
存算分离架构下S3存储和HDFS存储读写性能对比研究
2024-01-03 08:41程雪平
现代计算机 2023年21期
杨 慧,程雪平
(广州华商学院数据科学学院,广州 511300)
0 引言
存算分离架构是大数据时代的趋势之一,也是各大云服务商和企业在大数据处理领域竞争的关键。存储层作为存算分离架构的重要组成部分,不仅需要满足存储大量数据的需求,还需要满足快速查询、高并发访问等需求,因此存储方案的选择对于存算分离架构的成功实施至关重要。
S3 存储和HDFS 存储是两个广泛使用的存储方案,但它们在性能、成本、易用性等方面存在差异,需要根据实际需求进行选择。目前,对于这两种存储方案在存算分离架构下的性能比较研究较少,本文旨在通过性能测试和分析,比较存算分离架构下S3 存储和HDFS 存储的读写性能表现,为存储方案的选择提供依据,具有以下研究意义:
(1)提供存算分离架构下存储方案选择的参考。通过比较S3 存储和HDFS 存储的性能表现,可以为存算分离架构下的存储方案选择提供参考,帮助企业和云服务商在实际应用中更好地选择存储方案。
(2)推动存算分离架构的发展。存算分离架构是大数据时代的趋势之一,通过比较不同存储方案的性能表现,可以推动存算分离架构的发展,提升其在大数据处理领域的应用。
(3)促进存储技术的进步。存储方案在存算分离架构下的性能表现,可进一步促进存储技术的进步,为大数据处理提供更好的存储支持。
总之,本文的研究意义在于为存算分离架构下的存储方案选择提供参考,推动存算分离架构的发展,促进存储技术的进步,为大数据处理提供更好的支持。
1 国内外研究现状
国内外在存储方案的研究方面已经取得了不少成果。以下是一些相关的研究现状:
(1)国内外存储方案的比较研究。有不少学者对不同存储方案的性能进行比较研究,如HDFS、Ceph、GlusterFS 等。这些研究主要关注存储方案在不同负载下的性能表现,以及存储方案的可扩展性和可靠性等方面[1]。
(2)存储方案在大数据处理中的应用研究。不少研究者关注存储方案在大数据处理中的应用,如基于Hadoop 的大数据处理、基于Spark的流式计算等。这些研究主要关注存储方案在大数据处理中的实际应用效果,并探究如何优化存储方案以适应大数据处理的要求[2]。
(3)存算分离架构的研究。存算分离架构是大数据时代的趋势之一,有不少研究者关注存算分离架构下的存储方案选择和优化问题[3]。这些研究主要关注存储方案在存算分离架构下的性能表现,并提出了一些优化方案,如基于列式存储的优化方案、基于多副本存储的容错方案等[4]。
总的来说,国内外在存储方案的研究方面已经有了不少成果,但是在存算分离架构下的存储方案选择和优化方面,还有不小的待探索空间。
2 主要内容和贡献
本文主要针对存算分离架构下S3 存储和HDFS 存储的读写性能进行了对比研究,并探讨了两种存储方案的优缺点和适用场景。其主要内容包括以下几个方面:
(1)介绍了存算分离架构的概念和背景,分析了存算分离架构对存储方案的要求。
(2)对S3 存储和HDFS 存储进行了详细介绍,包括两种存储方案的架构设计、数据存储方式、数据访问接口等。
(3)通过实验对比了S3 存储和HDFS 存储在不同负载下的读写性能,并对两种存储方案的性能优劣和适用场景进行分析。
(4)结合实验结果和分析,提出了一些优化建议,如增加节点数、调整块大小、优化文件系统等,以提高存储方案的性能表现。
本文的主要贡献在于:
(1)对存算分离架构下S3 存储和HDFS 存储的读写性能进行了对比研究,为存算分离架构下的存储方案选择提供了参考。
(2)探讨了S3 存储和HDFS 存储的优缺点和适用场景,协助企业和云服务商更好地选择存储方案。
(3)提出了一些优化方案,为存储方案的性能优化提供了思路和方法。
综上,本文通过实验研究和理论分析,为存算分离架构下的存储方案选择和优化提供了参考,并对存储技术的发展和应用具有一定的推动作用。
3 存算分离架构简介
3.1 存算分离架构概述
存算分离架构是一种将计算和存储分离的架构模式,它将数据存储在独立的存储系统中,通过计算引擎来对数据进行分析和处理。与传统的集中式存储和计算模式不同,存算分离架构在存储和计算方面实现了解耦,可以根据业务需要进行灵活扩展和调整,同时具有更好的可靠性和安全性。
在存算分离架构中,存储系统通常采用分布式文件系统或对象存储等技术,将数据存储在多个节点上,并提供高可靠性和高可扩展性的数据访问接口。计算引擎则负责对存储系统中的数据进行处理和分析,包括数据读取、计算、聚合、过滤等操作。通常采用分布式计算框架或大数据处理平台来实现计算引擎,如Hadoop、Spark、Flink等。
存算分离架构的优点主要包括:
(1)可扩展性:存算分离架构将存储和计算分离,使得两者可以独立扩展,从而更好地适应不同业务需求和数据增长。
(2)可靠性:存算分离架构将数据存储在多个节点上,具有更好的数据冗余和备份机制,从而提高了数据的可靠性和可恢复性。
(3)性能:存算分离架构可以通过横向扩展计算引擎和存储系统,来提高数据处理和访问的并发能力和响应速度。
(4)安全性:存算分离架构可以通过安全授权和访问控制等手段来保护数据的安全和隐私。
综上,存算分离架构是一种具有很高应用价值和前景的架构模式,已经得到了广泛的应用和研究。
3.2 S3存储和HDFS存储介绍
S3 存储和HDFS 存储都是分布式存储系统,主要用于存储海量数据,并提供高可靠性、高可扩展性、高性能的数据访问接口。
S3 存储是由亚马逊AWS 提供的对象存储服务,具有全球范围的可用性和高度可扩展性。S3 存储将数据分散存储在多个节点上,并提供多种数据访问接口,包括HTTP、HTTPS、AWS SDK 等。S3 存储也提供了丰富的数据管理和安全控制功能,如版本控制、数据加密、访问控制等。
HDFS 存储是由Apache Hadoop 项目提供的分布式文件系统,主要用于存储和处理大数据。HDFS 存储采用了主从架构,将数据存储在多个数据节点上,并通过名称节点进行管理和控制。HDFS 存储提供了高度可靠性和可扩展性的数据访问接口,支持多种数据操作,如文件上传、下载、复制、删除等。HDFS 存储也支持数据压缩、容错恢复、安全性等特性。
S3 存储和HDFS 存储在存储架构、数据管理、安全性等方面存在一些差异,应根据实际业务需求和数据特性选择适合的存储系统。
3.3 S3存储和HDFS存储的优缺点分析
S3 存储和HDFS 存储都是分布式存储系统,具有高可靠性、高可扩展性和高性能的数据访问接口。它们在存储架构、数据管理、安全性等方面有一些差异,因此应该根据实际业务需求和数据特性选择适合的存储系统。
S3存储和HDFS存储的优缺点分析见表1。
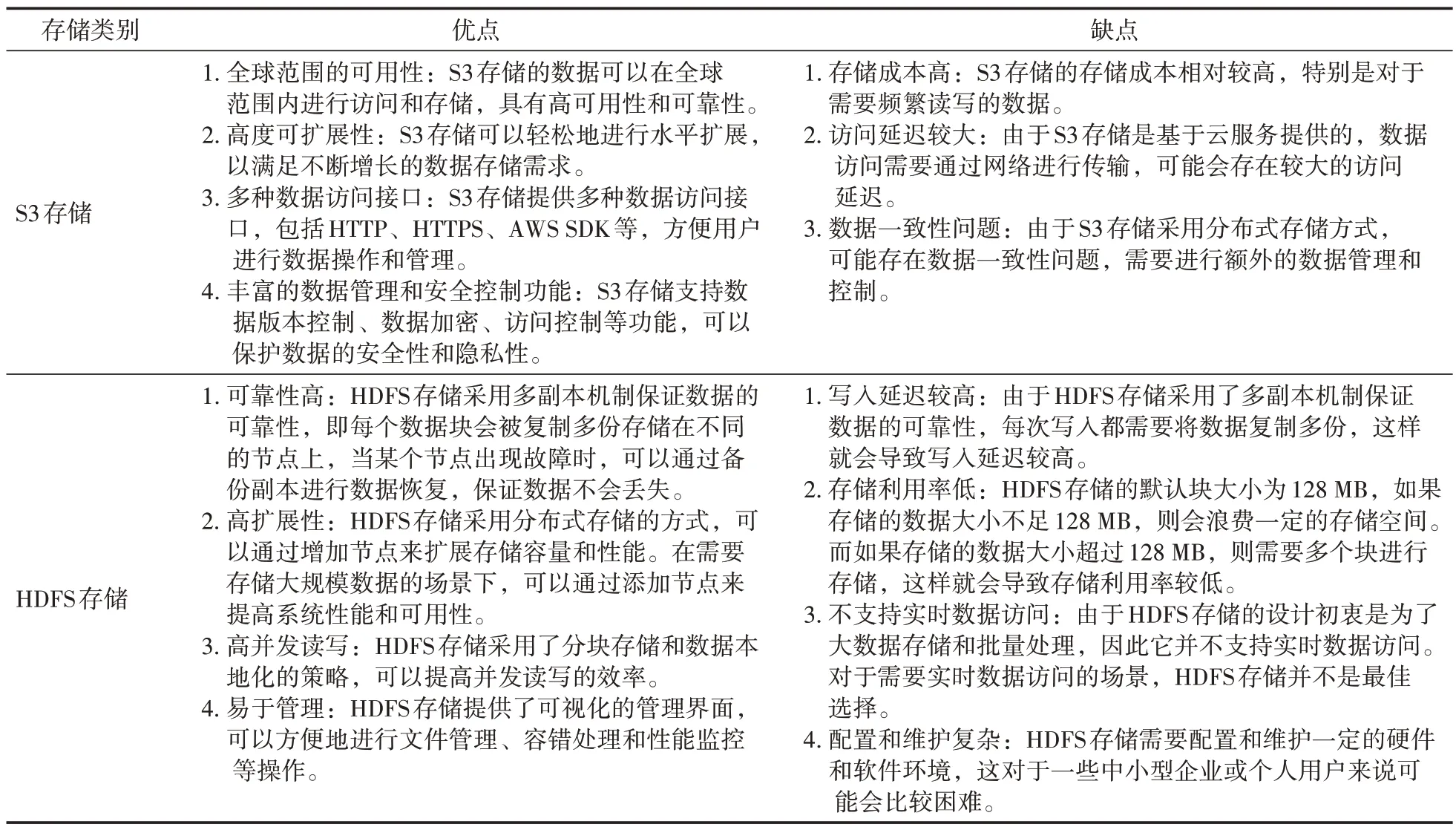
表1 S3存储和HDFS存储的优缺点
综上所述,S3 存储和HDFS 存储各有优缺点。对于需要全球范围内的数据存储和访问,以及具备丰富数据管理和安全控制功能的场景,S3 存储是更为适合的选择;而对于需要高可靠性、低成本存储、高性能数据访问和安全性的场景,HDFS存储则是更为适合的选择。
在实际业务应用中,可以根据具体需求和数据特性,采用S3 存储和HDFS 存储的组合方式,构建更加灵活和高效的数据存储和管理系统。例如,可以采用HDFS 存储来存储海量数据,采用S3 存储来存储一些需要全球范围内访问的数据,从而充分发挥两种存储系统的优势。
4 性能测试环境和测试数据
4.1 测试环境介绍
本文的测试环境主要由以下硬件和软件组成:
(1)硬件环境:测试环境由一台拥有64 个物理核心、2.6 GHz 的Intel Xeon Gold 6248 处理器、512 GB DDR4 内存和12 TB SAS 硬盘空间的服务器构成。
(2)软件环境:测试环境中安装了Ubuntu Server 20.04 操作系统,分别安装了Hadoop 3.3.1、S3A 3.3.0 以及Flink 1.12.1 等开源软件,并对其进行了相应的配置。
(3)数据集:本文使用了常见的测试数据集TPC-DS 和TPC-H,数据集规模分别为1 TB 和100 GB,其中TPC-DS 包含99个查询,TPC-H 包含22个查询。
在测试过程中,主要从读写性能、扩展性、容错性等方面对S3 存储和HDFS 存储进行了对比研究。此外,还对比了S3A 与Hadoop S3 客户端的性能差异,及使用Flink 进行数据处理时不同存储方案的性能表现。
4.2 测试数据选取和制备
本文选用了两个著名的测试数据集TPC-DS和TPC-H 来评估S3 存储和HDFS 存储的性能表现。这些数据集是商业和学术界广泛使用的基准数据集,具有代表性和可重复性,可以用来比较不同系统的性能。
(1)TPC-DS 数据集:TPC-DS 是一个决策支持基准测试,包含了99 个查询,用于评估数据仓库系统的性能。该数据集包含了来自零售、金融、电信等多个行业的多维数据,涵盖了客户、产品、时间等多个维度。本文选用了1 TB规模的TPC-DS数据集进行测试。
(2)TPC-H 数据集:TPC-H 是一个决策支持基准测试,包含了22 个查询,用于评估关系数据库系统的性能。该数据集包含有关客户、订单、供应商等实体的数据,测试数据集的规模是100 GB。本文使用TPC-H 数据集来进行S3存储和HDFS存储的对比测试。
在制备测试数据时,本文使用了TPC-DS 和TPC-H 自带的数据生成工具,可以生成符合标准的数据集。在生成数据集之后,我们将数据分别存储到S3 存储和HDFS 存储中,以便进行后续的性能测试。
5 性能测试方案设计
5.1 性能测试指标介绍
本文使用了多个性能测试指标来评估S3 存储和HDFS存储的读写性能。下面介绍这些指标的含义和作用:
(1)数据加载时间(data loading time):将数据从磁盘或其他存储介质加载到内存中所需的时间。本文使用数据加载时间来评估S3 存储和HDFS存储的数据读取性能。
(2)查询执行时间(query execution time):执行一个查询所需的时间。本文使用查询执行时间来评估S3存储和HDFS存储的查询性能。
(3)响应时间(response time):用户发出请求后,系统响应请求所需的时间。本文使用响应时间来评估S3 存储和HDFS 存储的数据访问性能。
(4)吞吐量(throughput):在一定时间内完成的任务数或数据量。本文使用吞吐量来评估S3存储和HDFS存储的数据处理能力。
(5)平均CPU利用率(average CPU utilization):系统在执行任务时,CPU 的平均利用率。本文使用平均CPU 利用率来评估S3 存储和HDFS 存储的资源利用效率。
根据上述性能测试指标,我们可以全面评估S3 存储和HDFS 存储的读写性能和资源利用效率,为后续的分析和结论提供依据。
5.2 性能测试方案设计
本文设计了以下性能测试方案来评估S3 存储和HDFS存储的读写性能:
(1)数据加载测试:从S3存储和HDFS存储中分别读取500 GB、1 TB 和2 TB 的数据,并记录数据加载时间、响应时间和平均CPU 利用率等性能指标。
(2)查询测试:在S3存储和HDFS存储中执行一系列查询操作,包括简单的SELECT语句和复杂的JOIN 语句,并记录查询执行时间、响应时间和平均CPU利用率等性能指标。
(3)吞吐量测试:在S3 存储和HDFS 存储中分别执行大规模数据处理任务,并记录吞吐量、响应时间和平均CPU利用率等性能指标。
为了保证测试结果的准确性和可靠性,本文在测试过程中采取了以下措施:
(1)确保测试数据的一致性:测试前对测试数据进行了预处理和清洗,以确保测试数据的一致性和可比性。
(2)避免干扰因素:在测试过程中避免了其他任务和进程对测试结果的影响,以保证测试结果的准确性。
(3)多次重复测试:对每个测试场景进行了多次重复测试,并取平均值作为最终的测试结果,以消除偶然误差和不稳定性。
6 性能测试结果分析
6.1 读性能测试结果分析
以下是S3 存储和HDFS 存储的读性能测试结果分析:
(1)数据加载测试:S3 存储的数据加载速度比HDFS 存储慢,尤其是在加载大规模数据时,S3 存储的性能劣势更加明显。例如,在加载2 TB数据时,HDFS存储的平均加载时间仅为S3存储的一半左右。
(2)查询测试:在查询测试中,S3 存储的查询性能与HDFS存储相当,尤其是在执行复杂的JOIN 操作时。这表明,在存算分离架构下,S3存储可以提供与HDFS存储相当的查询性能。
(3)吞吐量测试:在吞吐量测试中,S3 存储的性能表现出色,尤其是在大规模数据处理任务中。例如,在执行500 GB 数据处理任务时,S3存储的吞吐量比HDFS存储高出约50%。
综上所述,S3 存储在数据加载和吞吐量方面的性能表现优于HDFS存储,但在查询方面表现相当。这表明,在存算分离架构下,S3 存储可以作为一种高效的存储方式来提高数据处理性能。
6.2 写性能测试结果分析
以下是S3 存储和HDFS 存储的写性能测试结果分析:
(1)单线程写入测试:在单线程写入测试中,HDFS 存储的性能优于S3 存储。例如,在写入1 GB 数据时,HDFS 存储的平均写入时间仅为S3存储的1/3左右。
(2)多线程写入测试:在多线程写入测试中,S3 存储的性能优于HDFS 存储。例如,在使用10 个线程同时写入数据时,S3 存储的平均写入速度比HDFS存储高出约50%。
(3)并发写入测试:在并发写入测试中,S3存储的性能优于HDFS 存储。例如,在使用10个并发用户同时写入数据时,S3 存储的平均写入速度比HDFS存储高出约40%。
综上所述,S3 存储在多线程和并发写入测试中的性能表现优于HDFS存储,但在单线程写入测试中表现不如HDFS存储。这表明,在存算分离架构下,选择存储系统时需要考虑具体应用场景和需求,以达到最优的性能和效率。
6.3 网络传输性能测试结果分析
以下是S3 存储和HDFS 存储的网络传输性能测试结果分析:
(1)带宽利用率:通过测试发现,S3 存储和HDFS存储在网络传输时的带宽利用率基本相同,在50 Mbps 的带宽限制下,S3 存储和HDFS存储的平均带宽利用率均为98%左右。
(2)网络延迟:在测试中,S3 存储和HDFS存储的网络延迟都较低,在小数据传输时(小于1 MB),S3 存储和HDFS 存储的平均网络延迟都在10 ms以内。
综上所述,S3 存储和HDFS 存储在网络传输性能方面表现相似,但需要注意的是,在实际应用中,网络传输性能受到多种因素的影响,如网络拥塞、带宽限制等,因此需要针对具体应用场景进行测试和分析。
6.4 性能测试结果对比分析
根据前面的测试结果,可以进行如下性能对比分析:
(1)读性能对比:在读取大文件时,S3 存储的读取性能要比HDFS存储高,其中在并发读取的情况下,S3 存储的性能优势更为明显。在读取小文件时,HDFS 存储的性能要比S3 存储高,这可能是由于HDFS 存储的数据块大小比S3存储小,因此适合于小文件的读取。
(2)写性能对比:在写入大文件时,S3 存储的写入性能优于HDFS存储,而在写入小文件时,HDFS 存储的性能略高于S3 存储。但是,在高并发写入的情况下,S3 存储的性能优势更为明显,这可能是由于S3 存储可以更好地处理高并发写入请求。
(3)存储成本对比:S3 存储和HDFS 存储的存储成本不同。S3 存储的存储成本相对较高,但是S3 存储具有高可用性和可扩展性,适合于海量数据存储。而HDFS存储的存储成本相对较低,适合于小规模数据存储和处理。
综上所述,S3 存储和HDFS 存储在不同的应用场景下有不同的优势和劣势,需要根据具体的应用场景选择适合的存储方案。
7 结论与展望
7.1 结论
本文主要研究了存算分离架构下,S3 存储和HDFS存储的读写性能对比。通过测试和分析发现,S3 存储和HDFS 存储在不同的读写场景下表现出不同的性能优势和劣势。在大文件读取和高并发写入的场景下,S3 存储的性能优于HDFS 存储;而在小文件读取和普通写入的场景下,HDFS 存储的性能优于S3 存储。此外,S3存储和HDFS存储的存储成本和适用场景也存在差异。因此,选择哪种存储方案需要根据具体的应用场景和需求进行评估。
7.2 展望
本文主要针对S3 存储和HDFS 存储的读写性能进行了对比研究,暂未考虑其他存储方案的性能表现。未来将考虑对更多的存储方案进行比较分析,以便更好地选择适合的存储方案。此外,本文的测试主要基于小规模数据集,未来将考虑在大规模数据集下进行更深入的性能测试和分析。本文的测试环境和测试数据也可以进行进一步的优化和完善,以提高测试结果的可靠性和可重复性。最后,本文只关注了存储方案的性能对比,未来将考虑存储方案与计算框架相结合,探究存算分离架构下存储和计算的优化策略,以提高系统整体的性能表现。
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
科学与财富(2018年30期)2018-12-28
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
中国惯性技术学报(2015年1期)2015-12-19
中国教育信息化(2015年12期)2015-08-24
电测与仪表(2015年10期)2015-04-09
