
基于SPD多尺度输入的ST-MASA的肺炎智能检测模型
2024-01-22 12:04李芳芳束建华阚峻岭殷云霞孙大勇
宿州学院学报 2023年12期
李芳芳,束建华,阚峻岭,殷云霞,孙大勇,马 春
安徽中医药大学医药信息工程学院,安徽合肥,230012
肺炎是一种常见的肺部感染疾病,如果不能及时诊断和治疗,会造成很高的致死率,特别是对儿童和老年人。肺炎的病因有30多种,而2019年底开始流行的一种新型冠状病毒,人类感染极易导致肺炎,即COVID-19肺炎。此肺炎会导致有基础疾病的人有较高的死亡率。为了提高肺炎现有的检测效率,提升检查准确率,医务人员经过临床实验发现,肺部X光片可以清晰显示COVID-19患者肺部的影像学病灶特征,并可以最大程度减少对孕妇和儿童的伤害。因此,肺部X光检测成为肺炎诊断的有效手段之一。但传统的影像科医生利用阅片灯来阅片,这要求医生具有丰富的临床经验才能实现高质量诊断;此外高强度的阅片也容易导致误诊和漏诊。为了提高肺炎的检测效率,降低医生的漏诊、误诊率,借助医学影像AI辅助检测来提高肺炎检测的效率和精确度对现有的肺部疾病治疗有着深远意义。
自2016年,深度学习技术步入了快速发展通道,已被广泛应用于医学影像处理——例如肺部X光片的疾病检测中,并成功提高了COVID-19肺炎早期检出率。Shervin等[1]在5 000张X射线图像数据集上训练了4个最先进的卷积网络用于COVID-19的检测,并实现了超过90%的灵敏度和特异度。Wang等[2]介绍了一种名为COVID-Net的深度卷积神经网络,可以从胸部X光图像中检测COVID-19病例,该网络是开源的,并对公众开放。Jain等[3]使用Inception net V3、XCeption net和ResNeXt进行分类。Zhang 等[4]利用几种CNN模型开发了一个智能系统,可以识别COVID-19,并将其与普通肺炎和健康的肺部区分开来。Li[5]等构建了一个诊断系统,该系统结合了若干种二维的CNN模型,对COVID-19、社区获得性肺炎(CP)和健康人群进行了分类;诊断结果的敏感度和特异度分别达到了90%和96%。
虽然这些模型使肺炎的智能检测质量得到了很大的提升,但如何提高多类型肺炎诊断的精度,降低漏诊、误诊率仍然是一个巨大的挑战。现有的肺炎检测模型通常面临着如下问题:其一,目前的研究多集中在一到两种特定类型的肺炎,即COVID-19与CAP或健康肺的区别;因此,怎样同时检测多种类型肺炎是所要解决的问题之一。其二,不同肺炎胸部X光片的视觉特征比较相似,或者有时早期的病灶特征并不明显;这些都导致检测较为困难。为了解决这些问题,提出了一种融合了空间金字塔分解(SPD)模块[6]和在Swin Transformer[7]中应用轴向多头自注意力机制ST-MASA(Swin Transformer with Multi-Head Axial-Self-Attention)的网络模型来进行新冠肺炎(COVID)、非COVID的病毒性肺炎(Viral_Pneumonia)、肺不透明(Lung_Opacity)和正常(Normal)的分类操作。先利用SPD生成肺部X光片的多尺度图像输入,然后对每个输入图像进行ST-MASA处理,接下来通过全局平均池化(Global Average Pooling)GAP和Concatenate Layer后,再通过分类模块进行分类。
实验在一个公开的多种肺炎胸片数据集进行训练和测试,实验结果对比ResNet50、ResNet101[8]、Inception net-V3[9]和Swin Transformer模型,其准确率、召回率、F1-Measure等指标均有一定的提升。
1 相关概念
1.1 空间金字塔分解(Spatial pyramid decomposition,SPD)模块
SPD可以提供一种灵活、方便、多分辨率的格式,模拟人类视觉系统中的多尺度图像处理;它被广泛应用于医学影像领域。在肺部X光片中既有小的肺炎病变,也有大的肺炎病变;小的病变(低对比度)的检测通常需要较高的分辨率;相反,检测大的病变则需要低分辨率的图像,这样才能抓住深层特征,具有全局感受野。所以选择使用SPD来生成肺部X光片的多尺度视图,这样才能更好地表示出肺炎病变在不同尺度上表现出的关键的影像学特征。
1.2 Swin Transformer
Transformer[10]是谷歌团队首次于2017年提出的用纯Attention搭建的经典模型,其摈弃了RNN[11]的顺序结构,使得模型可以并行化处理,大幅提高了训练速度。Vision Transformer (ViT)是Dosovitskiy于2020年提出的可用于图像处理任务的模型,ViT的出现突破了CV和NLP在模型上的壁垒,开启了计算机视觉领域的一个新时代。传统的Transformer的核心Scaled Dot-Product Attention模块机制如式(1)[10]所示。
(1)
Swin Transformer中使用的不再是普通的Transformer,它修改了Transformer中的Multi-Head Self-Attention(MSA)层,成为一个基于Shifted Windows的方法,即借鉴了卷积神经网络中的层次化构造的方法(Hierarchical feature maps),这样的设计有助于在做视觉场景任务中取得较好的效果。其中,把特征图划分为多个大小可以不一致且不相交的窗口,每个窗口内使用Multi-Head Self-Attention,这样可以减少计算量,尤其在底层较大的特征图上(传统的ViT是对整个特征图进行Multi-Head Self-Attention),因此这种新的方式叫做Windows Multi-Head Self-Attention,即W-MSA。而Swin Transformer的创新策略也就是W-MSA、SW-MSA,本质上是基于Windows和Shfit-Windows计算MSA。ViT从单一低分辨率提取特征,其全局计算自注意力的复杂度是O(n2);而Swin Transformer通过分层架构,使得model可以在不同的scale中使用,其计算复杂度是线性的O(n);这样的特性使得Swin Transformer应用于大范围的视觉任务变得可行。分层设计和移动窗口方法也证明对所有的MLP架构是有帮助的。
1.3 轴向注意力机制
轴向注意力机制[12]是将自注意力机制分解成两个一维的自注意力机制,即分别为高度轴注意力机制和宽度轴注意力机制。这样的分解不仅减小了计算量,而且可在全局注意力网络中恢复较大的感受野。可以让注意力覆盖到大的区域,这使得对全局关系建模成为可能。
2 提出的肺炎智能检测模型
提出的模型是对胸部X光片进行分类,模型主要融合了空间金字塔分解模块和在Swin Transfor-mer中应用轴向多头自注意力机制——Swin Transformer with Multi-Head Axial-Self-Attention(ST-MASA)的网络模型来进行分类操作。对数据集中的新冠肺炎(COVID)、非COVID的病毒性肺炎(Viral_Pneumonia)、肺不透明(Lung_Opacity)和正常(Normal)的X光片进行分类。其架构图如图1。
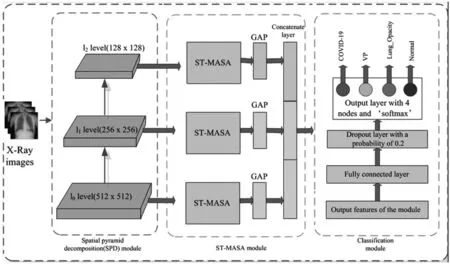
图1 所提网络模型架构图
利用空间金字塔分解(SPD)模块的策略,可以多尺度的输入肺部X光片,这样可以更好地提取关键的影像学特征,从而对大小形状各异的病灶进行检测、定位或分割等,提高了病灶检测的准确性。图中l0-l2分别代表金字塔的0、1、2三层。
将Swin Transformer中的W-MSA和SW-MSA编码器的多头自注意力机制(Multi-Head Self-Attention)部分改为多头轴向自注意力机制(Multi-Head Axial-Self-Attention mechanism,MASA)。其编码器结构图和轴向自注意力示意图见图2、图3。图2示意了使用了两个Transformer Blocks的输入输出情况,图3示意了其中的轴向自注意力机制。图2中,主要组件就是W-MASA、SW-MASA、Layer-Norm(LN)[13]和MLP;所有的Transformer结构都是一个轴向多头自注意力机制连一个前馈网络MLP,只不过在这两个组件之前要多加一个LN层,再增加一个残差连接。图中的残差网络结构的设计可以减少有效信息的损失,防止梯度消失或者爆炸。
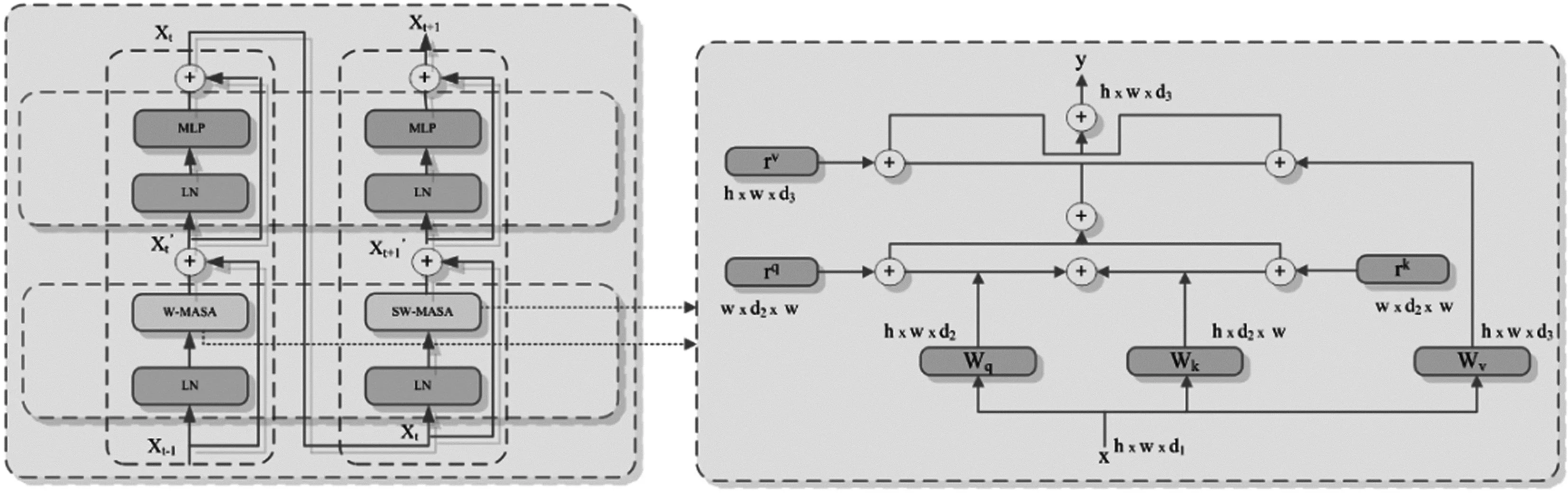
图2 Two Transformer Blocks 图3 轴向注意力机制
其相应公式如式(2)到式(5)所示:
(2)
(3)
(4)
(5)
模型应用的轴自注意力机制是将自注意力机制分解成两个一维的,即分别在高度和宽度方向上实施注意力机制。从两个维度计算,具有更好的计算效率,也可以适应原始的自注意力机制维度匹配,适用于反向传播。另外,提出的模型添加了位置偏移项;从而使得注意力值对位置信息更加敏感。这个位置偏移项就是通常所说的相应位置编码;此位置编码可以通过训练来学习。模型中,对所有的q、k、v都使用了相对位置编码。对于任何给定的输入特征图x,加入了位置编码并沿宽度轴更新的轴向注意力机制可以用如下公式表示:
(6)
其中,输入向量为(h*w*c),位置为o={i,j|i∈{1,2,…,h},j∈{1,2,…,w}},其输出为yij。rq、rk、rv是可学习向量,分别表示查询、键、值的位置编码。高度轴的注意力机制和宽度轴定义相同,一个轴向自注意力层在特定轴传播信息,两个轴向自注意力层都采用了多头注意力机制。与传统的自注意力机制相比,在轴向注意力机制添加位置偏移项后,可以实现全局感受野获得特征。
不同尺度图像经过每一个Swin Transformer with Multi-Head Axial-Self-Attention的网络块后使用一个全局平均池化(GAP)层来替代CNN中常用的全连接层,GAP层可以增强Feature Map和Categories之间的对应关系,从而能避免过度拟合[13]。然后,将各GAP层的输出沿指定的维度组合,以获得更好的特征表示。最后,对输出进行全连接层和Relu操作,经过Softmax后得到分类的结果[14]。
3 实验结果和分析
3.1 数据集
使用的数据集是来自飞桨公共数据集中的多种肺炎胸片数据集。此数据集包括10 192个健康以及3 616个COVID-19阳性病例、6 012个肺部浑浊(非COVID肺部感染)和1 345个病毒性肺炎图像。实验从中随机选取80%作为训练集,剩余20%作为测试集。
3.2 评价指标
实验使用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Measure等几个技术指标[15]。其中TP、FP、TN、FN分别为真阳性、假阳性、真阴性、假阴性的数量。Accuracy是指模型正确分类的样本数与样本总数之比;Precision评价模型预测正面标签的精度,Recall衡量的是正确预测正面标签的比例,Recall高意味着漏诊率低;F1-Measure是Precision和Recall的调和平均值,当F1值较高时,说明实验方法更加优异。此外,采用ROC曲线来检验分类性能,实验模型的ROC曲线如图14—18所示。ROC曲线图是反映敏感性与特异性之间关系的曲线。曲线下部分的面积被称为AUC(Area Under Curve),用来表示预测准确性。AUC值越高,曲线下方面积越大,说明预测准确率越高。指标定义如表1所示。
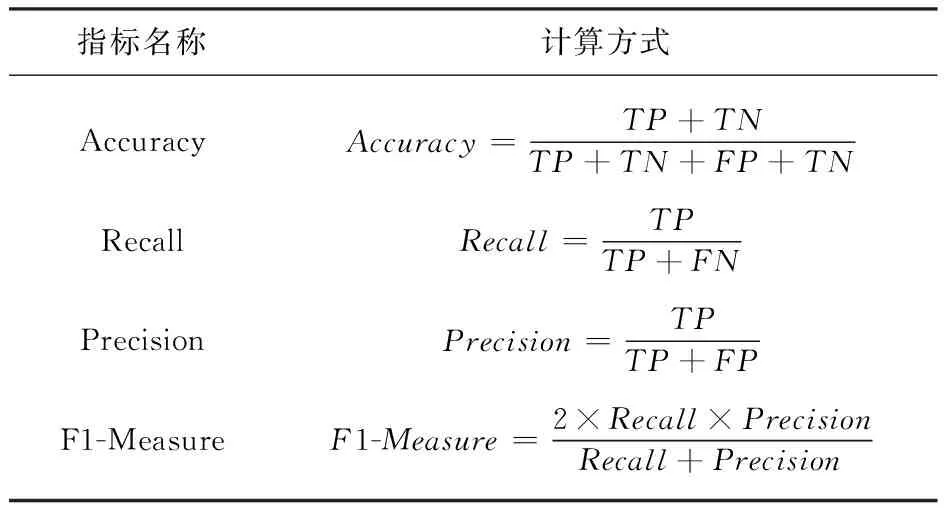
表1 评价指标
3.3 实施细节
实验基于Windows 10系统下,GPU为NVIDIA Tesla K80,实验环境为基于Windows的Pytorch深度学习框架。通过transform.Resize将图像缩放为128×128、256×256、512×512三种尺寸大小作为输入;采用Adam优化器进行模型训练,其中初始学习率、批处理大小分别设置为0.001和8;L=8为Transformer编码器数量;Epoch为300次。
3.4 实验结果
实验设计采用上述评价指标对ResNet50、ResNet101、Inception net-V3和Swin Transformer四种比较有代表性的模型做对比实验,图4至图8显示了五种网络模型下的准确率值。

图4 ResNet50网络模型下的准确率图

图5 Swin Transformer网络模型下的准确率图
图6 Inception net-V3网络模型下的准确率图
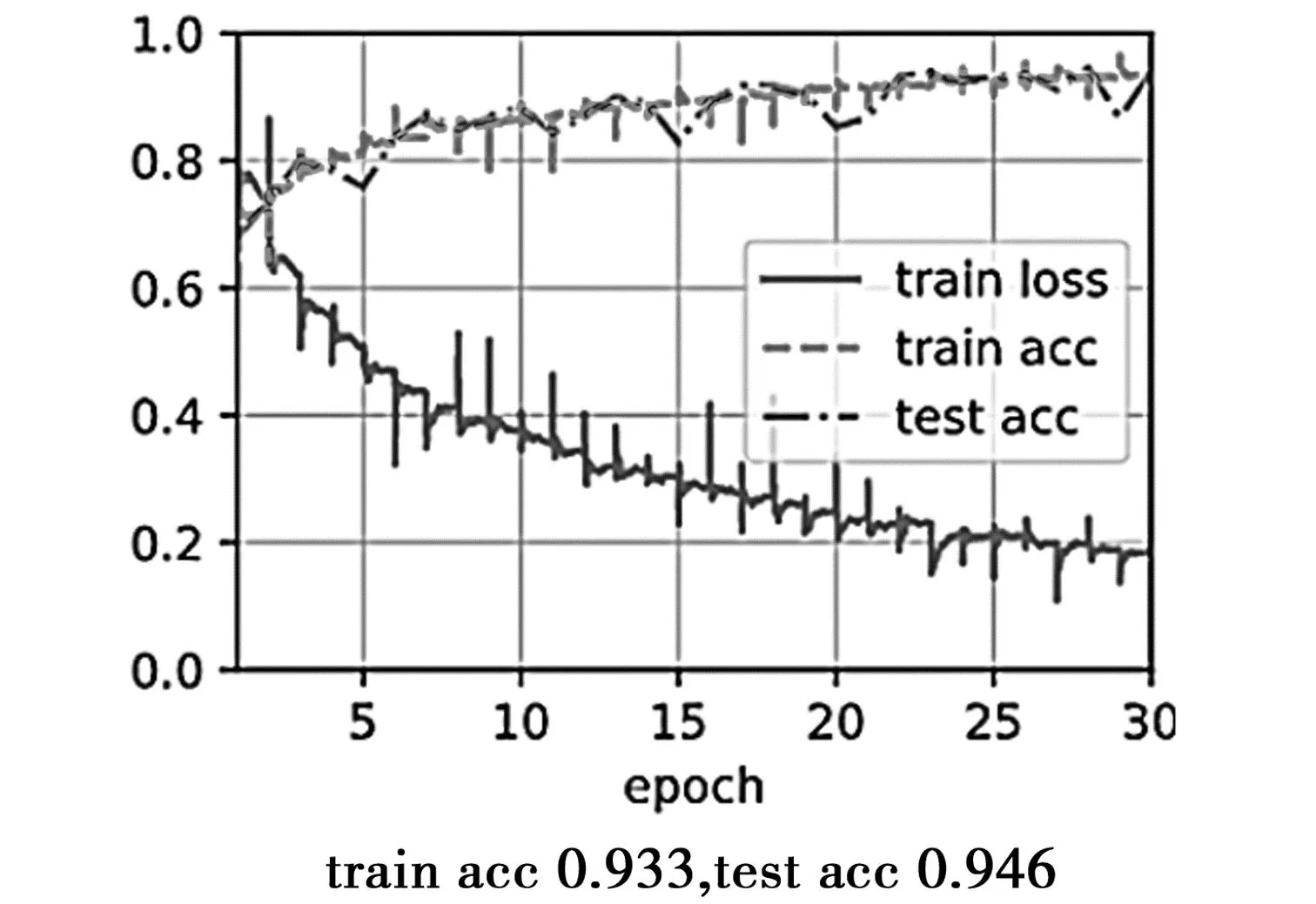
图7 ResNet101网络模型下的准确率图
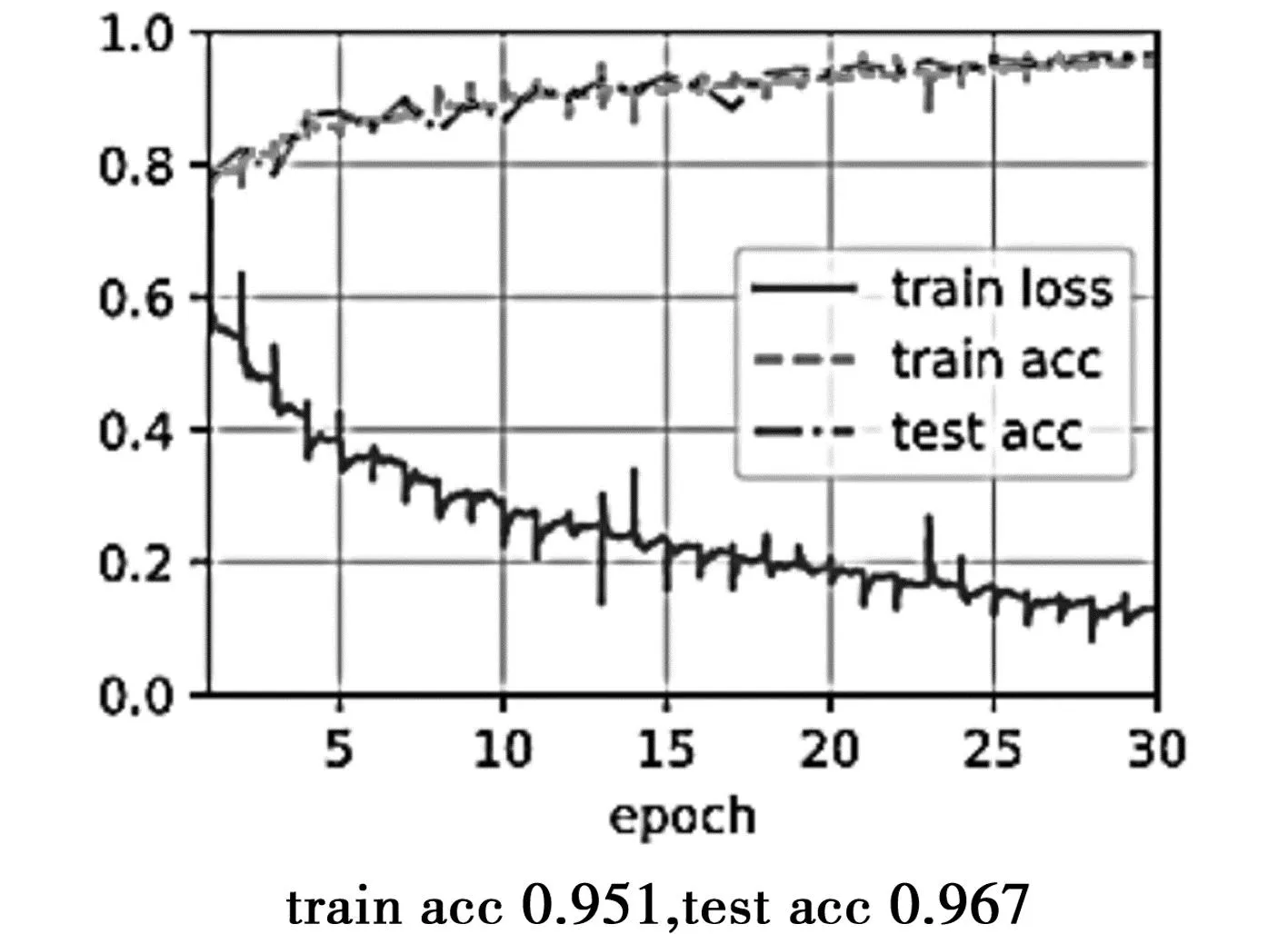
图8 proposed网络模型下的准确率图
为了更方便表示实验结果,特设置每一个e-poch代表迭代10次,共迭代300次。不同模型对应的混淆矩阵见图9至图13,从混淆矩阵中可以计算出每个模型的精确度、召回率及F1-Measure。
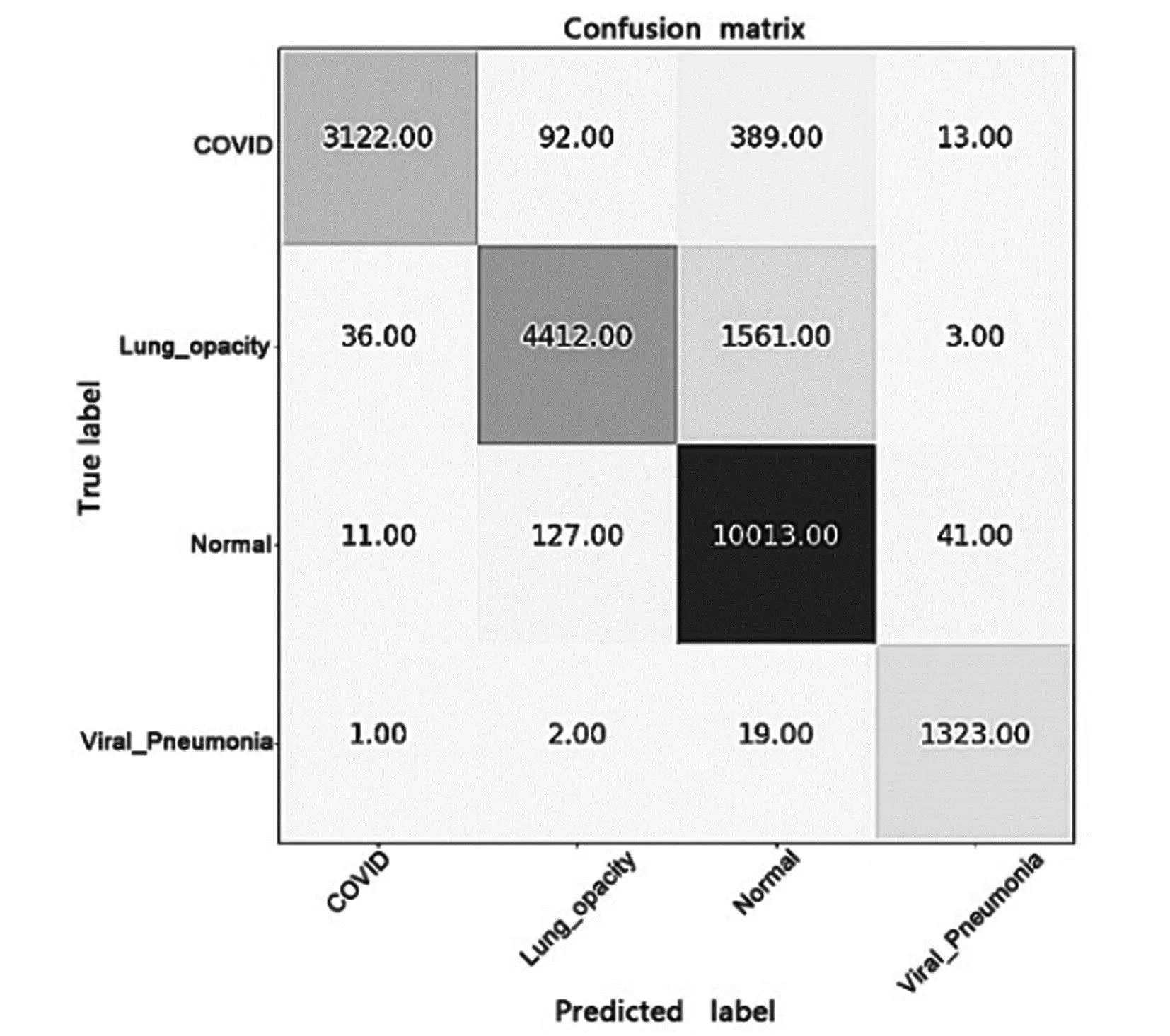
图9 ResNet50网络模型下的混淆矩阵

图10 Swin Transformer网络模型下的混淆矩阵

图11 Inception net-V3网络模型下的混淆矩阵
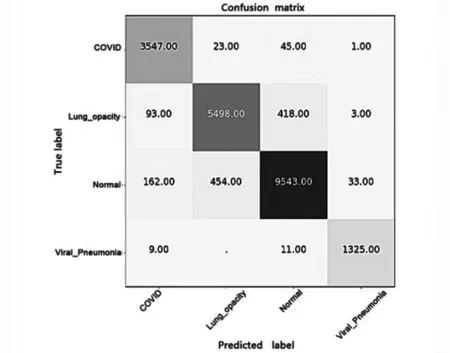
图12 ResNet101网络模型下的混淆矩阵

图13 proposed网络模型下的混淆矩阵
不同模型对应的ROC曲线如图14至图18。由图可知,所提模型的曲线下面积最大,因此说明所提模型的性能最好。
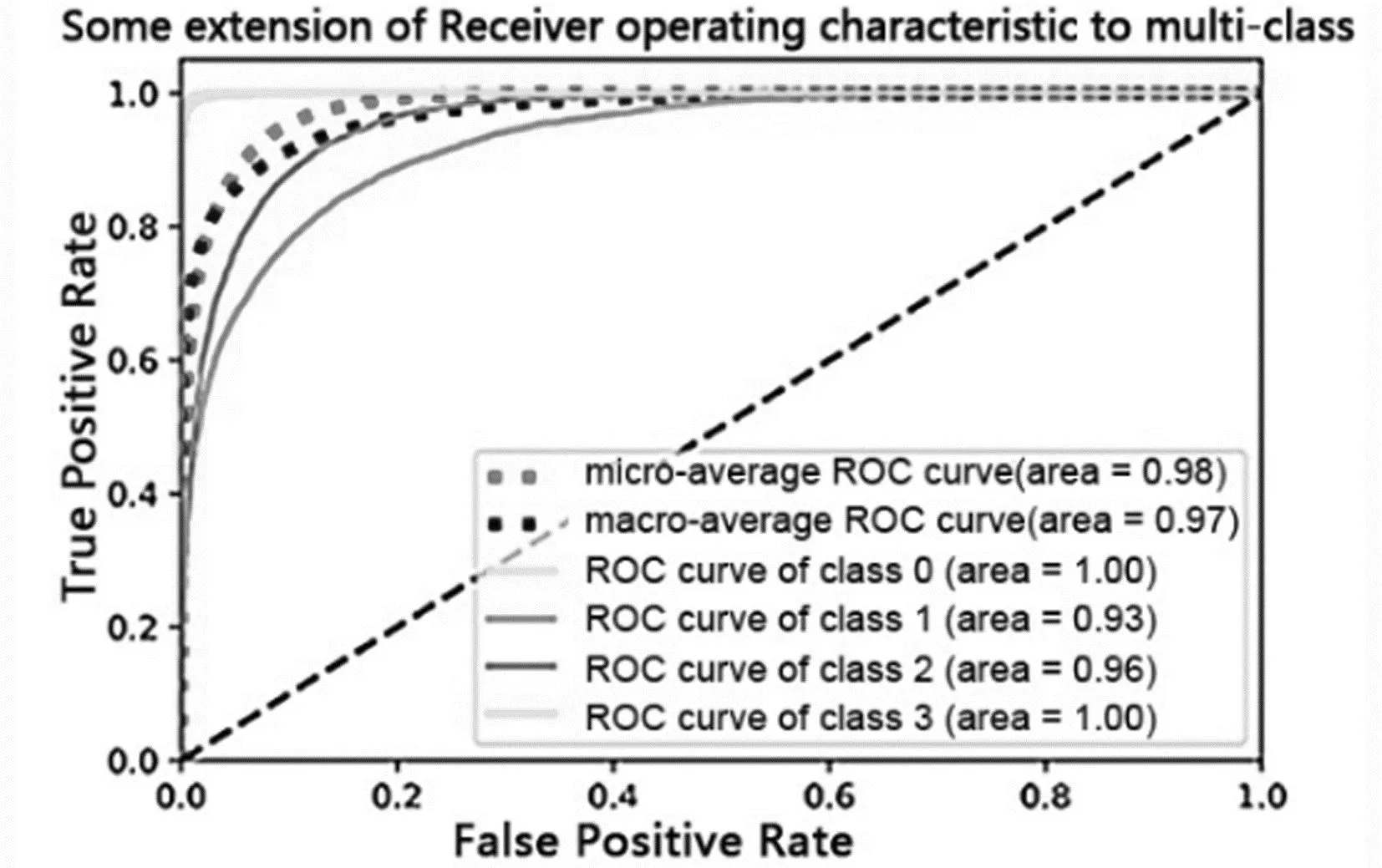
图14 ResNet50网络模型下的ROC曲线图

图15 Swin Transformer网络模型下的ROC曲线图
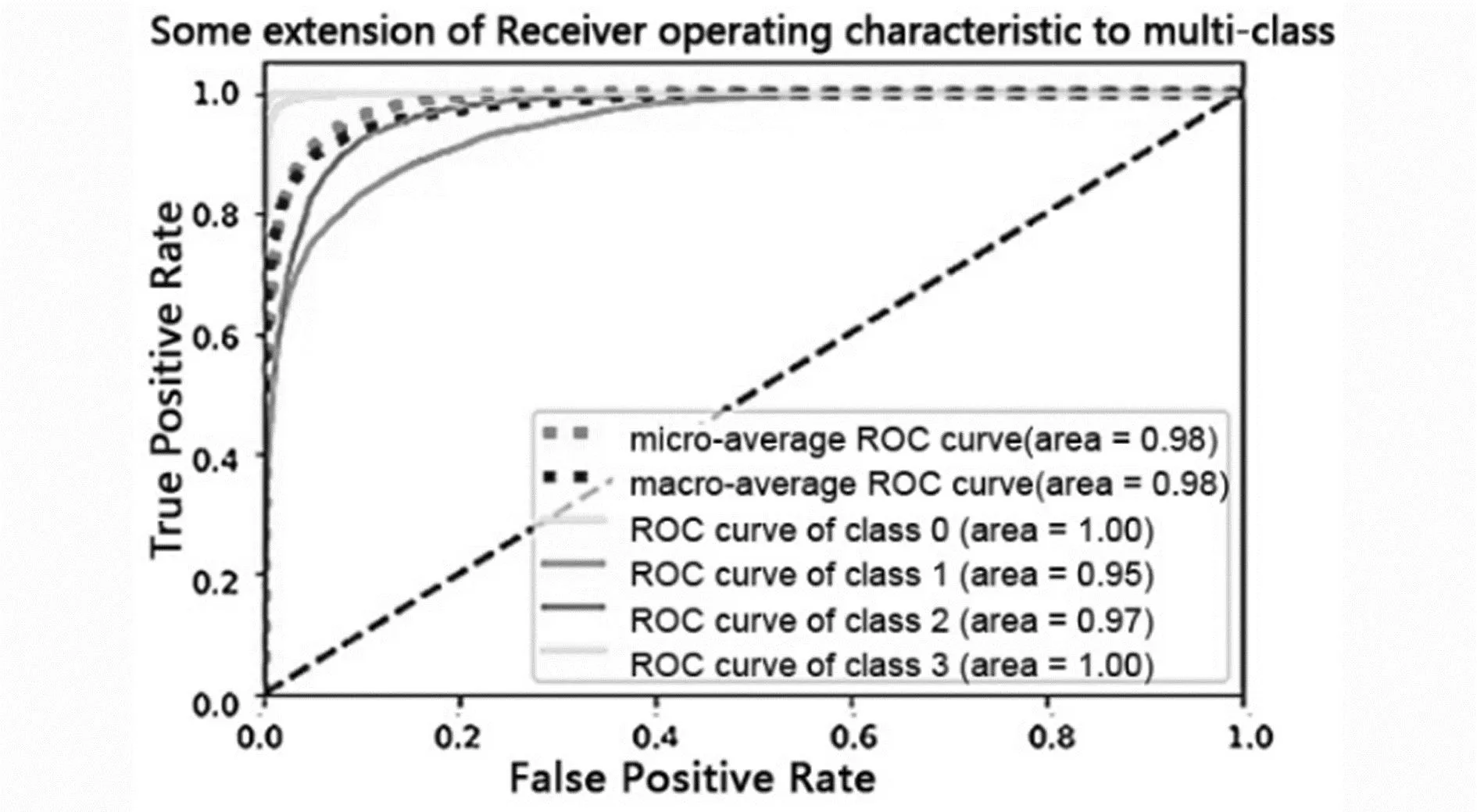
图16 Inception net-V3网络模型下的ROC曲线图

图17 ResNet101网络模型下的ROC曲线图
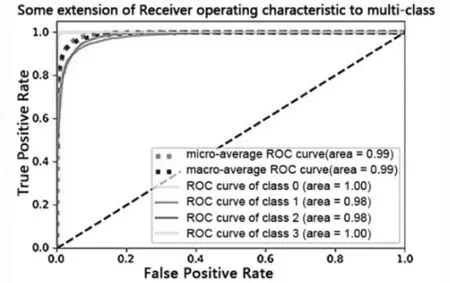
图18 proposed网络模型下的ROC曲线图
各评价指标的具体参数如表2 所示。从表2中可以看出,和四种经典的网络模型相比,所提出的模型的准确度最高,达到96.7%。其准确度、精确度、召回率及F1-Measure值比ResNet50分别高出5.1%、4.2%、8.5%和7.0%;比Swin-Transformer分别高2.4%、3.7%、2.8%和3.7%;比Inception net-V3分别高1.7%、1.5%、1.8%和2.0%;比ResNet101分别高2.1%、3.2%、1.8%和2.5%。可以看到,所提出的网络结构在这个评价指标上都取得了最好的性能。

表2 五种网络模型下的评价指标参数值
所提模型的部分预测结果如图19所示,其中上方为实际标签值,下方为预测结果。
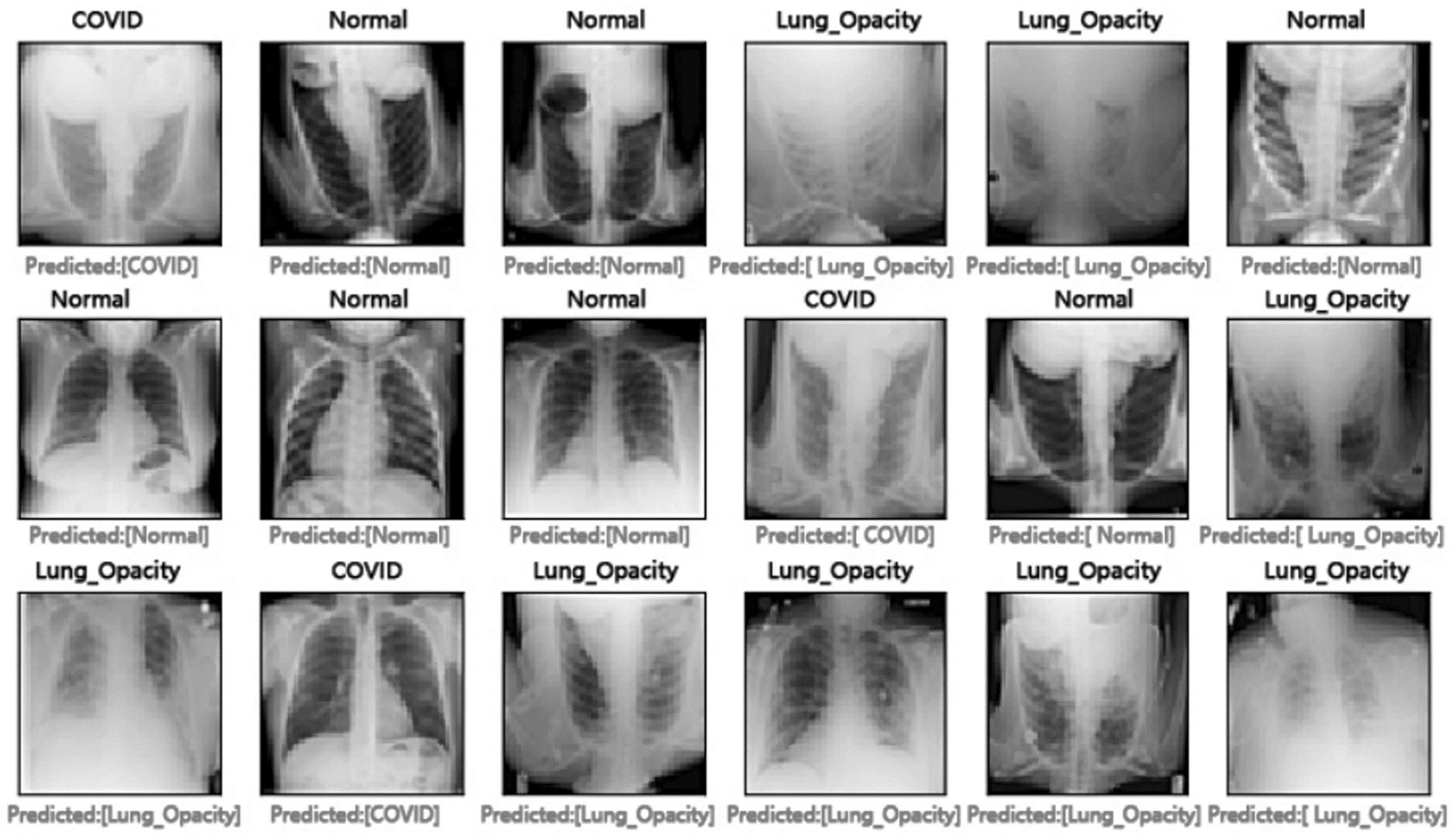
图19 部分预测结果图
4 结 论
提出了一种融合SPD模块进行多尺度输入的ST-MASA的肺炎智能检测模型,用于COVID-19、Lung_Opacity、Viral_Pneumonia和Normal的多类型肺炎的自动分类。该模型能够自动关注肺炎病灶的多尺度所表现出的关键特征,并利用轴向多头注意力机制,同时添加位置偏移项;从而能够充分实现全局感受野获得特征,得到特征图的空间信息。通过上面所提的定量实验及对比,其结果表明,该模型在训练集和测试集上均表现出更好的识别能力和泛化能力。相对于传统的CNN神经网络,提出的模型在辅助肺炎诊断的工作中表现出更优的性能;从而能更好地帮助放射科医生进行医疗检测工作。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
水泵技术(2021年5期)2021-12-31
小天使·一年级语数英综合(2021年8期)2021-08-17
小哥白尼(野生动物)(2019年9期)2019-12-21
快乐语文(2019年9期)2019-06-22
制造技术与机床(2018年12期)2018-12-23
传媒评论(2017年3期)2017-06-13
妈妈宝宝(2017年2期)2017-02-21
第二课堂(课外活动版)(2016年2期)2016-10-21
制造技术与机床(2015年10期)2015-04-09
