
基于多模态深度学习的汽车虚拟驾驶环境生成方法
2024-01-08 01:42:04张书生祝雪峰叶乾
计算机辅助工程 2023年4期
张书生, 祝雪峰,2, 叶乾
(1.大连理工大学 汽车工程学院,辽宁 大连 116024; 2.大连理工大学宁波研究院,浙江 宁波 315000)
0 引 言
安全性是汽车工业中必须要考虑的关键问题,开发高标准的自动驾驶车辆更需要大量的行驶测试,而传统的道路行驶测试需要花费数十年甚至上百年的时间[1]。针对这一问题,目前主流的解决方案是使用虚拟驾驶模拟器进行道路仿真试验,即使用代理模型通过虚拟驾驶环境进行自动驾驶研究。虚拟驾驶环境可根据环境状况与车辆进行互动,同时可为行人检测提供技术支持[2]。虚拟驾驶环境需满足2个技术要求:首先,从环境感知、导航与控制方面测试和验证自动驾驶车辆的性能;其次,生成大量标记的训练数据,这对深度学习尤其是计算机视觉方面的应用至关重要。
目前,虚拟驾驶环境的搭建方法主要分为3类:人工建模法、数据驱动法和神经网络合成法。人工建模法基于计算机图形学、物理规律和机器人运动规划技术,通过人工方式进行驾驶环境建模。该方法可自由调控光照和各物理场,但是存在图像仿真度不高、物体样式有限等问题。数据驱动法使用摄像机、激光雷达等各类传感器对实景进行扫描,从而自动构建虚拟驾驶环境。其使用的环境背景布局和图像直接取自实景,因此该方法图像仿真度极高,但是存在调控灵活度不够、无法改变光照和大气条件等问题。此外,实地取景步骤复杂,需要极大的工作量。神经网络合成法将场景语义布局转换为现实逼真的图像,因此仿真度高,但存在调控灵活度不够的问题。
近年来,深度学习逐渐应用于汽车性能分析。基于深度学习的图像样式转换技术为实现虚拟驾驶环境大气与光照条件的可控性研究提供可能,通过语义布局即可生成现实仿真图像。本文研究基于深度学习的汽车虚拟驾驶环境图像生成方法,同时通过将不同时刻(光照条件)下的日间行车图像转换为夜晚行车图像,设计虚拟驾驶环境图像的模态控制方法。
1 汽车虚拟驾驶环境多模态转换
假设x1∈χ1和x2∈χ2为来自2个不同图像域的图像。在无监督的图像转换过程中,样本分别从边缘分布p(x1)和p(x2)中提取,而不是提取自联合分布p(x1,x2)。本文目标是通过训练后的图像转换模型p(x1→2|x1)和p(x2→1|x2),预测2个条件概率分布p(x2|x1)和p(x1|x2),其中x1→2是将x1翻译至χ2产生的样本,x2→1是将x2翻译至χ1产生的样本。一般情况下,p(x2|x1)和p(x1|x2)是复杂的多模态分布,确定性编译模型不能很好地适用于这种情况。
1.1 部分共享的隐空间
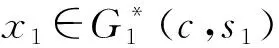
1.2 模型原理
本文模型的学习过程示意见图1。翻译模型由每个域χi(i=1,2)的编码器Ei和解码器Gi组成。每个自动编码器的隐码被分解为内容码ci和样式码si,(ci,si)=(Ec,i(xi),Es,i(xi))=Ei(xi)。
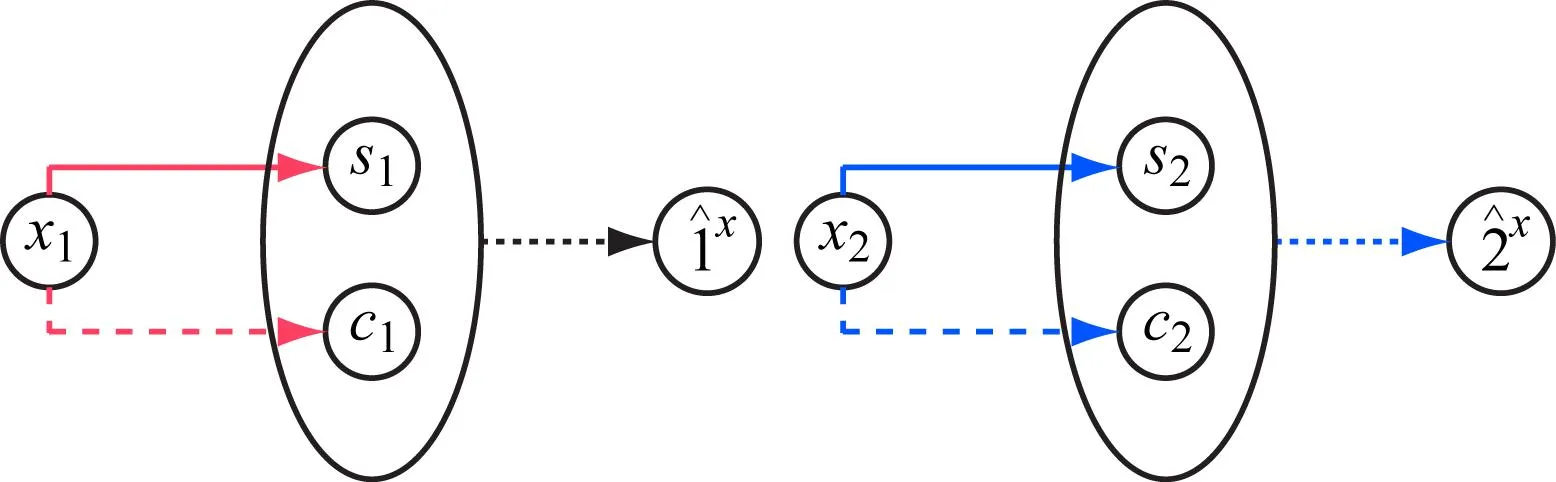
图 1 模型学习过程示意
图像到图像的转换通过交换编码器-解码器对执行,见图1下半部分。图像到图像转换模型由2个自动编码器组成,每个域各有1个。每个自动编码器的隐码由1个内容隐码c和1个样式隐码s组成。模型使用对抗目标(点线)进行训练,确保翻译后的图像与目标域中的真实图像不可区分。同时,模型使用双向重建目标(虚线)进行训练,以重建图像和隐码。虽然先验分布是单模态的,但由于解码器的非线性,输出图像分布可以是多模态的。损失函数包括双向重建损失和对抗性损失。双向重建损失确保编码器和解码器功能完全反向;对抗性损失确保翻译图像与目标域中图像的分布相同。
2 模型实例
所研究的自动编码器架构见图2,由内容编码器、样式编码器和联合解码器组成。

图 2 自动编码器架构
2.1 内容编码器和样式编码器
内容编码器由若干个对输入进行下采样的跨步卷积层和若干个处理卷积层信息的残差块组成[3],所有卷积层的输出都经过实例标准化(IN)[4]。样式编码器包含若干个跨步卷积层以及后面的全局平均池化层和全连接层,为保留重要样式信息而不在样式编码器中使用IN层。
解码器使用多层感知机(MLP)从样式隐码生成一组自适应实例标准化(AdaIN)层参数。内容隐码由具有AdaIN层的残差块处理,通过上采样和卷积层解码到图像空间。
2.2 解码器
解码器根据其内容和样式隐码重建输入图像,采用一组残差块处理内容隐码,最终通过若干个上采样和卷积层产生重建图像。参考在标准化层中使用仿射变换参数表示样式的研究内容,对残差块配备AdaIN层[5],其参数由多层感知器从样式隐码动态生成,具体信息为
(1)
式中:AdaIN()表示AdaIN层参数;z为先前卷积层的激活;γ和β为MLP生成的参数;μ()和σ()为通道平均值和标准偏差。
2.3 域不变的感知损失
感知损失通常定义为输出和参考图像在VGG特征空间[6]中的距离。采用域不变特性可以更为显著地感知损失,以便使用输入图像作为参考。在计算距离前,对输入VGG的图像提前执行IN处理,以便删除原始特征均值和方差。这其中包含许多特定于域的信息,域不变的感知损失能加速对高分辨率数据集的训练。
域不变的感知损失实验图像对比见图3。在参考数据集上进行实验验证[7],随机抽取2组图像对,其中:图3(a)为来自不同域(夏季和冬季)的同一场景图像,图3(b)为来自相同域的不同场景图像。

(a)同一场景图像对
不使用和使用IN计算距离的感知距离(无量纲)-图像对数量直方图见图4。在使用IN的情况下,即使来自不同的域,同一场景的图像对仍具有明显更小的感知距离。因此,在计算距离前应采用IN操作使得特征距离更具有域不变特性。

(a)不使用IN
2.4 神经网络架构
搭建网络架构:c7s1-k表示具有k个滤波器、卷积核大小为7×7、步幅为1的层;dk表示具有k个滤波器、卷积核大小为4×4、步幅为2的层;Rk表示包含2层核心大小为3×3卷积层的残差块;uk表示放大倍数为2的最近邻上采样层,其后是具有k个滤波器、卷积核大小为5×5、步幅为1的层;GAP表示全局平均池化层;fck表示具有k个滤波器的全连接层。IN应用于内容编码器,AdaIN应用于解码器。在生成器中使用ReLU激活函数,在辨别器中使用Leaky ReLU激活函数,函数自变量小于0的部分斜率为0.2。
(1)生成器架构组成如下:内容编码器为c7s1-64、d128、d256、R256、R256、R256、R256;样式编码器为c7s1-64、d128、d256、d256、d256、GAP、fc8;解码器为R256、R256、R256、R256、u128、u64、c7s1-3。
(2)辨别器架构为d64、d128、d256、d512。
3 模型训练
3.1 数据集
Cityscapes是一个大规模城市街景数据集,其中包含从50个不同城市的街道场景中录制的一组不同的立体视频,除去20 000帧粗糙注释帧外,还有5 000帧的高质量注释帧图像(见图5),用于训练语义视觉算法并评估其在城市场景识别任务中的性能。本文图像合成实验使用高质量像素级的注释数据集和无标签的视频数据集,图片像素重新插值为256×256。

图 5 Cityscapes高质量注释帧图像(部分)
Comma2k19是由Comma AI提供的自动驾驶数据集,见图6。该数据集是在美国加利福尼亚280高速公路的加利福尼亚圣若泽与旧金山之间的20 km路段上采集的,累计拍摄时长33 h,共有2 019段视频,每段时长1 min,视频分辨率为1 164×874。本文将其分辨率缩小为292×224,用于模态控制实验。

图 6 Comma2k19数据集视频帧(部分)
3.2 评估标准
3.2.1 主观评价
自动驾驶车辆最终要在真实环境中使用,虚拟驾驶环境的图像不仅需要在细节风格上保持真实性,环境中的内容物体也需要在逻辑上符合现实。为此,在评价模型输出的真实性时进行主观评价。将一个输入图像和经过网络编译后的生成图像展现给评价人员,然后要求评价人员在有限的时间内选择哪张图像是真实图像。为每个评价人员随机生成15个相关问题,共计100位评价人员参与该项调查。
3.2.2 LPIPS距离
LPIPS由图像深度特征之间的加权欧式距离给出,相关研究已经证明其与人类感知具有很高的相似性[8]。为量化评价图像转换的多样性,计算在相同输入情况下转换输出图像之间的平均LPIPS距离。使用100个输入图像,并对每个输入抽取10个输出对作为样本,总共有1 000个输出样本。
3.2.3 图像质量量化评价
在模态控制实验中,为评价多模态图像的质量,对每个输入图像抽取10个输出作为样本,共取100张输入图像。实验还需要评价在执行光照条件控制任务时样式隐码重建损失、内容隐码重建损失和图像重建损失对生成图像质量的影响。采用GAN辨别器作为图像质量量化评价标准,其中辨别器取自在Comma数据集上训练后的模型。对于白天到夜晚转换,使用夜晚域的辨别器;对于夜晚到白天转换,使用白天域的辨别器。评价标准为辨别器判断为真实图像的百分比。
3.3 实验分析
3.3.1 图像合成实验
实验目的是合成自动驾驶环境图像。神经网络可根据输入的街景图像语义布局生成真实的街景图像。实验使用Cityscapes数据集,将街景图像与其语义标签作为2个域供网络训练。本文模型与CG建模法主观评价的结果对比见表1。英特尔的CARLA[9]、微软的Airsim[10]、谷歌的Carcraft以及GTA5游戏是用于自动驾驶代理训练的主流虚拟环境。本文在上述人工建模环境中进行驾驶模拟,截取引擎盖视角的图像用于比较。

表 1 本文模型与CG建模法主观评价结果对比
从表1的数据可以看出,虽然本文方法生成图像被认为更真实的比例仅有39.76%,但是人工建模法的图像所获得的评价为0,即完全没有被认为是真实图像。相较于人工建模法,本文的方法可以在很大程度上改善生成图像的真实性。
同时,将本模型与其他神经网络合成法进行对比,当使用相同的语义分割标签作为输入时,预测的主观评价结果对比见表2。所研究模型真实性评价排名第二,效果较好,生成的图像示例见图7。
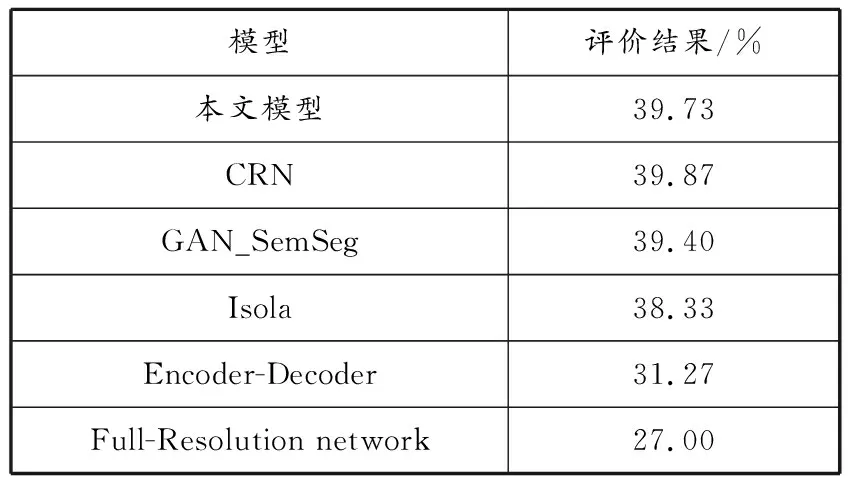
表 2 本文模型与其他神经网络合成法主观评价结果对比

图 7 本文模型生成的图像示例
在图7中,第一、二列图像为输入模型的语义布局,第三、四列为对应的合成图像。所生成的图像在训练集中并未出现过,但其图像内容合理、符合现实逻辑,可适用于自动驾驶模型的训练和测试。
3.3.2 模态控制实验
采用实验的方法证明所设计模型对图像模态进行控制的能力。虚拟驾驶环境的光照条件是重要属性,对自动驾驶算法影响很大。实验选取光照控制条件作为模态控制的可变因素,使用Comma2k19行车视频作为数据集,每隔25帧采样一次作为训练数据。完成优化的神经网络能在不同光照的驾驶环境下进行白天与夜晚的图像转换,并能可控渲染白天和黑夜不同时间段的光照。
定量分析本文模型及其3个变体,分别去除图像重建损失、内容隐码重建损失和样式隐码重建损失,结果见表3。在没有样式隐码重建损失的情况下,模型输出的多样性降低,与无图像重建的损失相比,完整网络前提下的图像多样性损失略低,但图像质量得到大幅提升,达到较好的平衡。
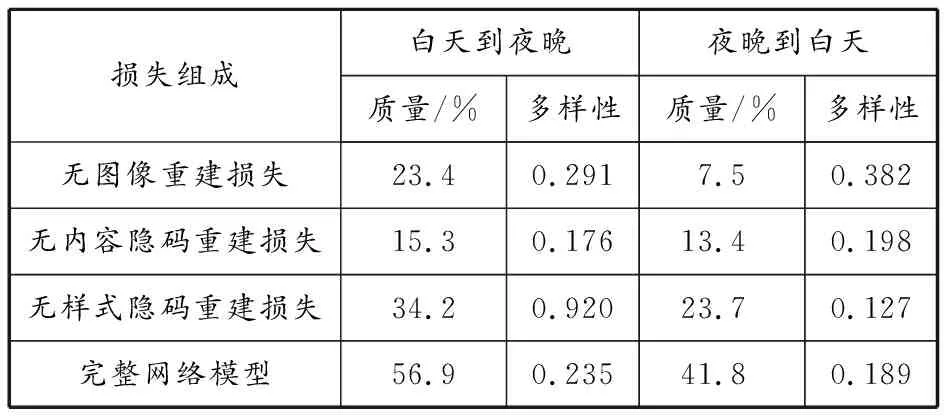
表 3 光照条件转换图像量化分析结果
白天转夜晚行车图像示例见图8和9。本文模型成功地将白天行车图像转换为夜晚行车图像。在给定白天行车输入图像情况下,通过输入不同的样式隐码,能控制转换生成夜晚图像的光照条件。神经网络输出结果表现出多模态特性,本文实验取其中3种光照条件的结果作为示例。输出的样式1与刚入夜的光照相似,远方天空微亮,由远及近亮度逐渐降低,前方车辆尾灯亮起,路面出现车辆大灯照射效果;样式2与有卤素路灯照明路面的光照相似,整体色调偏暖;样式3与深夜无路灯道路的光照条件相似,在车灯照射范围外的景物漆黑一片。虽然图片中的光照条件经历大幅变化,但是车道、车辆、树木和天空的位置、形状与布局都保持不变。

(a)原图

(a)原图
4 结束语
面向虚拟驾驶环境生成,提出基于多模态深度学习的虚拟驾驶环境图像生成方法。该模型属于无监督方法,可实现由语义布局合成全新模拟真实驾驶环境图像,并且在不影响图像内容的基础上控制图像模态。
在合成图像真实性的主观测试中,本文方法的结果优于传统建模法,同时在深度学习方法中也处于领先地位。本文方法可在多模态图像转换分析中提升图像质量及其多样性,为自动驾驶虚拟环境平台搭建提供技术参考。未来将结合长短时记忆网络,使视频中相隔较远的图像帧具有较好的连续性。
猜你喜欢
天然气与石油(2022年4期)2022-09-21 07:02:38
中国机械工程(2022年8期)2022-05-09 12:32:02
天然气与石油(2021年5期)2021-11-06 09:39:42
中国机械工程(2021年8期)2021-05-07 05:49:10
天然气与石油(2021年1期)2021-03-08 09:07:32
音乐教育与创作(2019年8期)2019-05-16 04:06:34
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
课堂内外(初中版)(2015年9期)2015-09-10 07:22:44
