
基于卷积神经网络的嵌入式视觉感知交互系统设计与实现
2024-01-23 04:00王智勇林鸿生周怡伶
科技创新与应用 2024年3期
陶 金,王智勇,林鸿生,周怡伶
(1.海军士官学校,安徽 蚌埠 233012;2.92682 部队,广东 湛江 524000)
视觉感知交互系统在民用领域应用广泛。早期的视觉感知一般是物体探知,如避障拐杖[1]、电子式行进辅具[2]、导盲机器人[3]等,其原理大多都是利用可见光、红外、声呐等传感器进行探测,判断障碍物的情况,然后通过报警的形式提醒用户,但随着AI 技术的进步,仅探测功能并不能满足“感知”层次的需求,即对环境与物体的性质判断与属性解释。在这方面,语音智能助理发展较快、应用更广,语音智能助理主要意义在于解放双手,语义辨识功能就是感知的直接体现。因循这一思路,可以开发一种对环境与物体进行视觉感知,配合辅助语音交互的嵌入式系统,具有较强的现实意义和应用前景。
该系统的开发需要考虑以下几个方面。
1)采集图像以后,需要判断图像中存在哪些目标以及获取它们的坐标位置。
2)采用卷积神经网络对不同的目标进行分类识别,并在嵌入3 式平台上实现。
3)语音识别如何实现。
4)语音播放如何实现。
1 系统硬件设计
系统以ARM Cortex-A9 处理器为核心,频率达到650 MHz,片内集成了32 KB 指令Cache 和32 KB 数据Cache,NEON 媒体处理引擎,非常适合于图像处理。
系统构成主要包括语音识别、语音播放、图形采集、中央处理控制等功能模块。硬件组成框图如图1 所示。由图1 可看出,语音识别模块收集语音指令,引导图像采集模块完成图形采集,中央处理控制模块对采集的图像数据进行计算处理,完成图像中逻辑目标的分割并智能识别,识别结果通过语音播放模块输出给用户。
1.1 图像采集模块
考虑到系统使用的是Ubuntu 操作系统,图像采集模块采用支持UVC 协议的Rmoncam S907 USB 摄像头为图像采集设备。镜头焦距为6 mm;输出分辨率为640×480;像素为130 万。
1.2 语音识别模块
语音识别目前主要有2 个方案:本地语音识别方案和云端语音识别方案。考虑到云端语音识别需要连接网络,所以采用本地语音识别方案。识别框架如图2所示。
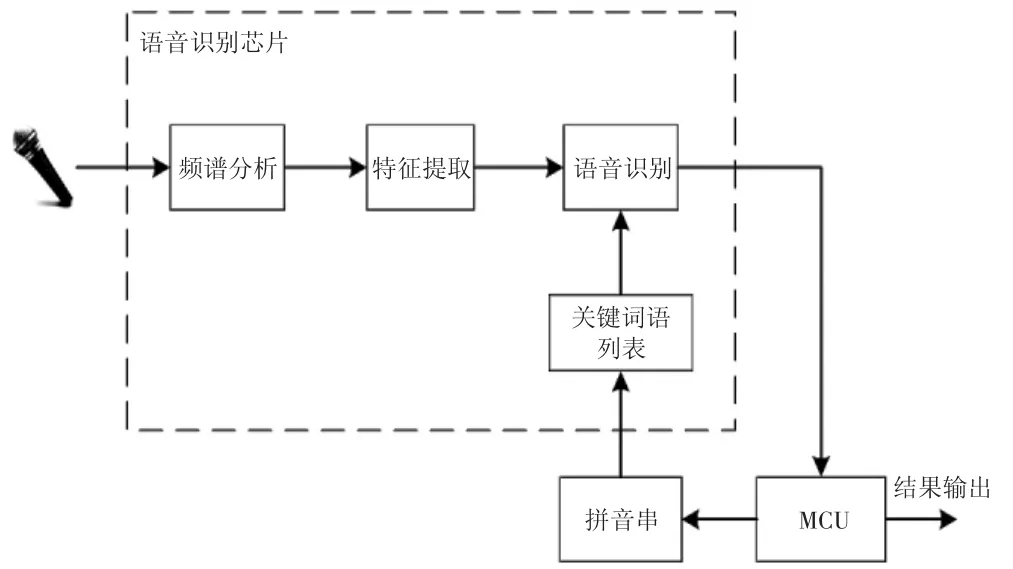
图2 本地语音识别框架
1.3 语音播放模块
语音播放模块采用MP3 播放模式,选用型号为BY8301-16P 模块。该模块支持MP3、WAV 格式的解码,内部独立存储介质使用SPI-FLASH,设计安装功率为3 W 的语音播放驱动单元。
2 系统软件设计
本系统底层硬件提供驱动支持、中断管理、内存管理等功能通过嵌入式操作系统实现,当系统启动后,引导程序将启动操作系统并初始化各部分硬件,再进入目标分割与识别的主程序。本系统采用Ubuntu 操作系统。系统软件流程如图3 所示。
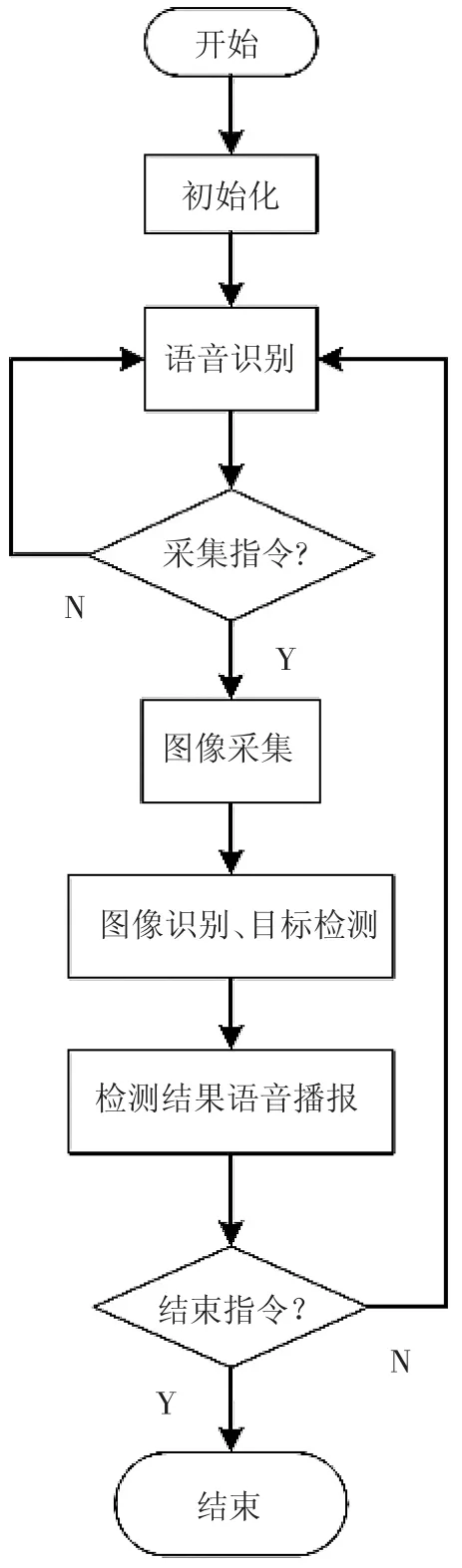
图3 系统软件流程
本文重点研究其中的目标分割算法[4-10]与目标识别算法[11-13]。
2.1 目标分割算法
该算法的主要程序步骤如下。
1)选择基于面截块的图像分割算法获取初始化分割截块R={r1,r2,…,rn}。
2)将拟合度集合初始化S=Ø。
3)计算相邻分割截块拟合程度量化值,并将该量化值以元素形式纳入拟合度集合S中。
4)查询到拟合度集合S中拟合度最大的2 个分割截块。在此标记为ri和rj,将ri和rj合并成为一个分割截块,并标记为rt,查询上一步中所涉及的ri和rj分别相邻的分割截块,再次计算获取拟合度,并将此值从拟合度集合S中剔除;再次计算rt与相邻分割截块(即第一步中与ri或rj相邻的分割截块)的拟合度,重新将新获得的计算结果纳入拟合度集合S中;最后,将通过合并得到的新分割截块rt添加到分割截块集合R中。
5)逐一提取各分割截块的边界矩形,联合所有矩形,即可获得目标物体的概略位置。
此步的难点在于原始分割截块的获取和拟合度的计算。
2.1.1 原始分割截块的获取
将最小生成树算法与分割截块合并方法结合,采用基于自适应阈值的快速最小生成树分割方法,分别取2 个相邻分割截块各自的最大边权值与阈值求和数,当该分割截块之间的阈值小于上述数值使即将此两分割截块进行合并处理。
式中:K为一个常数,|C1|和|C2|为分割截块C1和C2的二维平面大小,Int(C)为最小生成树中分割截块C的最大边权值。为分割截块C1和C2边缘连接指数的最小权值。
2.1.2 拟合度的计算
1)颜色拟合度。为使用高维向量表示每个分割截块的颜色特征,使用L1 范数归一化逐一颜色通道计算获得图像的数值分布直方图,由于每个颜色通道的直方图有25 位,因此各分割截块可得到唯一对应的75 维向量。分割截块之间颜色拟合度通过下面的公式计算
合并分割截块时,新生成分割截块的直方图需要重新计算,如下式所示
2)纹理拟合度。每个颜色通道含8 个不同方向,设方差σ=1,运行高斯微分,获得10 bins 的分通道单色值直方图。参照颜色拟合度计算方式运行纹理拟合度计算,新分割截块纹理特征计算过程亦类似。
3)二维平面大小拟合度。通过合度方法计算二维平面大小数值,数值小的分割截块优先合并
4)吻合拟合度。取已合并分割截块Bounding Box值,该值大小对应吻合拟合度低与高,即值越大,吻合拟合度越低,反之越高。
最后,组合上述各类拟合指标的拟合度计算方式。
2.2 图像分类识别算法
作为最常见的深度学习网络架构,卷积神经网络在解决图像目标识别方面具有非常实用和卓越的效果。
综合考虑运算速度和识别准确率,本文采用卷积网络的典型架构。采用的分类网络结构如图4 所示。输入彩色图像尺寸为32×32×3,卷积层组合(3×3 卷积、3×3 卷积、池化层)重复3 次,2 个全连接层都含有1 024 个神经元,输出层为SVM。其中卷积核大小均为3×3,池化层尺寸为2×2。

图4 图像分类识别网络结构
本文采用Cifar-10 和Cifar-100 作为物体识别的数据集。从2 个数据集中抽取10 个类别的数据组成一个新的数据集,用于网络训练。每个类别抽取600 张图片,其中500 张为训练集,100 张为测试集。
3 实验结果
为了验证本文方法的可行性,作者从网络上收集了简单背景的图片12 张,图片里共有物体21 个;收集了复杂背景的图片16 张,图片里共有物体21 个。
按照上述方法进行实验,重点对目标分割算法和图像分类识别算法进行验证。目标的分割结果在图像上以方框来呈现,如图5 所示;目标的识别结果以分类识别的概率大小来呈现。本文对简单背景和复杂背景下的场景进行实验,部分实验对象如图6 和图7 所示。简单背景的实验结果见表1,复杂背景的实验结果见表2。

表1 简单背景的实验结果
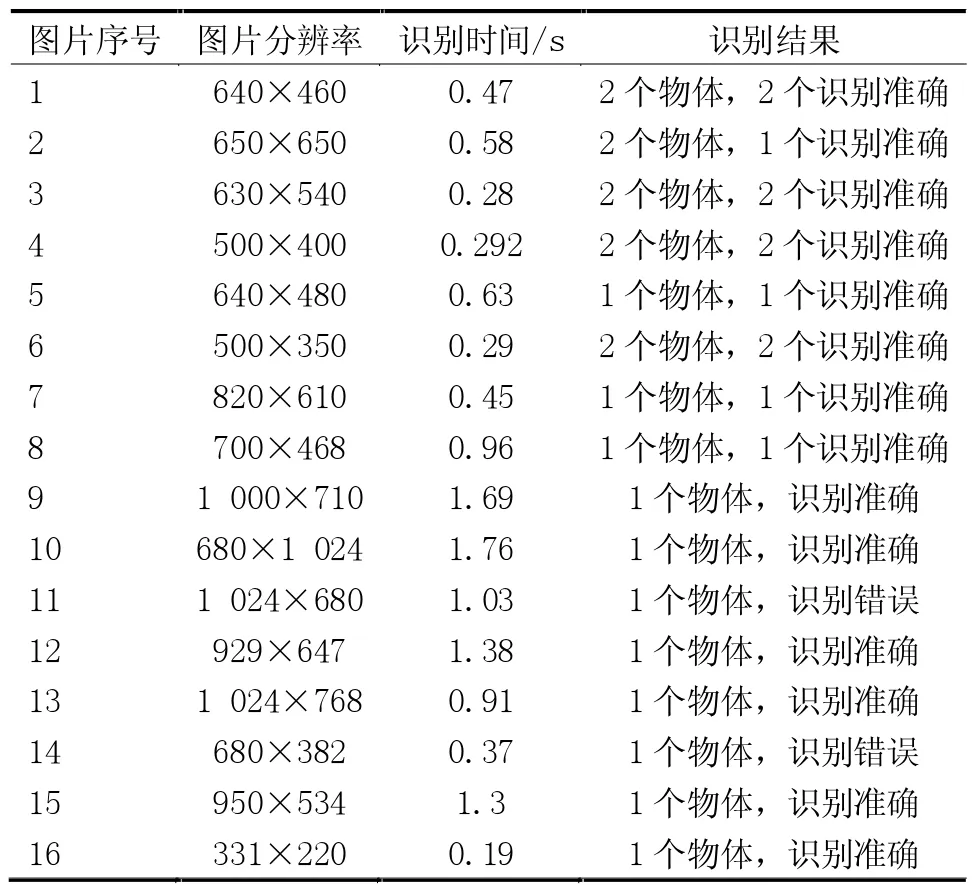
表2 复杂背景的实验结果
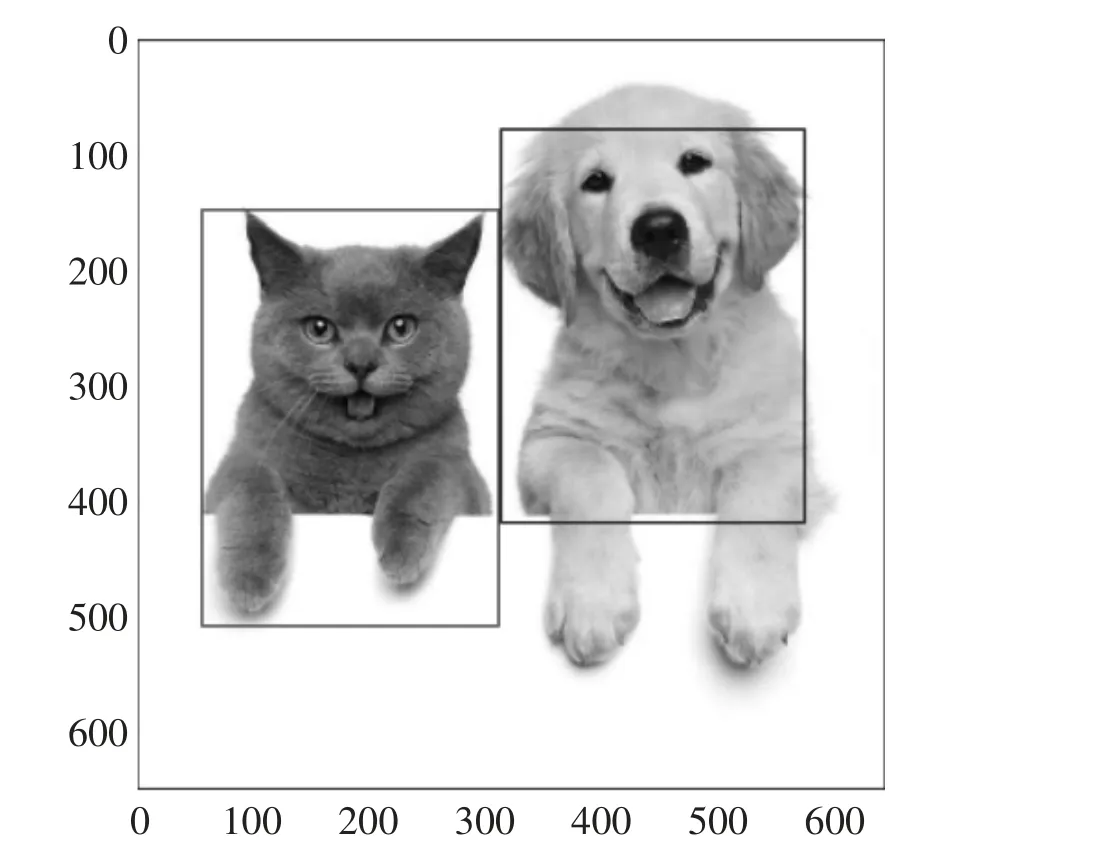
图5 目标的定位结果

图6 简单背景的部分实验对象

图7 复杂背景的部分实验对象
通过实验,得到如下结论。
1)简单背景和复杂背景下,均识别了21 个物体,其中3 个识别错误,识别准确率均为85.7%。
2)图像分辨率越大,消耗时间越多。
3)进行物体识别所消耗的时间比较小,适合于应用到嵌入式系统。
4)复杂背景的图片要比简单背景的图片耗时长。
4 结论
本文设计并实现了嵌入式视觉感知交互系统,实现了目标图像的采集、目标的分割、目标的识别以及语音识别、语音播放。针对设计的目标分割定位算法、目标识别算法,本文进行了大量实验,验证了系统设计的可行性。下一步研究方向是在嵌入式平台上采用卷积神经网络实现目标分割,提高分割的准确率及缩短运行时间,达到可以实时处理的水平,并将其应用于一些智能化系统之中。
猜你喜欢
汽车工程师(2021年12期)2022-01-17
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年14期)2021-01-08
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
北京航空航天大学学报(2018年1期)2018-04-20
贵州师范学院学报(2016年4期)2016-12-01
