
浅谈C语言的常见陷阱
2024-01-18 09:09石也牧
科学与信息化 2024年1期
石也牧
华中师范大学人工智能教育学部 湖北 武汉 430079
引言
C语言是最重要的编程语言之一,它同时具备高级和低级语言的特点[1]。C语言的目标程序效率高,它被广泛应用于多个领域:Linux内核使用的是C语言、Python是用C语言写的、《数据结构》课程一般也使用C语言来描述,等等。C语言自身有很多陷阱,编程者一不小心就会“掉进坑里”[2]。了解C语言常见的陷阱和规避方法,可以更深刻地理解相关的知识点,使较难的学习过程变得相对轻松。
1 不同类型数值的比较
下面这段程序,是两个整数的比较,显然x比y大,预期的打印结果为x〉y:
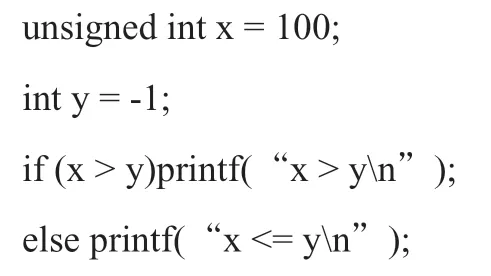
实际的运行结果为x〈=y。x是无符号整型,y是普通整型,当把它们比较时,系统先将类型转换一致,y被转换为无符号整型。增加一条打印语句printf(“%u ”,y),可知,-1转换为无符号整数之后为4294967295,所以,结果为x〈=y。
不同类型的变量,取值范围不同,要尽量避免两个不同类型数值的比较。当然,可采取类型的强制转换,但也改变不了变量的原本取值范围。
2 等号的误用
直接判断两个浮点数是否相等合乎语法,但结果会出乎意料。例如:

打印结果为:b!=0.1。系统认为b与0.1不相等,这是由浮点数的存储方式导致的,计算机在存储浮点数时是有误差的。增加一条打印语句printf(“%.18f ”, b),得到结果是0.100000001490116120,看来b确实不是0.1。判断两个浮点数是否相等,应该采用的方法是:判断它们之差的绝对值是否小于某个预设的很小的正数。就是说,计算机上的两个浮点数相等,是指在可接受的误差范围之内相等。
3 宏定义——简单的替换
在程序预处理阶段,系统进行宏替换,注意,只是简单的字符串替换。宏定义不是普通的语句,结尾不需要加分号,如果加了可能会导致错误。例如:
#define MAX 10;
int a[MAX];
MAX被替换后,数组a变为a[10;],这显然是不对的。
宏比函数简洁灵活,宏不是函数。例如,定义宏SUM,SUM与(a,b)之间有空格:
#define SUM (a,b) ((a)+(b))
引用SUM(1,2)不能得到1与2之和,因为SUM被替换为(a,b)((a)+(b)),而不是SUM(1,2)被替换为((1)+(2))。如果是函数定义,函数名后面有或者没有空格,都不影响函数的功能。
4 字符串的�
定义一个字符串时,系统自动在末尾添加�,用户察觉不到。�是字符串结束符,它是不可打印的字符,ASCII码为0。看下例:
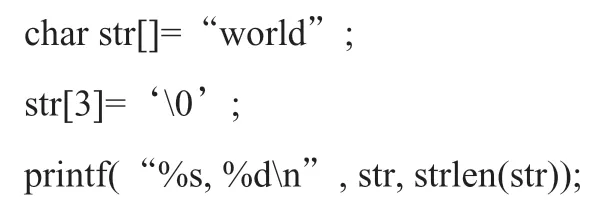
运行结果为:
wor, 3
在赋值str[3]=‘�’之后,当下标为3时就到结尾了。打印字符串时,�及之后的内容不显示,字符串的长度只计算�之前的内容。
下面定义一个字符串,然后用键盘输入它:
char str[6];
scanf(“%s”, str);
这两行看似正常的代码有越界的风险。str[6]可容纳6个字符,最后一个字符必须是�,所以输入字符串时,超过5个字符就会越界。改为如下语句就可以保证多输入的字符被忽略:
scanf(“%5s”, str);
这时,最多有5个字符被接收,然后,系统自动在后面添加�。
用宏来控制字符串长度时,注意给�留一个位置。如下的语句是正确的:
#define MAX_LEN 30
char buf[MAX_LEN + 1];
scanf(“%30s”, buf);
拷贝字符串时,要为目标字符串多分配一个字符的空间,供�占用:
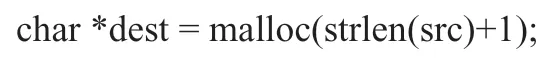
5 数值溢出
下面的程序,判断a+b是否大于1000:

运行结果为a+b〈=1000。这是因为a+b的结果向上溢出了,a+b变成了一个负数。
有一个预防两个正数相加溢出的方法,就是确保每个正数的两倍都不溢出,相加之后也不会溢出。将int类型改为long long int,扩大变量的取值范围,一定程度上可预防溢出的发生。
6 指针越界
下面定义了一个数组a,指针p指向a的首地址,指针p2指向a的起始向后移动两个元素的地址:

运行结果应该为:显示a的第一和第三个元素的值,但实际上不是。sizeof(int)的值是4,所以p2=a+8,指针p2已经指到数组a之外了,*p2将是个不确定的值。改为p2=a+2之后,可得到预期的打印结果。指针p2是整型,它的偏移步长本身就为4,无须借助sizeof(int)来移动指针。指针移动时,注意不要指到数据不可知的地方,即不要越界访问所指向的内容。
7 内存泄漏
函数realloc()是对已分配好的内存块重新进行分配,使用不当会引起内存泄漏。例如:
str = realloc(str, 32);
上面的代码中,如果内存重新分配失败,realloc()返回NULL,原本正常的指针str变为NULL,导致内存泄漏。把realloc()的结果先赋给一个临时指针,就避免了str变为NULL的可能:
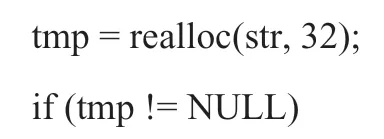
8 不要省略花括弧
当语句块只有一条语句时,花括弧不是必需的。例如:
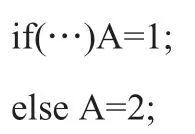
现在,需要仅在条件不成立时增加赋值语句B=3。有的程序员,会这样写,特别是在用过Python之后:
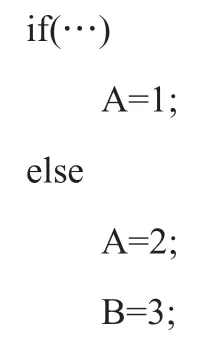
等效的代码为:
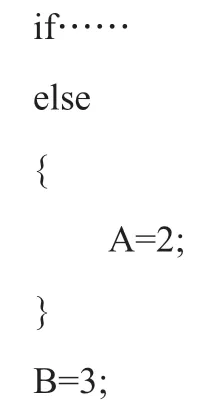
这意味着,无论条件成立与否,都会将B赋值为3,这不符合初衷。应该这样写才正确:
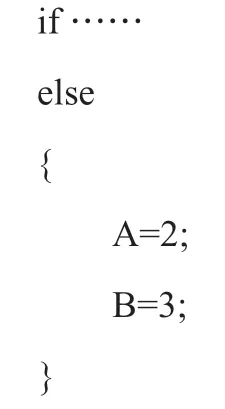
C语言不像Python那样强制缩进。C语言是用花括弧将同一个语句块的语句括在一起,即使各条语句缩进不一致,也不影响软件的功能。一个好的建议是,C语句块,哪怕只有一条,也要用花括弧括起来,这可以减小今后维护软件时出错的概率。再看一个例子,在一个void型函数的内部,有这样两行:
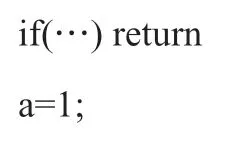
显然,return的后面少了一个分号,看起来编译会出错。但实际上,编译成功,因为它等效为:
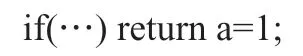
编译通过后,缺少分号的问题不再容易被发现。将if的语句块用花括弧括起来,改为:
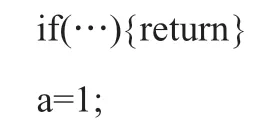
这时,会有编译错误,return后面缺少分号的问题会马上被发现。
9 函数要有返回值
定义函数时一定要有类型,或者使用void。函数一定要有与其类型一致的返回值,无类型函数,也应使用return返回。下面,定义一个结构体和一个没有指定类型函数:

这段代码没有编译错误,函数fun_a()能正常被调用。但隐藏着一个不容易被发现的问题:fun_a()的类型不是默认的int,而是结构体struct student。因为在struct student的右花括弧的后面少了一个分号,导致函数fun_a()成了是结构体类型。虽然能编译成功,但这绝对是一个潜在的风险。
在fun_a()前面加上类型或者加void,当结构体struct student的定义少分号时,就会有编译错误,缺少分号的问题就能够被及时发现。正确的代码如下:

主函数main()一定要有返回值,尤其是C代码相应的执行程序作为操作系统中的一条命令时。如下的main()函数没有具体的返回值,是void型:

将上面的内容保存为文件main.c,在Linux下用gcc编译成默认的可执行文件a.out,它运行正常,打印出hello world。整个过程看似正确,但执行后的返回值不是0:

Linux系统下的命令结果为非0时,被认为是运行失败。如果这个失败被另一条命令捕获,将可能引起其他问题。在主函数名前面加上int,使用return 0返回,就不会有潜在的麻烦了。
10 其他
注意,注释不可嵌套。例如:
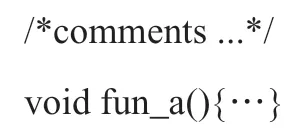
如果暂时不需要函数fun_a()了,可注释掉它。但需注意,如下这样注释是不可取的:

因为,第一个/*将和第一个*/配对,第二个*/落单,函数fun_a()并没有被注释掉,而且,落单的*/会引起编译错误。当需要注释掉连续的一整块内容时,使用条件编译比较方便:

写代码时要认真,避免笔误。例如,不要把&误写为&&,不要把||误写为|。某些笔误“歪打正着”地通过了编译,并且程序能够取得看似合理的运行结果时,会埋下隐患。下面的例子,使用结构体指针访问成员时,n-〉a不小心写成了n--〉a:

n--〉a相当于n-- 〉a,先进行n〉a(指针n地址值是否大于a)的判断,再运行n--(地址值减小)。内存地址值一般是大于10的,n〉a成立,所以printf的打印结果为1,但这个1并不是n-〉a(结构体m的成员a)的值1。普通变量名和结构体成员名恰好都叫a,成员a的值恰好为1,有了巧合,这个笔误得以“蒙混过关”。结构体成员与普通变量重名,虽然语法合理,但容易造成误会,应尽量避免。
11 警告不可忽略
有的编码者往往只关注编译error,忽略warning。实际上,不但不能忽视警告,还应通过设置编译选项,让其尽可能多地暴露出来。以上谈到的一些陷阱,通过解决告警信息中提示的问题就能规避。有的warning就是潜在的error,没有特殊原因的话,warning也应该消除[3]。
PC-lint是一个静态的C/C++代码检查工具,它比编译器要严格,能检测出很多符合语法但不易被发现的问题,可以把它视作更严格的编译器[4]。使用PC-lint,对提高软件质量很有帮助,详见pclintplus.com。
12 结束语
以上举出的是一些比较简单的缺陷案例,还有很多隐藏较深的陷阱。软件生命周期中的大部分时间是在维护,研究编程语言的陷阱可以降低维护成本。很多C用户尤其是初学者,只重视教程中语法的学习,只解决编译错误,基本上不考虑陷阱,直到出了问题,才开始找原因。如果一开始就重视避免写出有缺陷的代码,把编译error和warning放在同等重要的位置一起解决,日后将会节省出大量修改bug的时间和精力。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
计算机教育(2020年5期)2020-07-24
电子制作(2018年16期)2018-09-26
广东第二课堂·小学(2017年9期)2017-09-28
山东工业技术(2016年15期)2016-12-01
电测与仪表(2015年5期)2015-04-09
淮南师范学院学报(2015年3期)2015-03-22
单片机与嵌入式系统应用(2014年9期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
