
基于YOLOv5 改进的轻量级目标检测模型
2024-01-05 07:21厉振坤付芸
长春理工大学学报(自然科学版) 2023年6期
厉振坤,付芸
(长春理工大学 光电工程学院,长春 130022)
目标检测的研究一直以来都是CV 领域中最基本、最具有挑战性的研究课题之一。 旨在通过确定目标在图像中的位置以及分类,从而达到视觉感知的效果。 特别是近年来,随着互联网技术和人工智能技术的发展,硬件设备的升级更新,以及自动驾驶、人脸检测、视频监控等需求不断多样化和丰富化,吸引越来越多的研究者和研究机构投入到目标检测的研究热潮中。在城市人口不断增加、交通拥堵、安全问题日益严重的今天,城市公共场所的治理已经备受关注,实时监控系统的完善可以有效地改善城市公共治理问题。
早期的目标检测在探测感兴趣对象时一般经过预处理、滑动窗口、特征提取、特征选择、特征分类、事后处理、输出操作等6 个过程。然而,传统目标检测算法有很多缺陷。 一方面,由于物体的大小和纵横比不同,且照片中物体的位置不确定,就需要很多尺度的滑动窗口来搜索整个图像。因此就会产生很多不必要的滑动窗口。 再加上会产生很难确定数量的冗余候选框,计算量也会大大增加。另一方面,特征提取算法经过人为设计,很难成为一种既能描述各种对象又具有较高通用性的完美算法。
随着科技的发展,算力不断提升,又因卷积神经网络的出现,基于深度学习的计算机视觉处理方法得到越来越广泛的应用。 其中,基于深度学习的目标检测方法是通过构建深层神经网络模型,经过学习不断优化网络参数,从训练集中提取特征信息,从而完成目标检测的任务。目前,许多深度学习虽然相比于传统算法,算力上有很大程度的提升,但在实际应用场景中,庞大且复杂的深层神经网络依旧难以应对移动端移植的问题。 在自动驾驶、边缘穿戴等实际任务中,能够同时满足精度高、速度快和硬件要求低的网络在市场中备受青睐。 因此,使用各种方法对深度学习模型进行压缩和加速,降低模型的参数量和计算量,使其能够应用于存储和计算资源有限的场景中,一直是研究人员努力探索的目标。
有人尝试将紧凑型网络应用于目标检测任务的深层神经网络中。 然而,由于这种网络的参数量低,其特殊的结构难以与其他的压缩和加速方法联合使用,且泛化能力较差,不适合作为预训练模型帮助训练其他模型,因而无法满足目标检测任务所需的精度和泛化性的要求。为了解决这些问题,本文开展了相关的研究。针对YOLOv5 网络架构,首先,采用ShuffleNetv2[1]作为主干网络,ShuffleNetv2 是一种在ShuffleNetv1[2]及MobileNetv2[3]基础上通过分析两者的缺陷并进行改进的轻量化网络,具有精度高、速度快的优点[4]。相比于CSPDarkNet53,该网络具有极小的参数量。其次,添加Stem 模块,确保较强的特征表达能力,且能够减少大量的参数。 还使用coordinate attention 加强对重要信息的聚焦。 再次,针对改进后的网络架构以及VOC2007 数据集检测任务中类别的互斥性,使用二元交叉熵损失函数。在保证精度的前提下,本文优化了YOLOv5网络结构的计算量和参数量,得到了高性能轻量化目标检测模型。最后,在PASCAL VOC2007 数据集上进行了实验。
1 轻量级目标检测模型
YOLO 是Redmon 等人[5]提出的一种端对端实时对象检测算法,它使用卷积神经网络来执行图像的特征提取、对象分类与定位,具有高效的优点,但在精度方面存在欠缺。YOLOv2 算法利用K-means 聚类预处理先验框的大小,将先验框聚类为长宽不同的9 类,以检测大小尺度不同的目标,从而弥补了YOLO 精度方面的缺陷。尽管如此,YOLOv2 没有关注不同尺寸图像的训练问题,在小目标检测中效果不佳。在后来的研究中,YOLOv3 的出现,在YOLOv2 的基础上,使用特征金字塔网络以改善检测性能,尤其是在小目标检测中提升显著。不过,YOLOv3 在检测复杂特征的物体时性能仍然有待提升。在YOLOv3的基础上,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面进行了不同程度的优化。YOLOv4 算法用于林火检测中,使模型的性能得到了提升。YOLOv5 网络开源架构使得YOLO 系列目标在计算机视觉应用上更进一步[6-7]。 YOLOv5 在Backbone 上采用了CSPDarknet53、Mish 激活函数和Dropblock,在Neck 中采用了SPP 结构等。同时,借鉴了CutMix[8]方法在输入端采用了mosaic 数据增强,有效解决了模型训练中最头疼的“小目标问题”。YOLOv5 的提出推动了YOLO 模型的轻量化和精准化的发展。
近年来,很多学者根据YOLO 的网络特点对其进行了有针对性的改进,以利于YOLO 系列网络在各个领域中的应用。彭玉青等人[9]对YOLO网络的层数和参数进行调整,基于空间金字塔池化方法对图像进行多尺度输入。深度卷积网络在进行特征提取时,不同层次的特征图所包含信息的侧重不同[10],Kim 等人[11]对YOLO-V3进行改进,采用空间金字塔池化方法,并引入五个不同尺度的特征图加强网络提取特征的能力。Li 等人[12]使用四个检测层以提高YOLO-V3对小目标的检测性能。He 等人[13]增加了另一个快捷连接,在两个“剩余单元”之间连接两个CBL,以提高信息传输特征提取网络的性能。
2 本文方法
YOLOv5 模型在目标检测领域取得了非常好的效果,然而其参数量有待进一步优化。 本文的方法使用较少的模型参数量和计算量,提高了模型的检测速度。
(1)采用ShuffleNetv2 替换YOLOv5 原有的CSPDarkNet53。
(2)加入Stem Block,确保特征提取网络拥有较强的特征表达能力,以弥补更换特征提取网络后丢失的精度,且该模块只占据很小的参数量。
(3)在主干网络的末端添加CA(Coordinate Attention),虽然模块有一定的参数量,但整体上比YOLOv5 仍减少了90% 的参数量,且提升了精度。
(4)使用二元交叉熵损失函数,针对数据集进行设计,利用类别间互斥性提升训练效果。改进后的模型架构如表1 所示。

表1 改进模型的提取网络结构
2.1 轻量级特征提取网络
ShuffleNetV1 结构中引入了“通道随机播放”操作,可以使用不同信道的通信。同时,还采用瓶状结构和逐点群卷积的技术,以提高准确性。
对于轻型级模型来说,逐点群卷积与瓶颈状结构增加了内存访问的成本(Memory Access Cost,MAC),与G1 和G2 相违背,这一成本大大增加了轻型网络的负担。并且,group 的过多使用也违反了G3。同样,shortcut connection 中element-wise add操作也违反了G4。所以,本文要解决的问题是,如何在不密集卷积和分组过多的前提下,还可以保持大量的且同样宽的信道。
ShuffleNetV2 的出现,针对ShuffleNetV1 的问题做出了改进,如图1(c)所示,在每个单元的开始,c 特征通道会输出两个分支(ShuffleNetV2 中对channels 分成两半)。 根据G3,group 不能过多,所以,其中一个分支不改变,由三个卷积组成另一个分支,它们具有相同的输入和输出通道以满足G1。 为了满足G2,两个1×1 卷积由组卷积改变为普通的卷积操作。经过卷积操作将两个分支连接起来,而并非相加(G4)。所以,此时通道数不变(G1)。然后,再使用“channels shuffle”操作来实现两个分支之间的信息通信,这里使用的“channels shuffle”与ShuffleNetV1 中使用的操作是相同的。此时,不再使用ShuffleNet v1 中的“Add”(累加)操作。由于对空间下采样单元的修改(移除通道分离操作符),输出的通道量相比原来增加了一倍,如图1(d)。图1(c)、图1(d)的构建块与由此产生的网络就是ShuffleNet V2。因此可以得出结论,它遵循了所有的指导原则,该体系结构的设计也是高效的。
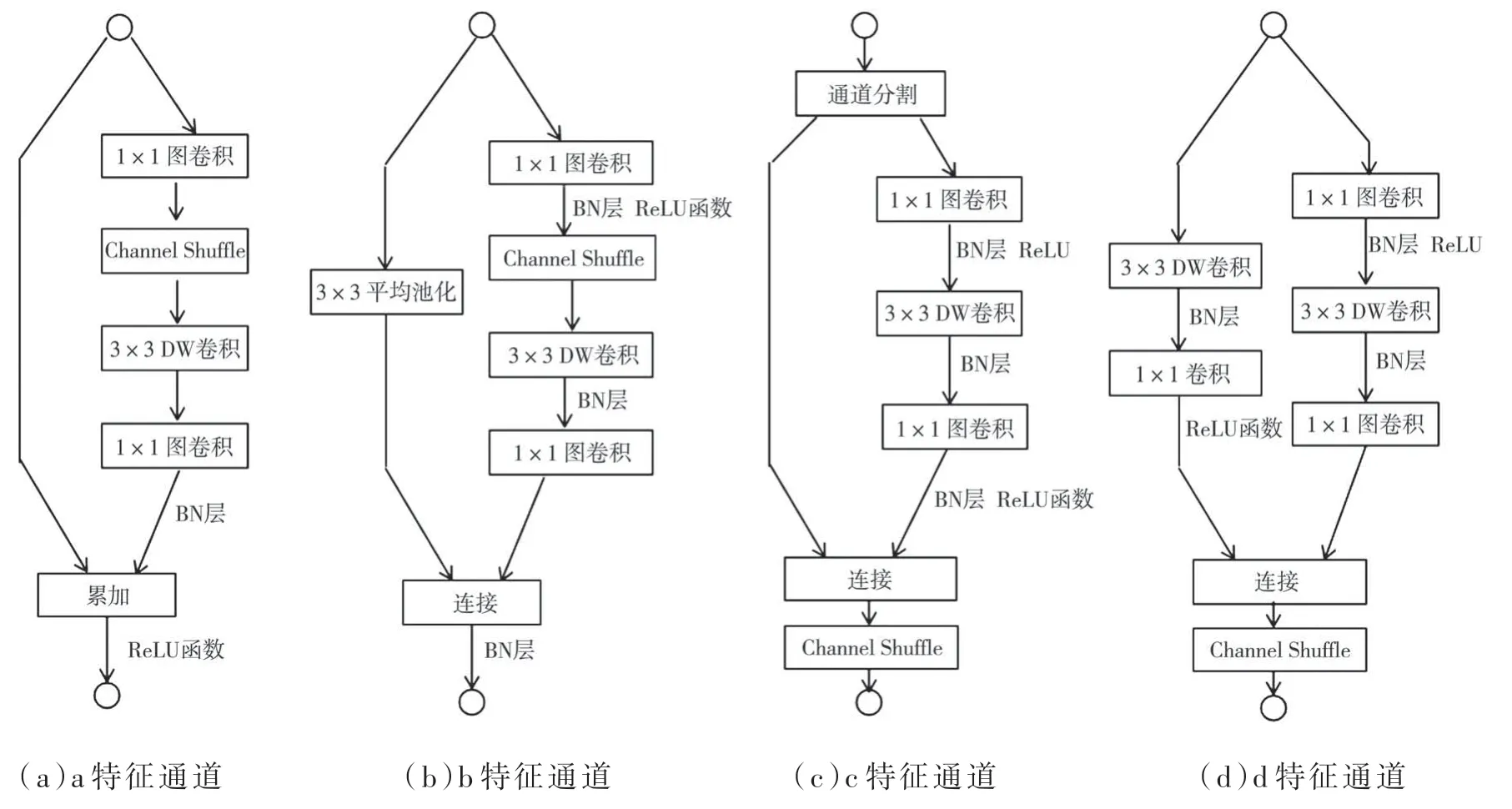
图1 ShuffleNetV2 结构
2.2 Stemblock
Stemblock 结构是PeleeNet 中用于下采样的方法。 在模型中添加Stemblock,使其拥有很强的特征表达能力。其结构如图2 所示。
在该结构中,首先,对输入特征图进行卷积操作并改变其通道数,此时卷积核大小为3×3。其次,特征图通过网络结构的两个分支同样分为了两个部分。其中,一个分支的特征图会通过最大池化下采样的操作,而特征图的另一部分会先进行1×1 卷积,此时通道数只有原来的1/2,接着进行3×3 的卷积。接着,再将两个分支的输出的特征图进行拼接,最后,使用1×1 卷积操作还原通道数量。与原始卷积运算相比,Stemblock结构的优势是在减少参数量的同时,又更好地保留了语义信息,最大可能地减少了信息的丢失。
2.3 Coordinate Attention
这种新的注意力机制可以让网络使用很小的计算成本,将位置信息嵌入到通道注意力中,并参与更大的区域信息计算。所以可以先将通道注意力分为两个并行的特征编码分支,目的是使注意力图包含整个的空间信息,由此减轻2D 全局池化所引起的位置丢失。简单来说,就是将水平与垂直方向的两个输入特征通过两个一维的全局池化操作,聚合成两个独立的拥有方向感知的特征图。这两个特征图被嵌入了特定的方向信息,还被编码成两个注意力图,所以,每个由此生成的注意力图都很好地保存了位置信息。 为了能更好地强调感兴趣的信息,这里将两个注意力映射经过乘法应用到输入的特征映射中。 这种操作能够区分空间方向,同时生成坐标感知注意力图,因此,注意力方法也称为坐标注意力,如图3 所示。
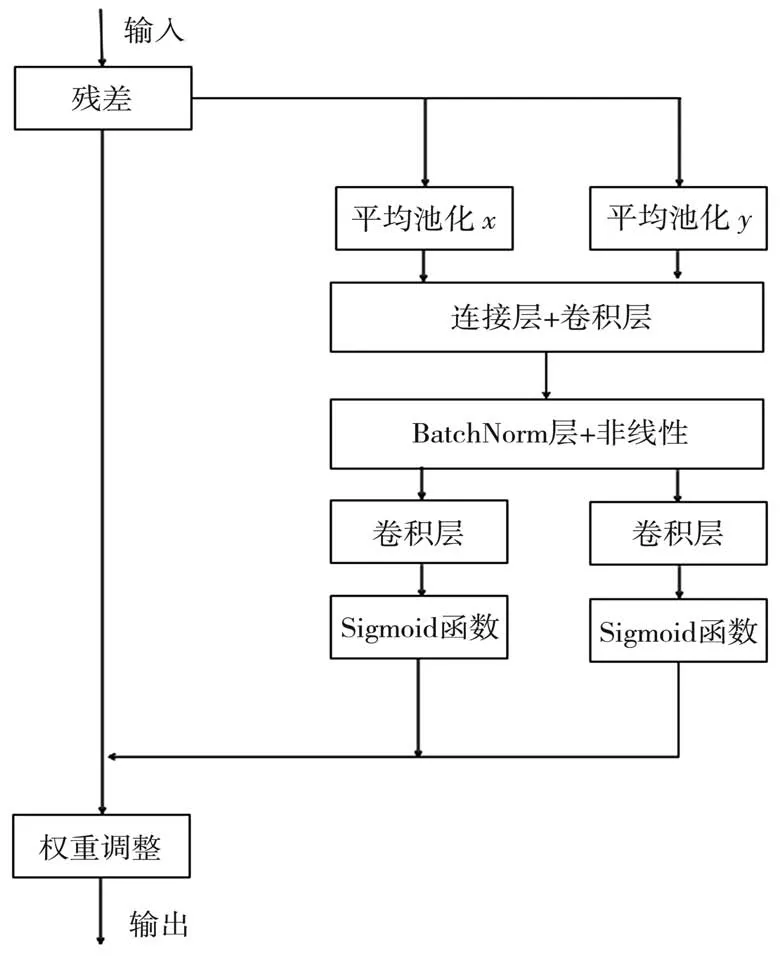
图3 注意力机制原理图

图4 使用Labellmg 进行数据集的标注
注意力机制将输入特征与两个单一方向的垂直和水平识别特征相结合。两个具有嵌入式方向特定信息的特征映射分别被编码为两个内存映射,每个内存映射捕获输入空间方向的特征映射的远程依赖性。 因此,位置信息可以存储在生成的注意映射中。 然后,通过乘法将两个注意力映射应用于输入特征映射以强调兴趣的表示。
坐标注意力不仅可以获取位置敏感信息和方向感知,还能获取跨通道信息,所以能够很好地获取感兴趣的对象和信息。 同时,由于该方法具有轻量和灵活的特点,可以随意地插入到移动网络。最后,作为预训练模型,协调注意力可以为移动网络的下游任务带来显著的性能提升,特别是对于那些密集预测的任务。
本文将该注意力机制模块用在改进后目标检测网络的特征提取网络的末端,目的是加强注意力的聚焦程度,从而弥补替换特征提取网络所引起的提取能力的降低。
2.4 二元交叉熵损失函数
在YOLOv5 中,原先采用的是BCEWithLogitsLoss,其将Sigmoid 添加到loss 函数中。 Sigmoid概率和不为1,需要将sigmoid 函数应用于每个原始的输出值,输出预测将是那些能够超过概率阈值的类,因此,同一目标可能会划为多个类别,这是考虑到自然场景下同一个目标可能属于多个类别。
然而,在VOC2007 数据集中,所有的类别都是互斥的,不存在同一个目标具有多个类别的属性。因此,使用二元交叉熵损失函数,该损失函数同时使用了LogSoftmax 和NLLLoss。 关于LogSoftmax,每个元素都会在0 到1 的范围内,元素加起来就是1。这样就可以理解为概率分布,其输入数字越大,概率越大。 它确保所有的输出概率之和等于1(或接近1)。在处理流程中,对输入数据先做log_softmax,再过NLLLoss。交叉熵公式如下:
3 实验与结果
3.1 实验配置
为了避免测试数据因实验环境的不同而发生变化,本文中所有测试均在相同的硬件和软件环境下进行。硬件环境配置参数如表2 所示,软件环境配置如表3 所示。

表2 硬件环境配置

表3 软件环境配置
为了满足实验要求,本文使用VOC2007 数据集进行训练,VOC 数据集有20 类,针对监控系统下实时检测类的数量可以很好的满足,由于本模型注重对车辆和行人的检测,所以选取1 182张车辆数据集,和1 327 张行人数据集并使用LabelImg 进行标注。
为了证明方案的有效性,使用原YOLOv5 模型,只替换过主干网络的YOLOv5-Shuffle 模型和本文改进后的三个模型进行训练和测试。
训练开始前,为了避免纵横比不匹配对训练结果的影响,本文将数据集中的所有图像均裁剪成512×512 大小。考虑到GPU 显存大小,参数设置如下:Batch_size(批尺寸)为12,Initial learning rate(初始学习率)为0.002,每次训练300 epochs。本文将VOC2007 划分为训练集、验证集和测试集,并将训练集、测试集和验证集进行7∶2∶1 的划分。
采用Xavier initialization 来初始化神经网络的每一层。实验所涉及的所有超参数如表4 所示。

表4 实验参数设置
3.2 评价指标
在目标检测领域,样本可分为四种类型:true positive( TP )、false positive( FP )、true negative( TN)和false negative( FN ),根据其真实类和预测类的组合进行划分。
为了量化所提出的网络与其他网络的性能比较,本文使用典型的评价指标,比如,精确率(P)和召回率(R),公式如下:
平均精度(AP)是P-R curve 下方的面积,就是对P-R curve 的Precision 值求均值。 对于P-R curve 来说,使用定积分来进行计算:
在目标检测性能测试的实际计算中,还要对P-R curve 进行平滑处理。 对P-R curve 上的每个点,Precision 值计算公式如下:
mAP 是对多个类别mAP 求平均值。由于本文的方法只对路面物体进行检测,所以mAP 和AP 在本文的含义是相同的。mAP 是目标检测中衡量性能的最重要的一个指标。
Params 和FLOPs 是用于衡量模型复杂性的指标。 FPS 代表检测器每秒可以处理的图片帧数,数值越大代表检测速度越快。
3.3 实验结果
横坐标是训练轮次,纵坐标是mAP 值,原模型与本文改进模型mAP 的对比如图5 所示。

图5 模型的mAP 对比
改进后的模型检测效果如图6 所示。

图6 改进模型检测效果
表5 为原模型与改进模型复杂度和帧数的对比。

表5 模型的测试结果对比
从图5 与表5 显示的实验结果可知,替换主干网络后的YOLOv5-Shuffle 模型会造成很大的精度损失,平均精确度降低了0.15,对于车辆和行人拥挤的场景下,这样的模型不适合用于实时监控领域。而本文提出的改进方法将参数量和计算量都减少到了原来的1/10 左右,检测帧数同样提高了17 点,而平均精确度只降低0.08,所以本模型在大幅度提高了模型的运算速度前提下,很好地控制了精度损失。
4 结论
本研究基于YOLOv5 提出了一种改进的目标检测算法。采用ShuffleNetv2 替换了原先的CSPDarknet53,并且使用Stem Block、Coordinate Attention、二元交叉熵损失函数弥补了替换特征提取网络引起的精度损失。其中,使用Stem Block 对网络进行轻量化处理,填补替换特征提取网络后对网络实时性能造成的损失。 Coordinate Attention耗费很小的结构,提升了网络的精度和目标框边界的回归能力。本文所提出的轻量级的网络架构可以用于自动驾驶等领域中。考虑到驾驶环境的复杂性和多变性,网络仍需进一步完善。因此,未来的工作中将对网络进一步轻量化并使其更好地应用于目标跟踪领域。 另外,Head阶段中上采样部分仍可继续改进,如何使用一些复杂度较低的图像超分辨算法,可以更好地检测出小目标。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
