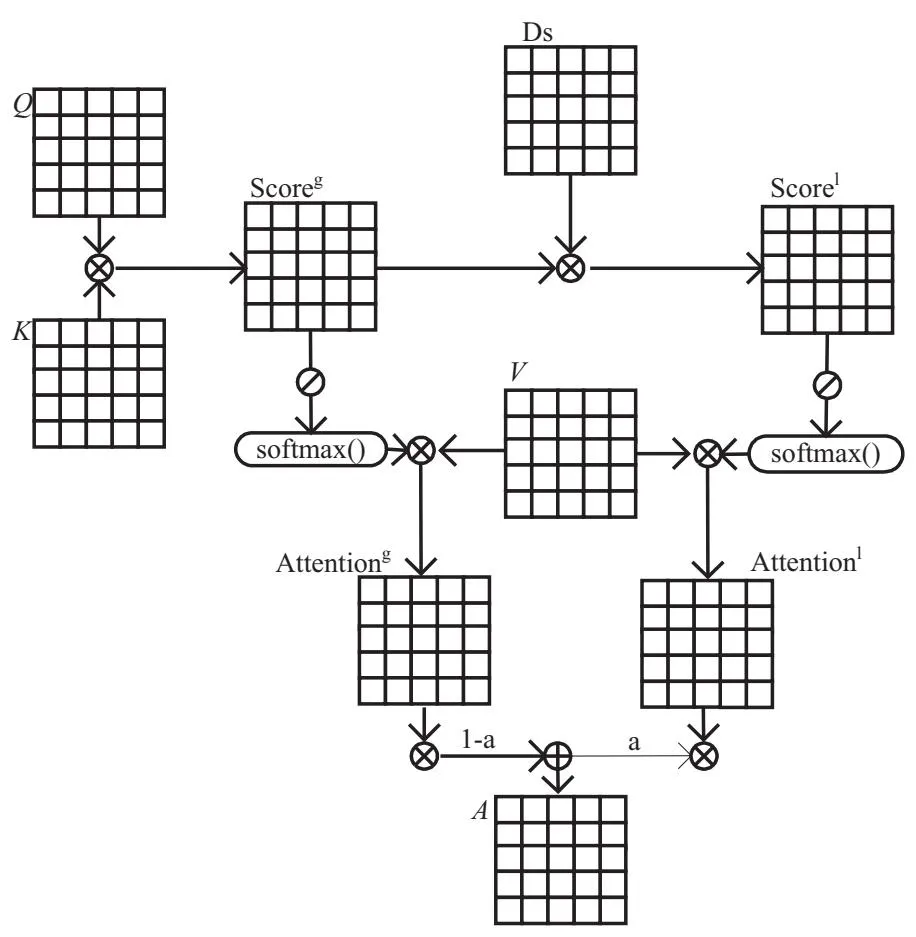
图4 Transformer编码器层结构
对这两个attention分数做归一化处理,然后对V加权求和分别得到这一层编码器注意力表征Attentiong和依存句法局部注意力表征Attentionl。计算公式如式4和式5所示。这里的d是指嵌入维度。
(4)
(5)
而最后的输出表征是在两个表征代表的全局信息和局部信息找到一个平衡。针对每一个token,设置阈值αk,k∈[0,s]用于组合全局和局部注意力。这个值是可变的,更大的阈值意味着更多的注意力集中在句法信息上,对于与依存句法矩阵没有关联的token,这个αk为0;对于有关联的token,这个αk为0.5。计算公式如式6所示。
(6)
每一个token得到的注意力输出如下,然后汇总可得此层的注意力表征输出Ak,最后传给下一层继续此循环,最后得到整个BERT层的输出表征H。与原始架构相比,文中方法只是在每一层编码器中加入依存矩阵Ds和α进行运算,使得此方法较容易在现有的BERT代码中嵌入实现,比起很多论文复杂的模型叠加来训练更全面的表征无疑是精简的。计算公式如式7所示。
(7)
2.2.4 实体-句子信息交互层
时间关系抽取已获得丰富的句子信息,接下来需要获取句子中时间实体和临床事件实体的信息,常用方法[19]将句子信息和两个实体信息池化后拼接进行关系分类。然而这样的拼接并不能得到实体的交互信息,为得到这些实体的交互信息,现有方法会使用全连接,外积,内积,哈达玛积。该文在FiBiNET的Bilinear-Interaction基础上[20],提出利用现有的依存矩阵引导权重结合内积和哈达玛积来获得实体交互信息,内积和哈达玛积交互会考虑不同特征对于预测目标的重要性程度,给不同的特征根据重要性程度进行加权。
整个BERT层最后的输出词向量为H:
H=[h0,h1,…,hi,…,hj,…,hl,…,hn,…,hs]
(8)
由于每一条输入句子前加上了[CLS]标识符表征整个句子,所以取第一个向量h0代表整个句子信息。对于句子中第一个实体e1,获取e1在句子的下标为i到j,那么hi到hj是实体e1的最终隐藏向量。对于第二个实体e2,获取e2在句子的下标为l到n,那么hl到hn是实体e2的最终隐藏向量,取这些向量的平均向量he1,he2来获得目标实体的向量表示。然后通过激活函数和全连接层分别得到最终的句子向量和实体向量表示。W0∈Rd×d,W1∈Rd×d,W2∈Rd×d,其中d是BERT的隐藏向量大小。然后将实体1的最终表示与依存代表的权重矩阵进行内积,再与实体2进行哈达玛积就能获得两个实体重要维度上的信息。计算公式如式9~式14所示。
(9)
(10)
H0=W0[tanh(h0)]+b0
(11)
He1=W1[tanh(he1)]+b1
(12)
He2=W2[tanh(he2)]+b2
(13)
Hbili=He1·DS⊙He2
(14)
然后将H0,He1,He2,Hbili连接起来获得包含重要信息的句子信息和丰富实体信息的向量H',这里设置W3∈RL×3d(L为时间关系总数10),以上b0,b1,b2,b3为偏置。添加一个全连接层和softmax层,该文使用交叉熵损失函数。计算公式如式15和式16所示。
H'=W4[concat(H0,He1,He2,Hbili)]+b4
(15)
p=softmax(H')
(16)
3 实验与分析
3.1 数据集
鉴于目前没有中文时间关系数据集,该文在私有数据集和公有数据集上进行中文临床文本时间关系研究。私有数据集源于合作医院抑郁症临床数据(Chinese Medical Record of Depression,CMRD),应医院要求不予公开。主要内容包括患者的个人信息、入院日期、出院日期、现病史、个人史等信息。抑郁症文本包含病人所有的病史,拥有较长且完整的时间线描述病人的病情和住院情况,适用于时间关系抽取任务。公开数据集源于2020CCKS的骨科临床文本,本身有标注好的实体信息。
抽取每一个句子的时间实体和事件实体或者事件实体和其他事件实体作为关系候选对,然后标注它们的句内和句间时间关系。最后共标注了100份电子病历数据。标注出的句内和句间数据集如表3所示,总样本以8∶2分为训练集和测试集。
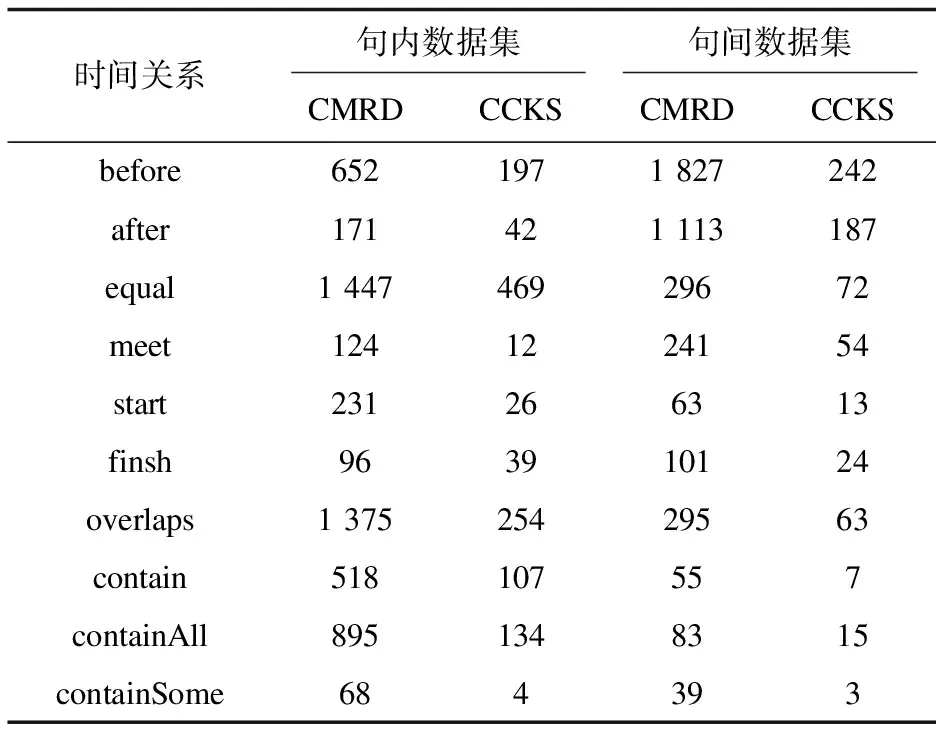
表3 句内和句间数据集数量
3.2 实验设置
所有实验运行在搭载了Tesla P-100 PCIE显卡和Intel(R)Xeon(R) CPU E5-2600 v4 @ 2.00 GHz型号CPU的机器上,使用PyTorch1.4.0作为深度学习框架,依赖Python 3.7环境下完成实验。
文中方法实现基于huggingface官网的bert-base-chinese模型,依存句法分析使用spacy的zh_core_web_sm-3.3.0版本。
句内时间关系抽取实验和句间时间关系抽取实验是分开实现的。实验基线模型为原始BERT[4]和丰富实体信息的R-BERT[5]。为评测DS-EI-BERT模型在时间关系抽取任务的有效性,将与BERT和R-BERT在相同数据集上进行比较。为验证文中模型的竞争力,在文中数据集上对比了现有的时间关系抽取最好的模型BERT-TS[2]。除此之外,对比了相关工作中其他深度学习模型。Juline等人[8]提出的BI-LSTM方法同样是在已知实体情况下识别实体之间存在的关系,使用TensorFlow实现模型。Dmitriy等人提出的CNN方法[11]使用时间表达式的类型代替时间实体作为CNN的输入,文中亦在BERT的输入层融入实体类型信息。
3.3 评价指标
实验采用精确率(Precision)、召回率(Recall)和F1值(F-score)3个指标来评价中文电子病历中时间关系抽取的性能。计算公式如式17~式19所示。
(17)
(18)
(19)
3.4 结果与分析
使用不同的参数训练模型后,以下实验中 BERT模型的超参数设置:最大序列长度为128,学习率为1e-5,batch为16,dropout为0.1。CNN模型的超参数设置:最大序列长度为128,学习率为1e-4,batch为50,dropout为0.25。BI-LSTM模型的超参数设置:最大序列长度为128,学习率为1e-3,batch为64,dropout为0.4。
3.4.1 句内时间关系抽取
实验结果如表4所示。从表4可以看出,BI-LSTM和CNN取得的P,R和F1值都比预训练BERT及衍生方法的低。CNN能捕捉局部语言信息,但是对于中文这种具有长距离的句子,不能很好地捕捉上下文语义,实验效果并不好,P和R相比之下存在较大差距;而BI-LSTM通过递归不断捕捉句子上下文语义,P值相较CNN提高4.4百分点,但是和BERT的自注意力机制捕捉信息能力存在差距,此外BI-LSTM的训练时间过长,和其他模型比较起来需要更多的计算资源。这里也能看出对于时间关系抽取这一项任务,模型学习句子整体信息极为重要。
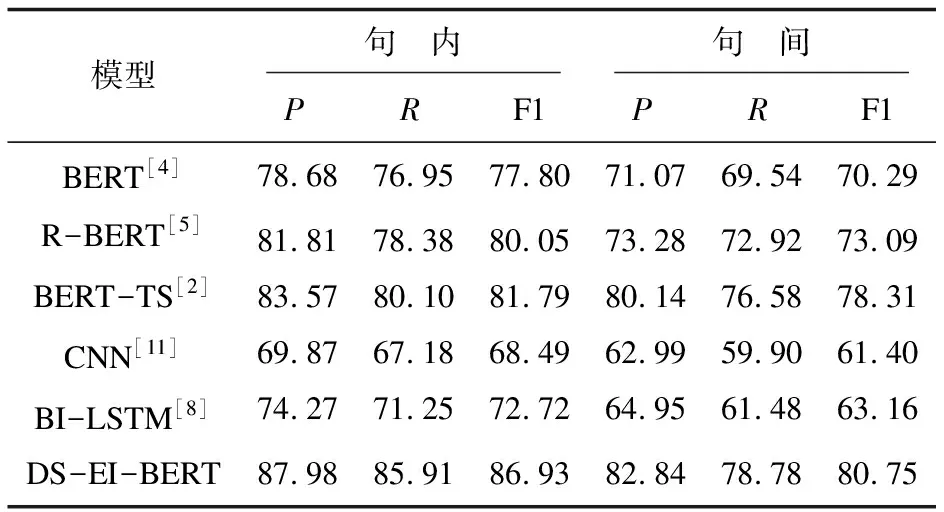
表4 句内与句间时间关系对比实验 %
预训练语言BERT模型系列表现优异,BERT原始架构也要比CNN,BI-LSTM表现优异,其F1值达到77.8%。R-BERT对比BERT模型学习句子中的实体信息,进一步提升时间关系抽取的效果,在F1提升2.25百分点。这两个基线模型实验证明实体信息能帮助时间关系抽取,笔者认为抽取实体信息能改善时间关系实体跨度大的问题。
文中模型DS-EI-BERT在表4中在P,R和F1上优于其他模型。原因在于自注意力机制层使用依存句法进行全局信息和局部信息提取,可以帮助BERT更好地学习句子语义。而使用两个实体进行特征交互进一步丰富了实体信息,让模型进一步提升使得F1值达到86.93%。
最后和现有时间关系抽取最好的模型BERT-TS对比,P,R和F1值都有不错的提升,分别提升4.41百分点,5.81百分点和5.14百分点,验证此方法在现有的时间关系抽取模型中都有不错的竞争力。
3.4.2 句间时间关系抽取
实验结果如表4所示,句间实验的整体效果较句内实验在P,R,F1值都有退步,分别降低5.14百分点,7.13百分点,6.18百分点。原因在于句间的语句比较句内的语句,无论从输入句子长度还是整体句子复杂度都有提升,对模型的语义理解有更高的要求。BERT系列实验效果比其他深度学习模型还是有不错的提升,但是与句内时间关系相比,P,R和F1值都有退步。
文中模型DS-EI-BERT在表4中在P,R和F1上依旧优于其他模型,分别达到82.84%,78.78%,80.75%。但是BERT-TS也有非常好的效果,F1值达到78.81%。可以看出,时间关系抽取不仅从模型提升上能够提高抽取效果,从关系实体候选策略入手也能提升不错的效果。
3.4.3 消融实验
最后为了验证依存句法和实体信息的有效性,进行了消融实验,一共设计4组实验,设计只保留依存句法矩阵引导自注意力机制的DS-BERT和只保留实体信息层的EI-BERT进行消融实验,结果如表5所示。
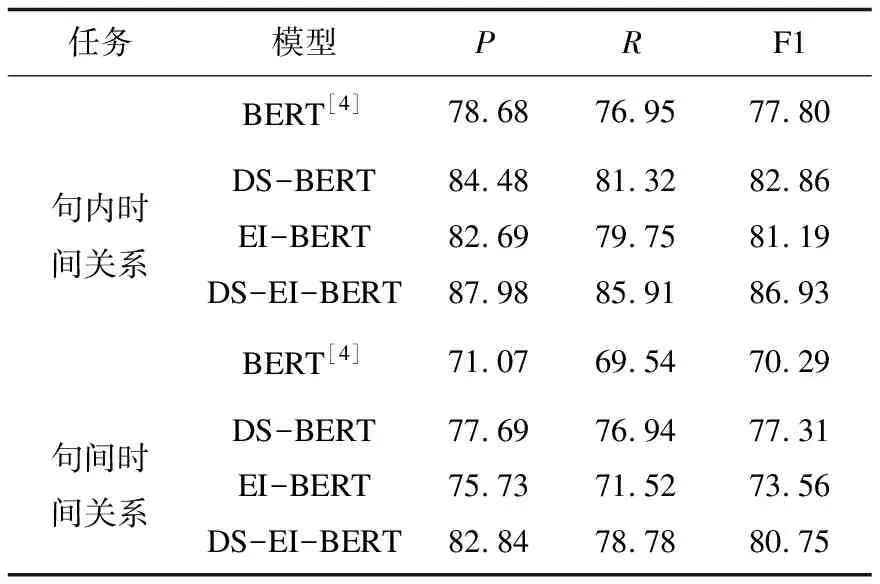
表5 句内/句间时间关系消融实验 %
句内和句间消融实验模型EI-BERT与BERT对比F1值分别提高3.39百分点和3.27百分点。进一步验证了提取出更多的实体信息能提升抽取效果。句内和句间消融实验模型DS-BERT与BERT对比F1值分别提高5.06百分点和7.01百分点,也显示依存句法和实体信息的有效性,且对于句间这类长距离的抽取任务,依存句法能帮助模型学习长句子的重要部分获得更好的结果。DS-EI-BERT集中句子信息和实体信息,最大程度提高模型效果,使得P,R,F1值达到最高。
4 结束语
临床时间关系抽取作为临床信息抽取中重要的分支,如何从一个复杂冗余的临床病例文本抽取精确的时间关系有着重要的作用。该文发现中文数据集的复杂时间描述难以使用现有的时间关系任务展示时间线,于是扩充了复杂时间关系抽取任务。并且针对复杂时间关系句子语义的复杂性,从句子信息和实体信息提升模型实验效果。利用BERT模型的自注意力机制融合输入句子的依存句法特征,帮助句子充分利用依存句法信息,引导BERT关注更有用的信息;利用输出表征的实体信息进行特征交互来丰富实体信息。在句间时间关系抽取中只考虑相邻句子的时间关系抽取,在后续研究中,考虑使用滑动窗口来扩大关系候选对的面积,从而研究一段文本之中包含的时间关系。
猜你喜欢
中国设备工程(2023年16期)2023-08-29
计算机应用(2022年8期)2022-08-24
计算机系统应用(2020年8期)2020-03-22
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中华手工(2017年2期)2017-06-06
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国美术馆(2016年6期)2017-01-19
中外会展(2014年4期)2014-11-27
