
基于改进YOLOv5l 的田间水稻稻穗识别
2024-01-15 06:01蔡竹轩蔡雨霖曾凡国岳学军
华南农业大学学报 2024年1期
蔡竹轩,蔡雨霖,曾凡国,岳学军
(华南农业大学 电子工程学院/人工智能学院,广东 广州 510642)
农业是第一产业,也是我国经济建设和社会发展的保障性产业[1-2]。作为粮食作物中最主要的种类之一,水稻在2011 年的消费量已占中国人口总口粮全年消费量的55%,全国有超过60%的人口以稻米为主食[3]。随着我国人口不断增长,对水稻的需求量也不断攀升,如何快速准确地对水稻的产量进行预估变得尤为重要。传统田间水稻的估产一般采用的是有损的方法,即在大田中按面积等距或者按组平均抽样的原则,选取一些小田块作为样本,水稻收获后对其脱粒、晒干、扬净、称质量后、利用水分测定仪测定含水量,并按粕稻比例13.5%,粳稻比例14.5% 来计算出最终的水稻产量[4]。稻穗是水稻重要的营养生殖器官,是谷粒着生的部位,其数量不仅与水稻产量直接相关[5],而且在水稻病虫害检测[6]、营养诊断[7]及生育期检测[8]等方面也有着十分重要的作用。过去检测稻穗主要依靠人工识别,这严重依赖于从业人员的技术经验,不仅费时费力,而且主观性较强。
随着计算机信息技术的发展,机器视觉技术也随之飞速发展并被广泛应用到农业实际生产中。赵锋等[9]利用麦穗颜色信息去除图片中的田间背景等干扰信息,训练AdaBoost 分类器对麦穗区域进行识别,对随机选择的100 个样本取得了88.7%的识别准确率。范梦扬等[10]利用浅层学习方法,针对局部小范围内的田间小麦低分辨率群体图像,提取麦穗的颜色和纹理特征训练支持向量机分类器,实现对麦穗轮廓的提取和检测,通过统计麦穗茎的骨架以及有效交叉点的数量获得稻穗数量。Zhou 等[11]利用主成分分析算法抽取小麦图像的颜色、纹理和边缘等代表性特征,进一步训练双支持向量机模型实现对小麦麦穗的识别,取得了79%~82%的计数准确率。Duan 等[12]基于I2 颜色平面的滞后阂值生成稻穗图像块,训练BP 神经网络模型对图像块进行分类并计算稻穗数。Li 等[13]利用Laws 纹理能量特征生成麦穗图像块,训练BP 神经网络模型对图像块进行分类并计算麦穗数。Olsen 等[14]使用不同尺度的超像素生成田间高粱图像块,训练线性回归模型来实现计数。
传统机器视觉识别方法计算简单、处理速度快,但存在特征设计对人工经验依赖性强、模型泛化能力弱、鲁棒性不强等问题,且对高密度种植的田间水稻,实际应用还存在一定限制。作为机器学习领域革命的代表,深度学习具有强大的自动特征提取、复杂模型构建以及图像处理能力等优势,已在多个研究领域取得了重大进展,农业应用中的快速检测和分类便是其中之一。
李静等[15]提出了一种改进的GoogLeNet 卷积神经网络对玉米螟虫害图像进行检测,识别平均准确率达96.44%。顾伟等[16]利用改进的SSD 模型对群体棉籽进行识别,提高了对小物体的检测精度。周云成等[17]提出一种基于面向通道分组卷积网络的番茄主要器官实时识别模型。Koirala 等[18]使用YOLO 算法模型对芒果进行检测并预测产量。Tian 等[19]通过改进的YOLO-v3 模型检测果园中不同生长阶段的苹果。张领先等[20]提取冬小麦的麦穗、叶片和阴影3 类标签图像,构建了数据集,采用梯度下降法对模型进行训练,并结合非极大值抑制进行冬小麦麦穗计数,总体识别正确率达99.6%。彭文等[21]运用深度卷积神经网络技术,对6 种水稻田杂草进行识别。黄小杭等[22]对不同分辨率图像进行试验,运用K-means 维度聚类及深度可分离卷积网络等方式对YOLOv2 网络进行调整并对莲蓬进行检测,检测速度可以达到102.1 帧/ms。彭红星等[23]采用改进的SSD 深度学习神经网络对荔枝、苹果、脐橙以及皇帝柑进行识别,使用迁移学习等方式进行优化,提高了自然背景下SSD 网络识别水果的泛化能力。张洋[24]提出了一种面向稻穗种粒缺陷识别的个性特征显著化规范轻量Rice-VGG16 模型,识别稻穗缺陷种粒的精确度达99.51%。马志宏等[25]将稻穗充分铺开后提取稻穗枝梗的几何形态特征,并基于此与稻穗粒数建立映射关系,预测稻穗粒数的相对误差为6.72%。
基于深度学习的农作物分类和识别方法已逐渐成为主流并取得一定的效果,然而,因水稻稻穗微小的特点,其空间信息在特征图上极易被损失,且田间场景具有较高的复杂性以及受通用目标检测算法泛化能力的约束,稻穗识别的精度下降、效果不佳,在实际应用中还存在一定的局限性。本研究通过改进YOLOv5l 网络模型,引入有效通道注意力(Efficient channel attention,ECA)机制模块[26],加强对图片中待检测目标的特征提取,提出一种改进YOLOv5l 的田间水稻检测模型,以期实现对水稻稻穗检测和水稻的无损估产。
1 材料与方法
1.1 数据样本采集
数据采集自田间,采集时间为2021 年6 月,采集地点为广东省植物分子育种重点实验室试验基地,在晴天利用Nikon D3300 作为采集设备,镜头型号为AF-S 28-300MM F/3.5-5.6G ED VR,其有效像素为2 416万,图像格式为JPEG,满足水稻图像采集的要求。如图1 所示,为了提高模型的识别精度,本文在图像采集时,使用了拍摄底板辅助拍摄,即制作一块边长为0.30 m×0.25 m 的纯黑色底板作为数据样本采集时的拍摄底板。图像采集时保持相机闪光灯关闭,拍摄相机与目标稻穗的距离统一固定在30 cm左右,以确保每一目标稻穗图像大小相近且清晰,最终采集到图像650 幅,像素大小为6 000×4 000。

图1 原图像和数据增强后的图像Fig.1 Original image and images after data augmentation
1.2 数据增强与数据集构建
对于多目标、小目标的图像,深度学习算法往往需要大量的图像数据才能有效地提取图像特征并分类。为了有效提升数据样本的数量、增加数据样本的多样性和数据库的大小、提升检测算法模型的精度,本文对采集到的图像数据样本进行预处理,包括数据标注和数据增强2 个步骤。
图像数据本身没有标签和语义,需要进行标注才能用于训练。本文利用LabelImg 标注工具,按照PASCAL VOC 标准进行稻穗谷粒的标注。因1张稻穗图片中的1 株稻穗包含多粒稻谷,标注1张稻穗图片数据需要画将近90 个框,耗时约10 min,故将LabelImg 设置为自动保存和高级模式,可以加快人工标注单一稻穗图像的速度。
数据增强(Data augmentation,DA)通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模,是提高目标识别算法鲁棒性的重要手段。本文采用随机长宽比裁剪、水平翻转、垂直翻转、饱和度增强、饱和度减弱、高斯模糊、灰度化、CutMix、Mosaic 共9 种操作,调整图像的几何形态、识别目标内容结构组成和颜色种类,随机改变训练样本,降低模型对识别目标的几何属性和颜色属性的依赖,从而提高模型的泛化能力。将原数据集扩充到原来的5 倍,共得到3 250 张图片,原图和数据增强后的图像效果如图1 所示,并将数据集按照7∶2∶1 的数量比例划分为训练集、测试集和验证集。
1.3 水稻稻穗检测方法
作为目前最先进的目标检测算法之一,YOLOv5具有检测速度快、识别性能好、网络结构简单、使用方便等特点。其性能与YOLOv4 不相伯仲,但相比DarkNet 小了近90%,推理速度可以达到140 帧/ms,满足实时检测的要求。YOLOv5 共有YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x 4 种版本。网络结构中的Ultralytics 模块通过depth_multiple 和width_multiple 2 个参数控制模型的深度和卷积核的数量,故4 种模型检测的深度和广度有所不同。其中,YOLOv5s 网络最小、速度最快、精度最低,其余3 种模型相对于加深加宽网络,检测精度不断提升,但速度也随之减慢。本文试验检测目标为大田水稻稻穗,具有数量多、体积小、分布密等特点。YOLOv5l 是YOLOv5 系列中性能与模型大小的平衡点,它在一定程度上保持了较高的检测精度,有助于在密集场景中有效地检测目标。而且,YOLOv5I相对较小,这意味着在一些计算资源有限的设备上也可以实现高质量的目标检测,有利于后续将检测算法部署在一些边缘设备上。故本文选择YOLOv5l作为基础算法进行优化提升。
2020 年,Wang 等[26]认为Hu 等[27]在2019 年提出的压缩激励(Squeeze excitation,SE)通道注意力机制中,降维会对通道注意力产生负面影响,故提出了有效通道注意力(Efficient channel attention,ECA) 模块,从而实现不降维的跨通道交互策略。如图2 所示,ECA 主要由全局池化(Global average pooling,GAP)、CONVLD 和SCALE 3 个操作组成,GAP 沿着空间维度进行特征压缩,将W×H×C的特征输入转换为1×1×C的特征输出,以获得全局信息,W、H、C分别表示特征的宽、高、长信息。然后利用CONVLD 实现无降维的局部跨通道交互,直接获取通道与权重的相关性,再通过sigmoid 函数获得归一化的权重,最后SCALE 操作是将归一化后的权重通过乘法加权到每一个通道特征上,得到经过通道注意力后各通道加权的语义特征。
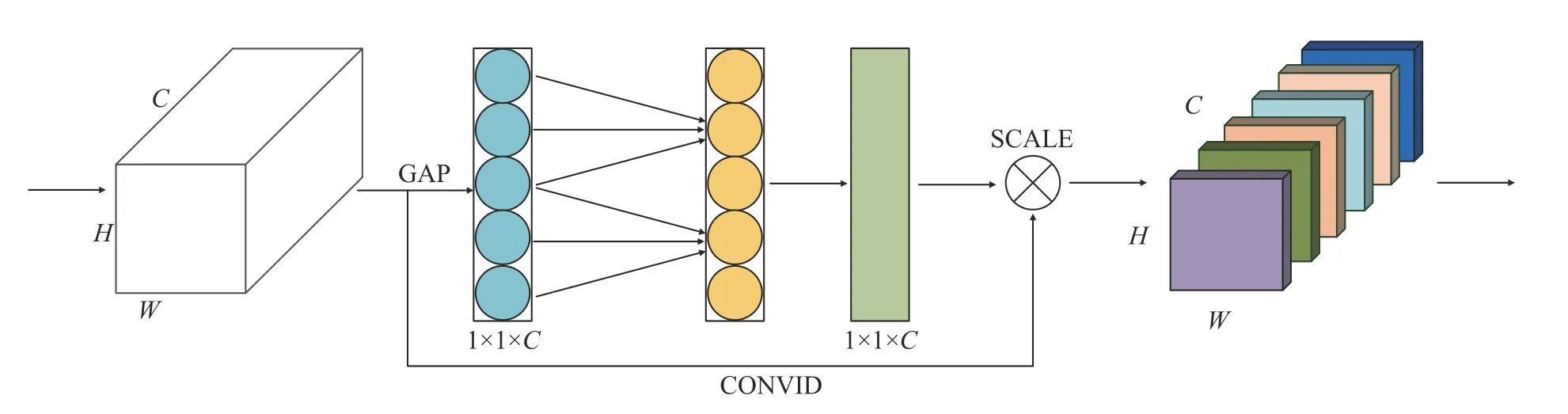
图2 ECA 流程图Fig.2 Flow diagram of ECA
YOLOv5l 的网络结构主要由输入端(Input)、骨干网络(Backbone)、多尺度特征融合模块(Neck)和输出端(Output)4 部分组成。C3 层用于提取输入样本中的主要信息,增强了网络结构中的梯度值,得到更细的特征粒度,同时减少了计算量,有效提升了网络的计算能力。SPP 层将上下文特征分离,使得输入主干网络的特征图尺寸不受限制,提高了网络的感受野。小目标特征信息通过多层网络结构处理后,位置信息模糊粗糙,特征信息出现不同程度的丢失。这使得网络模型出现对小目标的误检和漏检。为提高原始模型对水稻小目标稻穗的检测精度,本研究提出改进YOLOv5l 网络模型,具体结构如图3 所示。在骨干网络中的SPP 层前置入ECA注意力机制模块,ECA 通过不降维的跨通道交互增强了相关通道的特征表达并降低性能损耗,使得小目标信息更易被网络学习。
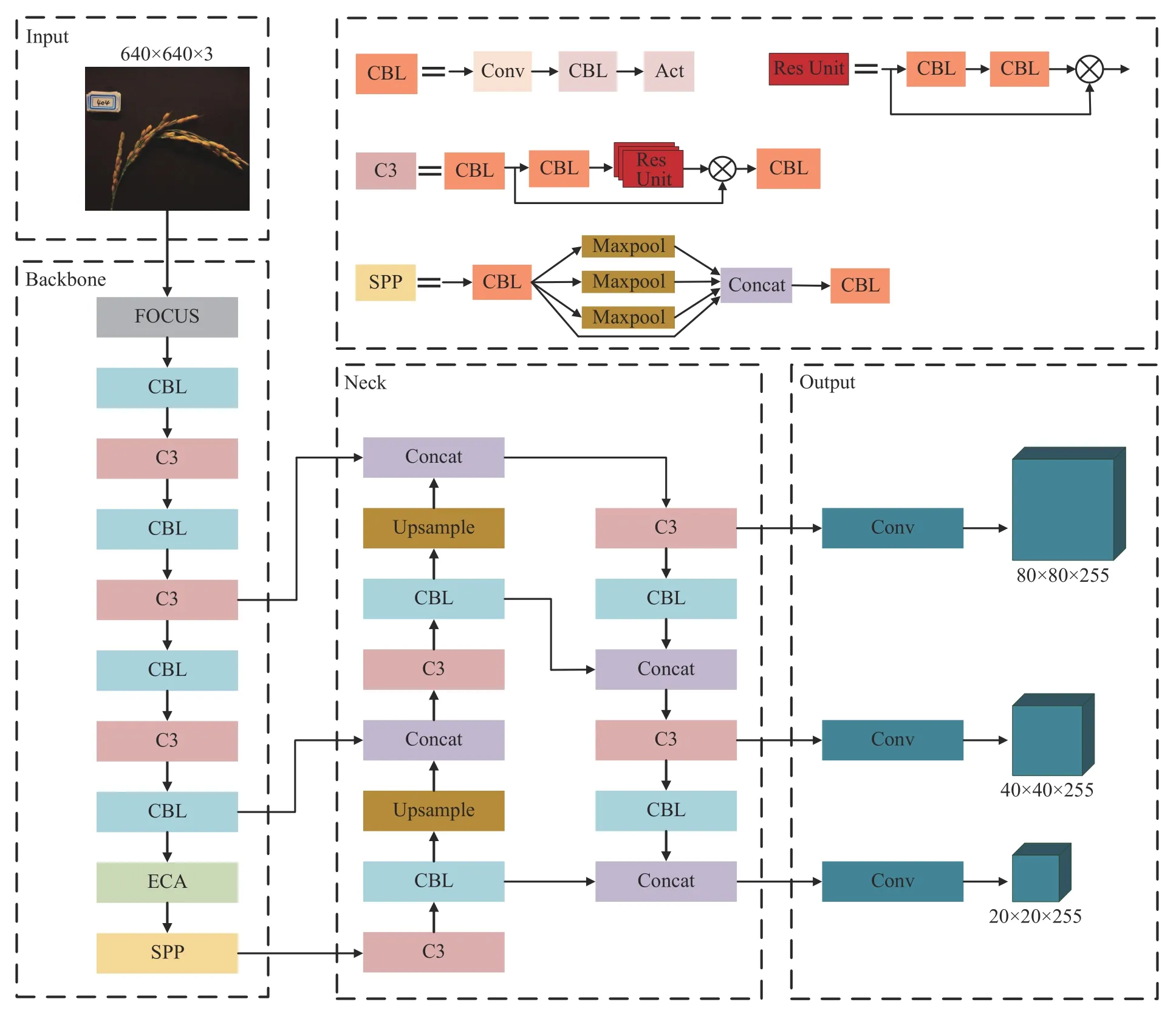
图3 改进YOLOv51 网络总体框图Fig.3 Overall block diagram of the improved YOLOv51 network
2 结果与分析
本研究试验平台选择Windows10(64 位)操作系统。CPU 型号为Intel(R) Core I9-10900K,GPU 型号为Nvidia GeForce RTX3090,计算机内存为24GB。测试的框架为Pytorch1.9.0,使用CUDA10.1 配合CUDNN7.6.5.32 运行;编程语言为Python。本研究在网络模型训练阶段,将初始学习率设置为0.000 1,总迭代次数设置为300 次。
2.1 检测算法评估指标
为了客观、全面地评价所提方法对田间水稻稻穗检测试验的结果,本研究采用精确率(Precision,P)、召回率(Recall,R)、平均精度(Average precision,AP)和损失函数(Loss function)等指标衡量检测效果,其中,P是指所有被标记为稻穗的物体中,稻穗正样本所占的比率;R是指测试集中所有的稻穗正样本中,被正确识别为稻穗的比例;而以P为纵坐标、R为横坐标,绘制曲线,AP 即为曲线的积分。具体计算如公式(1)~(3)所示。
由表3可知,KX9384 1穴2株、3株和1株处理较西蒙6号覆膜和不覆膜对照处理增产均达到极显著水平,增产幅度最高为1穴2株种植方式,分别为15.79%,19.23%。KX9384 3种方式处理间,1穴2株比1穴3株和1穴1株增产极显著,1穴3株比1穴1株增产显著。西蒙6号覆膜比不覆膜增产显著。
式中,TP 表示稻穗被正确分类和定位的正样本个数,FP 表示被标的为稻穗的负样本个数,FN 为测试样本中真实的正样本数减去TP,N为样本总数。
损失函数用来估量模型预测值和真实值不一样的程度,其值的大小极大程度上决定了模型的性能好坏。YOLOv51 采用了分类损失(clsloss)、坐标损失(giouloss)和置信度损失(objloss)来指导训练。其中,分类损失和置信度损失分别用于判断锚框与对应的标定类别是否正确和计算网络的置信度,采用二值交叉熵,具体计算如式(4)、(5)所示;坐标损失用于判断预测框与标定框之间的误差,采用giou 计算方式,具体方式如式(6)所示。总损失为以上3 部分损失的加权和,α、β、γ为3 类损失各自的权重,计算公式如(7)所示。
2.2 ECA 模块融合位置对比
将ECA 模块融合到网络模型的不同位置,开展试验并进行对比。分别在YOLOv5l 的C3 层和SPP 层融入ECA 注意力模块,生成3 种新的基于YOLOv51 的算法模型:ECA-YOLOv5l-Backbone、ECA-YOLOv5l-Neck 和ECA-YOLOv5l-SPP。图4为3 种ECA 模块融合网络的具体位置。检测试验结果如表1 所示,将ECA 模块融入到SPP 前的检测效果较好。分析认为,目标特征信息在Backbone的多层网络处理中逐渐粗糙并出现部分丢失,在SSP 层前融入注意力机制能够使网络模型清晰关注目标的特征信息,提高检测精度。而在Neck 部分,由于网络深度较大,目标的特征信息被淹没,语义信息较为粗糙,导致注意力模块无法较好地关注到目标特征。
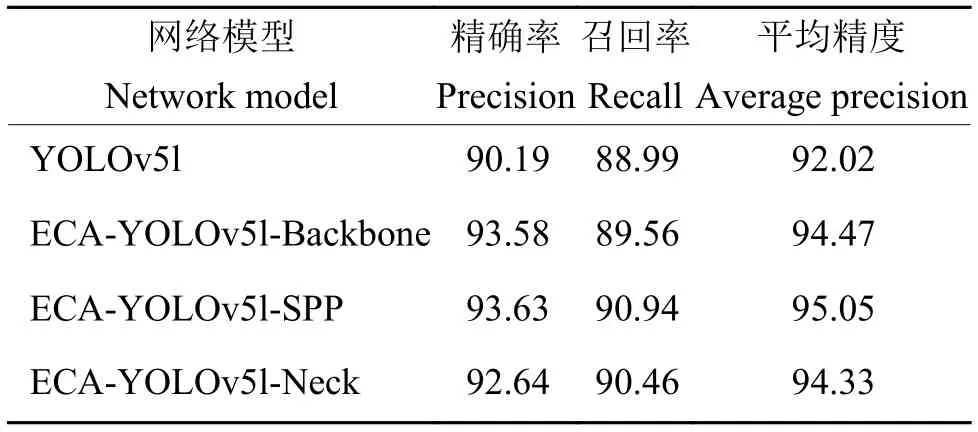
表1 ECA 模块融合结果对比Table 1 Comparison of ECA module fusion results %

图4 3 种融合ECA 模块的YOLOv51 模型Fig.4 Three YOLOv5l models incorporating ECA modules
2.3 YOLOv5l 消融试验对比
为验证本研究提出的YOLOv5l 改进方法,用原数据集针对ECA 和DA 开展消融试验,用于判断每个改进点的有效性。在原有模型基础上依次加入DA 和ECA,模型训练过程中使用相同的参数配置。试验结果如表2 所示,在引入DA 后,模型性能有显著提升,平均精度提高了3.84 个百分点;而在引入ECA 和DA 后,模型的精确率和召回率均有所提升,平均精度提高了6.87 个百分点。分析认为,引入数据提升了模型的泛化能力和鲁棒性,使得模型的检测性能有较大提升;而引入注意力机制使得模型选择性地强调信息特征,提高了其表征能力,表现为检测精度提升较为明显。
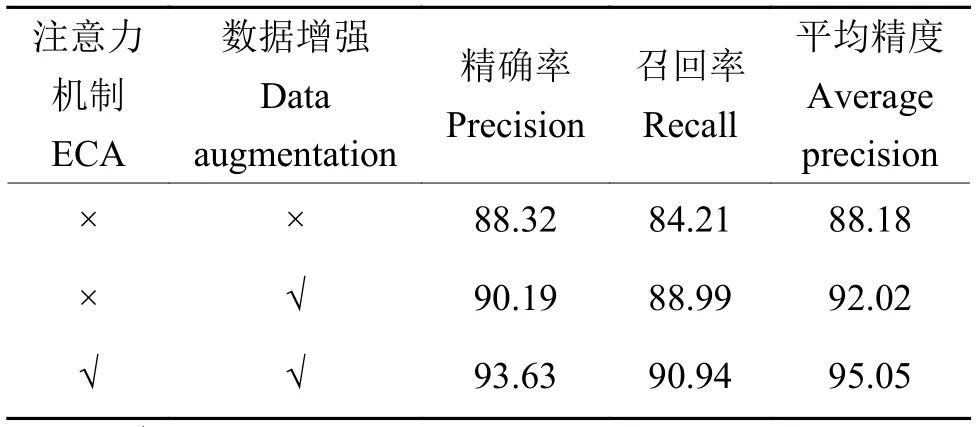
表2 YOLOv5l 消融试验1)Table 2 YOLOv51 ablation experiment %
2.4 不同网络模型的对比试验
为验证本研究提出的改进YOLOv5l 算法的性能,将其与YOLOv5l、YOLOv5x 和目前主流的目标检测算法Faster R-CNN、SSD 比较。5 种网络模型使用同样的数据集且使用同样的数据增强方法,训练方式均为随机梯度下降法(SGD),初始学习率均设置为0.000 1,总迭代次数设置为300 次。得到5 种检测算法平均精度随迭代次数的变化曲线(图5a)、P-R曲线(图5b)和随迭代次数的损失值变化曲线(图6)。图7 为ECA-YOLOv5l-SPP 算法模型检测结果示例。
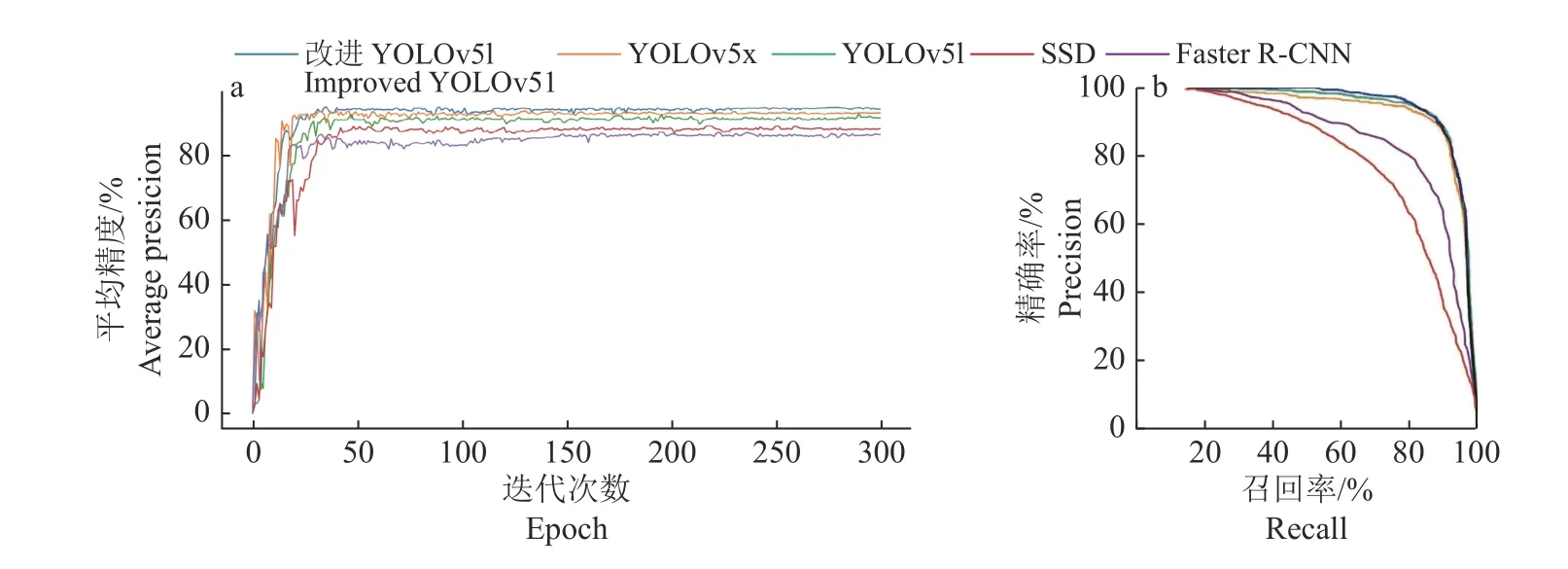
图5 不同网络模型平均精度曲线(a)和P-R 曲线(b)Fig.5 The average precision curves (a) and precision-recall curves (b) of different network models
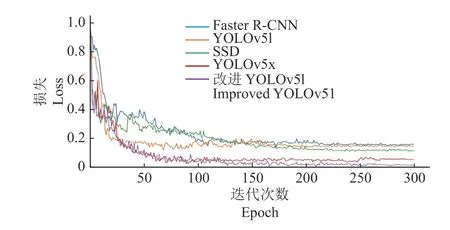
图6 不同网络模型的损失值随迭代次数的变化曲线Fig.6 Changes in the loss values of different network models with epoches

图7 识别结果示例Fig.7 Example of recognition results
由图5 可知,平均精度均随迭代次数的增加递增并最终平缓收敛。由图6 可知,5 种模型损失均随迭代次数的增加递减,一开始由于初始学习率设置较大故损失下降较快,随着迭代次数增加,学习率逐渐变小,曲线逐渐平缓至最终收敛。改进YOLOv51 损失最小,其次是YOLOv5x。同时,可直观地看到,改进YOLOv51 的曲线面积大于其他目标检测模型的,这表明改进 YOLOv51 模型具有更高的平均精度。
由表3 可知,改进YOLOv51 占用内存少的同时保持较高的检测率和检测精度,平均精度达95.05%,是所有模型中最高的,且内存仅为 91.9 MB,比YOLOv5x 小 45%。此外,检测速率为23.50 帧/ms,比 Yolov5x 快5.4 帧/ms。
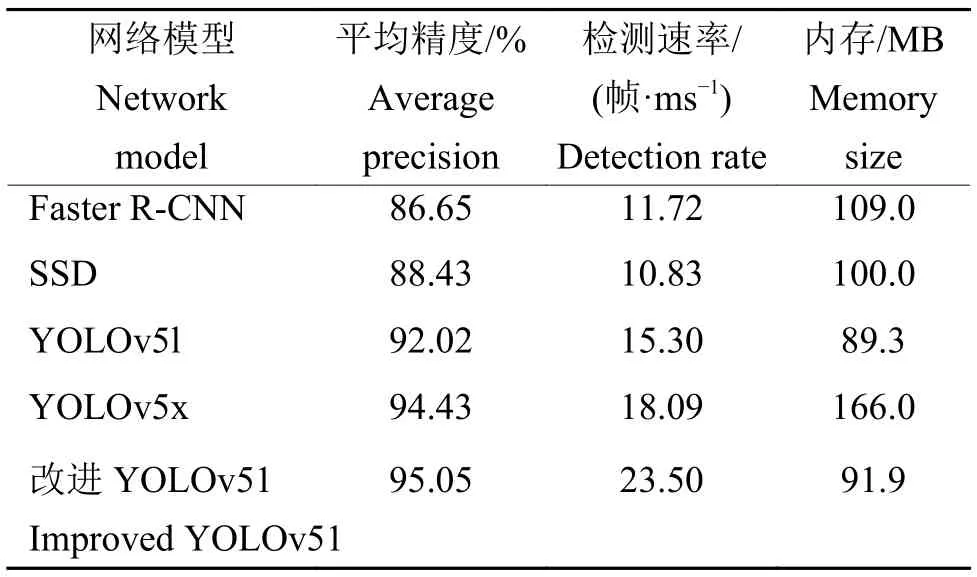
表3 不同网络模型检测性能对比Table 3 Comparison of different networks
试验结果表明,本研究提出的网络模型减少了额外算力和内存开销,在保持较高的检测速率和检测精度的同时,占用内存资源也较少,优于原有的YOLOv5l 算法和主流目标算法,可用于田间环境下的水稻稻穗精准检测。
3 结论
为解决田间水稻稻穗检测过程中要求高、精度低等问题,提出一种改进YOLOv5l 的田间水稻检测算法。构建了田间水稻稻穗数据集;将ECA 机制与原始YOLOv5l 进行融合,对比了ECA 融合网络模型不同位置的检测性能;对YOLOv5l 进行ECA和DA 消融试验,并与传统模型进行对比试验,主要结论如下。
ECA 使用不降维的跨通道交互策略,通过共享权重减少了模型参数,进一步提高小目标检测的精度和速度。检测目标的特征信息在经过网络多层处理后变得粗糙模糊甚至丢失,而在SSP 层前融合ECA 能使网络增强相关通道的特征表达,较好地关注到目标信息,从而使检测的平均精度相对于未融合网络提高了3.03 个百分点。
改进模型的平均精度比Faster R-CNN 提高8.4 个百分点,比SSD 提高6.62 个百分点。相比于YOLOv5x,改进模型的检测平均精度提高0.62 个百分点,内存占用减少74.1 MB。本研究为大田环境下水稻稻穗的精准检测提供了一定的理论以及实践依据,为田间水稻无损估产奠定了基础。
尽管本文所提出的改进算法对大田水稻稻穗具有较好的识别效果;但还存在部分未能准确识别的稻穗,这是因为在数据集构造过程中,部分稻穗因遮挡无法被准确标注,同时本次试验所用数据有限,今后将进一步提升标注准确度和完全度,并扩大图像数据集,建立更具代表性、样本特征更为丰富的大田水稻稻穗数据库。
猜你喜欢
作文小学高年级(2023年2期)2023-03-13
青少年科技博览(中学版)(2022年6期)2022-12-27
军事文摘(2021年22期)2021-11-26
公民与法治(2020年20期)2020-11-27
文苑(2020年6期)2020-06-22
文苑(2019年22期)2019-12-07
作文评点报·小学三、四年级(2019年3期)2019-03-05
草原(2018年10期)2018-12-21
电子制作(2018年11期)2018-08-04
测绘科学与工程(2016年5期)2016-04-17
