
基于三支决策的联邦学习客户选择模型
2024-01-15 08:21李晓琦张春英刘璐王立亚
华北理工大学学报(自然科学版) 2024年1期
李晓琦,张春英,刘璐,王立亚
(华北理工大学 理学院,河北 唐山 063210)
引言
联邦学习(Federated Learning,FL)作为一个新的分布式机器学习模式,使客户端在保持数据集私有化的前提下训练本地模型,中央服务器通过多次迭代聚合本地模型,得到了具有良好推广性的全局模型[1,2]。在联邦学习中,中央服务器的核心任务是聚合从客户端收到的模型参数,以学习改进全局模型,并将其与客户端共享。通信带宽是联邦学习的一个主要瓶颈,因为大量的客户端都将其模型参数更新发送给中央服务器。联邦服务器的通信资源和计算资源也会限制参与客户端的数量。
最常用的减少联邦学习通信带宽的方法之一是降低通信频次,增加客户端的计算成本。这通常要求客户端在通信之前多次迭代局部梯度下降[3]。作为使用最广泛的联邦学习算法,FedAvg也是采用这种方法来减少通信成本的。为了进一步减少通信成本,服务器可以选择每一轮参与迭代的客户端集合。FedAvg在不改变总客户端数量的情况下随机选择参与训练的客户端,同时服务器把全局模型广播给所有的客户端,包括该轮未参与的客户端。然而,在这种方案存在偏颇。因为对于未参与训练的客户端,FedAvg产生的模型与预期中客户端单独训练得到的模型存在着偏差。Li等人[4]提出了一个公正的客户选择方案,即为被选中的客户端创建新的全局模型。
由于联邦学习中的通信限制和间歇性客户端可用性,只有一部分客户端可以参与每轮训练。但是,每轮迭代中客户端部分参与联邦训练会加剧数据异质性对最终全局模型的影响[5-7]。F-RCCE[8](Federated REINFORCE Client Contribution Evaluation)框架使用了参与方全部的梯度参数并且验证了该框架在数据分布不平衡下的性能,CFFL[9](Collaborative Fair Federated Learning)框架使用参与方部分的梯度参数调整分配的模型性能来实现联邦学习的合作公平性。文献[10]通过提出Top-k梯度选择算法,筛选上传的梯度参数以减少用户之间同步梯度的通信开销。客户选择中最常见的目标是加快训练的聚合过程。不同的学者给出了不同的技术方案。Chen等人[11]专注于减少训练轮中的客户数量,仅与选中的客户端进行通信可以将通信减少到客户端循环迭代中的十分之一。Chen等人[3]表示,最佳客户抽样可能会产生与客户完全参与方案中相似的学习曲线。Cho 等人[6]提出了 pow-d 方法,旨在减少训练轮次的总数以达到相同的精度。Cho等人[12]提出了基于MAB(Multi-Armed Bandit)的客户端选择策略UCB-CS,并计算每个客户端的累积局部损失值和每个客户端被采样次数的计数,使该客户选择策略提高了收敛速度。
三支决策(Three-way Decisions)[13]是一种处理不确定性决策的粒计算方法,已成功用于各种领域。三支决策理论通过引入边界域的概念,将那些不能立刻做出判决的对象划分到边界域以待进一步处理,这和人们在实际生活中做决断的行为相符合,同时能降低一定的决策错误率。针对联邦学习中客户选择的问题,依据三支决策理论,在客户选择的过程中,制定三支联邦客户的分类规则,提出了一种基于三支决策的联邦客户选择模型。该模型根据客户端的参数损失值和精度,利用三支决策的阈值判定客户端是否参与联邦聚合训练,从而加快联邦模型的收敛。
1 三支决策相关理论
1.1 三支决策
三支决策的主要思想就是根据域的划分将整体分为3个独立的部分,并对不同部分采用不同的处理方法,其基本思想可以用图1来描述。设U={x1,x2,...,xn}是有限、非空实体(对象)集,C是有限条件集。三部分分别为正域、负域和边界域。

图1 三支决策的三个域


表1 代价函数

表2 代价函数
λPP,λNP,λBP分别表示当对象属于C时采取行动aP,aN,aB的代价,λPN,λNN,λBN分别表示当对象属于C时采取行动aP,aN,aB的代价。P(C|[x])表示[x]属于集合C的条件概率,对于[x]中的对象,分别采取行动aP,aN,aB的期望代价为:
(1)
根据贝叶斯决策论的最小风险决策过程,可得如下最小代价决策规则[17]:
(P)若R(aP|[x])≤R(aN|[x])且R(aP|[x])≤R(aB|[x]),则x∈POS(α,β)(C)接受决策;
(N)若R(aN|[x])≤R(aP|[x])且R(aN|[x])≤R(aB|[x]),则x∈NEG(α,β)(C)拒绝决策;
(B)若R(aB|[x])≤R(aP|[x])且R(aB|[x])≤R(aN|[x]),则x∈BND(α,β)(C)延迟决策。
令,
(2)
(P) 如果P(C|[x])≥α,则x∈POS(α,β)(C)接受决策;
(N)如果P(C|[x])≤β,则x∈NEG(α,β)(C)拒绝决策;
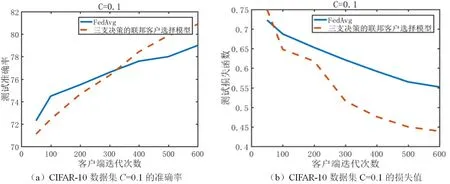
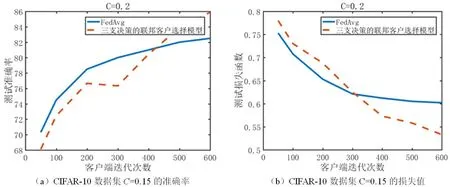
(B)如果α 该部分详细介绍联邦学习的基本步骤,基于三支决策的联邦客户过程和基于三支决策的横向联邦学习模型。 联邦学习被认为是一个迭代过程,每次迭代都对中心机器学习模型进行改进,从服务器随机选择客户端下载可训练模型,使用自己的数据更新模型,并将更新后的模型上传到服务器,同时要求服务器聚合多个客户端更新以进一步改进模型。 联邦学习实现可以概括为以下3个步骤[18]: (1)模型选择:首先启动中央服务器预练的机器学习模型即全局模型及其初始参数,然后将全局机器学习模型与联邦学习环境中的所有客户端共享; (2)局部模型训练:在与所有客户端共享初始机器学习模型和参数后,在客户端的初始机器学习模型即局部机器学习模型使用个人训练数据进行训练; (3)数据传输:上行:客户端上传参数到服务器,下行:服务器传输参数到客户端; (4)聚合模型:本地模型在客户端级别进行训练,更新被发送到中央服务器,以聚合和训练全局机器学习模型。全局模型将被更新,改进后的模型将在各个客户机之间为下一次迭代共享。 联邦学习处于一个持续的迭代学习过程中,重复上述(2)和(3)的训练步骤,以保持所有客户端的全局机器学习模型更新。 联邦学习经典算法FedAvg主要思路是随机选择m个客户端采样,对这m个客户端的梯度进行全局模型更新。 在一般横向联邦学习框架FedAvg算法中有K个客户端,其中客户端k有本地数据集Bk,包含数据样本Dk=|Bk|。所有客户端利用中央服务器旨在共同寻求模型参数向量w,以最大限度地降低以下目标: (3) 结合联邦学习的主要步骤[18]:模型选择、局部模型训练、数据传输、聚合模型。在第一轮聚合模型之后增加客户选择模块,设计出基于三支决策选择模型的联邦学习整体框架,如图2所示。 图2 联邦客户选择总体框架图 在联邦客户选择框架中,中央服务器执行全局模型聚合模块和客户选择模块。依据Yao提出的多类分类问题[13]三支决策模型,客户选择模块将把所有客户端划分为3个部分,分别是POS域表示被选中,NEG域表示没有被选中,BND域表示待定选择。基于三支决策的联邦客户选择模型具体算法思路如下: (1)分域:利用上一轮客户端的损失函数Fk(w)采取行动aPP的期望代价,使双曲正切函数tanh(Fk(w))代表条件概率,令tanh(Fk(w))=P(C|xk),若P(C|xk)>α将k划分POS域,若P(C|xk)<β将k划分NEG域,若β (2)判断:如果POS域中被选中的客户端少于m个,则从BND域中再次选择; (3)迭代:此时条件概率使用上一轮客户端回传的精度vacck的双曲正弦函数sinh(vacck),令sinh(vacck)=P(C|xk),直到正域中选中的客户端大于等于m个。 双曲正切函数和双曲正弦函数,在(0,+∞)范围能单调递增,使用双曲正切函数和双曲正弦函数对参数进行归一化处理。客户端总数是K,每轮客户样本数量为m。 为了验证算法的有效性, 本次实验共选择:CIFAR-10、Fashion-MNIST、MNIST这3种公开的数据集进行试验。 选取Fashion-MNIST、MNIST、CIFAR-10数据集中的2个类别,转换图片像素为1×28×28,每种类别挑选4 000张图片,其中3 000张训练图片、1 000张测试图片。初始化100个客户端,把3 000张训练图片及1 000张测试图片分别平分为100份,也即每个客户端拥有30张训练图片、10张测试图片,使其充分满足横向联邦学习的业务特征。 实验采用联邦平均经典算法FedAvg的联邦聚合算法和三支联邦客户选择算法进行比较,均采用CNN机器学习算法。2个算法参数如表3所示。其中IID表示客户端数据的分布方式,IID=TRUE代表客户端的数据分布方式采用独立同分布方式;K表示客户端总数量;C表示客户端选择比例;Learning_rate表示学习率,代表可变参数每次更新的幅度。 表3 算法参数 3.2.1参数C=0.1 参数C=0.1时的实验结果分别如图3、图4、图5所示。 图3 Fashion-MNIST数据集参数C=0.1时的实验结果 图4 CIFAR-10数据集参数C=0.1的实验结果 图5 MNIST数据集参数C=0.1的实验结果 根据图3 Fashion-MNIST数据集实验结果可知,随着迭代轮次增加,三支联邦客户选择算法的准确率逐渐上升,而且上升幅度较大。FedAvg算法准确率变化幅度较小。当迭代轮次到600时,三支联邦客户选择算法的准确率达到99%,与FedAvg算法相比准确率提高了约5.5%。三支联邦客户选择算法的损失值下降幅度较大,且总是低于FedAvg算法。三支联邦客户选择算法收敛速度比FedAvg快。 根据图4 CIFAR-10数据集实验结果可知,随着迭代轮次增加,三支联邦客户选择算法和FedAvg算法的准确率都逐渐上升,而且三支联邦客户选择算法变化幅度较大,FedAvg算法准确率变化幅度较小。当迭代轮次大于300时,三支联邦客户选择算法准确率高于FedAvg算法。当迭代轮次到600时,三支联邦客户选择算法的准确率达到83.2%,与FedAvg算法相比提高了约4%。三支联邦客户选择算法的损失值下降幅度较大,且总是低于FedAvg算法。三支联邦客户选择算法收敛速度比FedAvg快。 根据图5 MNIST数据集实验结果可知,三支联邦客户选择算法的准确率逐渐上升,而且三支联邦客户选择算法变化幅度较大。FedAvg算法准确率变化幅度较小。在迭代轮次大于400时,三支联邦客户选择算法准确率高于FedAvg算法。当迭代轮次到600时,三支联邦客户选择算法的准确率到94%,与FedAvg算法相比提高了约3%。在迭代轮次大于100时,三支联邦客户选择算法的损失值下降幅度较大,且总是低于FedAvg算法。三支联邦客户选择算法收敛速度比FedAvg快。 3.2.2参数 C=0.15 参数C=0.15时准确率的实验结果分别如图6、图7、图8所示。 图6 MNIST数据集参数C=0.15的实验结果 图7 Fashion-MNIST数据集参数C=0.15的实验结果 图8 CIFAR-10数据集参数C=0.15的实验结果 根据图6 MNIST数据集实验结果可知,当迭代轮次小于420时,三支联邦客户选择算法的准确率小于FedAvg算法。当迭代轮次大于420时,三支联邦客户选择算法的准确率变化幅度较大,且始终大于FedAvg算法准确率。整体来看,FedAvg算法准确率变化幅度较小。当迭代轮次到600时,三支联邦客户选择算法的精度达到95%,与FedAvg算法相比准确率提高了约3%。在迭代轮次大于100时,三支联邦客户选择算法的损失值下降幅度略大于FedAvg算法。三支联邦客户选择算法收敛速度比FedAvg 快。 根据图7 Fashion-MNIST数据集实验结果可知,在迭代轮次达到100之后,FedAvg算法的准确率没有明显增加。当迭代轮次到600时,三支联邦客户选择算法的准确率达到98%,比FedAvg算法的准确度提高了约5%。在迭代轮次大于100并且小于400时,FedAvg算法和三支联邦客户选择算法收敛速度差别不大,但在迭代轮次大于400时,FedAvg算法的损失值又逐渐增加,这是出现了过拟合现象。而三支联邦客户选择算法随着迭代轮次增加,损失值逐步减小,没有出现过拟合现象。 根据图8 CIFAR-10数据集实验结果可知,随着迭代轮次增加,三支联邦客户选择算法和FedAvg算法的准确率都逐渐上升,当迭代轮次小于500时,FedAvg算法高于三支联邦客户选择算法的准确率。当迭代轮次大于500时,三支联邦客户选择算法的准确率高于FedAvg算法。当迭代轮次到600时,三支联邦客户选择算法的准确率达到84%,与FedAvg算法相比准确度提高了约2%。随着迭代轮次增加,三支联邦客户选择算法的损失值下降幅度较大,且总是低于FedAvg算法。三支联邦客户选择算法收敛速度比FedAvg快。 3.2.3参数C=0.2 参数C=0.2时准确率的实验结果分别如图9、图10、图11所示。 图9 Fashion-MNIST数据集参数C=0.1的实验结果 图10 CIFAR-10数据集参数C=0.2的实验结果 图11 MNIST数据集参数C=0.2时的实验结果 根据图9 Fashion-MNIST数据集实验结果可知,在迭代轮次大于100时,三支联邦客户选择算法的准确率大于FedAvg算法,三支联邦客户选择算法的准确率逐渐上升,而且变化幅度较大。FedAvg算法精准度变化幅度较小。当迭代轮次到600时,三支联邦客户选择算法的准确率达到99.5%,与FedAvg算法相比准确率提高了约5%。在迭代轮次大于100并且小于400时,FedAvg算法和三支联邦客户选择算法收敛速度差别不大,但在迭代轮次大于400时,FedAvg算法的损失值又逐渐增加,这是出现了过拟合现象。而三支联邦客户选择算法随着迭代轮次增加,损失值逐步减小,没有出现过拟合现象。 根据图10 CIFAR-10数据集实验结果可知,随着迭代轮次增加,三支联邦客户选择算法和FedAvg算法的准确率都逐渐上升。当迭代轮次小于420时,FedAvg算法高于三支联邦客户选择算法的准确率。当迭代轮次大于420时,三支联邦客户选择算法的准确率高于FedAvg算法。当迭代轮次到600时,三支联邦客户选择算法的准确率达到86%,与FedAvg算法相比准确率提高了约3.5%。随着迭代轮次增加,三支联邦客户选择算法的损失值下降幅度较大。在迭代轮次小于300时,FedAvg算法收敛速度比三支联邦客户选择算法快。在迭代轮次大于300时,三支联邦客户选择算法收敛速度比FedAvg快。 根据图11 MNIST数据集实验结果可知,当迭代轮次小于340时,三支联邦客户选择算法的准确率小于FedAvg算法。当迭代轮次大于340时,三支联邦客户选择算法的准确率大于FedAvg算法,而且变化幅度较大。FedAvg算法准确率变化幅度较小。当迭代轮次到600时,三支联邦客户选择算法的准确率达到95%,与FedAvg算法相比,准确度提高了约4%。三支联邦客户选择算法收敛速度比FedAvg 快。在迭代轮次小于200时,FedAvg算法损失值小于三支联邦客户选择算法的损失值。在迭代轮次大于200时,三支联邦客户选择算法的损失值小于FedAvg算法,并且下降幅度大于FedAvg算法。 根据在不同数据集上,联邦平均算法FedAvg和基于三支决策的联邦客户选择算法,针对不同参数设置得到的算法结果进行对比分析。表4、表5和表6列出了三个数据集在参数C=0.1、0.15、0.2的情况下实验结果显示的最高准确率和最小损失值。 表4 C=0.1的最高准确率和最小损失值 表5 C=0.15的最高准确率和最小损失值 表6 C=0.2的最高准确率和最小损失值 由表4、表5和表6可知,三个数据集在不同的参数C的情况下,三支联邦客户选择算法的准确率均高于FedAvg算法。三个数据集在参数C=0.1、0.15的情况下,三支联邦客户选择算法的损失值均小于FedAvg算法。Fashion-MNIST数据集在C=0.2的情况下,三支联邦客户选择算法的损失值均大于FedAvg算法,在参数C=0.1、0.15的情况下,三支联邦客户选择算法的损失值均小于FedAvg算法。 (1)提出了一种融合三支决策思想的联邦客户选择的方法。在CIFAR-10、MNIST、Fashion-MNIST这3种数据集进行的实验证实了所提出方法的可行性与有效性。 (2)与随机选择方法相比,基于三支决策的联邦客户选择方法,Fashion-MNIST数据集上准确率提高了约5%,在CIFAR-10数据集上准确率提高了约3%,在MNIST数据集准确率提高了约4%。2 基于三支决策的联邦客户选择模型
2.1 联邦学习基本步骤
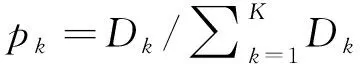
2.2 基于三支决策的联邦客户选择模型

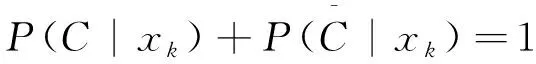
3 实验
3.1 实验环境

3.2 实验结果










4 结论
猜你喜欢
健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27家庭影院技术(2020年10期)2020-12-14家庭影院技术(2019年7期)2019-08-27中国交通信息化(2018年5期)2018-08-21传媒评论(2018年4期)2018-06-27传媒评论(2018年4期)2018-06-27电子测试(2018年10期)2018-06-26俄罗斯问题研究(2013年1期)2013-03-11
