
遥感数据驱动的电力污秽等级XGBOOST 预测模型
2024-01-09 07:50周仿荣朱龙昌杨可意
地理空间信息 2023年12期
周仿荣,文 刚*,马 仪,张 辉,朱龙昌,杨可意,韩 舸
(1.电力遥感技术联合实验室(南方电网公司云南电网电力科学研究院),云南 昆明 650217;2.武汉大学遥感信息工程学院,湖北 武汉 430079)
近年来,通过大量实验室和自然环境的实验发现,电力污秽来源于绝缘子所处环境大气中的污染物。宿志一[6]证实大气污染是引起污闪事故的重要原因;胡霁[7]等发现利用PM2.5浓度观测可以提高绝缘子等值盐密(ESDD)的建模精度;熊宇[8]等将大气质量指数(AQI)引入ESDD 动态累积模型,成功提高模型预测精度;高嵩[9]等定量分析了降雨对污秽积累的冲刷作用。目前在单点尺度上利用大气环境数据和气象数据对电力污秽的积累预测取得较好的进展。但是,利用这些驱动因子进行区域性评估和电力污秽等级制图尚需要进一步探索[8,10]。要形成一种准确的电力污秽等级图绘制手段,还存在较大的差距[11-12]。
针对这一问题,本研究提出一种多源数据融合的电力污秽等级预测模型。在前人研究的基础上进一步引入夜间灯光遥感数据作为人类活动强度的量化指标,同时利用记录污染源信息的文本数据生成空间化的污染源核密度,并采用网格化排放清单表征多种大气污染物的排放量。以云南地区作为研究对象,利用形成的高维输入属性集合,以现有污区图为目标,采取XGBOOST 进行建模以完成污秽等级空间预测。
1 研究区与数据源
1.1 研究区概况
云南省位于我国西南部,大气环境质量在全国属于上游水平[13],因此云南省与现有电力污秽累积研究有很大的区别。云南省2018—2020年大气PM2.5数据显示,其全省年最大PM2.5质量浓度仅为53.2 μg/m3。由此可见PM2.5或AOD 不可能是该地区电力污秽的主要驱动因子,这为建立预测模型带来了巨大挑战。但也正是由于研究区的特殊性,在本地区能够适用的建模方法具有更强的移植能力。
1.2 实验数据
本文搜集到的多源数据信息主要分为四大类:遥感数据(包括夜间灯光数据[14]、归一化植被指数数据、大气环境数据)污染排放企业位置文本数据、气象数据、污染物网格化排放清单。本研究目标是建立面域预测模型,需要对原始数据进行预处理。将具有空间属性的卫星遥感数据和网格化排放清单统一到1 km的分辨率和相同的坐标系,以获得一致的空间数据。气象数据采用克里金插值转换为1 km分辨率的栅格型空间数据。污染企业信息将文本类型属性转换为点状矢量数据,再利用核密度分析和距离分析转换为1 km分辨率的栅格数据,并使用排放强度作为权重。
2 流程与方法
多源环境数据融合的电力污秽评估模型流程为:①搜集多源异构数据。为了完成污秽的空间评估,要求所有建模数据是时空数据。搜集到的数据中表征排放源信息的数据是文本类型,主要包括经纬度、排放强度分级和影响范围分级数据。本研究采用核密度分析和距离分析的空间分析手段将文本数据转换为空间数据。②对所有数据进行时空配准并进行数据清洗并剔除异常值。③使用2020 版云南省污区图作为标签图层,利用XGBOOST 建立输入数据到标签的映射关系,并采用十折交叉验证法训练和验证模型。④为了消除重采样排放清单数据以及某一变量重要性较高引起的锯齿效应,我们将采用引导滤波进行平滑处理,以获得云南全省污染等级的最终空间预测结果。
XGBOOST 是一种由GBDT(gradient boosting decision tree)算法发展而来的机器学习算法[15],其在集成学习的基础上,结合梯度信息,完成了对目标函数的优化,获得最优解。相比于GBDT,XGBOOST除了运用了损失函数的一阶导数信息外,还通过对损失函数的泰勒展开,获取损失函数二阶导数信息,更快获得最优解[16]。XGBOOST算法由一系列决策树组合而成:
式中,FS(forest sets)为决策树集合;xi为第i条数据的特征值所组成的向量;fn(xi)为第n个独立决策树,其中包含树的结构和权重信息;N为决策树的总量;为第i条数据的预测值。
XGBOOST 定义了损失函数Loss,通过训练集提供的数据训练,可以获取决策树的相关信息。
式中,L(yi,)为预测值和真实值yi间的损失函数,根据任务需求不同,选取的损失函数种类不同,本研究中选取multi-softmax作为预测值和真实值yi间的损失函数。M为训练集数量,Ω(fn)为决策树的正则项,防止树结构过于复杂,产生过拟合现象。
XGBOOST通过多轮迭代获取最优解,其中第t轮的损失函数可表示为公式(3)。
为了方便后续求导过程,将公式(4)代入公式(3)可获得t轮的损失函数的简便表示。
为求取第t轮损失函数中叶子权重的最优解,对第t轮迭代的损失函数Losst进行二阶泰勒展开可以得到公式(6):
式中,Δft(xi)为第t轮预测值与第t-1 轮迭代的增量;gi和hi分别为L(yi,̂ )的一阶导数和二阶导数;Ij={i|q(xi=j)}为第j颗树所有叶子的权重;为Ω(ft)的代数形式。
在公式(6)的基础上对w求偏导,可以得到第j棵树的叶子权重在第t轮的迭代情况下的最优数值
通过设定迭代次数和决策树的结构信息,我们可以获得在给定数据集情况下训练好的XGBOOST 模型
引导滤波(guided filtering)和双边滤波(BF)、最 小 二 乘 滤 波 (WLS) 是 三 大 边 缘 保 持(edge-perserving)滤波器[17]。他们在保持边缘的基础上,对图像进行了平滑操作。
引导滤波定义了在给定引导图像I 和原始图像p的条件下,输出图像q 可以表示为公式(8),其中wk为滤波核大小,ni为噪声。
通过求解代价函数E(ak,bk),可获得ak和bk,其中为正则约束项。
分别对ak和bk进行求导,可以获得给定滤波窗口wk范围内的最优估计值
3 结果分析
本文使用十折交叉验证法对构建完成的数据集进行训练,利用XGBOOST 模型在测试集上进行验证,最终取得了87%的精度。图1~3 展示了电力系统现行的污区图、基于多源遥感数据的XGBOOST 模型直接输出结果以及采用引导滤波后的结果。

图1 云南省2021年电力系统污区图(审图号:GS(2019)1822号)
对比图1~3,发现对于电力系统最为关心的高风险区域(1~3),图2 与图1 非常接近,很好地还原了由工业排放引起的局部高风险区域。与熊宇等的结果相比,本研究结果对于重污染地区(1~2)的预测表现更为优秀。这是由于本研究利用夜间灯光遥感产品更准确地刻画了人为排放的分布情况,同时XGBOOST算法的性能比支持向量机等传统分类器更为优越。
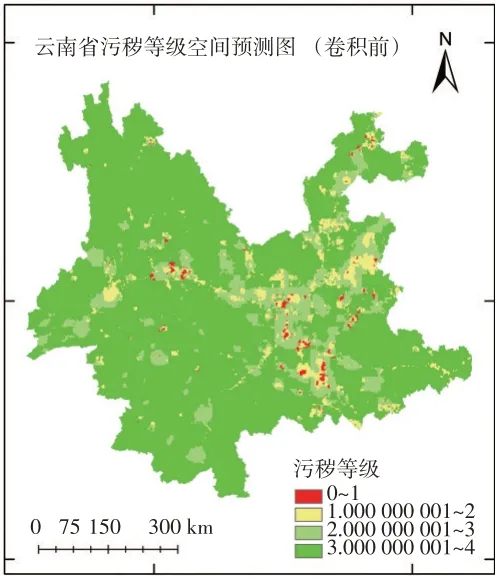
图2 利用多源环境数据和XGBOOST算法得到的云南省电力系统污区图(审图号:GS(2019)1822号)
图3 表明引入引导滤波可以显著的抑制在局部空间上,由于排放清单的低空间分辨率导致的粗糙不平滑的边缘。可以明显观察到,通过引导滤波卷积后的预测结果在空间分布上与污秽等级实测图更接近,边缘也更加平滑,更符合污秽等级分布的真实情况。
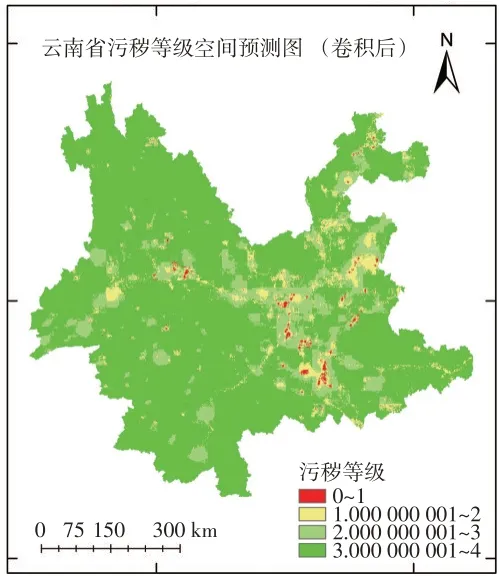
图3 经过引导滤波后的云南省电力系统污区图(审图号:GS(2019)1822号)
为了更好地定量评价本文所提方法的预测精度,表1 展示了最终预测结果与现行污区的混淆矩阵。从电网安全的角度看,较为严重污染等级(1~3)的地区更受重视,这些地区往往需要更为频繁的清污工作。但是,从图1 可以看出,1~3 等级的地区在面积上的占比不大。如果以总体精度为考察对象,最极端的模型可以通过将全部地区划分为等级4来取得0.8以上的精度,这显然与应用初衷不相符。表1显示,本文所提模型对于每一类的预测精度都达到0.8以上,并没有通过牺牲1~3 类别预测精度来实现总体的高精度。这是本方法一个重要的特征和明显的优势。这表明本方法得出的结果不仅具有数学意义上的有效性,更重要的是对于指导电力系统的实际工作具有巨大的价值。

表1 模型预测性能评价混淆矩阵
4 结果与讨论
本文预测精度优于传统污秽等级预测方法,我们认为这与引入了夜间灯光数据相关。夜间灯光数据很好地表征了与污染程度存在紧密相关性的人类活动的强度,使得高分辨率的夜间灯光数据在很大程度上弥补了排放数据低分辨率的缺陷,从另一个角度表征了预测点的环境污染情况,进而使得预测精度获得了提升。
决策树中,子树的分裂往往决定了最终整体树的分类效果。特征参与子树分裂的次数越多,该特征在分类中的作用越大。在上述预测精度的情况下,图4按照数据集的统计顺序给出了每种属性数据参与子树分裂的次数占总次数的频率。从图4 可见,污染气体排放数据如OC、NOX、SO2、VOC以及NO2和SO2的遥感数据在预测中仍然起了较大作用,几种排放数据的累计重要性占比达到了51.9%,超过一半。对于PM2.5和PM10,由于2 种数据在统计性质上高度相关,它们的重要性占比相近。此外,夜间灯光属性占比达10.4%,证明了夜间灯光数据在实际分类过程中起到了很大作用,提高了预测精度。实验结果表明,提高污染气体遥感分辨率和精度,引入夜间灯光数据,有助于提高污秽监测的预测精度。
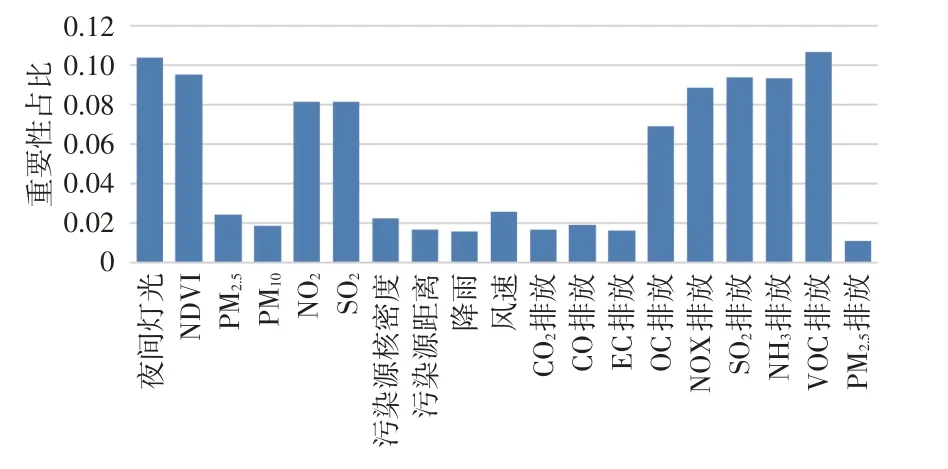
图4 输入参数在模型中的重要性排名
5 结 论
本文借助机器学习中XGBOOST 算法,利用包括大气环境、气象、夜间灯光遥感数据、污染源核密度,网格化排放清单表在内的多源数据,作为驱动因子对云南省进行污秽等级预测,并与实测污秽等级分布进行比较。实验结果表明,本文所提方法在污秽等级预测上与现有污区图吻合率达到87%,单一种类的预测精度均达到80%以上,表明了多源数据融合的电力污秽等级XGBOOST 预测模型在污秽等级预测上具有良好的潜力。
猜你喜欢
飞天(2021年6期)2021-06-28
西安交通大学学报(2021年2期)2021-02-22
成都信息工程大学学报(2019年3期)2019-09-25
西南交通大学学报(2018年6期)2018-12-18
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
西安工程大学学报(2016年2期)2016-06-05
空间控制技术与应用(2015年3期)2015-06-05
遥测遥控(2015年2期)2015-04-23
郑州大学学报(医学版)(2015年1期)2015-02-27
