
基于Prometheus的高校数据中心云计算平台监控系统研究
2024-01-14 06:35董东野田晓玲刘鹏飞
北京工业职业技术学院学报 2024年1期
罗 波 董东野 田晓玲 刘鹏飞
(1.北京工业职业技术学院信息工程学院,北京 100042;2.北京优特捷信息技术有限公司,北京 100102)
0 引言
随着云计算技术的快速发展,越来越多的高校开始采用云计算平台来支持各类教学、科研和管理工作。高校数据中心云计算平台作为高校的核心基础设施,承担着大量计算、存储和网络资源的管理及调度任务。为了确保云计算平台的可靠性、通用性和资源动态伸缩,需要对整个云计算平台的应用服务进行实时监控和管理。
1 云计算平台监控系统的研究
在监控系统中,最重要的就是采集应用程序运行的各项数据指标,这些指标能够说明应用程序在系统中资源占用的情况。例如,当请求数较高时,系统响应变慢,如果有请求计数指标,则可以确定原因并增加计算资源。基于Prometheus的监控系统具有高度可扩展性和灵活性,能够满足高校数据中心云计算平台的监控和管理需求。
1.1 监控的需求及选择
监控是生产环境必需的一部分,是稳定服务的基础。在高校Kubernetes容器资源管理平台中面临的监控需求:①合理的维护成本;②监控大量高动态的系统组件;③既要对单个组件、也要对整体区域的多个维度进行测量、分析和报警。
负责谷歌Borg集群管理系统的监控系统从自定义的脚本进化到Borgmon,提供了基于时间序列(Time-Series)的监控系统。Prometheus是一款开源的、基于谷歌Borgmon开发的监控和警报系统[1],具有高度可扩展性和灵活性,适用于大规模的分布式系统监控。高校Kubernetes容器资源管理平台源于谷歌的Borg系统,故Prometheus系统非常适合用于Kubernetes对Pod的监控。
1.2 容器的数据收集方法
在高校Kubernetes容器资源管理平台中,启用的业务大部分是以Pod的方式发布[2]。cAdvisor(Container Advisor)是一个用于监控和分析容器性能的开源工具,它可以与Prometheus等监控系统集成,提供容器级别的监控数据。
cAdvisor不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和http接口,方便Prometheus进行数据抓取,此外还可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况等。cAdvisor使用Go语言开发,利用Linux的Cgroups获取容器的资源使用信息。
1.3 采集数据的存储方法
Prometheus将所有抓取来的服务监控数据存储在内存数据库,定时到磁盘上进行数据检查(CheckPoint),将这些监控数据周期性打包到外部的时序数据库(Time-Series Database,TSDB)中。对于一个周期性1 min的检测任务,每次产生12 B数据,若106个时间序列数据需要存储12 h,则可以计算出所需的存储空间
图1所示为数据存储模型,主机1、主机2等分别表示每一个时间序列,每个点的数据存储格式是(Timestamp,Value),表示时间点和具体值,纵列串起来的是一个时间序列,由一个标签(Label)集合定义。

图1 数据存储模型图
监控数据时间序列存放如图2所示,时间序列(Time-Series)[3]被存储为(Timestamp,Value)序列,通常称为矢量(Vectors)。随着时间的不断推进,旧的数据会被忽略掉。

图2 监控数据时间序列存放图
存储数据的方式是一块固定大小的内存空间,称为时间序列空间(Time-Series Arena)。当这块内存空间满了之后,由回收者(Garbage Collector)回收最老的数据。通常情况下,空间会存储12 h的数据,底层服务存储的时间会更少。
2 运维监控平台设计
2.1 选择数据监控指标图
如图3所示,常见的云平台Prometheus数据监控指标可分为业务层监控、应用层监控、中间件及基础设施类监控和系统层监控。
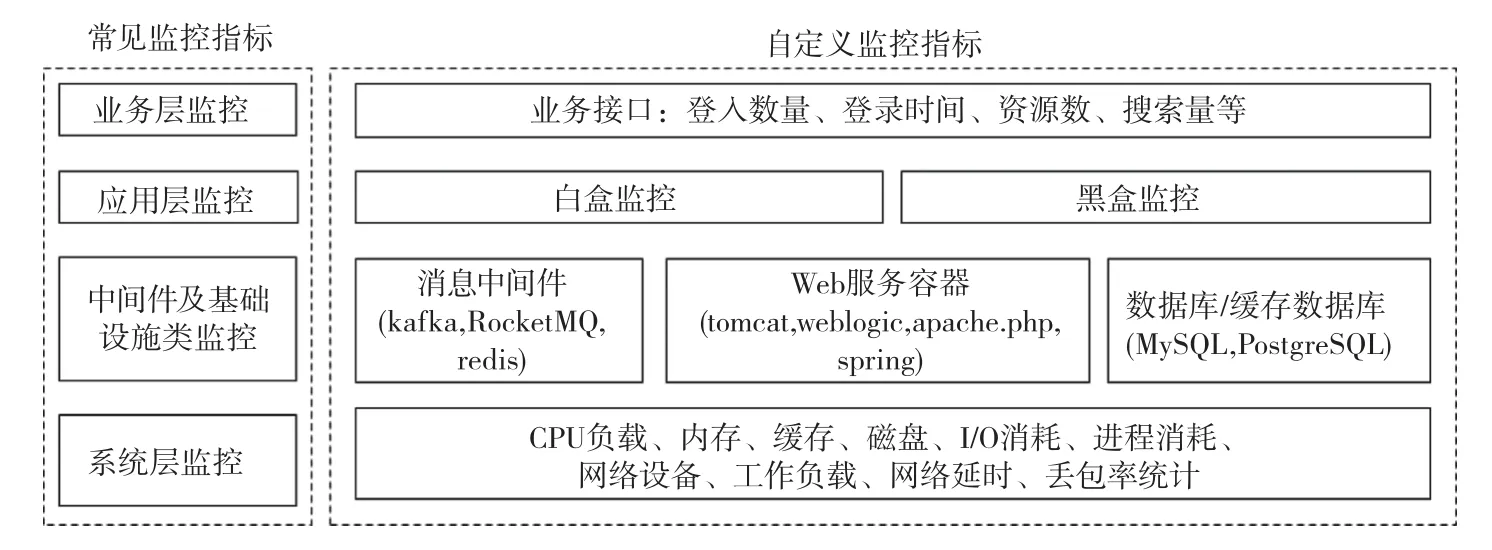
图3 Prometheus数据监控指标图
除了常见监控指标,还可以根据实验研究需要自定义指标,对常见的监控指标进行细化。通过Prometheus提供的客户端库,将自定义的监控指标推送给Prometheus进行数据采集,实时掌握监控指标的运行状态。
2.2 Prometheus组件及选择
如图4所示,Prometheus包含多个组件。根据作用不同,将监控系统设计为数据采集层、存储计算层和应用层三个部分,并自行选择组件。

图4 Prometheus生态组件图
监控系统中,数据采集层主要进行数据采集工作。Pushgateway组件是Prometheus的一个中间网管组件,类似于Zabbix的Zabbix-proxy,主要解决一些不支持主动拉取方式获取数据的场景问题。例如使用自定义shell脚本监控一些临时服务的健康状态,但这些shell脚本无法让Prometheus服务监控其运行的数据。具体解决方案是在shell脚本中,将临时服务的数据按Prometheus监控数据的格式主动推送到Pushgateway组件中,然后配置Prometheus server拉取Pushgateway。
存储计算层主要负责所有监控数据的存储。Prometheus的设计是由服务端主动拉取监控数据,并将数据根据配置的数据格式或标签进行转换、删除等操作,然后根据规则中配置的标识进行计算,按照计算结果发出告警或者不操作。以CPU使用率达到80%是一条告警规则为例,Prometheus对数据进行判断是否符合告警规则,符合就发送消息给应用层的Alertmanager组件,不符合就不操作。最后,Prometheus根据配置时间周期将数据保存到本地或第三方存储。
应用层实现整个集群的告警发送、分组、调度、警告抑制等功能。Alertmanager组件的作用是监听Prometheus服务发来的消息,结合自己的配置,如等待周期、重复发送告警时间、路由匹配等配置项,将消息发送给指定的接收者;Alertmanager组件还支持多种告警接收方式,如告警页、邮件、短信等。目前PrometheusWeb UI自带的组件在数据展示方面不太友好,一般平台使用Grafana组件展示Prometheus数据。Grafana支持Prometheus的PromQL语法,能够和Prometheus数据库交互,加上Grafana强大的UI功能,平台可以轻松获取很多好看的界面,调用已经做好的模板。
2.3 Prometheus部署实施
在现有高校云计算平台中进行Prometheus部署实施,采用Operator的方式。Prometheus的版本为0.7。
(1)在“kube-prometheus-release-0.7/manifests”目录替换镜像源

(2)在prometheus-service.yaml文件中进行修改

(3)在grafana-service.yaml文件中进行修改

(4)部署过程

(5)“kube-prometheus-release-0.7/manifests/” 目录下执行操作

平台执行上述操作,部署Grafana,Prometheus及node - exporter 组件,如图5 所示,在Kubernetes的集群中通过kubectl 命令查看service 的信息可知,在Kubernetes 集群任意节点使用“IP 地址:30090”或“IP 地址:30091”可以访问Prometheus或 Grafana。

图5 部署的监控组件图
2.4 自动发现机制
服务发现可通过第三方提供的接口来实现。Prometheus查询需要监控的静态配置数据,获取需要监视的目标列表,轮询这些目标获取监控数据。
自动发现机制便于使用者在监控系统中动态添加或者删除资源。在Prometheus监控系统中,file_sd_configs可以用来动态添加或删除目标(target)。
可以通过在scrape_configs添加如下配置,修改Prometheus配置文件。

files 表示文件的路径,文件为.yaml 或.json 格式,可以用通配符*.json,让Prometheus定期扫描这些文件并加载新配置。用refresh_interval 定义扫描的时间间隔,扫描以.json 结尾的文件。
target.json 文件包含的项与prometheus.yml 配置文件中job_name.static_configs 的项一致,用户可以为每组targets 加labels,便于告警分组、告警抑制时使用。
3 可视化展示工具Grafana
Prometheus负责时序型指标数据的采集及存储,而数据的分析、聚合及直观展示等功能都由Grafana负责。在平台中部署的Grafana组件,可以提供丰富的图表和仪表盘,将各种数据源中的指标数据进行可视化展示和分析,是一个开源的数据可视化和监控工具[4]。Grafana支持与多种数据源集成,包括Prometheus,InfluxDB,Elasticsearch,MySQL等。用户可以通过Grafana的Web界面创建和设计仪表盘,选择不同的图表类型、指标和时间范围,自定义仪表盘的外观和布局[5],把监控数据以图形化形式展示。Grafana支持实时更新数据,用户通过设置刷新频率,使仪表盘中的数据始终保持最新状态。此外,Grafana还提供了告警功能。用户可以设置告警规则,当指标数据达到或超过设定的阈值时,Grafana触发告警,发送通知给指定的用户或团队。如图6所示,通过Grafana,用户可以更直观地了解数据的趋势和变化,进行系统监控和性能分析。

图6 通过Grafana的W eb界面创建的仪表盘呈现图
4 业务压力测试
在高校Kubernetes容器资源管理平台中部署nginx业务容器,模拟业务入口,通过ab命令进行压力测试,业务压力上升,CPU指标增加。通过Grafana观察nginx业务容器CPU的趋势变化,并得到不同时间段的CPU资源占用率,如图7所示,Grafana显示的曲线图在时间点09:06:15时,Pod的CPU资源占用率达到了71.4%,已经达到告警的范围。后续的研究可以结合CPU资源占用率进行及时的告警处理。
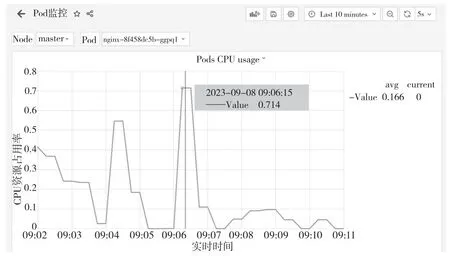
图7 不同时间段的CPU资源占用率图
5 结论
通过分析高校Kubernetes容器资源管理平台面临的监控需求,在高校数据中心云计算平台监控系统中加入Prometheus监控组件,实时监控云计算平台中的服务和节点运行状态,并将采集的数据存储到Prometheus的时间序列数据库。使用可视化展示工具Grafana对数据进行查询、分析,并通过业务压力测试证明了本文研究的可行性与普适性,可以在高校数据中心系统推广使用。
猜你喜欢
阅读(快乐英语中年级)(2022年11期)2022-05-30
能源工程(2022年2期)2022-05-23
疯狂英语·新读写(2021年10期)2021-12-07
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
读者·校园版(2019年24期)2019-12-10
新世纪智能(英语备考)(2019年4期)2019-06-26
铁道通信信号(2019年11期)2019-05-21
小朋友·聪明学堂(2015年8期)2015-11-30
太阳能(2015年11期)2015-04-10
