
融合全局特征和时间信息的社会推荐研究
2024-01-22 11:05周华平周明
信阳农林学院学报 2023年4期
周华平,周明
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
在当前信息爆炸的时代,人们利用大数据这把双刃剑,在掌握信息、丰富知识、开阔眼界的同时,也被大量的“泡沫数据”所影响,被无效的信息所包围,无从下手,无从关注。此外,用户所关心的信息被严重封锁,无法获得。目前,缓解这些问题是当务之急。正是在这种情况下,推荐系统应运而生,以处理“泡沫数据”对用户的负面影响。社会推荐系统在帮助目标用户寻找潜在的感兴趣的项目方面有着广泛的应用。在社交推荐领域,由项目与项目、项目与用户、用户与用户组成的多方互动可以用图形来表达,项目和用户是节点,互动是边。因此,推荐系统与更丰富的社会网络相结合,利用它们之间传播的信息提高推荐的相关性和有效性。
社会化推荐考虑通过采用用户感兴趣的内容,即用户关系链中的推荐内容来进行推荐。近年来,Guo等人[1]研究了物品特征之间的关联性,并将用户特征空间和物品特征空间抽象为两个图网络,以提高社交推荐的准确性。Liu等人[2]提出了一个同时发现多种复杂关系的物品关系图神经网络[3],并为不能直接获得的物品或用户信息提供了一个解决方案。关于关系,实体之间也存在高阶关系。许多研究考虑整合知识图谱和用户-项目图谱来捕捉这些高阶关系。鉴于图神经网络的力量,它们被纳入了本文的框架。
自注意力机制被应用于模拟行为之间的相互作用。Zhou等人[4]指出,在电子商务领域中,用户可能会进行多种行为,如浏览、购买和收藏产品,使用优惠券,点击广告,搜索关键词,撰写评论或观看商家提供的产品介绍视频等,因而从一个更全面的角度了解用户行为,能为我们提供不同的视角。然而,面对用户行为的异质性和多样性,现有的推荐模型难以提供更准确的推荐结果。具体而言,自注意力机制用于将用户每个行为的客观表示转化为其内部记忆中的表示。客观表示是指当用户A和B执行相同的行为时,行为本身的表示可能是相同的,但在A和B的记忆中,该行为的重要程度和清晰度可能完全不同,因为A和B的其他行为是不同的。
结合以上背景,本文提出了一种全新的图神经网络社交推荐系统。
-在特征融合阶段,为全局特征的融合引入了一个自我关注的机制。
-提出使用门控递归单元对用户和项目的时间交互历史进行建模。
1 基础定义
用U={u1,u2,…,um}和V={v1,v2,…,vn}分别表示用户和项目的集合,其中m和n分别为用户和项目的数量。L∈Li*j表示为用户与项目的交互图。用户ui对相应项目vj给出的评分值用来表示eij。如果用户不对项目进行评分或两者没有互动,则eij=0。一般来说,矩阵L是稀疏的。将用户社交图定义为PU=(U,QU),其中QU作为边集连接用户。
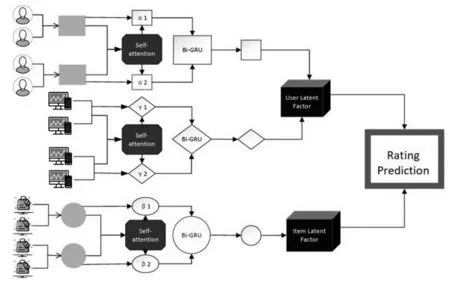
图1 GFTI-Rec的总体框架
输入层对原始数据进行预处理,然后构建项目关系图,进一步将预处理后的数据转换为用户和项目嵌入,之后通过本文新提出的门控递归单元网络进行聚合,获得用户的潜在因子偏差,项目建模被用来学习项目的潜在因子偏差。最后,潜在因素偏差通过输出层输出,最终得到预测分数。
2 模型分析

(1)
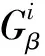
(2)
Rt=σ(wirxt+ht-1whr+br)
(3)
Zt=σ(wizxt+ht-1whz+bz)
(4)
接下来需要通过对神经单元进行门控来计算候选的隐藏状态pt,以便计算隐藏状态qt:
pt=tanh(wipxt+(Rt⊗ht-1)whp+bh)
(5)
qt=pt⊗(1-Zt)+ht-1⊗Zt
(6)
其中wip和Rt表示权重,bh表示偏差向量。
为了提高模型的性能,我们使用双向门控递归单元,如图2所示,输出是由全连接层的激活函数sigmoid得到的:

图2 双向门控循环单元示意图
由于缝合操作是由前向和后向传播的结果结合表示,所以最终的节点表示为:
(7)
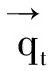
2.1 注意力网络
由于自注意机制可以有效地捕捉全局特征,它解决了一般注意力机制只能局部学习的残缺问题。同时,自注意机制不仅可以自动学习用户自己的特征,还可以提供物品属性的全面表述,见图3。
使用的自注意机制的输入由Q,K,V组成。这里Q,K,V的输入由用户和项目信息的嵌入向量组成,然后加权得到最终输出:
(8)
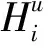
(9)
2.2 用户聚合
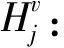
(10)
其中,σ用于表示非线性激活函数,w和b分别表示权重和偏差,X(i)表示聚合的用户意见感知互动。
(11)

最终得到的聚合函数如下:
(12)
2.3 社交聚合

(13)
其中,γ用于表示非线性激活函数,w和b分别表示权重和偏差,D(i)表示聚合的邻居意见感知的相互作用。
2.4 预测
(14)
其中goutput是一个三层神经网络的多层感知器。
2.5 模型训练
从评级预测的角度来评估我们提出的模型。让α为数据集中的所有评级的集合,α={(i,j):eij≠0}。对于评级预测的任务,有一个常用的目标函数:
(15)
3 实验
3.1 参数设置
3.1.1 数据集 我们将模型分别放在Ciao和Epinions数据集上进行评估,这两个数据集都取自流行的社交网站,都包含了用户、项目、评分和社交关系等组成部分,每个社交数据项的 “关注者数据指数”和“关注者指数”都包括在内(表1)。
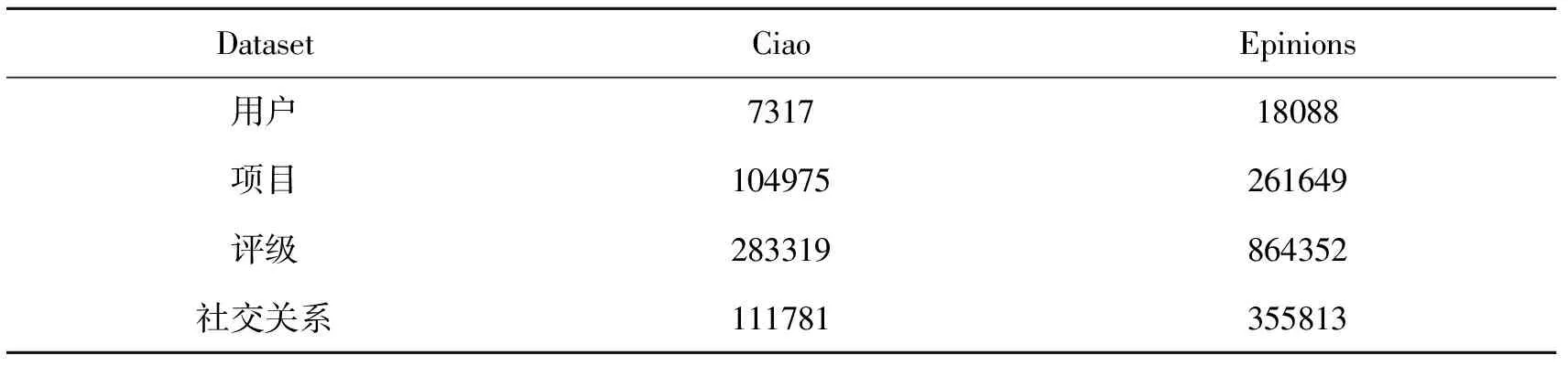
表1 Ciao数据集和Epinions数据集的特点
3.1.2 评价指标 在比较本模型与其他比较模型的评分预测性能时,我们使用两个指标来评估推荐算法的预测准确性,即MAE和RMSE。
(16)
(17)
其中,测试集中所有得分边的权重用yi表示,测试集中每条得分边的预测权重用xi表示。
3.1.3 基线模型 传统的推荐算法:PMFcite[5],SocialMF[6],它只使用用户和项目的潜在因素进行建模。
基于传统方法的社会推荐:SoReC[7],TrustMF[8],在原先评分信息之上使用社会信息,即同时使用评分信息和社会网络信息。
基于深度学习的推荐算法:Deep-SoR[9],一种深度社交推荐。
基于图神经网络的社交推荐算法: GraphRec[1],GDSRec[10]。

表2 对不同方法的预测性能进行评级
3.1.4 参数设置 我们使用Python 3.8、PyTorch 1.7和Cuda 11作为算法构建的环境。对于每个数据集的参数设置,0.8被用作学习参数的训练集,0.1被用作优化的验证集,最后0.1被用作测试集。对于嵌入大小,我们测试了[8,16,32,64,128,256]的值,而学习率在[ 0.0005,0.001,0.005,0.01,0.05,0.1]之间。对于Bi-Gru来说,层数不仅决定了模型的复杂性,也决定了对模型误差的影响,我们将其设置为[1,2,3]。
3.2 模块性能分析
3.2.1 自注意力机制的影响 本文分析和比较了以下2个模型的变体,以证明所提方法的有效性。
3.2.1.1 GFTI-Rec 使用一个自我注意机制来学习不同层次的信息(本文中的模型)。
3.2.1.2 GFTI-Rec-1 本文中的自我注意机制被一个由单层神经网络组成的注意网络取代,以证明本文中使用的注意机制的有效性。
3.2.1.3 GFTI-Rec-2 禁用注意层,直接输入上下文信息,以证明第1层的注意机制对模型在信息过滤中的作用。

图4 自注意力机制对获得潜在因子偏差的影响
自我注意α,β,γ:消除了三种自我注意机制,即通过项目聚合、社会聚合和用户聚合分别对用户的潜在因子偏差进行建模,通过基于均值的项目聚合函数对项目空间用户的潜在因子偏差进行建模,基于均值的社会聚合函数对用户的潜在因子偏差进行建模,通过基于均值的项目聚合函数对项目空间用户的潜在因子偏差进行建模,基于均值的社会聚合函数对社会用户的潜在因子偏差进行建模。
3.2.2 双向门控单元的影响 我们猜想,模型的复杂性可能由GRU的类型和GRU层的数量决定。为了避免过度拟合,我们分别研究了单层GRU、Bi-GRU和LSTM对模型误差的影响。
从图5中可以看出,Bi-GRU对数据集有较好的推荐作用,而层数过多则有较严重的过拟合现象,层数过少则削弱了模型的学习能力,如果使用单层GRU或LSTM,我们无法达到模型的最佳学习能力。

图5 双向门控循环单元对交互建模的影响
我们还研究了不同的超参数设置对我们的推荐算法有效性的影响:
(a) 迭代次数的影响;
(b) 不同批次大小的影响;
(c) 不同丢弃率下Dropout的影响。

图6(a) 迭代次数对模型性能的影响
(a)实验结果表明,模型的性能随着迭代次数的增加而变化,随着迭代次数的增加,模型性能先增加后减少。迭代次数为4时,模型性能最佳。如果迭代次数太少,模型训练就不能收敛,出现欠拟合。

图7(b) 不同的批次大小对Ciao和Epinions数据集的影响

图8(c) 在Ciao和Epinions数据集上不同丢弃率的Dropout的影响
(b)随着批处理量的增加,模型的性能并没有变好,而相对较小的批处理量,再加上一点随机性,就相当于在学习过程中加入了噪声,从某种意义上说,会有一些典范效应。
(c)在大多数非线性激活单元的输出和GRU层之间,通过增加一个辍学层和调整全局统一辍学概率,可以使模型在抑制过拟合方面有更好的表现。辍学概率的变化决定了模型的最佳预测误差,当辍学概率在0.5时,模型将在预测误差和过拟合之间达到良好的平衡当辍学概率在0.5时,模型将在预测误差和过拟合之间达到良好的平衡。
4 结论
可以看出,Epinions数据集比Ciao数据集有更多的用户项目互动,而且用户对特定项目的兴趣往往会随着时间而波动。因此,像PMF和NCF这样仅仅利用评级信息的模型在Ciao数据集上的表现稍好,但像SoRec和Graphrec这样利用数据集的社会关系的模型在Epinions数据集上的表现稍好。相对而言,我们的方法优于以前的推荐模型,因为它结合了社会数据,并更广泛地利用了数据本身的全局特征。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
学生天地(2020年6期)2020-08-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
系统医学(2016年8期)2016-02-20
