
基于华为鲲鹏处理器的计算课程教学环境构建
2024-01-02 08:35张战炳于潇雪高亦沁周衍晓林新华
软件导刊 2023年12期
张战炳,于潇雪,高亦沁,周 芸,周衍晓,林新华
(1.上海交通大学 网络信息中心,上海 200240;2.上海擎云物联网股份有限公司,上海 200070)
0 引言
高性能计算(High Performance Computing,HPC)在推动科学、工业、医学和教育的发展进程中至关重要,可大规模服务于全校教学、科研和管理等环节[1-3]。长期以来,高性能计算机的处理器都被通用性强且性能高的Intel x86架构处理器所垄断,包括中国在内的很多国家都被迫依赖进口芯片来部署大规模超算系统[4]。
近年来,随着功耗问题得到广泛重视[5],一直活跃于移动、嵌入式领域的ARM 芯片开始凭借其低功耗、低费用的优势在HPC领域发力[6-7]。美国Marvel 公司制造的ThundeX2[8]、日本富士通设计的A64FX[9]和中国华为研发的鲲鹏920 芯片[10],正成为HPC 传统x86 架构处理器的替代品[11]。国外研究将ARM 处理器应用于HPC 系统的时间较早,在2013 年就有研究者评估了ARM 处理器应用于HPC 系统的可能性[12]。2015 年,欧洲联合研究项目勃朗峰(Mont-Blanc)发布了基于ARM Cortex-A15 处理器的超算原型[13-14]。2020 年,日本基于ARM A64FX 处理器建设的富岳(Fugaku)[15-16]问鼎全球高性能计算机TOP 500 榜单,成为世界上首个基于ARM 架构的顶级超级计算机,展示了ARM 架构在超算领域的非凡潜力。而在国内,将ARM 处理器引入HPC 集群的时间较晚,2019 年开始逐渐有针对面向HPC 的ARM 处理器评测[17-19]。在高校,目前仍未见ARM 架构超算的建设和使用。
为摆脱进口依赖,响应国家掌握核心技术,加快推进国产自主可控替代的号召,上海交通大学基于国产ARM芯片建设了一台超级计算机——国产超算平台,也称为ARM 超算平台。上海交通大学国产超算平台是国内高校首个建成和投入使用的ARM 架构超算,可为兄弟高校建设和使用ARM 超算积累经验。
为了源源不断地培养高水平创新人才,上海交通大学在国内高校率先提出将计算深度融入专业课教学的新理念。通过深度融合计算与专业课,研发数据驱动的全过程计算教学在线实践平台,以国产超算平台构建计算课程教学支撑环境,支撑线上线下混合式教学和大规模虚拟仿真实验教学,为学生提供沉浸式的在线学习体验和个性化的学习资源服务。这是国内高校首次践行基于ARM 超算的教学支撑实践,为ARM 超算的推广应用提供了一个新的视角。
该工作主要有以下3 个创新点:①建设并运营了高校首台ARM 架构超算,为ARM 超算的建设和使用积累了经验;②对超算上广泛使用的科学应用进行了移植和评测,为ARM 超算使用者提供了有价值的参考和借鉴;③探索了基于ARM 超算的教学支撑实践,为ARM 超算的运营和推广提供了新视角。
1 系统介绍
1.1 硬件配置
目前,国产ARM 芯片厂商包括天津飞腾、华为海思和阿里平头哥等[20]。其中,华为于2018 年推出的鲲鹏920 是业界首款7 nm 数据中心级ARM 处理器[10],且过往研究表明其拥有不错的高性能计算应用运行性能,在绿色计算领域具有极强的竞争力[18]。因此,上海交通大学国产超算平台基于华为鲲鹏920 处理器建设,共100 个计算节点,每节点配备128核(2.6 GHz)、256 G 内存(16通道DDR4 2933)。
由于超算集群的节点间通信流量极大,对链路带宽和通信延迟均提出了很高的要求。目前,超级集群建设通常采用InfiniBand(IB)[21]和Omni-Path Architecture(OPA)[22]两种高吞吐、低延迟的高性能通信架构。相较于OPA,IB的发展优势更明显,是HPC 领域中活跃的第一大互联网络[23],因此国产超算平台采用IB 网络承载节点之间的通信。
1.2 软件环境
上海交通大学原有基于Intel Cascade Lake 6248 芯片建设的π2.0 超算平台[24],也称作x86 超算平台。国产超算平台的加入是整个超算中心的一次重大扩展,为了保障不同平台使用体验的一致性,国产超算平台采用了和π2.0 平台相同的CentOS 操作系统版本和Slurm 作业调度系统[25]版本作为基础环境。其中,操作系统版本为CentOS Linux release 7.6.1810,作业调度系统版本为slurm-19.05.7-1.el7.aarch64。Slurm 作业调度系统通过修改Controller 节点和Worker 节点的配置文件,将国产超算平台命名为ARM128C256G 队列,并无缝接入π2.0 平台,从而保持多计算平台作业提交体验的一致性。
2 共享文件系统接入
2.1 IB网络拓扑
为了充分保障网络带宽,在规划国产超算平台的网络拓扑结构时,考虑了单一大型交换机的中心拓扑结构和胖树拓扑结构两种方式。过往研究表明,相较于前者,胖树拓扑结构能在保障网络带宽的前提下价格更低,能有效降低机房布线施工的难度[26]。因此,国产超算平台采用了简化的胖树拓扑结构组建IB 网络,详细拓扑结构如图1所示。
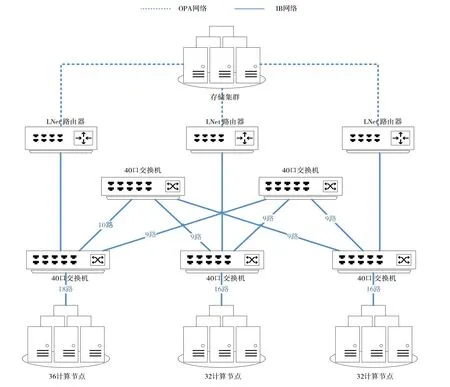
Fig.1 IB network topology图1 IB网络拓扑结构
由图1 可见,国产超算平台的IB 网络包含5 台40 口小型交换机,其中3 台作为接入层交换机,与计算节点直连;剩余2 台作为核心层交换机,与接入层交换机进行网状连接。IB 网络中的每条物理线路支持200 GB/s 的通信带宽,整个接入层与计算节点之间合计有10 000 GB/s 的通信带宽,而接入层与核心层之间合计有11 000 GB/s 的通信带宽。由于IB 交换机自带路由选择功能[27],可确保接入层与交换层的数据流量均匀分摊到每一条等价链路上,因此在胖树拓扑结构下,任意两个节点之间始终享有100 GB/s的可用通信带宽。
2.2 Lustre文件系统配置
为了提供给用户无差别的数据访问服务,国产超算平台采用了以存储为中心的设计思路,接入π2.0 超算平台的统一存储集群。π2.0 超算平台中,存储采用Lustre[28]并行文件系统,服务端版本为lustre-2.12.4,由两台MDS/MGS与10 台OSS 服务器组成,内部采用OPA 高速网络互联。对于国产超算平台而言,为接入π2.0 超算平台的统一存储集群,需解决Lustre 客户端安装、LNet 网络配置两个问题,打通与Lustre 服务端的流量限制。
Lustre 客户端的版本选择受限于服务端版本、操作系统类型、操作系统版本等因素,且由于官方预编译软件包未适配ARM 架构。因此,国产超算平台尝试对多个Lustre客户端版本进行编译安装和测试,在综合考虑兼容性、测试性能后选定lustre-client-2.12.4 版本。在网络连接的实施方面,Lustre 服务端采用OPA 网络,而国产超算平台采用IB 网络,因此需解决异构网络的连通问题。首先,在国产超算平台采用路由节点(LNet Router)桥接的方式与Lustre 服务端连通。在实际操作中,国产超算平台中的3台接入层交换机分别接入一台路由节点,从而可分流与Lustre 服务端之间的数据流量,避免路由节点的吞吐量限制成为集群数据访问性能的瓶颈。然后,在Lustre 服务端、客户端、路由节点分别配置好LNet 路由,以成功打通OPA 和IB 异构网络之间的流量。
基于上述操作,国产超算平台成功接入了π2.0 超算平台的Lustre 文件系统,从而构建了一套存储、多种计算的数据密集型超算平台。
3 应用软件部署
面向超算平台的计算软件环境构建,存在基础依赖差异大、编译过程复杂、多版本共存等问题[29]。为解决上述问题,一系列软件包管理器应运而生[30],国产超算平台主要采用Spack[31]、Singularity[32]方式提供应用软件的部署。
3.1 Spack编译方式
源码编译方式安装的软件能保证与ARM 架构兼容,可调整参数优化性能。基于以往研究经验[29],Spack 使用方便、灵活、可定制,因此国产超算平台采用Spack 源码编译方式作为首选软件安装方式。
Spack 作为一款包管理器,将编译过程中的关键步骤抽象为一系列函数。在实际执行时,Spack 将根据用户编写的函数流程完成源码下载、解压、编译、安装等过程。Spack 编译选项丰富,可指定软件版本、优化选项、编译器、依赖软件包等参数,具有高度的灵活性、易用性和可扩展性。因此,Spack 编译的软件会自动生成相应的环境模块(Environment Module),简化了软件调用的难度。目前,国产超算平台已通过Spack 部署了大量常用软件,如表1所示。
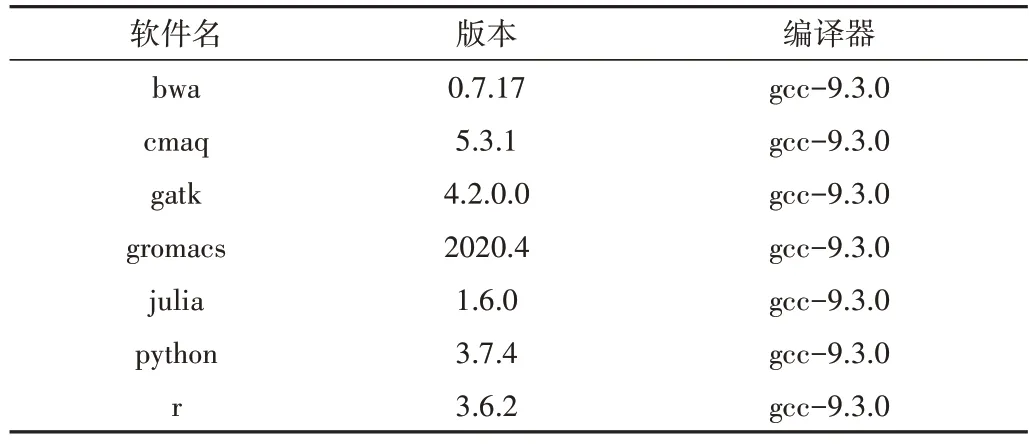
Table 1 Part of Apps installed by Spack on domestic supercomputing platform表1 国产超算平台上由Spack部署的部分软件
3.2 Singularity镜像方式
对于一些Spack 不支持、难以安装或性能不佳的软件,国产超算平台使用容器作为重要补充手段。目前,流行的容器构建工具有Singularity 和Docker。其中,Docker 为普通用户提供了特权模式(--privileged),允许其进入容器后以root 权限执行任何操作,更适合微服务的形式,但无法满足高性能计算中多用户环境的安全性要求[33]。因此,国产超算平台选择Singularity 作为构建镜像的工具。
3.2.1 预编译镜像
对于常见的应用,国产超算平台提供预编译镜像供用户直接使用,整合了基础软件环境的基础镜像和部署了专业软件的应用镜像(见表2)。基础镜像将通用软件依赖打包安装,可避免重复性工作;应用镜像则进行科学应用软件的打包、测试和优化,方便用户即开即用。对于国产超算平台尚未提供的软件,用户可在Docker Hub、Singularity Hub 等开源镜像软件源上寻找合适的预编译镜像,只需执行Singularity pull 即可一键部署。
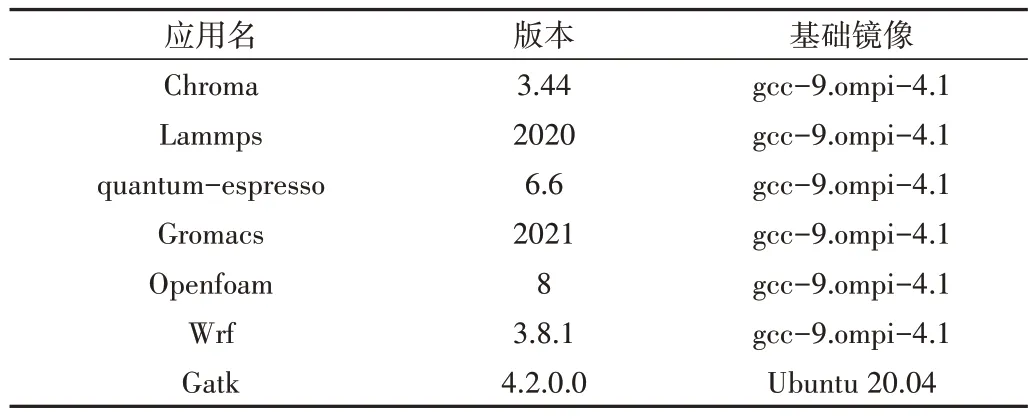
Table 2 Part of App images on domestic supercomputing platform表2 国产超算平台的部分应用镜像
3.2.2 非特权用户自定义镜像
出于安全性的考量,普通用户无法在超算平台使用Singularity recipe 制作镜像,但为了满足用户自定义构建镜像的需求,国产超算平台采用Dockerized Singularity 方式,在Docker 中运行Singularity 来赋予非特权用户构建SIF 镜像的权限。具体为,国产超算平台将一个计算节点作为镜像构建节点,所有用户共享一个build 账号用于构建镜像,用户通过Docker 特权模式(--privileged)进入预装有Singularity 的Docker 容器,在内部获取root 权限即可执行Singularity recipe 进行镜像构建,构建完毕后镜像的所有者仍为root,普通用户仅拥有读取、执行权限。
综上,国产超算平台的非特权用户镜像构建流程具有集群安全、体验一致、使用灵活的优势,可满足用户对特殊科学软件自定义构建的需求。
4 实际应用性能评测
国产超算平台通过对LAMMPS[34]、GATK(Genome Analysis Toolkit)[35]等科学应用进行正确性测试和性能测试,以验证平台软件的可用性与性能,部分科学应用的测试结果如表3所示。
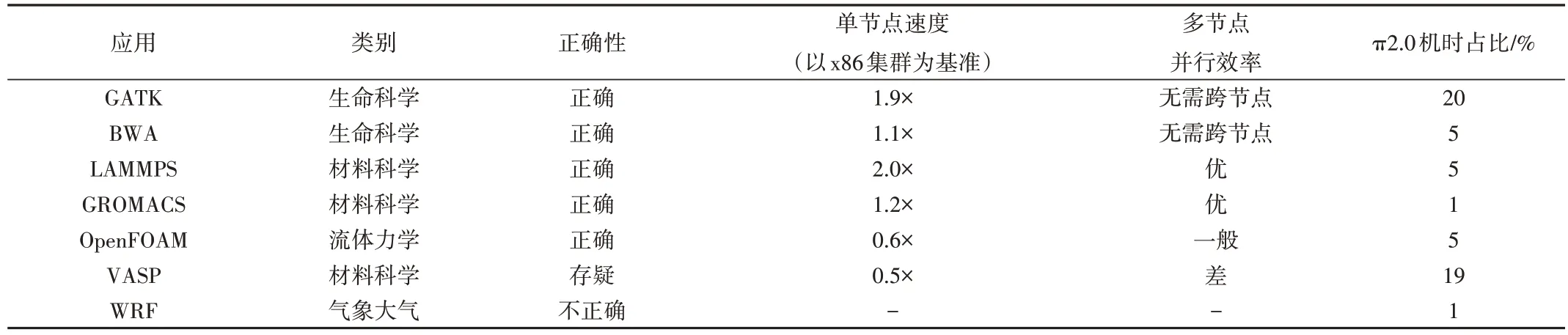
Table 3 Apps tested on ARM cluster表3 ARM集群上测试的科学应用
测试分别基于国产超算平台和π2.0 超算平台,由于两大计算集群使用的文件存储相同,集群内的网络带宽、集群与存储间的网络带宽也相同,因此评测更多集中在两大集群的处理器架构和单节点配置差异导致的应用性能差异。本文以LAMMPS和GATK应用为例,展示具体评测过程。
4.1 LAMMPS测试
LAMMPS 是典型的分子动力学软件,在材料科学、计算物理、计算化学中占有重要地位,具有计算密集型的特点[33]。上海交大计算平台π2.0 超算平台上约有5%的CPU 资源运行LAMMPS 计算,本次测试采用的软件版本为LAMMPS 14 May 2021。LAMMPS 在国产超算平台上通过Spack 进行源码编译安装,调用全局部署的GCC 9.3.0、OpenMPI 4.0.3、FFTW 3.3.8 等基础应用环境即可顺利完成源码安装。
(1)正确性测试。基于LAMMPS 的两个经典算例EAM和LJ,搭建50 万原子的体系,在NPT 系统下运行5 万步,观察体系压强。比较压强曲线发现,LJ 压强曲线在ARM 集群和x86 集群中几乎完全重合,EAM 压强曲线在后半段存在微弱波动,但整体维持在同一水平线。因分子动力学计算基于统计热力学,原子存在热涨落波动,一般温度和压强等宏观参量只要稳定在目标值,结果就算合理。由此可知,国产超算平台上的LAMMPS 具有计算可靠性。
(2)性能测试。采用LAMMPS 的算例EAM,在ARM 集群和x86 集群上的测试运行性能,分别比较1、2、4、8、16 个节点的运行速度。算例EAM 搭建了86.4 万原子的体系,在NVE 系统下运行5 000 步,测试结果如图2 所示。当LAMMPS 在ARM 集群单节点上运行时,其计算速度是x86集群单节点的2 倍;当扩展到16 个节点并行计算时,ARM集群相较于x86 集群仍保持1.5 倍的优势。从两大集群的并行效率(假定单节点并行效率为100%)来看,ARM 集群多节点并行的性能损失更明显。
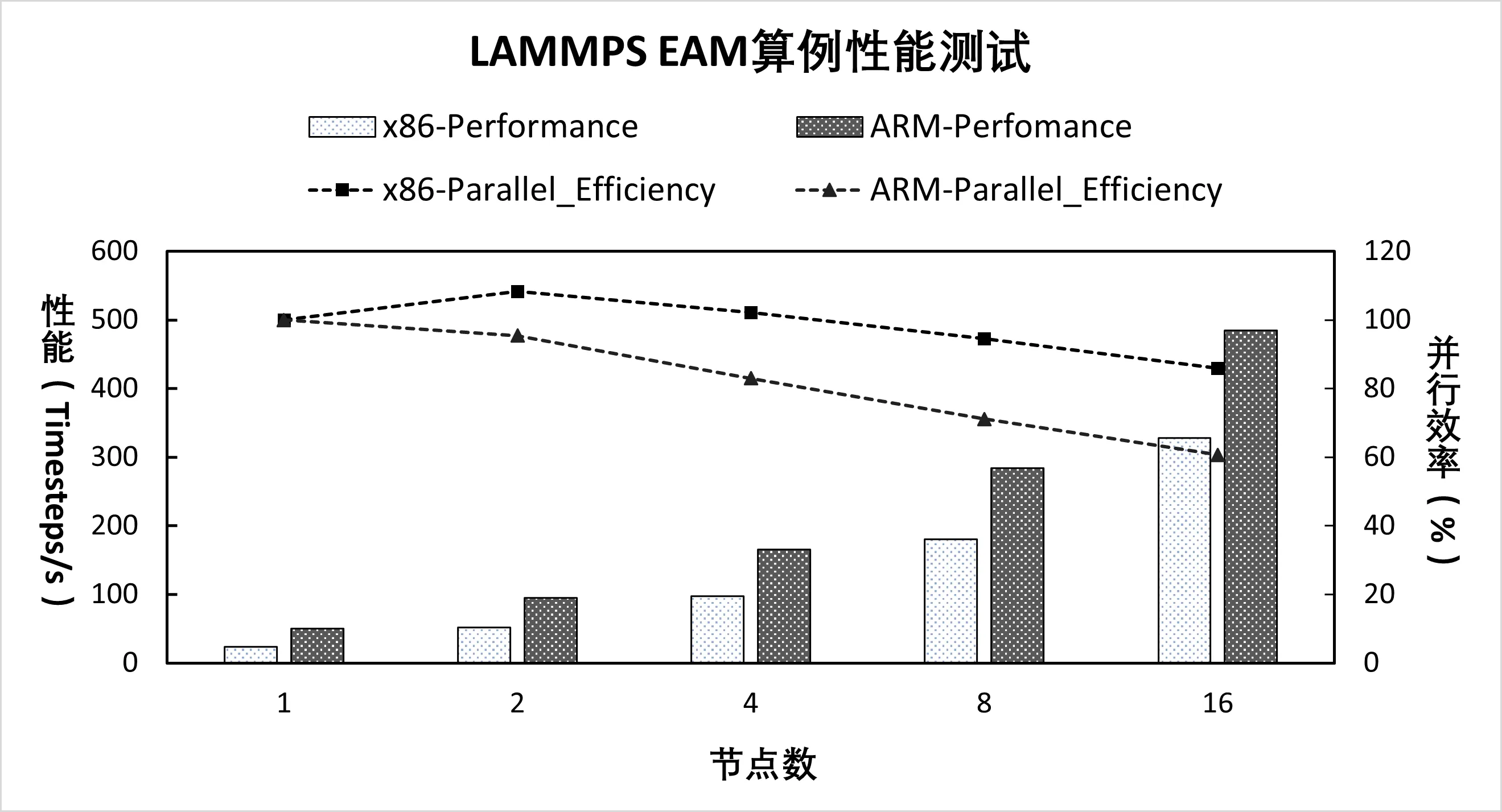
Fig.2 Performance of a system consisting of 864 000 atoms running 5 000 steps based on EAM examples图2 采用EAM算例搭建86.4万原子的体系运行5 000步的性能
上述测试结果表明,在国产超算平台上运行LAMMPS具有计算正确性,并在单节点和多节点运行时能充分发挥ARM 处理器的多核优势,以提升其性能。
4.2 GATK测试
GATK 是由Broad Institute 开发,用于生物信息高通量测序数据分析的工具集,包含一系列基因组和转录组分析工具,是生物信息分析中变异检测的金标准[35],在π2.0 超算平台上的机时占比达20%。测试采用的GATK 版本为4.2.0.0,在国产超算平台上通过Spack 进行源码编译安装,依赖环境为GCC 9.3.0,openjdk 1.8.0,Python 3.7.4,r 3.6.2,openblas 0.3.9。
(1)正确性验证。基于官方提供的测试数据和测试流程(https://github.com/gatk-workflows),在ARM 集群和x86集群分别运行GATK 变异检测流程,发现两次结果中检测出的位点总数一致,位点REF 值和ALT 值相同,仅约0.4%的位点存在PL 值差异,且差异较小。由于位点PL 值每次运行都存在微小差异,但并不影响最终结果,因此可表明ARM 集群上的GATK 具有计算可靠性。
(2)性能测试。基于上述相同的测试数据和分析流程,分别在ARM 集群单节点和x86 集群单节点上运行GATK 软件的MarkDuplicates、BQSR 模块,收集模块运行时间。测试结果发现,MarkDuplicates 和BQSR 任务在ARM集群上的运行时间分别为x86 集群的70%和50%,总体上ARM 集群单节点运行GATK 能达到x86 集群性能的1.9 倍(见图3)。

Fig.3 Performance comparison between GATK MarkDuplicates and BSQR modules图3 GATK MarkDuplicates和BSQR模块的性能比较
综上,GATK 在ARM 集群上具有计算可靠性,且能充分发挥多核优势来实现更高的单节点计算性能。
5 计算课程教学实践
上海交通大学研制的计算教学在线实践平台,能为师生个性化定制在线实践课程及配套实验环境,支撑课堂直播、实验实训、作业考试、在线测评、微认证等全过程计算教学。平台基于国产超算平台构建虚拟仿真实验环境,可与课程教学资源有机结合,使学生边学边练,在做中学。例如,材料智能设计与制备加工课程通过在国产超算平台部署课程实验镜像模板,包含电子结构计算软件、分子动力学软件等软件应用,密度泛函理论、蒙特卡罗等计算方法,以图形化桌面、系统命令行、IDE 在线编程、Jupyter Notebook、3D 虚拟仿真等多种模式构建虚拟仿真实验环境(见图4),一站式提供课程所需的专业计算软件,根据课程实验规模实时调度计算资源,实现资源的自动管理。
Fig.4 Experimental environment for neural networks chapter in the course of intelligent design and preparation of materials图4 材料智能设计与制备加工课程神经网络章节的实验环境
目前,国产超算平台已部署、上线了人工智能数学基础、多尺度材料模拟与计算、航空航天计算方法、分子模拟的理论与实践、计算生物学、前沿技术与计算实践、云计算及虚拟化等多门课程的虚拟仿真实验环境,涵盖人工智能、材料、化学、生物、航空航天众多领域。
6 结语
作为国内高校第一台ARM 超算,上海交通大学国产超算平台的建设为兄弟高校建设和使用ARM 超算积累了经验,践行的数据密集型超算建设,为超算平台的发展提供了技术探索。平台实践表明,当前ARM 架构的软件生态已可满足高校主流的科学计算需求。进一步,国产超算平台可为计算课程实践提供良好的支撑环境,通过部署课程实验镜像模板,将虚拟仿真实验环境与课程教学资源有机结合,为师生提供个性化定制的在线实践课程及配套实验环境。
国产超算平台的建设和教学支撑环境的构建,为科学计算用户和学生提供了先进的计算资源和教学支持,不仅提升了学校的科研水平和教学质量,也为学生的学习和发展提供了更好的条件和机会。上海交通大学将继续致力于推动科学计算和教学的创新发展,为学术研究和教育培养作出更大贡献。
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
电子设计应用(2004年7期)2004-09-02
