
基于CBAM-VMFC模型的化纤丝饼质量缺陷识别
2024-01-11 00:51李剑锋
毛纺科技 2023年12期
俞 璇,李剑锋
(中国计量大学 经济与管理学院, 浙江 杭州 310018)
化纤作为一种常用材料被广泛应用于服装、航空、医疗等各个领域,但我国化纤生产领域的管理水平、生产流程以及生产辅助技术仍处于相对落后的阶段[1]。
受限于设备数字化程度较低和研发资金不足等,化纤产品的质量检验主要依靠检验员人眼识别[2],具有极强的不稳定性,人工接触的检测方式也有可能为丝饼带来二次损伤。此外,传统的图像识别技术也存在特征量化困难、识别能力较弱等问题,难以满足工业要求[3]。
随着工业4.0时代的到来以及高性能芯片、云计算平台的出现,机器视觉算法日臻成熟,其领域从电子元件疵点识别[4]逐渐扩展到汽车质检[5]、自动驾驶[6]、人脸识别[7]、机器人分拣[8]、车牌标识[9]等。相对于传统图像识别技术,基于深度学习的机器视觉技术在及时性、准确性、抗干扰性上有显著提升,系统硬件设备也更具优势。因此,运用人工智能技术实现纺织设备数字化、网络化和智能化[10]已是大势所趋。
当前,国内在化纤纺织领域中,缺陷研究主要历经3个阶段,从长丝断头识别[1,11]到丝饼表面缺陷,再到织物疵点研究[12-14]。基于计算机设备和图像技术的机器视觉检测技术逐步提升,丝饼表面缺陷识别也有了新的研究突破。郭根[15]以搭建硬件平台为基础,通过单方向凸包和支持向量机(SVM)检测丝饼毛羽,并结合打光技术以DoG算法和坐标序列法检测丝饼油污与凹陷问题。景军锋等[16]通过分析梯度空间下图像信息熵和能量变动差异,设置阈值识别丝饼污渍、压痕、飘丝三大缺陷。然而,此类方法均需根据特定数据库提取特定匹配特征,二者具有极强的相关性,一旦更换原始输入图片,则需重新提取特征,通用性与普适性较弱,且识别过程需要依照缺陷数目单独设置模型用于检测,没有集成的多分类视觉模型。
相较于传统的机器视觉算法,深度学习方法可以将数据直接传递到网络,利用卷积层自动提取缺陷图像的特征[17],并通过小批量梯度下降优化模型损失函数,得到满足需求的检测结果。吴旭东等[18]基于卷积神经网络,提出DVYC分类模型,通过卷积核的分离、通道的变换等操作,实现细纱断头检测。王泽霞等[19]以AlexNet为网络基础,通过全局最大池化法将绊丝、成型不良、油污3类缺陷的识别准确率提升至97.1%,虽然该方法对成型、污渍类大面积缺陷有着显著的识别率,但其对于毛丝类小面积缺陷检测的成果仍有待校验。
为适配我国“智能制造2025”中智能改造、精准制造的要求,本文研究遵循智能化发展应与现有生产设备适配的内在逻辑,针对化纤丝饼生产制造过程中的毛丝、绊丝、纸管破损三大主要缺陷,设计基于混合注意力机制(CBAM)和改进全连接层的VGG网络(Convolutional Block Attention Module-VGG with Modified Fully Connected Layer,CBAM-VMFC)模型,以改进的机器视觉技术提高丝饼表面缺陷识别率,以高效的质量控制技术保证丝饼检测的准确性和实时性,提高企业核心竞争力。
1 研究设计
毛丝、绊丝、纸管破损是丝饼出库前的三大主要缺陷,也是衡量化纤丝饼质量的重要指标之一,图1为3种缺陷的局部放大效果。在产品包装出库前运用机器视觉算法筛除带有这3种缺陷的丝饼,能保证产品的质量精度需求,对企业的建设与发展有着重要的现实意义。

图1 3种缺陷
1.1 研究样本
本文实验所需的图像来源于国内某家500强企业。以本文实验为例,探索深度学习技术赋能化纤丝饼的质量控制,对纺织领域的其他纱线或织物的缺陷识别也具有一定的参考价值。
样本的选取遵照抽样原则[20]。丝饼的缺陷种类较多,根据FZ/T 50054—2021《化学纤维 长丝卷装外观在线智能检测》,目前在生产过程中出现的外观疵点主要有17种。从9种型号的丝饼中随机抽取样本进行拍照,基于工人经验比照正常样本,对毛丝、绊丝、纸管破损3种缺陷进行标签标注,用于缺陷数据集的构建。
1.2 研究方法
鉴于当前丝饼表面缺陷多分类识别问题的不足,本文提出一种基于深度学习的机器视觉技术,实现丝饼质量缺陷的智能诊断过程。具体研究内容包括数据预处理过程和模型设计与实验对比2个方面。
数据预处理过程:将毛丝、绊丝和纸管破损的单通道灰度缺陷图像混合输入并打乱样本,通过数据集随机化保证模型泛化能力,对缺陷样本实行过采样缓解采集数据类别不平衡的问题。
模型设计与实验对比:为论证模型改进的有效性,本文通过与原始VGG[21]模型的消融实验对比,检验全连接(FC)层改进、CBAM混合注意力机制[22]加入的效益。
① VMFC模型。将VGG11模型最后的全连接层调整为大小256和1的2个FC层,并在2个FC层之间运用Dropout方法防止过拟合。在此将改进全连接层后的网络命名为VMFC(VGG with Modified Fully Connected Layer),验证改进后的卷积网络模型的识别准确率。
② CBAM-VGG模型。加入CBAM混合注意力机制,在图像空间和通道双维度上进行权重分配,捕获和强化数据空间内重要区域的特征。在此将添加了CBAM模块的VGG网络命名为CBAM-VGG(Convolutional Block Attention Module-VGG),验证混合注意力机制对VGG11模型的改进效果。
③ CBAM-VMFC模型。将全连接层的改进和混合注意力机制全部加于原始VGG11模型。
将VGG11模型、VMFC模型、CBAM-VGG模型和本文算法CBAM-VMFC进行比较,基于消融实验的结果,论证模型改进的有效性。
1.3 研究意义
丝饼运输至仓库存储后,传统企业的丝饼外观质量缺陷检测流程是由工人对制造完成的丝饼进行外观勘测,发现缺陷后填写表单并分类降等,最后包装出库,完成产品交付。智能改进路线运用基于深度学习的机器视觉技术,只需要智能质检和智能评级2步,即可高效识别丝饼外观缺陷,对瑕疵丝饼予以降等处理,并将降等丝饼的托盘号、批号、缺陷类型等实时更新至数据库,便于人工复核。对数据库中某时间段或某批号丝饼的降等信息进行分析,当出现异常降等数和异常缺陷标记时立刻警示,反馈至前道工序,查看故障来源。化纤丝饼生产质量控制流程对比如图2所示。智能质检和智能评级操作精简了传统的企业质量控制流程,能有效降低2类误判的产生,在提高检测精度、提高检测效率的同时,节约人力成本,满足企业远程智能化管理互联互通的需求。

图2 化纤丝饼生产质量控制流程对比
2 图像采集与预处理
采用分辨率为2 448像素×2 048像素的工业CMOS相机(型号DFK33GX264e,德国映美精公司)采集原始图像。由于原始图片像素值较高,且为符合神经网络的输入尺寸设置,因此将输入图像尺寸设置为224像素×224像素。
首先,基于专家经验对采集到的图片进行标签标注;然后将RBG三通道图像转化为单通道灰度图以便神经网络运算;其次,通过随机旋转等操作达到数据增强的效用,以数据集随机化的方式保证模型泛化能力。由于数据集内各类别样本量的不平衡,因此需要对缺陷样本实行过采样,即从少数样本中随机重复采样扩充样本容量的方法,缓解采集数据类别不平衡的问题。
3 CBAM-VMFC模型的构建
神经网络是深度学习的核心组成,卷积神经网络(CNN)和循环神经网络(RNN)均在深度学习中应用广泛。深度卷积神经网络(AlexNet)、使用块的卷积神经网络(VGG11)、残差卷积神经网络(ResNet50)等均为CNN模型,被用于大型数据集的图像分类探索[22-23]。
VGG模型最初由牛津大学的K. Simonyan和A. Zisserman在LSVRC-2014(ImageNet视觉识别竞赛)中提出,该模型以92.7%的准确率位列本地化领域榜首和分类领域的榜二。Simonyan和Zisserman经过大量的对比试验,发现通过小的卷积层增加网络的深度,可以显著提高模型的准确性。因此,本研究以VGG11为网络基础,如图3所示,通过其中的8层卷积层和5层池化层完成特征提取,通过最后的全连接层完成图像分类[24]。

图3 CBAM-VMFC模型
由于全连接结构会使得网络参数过多,检测速度下降,因此将VGG11模型最后的3个全连接层调整为节点大小256和1的2个全连接层,有效减少全连接层的网络参数计算量,并通过Dropout方法防止模型过拟合。此外,由于毛丝缺陷属于小面积缺陷模型,也需要提高模型特征检测水平,因此在网络中加入混合注意力机制,捕获重要区域特征,使模型达到更高的检测效率。
3.1 全连接层的改进和Dropout方法的加入
深度学习的改进思路之一就是在不改变输入或输出大小的情况下,以模型有效性为基准实现参数的节约[25]和计算量的减少。VGG模型的全连接模块主要由3个全连接层构成,参数量较大,因此本文将全连接模块改进为2个FC层,并调整节点数量以实现改进目的,优化模型运行进程。
卷积后得到的特征图经由展平(Flatten)操作,化为一维向量输入全连接层,为分类器提供输入。展开特征图中的每个向量都与后一层节点相连。设全连接层为输入值Q和输出值P的图层,权重W储存在Q×P的矩阵中,全连接层的计算量为:
y=matmul(x,W)+b
(1)
式中:x表示输入值Q的向量;W是包含图层权重的Q×P矩阵;b是P偏差值的向量;y为计算的参数,其大小为(P,1),其参数量为权重W与偏置b的总和。
矩阵乘法matmul(x,W)的具体表示如下:
(2)
当特征数高于样本数时,线性模型会出现较高的偏差和较低的方差,这种泛化性和灵活性之间权衡被描述为偏差-方差权衡(bias-variance tradeoff)。在神经网络的学习中,尽管案例样本数远大于特征数,深度神经网络仍有过拟合的风险,因此需要上述2个全连接层之间运用Dropout方法,在每轮批次中随机让网络的部分隐层节点值为0,减少神经元之间共适应(co-adaption)性,保证网络前项传播的过程中模型更强的泛化效果,防止过拟合。
3.2 混合注意力机制
注意力机制(Attention Mechanism)借鉴了人类视觉特性,聚焦于局部信息的显著部分并赋予权重,通过不同区域的信息整合,从而形成对被观察对象的整体记录。
Itti等[26]在计算机视觉领域引入注意力机制,通过动态神经网络以显著性高低选择重点区域。Mnih等[27]首次在循环神经网络RNN模型上运用注意力机制实现图像分类。Fu等[28]提出一种基于CNN模型的循环注意力卷积神经网络RA-CNN,通过网络递归分析局部信息,并根据子区域的预测整合完成整张图片的分类预测。注意力机制主要有软注意(全局注意)、硬注意(局部注意)和自注意(内注意)3大类。软注意力属于确定性的注意力,具有可微分的特性,因此能运用神经网络算出梯度并且通过前向传播和后向反馈来学习得到注意力的权重。在卷积神经网络中,软注意机制主要有空间域、通道域和混合域三大注意力域,因而分别对应空间注意力模型、通道注意力模型、空间和通道混合注意力模型3种模型。

(3)
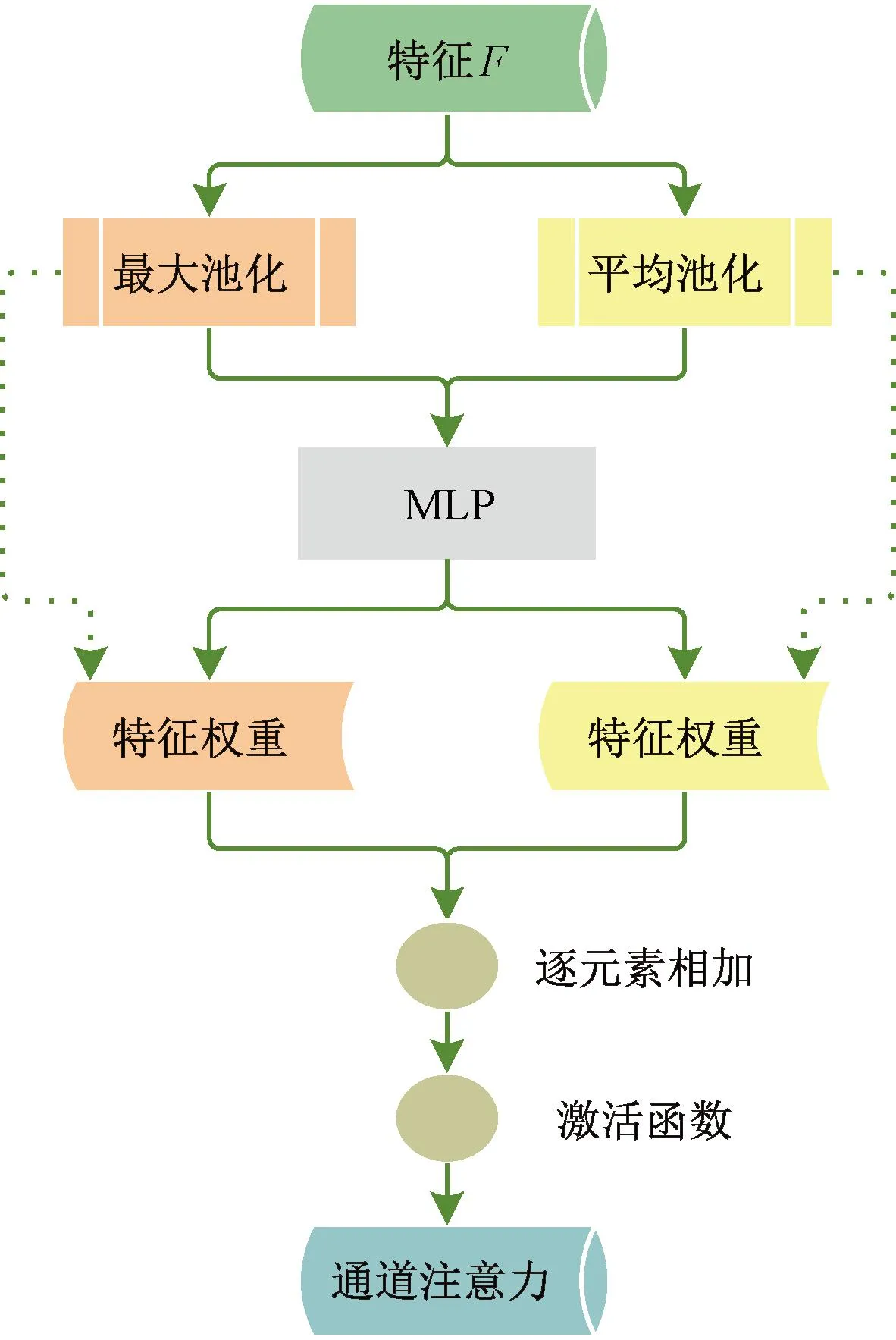
图4 通道注意力模块
式中:W0和W1为MLP模型的2次卷积后的权重;σ表示Sigmoid激活函数。

(4)
式中:f7×7表示7×7大小卷积核的卷积操作。
本文采用混合注意力CBAM模型,通过池化操作获得通道域和空间域的权重,并以串行形式完成权重与特征元素的相乘,最后对输入的特征图和输出的特征图进行逐元素相加,得到混合注意力特征图M∈H×W×C(如图6所示)。

图6 混合注意力机制
4 实验结果与分析
本文实验由16 G显存大小的GeForce RTX 2080 Ti显卡驱动,在Windows10操作系统上,调用Pytorch1.8深度学习框架完成网络调试工作,以CUDA11.0为架构,采用Python3.8.5版本进行程序编写。
4.1 实验数据集
本文实验累计拍摄图片总数37 179张,其中合格样本图像14 572张,毛丝样本图像19 242张,绊丝样本图像1 732张,纸管破损样本图像1 633张。将标签标注好的正常样本和缺陷样本进行混合,4类样本各选取200张作为测试集用于最后的结果评价,提取剩余的数据按照8∶2的比例划分训练集与验证集,用以模型训练和参数调整。
4.2 参数设置
设置模型每批次训练的样本数量(Batch Size)为64,最大迭代次数(Epoch)为100,优化器选择带动量的随机梯度下降SGD,动量设置为0.9,学习率设置为1.5625e-3,前10次迭代开启学习率预热,保证模型在趋于稳定后使用预设的学习率能加快收敛速度。
4.3 评价指标
本文采用准确率(Accuracy)P0、混淆矩阵、ROC(Receiver Operating Characteristic)曲线下的面积AUC(Area Under Roccurve)、kappa系数为评价指标,Pe为计算过程指标,表示偶然一致性。ROC曲线根据不同的分界值划定二分类,其中TP(True Positive)表示正例被预测为正例,FN(False Negative)表示正例被预测为负例,FP(False Positive)表示负例被预测为正例,TN(True Negative)表示负例被预测为负例。其余公式如下:
(5)
(6)
(7)
4.4 实验结果
模型训练的缺陷识别准确率曲线和交叉熵损失值曲线如图7、8所示,由于初期的学习率预热,模型准确率有较大的起伏变化,但随着迭代次数的增加,网络不断优化学习,缺陷识别准确率显著提高,损失值逐渐减小,预测结果趋于稳定。
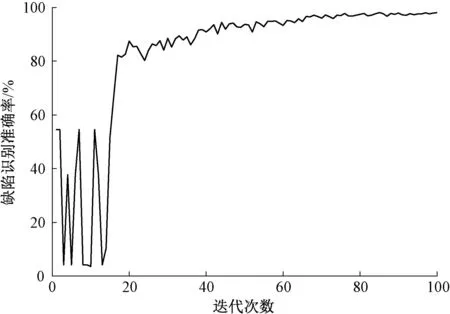
图7 缺陷识别准确率曲线
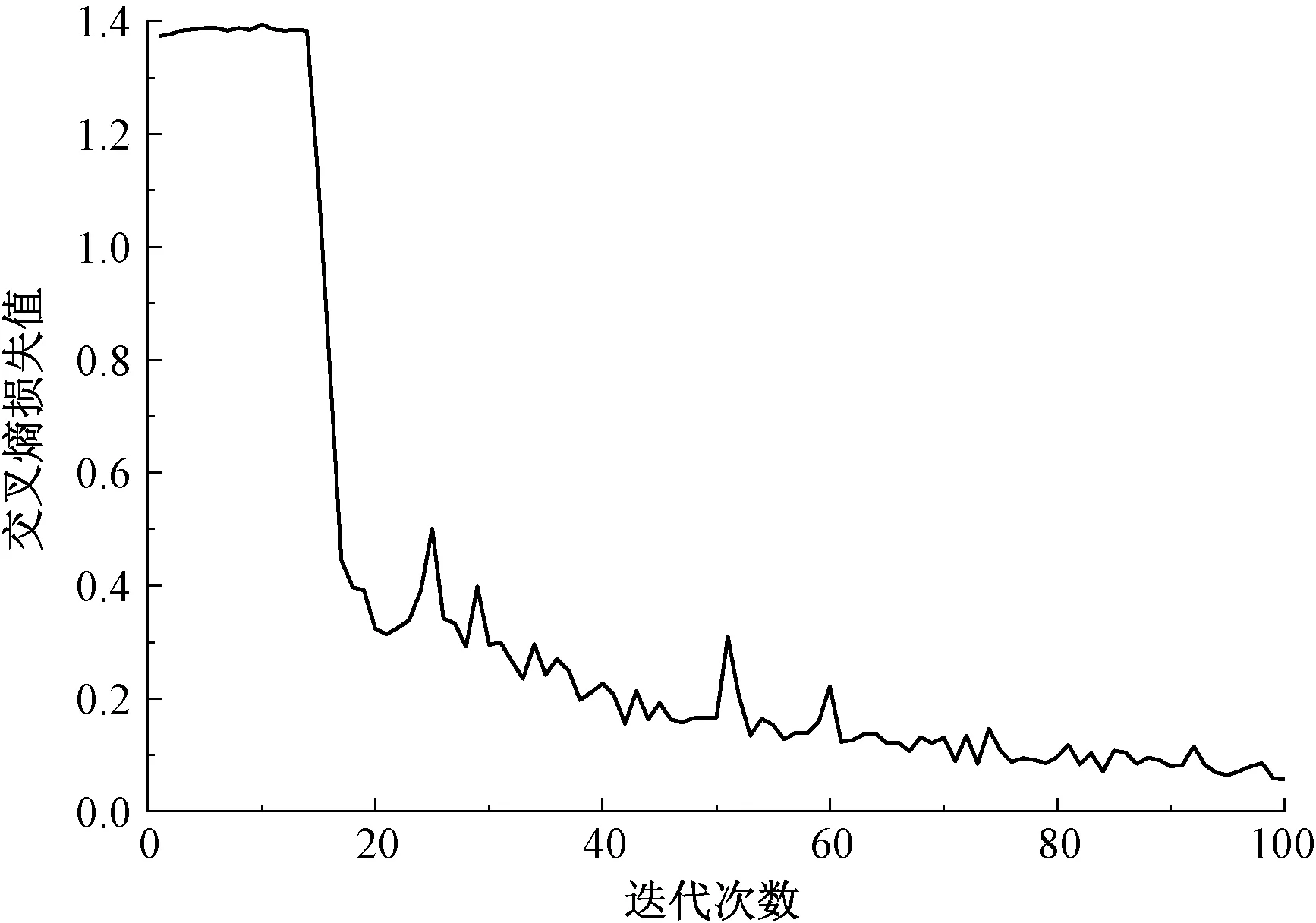
图8 交叉熵损失值曲线
图9为混淆矩阵,纵轴为真实标签,横轴为预测标签,标签0表示合格图像,标签1表示毛丝缺陷,标签2表示绊丝图像,标签3表示纸管破损图像。毛丝、绊丝图像的识别准确率均为100%,可见模型对于大、小面积缺陷均有着较高的检测能力;由于纸管包装存在圆圈花纹图案,模型会造成误判,因此纸管破损的识别水平相对较低,只有92.0%的准确率。最终模型在测试集上的预测准确率为97.5%,成果较为理想。

图9 混淆矩阵
4.5 消融实验
为了论证本文算法对丝饼表面缺陷识别的有效性,设计如下消融实验检验不同模块的改进效用。
4.5.1 全连接层的改进
原始VGG模型的全连接模块由3个全连接组成,根据公式计算需要123 633 667个参数,这使得网络训练速度较慢。因此将VGG11模型最后的3个全连接层调整为大小256和1的2个全连接层,以实现参数量和计算量的减少。如表1所示,全连接层的参数总量从123 633 667降低至 6 422 529,模型整体的参数内存减少440 MB。

表1 全连接层改进
4.5.2 注意力模块的添加
混合注意力模型可以沿着独立的通道维度和空间维度获得二者权重,并进行自适应特征优化,CBAM属于轻量级的通用模块,因此能忽略其参数成本将其集成到CNN架构中进行端到端的训练,具有广泛的适用性。
不同方法缺陷识别准确率如图10所示,改进全连接层后VMFC模型的收敛速度较VGG11有着明显的提升,同样CBAM-VMFC的收敛速度也快于CBAM-VGG模型。
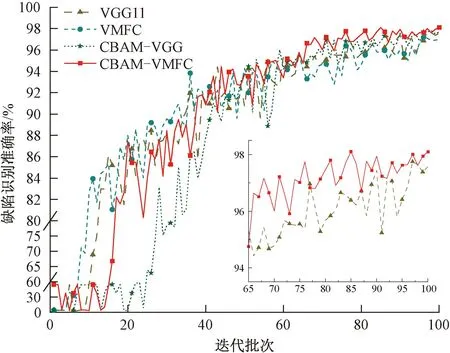
图10 方法对比
随着迭代周期的增加,CBAM-VMFC模型优势逐渐显现,其缺陷识别准确率明显高于其他3个模型,说明网络能够准确高效地提取图片的关键特征信息并完成分类任务。
CNN通过卷积层、池化层和全连接提取数据特征,完成图像分类、语音识别等工作。而RNN则基于时间序列文本的长期依赖关系,多应用于自然语言处理等方面。为全面比较各类模型对化纤丝饼质量缺陷的分类结果,本文添加深度学习中RNN领域的长短期记忆模型(LSTM)、门控循环单元(GRU),同VGG11模型、VMFC模型、CBAM-VGG模型和CBAM-VMFC模型对图像进行训练对比,结果如表2所示。

表2 测试集性能对比
选取合格、毛丝、绊丝、纸管破损图像各200张作为测试集,比较4类样本的正确识别数量。根据测试集性能对比,RNN除参数内存较小的优势外,在图像分类上效果不及CNN模型。对比4个CNN模型的分类性能,全连接层的改进使得VMFC以微弱的精度损失为代价提高了模型的检测效率,CBAM轻量级模块的加入,有效提高了模型对于合格类图像和纸管破损图像的识别效率,保证了模型在提升预测准确率同时没有计算量和参数量的负担,更好完成了毛丝、纸管破损的缺陷检测识别工作。CBAM-VMFC对于合格图像和绊丝图像均有100%的识别成效,并于交叉熵损失、准确率和kappa 3个方面指标表现最优,说明本文方法对提高丝饼表面缺陷的识别准确率有着显著成效。经由本文研究方法的单张图片的测试时间为0.1 s,满足工业用时规定。
5 结 论
本文提出了一种基于混合注意力机制和改进全连接层的VGG网络模型(CBAM-VMFC),用于毛丝、绊丝、纸管破损3种图像的缺陷识别。首先对图像实现灰度化处理便于卷积神经网络学习;其次以过采样的方式缓解样本不平衡问题;然后,将原始的3个FC层调整为节点大小256和1的2个FC层,并在之间运用Dropout方法防止过拟合,减少模型参数量和计算量,将加快模型收敛速度;最后在卷积层与全连接层之间加入混合注意力机制CBAM模块,获得输入特征空间域和通道域的权重赋值,强化重要区域的感兴趣特征。结果表明,对比VGG11模型、VMFC模型、CBAM-VGG模型,本文方法能有效节约440 MB的参数内存,满足深度学习中参数节约与计算量减少的改进目标,有效加快模型收敛速度,以97.5%的准确率识别丝饼外观瑕疵,可满足工业运用的需求。识别出缺陷后,系统对瑕疵丝饼做降等处理,并将降等信息实时更新至数据库,对异常信息及时反馈示警,实现智能化质检管理。
在工厂实际运用中,降等的丝饼会根据瑕疵程度进行多等级质量评价,按评级流入市场售卖;而本文方法只能完成降等操作,而无法进行后续的多级别等级评定,因此在之后的学习中,会进一步研究实现识别之后的质量评级问题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
