
基于极值分析的钻井参数刺峰噪点数据识别研究
2024-01-14 02:33:38梁欣怡刘世杰柴晓武
录井工程 2023年4期
宋 涛 陈 添 梁欣怡 田 宇 刘世杰 柴晓武
(①中国石油渤海钻探第一录井公司;②中国石油渤海钻探工程技术处;③中国石油长庆油田分公司第一采油厂)
0 引言
石油天然气钻探过程中,确保优快安全施工是非常重要的工作。为此,在钻井施工中,井场部署综合录井服务,通过诸多传感器实时感知钻井作业过程中各环节的物理量,获得大量实时钻井参数数据,用于实时反映钻井作业的各种工况。通过对钻井参数数据的实时在线智能分析,可以自动探测到萌芽中的异常,并及时向钻井操作人员发出预警信息,为钻井优快安全施工提供有力保障。
综合录井仪钻井参数记录系统以一定的频率采集并记录相关传感器测量的数据信息,采样周期通常为1 s 或5 s,因此钻井参数数据具有时序性和间断性的特点。钻井参数源自钻井现场各类传感器的实时记录,受钻井现场的复杂性、传感器的灵敏性等多方面因素影响,各个传感器所测得的钻井参数数据会随着时间的推移而呈现出数值波动,有时也会产生较多明显的异常离群数据点[1]。这些明显的异常离群数据点在曲线中偏离正常波动趋势过大,表现为显著不同于其他数据分布的数据对象[2],本文称其为刺峰噪点数据。
钻井异常事故的智能化报警主要依托于对单项或多项钻井参数变化趋势以及各项参数之间协同变化趋势的分析,刺峰噪点数据会对参数曲线上升或下降变化趋势的分析产生严重干扰。若钻井参数数据中仅有极少噪点数据,对智能化报警系统的整体准确预警不会有较大影响,但事实上,受钻井现场的诸多复杂因素影响,这类刺峰噪点数据时常产生,数据质量问题较为突出,可能导致智能化报警系统错误报警,有效识别并剔除这些刺峰噪点数据,对于钻井施工过程中智能化报警系统等大数据智能诊断具有重要作用。因此,研究并应用新的大数据噪点数据识别技术具有非常重要的意义。
1 刺峰噪点数据识别研究现状
本文探讨的刺峰噪点数据是指在各钻井参数曲线中出现的明显向上或向下突变,超出大多数数据波动范围的尖峰状数据点,且在该类数据点的一定邻近时间内未出现与之相类似的数据点,换言之,即为钻井参数曲线上与大多数数据都不相邻的孤立的数据点。刺峰噪点数据有两个显示特征:一是其波动幅度比其他大多数数据的波动幅度都大;二是刺峰噪点数据在邻近一段时间内未频繁出现,数据点相对孤立。如图1 所示,图中蓝色方块数据点即为典型的刺峰噪点数据。
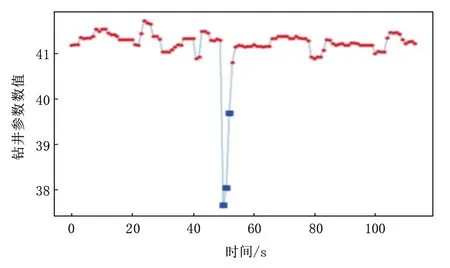
图1 典型的刺峰噪点数据
钻井参数曲线的散点分布形式多种多样,同样钻井参数中的噪点数据也是多种多样,导致实际工作中难以准确、全面识别所有噪点数据。因此,本文仅致力于解决相对明显的刺峰噪点数据,对于其他界定模糊的噪点数据则不做深入研究。图2中所示的蓝色方块数据点不能识别为刺峰噪点数据,原因在于类似数据点频繁出现,可能是钻井现场某种真实信息的客观反映,若将该类数据点直接剔除,可能会增大钻井参数数据失真的风险。

图2 钻井参数散点图
异常值或离群点数据分析是机器学习领域经常遇到的问题。拉依达法、格鲁布斯法、肖维勒法等方法均采用均值或方差以统计学方式识别常规型异常离群噪点数据[2-3];岳峰等[4]使用基于数据密度分布的方式有效检测聚类边界点数据;刘帆[5]使用深度学习方法识别并去除图像中的噪声。在石油钻井领域,对钻井现场的环境噪声治理与研究较多,但对钻井参数离群噪点数据研究很少。本文以钻井参数为样本,借鉴前人的方法经验[1-13],对基于极值分析的钻井参数刺峰噪点数据识别方法进行探讨研究,以供业内技术人员参考。
2 刺峰噪点数据识别
一般来讲,对于一组离散样本数据集,在数据正常趋势线附近的离群刺峰噪点数据首先是偏离正常趋势范围的极值数据。因此,基于极值分析的钻井参数刺峰噪点数据识别方法,首先研究筛选离散数据样本的极值集,然后在极值集的基础上进行离群噪点识别,并进一步对噪点附近的数据进行再识别,剔除正常数据点,最后形成噪点数据集并标记。
2.1 极值点算法分析
通过钻井实时数据分析发现,若干个连续时间的采样点上表现为上升或下降趋势波动,之后发生相反趋势波动,即使是较小幅度的变化也会表现出上升或下降的曲折波动。在连续的数据曲线中,波峰或波谷即为函数的极大值或极小值。钻井参数曲线的波动情况也与之相似,图3为某井某项钻井参数在近1 min内的波动曲线,其中由黑色实线串连在一起的黑色散点为采集的钻井参数数据,红色圆点为曲线中分段波峰极大值点,绿色圆点为分段波谷极小值点,蓝色虚线为极大值与极小值的串连线。该图中黑色的原始钻井参数曲线相对较平缓地上升或下降,波动较小。曲线中的各钻井参数极大值点与极小值点是曲线局部波动的上限和下限,并且由较少极值点串连的蓝色虚线所反映的曲线趋势同原始曲线的趋势相同。由此可见,参数曲线中钻井参数极值点是曲线波动的边界,参数曲线可反映变化趋势,其数据分析具有同等价值。

图3 钻井参数波动曲线
通过分析可知,刺峰噪点数据的波动幅度常大于正常极值点数据的波动幅度,故本文所研究的刺峰噪点数据识别以极值点数据集为基础,且对于常规离散点数据而言,满足公式(1)则为极值点:
式中:ni为某一常规离散点数据;ni-1为ni前一个点的数据;ni+1为ni后一个点的数据。
但离散点数据还可能存在两个数据点相等的情况。如与图3 对应的极值数据统计(表1)显示,11:45:09 数值为9.2,至11:45:10、11:45:11 两个数据点均为9.3;至11:45:14数值降为9.1后,连续出现两个相等的9.0,至11:45:19 出现极小值8.7。对于钻井参数曲线中多个连续相等的数据点,本文取最后一个上升或下降的拐点值为极值点,如表1 中11:45:23的8.8为极大值。
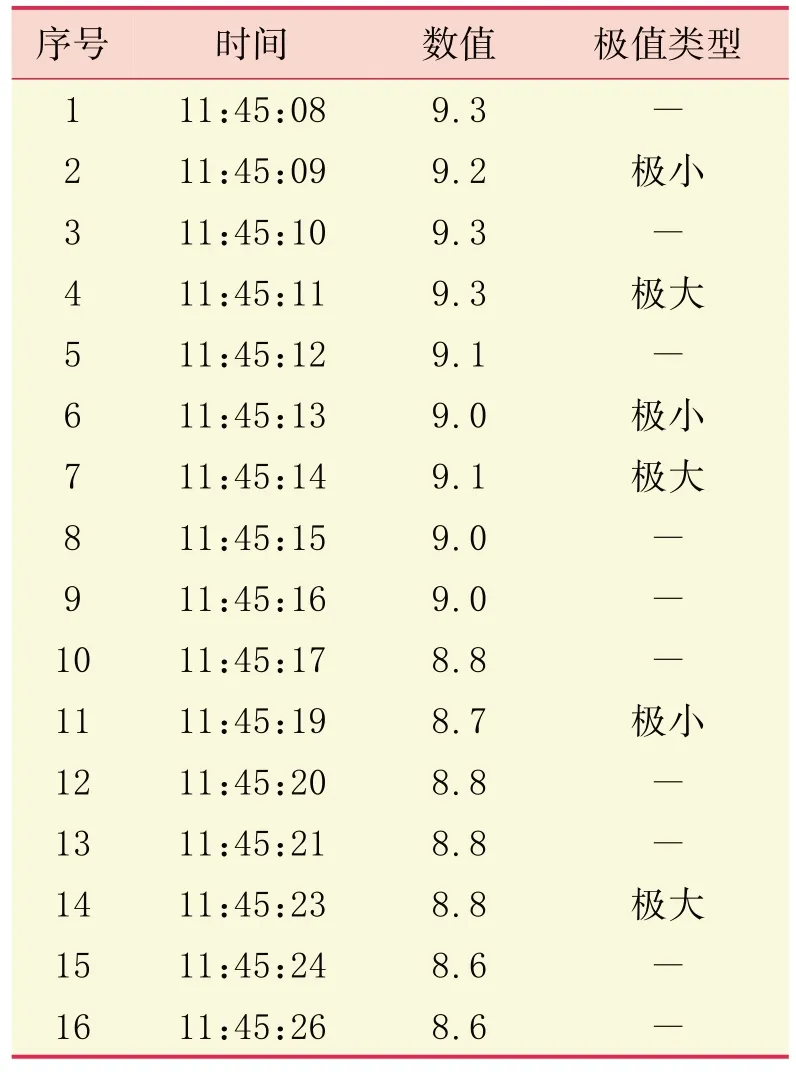
表1 极值数据统计(对应图3)
依据以上分析,极值点集可依据公式(1)采用计算机编程快速自动判断识别建立。
2.2 刺峰噪点数据识别算法研究
刺峰噪点数据识别过程首先是识别极值点集,进而识别噪点数据。噪点数据的识别基于实际的钻井参数数据极值点来分析,先对噪点的特征进行分析,区分出特殊情况,为计算机算法提供理论依据,最后列出计算机可编程噪点识别的数学逻辑算法。
2.2.1 刺峰噪点数据特殊情况分析
通过分析大量由于噪点数据影响而造成的错误处理结果,总结出噪点数据的总体特征为:曲线噪点数据的波动幅度远大于大多数正常极值点数据的波动幅度,远离主拟合趋势线,且曲线的噪点数据波动幅度与曲线数据原值呈一定的比例。
但在实际散点曲线中,也存在如图4 所示的特殊情况,即数据波动幅度虽然大,但仍属于正常数据曲线波动。图4中红色圆点为曲线中的极值点,从第8 s到第12 s 之间,钻井参数数值由6.66 下降至5.15,其波动幅度比邻近极值点的波动幅度大出许多,但这种曲线波动属于因作业工况调整引起的数值正常波动,该类波动幅度大的数据点不能作为噪点数据处理。
图5给出了另外一种特殊情况,直观可见:虽然第8 s 的数据点值90.41 的波动幅度比两侧数据点值90.02 大出许多倍,但从纵轴上看,其波动幅度仅为0.39,处于数据原点90.41 变化的1%之内。该类数据点相对其附近数据点的波动幅度有些异常,但波动幅度与数据点原值相比非常小,且当曲线时间窗口拉长后,这类波动并无明显异常,因此这类相对原值波动极小的数据点不应看做噪点数据。
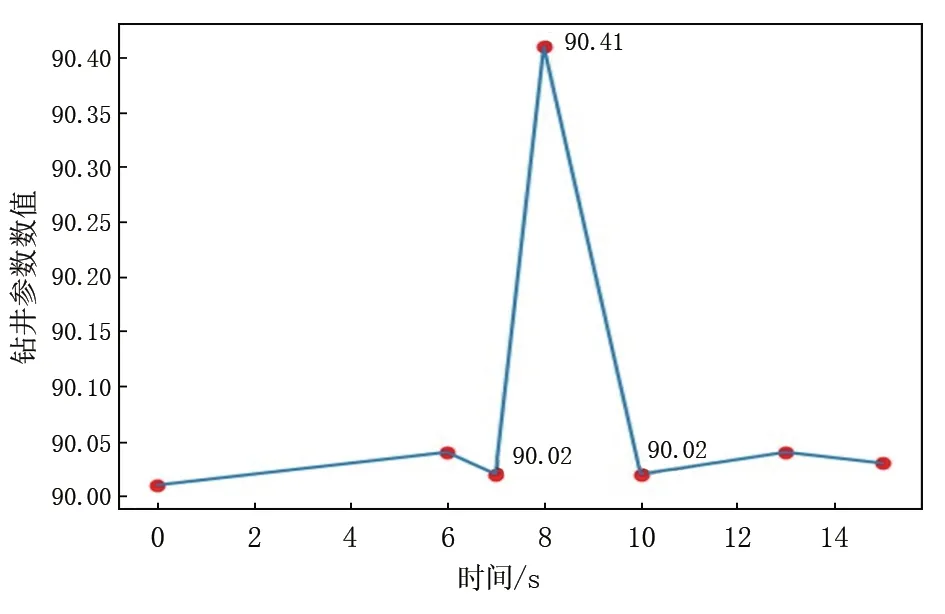
图5 正常数据波动幅度图
2.2.2 刺峰噪点数据识别算法
钻井参数极值刺峰噪点数据识别基本思路为按照专业技术人员对噪点数据的常规认知算法,通过添加约束条件,将正常数据点(含正常极值点)剔除。具体做法是:首先按照公式(1)先识别出极值点,然后将每个极值点假定为极值噪点数据,设定相关约束条件检测其是否符合极值噪点数据特征,如果符合再将相关约束条件应用于该极值点两侧的非极值点数据(范围限定在检测极值点到两侧最邻近的不同类型极值点之间的数据点),最后将满足约束条件的数据点标记为噪点数据。
图6 为某井钻井参数数据极值点曲线,数据点i处的时间横轴x值为xi、钻井参数数值纵轴y值为yi;假定钻井参数数值y变化幅度大的极值点为噪点(noise),噪点与左、右两侧不同类型极值点x、y的差值分别看作微分量dx1、dx2与dy1、dy2;为区分钻井参数曲线整体横纵轴的波动幅度,记在一定时间段(interval)内钻井参数曲线两两相邻不同类型极值点的差值由小到大排序后的横、纵轴的中位数分别为dxm、dym。
极值噪点判别约束条件如公式(2)所示,式中α、β、γ、η均为待设定的超参数。公式(2)中:不等式①是对刺峰噪点数据在水平、垂直两个方向上波动幅度的限制,α是刺峰噪点数据与曲线整体在垂直方向上波动幅度的比例关系,β是曲线波动的时间间隔;不等式②是刺峰噪点数据特征的形式化表示,γ是刺峰噪点数据的波动幅度占钻井参数数值本身的百分比,因此γ的取值比较小,结合实验可判定,γ取值为1%~5%时较为合理;不等式③是针对图5 中的特殊情况所做的约束,η是刺峰噪点数据左、右两侧的波动比例,刺峰噪点数据的特征为左、右两侧的波动幅度近似,η取值2~3为合理范围。
2.2.3 噪点附近非极值噪点识别算法
非极值噪点数据判别以图7 为例来说明。图7 中红色圆点和蓝色方块为曲线中的极值点,绿色和蓝色三角表示由最底部极小值到两侧极大值逐渐上升的中间过渡数值点。通过公式(2)的条件约束,可以识别出蓝色方块极值点为极值刺峰噪点数据;显然,刺峰噪点数据右侧的蓝色三角形数据点同样为异常噪点数据,但接近曲线主趋势线的绿色三角形数据点则不应被归属于噪点数据。通过大量实验得出:极值刺峰噪点ni(noise(xi,yi))左、右两侧相同时间窗口范围(图7 中虚竖线所限定的区间)内,最接近刺峰噪点的极值点k(limit(xk,yk)),最具有参考性,取为参考约束点limit,围绕该点增加约束条件即可较好地划分出噪点与正常数据点。记极值刺峰噪点y值为ynoise,参考约束点的y值为ylimit。公式(3)给出了极值噪点数据到邻近不同类型极值点之间数据是否为噪点数据的划分约束条件。
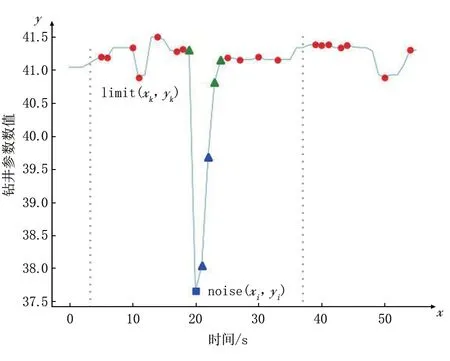
图7 噪点数据波动曲线
Extreme noise neighbor s.t.
公式(3)中ϕ、λ均为待设定的超参数(ϕ表示噪点数据到邻近约束点距离与曲线整体的波动比例,λ表示检测数据点到约束点距离与被检测的极值点波动的比例)。除此之外,搜索极值噪点左、右两侧同类型极值limit约束点的时间范围也是一个超参数,时间窗口越大,参考的范围越宽,反之则越窄。公式(3)中不等式④是针对极大值噪点的设定,不等式⑤是针对极小值噪点的设定。
通过公式(2)约束条件可以判定极值点是否为噪点数据,通过公式(3)约束条件可以判断极值点两侧的非极值点是否为噪点数据。为进一步避免错误识别,可对已识别的噪点起止点时间间隔再次约束,以避免较长时间的上升或下降。整个钻井参数噪点数据识别算法流程如图8所示。

图8 钻井参数噪点数据识别算法流程
3 噪点数据识别准确性实验评估
3.1 噪点数据识别超参数设定
钻井参数噪点数据波动幅度与正常数据的波动幅度差异悬殊,二者波动幅度的比例关系在噪点数据识别中非常重要,这涉及超参数α、β的设定。通过对曲线中含有刺峰噪点的两两相邻的极值点横、纵坐标的差值进行分析,显示出刺峰噪点数据y值差值异常大于其他极值点y值差值,x值差值则相对稳定。分析大量含刺峰噪点数据曲线样例,结果表明,仅出现个别刺峰状异常离群噪点的现象较为普遍,如图9a所示某口井的钻井参数曲线。图9a 蓝色方块数据点为噪点数据,图9b 为图9a 的相邻极值点差值分析结果,蓝色、绿色散点分别为相邻极值点y、x值的差值绝对值排序分布。
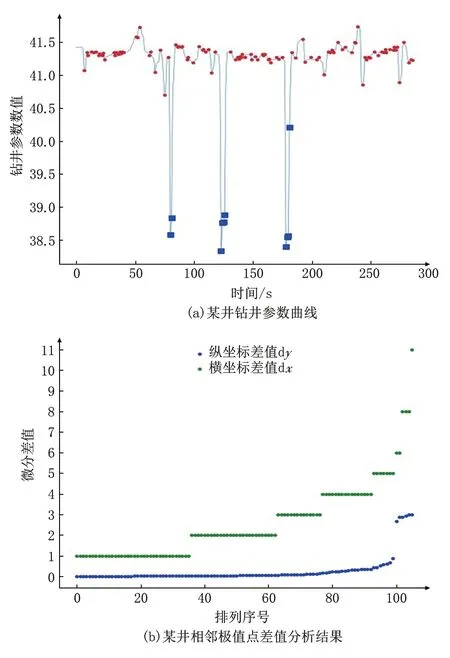
图9 钻井参数噪点数据波动分析图
图9b 显示极值点y值波动幅度(蓝色散点),只有极少噪点数据的波动幅度大于2,大部分非噪点数据的波动幅度均接近于0,二者的比例关系即为公式(2)中的超参数α;绿色散点为离散的整数,逐渐地上升并减少,表明各个极值点上升或下降的时间间隔多数在5 s 以内,连续8 到10 个数据点上升或下降的曲线片断很少。经多次实验验证,α取值8~15 为合理范围,极值点两侧的总时间间隔β取值10~20 为合理范围。在运算的最后,依然还会对噪点数据的起止时间间隔再次约束,所以β可以适当设置大一些。
通过大量钻井参数数据案例测试分析,得到刺峰噪点数据识别准确率较高的一组超参数,即:α=9、β=16、γ=2%、η=3、ϕ=4、λ=0.2。搜索极值噪点数据左、右两侧同类型极值(limit)约束点的时间范围是25 s,噪点数据起止时间间隔约束小于7 s。
3.2 噪点数据识别准确性评估
为评估刺峰噪点数据识别准确率,随机抽样30口井某一天24 h 的扭矩、立管压力、总池体积、入口流量、出口流量共5 种钻井参数数据,将24 h 划分成5 min为一个时间窗口,把上述超参数应用于图8算法中,识别钻井参数刺峰噪点;再将识别到含有噪点数据的5 min 钻井参数数据绘制成曲线图,并标记噪点数据,然后随机抽样200 张噪点数据图片(图10),请专业钻井技术人员评估,准确率达82%以上。

图10 钻井参数噪点数据波动分析图
噪点数据的准确性与数据的质量有很大关系,不同的钻井参数应该有不同的约束条件。从30 口井5种钻井参数噪点数据召回统计(表2)可以看出,出口流量的噪点数据召回量最大,达到1 630 个,也印证了钻井现场技术人员的普遍经验认知,即出口流量数据质量较差,与井场实际情况相符。
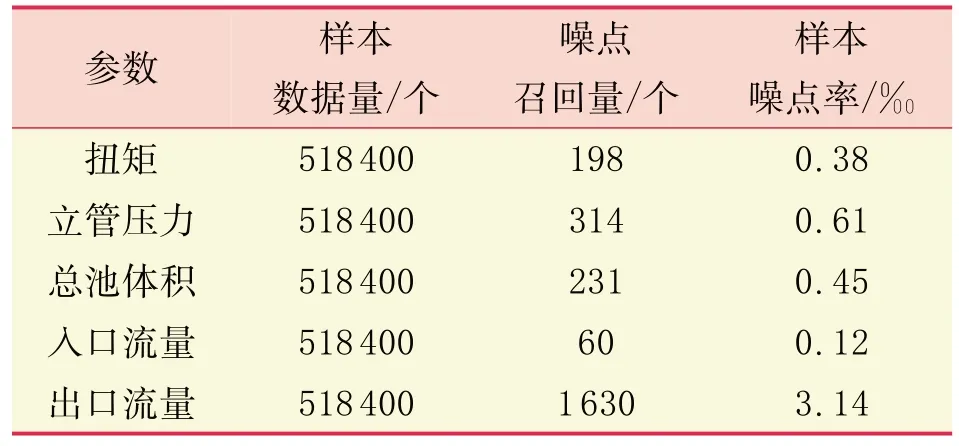
表2 30口井5种钻井参数噪点数据召回统计
4 结论
针对钻井参数曲线中的噪点数据识别问题,本文探讨并给出了以极值为基础的刺峰噪点数据识别算法,该算法以刺峰噪点数据在曲线中呈现的特征为判断标准,并给出了可编程的算法数学公式。通过数学算法和计算机流程图,首先建立极值点数据集,再识别极值点是否为噪点数据并建立约束条件,进一步将约束条件应用于极值点两侧的非极值点,最后整体识别极值点及其两侧的数据是否为噪点数据。
该算法经过大量现场试验数据验证和评估,具有很高的准确度。因此,本文提出的基于极值的钻井参数刺峰噪点数据识别算法可应用于钻井现场实际数据分析汇总,也可应用于类似的工程作业数据分析诊断。
猜你喜欢
新世纪智能(数学备考)(2021年10期)2021-12-21 06:20:38
摄影之友(影像视觉)(2020年4期)2021-01-09 10:10:10
河北理科教学研究(2020年3期)2021-01-04 01:49:40
中学数学杂志(2019年1期)2019-04-03 00:35:46
宇航计测技术(2018年3期)2018-09-08 02:21:24
制导与引信(2017年3期)2017-11-02 05:17:02
摄影之友(影像视觉)(2017年3期)2017-04-28 02:34:31
制造业自动化(2017年2期)2017-03-20 14:26:17
摄影之友(影像视觉)(2016年5期)2016-09-13 02:37:47
天津师范大学学报(自然科学版)(2015年2期)2015-03-11 18:46:52
