
基于分布式挖掘的支撑网告警关联规则处理技术
2024-01-14 02:25罗春艳万能
广东通信技术 2023年12期
[罗春艳 万能]
1 引言
随着移动通信网络规模的不断扩大,支撑网的告警种类、告警数量以及多源告警设备之间的告警信息也不断增加[1]。然而,在现有的告警事务数据中的关联规则只要依赖于专家经验,导致网络故障根因分析效率不高,精度时好时坏[2]。另外,在网络分布式环境下由于告警事务数据分布不均匀的问题,传统集中式关联规则挖掘方法很难确定最小支持度和最小置信度,从而使得关联规则方法在某些区域中效果显著,在某些区域中效果不理想。除此之外,传统集中关联规则采用专家经验设定的最小支持度和置信度也不适用于分布式环境下关联规则的制定。为此,本文提出一种基于分布式挖掘的支撑网告警关联规则处理技术,该技术通过贝叶斯深度学习的方法很好地解决了告警事务不均匀所导致的网络故障根因分析效率和精度的问题,利用局部模型获取的支持度和置信度分析全局模型中支持度和置信度分布,进而确定全局模型最小支持度和置信度,避免专家经验设定最小支持度和置信度所出现的效率不高和精度不高的问题。
2 相关方法
2.1 告警事务数据预处理方法
文献[3~4]认为相邻时间窗口的告警事务数据具有相似特征,因此在告警事务数据提取时,可以根据需求对告警事务数据进行压缩处理,从而降低告警事务数据的冗余性。然而,基于滑动时间窗口的告警事务数据提取方式虽然简单,但是也有很多不足,比如:滑动窗口假定数据告警事务数据分布是均匀的,并且在滑动时间窗口宽度确定的情况下,不同时间段所提取出来的告警事务数据质量存在不一致现象,因此,采用固定时间窗口宽度提取的告警事务数据通常存在数据质量不高的现象。
为了解决滑动时间窗口提取告警事务数据所带来的问题,研究人员采用聚类算法对告警事务数据进行预处理。该方法利用有用告警事务数据稀疏特性,将告警时间段具有强相关性特征的事务数据进行提取,并基于文本相似度对提取的事务数据进行聚合形成告警事务数据簇,大大降低告警事务数据提取所带来的数据冗余量过多的问题。告警事务数据预处理的流程如图1 所示。

图1 告警事务数据预处理流程
2.2 告警事务数据关联性分析
网络一种故障告警会引发多个设备告警行为,因此告警事务存储数据库中会存在数量非常庞大的告警信息。为了有效减少网络管理人员的工作量,通过分析告警事务数据关联性,结合关联规则构建告警关联规则库,并基于关联结果定位网络故障,实现告警事务数据的精准分析。
(1)基于文本相似度的告警事务数据聚合方法
为了解决不同设备所采集的告警时刻不一致问题,通常采用属性相似度分析的方法[2~4]来实现告警事务数据聚合。假设经过处理之后的告警事务数据可以用一个七元组进行表示其中,id表示告警事务数据的序号,timestamp表示告警事务数据的时间标签,src表示告警事务数据的源IP 地址,dst表示告警事务数据的目的IP 地址,mag表示告警事务数据的告警类别,sport表示告警事务数据的源端口,dport表示告警事务数据的目的端口。基于告警属性(除时间标签外)的相似度计算告警事务数据的整体相似性。
γij表示两个告警事务数据的数据之间的相似性,告警事务数据采用七元组类似文本的方式进行处理,进而采用余弦相似性的方式来衡量告警数据之间的相似度。表示第i 个告警事务数据的数据,表示第j 个告警事务数据的数据。结合公式1 衡量告警事务数据库中两两告警事务数据的相似性,如果相似性大于设定的阈值γθ,那么将两个告警事务数据进行聚合,聚合的方式通常随机删除的方法对高相似度的告警数据进行剔除,进而降低告警事务数据的冗余度。
(2)基于关联规则匹配的告警事务数据处理
在对告警事务数据进行合并后,传统方法采用关联规则来处理告警事务数据序列,并基于告警事务数据序列挖掘k-项集,结合设定的支持度和置信度挖掘告警事务数据的频繁k-项集,产生告警关联规则。
如果k-项集支持度满足支持度阈值,那么集合X 称为D 的k-项集。
其中,support(X)表示项集X 的支持度σX表示数据集D 中包含项集X 的数量,D 表示数据集中总的项集数量。(3)
其中,confident{D⇒X}表示频繁项集X 的置信度,置信度是衡量告警事件事务数据发生的条件概率的稳定性程度。
传统的方法是通过人工的方式设置支持度阈值和置信度阈值,当support(X)大于设定的支持度阈值时且confident{D⇒X}大于设定的置信度阈值时,则项集X 为频繁项集。
基于公式2 和公式3,可以从告警事务数据集D 找出满足要求的频繁项集。
(3)基于LSTM 的告警故障类型识别与定位
由于告警事务数据涉及不同的告警信息,通过机器学习将告警信息的特征与故障类别进行相关性分析,实现告警故障的自动识别。目前告警故障类型识别模型有很多,包括支持向量机[5~6]、贝叶斯模型[7~8]、随机森林[9~10]、BP神经网络[11~12]等。这些模型都是将经过关联规则分析的历史告警事务数据的序列与人工经验设定的故障类型标签建立相关模型后,然后模式匹配的方式实现告警故障类型的预测。如果经过关联规则分析的历史告警事务数据序列中蕴含了n 项告警,在对应的检测窗口中n 项序列与待预测的经过关联规则分析的告警序列相匹配,那么就能够实现告警故障类型识别;最后,基于告警故障类型发生的告警位置确定故障所在的位置。
然而,如何设置合理的支持度阈值和置信度阈值是告警事务数据处理的关键问题,因为合理的支持度阈值和置信度阈值直接影响频繁项集的数量,也会直接影响告警故障类别识别的准确率。因此,本文基于分布式挖掘的方法挖掘告警关联规则。也就是采用贝叶斯深度学习的方法实现频繁项集支持度和置信度进行分布估计,从而为频繁项集支持度阈值和置信度阈值的设定提供数据基础。
3 基于分布式挖掘的支撑网告警关联规则分析
随着网络规模的迅速扩大以及云计算大数据技术的快速发展,大规模数据的存储、实时分析成为可能。然而,当前的移动通信支撑网是2/3/4/5G 共存的异构网络,网络的分层异构特点使得传统的集中处理告警数据方法难以满足现有实时分析的要求,因此,分布式挖掘方法成为支撑网告警数据实时分析的重要诉求。
传统的分布式挖掘方法通常采用缩小增量学习[13~15]和共享式投票的分布式算法[16~17]实现告警频繁模式建模,这些方法虽然能够对分布式的数据进行实时学习,然而没有从全局的角度考虑数据样本分布的情况,因此在构建告警关联规则模式时有可能因为数据分布差异问题导致模型精度不高。为了解决数据分布差异问题,本文采用贝叶斯深度学习的方法实现告警关联规则分布的估计,也就是基于所获得的频繁项集后,从全局的角度采用贝叶斯深度学习的方法对频繁项集支持度和置信度进行分布估计,从而获得全局角度下频繁项集的支持度和置信度,实现中心模型的构建,具体的流程如图2 所示。
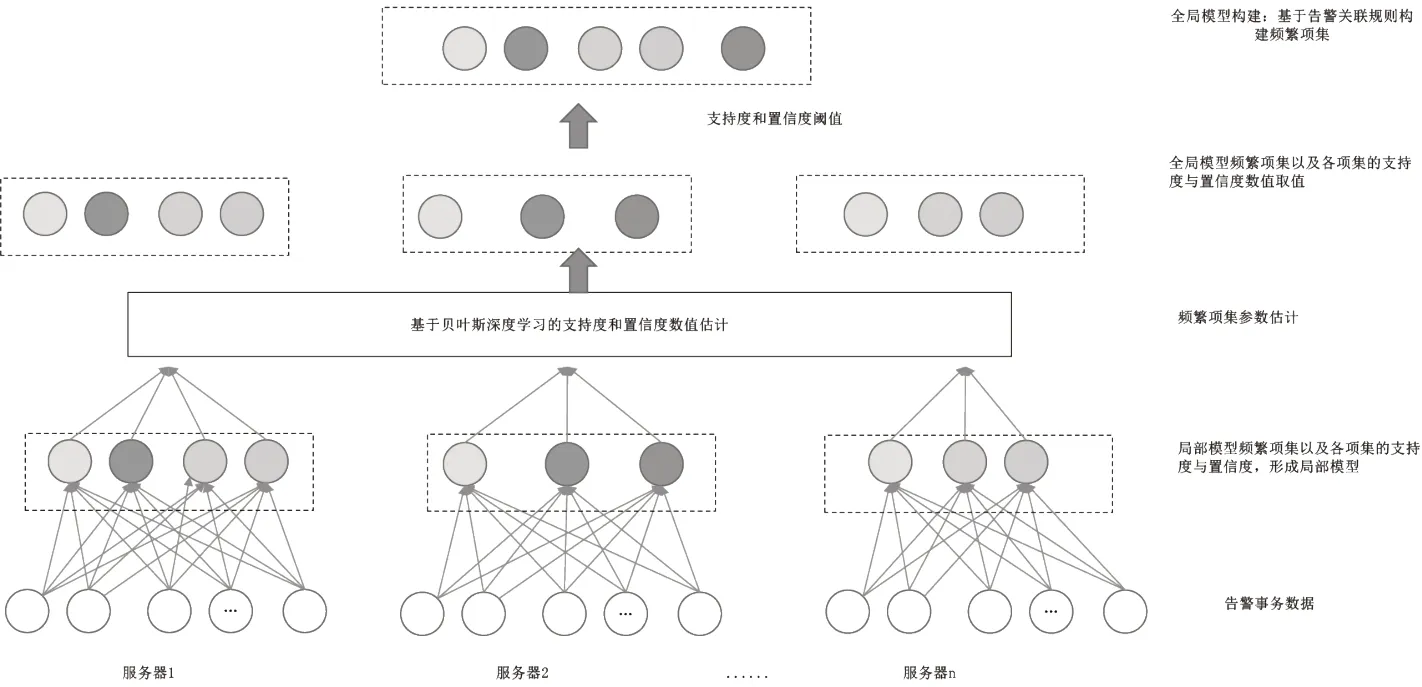
图2 基于分布式挖掘的支撑网告警关联规则分析流程
3.1 局部模型训练方法
本文采用聚类算法和滑动时间窗口算法对告警数据进行过滤后,对网络中发生频率较低、持续时间短的颤动告警数据进行提出,减少告警事务数据中的“噪音”,为告警事务数据的频繁项集提供良好的数据基础。
在此基础上,本文采用基于文本相似度告警信息聚合,进一步压缩数据量。考虑到告警故障将会在特定的时间段产生大量的告警事务数据,虽然每一个告警设备产生的告警事务数据在时间上具有一定的差异性,但是从告警事务数据分布来看,各个设备所产生的告警事务数据在相似时间段会产生相似类型的告警属性数据。基于上述的分析,假设经过处理之后的告警事务数据采用文本相似度的告警信息相似度衡量公式为:
告警事务信息整合后,采用关联规则的方法获取不同区域支撑网的告警事务项项集以及各项集的支持度和置信度,形成局部模型。
3.2 基于贝叶斯深度学习的支持度和置信度数值估计
贝叶斯深度学习的思路是把参数分布作为神经网络的输入,然后通过反向传播优化贝叶斯深度学习神经网络的权重,从而确定参数的最终分布;结合参数分布确定参数的取值范围,为全局模型的构建提供数据基础。基于贝叶斯深度学习的参数估计过程如图3 所示。
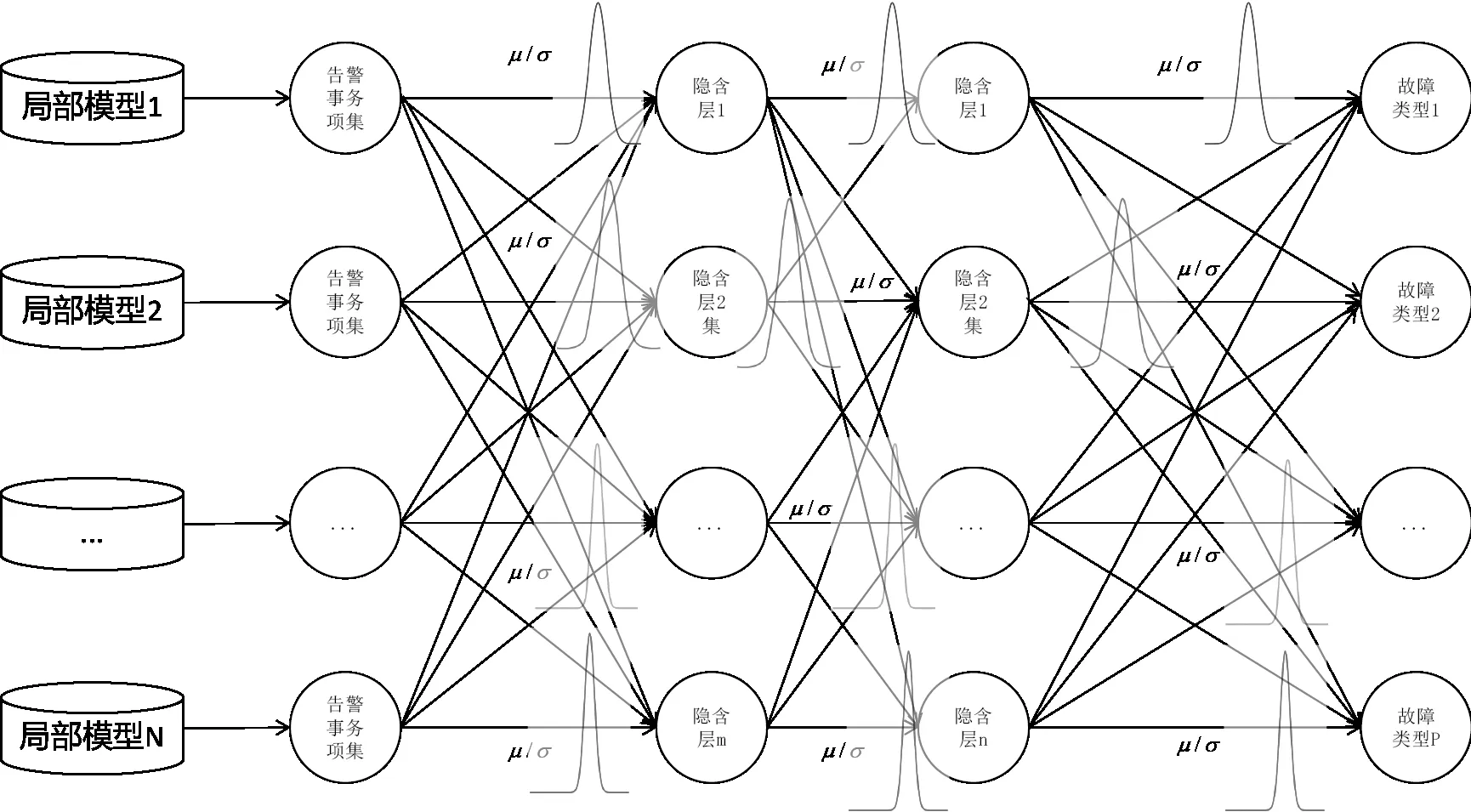
图3 基于贝叶斯深度学习的参数估计过程图
假设某一个局部模型的告警事务项集和故障类型训练集为D 为{xi,yi},第i 项告警事务项集的支持度服从均值为μi,方差为δi的高斯分布基于贝叶斯深度学习的损失函数为:
其中,δ1、δ2、δ、π是超参数,需要提前设置。ypred是基于告警事务项集所得出的故障类型的预测值,yj表示基于告警事务项集所设定的故障类型的标签值。
在局部模型频繁项集产生的基础上,结合支持度和置信度分布确定最小支持度和最小置信度(假设第i 项告警事务项集的支持度取值大于1 倍标准值),以此筛选满足条件的告警频繁项集后,得到全局模型的所有频繁项集。
3.3 基于LSTM 预测故障类型和故障概率
采用LSTM(Long Short Term Memory,长短记忆)神经网络预测故障发生的概率,输入由告警事务项集,经过多个隐含层实现告警故障类型以及告警故障概率。
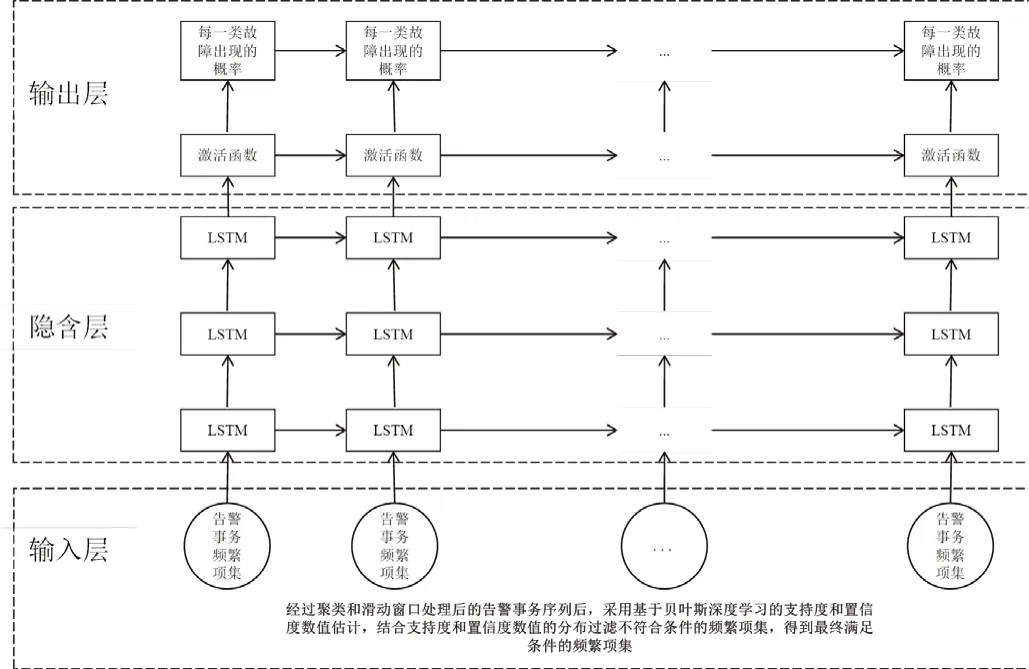
图4 基于LSTM 预测故障类型和故障概率流程图
4 实验分析
实验采用某地市2020 年1~9 月的部分告警数据共768 035 条,未发生告警数据共359 025 821 条,从上述告警数据和未发生告警数据中提取30%作为测试数据集对模型的验证,剩下的70%作为训练数据集对模型参数进行计算。
首先经过聚类和滑动窗口处理得到合并后的告警事务序列后,分别采用本文的方法和共享式投票的分布式算法实现告警类型和各类型发生概率的预测。
本文算法思路是:基于贝叶斯深度学习的支持度和置信度数值估计后,结合支持度和置信度数值分布过滤不满足频繁项集得到满足条件的频繁项集后采用LSTM 实现告警类型和各类型发生概率的预测。
共享式投票的分布式算法是将局部模型进行加权平均后获得全局模型频繁项集支持度和置信度数值,结合最小支持度(通常大于支持度均值)和最小置信度数值(通常大于置信度均值)过滤不满足频繁项集得到满足条件的频繁项集后采用LSTM 实现告警类型和各类型发生概率的预测。
基于上述两种不同的方法,得到满足k-繁项集的数量对比如表1 所示。
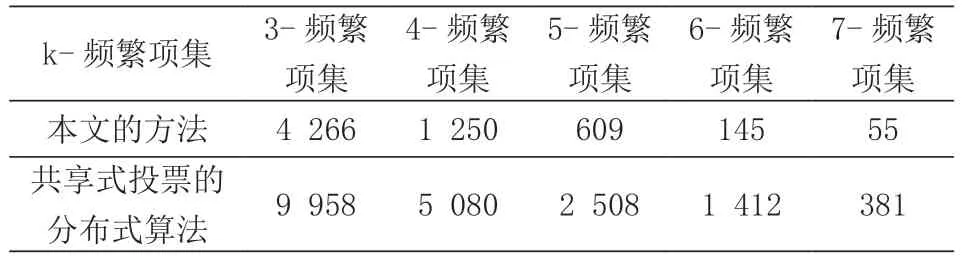
表1 k-频繁项集的数量对比
在获取频繁项集的基础上,分别将上述的频繁项集输入到LSTM 中,得到模型的准确率和召回率对比如表2所示。
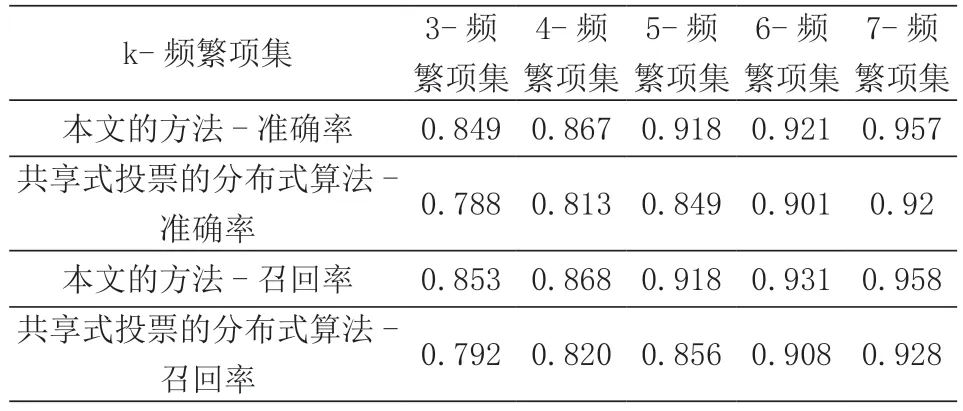
表2 k-频繁项集输入到LSTM 的准确率
由此可知,基于贝叶斯深度学习算法所获得的支持度和置信度分布后,基于分布过滤满足条件的频繁项集用于网络故障预测的准确率和召回率均比共享式投票的分布式算法高,这是因为贝叶斯深度学习对频繁项集支持度和置信度的分布进行估计后,能够从全局的角度考虑支持度和置信度的数值范围,并基于统计角度来获取最小支持度和置信度(大于1 倍标准值),而共享式投票仅仅采用加权平均的方式获得最小支持度和置信度,这种方法将所有局部模型的重要性视为一致,而没有考虑不同局部模型数据分布不一致的问题,因此在准确率和召回率(特别是项集数量较小的情况下)较低。
5 结束语
本文针对现有关联规则挖掘的方法没有考虑到分布式环境下数据量和数据分布存在的问题所导致关联规则效率和精度不高的问题,提出了一种基于分布式挖掘的支撑网告警关联规则处理技术。该技术通过聚类算法和滑动窗口对告警事务数据进行预处理,找出一个告警事务数据密集集合,并通过滑动窗口找到相似时间发生的告警,从而形成告警事务数据存储库后,采用贝叶斯深度学习的方法实现告警事务频繁项集支持度和置信度数值分布的估计,从而为分布式环境下告警事务数据分布式挖掘提供了科学的数据基础,形成了告警事务关联规则库。最后,采用LSTM 的方法挖掘预测故障类型和故障概率,实现告警预警。实验表明,本文所提出的方法在实际应用中验证了技术的可行性,可为分布式告警预测提供理论支撑。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
计算机应用(2018年5期)2018-07-25
轴承(2015年2期)2015-07-25
计算机工程(2014年6期)2014-02-28
长春大学学报(2013年8期)2013-06-21
电讯技术(2011年11期)2011-04-02
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
