
基于模糊聚类分析的能源产业信息自动挖掘建模研究
2024-01-05 12:05:48丁胜利
电子设计工程 2024年1期
陈 竞,杜 杰,丁胜利
(南方电网数字电网研究院有限公司,广东广州 510663)
新型能源产业能够为用户提供智慧用电方案,电费谷值时储电,峰值时用电,将大幅度减少用户电费[1-3],还可以利用互联网对信息流进行跨界交换,为用户提供实时的电表数据,但是随之而来的问题是能源产业信息剧增[4-5],加大了信息挖掘难度。文献[6]通过模糊C 均值算法聚类降维后的特征数据,获取数据挖掘结果,该模型具备较优的数据聚类效果。文献[7]依据模糊神经网络建立数据挖掘模型结果。但这两种方法均存在计算开销较大的缺点,在挖掘较大规模的信息时实时性较差,在数据维度不同时的挖掘效果较差。
模糊聚类分析算法具备模糊集合理论的特点,在各大领域均取得了较优的应用效果,可全面呈现数据集的结构[8],聚类效果较佳。为此建立基于模糊聚类分析的能源产业信息自动挖掘模型,以此精准自动挖掘能源产业信息。
1 能源产业信息自动挖掘建模方法
1.1 确定初始聚类中心
利用基于密度聚类算法确定初始聚类中心[9],步骤如下:
步骤1:通过基于密度聚类方法获取o维Xφ内每维中的聚类中心,相应区间内能源产业信息样本点数量为ri,i∈{1,2,…,n} ;
步骤3:计算dτ的确切度ρ,公式如下:
式中,构建dτ的o维子区间中相应标号子集的并、交分别为Rτ、。
步骤4:以ρ符合dτ为前提,确定能源产业信息样本集的孤立点,公式如下:
在γ未超过设定百分比值的情况下,代表dτ内的能源产业信息样本点属于孤立样本点,即虚聚类[11-12],通过步骤4 可获取τ′个符合ρ与γ条件的有效聚类子集;
1.2 粒子群优化KFCM算法
利用粒子群优化(Particle Swarm Optimization,PSO)算法优化缩短KFCM 算法的聚类时间[14],提升能源产业信息自动挖掘精度。
网络信息的海量化和获取的便利化,造成相当一部分学生做作业时对电脑产生依赖,主要表现为遇到问题时不是进行认真的思考和研究,而是动辄上网搜索,在网络上寻找答案。因此,在新媒体环境下,如何提高学生的钻研精神和创新意识,减少网络依赖,杜绝网络抄袭,成为学校和老师必须重视的问题。
步骤1:设置样本数量c与允许误差δ;
步骤2:设置群体规模n,惯性权重ω,学习因子η1、η2,指数权重w;
式中,t是迭代次数;vi(t)、Yi(t)是粒子前一时刻的速度与位置;任意数是ϖ1,ϖ2∈[0,1] ;P(t)、P′(t)分别是个体、全局极值。
步骤7:如果此时迭代次数T达到Tmax,那么结束迭代,在最后一代搜索出最佳解,获取得到P′的粒子,即初始聚类中心的集合,反之,令t=t+1,返回至步骤5;
步骤8:将更新隶属度函数ζjk作为一个粒子,对其进行更新处理[15];
1.3 能源产业信息自动挖掘建模
步骤4:通过融合改进的Hubert Γ 统计量与分离度建立KFCM 的自动挖掘模型F′Γ(c,G,Xφ),其公式如下:
2 实验分析
以某电网为实验对象,该电网共包含42 个发电站,其中包含16 个水力发电站,在该电网内随机选择有关16 个水力发电站的10 个数据集,这10 个数据集的样本规模逐渐增大,由100 GB 到1 000 GB,且数据集的样本维度各不相同,这10 个数据集内的能源产业信息包含电网发电量信息、能源消耗信息、能源供应商信息与客户用电信息等。
利用该文模型自动挖掘10个数据集内在2020年有关16 个水利发电站的能源消耗信息,自动挖掘结果如表1 所示。
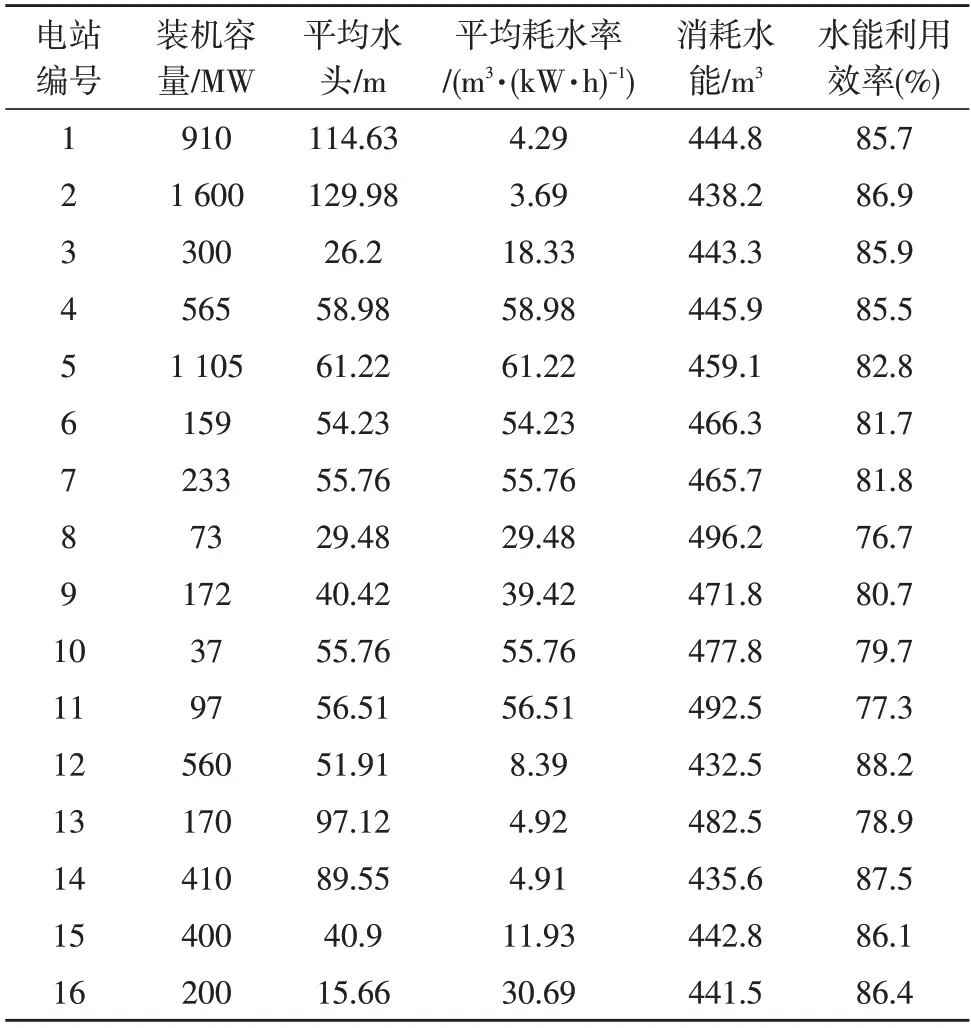
表1 能源消耗信息自动挖掘结果
根据表1 可知,该文模型可有效挖掘出所选择的10 个数据集内有关能源产业信息中的能源消耗信息,且自动挖掘结果非常详细,实验证明该文模型可有效自动挖掘能源产业信息。
以数据集1 为例,利用该文模型聚类处理该数据集内各类别能源产业信息的数据,该数据集内共包含三种类型的能源产业信息,分别是电网发电量信息、能源消耗信息与客户用电信息,聚类结果如图1所示。

图1 聚类结果
根据图1 可知,该数据集内共包含三个类别的数据,该文模型的聚类结果中共包含三个类别,与实际结果一致,说明该文模型具备较优的能源产业信息聚类效果。
利用调整兰德系数(Adjusted Rand Index,ARI)衡量该文模型的聚类效果,其取值区间为[-1,1],其值越大,聚类效果越佳,测试结果如图2 所示。

图2 ARI测试结果
根据图2 可知,在不同数据集规模时,该文模型的平均ARI 值与最大ARI 值均较高,具备较优的能源产业信息聚类效果。
测试该文模型在不同样本维度时,初始聚类中心优化前后的能源产业信息自动挖掘的完整性,测试结果如图3 所示。

图3 完整性测试结果
根据图3 可知,样本维度越大,该文模型的初始聚类中心优化前后的完整性均有所降低,在不同样本维度时,优化后的完整性均显著高于优化前,且收敛速度快于优化前。实验证明,在不同样本维度时,初始聚类中心优化后的完整性值较高,即优化后的能源产业信息自动挖掘效果优于优化前。
3 结论
电力企业的不断改革,使得能源产业信息呈爆炸式增长,同时由于能源产业信息规模庞大、维度不同,加大了能源产业信息自动挖掘难度,无法精准找到所需信息,为此建立基于模糊聚类分析的能源产业信息自动挖掘模型,提升信息自动挖掘效果,在不同能源产业信息规模与维度时,均可精准自动挖掘所需信息,为电力企业和用户提供更好的服务。
猜你喜欢
学生天地(2020年5期)2020-08-25 09:09:08
中华诗词(2019年7期)2019-11-25 01:43:00
电子测试(2018年10期)2018-06-26 05:53:36
电子测试(2017年15期)2017-12-18 07:19:27
汽车博览(2016年9期)2016-10-18 13:05:41
灯与照明(2016年4期)2016-06-05 09:01:45
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
智能系统学报(2015年4期)2015-12-27 09:38:39
交通建设与管理(2015年15期)2015-03-20 15:19:15
电子设计工程(2015年6期)2015-02-27 12:04:53
