
An improved algorithm for adapting YOLOv5 to helmet wearing and mask wearing detection applications
2024-01-08 09:11:50ZHANGYouyuanYANGGuiqinDIAOGuangchaoSUNCunweiWANGXiaopeng
ZHANG Youyuan,YANG Guiqin,DIAO Guangchao,SUN Cunwei,WANG Xiaopeng
(1.School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China;2.School of Information Science and Engineering,Lanzhou University,Lanzhou 730000,China;3.School of Computer Science and Engineering,University of Electronic Science and Technology,Chengdu 611731,China)
Abstract:In order to achieve more efficient detection of wearing helmets and masks in natural scenes,an improved algorithm model YOLOv5+ is proposed based on the deep learning algorithm YOLOv5.For target detection tasks,small targets are usually detected on a large feature map.Considering that most of the detected objects are small-scale targets.Therefore,when the input image size is 640×640 pixels by default,a feature map of size 160×160 pixels is added to the detection layer of the original algorithm,and complete intersection over union (CIoU) is selected as the loss function to achieve more effective detection of helmet wearing and mask wearing.The experimental results show that the mean average precision (mAP-50) of the YOLOv5+ network model reaches 93.8% and 92.3% on the helmet-wearing and mask-wearing datasets,respectively,which is both improved compared to the precision of the original algorithm.This method not only meets the speed requirement of real-time detection,but also improves the precision of detection.
Key words:YOLOv5; CIoU; helmet wear detection; mask wear detection; adaptation to small target detection
0 Introduction
It is especially important to wear helmets and masks on specific occasions.Otherwise,there will be serious safety hazards and risks of pandemic outbreak.The usual detection methods include manual inspection and real-time monitoring of surveillance images.However,manual inspection is time-consuming and labor-intensive,and real-time monitoring of surveillance images requires supervisors to keep a close eye on the screen for a long time,making it easy to misjudge.In recent years,with the booming development of some new technologies such as 5G technology,Internet of things,cloud computing,big data,and artificial intelligence,it is possible to replace some of the relatively inefficient technical means with better ones.
Deep learning can automatically extract features from images,avoide the subjectivity of manual feature extraction and has been widely used in target detection and classification problems.Therefore,deep learning-based target detection algorithms are gradually becoming the mainstream of target detection algorithms.Mainstream target detection algorithms are divided into two main categories.The first category is two-stage target detection algorithms,represented by regions with CNN features (RCNN)[1],Fast-RCNN[2],Faster-RCNN[3],etc.This type of algorithm divides the target detection into two steps.Firstly,a sliding window is used to obtain the candidate regions on the image and the feature vectors of the candidate regions are extracted.Secondly,the candidate regions are classified and their positions are predicted by using methods such as regression.The two-stage target detection algorithm implies a cascade structure,which improves the precision of detection to a certain extent.
However,the expansion of the algorithm model causes an increase in computation and slows down the detection speed,which makes it difficult to meet the real-time requirements.The second category is one-stage target detection algorithms,represented by single shot multibox detectior (SSD)[4],you only look once (YOLO)[5-10]series of algorithms,etc.This type of algorithm omits the stage of candidate region generation,and directly obtains target classification and location information,which improves the speed of target detection to a certain extent.
Some scholars have donemany researches on the detection of wearing helmets and masks.Liu et al.[11]obtained the area above the face by detecting the skin color,extracting the Hu moment as the feature vector and using the SVM model to realize the helmet detection.Wu Dongmei et al.[12]proposed an improved helmet recognition method based on Faster-RCNN,which merged the feature layers obtained in multiple stages and performed multi-scale detection to make the network model optimal.Wang et al.[13]improved the YOLOv3 algorithm,designed a new objective function to make the objective function IoU locally optimal,and realized the optimization of helmet detection.Xiao Junjie[14]applied the YOLOv3 and YCrCb methods to achieve 89% mAP detection for masks.Guan Junlin et al.[15]used the YOLOv4 method to identify mask wearing,and the detection effect was relatively satisfactory,which basically met the needs of mask wearing detection in most occasions.
Although these target detection algorithms have achieved good results,some problems still exist.For instance,the research on small target detection is still immature,and the resolution of small targets is low and the pixel share is small.The low resolution of small target objects decides that very limited useful information can be extracted during the detection process.The deep perceptual field in the convolutional neural network is large,and the feature map keeps decreasing after multiple downsampling,which makes it more difficult to extract features,leading to the existence of missed and false detections for small target detection.
A simple and efficient improved network model is proposed,in order to solve the problem of poor results and high leakage rate in the detection of small and medium-sized targets such as helmet and mask wearing.Firstly,the YOLOv5 network structure is modified,and the detection scale is extended to four scales.In addition,complete intersection over union loss (CIoU_Loss)[16]is used to replace generalized intersection over union loss (GIoU_Loss)[17]as the loss function.It made the regression of the bounding box more stable,so as to better adapt to the detection of helmet and mask wearing.The network is trained on the self-made helmet and mask wearing datasets,and the trained YOLOv5 network model is used for testing.After a variety of tests such as pictures,videos,cameras,etc.,the missed detection rate of the designed model has been decreased,the detection precision has been significantly improved,and it meets the actual detection requirements.
1 Network structure and improvement of YOLOv5
1.1 Network structure of YOLOv5
YOLOv5 is classified into YOLOv5s,YOLOv5m,YOLOv5l and YOLOv5x,according to the network depth and the width of the feature map,among which YOLOv5s has the smallest volume.YOLOv5s is chosen as the detection model.The network structure and its main modules are shown in Fig.1.The model is mainly divided into three parts:input,backbone and head.
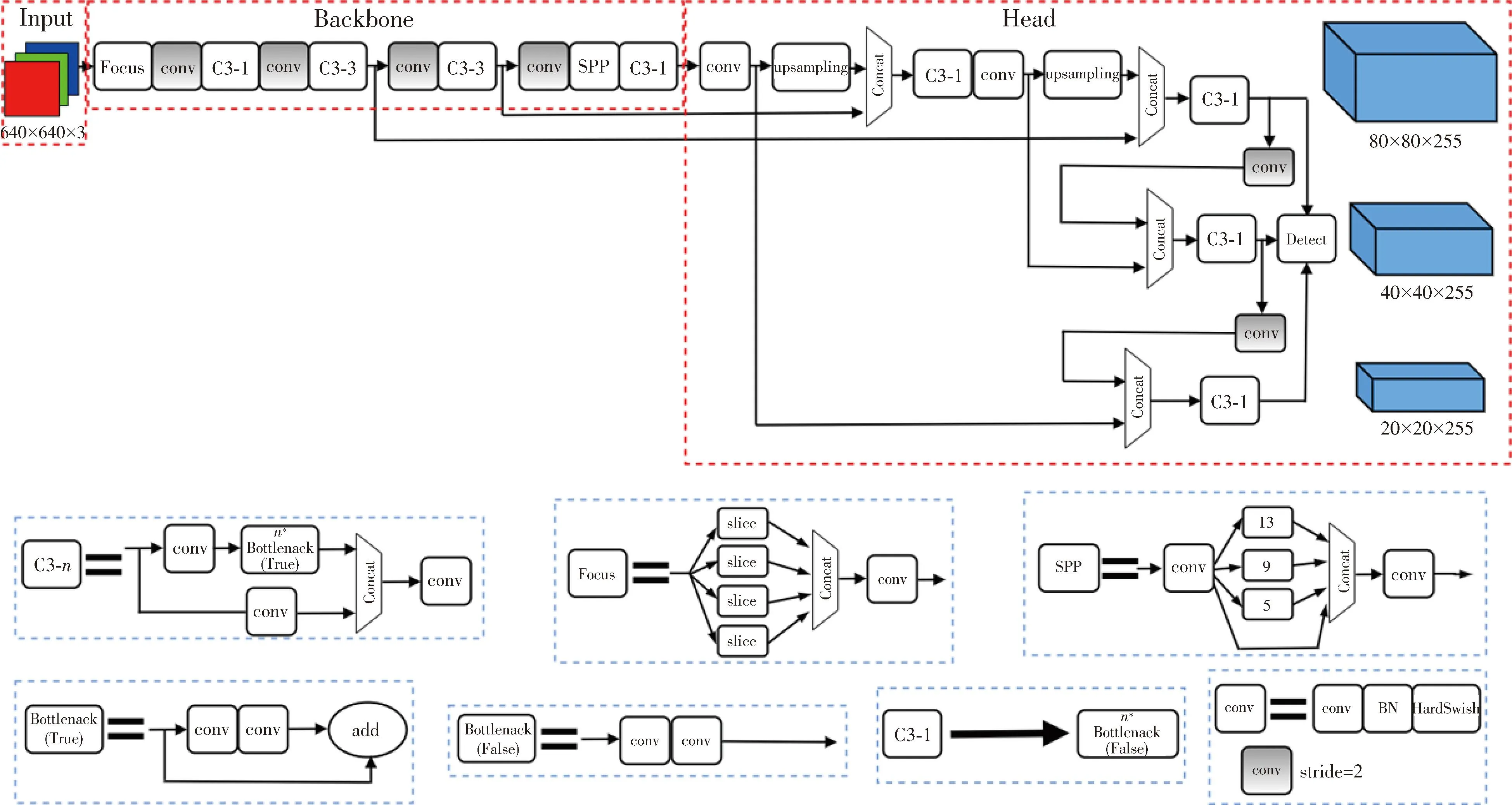
Fig.1 YOLOv5 network structure
Input:Scaling images and mosaic data enhancement are adapted to achieve automatic calculation of the best anchor box values for the dataset.The length and width of different pictures are different,so the common way is to scale the original picture to a standard size and then send it to the detection model for training.The standard size of the designed picture is 640×640×3 pixels.YOLOv5 and YOLOv4 both adopted Mosaic data enhancement method,which randomly calls 4 images and performs random size,distribution and stacking.It makes the data richer and adds many small targets to improve the recognition ability of small objects,which meets the demand of small target detection like helmet and mask.The initial anchor box values need to be set before training the network.By adapting the anchor box,YOLOv5 will automatically learn the size of the anchors according to the labels of the new dataset.Steps are as below.The prediction box is output on the basis of the initial anchor box,which is then compared with the ground truth (true box).The custom dataset is analyzed by usingk-means and genetic learning algorithms.In the end,a predefined anchor box suitable for object bounding box prediction in the custom dataset is obtained.
Backbone:Backbone mainly contains focus structure,cross stage partial network (CSPNet) structure and spatial pyramid pooling (SPP) module.The focus structure is shown in Fig.2,and the key step is the slicing operation.The data is first sliced into 4 parts,each of which is equivalent to twice the downsampling.Then it is spliced in the channel dimension.Finally,it is convolved,and the main purpose is to speed up inference.The main purpose is to accelerate the inference speed.By taking the structure of YOLOv5s as an example,inputting a 640×640×3 pixels image into the focus structure and using the slicing operation,it first becomes a feature map of 320×320×12 pixels.And then after a convolution operation of 32 convolution kernels,it finally becomes a feature map of 320×320×32 pixels.CSPNet mainly performs partial cross-layer fusion.By integrating the gradient changes into the feature map from beginning to end,the precision is guaranteed while reducing the amount of calculation.The SPP module consists of three main parts:conv,max pooling and concat,and the main purpose is to increase the perceptual field and extract the most important multifaceted features without slowing down the network operation.
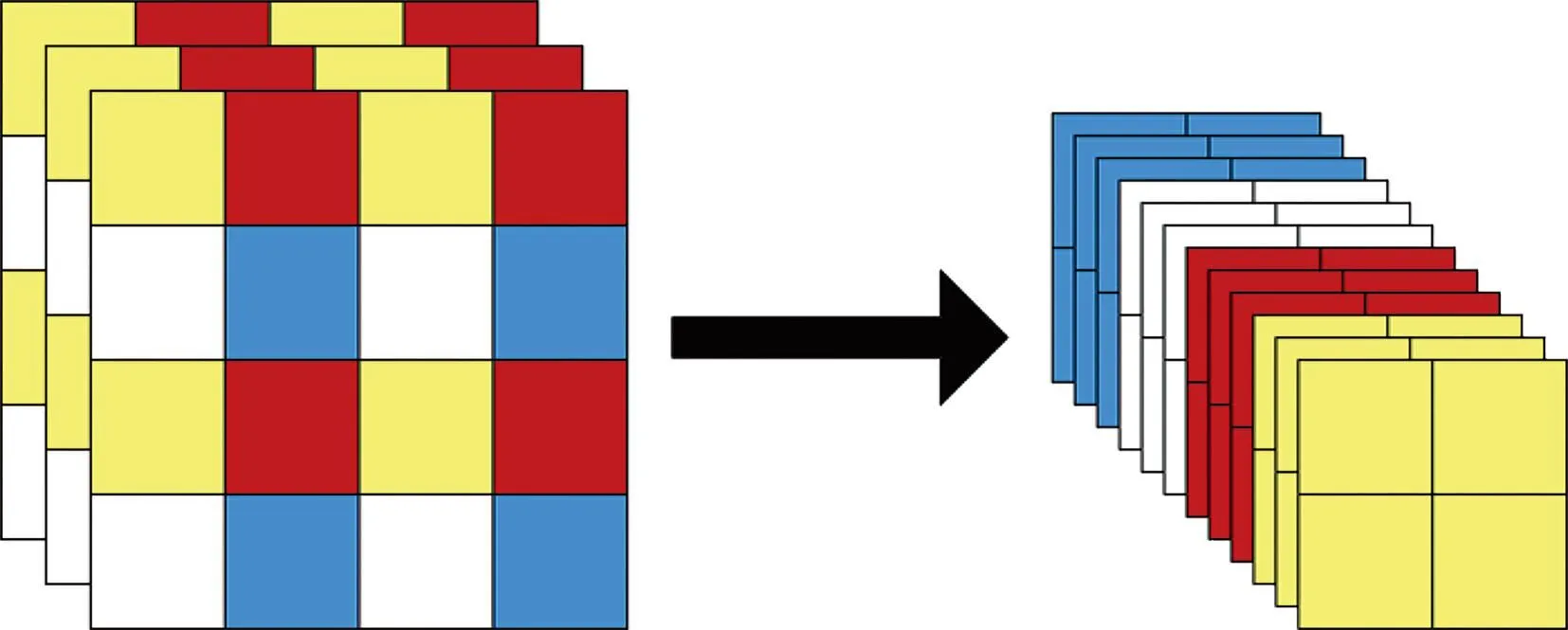
Fig.2 Focus slicing operation
Head:Head mainly contains PANet and Detect modules.Path-aggregation network (PANet)[18]mainly enhances the accurate positioning of the information flow in the lower layer through the bottom-up path,and establishes the information path between the low-level features and the high-level features,and thereby enhance the entire feature hierarchy.The detect module includes bounding box loss function and non-maximum suppression (NMS).In the output part,many target boxes that appear are filtered,and the weighted NMS operation is used to obtain the optimal target box.
1.2 Improved YOLOv5 model
1.2.1 Improvement of network structure
The YOLOv5 model has the characteristics of fast recognition and high detection precision.However,in order to achieve proprietary detection of small and medium-sized targets such as safety helmets and masks,and improve the precision of detecting wearing safety helmets and masks,the network structure of the YOLOv5 model needs to be further optimized and its parameter needs to be adjusted to better adapt to the detection of the specific tasks.
There are only three detection layers in the original YOLOv5 model,corresponding to three sets of initial anchor values.When the input image size is 640×640 pixels,the feature map of size 80×80 pixels in the detection layer can be used to detect targets of size 8×8 pixels or more.The feature map of size 40×40 pixels in the detection layer can be used to detect targets of size 16×16 pixels or more.The feature map of size 20×20 pixels in the detection layer can be used to detect targets of size 32×32 pixels or more.Considering that most of the helmets and masks to be detected are small targets,it is necessary to detect them in a larger feature map.
The improved network model YOLOv5+ is shown in Fig.3.It adds a feature map with a size of 160×160 pixels to the detection layer of the original algorithm,and adds a group of smaller anchor values.The anchor values present the initial values of the target width× height,and it is necessary to regress the offset between the real width×height and the initial width×height.Hence,it is needed to calculate best bossible recall (BPR) in the code by comparing the difference between the values of anchor and the values of the ground truth (real box).BPR can define the matching degree between anchor and label.The maximum value of BPR is 1.When BPR is below 0.98,it will be re-clustered and the anchor values will be calculated.Otherwise,it will return to the default setting of anchor values.The anchor values can be more consistent with the actual training data by adjusting the model parameters to update the anchor values through the adaptive anchor box.
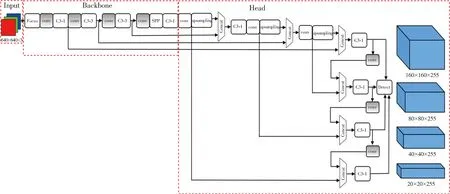
Fig.3 YOLOv5+ network structure
The YOLOv5+network model continues to upsampling the feature map after the 17th layer in the original algorithm network structure,so that the feature map continues to expand.In the 19th layer,the acquired feature map of size 160×160 pixels is fused with the 2nd layer feature map in the Backbone network with concat function.A larger feature map is obtained for small target detection.
1.2.2 Choice of loss function
GIoU_Loss is used as the loss function by the usual YOLOv5 for the bounding box regression.First,the minimum closed areaCof the two boxes is calculated,then intersection over union (IoU) is calculated.IoU is the intersection ratio between the predicted bounding box and the ground truth box.It can be expressed as
(1)
After that,the proportion of the closed area that does not belong to the two boxes in the closed area is calculated,and finally IoU is used to subtract the above-mentioned proportion to get GIoU[17].The step can be expressed as
(2)
However,GIoU has certain shortcomings.As shown in Fig.4,when the prediction box is inside the target box and the prediction box size is the same,the difference sets of the prediction box and the target box are the same at this time,and therefore the GIoU values of all three states are also the same.At this time,GIoU degenerates into IoU,and cannot distinguish the relative position relationship.

Fig.4 Prediction box contained inside target box
Zheng[18]proposed the DIoU to address the problems arising from GIOU.Similar to GIoU,DIoU can still provide the moving direction for the bounding box when it does not overlap with the target box.And DIoU can directly minimize the distance between two target boxes,so it converges faster than GIoU.DIOU is expressed by
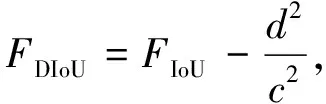
(3)
whered=ρ2(b,bgt) represents the Euclidean distance between the center point of the prediction box and the actual box,in whichbandbgtrepresent the center point of the prediction box and the ground truth box;crepresents the diagonal length of the rectangular closed area of both.As shown in Fig.5,when the target frame includes prediction frames,and the positions of the center points of the prediction frames are the same,the DIoU_Loss values of the three are the same.

Fig.5 Center point of prediction box is in same position
Considering these problems,CIoU[16]is improved on the basis of DIoU as the loss function to perform the bounding box regression.CIoU takes into account the overlap area,center point distance and aspect ratio of the target,making the bounding box regression more stable.The CIoU_Loss calculation formula is
(4)
whereρ2(b,bgt) represents the Euclidean distance between the two center points of the predicted box and the actual box;crepresents the diagonal distance of the smallest closed area;αrepresents the weight function;υis used to measure the similarity of the ratio between the detection box and the real box.The equations forαandυare
(5)
(6)
2 Experiment and analysis
2.1 Experimental environment and dataset
The experiment based on the pytorch 1.7.1 framework,the programming language is python3.8,the CUDA version is 11.2,the GPU is GeForce RTX 2080 Ti,and the operating system is Windows 10.
Since there is no publicly available dataset of helmet wearing and mask wearing in complex scenes,10 114 helmet wearing images and 8 000 mask wearing images are collected from online crawlers,field shots and real-world masked face dataset (RMFD) as the dataset.RMFD is the world’s first mask wearing dataset made public for free by Wuhan University in March 2020 and can be downloaded at https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset.The images in the dataset contain various angles,multiple and single targets,distances,occlusions,etc.,and they are labeled by the labelimg tool.An example dataset is shown in Fig.6.The dataset is labeled with labelimg for image targets,and the entire dataset is randomly divided into a training set and a test set with the ratio of 8∶2.The division of the dataset is shown in Table 1.

Table 1 Dataset division

Fig.6 Example dataset
2.2 Model training
YOLOv5s is chosed as the base model,and the improvement algorithm is also based on YOLOv5s.The stochastic gradient descent (SGD)[19]optimization algorithm is used for training.The initial learning rate is 0.01,and the cosine annealing strategy is used to dynamically reduce the learning rate.The momentum factor is set to 0.937,the weight decay coefficient is 0.000 5,the Batch size is 32,the epochs are 100,and the first three epochs are used as model warm-up.CIoU_Loss is used as the loss function.
In this experiment,the model is evaluated by using two main metrics:average precision (AP) and mean average precision (mAP).The mAP index is used for the evaluation of multi-label image classification tasks,and it is an important index to measure the overall detection precision of the model in multi-category target detection.If the mAP value is higher,it means that the comprehensive performance of the model in all categories is higher.The calculation of the indicator uses the concepts of precision and recall.It is expressed by
(7)
(8)
whereFTP(True positives) indicates the number of targets that are correctly detected;FFP(False positives) indicates the number of targets that are detected in error;FFN(False negatives) indicates the number of targets that are not detected;FPrecisionrepresents the proportion of the correct number of predictions in a certain category of prediction targets to the total correct samples;FRecallrepresents the ratio of the correct number of prediction targets to the total prediction samples.
AP-Rcurve is constructed with recall as the horizontal axis and precision as the vertical axis.The area under the curve is AP.AP50 represents the area enclosed by theP-Rcurve and the coordinate axis when the IoU threshold is 0.5.The AP50 formula is expressed as

(9)
The average precision mAP50 for all categories of targets can be expressed as
(10)
whereNrepresents the number of classifications;FAP50irepresents the average precision when the IoU threshold of a single target is 0.5.
2.3 Analysis of experimental results
2.3.1 Comparison of small target detection results
In order to verify that the addition of feature maps of 160×160 pixels in the YOLOv5+ algorithm helps to improve the precision of the network’s recognition of small targets,two test experiments are carried out in a specific screened dataset that mainly contains small targets.Firstly,100 tested images are screened.Then a total of 238 targets wearing masks and not wearing masks are counted.And there are a total of 380 targets wearing helmets and not wearing helmets.As shown in Fig.7,it is a partial preview of the picture to be tested.Each picture contains two scenes,a few small targets or multiple small targets.Then the same dataset is used to train two models.The first is a model trained on the basis of the original YOLOv5 algorithm,and the second is a model trained in the network after adding feature maps of 160×160 pixels detection head to the original YOLOv5 network.Finally,the evaluation parameters of these two models and the test results of small targets are compared and analyzed.

Fig.7 Some test pictures
In order to verify the effectiveness of the network structure after adding the feature map of 160×160 pixels,the data is selected that meets the small target in the RSOD[21-22]public data set for experiments.Fig.8 is the mAP0.5 curve change graph of the original algorithm and the improved algorithm during the training process.Fig.9 is the loss curve of the original algorithm and the improved algorithm during the training process.It can be seen from Fig.8 that the maximum mAP0.5 of the algorithm after adding the small target detection layer is higher than the maximum value of the original algorithm.It can be seen from Fig.9 that the overall loss curve after adding the detection layer is lower than that of the original algorithm.Therefore,the model after adding the feature map of 160×160 pixels is more suitable for detecting small objects.
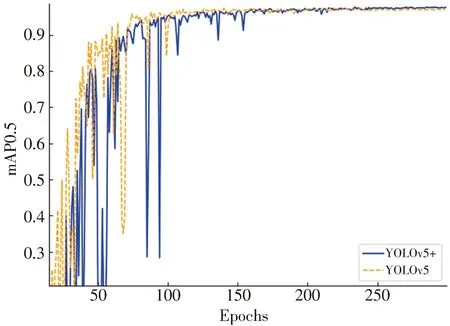
Fig.8 Comparison of model mAP0.5 curves before and after adding detection layer
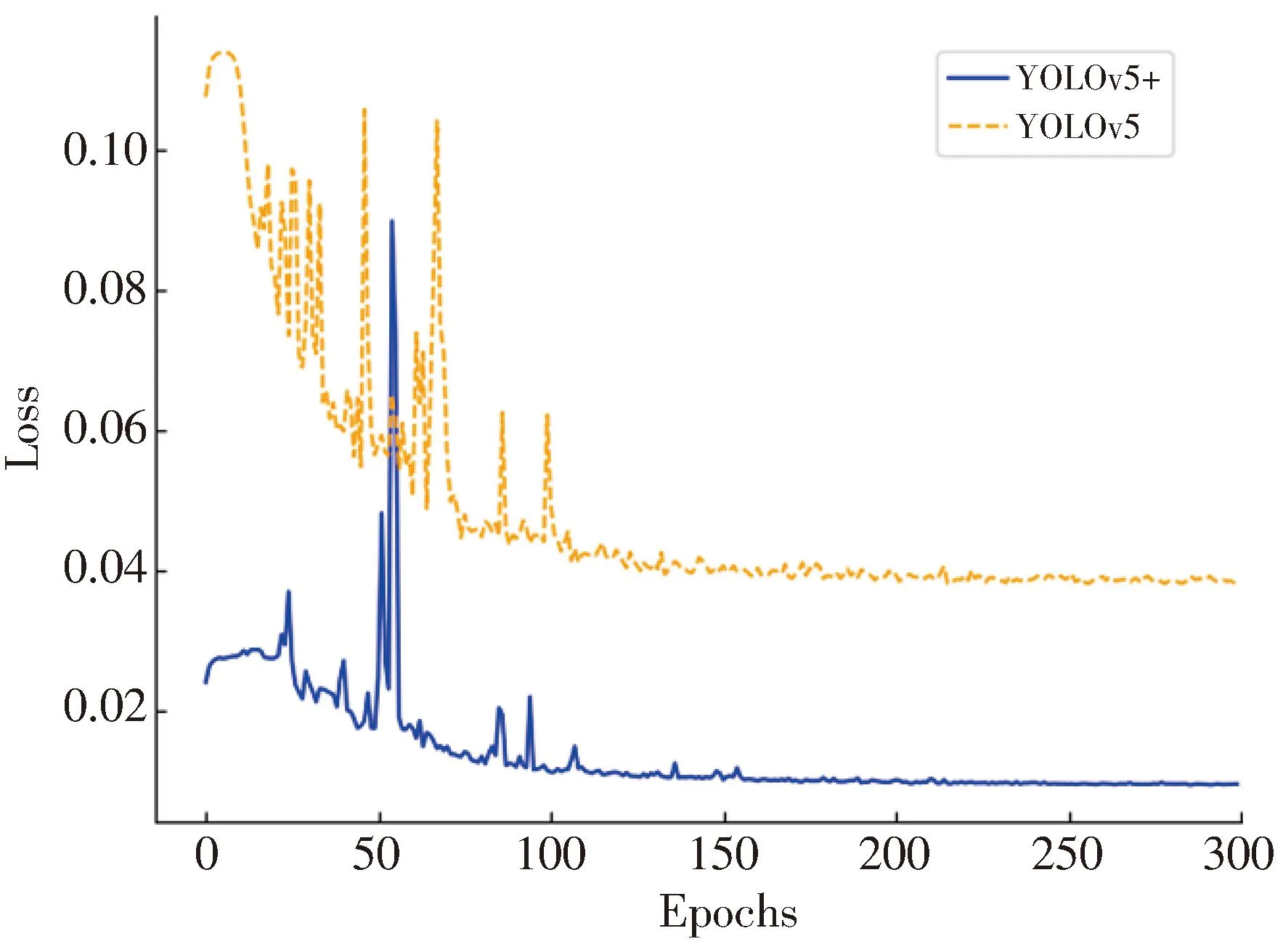
Fig.9 Comparison of loss curve of model before and after adding detection layer

Fig.10 Mask wearing single target detection

Fig.11 Mask wearing multi-target detection

Fig.12 Helmet wearing a few target detection
The mask wearing test results of the two models are shown in Figs.10 and 11.It can be seen that the training model YOLOv5+ with the addition of feature map of 160×160 pixels has improved recognition precision compared to the model trained by the original YOLOv5 algorithm.Both single-target mask wearing recognition and multi-target mask wearing recognition have better performance than the original algorithm model.
Similarly,the test results of the two models for wearing helmets are shown in Figs.12 and 13.It can be seen that the training model YOLOv5+ with the addition of feature map of 160×160 pixels is better than the model trained by the original YOLOv5 algorithm.The detection precision of the helmet wearing recognition is better and the accuracy is higher.
In order to better reflect that the model trained by adding feature map of 160×160 pixels has better recognition precision.The 100 test pictures extracted are tested with two models,and various data are counted.As shown in Table 2,it is a statistical table of the test data of the original YOLOv5 algorithm model.
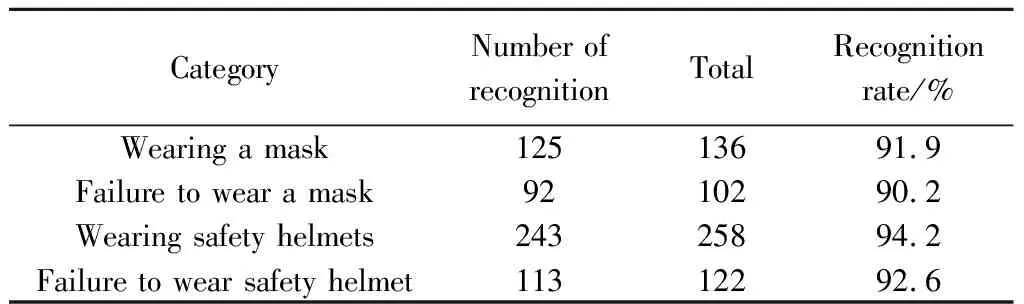
Table 2 Original YOLOv5 algorithm test results
Table 3 is the test results trained by the YOLOv5+ model after the feature map of 160×160 pixels has been added.By comparing with the Table 2,it is found that the recognition rate has been improved to a certain extent.

Table 3 Improved YOLOv5+ algorithm test results
2.3.2 Comprehensive experimental analysis
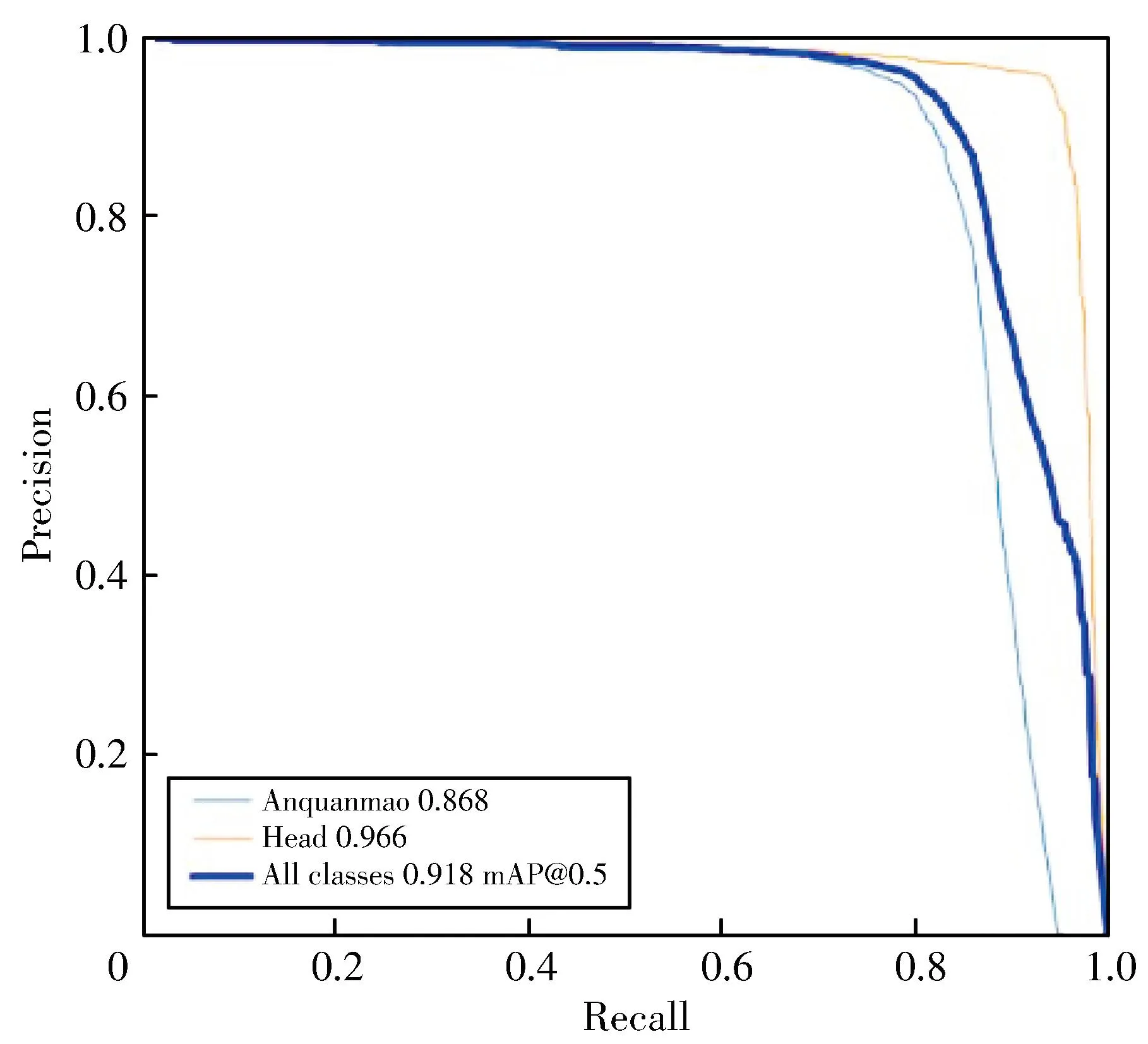
The YOLOv5 algorithm is compared with the improved YOLOv5+ algorithm,and the two algorithms are compared in the same environment.TheP-Rcurves of YOLOv5 and the improved algorithm for head target and helmet wearing target detection are respectively shown in Fig.13,and theP-Rcurves for face unmasked target and face target detection are shown in Fig.14.

Fig.13 Helmet wearing most target detection
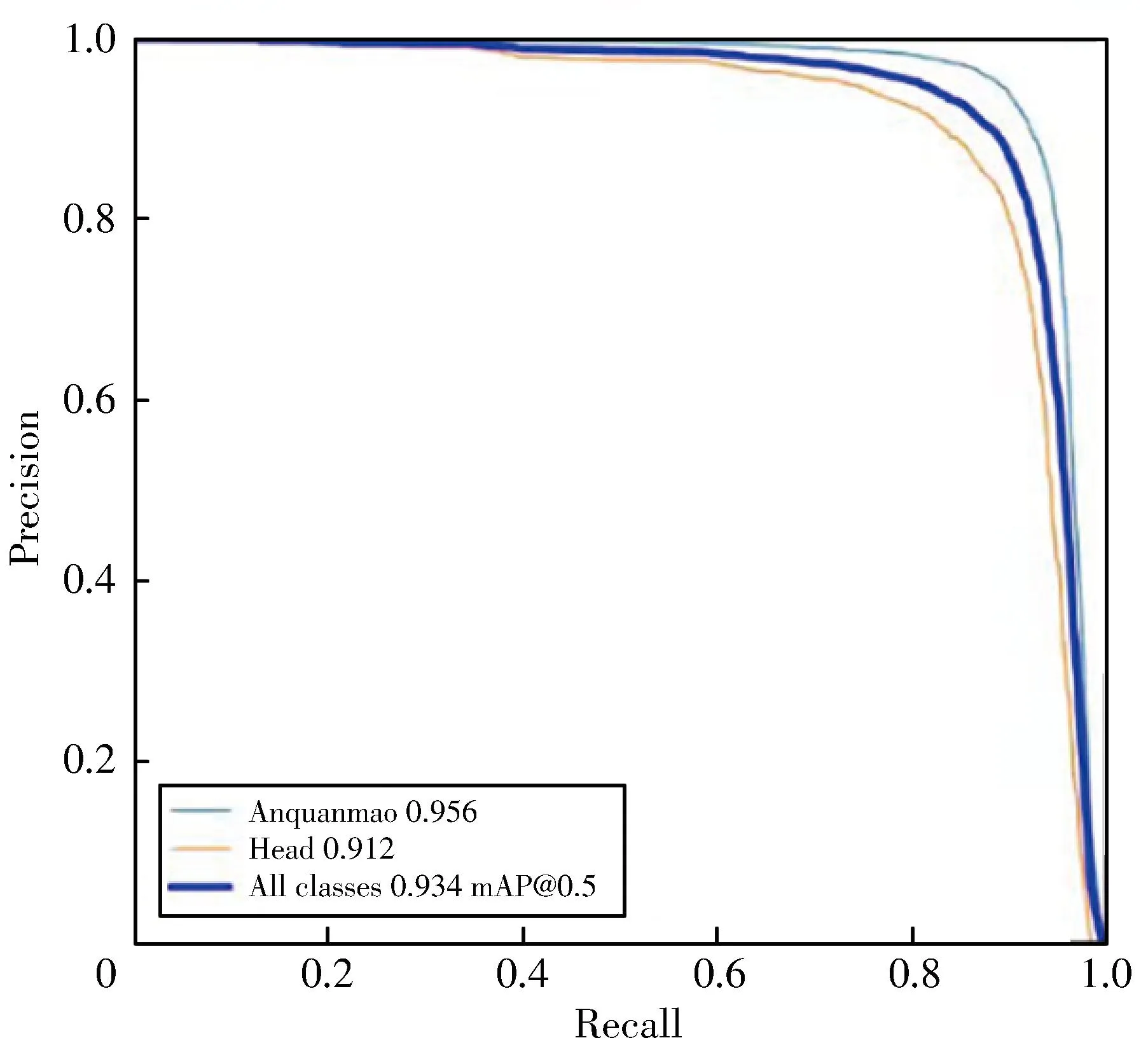
(a) YOLOv5
(a) YOLOv5
It can be seen from Figs.14 and 15 that the proposed algorithm has achieved better performance in the detection of helmet wearing and mask wearing targets.Compared with the original algorithm of YOLOv5,the two improved algorithms have improved in the detection of wearing helmets and masks.In order to ensure the precision of the prediction frame,AP50 and corresponding mAP-50 are used as evaluation indicators for helmet wearing and mask wearing detection.The specific test data is shown in Tables 4 and 5.
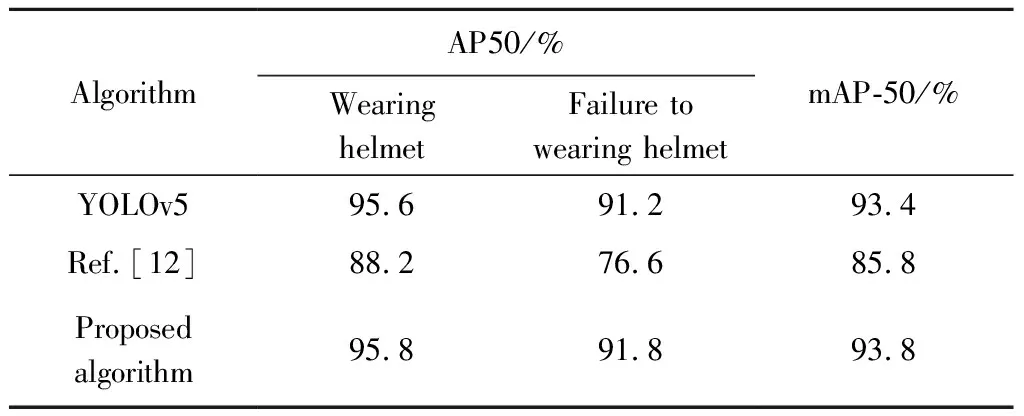
Table 4 Comparison of various data of helmet wearing test
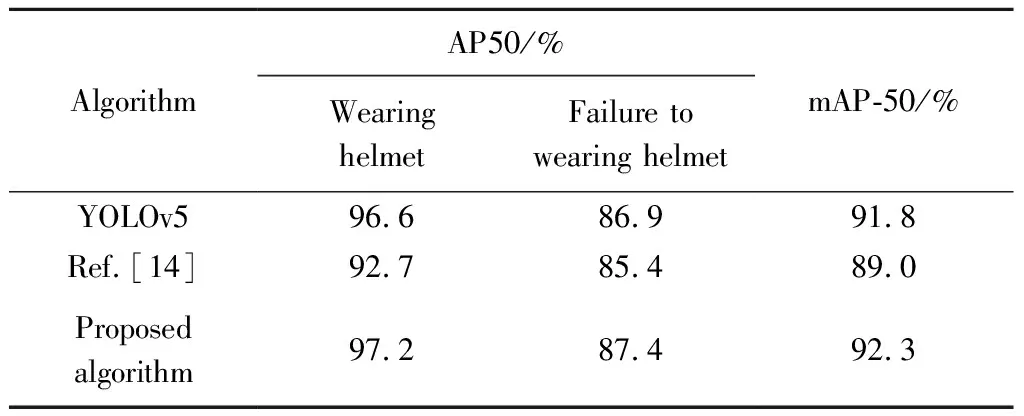
Table 5 Comparison of various data of mask wearing test
It can be concluded that YOLOv5+ achieved 93.8% and 92.3% of mAP-50 in helmet wearing detection and mask wearing detection tasks,respectively.In the helmet wearing detection task,the proposed algorithm is 0.4% higher than YOLOv5,and 8% higher than the algorithm in the reference[12].In the mask wearing detection task,the proposed algorithm is 0.5% higher than YOLOv5 and 3.3% higher than the algorithm in the reference[14].YOLOv5+ also outperforms other algorithms in all categories of AP.While maintaining high precision,YOLOv5 and its improved algorithms can reach 0.010 s-0.015 s for single image detection.The extremely fast processing speed is due to lightweight weight model of YOLOv5s.All kinds of AP of YOLOv5+ are also better than other algorithms.While maintaining high precision,the single image detection speed of YOLOv5 and its improved algorithm can reach 0.010 s-0.015 s,and the extremely fast processing speed benefits from the lightweight weight model of YOLOv5s.
In addition,in order to have a more intuitive feeling of the detection difference between the proposed algorithm and the original algorithm,some detection images are selected for comparative analysis.Two images are extracted from the test set of the helmet wearing and mask wearing data sets,and the images are input into the established model for detection,by which the corresponding category and confidence level are obtained.And through the computer camera,real-time detection is performed to verify the detection effect.The result is that the IoU-thres value is set to 0.45 and the conf-thres value is set to 0.4.The test results are shown in Fig.16.

Fig.16 Comparison of two algorithms in helmet wearing and mask wearing detection effect
It can be seen that for target detection and recognition under normal conditions,both the proposed algorithm and the YOLOv5 algorithm can recognize the wearing and non-wearing cases more efficiently.However,in terms of recognition precision,especially for wearing helmets and masks,the YOLOv5+ algorithm has a significant improvement.In the comparison of the second detection image in Fig.9,where there are small-scale multi-targets and occlusion,the original YOLOv5 algorithm has a missed detection,while YOLOv5+ has no missed detections or false detections.YOLOv5+ can successfully detect targets in a variety of scenarios while ensuring high precision,and hasn’t had any results of incomplete detected targets.Therefore,it can better complete the task of wearing helmets and masks.
3 Conclusions
In order to perform helmet wearing and mask wearing detection tasks more efficiently in natural scenes,an improved method is proposed based on the YOLOv5 network model.Since most of the detection objects in helmet wearing and mask wearing detection tasks are small-scale targets,the original YOLOv5 algorithm is improved by adding a feature map of size 160×160 pixels in the detection layer.This algorithm accommodates the detection of small-scale targets.And CIoU_Loss is chosen as the loss function.It can fully consider the information,such as centroid distance,overlap rate and aspect ratio between target and detection box,etc.The speed and precision of prediction box regression are improved.Experimental and test results show that the improved method can effectively improve the precision of the detection task of wearing helmets and masks.At the same time,it can meet the application requirements of wearing helmets and masks in actual scenes.The next step will be to continue to optimize and improve the network structure in order to construct a lightweight network model with better performance,and generalize the model so that it can be applied to more fields.
 Journal of Measurement Science and Instrumentation2023年4期
Journal of Measurement Science and Instrumentation2023年4期
- Journal of Measurement Science and Instrumentation的其它文章
- Chaotic opposition initialization and average mutation update-based differential evolution
- Train driver fatigue detection based on facial multi-information fusion
- Improved target detection algorithm based on Faster-RCNN
- A real-time laser stripe center extraction method for line-structured light system based on FPGA
- Electro-hydraulic servo force loading control based on improved nonlinear active disturbance rejection control
- Drive structure and path tracking strategy of omnidirectional AGV