
基于生成对抗网络的恶意域名训练数据生成方法
2024-01-06 08:26:18刘伟山马旭琦吴子琰
兰州理工大学学报 2023年6期
刘伟山, 马旭琦, 汪 航, 吴子琰
(1. 国家计算机网络应急技术处理协调中心 甘肃分中心, 甘肃 兰州 730000; 2. 兰州理工大学 机电工程学院, 甘肃 兰州 730050; 3. 兰州大学 信息科学与工程学院, 甘肃 兰州 730000)
在互联网产业蓬勃发展的同时,网络诈骗、DDoS攻击、勒索软件、计算机恶意程序感染等各类网络安全事件层出不穷.据国家计算机网络应急技术处理协调中心(CNCERT/CC)监测显示[1],2020年我国境内木马或僵尸程序控制服务器IP地址数量为12 810个,境内木马或僵尸程序受控主机IP地址数量为5 338 246个,由此构成的僵尸网络已经成为当前网络安全领域的巨大威胁.
僵尸网络[2]广泛采用域名生成算法[3]生成大量的随机域名来躲避安全检测,恶意域名的准确检测和识别成为当前网络安全管理的重要课题.基于神经网络的深度学习算法在恶意域名检测方面表现优异.Woodbridge等[4]首次利用长短期记忆网络[5]构建DGA(domain generation algorithm)域名检测器,并在检测准确率、召回率等方面相较于传统机器学习模型有着明显优势.Yu等[6]对利用不同的卷积神经网络训练出的DGA域名检测器检测准确率高达90%以上.袁辰等[7]提出一种DGA域名训练数据的生成模型,该模型结合了生成对抗网络的思想,直接将数据输入GAN(generative adversarial network)原始模型进行学习训练,保持了数据的真实特性.Anderson等[8]将自编码器融入生成对抗网络,提出一种DGA生成模型和检测模型(Deep DGA),通过多次迭代训练生成对抗网络后,生成器可以模拟出特征类似的真实DGA域名,使采用随机森林算法的DGA检测器的性能明显降低.
现有的DGA检测器均是基于公开的DGA域名数据集进行训练构建,缺乏最新的丰富的DGA域名训练样本数据,导致检测模型更新周期过长、过慢,检测的实效性、快速性不强,对未知的DGA域名检测效率不高.本文利用真实域名数据训练出一个自编码器,并将自编码器的编码网络和解码网络分别用作GAN网络的判别器与生成器,从而构建出一个基于GAN的DGA序列生成器.与袁辰等[7-8]提出模型的不同之处在于:
1) 通过预训练自编码器并将其应用于GAN网络最大程度地学习到了真实域名的潜在特性;
2) 在自编码器结构中除了设计卷积层来提取域名的n-gram信息外,还引入LSTM网络层以更好地捕获域名字符间的潜在特征[9],从而生成长度可变的字符序列;
3) 采用基于最大均值差异(maximum mean discrepancy,MMD)的两样本检验方法来验证生成器的输出样本与真实的Alexa域名样本来自相同的分布,保证生成模型和生成数据的有效性;
4) 将生成数据在基于LSTM网络的DGA域名检测器上进行验证,发现其能够有效降低检测模型的效率,而后进一步通过生成数据对域名检测器进行训练后,模型器性能明显提升.
1 相关理论
1.1 自编码器
自编码器(auto encoder,AE)通常被视为无监督学习网络[10],常用于帮助数据分类、可视化和存储,其核心作用是对输入序列进行压缩降维,之后再进行重建恢复.一个典型的自编码器包括编码器和解码器两个部分,其中编码器通过一系列预先设计的神经网络结构将输入序列编码为相应的低维向量,称为编码过程;编码后的数据通过解码器中的隐藏层来重建输入数据,即为解码过程.通过定义合适的损失函数,选择恰当的网络模型加以训练,可以近乎完美地重建输入序列,从而实现编码器输出的低维向量完整地表达原始序列内在特征的功能.
1.2 生成对抗网络
Goodfellow等[11]在2014年提出的生成对抗网络(GAN)是一种无监督式深度学习模型[12],其原理主要是通过两个神经网络相互博弈的方式来学习样本特征,从而根据原有数据集生成以假乱真的新数据[13].生成对抗网络包含两个独立的神经网络——生成网络G和判别网络D,D负责判别输入其中的数据是来自G产生的虚假数据还是真实数据;而G则不断提升自己的造假能力,只为生成能够成功欺骗D的对抗样本;双方在对抗过程中采取交替迭代的方法不断优化自身网络,从而形成一种对抗,最终达到平衡.
2 DGA域名生成模型设计
2.1 域名自编码器
一般的域名编/解码器常通过建立单个域名字符到数字编码的一一映射来实现,如袁辰等[7,14]将域名字符转换为基于 ASCII码的编码方式实现向量映射及逆映射.
为了更好地捕获域名字符间的潜在关系,并对长域名进行压缩表示,本文设计的自编码器编码网络主要由3个平行的卷积网络和1个LSTM网络级联组成,3个平行的卷积层各自有100个滤波核,卷积核尺寸分别为2、3、4,对应捕获域名数据字符间的n-gram信息,LSTM网络用于挖掘和表示变长域名序列的潜在特征,从而实现可变长序列的生成.具体来说,首先将Alexa域名进行序列标记(Tokenization),之后进行独热编码(One-hot),再将编码后的序列输入到级联的卷积层,之后将级联卷积层的输出并列拼接后送入到另一个卷积层,最后通过展平层将输入序列平展成一个1维的矢量,作为编码器的输出.该输出表达了原序列数据经过编码器压缩提取后的核心信息.编码器的输出作为解码器的输入,首先通过重构层将一维的输入序列重组成一个二维矩阵,然后将二维矩阵输入到与编码器结构类似的级联卷积层,之后将级联卷积层的输出并列拼接后送入输出卷积层,输出卷积层的有37个卷积核,卷积核的个数对应域名序列化字典的长度,激活函数为Softmax.Softmax激活函数的输出表示了域名的每个字符在标记字典上的概率分布.自编码器网络结构如图1所示.
2.2 生成对抗网络结构设计
2.1节设计的编码器实现了复杂域名字符序列在低维特征空间中的压缩表示,解码器则可以将该压缩表示还原成原始域名.基于此,将解码器用于构造GAN网络生成器,将编码器用于GAN网络判别器,从而设计一个新的域名生成网络模型.其中GAN模型生成器将被训练用于产生与Alexa Top 100万数据尽可能相似的域名,而判别器则尽可能地识别出输入的域名数据是由生成网络产生的还是从真实数据集采样而来的.图2为生成对抗网络结构图.
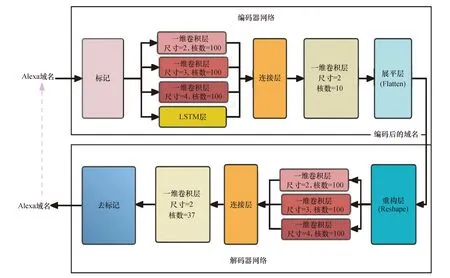
图1 域名自编码器码器结构图Fig.1 Domain name autoencoder architecture
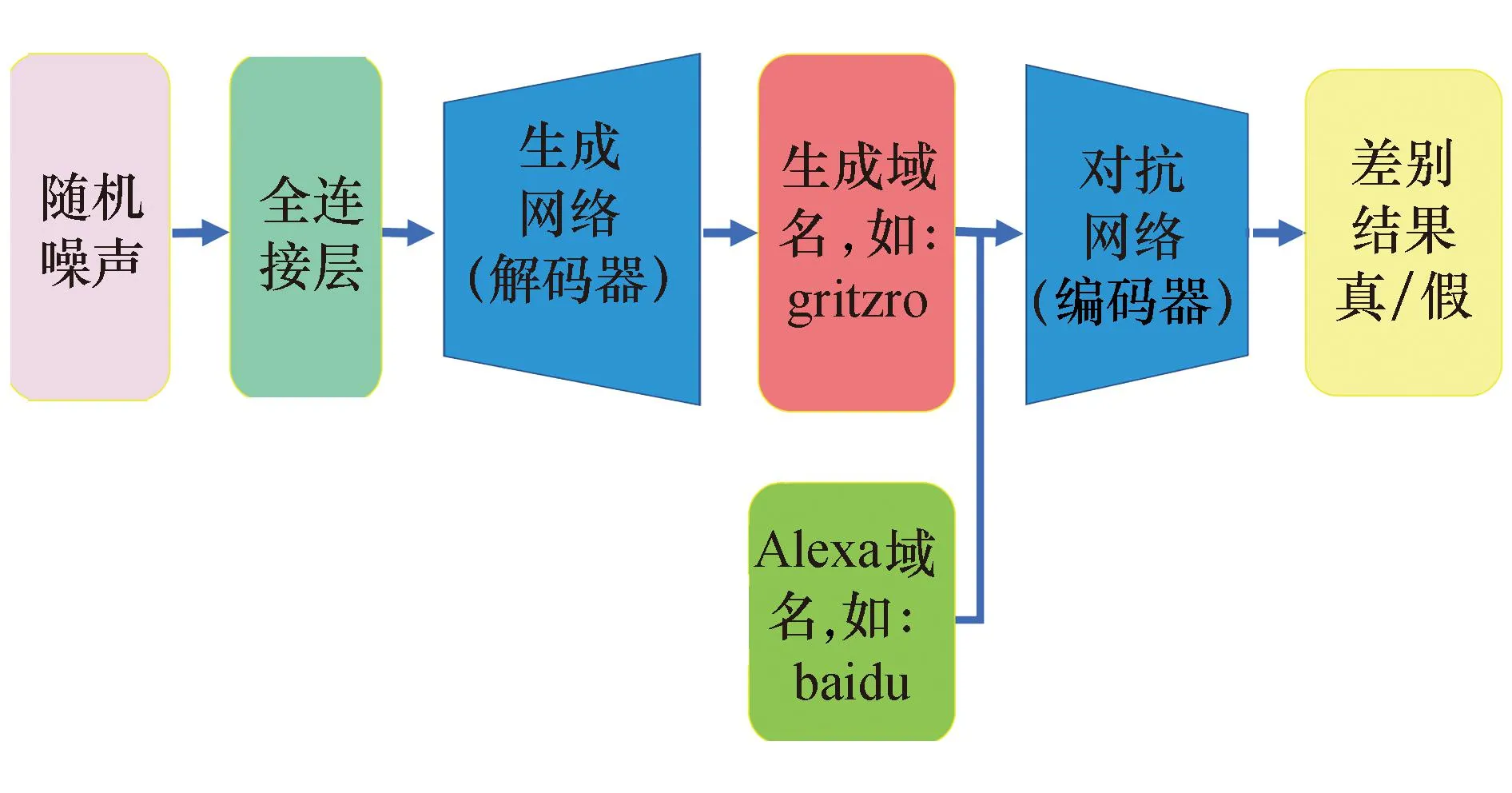
图2 生成对抗网络结构图Fig.2 GAN architectures
生成器的网络结构由一个全连接层与解码器构成.首先使用随机噪声发生器产生在[-1,1]上均匀分布的噪声,之后通过全连接层完成随机噪声的线性变换,使其维度与编码器的输出维度一致,最后通过ReLU函数激活后送入预先训练好的解码器,得到输出域名的标记采样.直观上,全连接层学习了从均匀分布的噪声空间到低维编码特征空间映射,而该低维空间正是编码器用来学习生成真实域名的特征空间.为了保证解码器的输出就是生成的域名数据,本文在训练生成器时冻结解码器的参数值,生成器的结构如图3所示.
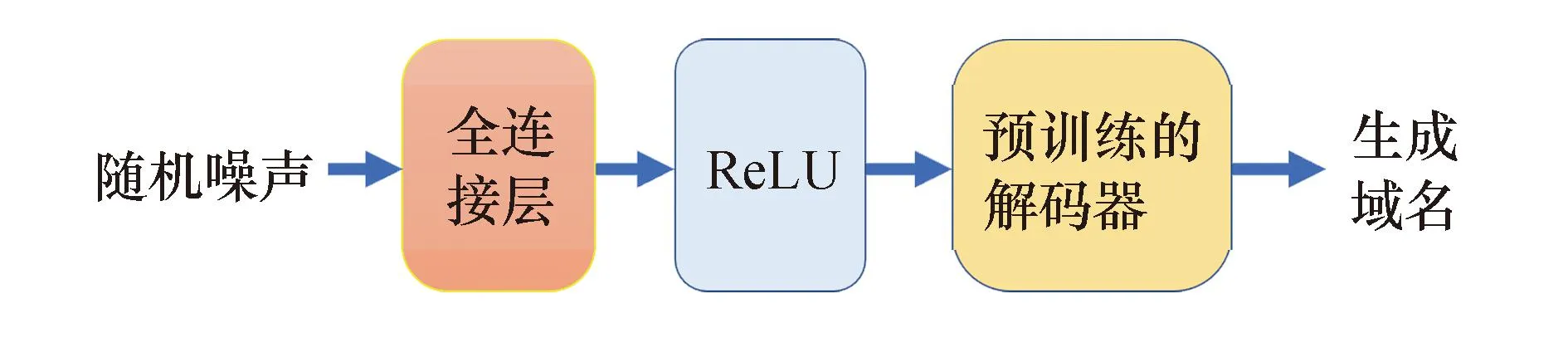
图3 生成对抗网络生成器结构图Fig.3 Generator architecture of GAN
判别器的结构与生成器类似,由编码器和一个全连接网络构成.预先训练好的编码器作为判别网络接收真实的Alexa域名或者生成器生成的假域名序列,之后将其输出经过全连接层变换为低维数据,最后通过Sigmoid函数激活后输出.在训练判别器网络时同样把预训练好的编码器的权重参数冻结之后再进行训练.判别器的结构如图4所示.
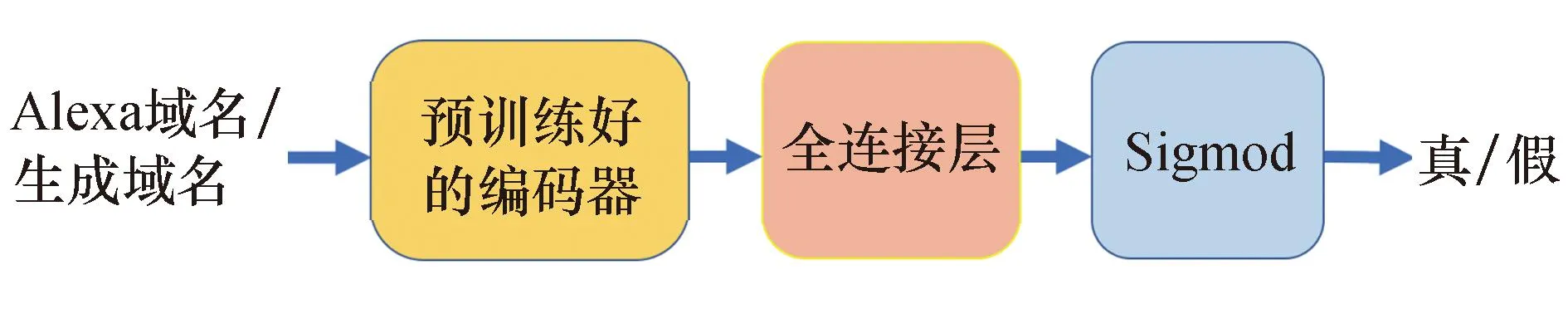
图4 生成对抗网络判别器结构图
2.3 生成对抗网络模型的训练
本文在采用标签光滑、改进损失更新等策略来提升模型训练的稳定性之外,特别考虑了借助统计中两样本检验的思想来指导模型的训练进程.一些实验中,常通过观察训练损失变化、肉眼判别域名相似度、绘制生成样本的直方图等手段来判别生成网络的训练质量,但这些操作很难给出明确的指标来判定GAN网络的训练质量.本文考虑在GAN模型训练的中间过程中,通过引入MMD检验来判别当前生成网络的输出样本是否与真实的Alexa域名样本来自相同的分布,即进行双样本检验.Gretton等[15]给出了MMD在双样本检验中的应用,其基本假设是:对于两个分布p和q,给定所有以分布生成的样本空间为输入的函数族F,若p、q对应生成的样本x和y在F中每个函数f上像的均值都相等,则可认为这两个分布相同.MMD具体定义如下:
其中:F通常取为希尔伯特空间中的单位球,实际操作时借助预先设定的核函数,如高斯核函数来表示.
实验中,若MMD检验通过,则说明生成样本的质量较好,从统计检验的角度已无法区分其与真实域名的差别,此时可停止训练.
3 实验与分析
3.1 实验环境与数据集
本文实验主要使用PyTorch深度学习框架,具体实验环境配置如表1所列.

表1 实验环境具体配置
本文实验所使用的数据集由两部分组成.第一部分从Alexa网站获取的排名前100万真实Web站点的域名,这部分数据作为模型的训练数据.第二部分是来自360安全实验室的现有DGA域名数据集,此部分用来对比实验.在实验之前,对使用的数据进行数据预处理,将所有域名的一级域名和二级域名(如.com、.net、.org等)剔除,只保留主机域名进行模型训练.
3.2 实验设计
3.2.1训练自编码器
在对GAN模型进行训练之前,需要对自编码器预训练.该步骤的必要性在于,若不用Alexa域名对自编码器进行预训练,后续GAN网络的训练会高度不稳定,且很难收敛.具体的实验步骤如下所述.
1) 抽取10万条Alexa数据,随机打乱后按照80/20的百分比划分成训练集和测试集;尝试不同的数据批大小(64,128,256等),最后综合考虑训练效率与模型表现,选择最优数据批大小为64.
2) 对自编码器中设计的LSTM网络的隐藏神经元个数尝试不同的取值(5,10,50,100等)进行消融实验对比,根据自编码器训练时间和后续用于GAN网络的表现,选择LSTM网络隐藏神经元个数为10.
3) 用交叉熵[16]作为训练的损失函数,即度量解码器Softmax输出的损失大小.
4) 初始学习率设置为0.000 1,后续随着损失的变小,学习率也随之减小,由此得到更好、更稳定的训练结果.
5) 训练中采用自适应矩估计(Adam)优化算法来更新自编码器网络的权重,同时设置权重衰减率为0.8,即借助L2正则防止训练出现过拟合.
实验发现,仅通过不到10个训练周期,自编码器就能近似无损地恢复输入的Alexa域名.经过计算,测试集上的均方误差(mean square error,MSE)约为3.234×10-5.这表明设计的自编码器结构可以完整地捕获复杂正常域名中的几乎全部信息,并给出相应的低维向量表示.图5为训练过程中自编码器损失值的变化过程, 其中橫轴表示训练的周期,纵轴表示模型在测试集上的损失.可以明显看出,随着训练次数增加,自编码器损失值逐渐降低并保持稳定,网络参数已非常稳定.
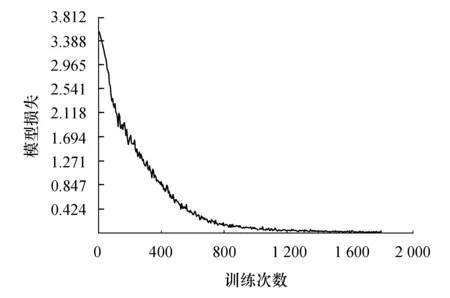
图5 自编码器训练损失图Fig.5 Autoencoder training loss
3.2.2GAN生成对抗模型的训练与检验
在该阶段,训练好的自编码器将被拆分为编码器和解码器,并分别嵌入到GAN网络的判别网络和生成网络中.对于GAN的训练过程详述如下.
1) 选取两部分数据作为训练数据,一部分是划分后的Alexa真实域名,另一部分是随机抽取的、服从均匀分布的噪声向量(其维数设置为8)通过生成网络后产生的样本.两部分样本各自采用5万条,其中Alexa域名被用作正样本,生成域名被用作负样本,用于判别网络的训练;此外,再将5万条生成域名当作正样本,用于生成网络的同步训练.
2) 尝试不同的批数据大小(64,128,256等)进行消融对比实验,根据GAN网络训练效率和稳定性,选择最优数据批大小为128,训练周期设为50.
3) 判别器使用交叉熵作为损失函数.
4) 实验中设置负样本的标签为0,同时对正样本的标签进行光滑处理,即从1随机变换到0.8~1.0的小数,来提升训练的稳定性.
5) 考虑到实验中判别器比生成器的收敛速度要快很多,在反向传播更新网络参数时,本文选取较强的Adam优化器来训练生成网络,同时采用较为朴素的动量随机梯度下降(stochastic gradient descent,SGD)优化器训练判别器,学习率分别设置为0.000 001与0.000 000 1,同时使用权重衰减来减少训练的过拟合.
6) 在训练过程中一些损失较小的周期间隔,对训练好的GAN网络中的生成器所生成的序列进行MMD两样本检验,由此决定是否进行训练早停(early stopping),完成GAN网络的训练.
对MMD两样本检验的过程做更进一步的详细说明,注意到此处待检验的问题为
H0∶P真实域名=P生成域名
其中:P真实域名和P生成域名分别表示真实域名与GAN网络生成域名的概率分布.实验中,通过计算MMD检验统计量,并进行Bootstrap抽样,可以估计出检验的p值(p-value),p值越小,表明拒绝原假设的把握越大.表2列出了在一些选定的训练周期,基于相应的生成样本计算出的p值.可以看出,在训练初期,尽管生成的样本看起来与Alexa域名接近,但对应检验的p值很小,显然生成网络输出的域名与真实域名仍有差异;但在训练后期,p值增大,若选取显著性水平为0.05,已无法拒绝原假设,表明从统计检验的角度,已无法区分生成样本和Alexa样本是否来自不同的分布,这保证了生成样本的质量.总结来说,GAN网络的训练经过85个周期的反向传播更新,最终得到收敛.

表2 生成模型MMD两样本检验 p值
3.3 实验结果分析
使用3.2实验中训练完成的GAN模型中的生成器生成20万条数据并将其去重后作为实验结果分析的验证数据集,分别从生成序列展示、生成序列字符频率分布、生成序列长度统计及其在DGA检测器的表现进行对比分析.
1) 生成对抗网络生成序列结果
表3为Alexa真实域名、真实的DGA域名与使用对抗生成网络生成的字符序列数据.通过观察发现,生成序列长度可变,字符序列表示已经与真实DGA域名较为近似,可以作为域名使用.

表3 Alexa域名、真实DGA域名与生成序列对比
2) 生成序列与真实域名长度分布图
DGA域名检测器通常会将序列的长度特征作为判断该序列是否为Alexa域名或DGA域名的特征,所以如果生成序列在长度特征上与Alexa真实域名保持相似,则更有可能躲避DGA域名检测器的检测.图6所示为Alexa真实域名与生成序列的长度分布图,图中横坐标表示域名序列长度,纵坐标为不同长度的域名数量所占比率.由图6可以看出,生成序列与真实域名在长度分布上非常接近,这一特性可以有效躲避一些以域名长度作为检测特征的DGA域名检测器,降低生成序列被发现的概率.
此处需要说明的是,通过对真实域名数据的统计特性进行分析,可以得出大部分正常域名的长度在20个字符以内,所以本文在训练模型时选择长度为20个字符的Alexa真实域名作为训练数据,生成的序列长度也是在20个字符以内.
3) 生成序列与真实域名长度分布图
同序列长度一样,序列的字符频率分布特征同样是DGA域名检测器判别真实域名与DGA域名的重要因素,如果生成序列的字符频率分布特征能够与Alexa真实域名尽可能相似,则有很大可能降低被发现率.图7为Alexa真实域名与生成序列的字符频率分布图,图中横坐标表示域名序列中的各个字符,纵坐标表示各个字符在所有域名序列中所占比率.由图7可以看出,生成序列与Alexa域名字符频率分布十分相似,躲避DGA域名检测器的概率较大.
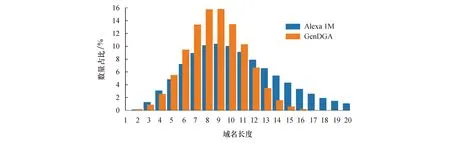
图6 生成序列长度分布图Fig.6 Generated domain lengths distributions

图7 字符频率分布图Fig.7 Unigram character distributions of Alexa top 1M and generated domains
4) DGA域名检测器验证结果
本文使用基于LSTM网络构建的DGA域名检测器对生成数据进行验证测试,表4为测试结果,具体测试过程如下:
a) 使用真实Alexa域名数据和DGA数据对基于LSTM网络的DGA域名检测器进行训练,之后使用真实的DGA数据作为验证集,发现模型的准确率和召回率均在91%以上;
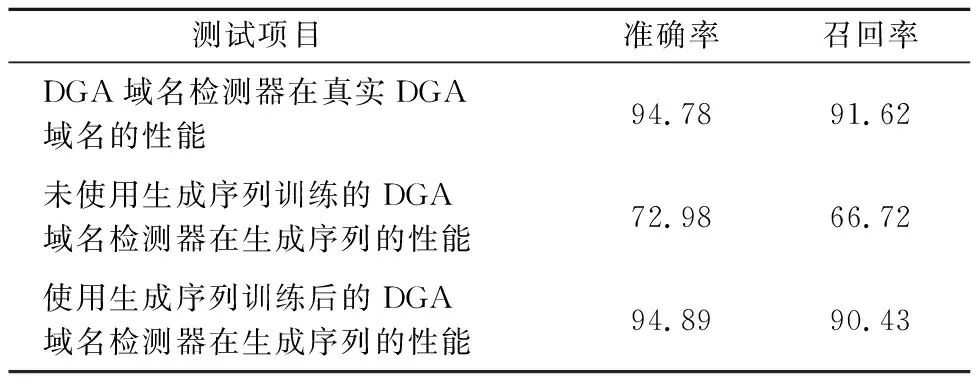
表4 DGA域名检测器测试结果
b) 将本文生成的序列20万条数据去重后按照1∶9的比例进行划分,其中第一部分数据首先拿来作为验证集,与真实域名数据混合后输入a)中训练好的DGA域名检测器中进行验证,发现模型在生成数据上的准确率和召回率均大幅下降,检测性能明显降低,说明生成序列在对抗DGA域名检测器方面取得良好的效果,有很大的概率能够躲避模型的检测;
c) 将生成序列的第二部分数据,即生成数据的90%作为训练集和测试集,对DGA域名检测器进行训练;
d) 将b)中准备好的验证集在c)中训练好的模型上进行验证,可以看到使用生成数据训练过后,模型发现生成序列的性能又有了提升,几乎回到了之前的水平.
通过对生成序列在字符序列表示、序列长度、字符频率分布的对比,以及使用生成序列在基于LSTM的DGA域名检测器进行检测和加强训练,对生成序列进行多方位的对比和验证,各项结果充分说明生成序列既具有真实域名的特性,又具备对抗现有DGA域名检测器的特性,使用其不仅可以有效解决模型训练数据不足的问题,又可以提升模型在对抗型恶意域名数据上的鲁棒性,达到了本文的目的.
4 结语
恶意域名数据集采集是训练DGA域名检测器工作中非常重要的一环.本文尝试将自编码器和生成对抗网络结合应用,生成恶意DGA域名序列,丰富恶意域名数据集,从而提升了检测模型的性能,并通过实验验证了此方法的可行性.
下一步工作将结合现有的深度学习技术继续改进域名特征提取算法,以期进一步提升生成域名的种类与质量,并评估生成模型的性能.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
计算机与网络(2018年10期)2018-02-15 09:06:37
中国交通信息化(2017年9期)2017-06-06 07:14:57
工业设计(2016年11期)2016-04-16 02:49:43
中国知识产权(2015年9期)2015-05-30 10:48:04
河南科技(2014年22期)2014-02-27 14:18:12
食品科学(2013年8期)2013-03-11 18:21:24
