
融合卷积神经网络和Transformer的人脸欺骗检测模型
2024-01-13 06:45何希平杨楚天旷奇弦
信息安全研究 2024年1期
黄 灵 何希平,2 贺 丹 杨楚天 旷奇弦
1(重庆工商大学人工智能学院 重庆 400067) 2(检测控制集成系统重庆市工程实验室(重庆工商大学) 重庆 400067)
人脸欺骗检测也称为人脸反欺骗(face anti-spoofing, FAS)[1-3]技术,需要针对同一张人脸图像准确识别其是真实人脸还是被攻击过的伪造人脸(如打印照片、视频重放、3D面具等).FAS在提取图像特征时更关注图像的全局细节信息是否符合人脸的自然属性,其中蕴含的细节变化是应该重点获取的特征信息.因此,在保持全局和局部特征提取能力的前提下实现参数量和准确度的平衡至关重要.
基于CNN的方法在人脸欺骗检测领域因其较强的局部感知能力而比较适合应用在端设备的视觉任务中,这类方法已经取得了很好的进展:2020年,Parkin等人[4]从RGB视频创建人工模式,使用包含较少身份和细粒度特征的中间表征提高模型对未知攻击以及未知种族的鲁棒性;2021年,George等人[5]提出一个新的跨模态的焦点损失函数,将RGBD通道与该损失函数结合从而调节不同通道的置信度;2022年,Yu等人[6]针对现有单模态和多模态FAS方法可能存在冗余和低效问题,训练了一个可以在各种模态场景下灵活部署的统一模型;同年,文献[7]通过多种模态信息互补逐步过滤欺骗样本.尽管基于CNN的这些模型都实现了很好的性能,但由于在提取图像特征时只能局部感知,无法实现全局特征的相关性交互,有一定的局限性.
视觉Transformer(visual transformer, ViT)[8]近2年在视觉领域十分火热,但是其在人脸欺骗检测上的应用较少.2021年,George等人[9]第1次使用Transformer进行演示攻击检测;2022年,Huang等人[10]采用Transformer作为主干模块,并使用多层感知机(MLP)头进行分类预测,以解决人脸反欺骗问题.虽然Transformer在性能方面效果显著,但是也存在计算成本较高、收敛慢且很难训练的问题.为了能够同时提取全局和局部特征,并且缓解CNN和Transformer的缺点,许多研究者开始探索两种模型的融合.2021年,Mehta等人[11]为了使Transformer模型能够用于移动视觉任务,提出了CNN和Transformer结合的模型结构;2022年,Zhang等人[12]为了将视觉Transformer的优点融合到CNN中,提出一种具有全局感受野且带有位置嵌入的全局循环卷积.
综上,针对现有人脸欺骗检测模型,基于CNN的模型架构存在无法获取全局感受野的特征相关性的缺陷,而基于Transformer的模型架构存在参数量大、不易训练等缺点.鉴于此,本文提出了融合CNN的权值共享和平移不变性以及Transformer的全局感受野优势的适用于人脸欺骗检测的模型架构.为了证明本文模型的有效性,在CASIA-FASD[13]、Replay-Attack[14]数据集和CASIA-SURF[15]数据集的Depth模态上进行了对比实验和消融实验.结果表明,本文方法可以提高人脸欺骗检测模型性能,优于其他检测方法.
1 本文模型
为了有效结合CNN和Transformer的优点,本文对MobileViT[11]改进优化,MobileViT巧妙地将MobileNetV2的逆残差块和Transformer模块进行结合叠加,从而实现局部与全局的视觉表征信息交互.其在图像分类、目标检测和语义分割等视觉任务中都取得了很好的性能.
本文从CNN和Transformer这2种模型出发,首先通过优化MobileNetV2中部分模块,设计出基于注意力机制的倒残差(attention-based inverted residual, AIR)模块,缓解特征图冗余的问题,主要提取局部特征,当步长为2时进行下采样;其次,与MobileViT中所用Transformer不同的是,本文Transformer部分结合了基于局部窗口的多头注意力和基于全局窗口的多分辨率注意力(multi-resolution overlapped attention, MOA)[16],最终设计了CNN和Transformer融合(convolutional neural network and transformer fusion, CTF)模块,结合了CNN对空间感应偏差、数据增强的敏感性较低和Transformer输入自适应加权和全局处理的优点,以缓解现有人脸欺骗检测模型中CNN无法提取全局信息以及Transformer模型参数量大的问题.
1.1 整体框架
本文模型具体结构如图1(a)所示.本文方法主要体现在CNN和Transformer的融合时局部和全局信息结合的过程,图1(b)则是局部像素与全局像素之间实现信息交互的过程效果示意图:
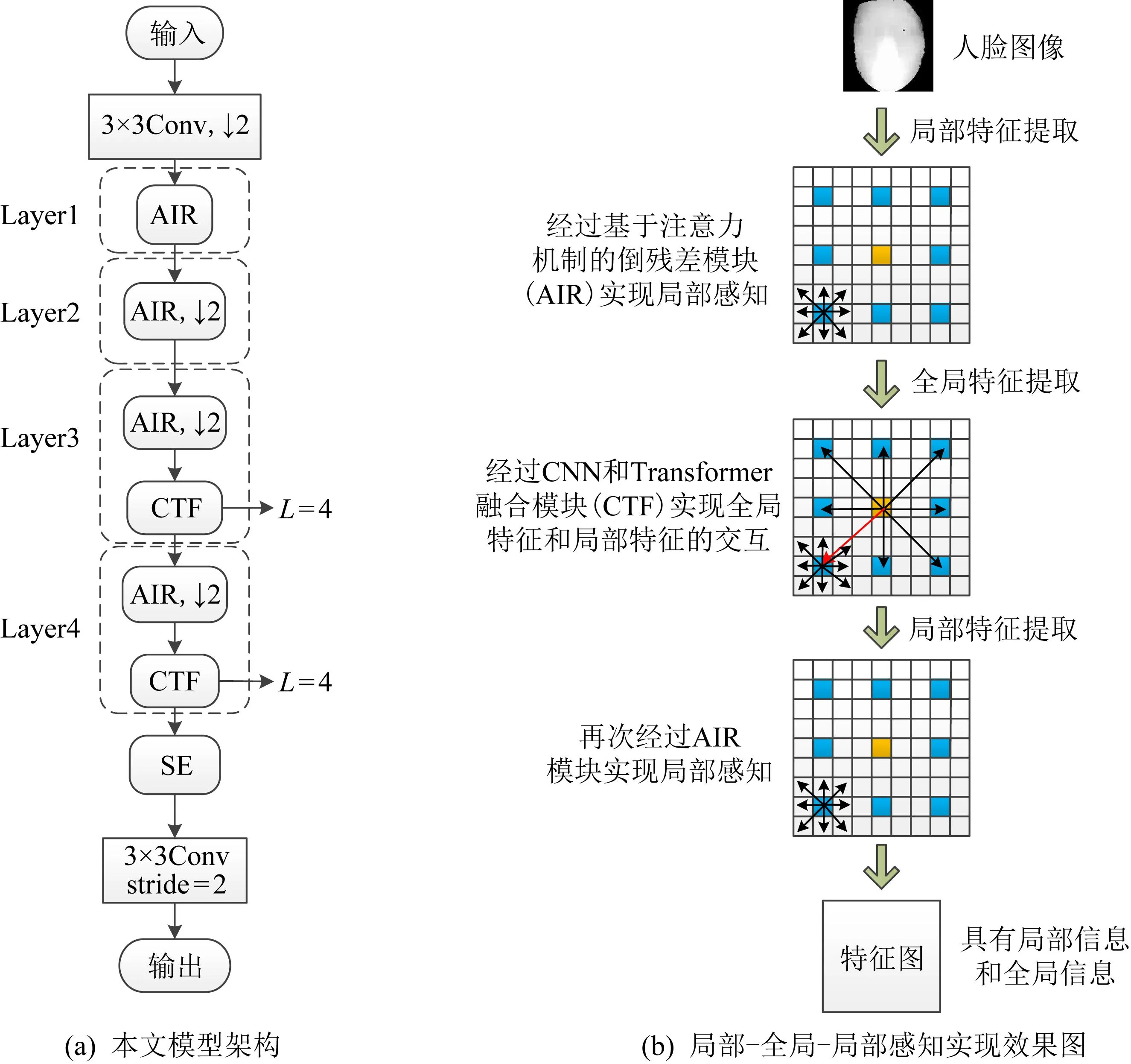
图1 融合CNN和Transformer的人脸欺骗检测模型
首先随机裁剪图像统一大小,在注意力机制的驱动下,再随机选取局部图像作为网络结构的输入,有效地避免训练网络时的过拟合问题.然后使用常规的3×3卷积层进行下采样,保证提取到丰富的局部特征.接着,主要是AIR和CTF这2个不同的功能模块进行叠加,基于CNN的AIR模块提取到的局部特征作为CTF模块的输入,然后再与经过CTF模块中基于Transformer提取到的全局特征进行融合,信息交互过程如图1(b)所示.最后添加的是通道注意力SE(squeeze-and-excitation)[17]模块对输入特征图进行通道压缩,获取每个通道的重要性,从而使模型更加关注信息量大的通道特征,提升模型对通道特征的敏感性.
1.2 AIR模块
文献[18]利用特征映射之间的相关性,以低成本的操作生成更多的特征图,在一定程度上缓解了特征图冗余的问题.而文献[19]以较少参数提取同样丰富的特征,实现结构轻量化.为了避免信息过于丰富从而引起的特征图冗余问题,以及构建各通道间的依赖关系,本文设计了基于注意力机制的倒残差网络——AIR模块,其结构如图2(b)所示.AIR模块是对MobileNetV2[20]进行优化设计的结果,MobileNetV2是一个带有线性瓶颈层的倒残差网络,具体结构如图2(a)所示:
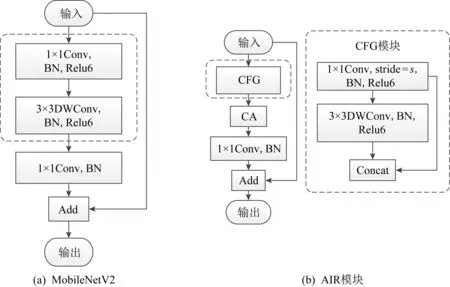
图2 MobileNetV2与AIR的结构
从图2可以看出,本文AIR模块的设计主要体现在特征廉价生成(cheap feature generation, CFG)模块,它将输入通过1×1卷积得到的特征图与再通过3×3的深度卷积得到的特征图进行融合拼接,实现以更少的参数通过线性变换生成更多的特征映射,降低计算成本.
由于CFG模块有通道拼接的过程,需要对通道间关系进行构建,因此,在CFG模块后增加坐标注意力(coordinate attention, CA)[21]模块,用精确的位置信息对通道关系和长期依赖进行编码.
1.3 CTF模块
为了实现局部和全局信息交互从而提升人脸欺骗检测模型性能,本文设计融合了CNN的归纳偏置特性和Transformer的全局感受野特性的CTF模块,具体结构如图3(a)所示.
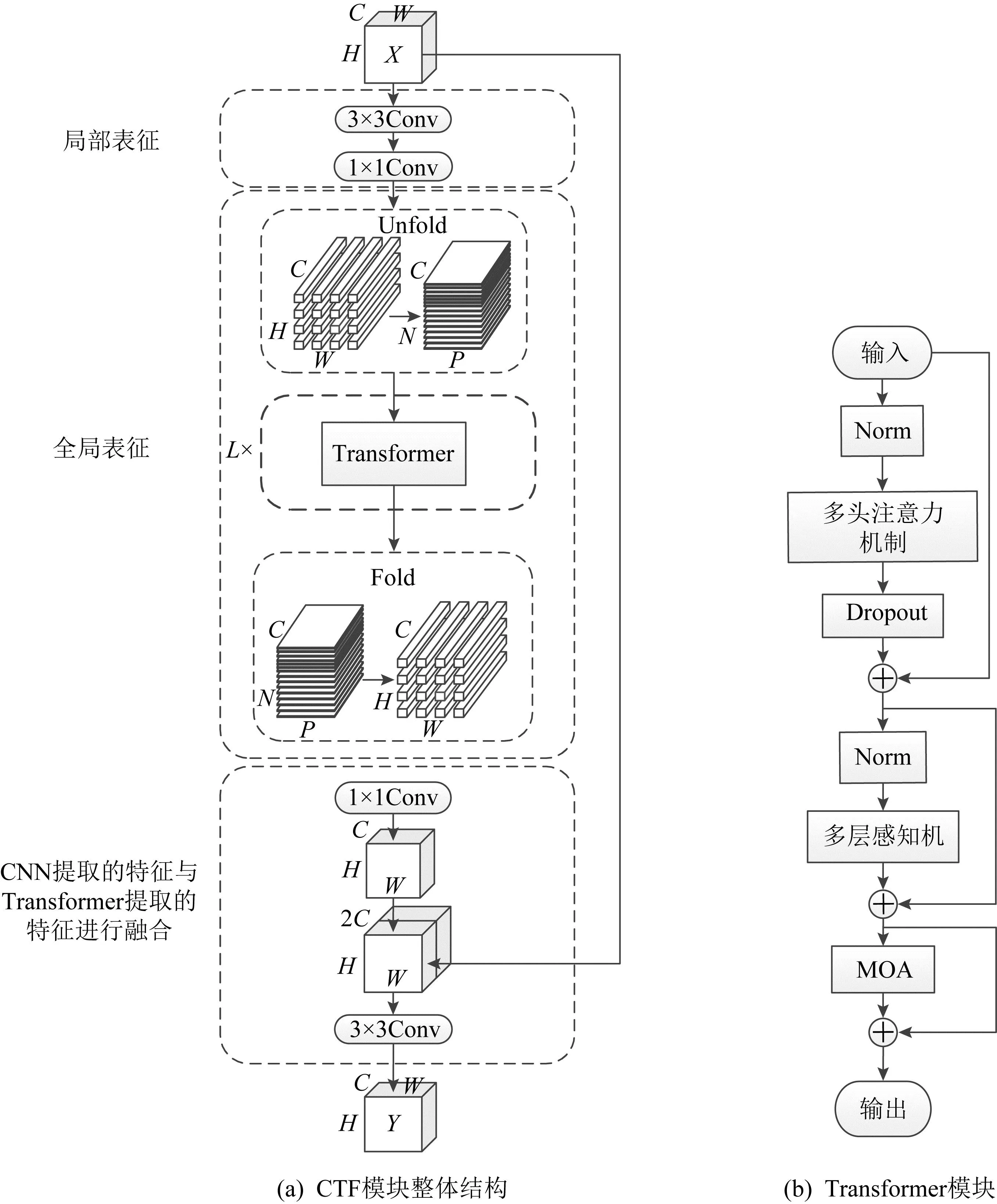
图3 CTF模块结构
CTF模块主要是在CNN主干网络中使用Transformer代替部分卷积模块.对比基于Transformer的模型,本文设计的CTF模块不需要大量数据,可以利用CNN的归纳偏置特性使用少量参数对局部和全局信息进行特征编码.首先用3×3卷积学习局部空间特征,通过1×1卷积将输入特征投影到高维空间,完成局部表征提取,最终得到特征图XC∈B×C×W×H.为了能够学习具有空间归纳偏置的全局表示,卷积操作后加入Transformer模块,如图3(b)所示.由于经过卷积后的图像不符合Transformer的输入,因此将XC展开为N个不重叠的图像块XP∈B×(w×h)×(N×C).
XP=Unfold(XC),
(1)
其中N=(W/w)(H/h);经过Transformer模块对每个图像块建模后,得到XT∈B×(w×h)×(N×C).
XT=Transformer(XP).
(2)
最后通过1×1卷积将输出的维度降到与CTF模块输入相同的维度,然后用3×3卷积将局部和全局特征进行融合,实现全局感知操作.在此之前,需要将特征图XT折叠成卷积操作的输入,即XF∈B×C×W×H.此时XF含有全局信息,再将其和原始输入图像进行连接,使得同时包含全局和局部信息.
XF=Fold(XT).
(3)
CTF中的Transformer模块可以获取全局信息,以弥补基于卷积的人脸欺骗检测模型只能局部感知的不足,该模块由基于局部窗口的多头注意力和基于全局窗口的MOA构成,如图4所示.
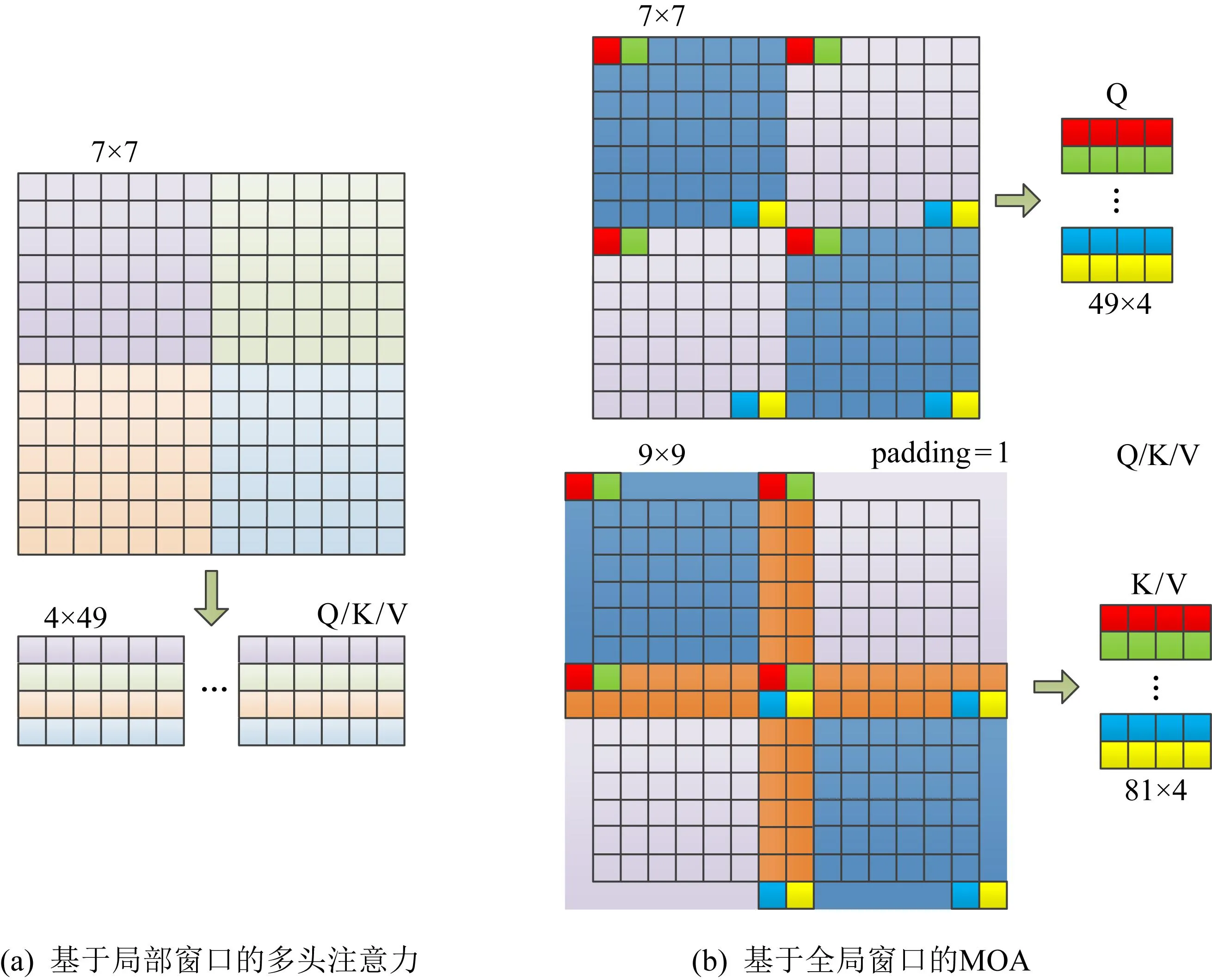
图4 2种自注意力模块Q,K,V的生成示意图
常规的自注意力机制中,Q(query)、K(key)、V(value)通过线性变换生成过程如图4(a)所示.而MOA-Transformer[16]中的MOA模块中,为了实现邻域像素信息的传递,用于生成K,V嵌入的图像块尺寸比用于生成Q嵌入的图像块尺寸稍大,且滑动步长比其本身要小,过程中有重叠.如图4(b)所示,橙色为重叠部分.MOA模块能够克服基于局部窗口的多头注意力不能建立长期依赖关系的问题,使所有像素之间尽可能进行信息交互,从而将基于局部窗口的多头注意力提取到的全局特征进行聚合.
2 实验分析与结果
2.1 实验基础
2.1.1 实验设置
本文实验均在python3.7.0环境下的pytorch框架中进行,CPU为Intel®CoreTMi7-11800H,GPU为NVIDIA GeForce RTX 3060,内存大小为16.0GB.本文模型的优化器使用SGD,损失函数选择常用于分类问题的交叉熵函数,初始学习率为0.05.批处理样本大小为64,循环10次,每次迭代次数为40次.
2.1.2 数据集
本文使用的数据集包括CASIA-SURF,Replay-Attack和CASIA-FASD.其中CASIA-SURF数据集包含RGB,Depth和IR这3种模态,本文主要在该数据集的Depth模态下进行实验.Replay-Attack和CASIA-FASD数据集是单模态的,只有RGB一种模态.
2.1.3 评价指标
为了公平起见,本文在不同数据集上作对比实验时使用了不同的评价指标.在CASIA-SURF数据集上实验时,使用平均分类错误率(average classification error rate, ACER)、准确率(accuracy, ACC)评估不同模型的精度,使用参数量(Params)以及每秒浮点运算次数(FLOPS)评估的模型计算量,ACER值越小ACC值越大,表明实验的效果越好.而在Replay-Attack和CASIA-FASD数据集上,使用等错误率(equal error rate, ERR)和半总错误率(half total error rate, HTER)作为对比实验的评价指标,其值越小越好.
2.2 消融实验
在人脸欺骗检测模型的结构设计中,本文分别引入了CA模块、SE模块、MOA模块以及改进优化的AIR模块中的CFG模块,因此,在CASIA-SURF数据集的Depth模态下进行消融实验,从而验证上述4个模块的有效性.
由表1可知,依次增加CA,SE和MOA这3个模块后,参数量有小幅度增加,但是模型精度变化显著,这表明CA,SE和MOA模块对本文模型的性能有较好的提升作用.而最后2行实验数据表明,在不添加CFG模块时,参数量为0.5999MB,准确率为98.15%,增加该模块后,不仅参数量下降为0.5977MB,且准确率提高了1.16%,验证了CFG模块的有效性.
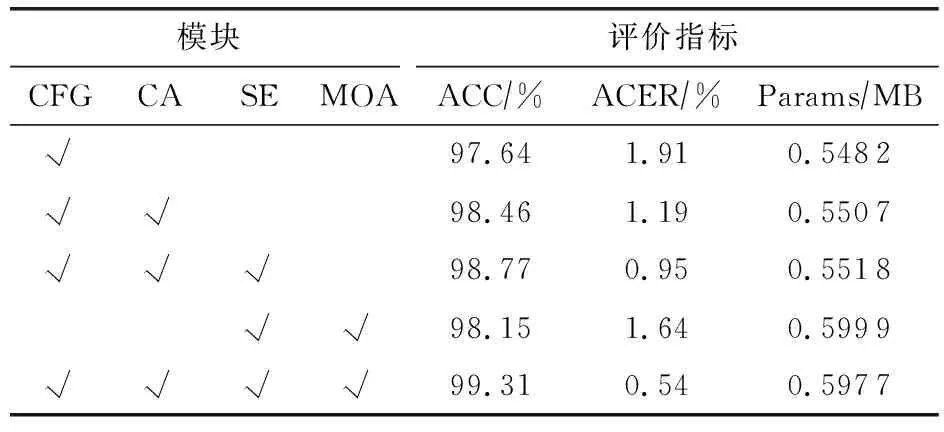
表1 在CASIA-SURF数据集的Depth模态下的消融实验结果
2.3 不同方法效果比较
2.3.1 CASIA-SURF数据集上的方法比较
本文融合了CNN和Transformer这2种模型,为了验证本文融合模型的有效性,将分别与基于CNN的模型和基于Transformer的模型在数据集CASIA-SURF(Depth模态)上进行对比实验.如表2所示.
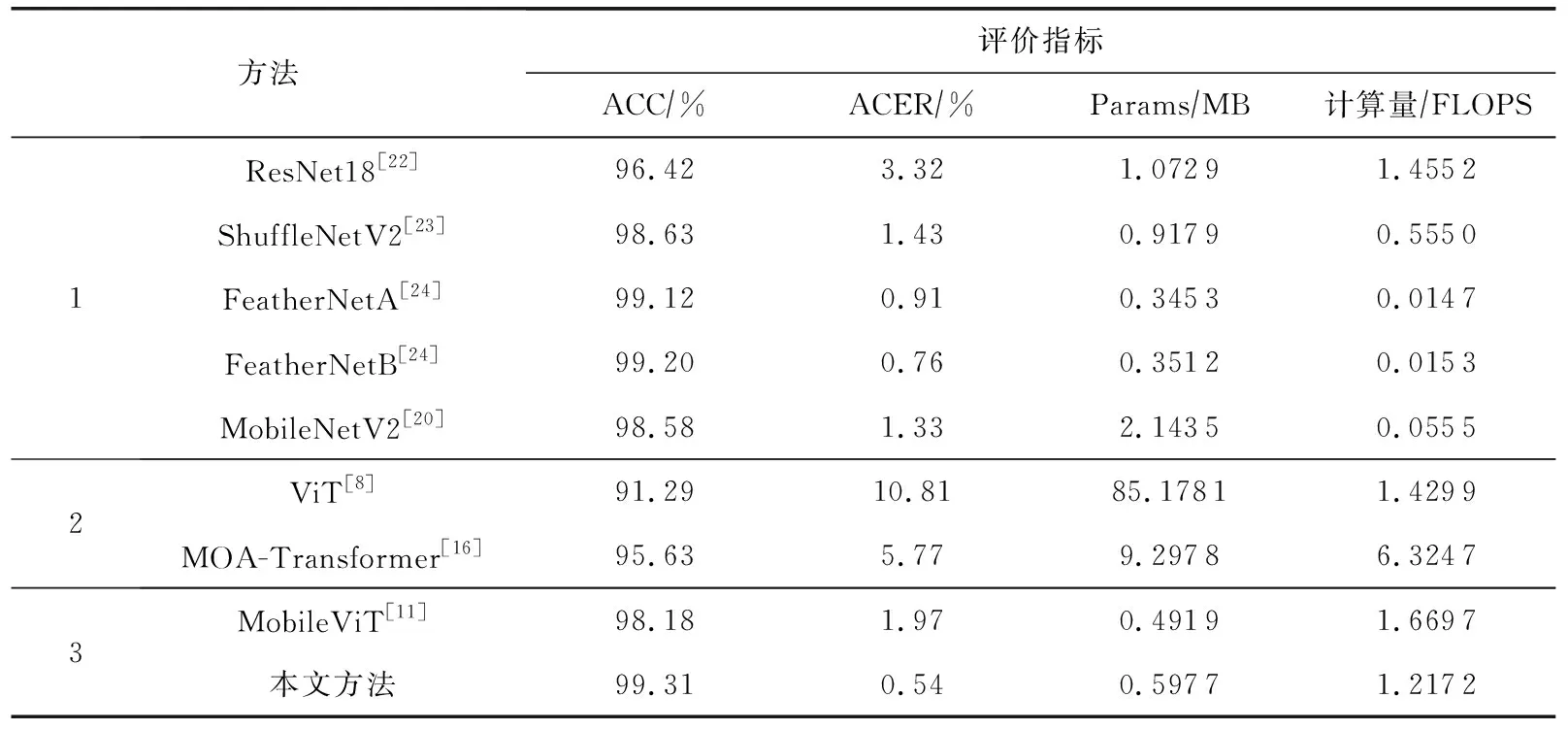
表2 在CASIA-SURF数据集的Depth模态下的对比实验结果
表2中方法1是基于CNN结构的人脸欺骗检测模型,方法2是基于Transformer结构的人脸欺骗检测模型,方法3是两者融合的模型架构,包括本文设计的模型.实验结果表明,与基于CNN的模型方法相比,本文模型的参数量达到0.59MB,虽然比专注于轻量化的FeatherNet系列略高,但受Transformer全局感知影响其精度更好,且与其他模型无论是在参数量还是准确度上进行比较都更具竞争力;与基于标准Transformer和基于MOA-Transformer模型相比,本文模型参数量仅0.59MB,而对比的2种Transformer模型分别达到了85.17MB和9.29MB,远大于本文的融合模型;通过与MobileViT方法比较,本文模型准确率提高1.13%,ACER降低到0.54%,表明了本文对其改进优化的有效性.
2.3.2 Replay-Attack和CASIA-FASD数据集上的方法比较
由表3、表4可知,本文所设计的模型在Replay-Attack和CASIA-FASD数据集上的ERR和HTER都实现了零错误率,是现有人脸欺骗检测模型中最好的结果.
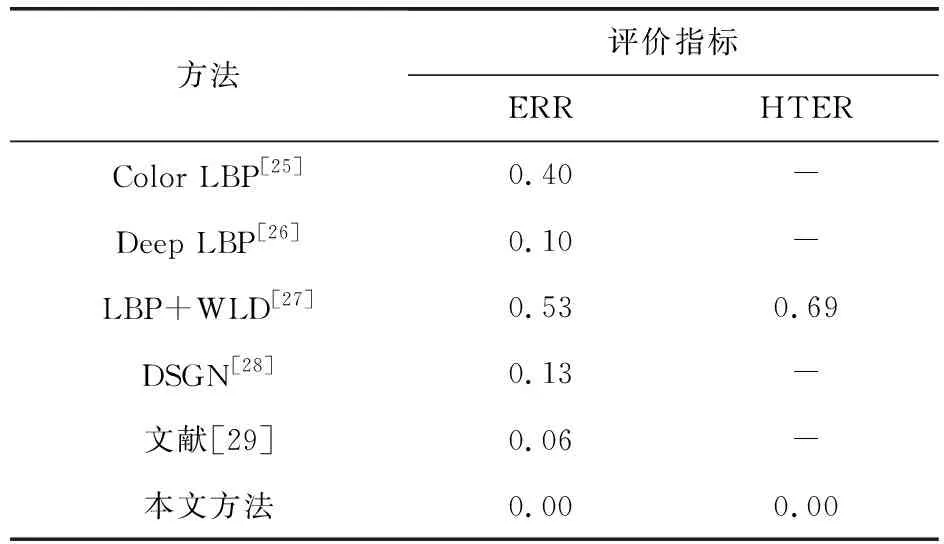
表3 在Replay-Attack数据集上与其他方法比较结果 %
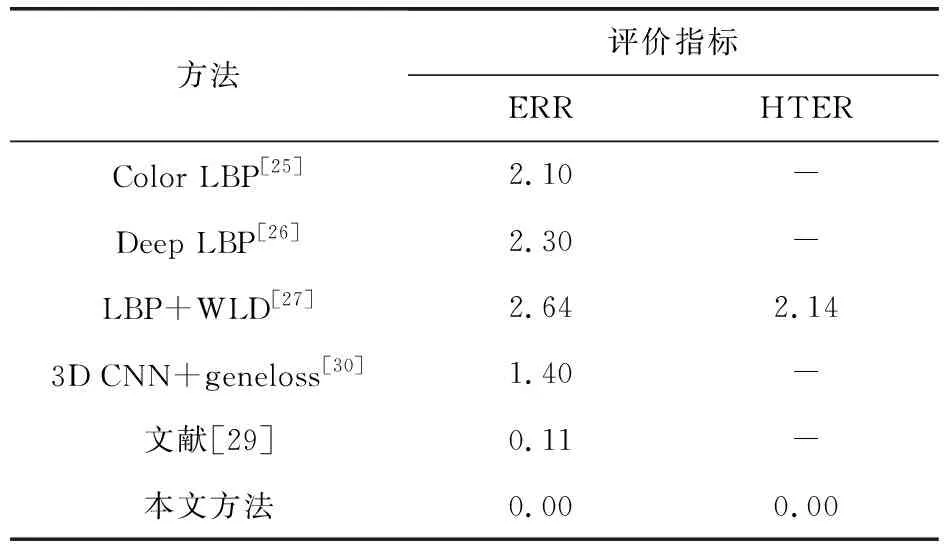
表4 在CASIA-FASD数据集上与其他方法比较结果 %
3 结 语
实际应用中,大型模型很难在边缘设备上部署,并且影响用户体验,本文的融合方法对比基于Transformer的大型模型方法在参数量方面大幅度降低,实现了网络的轻量化,更便于应用在边缘设备中.本文模型参数量为0.59MB,仅次于部分轻量级CNN架构,在多个数据集内部测试时,实验效果明显优化其他方法,下一步工作将考虑如何提高模型的泛化能力和鲁棒性.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
发明与创新(2015年33期)2015-02-27
中国卫生(2014年5期)2014-11-10
