
基于改进YOLOv8s的钢材表面缺陷检测
2024-01-02 07:47张文铠刘佳
北京信息科技大学学报(自然科学版) 2023年6期
张文铠,刘佳
(北京信息科技大学 自动化学院,北京 100192)
0 引言
钢材在生产和加工过程中会受到环境中各种因素的影响,导致表面出现裂纹、斑块和划痕等各类缺陷,必须对其表面进行缺陷检测。
近年来,目标检测算法快速发展,逐渐从传统的目标检测转向基于深度学习的目标检测。基于深度学习的目标检测算法大致可分为两大类:两阶段检测和一阶段检测。两阶段检测算法的代表主要是基于区域的卷积神经网络(region based convolutional neural networks,R-CNN)[1]系列算法,比如Fast R-CNN[2]和Faster R-CNN[3]。一阶段检测算法的代表主要是单步多框检测器(single shot multibox detector,SSD)[4]和YOLO(you only look once)[5]系列算法。目前已有许多研究将深度学习目标检测算法应用在钢材表面缺陷检测领域,如游青华[6]提出的基于深度学习的钢材表面缺陷检测方法,阎馨等[7]提出的基于改进SSD的钢材表面缺陷检测,Wang等[8]提出的基于改进YOLOv5算法的多尺度钢材表面缺陷检测。上述方法虽然在一定程度上提高了算法的性能,但在精度和参数量方面仍有不足之处。
由Ultralytics于2023年1月发布的YOLOv8模型,是目前YOLO系列最先进的目标检测模型,其在之前版本基础上,引入了一个新的主干网络、一个新的无锚(Anchor-Free)检测头和一个新的损失函数,进一步提升了模型的性能。为了保证钢材表面缺陷检测算法的先进性,本文在YOLOv8s算法的基础上做了相关改进。相比于目前主流的钢材表面缺陷检测算法,改进后的YOLOv8s钢材表面缺陷检测算法可以更加准确地检测出钢材表面缺陷的类别和位置,且模型参数量相对较小,便于在移动端部署。
1 改进的YOLOv8s算法
1.1 改进后的模型结构
为进一步提升钢材表面缺陷检测算法的精度,本文在YOLOv8s算法的基础上进行改进,主要改进3个方面:1)为了使模型关注更多维度的特征信息,将原主干网络第4、6、8层的C2f模块和原颈部网络第15、18层的C2f模块替换为C2f-Triplet模块;2)为了使模型在更大的感知区域内聚合上下文信息,将原颈部网络第10、13层的最近邻上采样模块替换为内容感知特征重组(content-aware reassembly of features,CARAFE)模块;3)为了提高模型收敛速度和回归精度,将原YOLOv8s的CIoU回归损失函数替换为SIoU损失函数。
1.2 C2f-Triplet模块
YOLOv8s网络结构中包含大量C2f模块,其主要功能是学习残差特征。因此,网络性能的优劣与C2f模块特征学习的情况密切相关。由于钢材表面缺陷在形态、位置、大小上差异较大,特别是裂纹类缺陷、点蚀表面类缺陷和轧制氧化皮类缺陷,同类缺陷形状和大小不一,且分布范围较广,原有的C2f模块对钢材表面缺陷的特征提取能力仍不足,缺少多维度的特征信息。所以,本文为进一步增强网络的学习能力,融合多维度的特征信息,设计了一个全新的模块——C2f-Triplet模块。C2f-Triplet结构将原C2f模块中所有的Bottleneck模块均替换为Triplet-Bottleneck模块。Triplet-Bottleneck模块在原Bottleneck模块的基础上在2个卷积层后增加Triplet注意力机制,使其拥有更强的特征提取和特征融合能力。
Triplet注意力机制使用三分支结构捕捉交叉维度交互来计算钢材表面缺陷的注意力权重,通过旋转操作和残差变换来建立维度间依赖关系,可以有效实现钢材表面缺陷特征信息的跨维度融合,并且这种注意力机制几乎是无参的。
Triplet注意力机制的网络结构如图1所示,该注意力机制由3个分支组成。当输入特征图大小为C(通道维度)×H(高度维度)×W(宽度维度)时,3个分支具体实现[9]如下:
1)第一个分支是对钢材表面缺陷通道维度C和高度维度H之间的特征信息进行交互。首先经过Permute函数将输入特征图沿H轴逆时针旋转90°,得到W×H×C的特征图,接着通过Z池化(Z-Pool)层在W维度上进行最大池化操作和平均池化操作,将特征图缩减为2×H×C大小,然后经过卷积(Conv)核大小为7×7的卷积层得到1×H×C的特征图,再经过批归一化(Batch Norm)层和Sigmoid激活层生成相应的注意力权重,最后将注意力权重乘回W×H×C特征图,并经过Permute沿H轴顺时针旋转90°,使其与输入特征图保持相同的形状,得到C×H×W的特征图。
2)第二个分支是对钢材表面缺陷通道维度C和宽度维度W之间的特征信息进行交互。首先经过Permute将输入特征图沿W轴逆时针旋转90°,得到H×C×W的特征图,接着通过Z-Pool在H维度上进行最大池化操作和平均池化操作,将特征图缩减为2×C×W大小,然后进行与第一个分支相同的操作,最终得到C×H×W的特征图。
3)第三个分支是对钢材表面缺陷的空间注意力权重进行计算。输入特征图首先经过通道池化(Channel Pool)得到2×H×W的特征图,然后经过卷积核大小为7×7的卷积层得到1×H×W的特征图,再经过批归一化层和Sigmoid激活层生成相应的注意力权重,最后将注意力权重乘回原始特征图,得到C×H×W的特征图。
最后对3个分支输出的C×H×W维度特征进行相加求平均值。
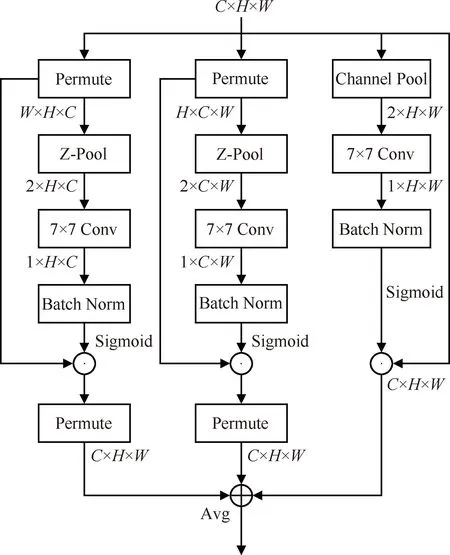
图1 Triplet注意力机制网络结构Fig.1 Triplet attention mechanism network structure
1.3 CARAFE上采样算子
YOLOv8s的上采样操作采用最近邻插值法,这种方法仅通过像素的空间位置来确定上采样内核,没有利用特征图的语义信息,感知域较小,特别是针对钢材表面缺陷这种范围较广且形态各异的特征,极易造成特征信息的丢失。而CARAFE上采样算子具有较大的感受野,可以在大的感知区域内聚合上下文信息,并且可以根据钢材表面缺陷特征图的语义信息生成自适应上采样核,有效避免特征信息的丢失,同时引入的计算开销很小,可以很容易融入网络架构中。因此,本文选用CARAFE上采样算子代替原有YOLOv8s中的最近邻插值上采样。
CARAFE上采样算子网络结构如图2所示。输入特征图X大小为H×W×C时,设定上采样倍率为σ,首先通过上采样核预测部分对上采样核进行预测,然后通过特征重组部分进行特征重组完成上采样,最终得到大小为σH×σW×C的新特征图X′[10]。
在上采样核预测部分,首先对通过通道压缩后大小为H×W×Cm的输入特征图进行内容编码,将通道数从Cm变为σ2×k2;然后将通道在空间维度上展开,得到形如σH×σW×k2的上采样核;最后对得到的上采样核通过Softmax函数进行核归一化,使卷积核的权重和为1,得到输出特征图T。
在特征重组部分,首先将输出特征图T进行空间维度展开,然后将输出特征图中的每个位置映射回输入特征图X中,取以其为中心的k×k的原特征图区域与该点的预测上采样核进行点积操作,相同位置的不同通道共享同一个上采样核,最终得到σH×σW×C的新特征图[11]。其中,X′的任意目标位置l′=(i′,j′),在X上都有源位置l=(i,j)与之相对应,N(Xl,k)为以位置l为中心的k×k大小的子区域,Wl′为上采样核预测部分预测的重组核。
1.4 SIoU损失函数
YOLOv8s的回归损失函数采用了CIoU损失函数。CIoU损失函数考虑了3个几何因素:重叠面积、中心点距离和长宽比。相比于之前的损失函数,虽然CIoU损失函数考虑的因素更加全面,但却没有考虑真实框与预测框之间方向不匹配的问题,使得模型在训练的过程中会出现预测框“四处游荡”的情况,从而导致收敛速度较慢且效率较低。
2022年,Gevorgyan[12]提出了一种新的目标检测损失函数——SIoU损失函数。这种损失函数考虑了回归之间的向量角度,重新定义了惩罚指标,解决了上述问题。与CIoU损失函数相比,SIoU损失函数收敛速度更快,准确性更高,因此,本文引入SIoU损失函数作为回归损失函数。SIoU损失函数由角度损失、距离损失、形状损失和IoU损失4个部分组成。
角度损失Λ定义如式(1)所示。增加这种角度感知组件可以最大限度地减少与距离相关的变量数量。
(1)
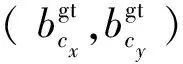
根据角度损失Λ重新定义了距离损失Δ。距离损失Δ与真实框和预测框的最小外接矩形有关,其定义如式(2)所示。
(2)
式中:ρx、ρy为真实框与预测框之间位置的偏离程度;rw、rh为真实框与预测框最小外接矩形的宽和高;γ为被赋予时间优先的距离值,与角度损失Λ有关。
形状损失Ω定义如式(3)所示。
(3)
式中:θ为形状损失的关注程度;ww、wh为预测框与真实框之间宽和高的拉伸程度;w、h为预测框的宽和高;wgt、hgt为真实框的宽和高。
IoU损失定义如式(4)所示。
(4)
式中:A表示预测框;B表示真实框。
最后SIoU损失函数LSIoU定义如式(5)所示。
(5)
2 实验及结果分析
2.1 数据集
本文实验数据集采用东北大学钢材表面缺陷数据集(NEU-DET)。该数据集收集了热轧钢带裂纹、杂质、斑块、点蚀表面、轧制氧化皮、划痕等6种常见缺陷,每种缺陷300张图片,共计1 800张图片。每种缺陷的典型样本如图3所示。

图3 NEU-DET数据集每种类型缺陷典型样本Fig.3 Typical samples of each defect type in the NEU-DET dataset
裂纹的形状较为复杂,多呈现为局部连续的树枝状向外发散,并具有一定的深度,周边一般伴随着严重的脱碳现象。裂纹产生通常是由应力造成,初生坯壳厚度不均匀以及坯壳内外温度不均匀都会造成应力超过坯壳抗拉强度,进而产生裂纹。杂质通常表现为不规则点状、块状或长条状的非金属夹杂物,颜色一般呈现为棕红色、黄褐色、灰白色或灰黑色。杂质产生的原因主要是板坯原有表面和皮下夹杂或加热过程中耐火材料及煤灰、煤渣等非金属物落在板坯表面,轧制时压入板面。斑块是指在钢材表面呈现块状或条片状的不规则斑迹,颜色多为黄色或黑色,一般是由于加热过程中混入细小的氧化铁皮,或冷却过程中冷却液不够均匀稳定所致。点蚀表面是指在钢材表面呈现连续或局部的凹凸不平粗糙面,主要是由于轧辊和轧槽磨损、锈蚀或粘上破碎的氧化铁所造成的。轧制氧化皮一般内嵌在钢板表面,深浅不一且形状各异,多为棕红色或黑色。轧制氧化皮产生的原因一般是操作不当或设置不合理导致氧化铁皮未除尽,轧制时压入钢材表面。划痕通常表现为明亮的细直线条,连续或断续地分布于钢材的局部和全长,主要是由钢材与机械零件产生非正常摩擦或运输过程中各种人为因素所致。
本文实验数据集中的图片均通过LabelImg软件进行标注,分别将图片中的裂纹、杂质、斑块、点蚀表面、轧制氧化皮和划痕标注为crazing、inclusion、patches、pitted_surface、rolled-in_scale和scratches。本文实验将1 800张钢材表面缺陷图片按照8∶1∶1的比例划分为训练集、测试集和验证集。训练集1 440张,每类缺陷各240张;测试集180张,每类缺陷各30张;验证集180张,每类缺陷各30张。
2.2 实验环境与参数设定
本文实验环境如表1所示。训练过程中,设置初始学习率为0.01,动量为0.937,权重衰减系数为0.000 5,批样本大小为8,训练轮数为100,输入图像尺寸为640×640。

表1 实验环境Table 1 Experimental environment
2.3 评价指标
本实验采用精确率、平均精度均值和参数量作为主要评价指标,同时还参考平均精度和召回率。
2.4 实验结果与分析
为验证各改进措施的效果及本文所提改进算法的有效性,本文实验在相同实验环境及参数设定下设置了原YOLOv8s网络组(称作V8-0)和3组消融实验组:1)引入C2f-Triplet模块;2)引入C2f-Triplet模块和CARAFE上采样算子;3)引入C2f-Triplet模块和CARAFE上采样算子,并将CIoU回归损失函数替换为SIoU损失函数。为方便描述,将以上3组消融实验组依次称作V8-1、V8-2和V8-3。实验结果如表2所示。
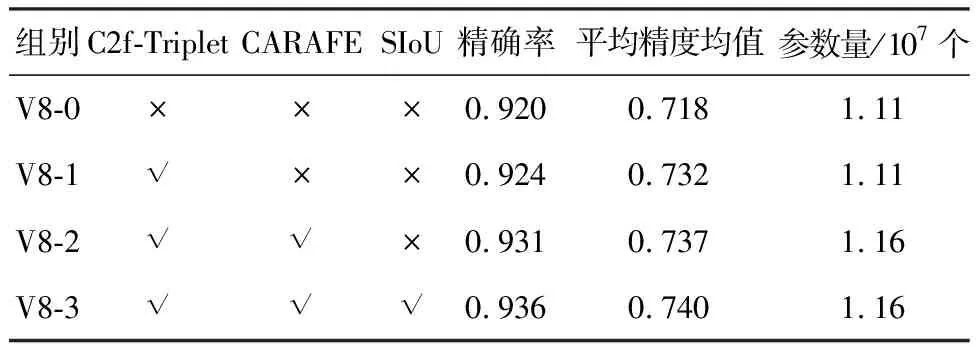
表2 消融实验结果Table 2 Results of ablation experiments
由表2可知,引入C2f-Triplet模块后的算法(V8-1)与原YOLOv8s算法(V8-0)对比,精确率提高0.4百分点,平均精度均值提高1.4百分点,参数量基本保持不变,证明引入C2f-Triplet模块可以在基本不增加网络模型参数量的条件下提升算法的精度。同时引入C2f-Triplet模块和CARAFE上采样算子后的算法(V8-2)与原YOLOv8s算法(V8-0)对比,精确率提高1.1百分点,平均精度均值提高1.9百分点,参数量增加5×105个,证明在引入C2f-Triplet模块的基础上引入CARAFE上采样算子后可以进一步提升算法的精度,但会略微增加网络模型的参数量。同时引入C2f-Triplet模块、CARAFE上采样算子和SIoU损失函数后的算法(V8-3)与原YOLOv8s算法(V8-0)对比,精确率提高1.6百分点,平均精度均值提高2.2百分点,参数量增加5×105个,证明在引入C2f-Triplet模块和CARAFE上采样算子的基础上引入SIoU损失函数可以更进一步提升算法精度,同时不会增加网络模型参数量。综上所述,验证了本文各改进措施的有效性以及本文改进算法的有效性。
图4展示了算法改进前后6种不同类型缺陷和所有类型的精确率-召回率曲线。精确率-召回率曲线与坐标轴围成的面积即为该类型的平均精度;平均精度均值是指交并比阈值为0.5时,所有类型的平均精度均值。
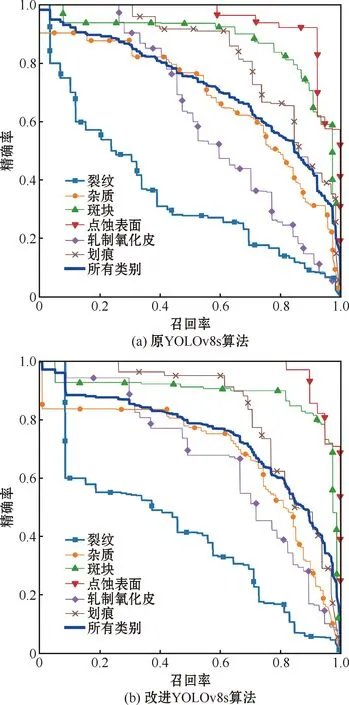
图4 YOLOv8s算法改进前后精确率-召回率曲线对比Fig.4 Comparison of precision-recall curves before and after improvement of YOLOv8s algorithm
由图4可知,YOLOv8s算法改进后,除杂质类缺陷外,其余5类缺陷的曲线与坐标轴围成的面积均有增加,其中裂纹类、点蚀表面类和轧制氧化皮类较为明显。YOLOv8s算法改进前后各类型缺陷平均精度具体数值如表3所示。
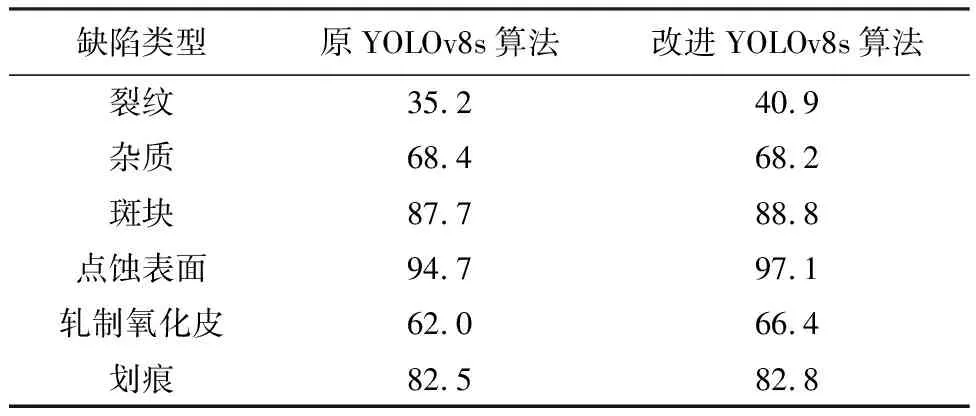
表3 YOLOv8s算法改进前后各类型缺陷平均精度Table 3 Average precision of various types of defects before and after improvement of YOLOv8s algorithm %
由表3可知,裂纹类缺陷平均精度提升了5.7百分点,杂质类缺陷平均精度基本保持不变,斑块类缺陷平均精度提升了1.1百分点,点蚀表面类缺陷平均精度提升了2.4百分点,轧制氧化皮类缺陷平均精度提升了4.4百分点,划痕类缺陷平均精度提升了0.3百分点。本文改进YOLOv8s算法可以有效提升各类型缺陷的检测平均精度,其中裂纹、点蚀表面和轧制氧化皮缺陷提升效果较为明显。
图5为YOLOv8s算法改进前后检测效果对比。图5(a)为对数据集中原始缺陷图片进行标注之后得到的图片,图5(b)为使用原始YOLOv8s算法检测得到的结果,图5(c)为使用本文改进YOLOv8s算法检测得到的结果。其中标识框上方标示着缺陷种类及该类别的置信度。本文仅选用上述效果提升较为明显的裂纹类、点蚀表面类和轧制氧化皮类等3类缺陷进行对比。

图5 YOLOv8s算法改进前后检测效果对比Fig.5 Comparison of detection effects before and after improvement of YOLOv8s algorithm
由图5可知,使用原YOLOv8s算法进行检测,虽然可以准确地判断缺陷的类别,但类别置信度普遍偏低,存在漏检现象。使用改进后的YOLOv8s算法进行检测,类别置信度有了明显提高,检测缺陷更加全面准确,可以检测出原YOLOv8s算法未检测出的轧制氧化皮类缺陷,验证了本文改进YOLOv8s算法的有效性。
为了比较本文改进算法与其他算法的效果,本文在相同的实验环境和参数设定下使用不同算法对同一数据集进行对比实验,实验结果如表4所示。
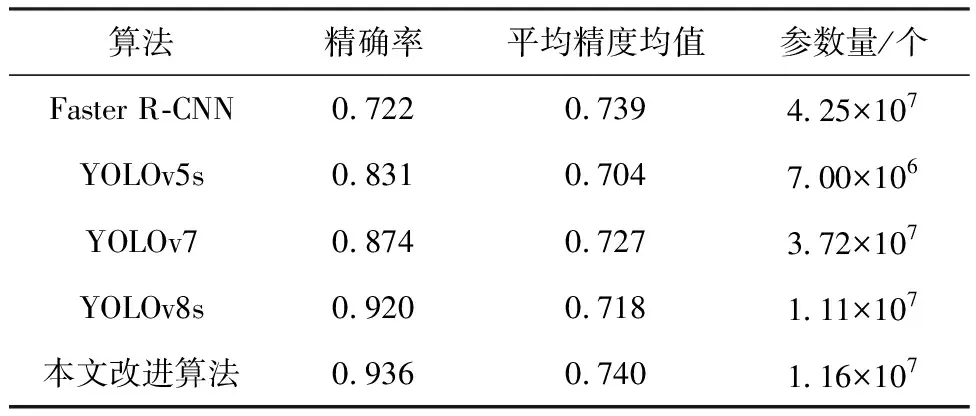
表4 对比实验结果Table 4 Comparison of experimental results
由表4可知,本文改进YOLOv8s算法的精确率和平均精度均值最高,相对于Faster R-CNN算法,精确率提高了21.4百分点,平均精度均值提高了0.1百分点;相对于YOLOv5s算法,精确率提高了10.5百分点,平均精度均值提高了3.6百分点;相对于YOLOv7算法,精确率提高了6.2百分点,平均精度均值提高了1.3百分点;相对于YOLOv8s算法,精确率提高了1.6百分点,平均精度均值提高了2.2百分点。在参数量方面,本文改进的YOLOv8s算法处于较低水平,相对于Faster R-CNN算法,参数量减少3.09×107个;相对于参数量最低的YOLOv5s算法,参数量增加4.6×106个;相对于YOLOv7算法,参数量减少2.56×107个;相对于YOLOv8s算法,参数量增加5×105个。综上所述,本文改进的YOLOv8s算法在增加极少量参数的前提下,保证了更优的检测精度,与其它主流算法相比可以更好地完成钢材表面缺陷检测任务。
3 结束语
为进一步提升钢材表面缺陷检测精度,本文提出了基于改进YOLOv8s的钢材表面缺陷检测算法。在YOLOv8s的基础上,将主干网络和颈部网络中的部分C2f模块替换为C2f-Triplet模块,将颈部网络中的最近邻上采样模块替换为CARAFE上采样算子,将原YOLOv8s的CIoU回归损失函数替换为SIoU损失函数。与原YOLOv8s算法相比,改进后的YOLOv8s算法在参数量仅增加5×105个的前提下精确率提高1.6百分点,平均精度均值提高2.2百分点。虽然本文提出的改进YOLOv8s钢材表面缺陷检测算法融合了更多维度的特征信息,使得算法可以在增加极少量参数的前提下提升各类缺陷的精度,但是对于裂纹类缺陷仍有提升的空间。所以,后续工作将针对裂纹类缺陷的特征提出相应的改进措施,进一步提升算法精度。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06
数学小灵通·3-4年级(2021年5期)2021-07-16
大众投资指南(2021年35期)2021-02-16
中华诗词(2019年7期)2019-11-25
今日农业(2019年15期)2019-01-03
灯与照明(2016年4期)2016-06-05
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
新疆钢铁(2016年3期)2016-02-28
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
