
聚类随机采样和代价敏感的电信客户流失预测集成模型*
2024-01-10 06:54李毅马文斌李国祥
企业科技与发展 2023年11期
李毅,马文斌,李国祥
(1.澳门科技大学商学院决策科学系,澳门氹仔,999078;2.广西财经学院大数据与人工智能学院,广西南宁 530007;3.广西财经学院教务处,广西南宁 530007;4.广西财税大数据分析工程研究中心,广西南宁 530007;5.广西财经学院网络与信息技术中心,广西南宁 530007)
0 引言
近年来,新冠病毒疫情防控激发了全社会的数字化消费需求,我国对加快数字经济发展也做出专门部署。作为国民经济基础性、战略性、先导性产业的电信业呈现持续健康发展的态势。工业和信息化部发布的《2021年通信业统计公报》显示,2021年我国电信业务收入累计完成1.47 万亿元,较2020年同比增长8.0%,增速较2020年净增4.1 百分点[1],但是从市场需求来看,市场已基本趋于饱和,用户增长速度减缓,依靠用户规模增长拉动收入增长将受到影响,在这种情况下,获取新客户的成本要比保留现有客户的成本高得多[2]。如何有效留住现有客户越来越受到学术界和业界的关注。
预测客户流失的概率是客户留存的重要环节,其发展水平是衡量客户保持策略的有效性和客户关系管理智能化程度的重要标志。但是电信行业具有客户较稳定、流失率较低、数据高度不平衡的特点,支持向量机[3]、神经网络[4]等机器学习算法通常假设输入数据是类别平衡的数据,在不平衡数据上的泛化能力有所下降。因此,设计一种能够提高识别流失客户率的模型至关重要。
为此,本研究将基于聚类的随机采样、编辑最近邻的数据清洗方法(Edited Nearest Neighbours,ENN)、代价敏感学习的梯度提升决策树、Bagging 集成学习等多种技术,提出一种能够提高预测客户流失准确度的新模型。首先,在特征层面利用特征选择方法降低噪声、冗余特征的影响;其次,在数据层面利用聚类随机采样、编辑最近邻方法降低数据的不平衡度;最后,在算法层面利用代价敏感学习提高梯度提升决策树对不平衡数据的适应性,集成若干代价敏感梯度提升决策树的预测结果,提高模型的泛化能力,并通过4个高度不平衡的数据验证该模型的有效性。
1 相关研究
1.1 客户流失预测
预测客户流失率的关键在于具有高准确度的模型和处理数据特征的能力。随着人工智能的发展,以统计学、统计机器学习等方法为主,客户流失预测研究取得丰富的成果。根据研究使用方法的不同,可以大致将研究划分为如下3个阶段。
(1)单模型阶段。这一阶段是客户流失预测的早期阶段,逻辑回归[5]、决策树[6]、支持向量机、神经网络等分类方法在流失预测模型的构建中发挥重要作用。
(2)集成学习阶段。集成学习是机器学习中的重要研究方向之一,其基本结构是先构建多个具有差异性的基分类器,然后利用适当的组合策略将结果进行整合,常可获得比单个分类器更好的泛化能力。为进一步提高预测模型的性能,研究者将随机森林[7]、ADABOOST[8]等集成学习方法引入客户流失预测中;XIAO等[9]将集成学习与代价敏感学习相结合,提出了一种针对不平衡数据的动态分类器集成方法;IDRIS 等[10]将遗传规划的搜索能力与Adaboost 的分类能力及粒子群优化的欠采样方法的不平衡数据处理能力相结合,提出一种具有更好的流失识别能力的高性能流失预测系统;LU 等[11]根据boosting 算法分配的权重将客户分成两个簇,并在每个类簇上分别建立流失预测模型;李为康等[12]为避免维度灾难和数据稀疏问题,提出一种包含Stacking 层和Voting 层的双层预测模型;肖进等[13]将元代价敏感学习、半监督学习融入Bagging 集成中,解决客户数据有标签样本数量少且类别不平衡的问题;GATTERMANN-ITSCHERT 等[14]利用随机森林流失预测模型,在数据的多个时间切片上训练模型,显著提高客户流失预测性能。
(3)深度学习阶段。近年来,深度学习方法在计算机视觉、自然语言处理、推荐系统等领域取得显著的成就。在客户流失预测领域,由于数据规模的极速扩大和数据复杂性的增加,急需开发新的具有大数据处理能力的预测模型。周捷等[15]引入长短期记忆网络LSTM,对客户数据中的时序数据进行建模,显著地提高了流失预测效果;夏国恩等[16]针对数据中的离散特征,提出2 种基于多层感知机的处理方法,避免了维度灾难和数据稀疏的问题;CENGGORO等[17]通过在深度学习中的向量嵌入概念构建可解释模型,模型所生成的向量在流失客户和忠实客户之间具有高度的区分性;李波等[18]利用生成对抗网络生成少数类样本,在银行客户流失分类问题上取得良好的效果。
上述研究对提高客户流失预测模型的性能具有重要意义,但在高度不平衡客户数据处理方面仍存在以下不足:①在实际业务环境中,客户流失数据是一种高度不平衡的数据。然而,当前国内外关于不平衡客户流失预测的研究大都使用不平衡度较低或类别平衡的客户数据来验证提出方法的有效性,但是大部分数据仅有数千条样本,规模相对较小,这样的实验数据无法充分体现客户流失数据的特点。②客户流失预测领域中处理不平衡数据的手段比较单一,研究成果还不够丰富。单一的方法在大规模、高度不平衡客户数据的情况下都存在缺点,如欠采样通常会因为少数类样本个数太少导致采样后的训练集样本数量不足,预测模型无法充分学习数据特征;过采样会生成大量的少数类样本,增加数据集的规模,降低模型学习效率,并且客户数据特征复杂度较高,往往包含大量离散特征,生成样本难度大;基于代价敏感的方法则会因为流失客户数量太少而导致预测方法对其识别率较低。
1.2 不平衡数据分类方法
当前关于不平衡数据分类的研究主要从数据层面和算法层面给出解决方案[19-20]。数据层面主要包括在样本空间中进行的重采样方法和优化特征空间的特征选择方法;算法层面主要是优化样本权重的重加权方法,需要对分类算法进行修改,使其能够适应不平衡数据,提高少数类样本的识别率。由于文中主要研究重采样方法和重加权方法在高度不平衡客户流失预测中的应用,下文将从重采样、重加权两方面对不平衡数据处理方法进行概述。
(1)重采样。重采样通过调整训练集样本数量来平衡类别分布,常用的有欠采样(Under-sampling)、过采样(Over-sampling)等方法。欠采样以减少多数类样本数量的方式平衡不同类别样本的数量,最常用的欠采样方法是随机欠采样,然而随机欠采样存在多数类中的一些有用数据可能会被消除的局限性。研究者通过引入聚类[21]、实例选择[22]等策略,有效解决随机欠采样的局限性。过采样以增加少数类样本的方式,提高少数类样本的比例,进而提高分类模型对少数类样本的识别率。目前较为常用的方法是合成少数过采样技术(Synthetic Minority Oversampling Technique,SMOTE)[23]。PUSTOKHINA 等[24]利用多目标降雨优化算法(Multi-objective rain optimization)确定SMOTE 的最佳采样率,提出一种改进的综合少数过采样技术。
随着研究的深入,研究者将重采样技术融入集成学习,极大地提升了不平衡数据分类算法的泛化能力。RUSBoost[25]、EasyEnsemble[26]及基于自步学习的集成学习[27]等方法在多个数据集上拥有优秀的表现;ZHU 等[28]综合比较了在客户流失预测环境中处理类别不平衡的技术的性能,实验结果表明,所采用的评价指标对技术性能有较大影响,采用AUC 时,Bagging与随机欠采样的结合显示其优越性。
(2)重加权。重加权方法通过为不同类别甚至不同的样本分配不同的权重,降低分类方法在不平衡数据上的偏差。重加权中的代表性方法是代价敏感学习[29],其通常在代价矩阵中为不同类别数据设置不同的误分代价。平瑞等[30]认为代价敏感方法在高度不平衡数据上性能较差,由此基于聚类的弱平衡准则,提出一种处理高度不平衡数据的代价敏感随机森林;GAN 等[31]认为错误分类代价会随着样本概率分布的变化而变化,提出一种结合代价敏感分类算法的TANBN 算法,以提高分类精度;王俊红等[32]将代价敏感与欠采样相结合,在Adaboost 权重更新阶段赋予少数类更高的误分代价。与重采样方法相比,代价敏感学习方法通常仅在原始数据上修改损失函数,有效利用所有样本信息,计算效率更高,更适合处理大数据。
重采样方法和重加权方法各有优劣,组合使用两类方法,可以避免单一方法的不足,同时可以集成两类方法的优势,提高对少数类样本的识别率。
1.3 梯度提升决策树
2001年,FRIEDMAN 提出了梯度提升决策树[33](Gradient Boosting Decision Tree,GBDT)。GBDT 是以CART 树为基学习器的提升方法,利用前向分步和加法模型实现学习的优化过程,其核心思想是用损失函数的负梯度近似模拟提升树中的残差。假设训练集D=({x1,y1),(x2,y2),…,(xm,ym)},其中xi=(xi1,xi2,…,xid),yi∈{0,1},损失函数为L(y,(fx)),根据《统计学习方法》,GBDT算法过程如下:
初始化一个只有根节点的树,估计使损失函数极小化的常数值:
迭代训练N棵树,n=1,2,…,N。
对每个样本i=1,2,…,M,计算损失函数的负梯度,将其作为残差的估计:
将公式(2)中计算出的rni作为样本标签,拟合一个CART 回归树,得到包含J 个叶子节点的叶节点区域Rnj,j=1,2,…,J。
对j=1,2,…,J,计算叶子结点最佳拟合值,使损失函数最小化:
更新学习器:
得到最终学习器:
综上所述,目前在客户流失预测领域和不平衡数据分类方面的相关成果较多,但针对高度不平衡的客户数据进行的研究较少。因此,本研究构建一种融合多种不平衡数据分类技术的电信客户流失预测模型,以期为企业制定和实施客户留存策略提供参考。
2 聚类随机采样和代价敏感的集成学习模型
假设训练集D中的大类别样本集为N,小类别样本集为P。RWBC-Ensemble 首先对客户流失数据进行特征选择,降低特征维度,然后根据随机选择的采样率,从聚类后的N中随机选择部分样本与P组成不平衡度较低的训练子集,接着利用ENN 对训练子集进行数据清洗,最后在该子集上训练一个样本权重不对称初始化的GBDT。重复上述过程若干次后,集成所有GBDT的输出作为最终的预测结果。模型流程图如图1所示。
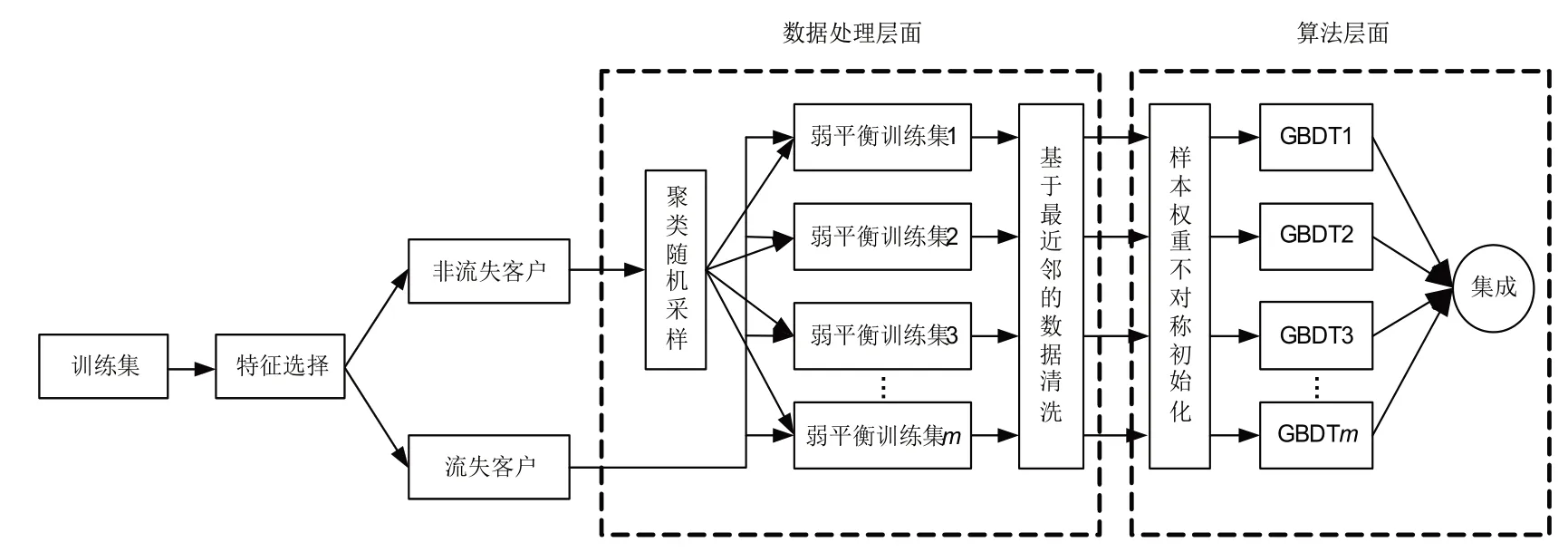
图1 RWBC-Ensemble流程图
2.1 特征选择
客户流失数据往往包含大量的连续特征和离散特征,若根据某种概率估计和分类决策函数规则从中选择出最优特征子集,仅利用部分特征构建预测模型,不仅可以减小特征中的噪声,而且可以降低后续预测模型的学习难度。在RWBC-Ensemble 中,研究利用XGBoost计算出的特征重要性筛选特征。
2.2 聚类随机采样
数据层面的欠采样方法通常以少数类样本数量为基准,对多数类样本进行下采样,达到平衡数据类别的目的。然而,在处理高度不平衡的客户流失数据时,完全平衡的欠采样容易造成多数类样本信息大量丢失。假设一个不平衡度为50的客户流失数据集,若流失客户有100 个样本,非流失客户则有5 000 个样本,欠采样后的新数据集仅有200 个样本,丢失98%的非流失客户数据。同时,1∶1 的采样比例并不一定是最佳的采样比例。采样比例对预测模型的性能具有重要的影响,最佳采样比例与数据本身有关,但是很难找到一个适用于多个数据的采样比例。此外,对多数类样本进行简单的随机欠采样,存在容易破坏数据分布的问题。
聚类随机采样策略尝试利用采样比例的随机性和重复性及聚类的“簇内相似度高,簇间相似度低”的特点解决上述问题。具体而言,首先,利用k-means聚类方法将非流失客户划分为多个类簇;其次,设置一个较低的采样比例列表,如可以将其控制在1~10之间,接着从中随机选择一个数值作为采样率,按比例从不同的类簇中随机选择若干样本组成新的非流失客户样本,以便保持非流失客户数据分布并利用更多的非流失客户数据;最后,通过多次采样,获得若干拥有不同不平衡度的数据集,从而可以利用集成学习的思想,降低单次、非最佳采样率对模型性能的影响,同时进一步提高非流失客户数据信息的利用率。
2.3 基于编辑最近邻的数据清洗
客户流失预测模型性能除受类别不平衡的影响之外,流失客户数据与非流失客户数据在分布上的重叠也是降低其性能的重要影响因素。清除决策边界附近的样本,可以令不同类别的样本更具有区分度。为此,本文在RWBC-Ensemble 中加入数据清洗模块,利用编辑最近邻方法(EditedNearestNeighbours,ENN)移除流失客户附近的非流失客户。
2.4 样本权重不对称初始化的GBDT
梯度提升树既适用于回归也可用于分类。用于回归问题时一般采用方差损失函数,处理分类问题时通常采用逻辑回归的对数损失函数[如公式(6)所示]。
在公式(6)中,每个样本的权重都是一样的。假设少数类样本的类别是1,多数类样本的类别为0,在数据类别不平衡的情况下,叶子结点中会存在较多的类别为0的样本,使多数类样本的权重大于少数类样本的权重。此时,模型的预测结果中会出现大量的类别0,导致预测结果出现偏差。
上文中,经过随机采样和数据清洗后的数据依然是不平衡数据,为使GBDT在这样的数据上保持稳定的预测性能,提出一种不对称初始化样本权重的方法。该方法根据数据类别间的比例,为不同类别的样本赋予不同的权重,构建代价敏感的GBDT。不同类别的样本权重的计算公式如下:
其中,α、β是权重调节系数,也是RWBC-Ensemble的超参数。
该样本权重计算方法主要受LANDESAVÁZQUEZ等[34]的启发,在其基础上将流失客户数据划分为安全样本wps和危险样本wpb,赋予危险样本更大的样本权重,并利用对数函数控制权重的衰减,其基本思想如下:首先,赋予所有样本相同的权重,即数据集D中样本数量的倒数;其次,根据数据的不平衡度,增加少数类样本的权重,令少数类样本的权重之和等于多数类样本的权重之和;再次,分别给少数类样本和多数类样本增加一个权重调节系数log(1-α)、log(α),便于根据需要进一步调整样本权重;最后,将少数类样本划分为安全样本和危险样本,赋予安全样本另外的权重调节系数β,进一步控制安全样本系数的变化。上述改变样本分布的策略,能够很自然地与随机采样等不平衡数据处理方法相结合,提高模型的预测能力。
3 实验结果与分析
为评估RWBC-Ensemble 在高度不平衡客户流失数据上的分类性能,研究选择4个高度不平衡的客户数据,以AUC 值、召回率(Recall)、精确率(Precision)为评估指标,将其与5 个欠采样集成方法[Easy-Ensemble[26]、BalanceCascade[26]、平衡随机森林[35](Balanced Random Forest,BRF)、RUSBoost[25]、基于自步学习的集成学习[27](Self-paced ensemble,SPE)]和2 个代价敏感集成方法[AdaCost[36]、Asymmetric Ada-Boost[37](AsymBoost)]进行比较。
3.1 数据说明
实验所用数据集的基本信息见表1。4 个客户数据集的不平衡度全部在50 以上,即非流失客户数量是流失客户数量的50 倍以上,是典型的高度不平衡数据。其中,CELL数据集采集自Kaggle 网站,共67 个特征;DUKE1、DUKE2、DUKE3数据集源自杜克大学,分别拥有171个特征,包括115个连续特征和56个类别特征。
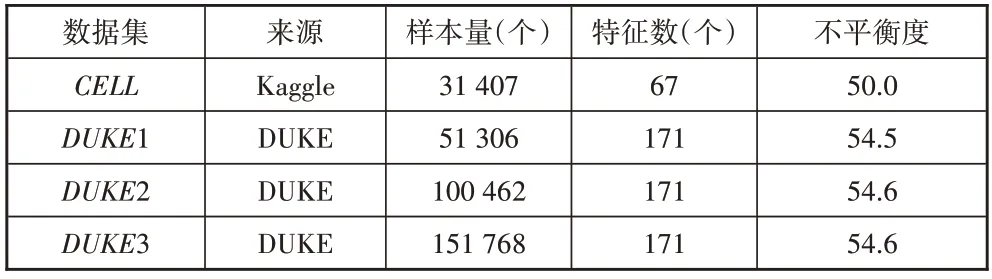
表1 数据基本信息
3.2 评价指标
在高度不平衡数据分类问题中,通常更关注少数类样本的识别率,然而由于多数类样本比重高,即使正确预测的少数类样本数量很少,依然能够获得高分类正确率,因此正确率并不能作为不平衡数据上预测算法的性能度量标准。实验采用AUC、Precision、Recall作为不平衡客户数据下流失预测模型的性能评估指标。AUC是受试者工作特征(Receiver Operating Characteristic,ROC)曲线下面积,ROC曲线以假正率(False Positive Rate,FPR)为横轴,真正率(True Positive Rate,TPR)为纵轴,ROC曲线下面积越大,模型的预测性能越好。Precision表示“预测出的流失客户中有多少是真正的流失客户”,Recall则是表示“流失客户中有多少被预测出来了”。根据客户流失预测混淆矩阵(见表2)。
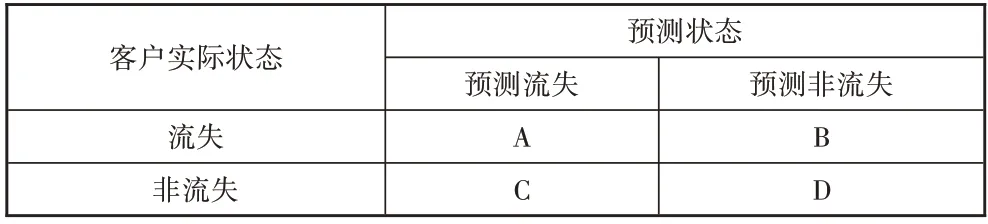
表2 客户流失预测混淆矩阵
Precision、Recall的计算公式如下:
3.3 实验设计
为降低数据集划分的随机性对实验结果的影响,文中所有实验均采用2 次5 折分层交叉验证的方式,即根据数据类别间的比例,将整个数据集划分为5份,保证每份数据的类别比例与原始数据的类别比例大致一致,每次选择其中的4 份作为训练集,剩余的1 份作为测试集。随机重复上述过程2 次,以10 次测试的平均值作为最后的评价指标结果。
RWBC-Ensemble 及所对比的7 种方法均为集成学习方法,基分类器的数量是预测结果的重要影响因素,为公平起见,首先将每个方法的基分类器的数量均设置为100,然后分别选取每个方法中比较重要的参数进行网格搜索寻优,选取的参数见表3。
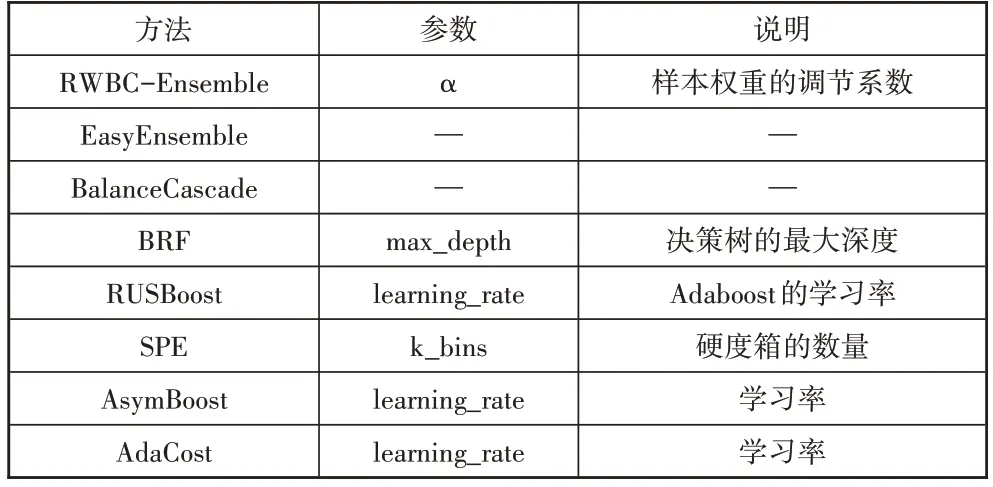
表3 算法参数说明
3.4 实验结果
为分析权重调节系数对模型性能的影响,并比较本文方法与其他方法的性能,共进行3 组实验,一组是不同权重调节系数下的模型性能对比实验;另一组是本文方法与5 个欠采样集成方法和2 个代价敏感集成方法的性能对比实验;最后一组是本文方法上的消融实验。
3.4.1 不同权重调节系数下的模型性能对比
本节给出不同权重调节系数下模型在3 个数据集上的性能变化(如图2所示)。由图2可知:①随着α取值的增大,模型的Recall提升较为明显,说明正确预测的流失客户数量不断增多;Precision呈现下降趋势,说明将非流失客户预测为流失客户的数量有所增加,这是因为当α取值较大时,模型更为关注少数类样本,即流失客户;AUC同样有所下降,说明模型虽然能够正确预测更多的流失客户,但是牺牲了非流失客户的预测准确度。②在4 个数据集上,当α取值在0.56、0.56、0.54、0.54 附近时,模型性能较为均衡。同时可以观察到,虽然DUKE1、DUKE2、DUKE3的不平衡度较高,但是随着数据规模的增大,模型在α取值较小时拥有较好的预测能力,表明随着流失客户数据量的增大,模型对流失客户数据特征的学习能力有所提升。
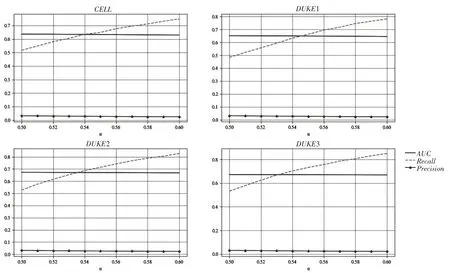
图2 不同权重调节系数下的模型性能
3.4.2 本文方法与其他方法的对比
本节给出本文模型及其他7 种模型在4 个数据集上的AUC、Recall、Precision值(见表4、表5、表6)。
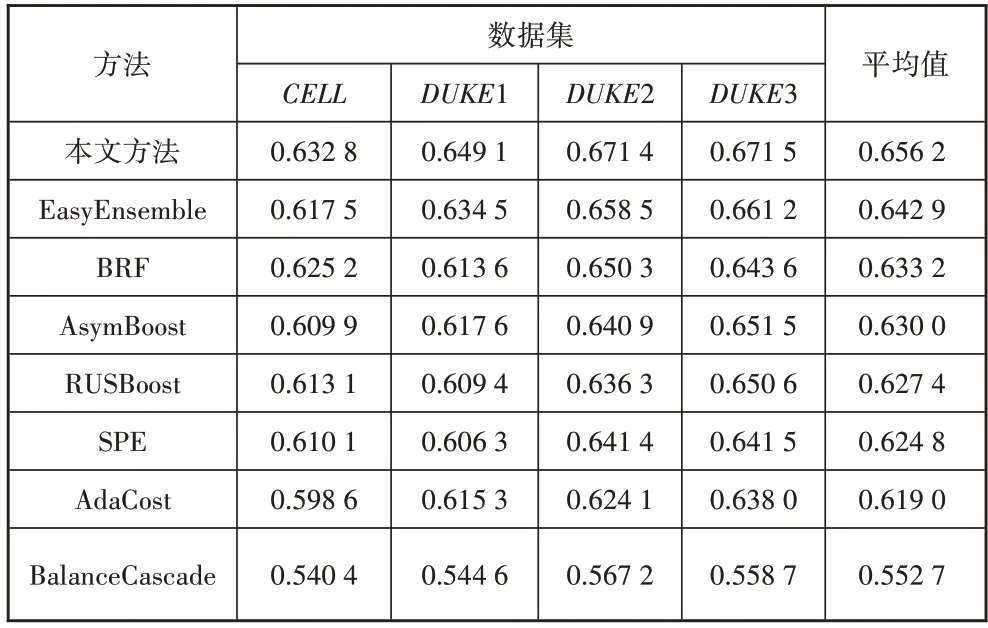
表4 不同算法的AUC对比

表5 不同算法的Recall对比
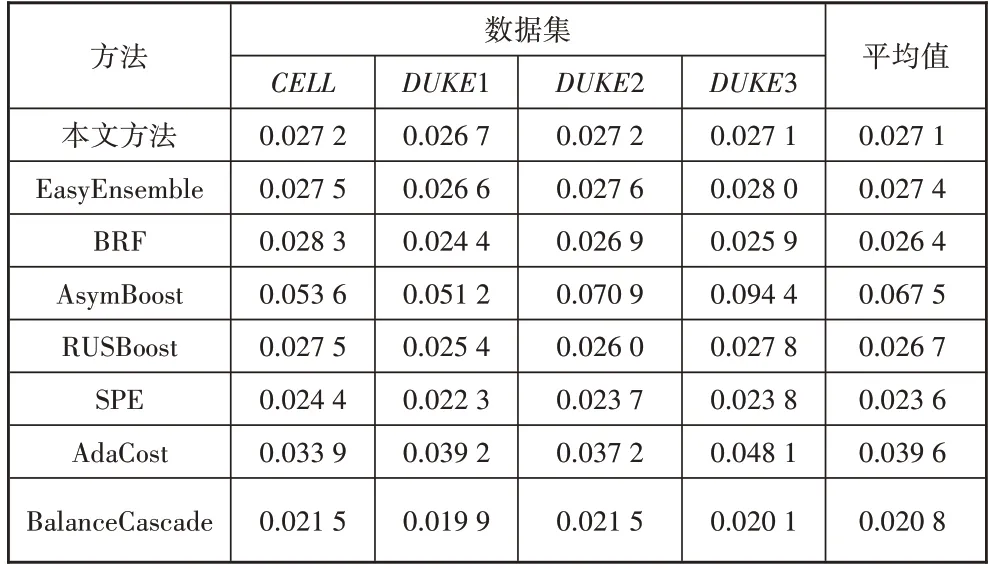
表6 不同算法的Precision对比
根据上述表中数据,可以得到以下结论:①本文提出的预测模型在4 个数据集上都取得最高的AUC值,与其他7 种方法相比,平均值高出3.76%,这表明,本文提出的预测模型在处理不平衡客户数据方面的整体性能最好。②本文提出的预测模型的Recall低于SPE,但仍然高于其他6种方法。SPE的Recall较高的主要原因是其牺牲了非流失客户的预测准确度。根据图2 可知,当权重调节系数α取值较大时,本文模型同样能够得到更高的Recall。③在Precision方面,本文提出的预测模型低于AsymBoost、AdaCost 等2种代价敏感集成方法。与EasyEnsemble、BRF等5种欠采样集成学习方法相比,本文提出的模型在4个数据集上的Precision平均值略低于EasyEnsemble,但仍然高于其他4种方法。AsymBoost、AdaCost的Precision值最高,但是其Recall值较低,说明在高度不平衡客户数据上,以AUC作为模型优化目标时,其分类结果偏向于非流失客户,正确识别的流失客户较少。④基于Bagging 架构的EasyEnsemble、BRF 和本文提出的RWBC-Ensemble 在3 个高度不平衡数据上具有更好的表现,在3 个方法中,RWBC-Ensemble 的性能最优。
3.4.3 消融实验
根据图2 所知,RWBC-Ensemble 在聚类随机采样和代价敏感的基础上,添加了特征选择和数据清洗2个数据处理模块,为验证其对模型预测能力的影响,研究设计了一组消融实验,实验结果见表7,其中FS表示特征选择模块,ENN表示数据清洗模块。
由表7可知,特征选择模块在不降低模型性能的情况下起到了移除噪声特征的作用,且在DUKE1 数据集上还有一定的提升。加入数据清洗模块后,模型的Recall提升较为明显,在AUC这个综合指标上也有提升,但是对非流失客户数据的清洗,对Precision指标有一定的影响,Precision略有下降。
综合以上分析,可以表明本文提出的RWBCEnsemble 模型对流失客户和非流失客户的识别能力较为均衡,整体预测性能最好。此外,通过调节α的取值可以识别更多的流失客户,对注重Recall的企业具有重要的参考价值。
4 结论
研究综合运用聚类随机采样、编辑最近邻、代价敏感、集成学习等多种不平衡数据处理方法,提出一种集成的不平衡客户流失预测模型,有效地改善了高度不平衡客户数据下的流失预测问题。实验通过与EasyEnsemble 等多个常用方法在4 个高度不平衡数据集上进行比较,结果表明,该实验方法能较好地避免欠采样、代价敏感等单一方法在高度不平衡数据上的缺点,进而使预测结果有较好的AUC、Recall和Precision值,具有较好的适用性和可行性。但是,客户数据往往具有高复杂度、高维度的特征,如何在数据特征上进行模型的改进与优化是下一步研究的重点。
猜你喜欢
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
海峡姐妹(2017年12期)2018-01-31
电信科学(2017年6期)2017-07-01
作文与考试·初中版(2017年12期)2017-04-19
新校长(2016年8期)2016-01-10
中学生(2015年12期)2015-03-01
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
河南科技(2014年15期)2014-02-27
