
中文命名实体识别研究综述
2024-01-20 08:14:00赵继贵钱育蓉侯树祥陈嘉颖
计算机工程与应用 2024年1期
赵继贵,钱育蓉,王 魁,侯树祥,陈嘉颖
1.新疆大学 软件学院,乌鲁木齐 830000
2.新疆大学 新疆维吾尔自治区信号检测与处理重点实验室,乌鲁木齐 830046
3.新疆大学 软件工程重点实验室,乌鲁木齐 830000
4.中国科学院大学 经济与管理学院,北京 101408
5.新疆大学 信息科学与工程学院,乌鲁木齐 830000
命名实体识别(named entity recognition,NER)是自然语言处理中的一项重要任务,这项任务最初是在1987年的信息理解会议[1](Message Understanding Conference,MUC)上作为实体关系分类的子任务被提出的。NER 的主要目标是确定实体的边界和类型。它从自然语言文本中识别出具有特定意义的实体,并能够准确识别它们的类型,这些实体的类型主要包括人名、组织名、地名等,如图1 所示是NER 实例。NER 主要从非结构化文本中提取有价值的信息,这些信息可应用于许多NLP 下游任务中,如信息检索[2]、知识图谱[3]、问答系统[4]、舆情分析[5]、生物医学[6-7]、推荐系统[8]等任务。

图1 NER实例Fig.1 NER identification example
大多数命名实体识别都是在英文基础上进行研究[9],英文的命名实体具有比较明显的形式标志,对实体边界的识别比较容易[10],在英文中,单词之间存在分隔符来识别边界,每个单词都有完整的含义。与英文相比,中文命名实体识别任务较为困难[11]。中文命名实体识别的难点在于:
(1)词边界模糊。中文没有像英文等语言一样使用空格或其他分隔符来表示词边界,这种特点导致中文命名实体识别面临着边界歧义和识别困难的问题。例如,“计算机科学与技术系”中“计算机科学与技术”是一个复合词,边界不明确。
(2)语义多样化。中文存在大量多义词,一个词汇可能会被用于不同的上下文中表示不同的含义,因此,命名实体识别模型需要具备更强的上下文理解能力才能正确地将其分类。
(3)形态特征模糊。在英语中,一些指定类型的实体的第一个字母通常是大写的,例如指定人员或地点的名称。这种信息是识别一些命名实体的位置和边界的明确特征。在中文命名实体识别中缺乏汉语形态的显式特征,增加了识别的难度。
(4)中文语料库内容较少。命名实体识别需要大量的标注数据来训练模型,但中文标注数据数量及质量有限,导致命名实体识别模型的训练更为困难。
针对以上问题,本研究按照中文命名实体识别研究的发展历程从基于规则的方法、基于统计模型的方法和基于深度学习的方法三方面进行总结。
1 数据集及评价指标
本章主要介绍CNER 数据集,包括公共数据集、竞赛数据集、私有数据集;其次详细介绍NER 的标注方案,最后介绍NER的评估指标。
1.1 CNER数据集
数据集提供标准的实体标注信息,用于评估不同算法和模型在中文命名实体识别任务上的性能表现,从而比较不同算法和模型的优劣。数据集中包含大量的中文文本和相应的实体标注信息,可以作为算法和模型的训练、测试和验证数据。高质量的数据集往往能够提高模型训练的质量和预测的准确率。通过使用数据集进行训练,使得算法和模型具备识别中文命名实体的能力。目前根据数据集的来源和可用性,一般可以将数据集分为公共数据集,竞赛数据集以及私有数据集[12]。
常用的中文公共数据集如表1所示,在各类数据集中包括社交媒体(Weibo)、电子简历(RESUME)、新闻(人民日报)等不同来源的语料库。MSRA 数据集由中国微软亚洲研究院发布,包含了多种不同的任务,包括中文分词、命名实体识别、词性标注等。该数据集的标注质量较高,是研究和评估中文自然语言处理技术的重要资源。Weibo 数据集是一个包含微博文本的大规模中文社交媒体数据集,由中国新浪公司提供,Weibo 数据集规模较大,具有很高的噪声和语言变异性,其标注质量较差。MSRA 和Weibo 数据集是中文命名实体识别中最广泛使用的语料库。Resume数据集由上市公司高管简历处理而成的,具有多样性、大规模和结构化的特点。OntoNotes 数据集包含新闻、广播、对话、文学作品等多种文本类型,包括大量的文本样本和标注数据,具有较大的规模的信息量。如表2 所示是四个通用数据集的数量统计,标注数量有限,为此CLUE 组织基于清华大学开源文本分类数据集THUCTC,选取部分数据进行NER,发布了CLUENER2020 数据集[13],它包含新闻、论坛、微博等领域的中文文本,并标注了人名、地名、组织机构名等10 种不同的实体类型,并已完成多项基线模型评估,有望成为未来通用的CNER数据集。
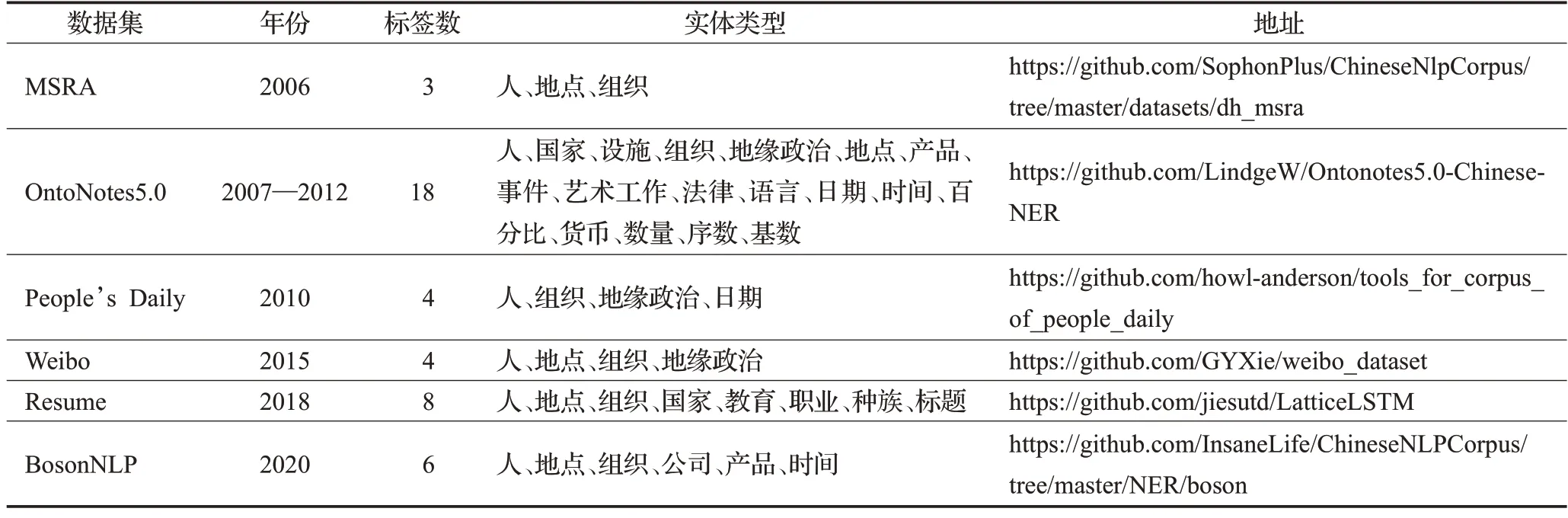
表1 中文命名实体识别数据集Table 1 Chinese named entity recognition datasets
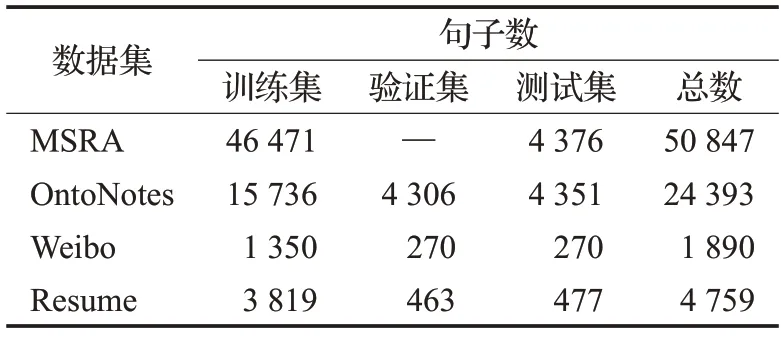
表2 常用公开数据集统计Table 2 Common public dataset statistics
竞赛数据集的特点通常是数据多,且标注精细。包括SIGHAN Bakeoff 2006 数据集、DuEE 2021 数据集等。其中,SIGHAN Bakeoff 2006数据集由中文信息处理国际会议(SIGHAN)组织的中文分词和命名实体识别竞赛而来,包含新闻、文学、网络等领域的中文文本。DuEE 2021 数据集由百度公司组织的中文事件抽取竞赛而来,包含新闻、微博等不同领域的中文文本,并标注了实体、事件、关系等信息。
1.2 标记方案
在命名实体识别中,通常使用序列标注的方法对输入的内容进行标注,序列标注的方法一般分为两类:原始标注和联合标注。中文命名实体识别任务中最常见的四个实体标签是:PER(人物),LOC(地点),ORG(组织),GPE(地缘政治实体)。实体标注的标签类型如表3所示。

表3 实体标注类型Table 3 Entity annotation types
三种常见的实体识别序列标注方法主要是BIO标注、BMES标注以及BIOSE标注方案。除以上三种常见的标注外,还有其他多种实体标注方式如IOB 标注方案。Reimers等人[14]比较了IOB、BIO、BIOES标记方案,提出标签方案会影响NER性能,并通过实验表明BIO和BIOES标注方案在NER任务中的性能要优于IOB标注方案。
1.3 评价指标
评估NER的性能主要有精确匹配和宽松匹配两种方式[15]。精确匹配指的是模型输出的实体与标注数据完全匹配,包括实体类型和边界位置都与标注数据完全一致。宽松匹配指的是模型输出的实体与标注数据部分匹配,但是存在误判或误漏的情况。相比之下,使用精确匹配的评估方式更合理。通常使用精确度(Precision)、召回率(Recall)和F1分数(F1-score)来进行评估。
Precision 指模型正确预测出的命名实体数量与所有预测出的实体数量的比例,Recall指模型能够正确识别的命名实体数量与文本中所有命名实体数量的比例,F-score 是准确率和召回率的调和平均值,平衡的F-score是最常用的评估指标。Precision、Recall、F1-score的具体表达式如下:
2 传统的中文命名实体识别方法
传统的中文命名实体识别的方法主要有两类:基于规则的方法、基于统计模型的方法。基于规则的方法主要依赖于专家设计的规则和模板来识别命名实体,通常需要考虑词性、语法、上下文信息等多个方面的特征,借助这些特征来解决词边界划分模糊以及语义多样化问题。基于统计的方法则是通过机器学习算法,从大量的语料库中学习输入的中文的特征和规律,使用基于特征工程的方法提取输入文本的形态特征以达到命名实体识别的目的。
2.1 基于规则的方法
基于规则的方法具有简单易用、可解释性强、适用范围广的优点。基于规则的方法根据一些匹配规则从文本中选择匹配的实体,这些规则主要基于正则表达式或字典。正则表达式由这些特定字符的预定义特定字符和组合形成,以表达字符串或文本的过滤逻辑。字典由实体集合建立,一般采用的方法是从已有的知识库、词典、语料库等数据源中构建,根据标注好的样本文本,设计一些匹配规则,匹配规则可以基于词语、词性、上下文信息等。
Hanisch等人[16]为解决所考虑的生物体中大量的歧义同义词,遵循基于规则的方法提出ProMiner 系统,该系统主要利用预处理的同义词词典识别生物医学文本中的蛋白质提及和潜在基因。Akkasi 等人[17]利用从训练数据集中提取的规则提出ChemTok 分词器,实验结果表明,在ChemTok输出上训练的分类器在分类性能和错误分割实体的数量方面优于其他的分类器。Quimbaya等人[18]通过提出基于字典的方法对电子健康记录进行命名实体识别,对可能组合进行评估,结果显示,在命名实体的识别过程中,召回率提高明显,对精确度的影响有限。
为减轻人工工作量,研究人员通过机器学习来制定和生成规则,如Collins 等人[19]提出的深度学习方法CoTrain,通过根据语料库对规则集应用无监督训练迭代来获得更多的规则。王宁等人[20]在金融领域利用规则的方法对公司名进行识别,根据金融新闻文本的深入分析总结出公司名的结构特征及上下文信息,在封闭的测试环境和开放的测试环境中准确率分别为97.13%和62.18%。基于规则的方法根据特定的领域来制定规则,在特定的语料库中能够取得较高的精度,但是存在规则制定成本高、规则泛化性能弱等局限性。
2.2 基于统计模型的方法
基于统计模型的方法通过构建概率模型来预测文本中每个词的实体标记,将命名实体识别问题向序列标注问题转换。经典的基于统计的机器学习模型已成功用于NER 任务中,这些模型通常使用基于特征工程的方法来提取特征,然后通过训练学习到的模型来预测命名实体。常用的机器学习方法包括:隐马尔可夫模型[21](hidden Markov model,HMM)、条件随机场模型[22](conditional random field,CRF)、最大熵模型[23](maximum entropy model,MEM)、支持向量机[24](support vector machine,SVM)等。
张华平等人[25]提出基于角色标注的中国人名自动识别的方法,采取HMM 方法对分词结果进行角色标注,通过对最佳角色序列的最大匹配来识别和分类命名实体,在人民日报数据集上取得了95.20%的准确率。张玥杰等人[26]提出一种融合多特征的MEM中文命名实体识别的模型,该模型将规则和机器学习的方法相结合,能融合局部与全局多种特征,在SIGHAN2008 NER语料库中F1值达到了86.31%。陈霄等人[27]针对中文组织机构名的识别任务为解决训练数据不足的问题,提出一种基于SVM 的分布递增式学习的方法,利用主动学习的策略对训练样本进行选择,逐步增加分类器训练样本的规模,提高了学习器的识别精度,实验表明采用主动学习策略的SVM 算法是有效的,在人民日报数据集上准确率为81.7%。Hu 等人[28]使用CRF 作为中文NER模型,比较基于字符级和单词级的两个不同层次模型的效果,利用不同的训练尺度和特征集来研究模型与训练语料库的关系及其利用不同特征的能力。表4 比较了常用的机器学习方法的优缺点。

表4 常用基于统计的机器学习方法总结Table 4 Summary of common statistical-based machine learning methods
传统的中文名命名实体识别方法包括基于规则的方法和基于统计模型的方法,相比之下基于规则的方法适用于对特定领域的实体识别任务,而基于统计模型的方法适用于处理复杂的实体识别的任务,尤其是在处理大规模数据时具有优势,能更好地挖掘数据之间的关系,提高预测的准确率。表5 总结了主流的传统的CNER模型,统一使用F1值作为评价指标。

表5 传统的CNER模型总结Table 5 Summary of traditional CNER models
3 基于深度学习的中文命名实体识别方法
深度学习方法在图像识别[34]、语音识别[35]和自然语言处理[36]领域中广泛应用。基于深度学习的方法在中文命名实体识别研究中具有准确性高、鲁棒性强、可解释性强以及处理效率高等优点,深度学习的方法通过大量的训练提取上下文信息之间的语义联系,可以解决语义多样化问题,结合分词工具、长短期神经网络等方法能够解决词边界划分问题,对提高自然语言处理的水平和应用场景的广泛性具有重要的作用[37]。
本文从基于深度学习的CNER 框架模型的角度进行研究[15],从嵌入层、编码层、标签解码层三个层面进行分析。嵌入层主要将输入的文本转换为向量的形式表示,将每个单词或字符映射到一个固定维度的实数向量上,使得神经网络能够更好地处理文本数据,在嵌入层中包括基于字符、基于词、基于字符和词的混合嵌入。编码层将嵌入层中的向量进行编码,转换为一组高层次的特征表示,利用神经网络进行深度学习,提取特征。标签解码层将上下文相关的表示作为输入并生成与输入序列相对应的标签序列。如图2所示,是基于深度学习的CNER的模型基本架构。
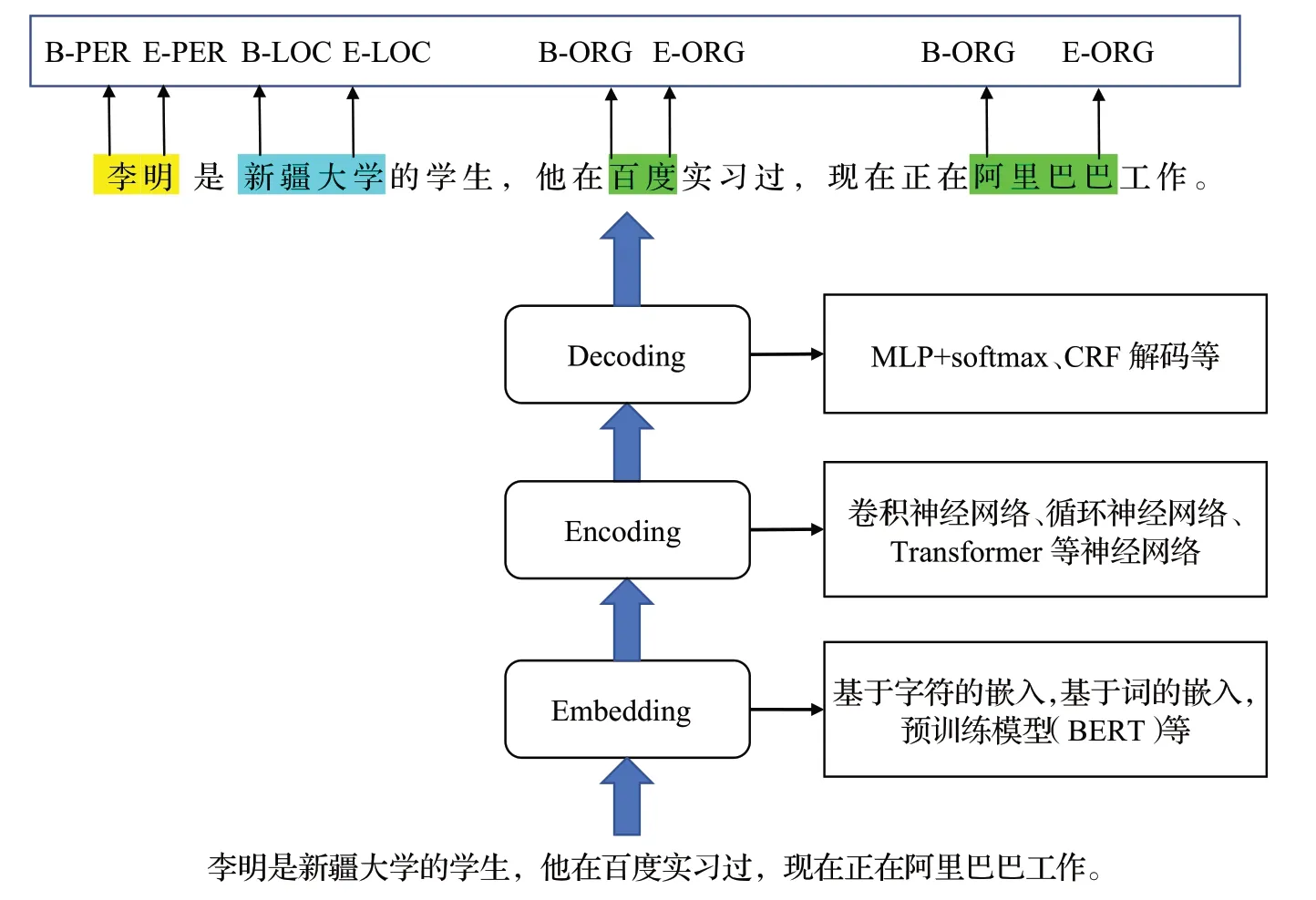
图2 基于深度学习的CNER模型架构Fig.2 Deep learning based CNER model architecture
3.1 嵌入层
传统的嵌入方式使用One-Hot编码[38]的方式对输入文本进行向量化,使用One-Hot 编码后,每个特征都被表示为一个向量。但这些向量之间没有明显的语义联系。由于中文是一种高度歧义的语言,单词或短语在不同上下文中可能会有不同的含义。因此,不能直接使用这些向量来推断特征之间的语义联系,但是分布式表示[39]是自动从文本中学习的,它可以自动捕获标记的语义和语法属性,能够从上下文中获取更多的信息,提高对实体的识别准确性。按照分布式表示将嵌入层分为基于字符的模型、基于词的模型和混合模型。
3.1.1 基于字符的模型
基于字符的模型将单词表示为字符序列的方法,它通过输入文本的字符级别表示,不需要明确的词边界信息,可以更好地处理CNER中的边界模糊问题。基于字符的模型具有可以处理未知的新词汇、对于拼音或汉字形式相似的实体具有一定的鲁棒性的优点。
为解决相邻字符之间强联系的问题,Zhang 等人[40]提出一种新的动态嵌入方法,该方法使用注意力机制来组合嵌入层中的字符和单词向量特征。基于单个字符特征的序列标注方法被广泛应用于中文命名实体识别任务,改善单个字符的表示方法,可提高实体识别的性能。为此,罗辉等人[41]提出了一种面向实体识别任务的中文字符表示方法,将这种字符表示输入到BiLSTMCRF实体识别模型中进行实体识别,证明了所提出的字符表示方法有效性。基于字符的模型存在不能携带语义信息、难以处理歧义词的缺点[42]。
3.1.2 基于词的模型
基于词的模型是将中文数据集的文本以词语的形式作为输入,借助分词系统[43]对数据集进行分词。基于词的模型可以捕捉到词与词之间的语义关系,在处理一些长词汇的实体时具有良好的效果。基于词的模型存在分词错误和在处理不规则的词以及新词时比较困难的缺点。
为解决不能利用长距离语境信息的问题,Chen 等人[44]提出一种用于词分割的+新型神经网络模型,该模型采用长短期记忆神经网络,将之前的重要信息保存在记忆单元中,避免了局部上下文窗口大小的限制。Ma等人[45]使用双向LSTM、CNN 和CRF 的组合,提出一种中性网络结构,自动从单词和字符级别的表示中获益,实现了端到端的NER,不需要特征工程或数据预处理,能适用于广泛的序列标签任务。在中文电子病历命名实体识别任务中,张华丽等人[46]为了消除传统命名实体识别方法高度依赖人工提取特征不足,结合词嵌入技术将电子病历文本序列进行词向量化表示,设计了双向长短时记忆(Bi-LSTM)网络与条件随机场(CRF)结合的网络模型,并在联合网络的基础上添加注意力机制,从而优化实体识别准确率。
3.1.3 混合模型
混合模型是将基于字符的模型和基于词的模型结合起来,由于基于字符的模型存在字与字之间语义提取缺失问题,基于词的模型存在分词错误的问题,同时将字符和词作为嵌入表示可以使模型具有较好的鲁棒性和识别精度。Zhang 等人[47]提出Lattice LSTM 模型,首次将词典信息融入到基于字符的模型中,与基于字符的方法相比,该模型明确地利用单词和单词序列信息。与基于词的方法相比,该模型不会受到分割错误的影响。Liu 等人[48]提出WC-LSTM 模型,该方法将词信息添加到词的起始或结束字符中,在获取词边界信息的同时减轻分词错误的影响,并且探索出四种不同的策略,将单词信息编码为固定大小的表示形式,以实现高效的批量训练。
随着预训练模型[49]的蓬勃发展,被应用于许多研究领域。预训练的语言模型在NLP 研究中可以捕获有利于下游任务的丰富知识,例如长期依赖关系、层次关系等。NLP 中预训练的主要优点是预训练过程中有无限数量的训练数据,需要标注的数据量大大降低,降低训练成本[50]。其中基于Transformer 的双向编码(bidirectional encoder representations from Transformer,BERT)模型[51]是中文命名实体识别中最常用的预训练模型,BERT 模型可以考虑整个输入句子的上下文信息,有助于提高模型对命名实体的理解和识别准确性。对于给定的字符,BERT将其字符位置嵌入、句子位置嵌入和字符嵌入作为输入连接起来,然后使用掩码语言模型[52]对输入句子进行深度双向表示预训练,以获得强大的上下文字符嵌入。
Jia 等人[53]是第一个研究如何利用输入文档文本的规模来增强NER 的人,使用CharEntity-Transformer 将实体信息集成到BERT中,该模型使用字符和实体表示的组合来增强自注意力。Chang 等人[54]提出一种基于BERT 的命名实体识别方法,构建一个BERT-BiLSTMIDCNN-CRF模型,使用BERT进行预训练,将训练好的词向量输入双向长短期记忆网络和迭代扩张卷积网络进行特征提取。然后结合两个神经网络的输出特征,最后通过条件随机场对预测结果进行修正,实验结果表明了预训练模型Bert 在处理文本嵌入起着重要作用。杨飘等人[55]利用BERT 预训练生成词向量,提出了基于BERT的BERT-BIGRU-CRF模型,在MSRA中文数据集上进行测试获得了不错的结果,F1值达到了95.43%。
表6 是嵌入层的分布式输入模型的优缺点以及一些代表模型的总结。

表6 嵌入层输入分布式模型总结Table 6 Summary of embedded layer input distributed models
3.2 编码层
编码层主要是将嵌入层输入的文本转换成一个高维的特征向量,方便后续的分类器对文本进行分类。中文命名实体识别的目标是学习一个好的特征表示,使得模型能够对中文文本进行命名实体识别。在中文命名实体识别的编码层中通常是采用卷积神经网络、循环神经网络、递归神经网络和Transformer 等其他类型的网络来提取特征,建立上下文关系。
3.2.1 卷积神经网络
卷积神经网络[60](convolutional neural network,CNN)是一种常用的深度学习模型,CNN最初是为计算机视觉研究开发的,但它已被证明可以有效地捕获具有卷积运算的n-gram(单词或字符嵌入)的信息语义特征[61]。CNN 通过卷积操作从局部特征中提取更高级别的特征,能够有效地处理文本中的依赖关系。
Goodfellow等人[62]提出一个具有多个Softmax分类器的CNN 模型,其中每个分类器负责多位数输入图像中每个顺序位置的字符预测。Jaderberg 等人[63]引入一种新的基于条件随机场(CRF)的CNN 模型,共同学习用于场景文本识别的字符序列预测和二元生成。为充分利用GPU并行性,Gui等人[64]提出基于卷积神经网络(CNN)的方法,该方法使用重新思考机制结合词典对并行匹配的句子进行建模,实验结果表明,该方法的识别效率更快。史占堂等人[65]为解决命名实体识别任务时存在一字多词、增加额外存储与词典匹配时间等问题,提出一种CNN-Head Transformer编码器(CHTE)模型,利用不同窗口大小的CNN获取Transformer中6个注意力头的Value 向量,使CHTE 模型在保留全局语义信息的同时增强局部特征和潜在词信息表示,提升了Transformer在命名实体识别领域的性能表现。
3.2.2 循环神经网络
循环神经网络[66](recurrent neural network,RNN)是一种用于处理序列数据的神经网络,它在时间上是有状态的,可以利用前面的上下文信息来预测出当前的输出,核心思想是通过引入“循环”来处理序列数据,使网络能够记住之前的状态,并将这些状态作为输入影响后续的输出。Quyang 等人[67]提出一种用于CNER 的深度学习模型,该模型采用双向RNN-CRF架构,使用连接的n-gram字符表示来捕获丰富的上下文信息。但是RNN在处理长序列是容易出现梯度消失或爆炸的问题,导致神经网络难以学习到长期依赖的关系。为了解决这些问题,后续研究人员提出一些改进的RNN 结构。Dong等人[37]将双向LSTM-CRF神经网络用于CNER,该网络同时利用字符级和部首级表示,是第一个研究BLSTMCRF架构中的中文部首级表示,并且在没有精心设计的功能的情况下获得更好的性能,在MSRA 数据集上F1分数达到了当时最先进的性能90.95%。
3.2.3 Transformer
Transformer是一种深度神经网络模型,由谷歌团队在2017 年提出的神经网络模型[68],它只基于注意力机制,而不是采用循环和卷积,旨在解决序列到序列的自然语言问题,在中文命名实体识别中取得不错的性能,且将训练时间大幅度压缩。
Transformer的核心组成部分是自注意力机制[69],它能够在一个序列中计算每个元素与其他元素的关联性,从而为序列中的每个元素赋予权重,进而实现上下文感知。Transformer由编码器和解码器组成,其中编码器将输入序列映射到隐藏表示,解码器则将隐藏表示转化为输出序列。Yan等人[70]提出TENER模型,这是一种采用自适应Transformer Encoder 的NER 架构,用于对字符级特征和单词级特征进行建模。Li 等人[71]提出FLAT:FLAT-lattice transformer 模型,将晶格结构转换为由跨度组成的平面结构,利用Transformer 的强大功能和精心设计的位置编码,可以充分利用晶格信息,并且具有出色的并行化能力。
3.3 解码层
解码层是NER 模型最后的阶段,主要任务是将上下文表示作为输入并生成与输入序列相对应的标签序列,目前主流方法有两种:MLP+Softmax与CRF。
3.3.1 多层感知器+归一化指数函数
多层感知器[72](multilayer perceptron,MLP)是一种由多层感知机或神经元组成的神经网络。当MLP在输出层使用归一化指数函数(Softmax)[73]作为激活函数时,通常使用交叉熵[74]损失来训练它,交叉熵损失是输入的预测概率分布和真实概率分布之间的差异的度量。MLP使用线性变换和非线性激活函数的组合来计算输入文本中每个单词的每个可能的实体类的分数。Softmax激活函数被应用于MLP的最后一层的输出,从而在每个单词的可能实体类上产生概率分布。在训练期间,训练MLP 以最小化输入的预测概率分布和真实概率分布之间的交叉熵损失。目标是调整MLP神经元的权重和偏差,使每个单词的预测实体类概率与真实标签匹配。在推理过程中,MLP 用于预测输入文本中每个单词最可能的实体类。这可以通过为每个单词选择具有最高预测概率的实体类来实现。然后可以使用得到的实体标签来提取输入文本中的命名实体并对其进行分类。
3.3.2 条件随机场
条件随机场(CRF)模型[75]作为一种判别式概率模型,可以直接建模序列标注任务中标签之间的依赖关系,能够有效地解决标签之间的冲突和歧义问题。CRF模型通常会利用已经预测出的局部标签序列,通过对全局标签序列的建模,来计算全局最优的标签序列,提高序列标注的准确性和鲁棒性。
在CNER任务中,通常将经过神经网络输出的每个单词的概率分布作为CRF 的输入特征,并将CRF 输出的每个标签分配给相应的单词。CRF 通常使用基于特征的方法来建立输入和输出标签之间的条件概率分布,这些特征可以是当前单词的特征(如词性、词向量等),也可以是前后相邻单词之间的特征(如词性标注、命名实体类型等)。
基于深度学习的中文命名实体识别属于端到端的模型,模型可以通过参数自动调节,规避多模块模型中模块之间相互影响产生偏差的弊端,同时也降低了模型的复杂度。除了从基于CNER框架模型的结构嵌入层、编码层、标签解码层进行研究之外,基于深度学习的中文命名实体识别还从基于神经网络、序列标注模型、基于前馈和双向模型、基于注意力机制、引入外部知识,以及直接使用大规模预训练模型进行实体识别。常用于命名实体识别领域的深度学习神经网络有:卷积神经网络和循环神经网络以及它们的变体长短期记忆网络、双向长短期记忆网络和门控循环单元等。为了提高中文命名实体识别的精度,一些模型引入了外部知识,如词典、知识库等。这些外部知识可以帮助模型更好地理解文本中的命名实体,并更准确地识别出它们。赵浩新等人[76]直接利用中文笔画序列生成字向量,旨在模拟笔画构造汉字的规律,以此来增强汉字的特征表示,从而提升命名实体识别的效果。为将词汇信息的特征添加到基于字符嵌入的模型中,闫河等人[77]提出了一种结合词汇信息特征的中文命名实体识别方法,采用带有残差连接的门控空洞卷积网络提取序列局部特征来表示词汇信息特征,并添加句子级注意力机制来增强网络的长序列建模能力,通过稀疏注意力机制将得到的全局和局部特征进行结合,去除特征融合中的冗杂信息,输出包含词汇信息特征的文本特征,证明了结合词汇信息在中文命名实体识别的精度上提升的有效性。表7 总结近五年来基于深度学习的CNER模型,并统计在MSRA数据集和Weibo数据集上的表现,其中使用F1分数作为主要评价指标。

表7 近五年基于深度学习的CNER模型总结Table 7 Summary of CNER model based on deep learning in last five years
4 CNER的研究趋势
4.1 扩充CNER的语料库
相比于英文的命名实体识别,中文的命名实体识别的语料库是比较少的,扩充中文的语料库是CNER未来研究的趋势之一[98-99]。现有的CNER语料库在规模上仍然比较有限,需要更多的数据来训练更精准的模型,在网络上爬取大量的文本数据,并利用人工标注的方法来构建更大规模的CNER 模型库。高质量的数据集对NER模型的训练和测试是至关重要的,可以通过对现有的CNER 语料库利用人工智能技术自动纠错来改善CNER语料库的质量。对于某些特定领域的命名实体,现有的CNER 语料库可能不足以提供足够的训练数据。可以考虑利用领域专家知识来构建领域特定的CNER语料库,从而提高模型在该领域的性能。
4.2 嵌套实体抽取
NER的任务通常不考虑嵌套实体问题,但通过对于大量中文文本信息的分析和调查,发现嵌套实体出现在具体文本中的概率相当大,每个实体对应多个标签,所以嵌套实体抽取CNER 未来研究的一个热点和难点。在处理嵌套实体时,通常使用神经网络模型识别文本中的实体,并预测它们之间的嵌套关系。此外,一些基于规则的方法和基于超图的方法也被用来解决嵌套实体抽取的问题。未来在处理中文嵌套NER 时,可以考虑利用嵌套实体的内部实体和外部实体的信息,从底层文本中获取更细粒度的语义信息,实现更深入的文本理解。
4.3 多模态命名实体识别
目前信息呈现出多模态化,如何将这些多模态化的信息进行实体抽取成为一大研究热点。多模态的命名实体识别是指在多个模态的输入数据中同时识别命名实体。这些模态可以是文本、图像、语音或视频等。多模态的命名实体识别可以更全面地理解和分析多媒体数据,从而提高自然语言处理、计算机视觉和语音识别等领域的信息抽取应用效果。Arshad 等人[100]提出一个端到端模型,学习文本和图像的联合表示。实验表明,该模型能够以更高的精度捕获文本和视觉上下文,在Twitter 多模态命名实体识别数据集上表现出最先进的性能。Zhang 等人[101]为MNER 提出一种基于去偏差对比学习的方法,该方法通过跨模态对比学习增强的模态对齐,对比学习采用了硬样本挖掘策略和去偏差的对比损失来缓解数量和实体类型的偏向,分别从全局上学习对齐文本和图像的特征空间。多模态的命名实体识别在实际应用中具有广泛的应用前景,在智能语音助手[102]、智能驾驶[103]、智能医疗[104]等领域中,多模态的命名实体识别可以帮助系统更好地理解用户的意图和需求,提高系统的智能化程度。
4.4 在垂直领域的应用
随着中文命名实体识别技术的不断提升,中文命名实体识别在垂直领域有着越来越广泛的应用。在金融领域,CNER 可以用于识别金融新闻中的公司名称、股票代码等信息,帮助投资者及时获取最新的市场信息。此外,CNER还能够用于识别金融交易中的实体及其关系,帮助风险管理和监管部门对金融市场进行监管。在医疗领域,CNER 可以用于识别医学文献中的疾病、药品、治疗方法等实体,帮助医生快速获取最新的医学信息,并进行诊断和治疗。同时,CNER 还可以用于识别医疗记录中的患者信息、医生信息等实体,帮助医疗机构管理和数据分析。在法律领域,CNER可以用于识别法律文书中的人名、地名、组织机构名等实体,帮助律师和法官快速获取相关信息,进行案件分析和裁决。将成熟的中文命名实体模型应用到垂直领域能给人们的生活带来极大的便捷。
5 结束语
近年来,随着深度学习技术的快速发展,中文命名实体识别算法的精度得到了大幅的提升,并且不断有新的方法被提出。但是当前中文命名实体识别研究仍然存在着许多挑战和问题,如语料库数据较少、嵌套实体抽取困难以及多模态实体抽取等。未来的研究方向应该聚焦于解决这些问题,提高中文命名实体识别算法的准确性和效率,同时拓展其应用范围,使其能够更好地满足实际应用的需求。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
中国外汇(2019年18期)2019-11-25 01:41:54
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
