
基于随机森林模型的旺业甸实验林场土壤全氮数字制图
2024-01-01 00:00:00甄诚王海燕雷相东赵晗董齐琪崔雪仇皓雷
华中农业大学学报 2024年3期
关键词:空间分布


关键词 土壤全氮; 随机森林模型; 空间分布; 土层深度; 数字土壤制图
中图分类号 S714 文献标识码 A 文章编号 1000-2421(2024)03-0249-09
氮是生物地球化学循环的关键元素之一,影响土壤质量和其他土壤性质[1-2],同时氮素缺乏对植物生长发育的影响很大,科学评价土壤氮素状况对土壤肥力管理和植物营养尤其重要。土壤氮库是生态系统中氮循环的重要组成部分,深层土壤氮库拥有巨大的氮储量,因此,了解土壤全氮(total nitrogen,TN)在垂直梯度上的分布及其控制因素的可靠估计对于研究土壤氮储量和氮循环极为必要[3]。
基于土壤调查的传统土壤制图方法既耗时又昂贵,导致土壤地图很难更新。近年来,随着高精度数字森林土壤数据库的建立和科学利用土地的要求日益提高,数字土壤制图(digital soil mapping,DSM)技术作为一种为土壤评估框架提供数据和信息的新方法被用来描述世界各地土壤属性的空间分布,此法方便、经济高效[4]。DSM 基于土壤属性和预测变量之间的数字关系,使用空间分析和数学方法来理解土壤属性的空间格局[5],也可以结合实验室土壤分析和遥感光谱指数等环境变量,建立高分辨率、高精度的土壤属性预测模型。
基于McBratney 提出的数字土壤制图框架,许多机器学习算法已被成功用于预测土壤属性[4]。随机森林(random forest,RF)模型具有不易过拟合的优势,相比于其他机器学习方法更加有效稳定。如,姜赛平等[6]运用3 种空间预测模型对海南岛不同土层深度土壤有机质(soil organic matter,SOM)空间分布进行了预测,结果表明0~5、0~20、20~40 cm 土层深度RF 模型表现优于其他模型(决定系数R2为0.21~0.37),40~60 cm 土层深度普通克里格方法最优,但该方法图斑较大,无法详细描述SOM 空间变异的细节信息。庞龙辉等[7]使用RF 模型对青海省表层土壤TN、粉粒、SOM 和pH 的空间分布格局进行预测,发现RF 模型预测土壤属性空间格局效果优异,R2分别为0.611、0.474、0.532 和0.542。Keskin 等[8]使用8种模型预测佛罗里达州土壤碳组分空间格局,结果表明RF 模型的预测效果最好,R2 达到0.72,远高于其他模型。Cubist 模型具有学习数据中的非线性关系的能力[9-10]。Shahbazi 等[11]在伊朗东阿塞拜疆省使用RF 模型和Cubist 模型对4 个标准化深度(0~15、15~30、30~60、60~100 cm)氮、磷和硼的空间分布进行建模和预测,结果表明Cubist 模型预测效果优于RF 模型。可以看出,不同模型在同一研究区域内效果不同,同一模型在不同研究区域内效果也并不相同,具有不确定性,且国内缺乏森林经营单位(如林场)层次的相关研究,需要更多的验证。
本研究以内蒙古赤峰市旺业甸实验林场为对象,基于土壤实测数据,结合多源数据集作为环境协变量,使用RF 模型和Cubist 模型探索影响土壤TN 含量的环境协变量,对该林场不同土层深度土壤TN 含量进行空间预测,形成林场TN 数字地图,以期为林场尺度森林土壤养分管理和可持续利用提供参考。
1 数据与方法
1.1 研究区概况
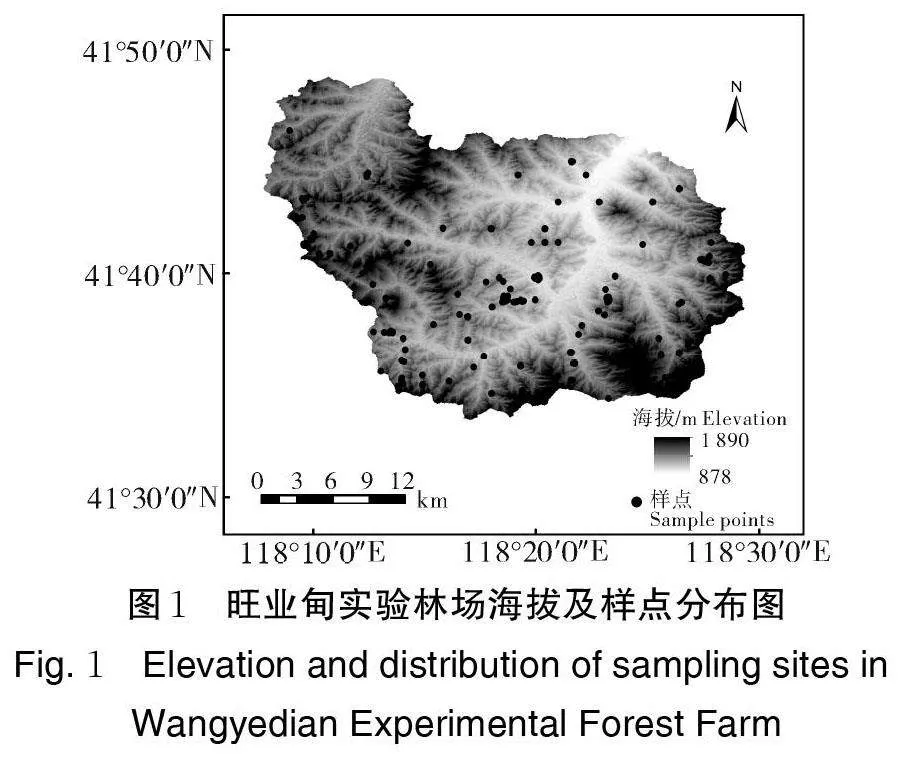
旺业甸实验林场(41°33′~41°49′N,118°07′~118°30′E)位于内蒙古自治区赤峰市喀喇沁旗西南部,处于草原向森林的过渡地带。地貌类型为中山山地,海拔高度877~1 890 m。属暖温带半干旱地区,为明显的大陆性季风气候。年平均降水量430~560 mm,年平均气温1.8~6.2 ℃,无霜期117 d。林场经营面积281 km2,有林面积约235 km2,其中人工林约118 km2,天然林约117 km2。土壤类型以典型棕壤为主,还包括暗棕壤、褐土和草甸土等。成土母岩主要有岩浆岩和沉积岩等,少数发育在黄土母质上。
1.2 土壤样品采集与测定
2021 年9 月,综合考虑林场地形地貌和林分类型等因素,采用典型取样方法,在该林场设置了147 个采样点(图1),其中人工林71 个,天然林76 个,在每个样点设置一块20 m×30 m 的样地,在样地内多点采集0~10、10~30、30~50 cm 3 个土层深度的土壤,分层混匀后带回实验室。同时记录样点经纬度、海拔、坡度、坡向和林分类型等信息。混合土样经风干、去除杂质、研磨,通过孔径0.25 mm 筛,采用凯氏定氮法测定土壤TN 含量[12]。
1.3 环境协变量数据来源及处理
本研究初步选择使用12 个环境协变量作为预测土壤TN 的因子(表1),包括x 坐标、y 坐标、地形、气候和生物变量数据。使用ArcGIS 10.5 生成环境变量并将其传输到栅格层。地形属性是数字土壤制图中使用最广泛的环境预测因子[11]。本研究中使用6个地形变量,包括海拔(elevation)、坡度(slope)、坡向(aspect)、剖面曲率(profile curvature)、地形粗糙指数(topographic roughness index,TRI)和地形湿度指数(topographic wetness index,TWI)。数据来源于地理空间数据云(https://www. gscloud. cn/search)GDEMV3 数字高程数据。TRI 和TWI 使用SAGAGIS 生成,其他4 个变量使用ArcGIS 10.5 生成。湿度和温度影响土壤氮的积累速度,被广泛应用于TN预测[13]。采用研究区1970−2000 年30 a 的年平均气温(mean annual temperature,MAT)和年平均降水量(mean annual precipitation,MAP)作为气候变量,数据来源于世界气象数据库网站(https://worldclim.org/),在ArcGIS 10.5 软件中使用最临近法将MAT和MAP 数据重采样到30 m 分辨率。生物变量使用归一化植被指数(normalized difference vegetation index,NDVI)和红边叶绿素植被指数(red edge chlorophyllindex,RECI)进行表征[14]。数据来源于地理空间数据云(https://www.gscloud.cn/search)Landsat8 OLI 图像,图像采集于2020 年10 月15 日。使用ENVI 5.6 对图像进行辐射定界和大气校正,采集近红外波段5(B5,0.85~0.89 μm)和红外波段4(B4,0.63~0.68 μm)用于计算NDVI 和RECI,构建模型。
1.4 建模方法
随机森林(RF)是Breiman 提出的一种基于树的集成学习技术[15],RF 模型中的节点纯度(Inc‐NodePurity)可表征各环境因子对目标变量的贡献率,该值越大表示该变量的重要性越大[16]。本研究中RF 模型的2 个重要参数mtry 和ntree 通过网格搜索确定为2 和800,用于预测林场土壤TN 含量分布。
Cubist 模型是一种先进的基于树的回归算法[11]。本研究中Cubist 模型的2 个重要参数committees 和neighbours 分别设置为10 和9,用于预测林场TN 含量分布。
1.5 模型验证与预测不确定性评估
使用交叉验证来评估模型的预测性能,该方法的优点是在较小的数据集上执行,可靠且无偏倚[17]。本研究使用十折交叉验证,重复10 次,用平均绝对误差(MAE)、均方根误差(RMSE)和R2 3 个统计指标来评估模型在预测土壤TN 方面的性能。使用模型迭代100 次预测的土壤全氮含量的标准差绘制模型预测的不确定性分布图。
2 结果与分析
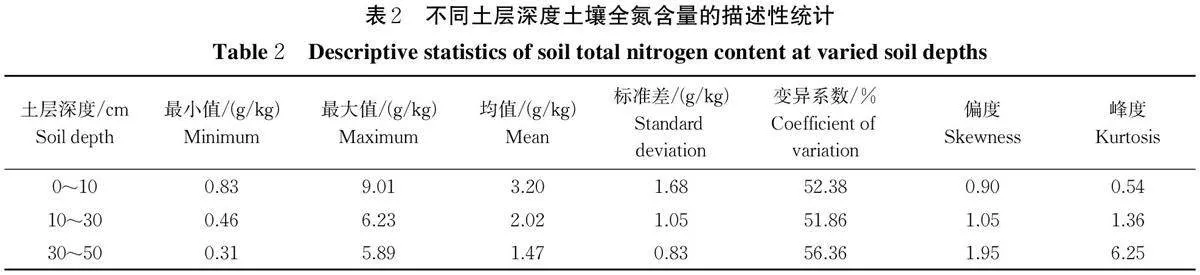
2.1 土壤全氮的描述性统计分析
研究区147 个样点0~10、10~30 和30~50 cm3 个土层深度土壤TN 的描述性统计信息见表2。土壤TN 含量的均值和标准差随着土层深度的增加而降低,均值分别为3.20、2.02、1.47 g/kg。3 个土层深度TN 含量的变异系数为51.86%~56.36%,均属于中等变异[18]。土壤TN 经对数转换后符合正态分布。
不同林分类型土壤TN 含量的分布情况如图2所示。从整体看,不同土层深度天然林土壤TN 含量高于人工林土壤TN 含量。
2.2 环境协变量的选择
采用Pearson 相关系数法进行环境协变量的选择。不同土层深度TN 含量与环境协变量之间的Pearson 相关分析结果表明(表3),0~10 cm土层TN含量与海拔(r=0.533)、坡向(r=0.178)和年平均降水量(r=0.553)呈正相关,与y坐标(r=−0.205)、年平均气温(r=−0.501)和归一化植被指数(r=−0.265)表现出负相关关系。x 坐标、坡度、剖面曲率、地形粗糙指数、地形湿度指数和红边叶绿素植被指数与TN 含量相关性不显著,给予剔除。
除y 坐标和坡向与30~50 cm 土层TN 含量相关性不显著,10~30 和30~50 cm 土层TN 含量与环境协变量的关系与0~10 cm 土层基本一致。因此,土壤TN 含量最终使用海拔、坡向、年平均降水量、y 坐标、年平均气温和归一化植被指数作为环境协变量进行建模预测。
2.3 不同土层深度土壤全氮含量预测模型结果
利用样地数据训练的RF 模型和Cubist 模型的交叉验证结果如表4 所示,在不同土层深度下,RF 模型的预测效果均优于Cubist 模型,可以解释不同土层TN 含量的空间变化范围(39%~59%),且具有较高的R2 和较低的RMSE 和MAE。因此选用该RF 模型对林场土壤TN 的分布格局进行预测并制图。对于0~10 cm 土层TN,RF 模型的解释率超过50%,而对30~50 cm 土层TN 则表现出较低的预测性能(R2=0.39),RMSE 和MAE 也随土层深度的增加而增大,这可能是因为用于建立与土壤属性关系的环境协变量多采集于地表,环境协变量的解释能力随着土层深度的增加而降低所致。
2.4 林场土壤全氮制图及不确定性分布图
由图3 可知,0~10 cm 土层TN 含量预测值变化范围为1.08~5.89 g/kg,均值2.87 g/kg;10~30 cm土层TN 预测值变化范围为0.64~4.37 g/kg,均值1.84 g/kg;30~50 cm 土层TN 预测值变化范围为0.58~3.74 g/kg,均值1.28 g/kg。土壤全氮的平均含量随土层深度的不断增加而降低。预测的3 个土层深度TN 含量空间分布的总体变化趋势基本一致,均表现为西部、北部和中部低,西南、东南和东部高的空间格局,且与海拔的变化特征大致相符。
由图4 可知,RF 模型预测土壤TN 的标准差的平均值随土层深度的增加不断提高,依次为0.013、0.018 和0.019 g/kg,即使是标准差的最大值(0.032、0.035 和0.036 g/kg)仍较低,总体上RF 模型的预测不确定性很低。
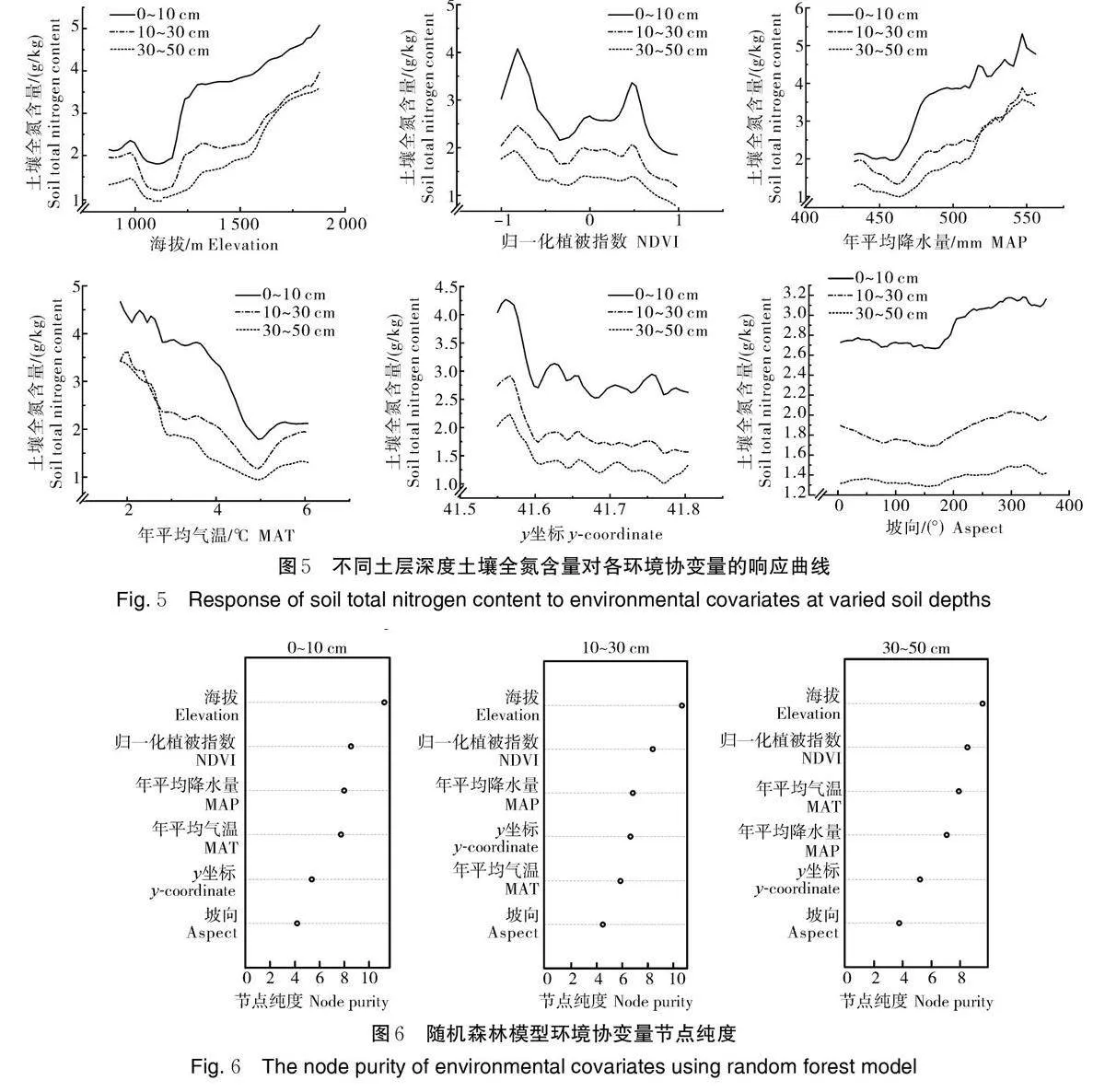
2.5 土壤全氮对各环境协变量的响应
基于研究区土壤TN 的预测数据和提取的环境协变量数据,使用RF 模型绘制了土壤TN 对各环境协变量的响应曲线(图5),用于表征土壤TN 与各环境协变量之间的关系。由图5 可知,土壤TN 与各环境协变量呈差异较大的非线性关系,不同土层深度土壤TN 与各变量之间的响应曲线在趋势上大体相同。总体来看,土壤TN 含量随海拔和年平均降水量的增大而增加,随年平均气温的增大而减小,这与Pearson 相关分析结果基本一致。土壤TN 与坡向和y 坐标表现为波动变化趋势。土壤TN 与归一化植被指数之间的响应曲线较为特殊,随着归一化植被指数的增大,土壤TN 先升高达到第一个峰值后迅速下降,再逐步上升到第二个峰值后递减,这可能是由于人工林和天然林2 种林分类型的差异造成土壤TN与归一化植被指数之间呈复杂的响应关系。
2.6 环境协变量对土壤全氮影响的重要性
使用RF 算法中环境协变量的节点纯度表征对应环境协变量的相对重要性。由图6 可知,3 个土层深度TN 含量的分布格局基本一致。海拔对林场土壤TN 含量影响最大,其他依次为:归一化植被指数gt;年平均降水量gt;年平均气温gt;y 坐标gt;坡向。旺业甸实验林场海拔877~1 890 m,四周向中部逐渐递减,西南、东南和东部土壤在海拔高度的影响下人为干扰较少且水热条件较好[19],分解和转化有机质的细菌的活性和种类在低温下受到限制[20],土壤氮素得到累积;中部和北部主要为居民区,处于低海拔地区,同时植被覆盖较差,不利于土壤氮素的累积。
3 讨论
本研究在地形复杂的林场尺度下,对旺业甸实验林场147 个样点,结合海拔、归一化植被指数、年平均气温、年平均降水量、坡向和y 坐标等环境变量,利用RF 模型和Cubist 模型对0~10、10~30 和30~50cm 3 个土层深度土壤TN 含量的空间分布进行预测,并使用十折交叉验证方法进行验证,同时探究影响土壤全氮空间分布的主要变量。结果显示:①0~10、10~30 和30~50 cm 土层实测TN 含量随着土层深度的增加逐渐减小;②相较于Cubist 模型,RF 模型能更好地预测3 个土层深度土壤TN 含量的空间分布,能解释39%~59% 的土壤TN 空间变异;③用RF 模型预测土壤TN 含量,不同土层深度TN 含量均呈现西部、北部和中部低,西南、东南和东部高的空间格局;④土壤TN 受到多种环境变量的综合影响,海拔是影响该林场土壤TN 含量空间分布格局的最主要因素,其他依次为:归一化植被指数gt;年平均降水量gt;年平均气温gt;y 坐标gt;坡向。环境变量对土壤TN 的影响随土层深度增加而减小。
在所有环境协变量中,地形变量对研究区内土壤TN 含量空间分布的影响最大。这是因为对于小尺度数字土壤制图研究,地形变量不仅可以描述地形属性和地貌部位信息,也可以反映主要由地形地貌变化引起的局部小气候差异对土壤形成的影响,通常是小尺度下土壤属性空间变异的主导因素[21]。地形是土壤形成的五大自然因素之一,对土壤TN 的影响主要体现在影响地表植被分布和水热交换这2个方面[22-23]。本研究发现,在所有地形变量中,海拔在预测旺业甸实验林场土壤TN 空间分布的过程中发挥最重要的作用,旺业甸实验林场属中山山地地形,海拔高度差近1000 m,地理坐标的改变会使森林组成产生较大的垂直地带性变化,进而影响土壤TN含量,与前人的研究结果一致[24-26]。气温随海拔下降而上升,直接导致土壤温度升高,促进土壤微生物的活性,Yu 等[27]研究表明森林土壤反硝化作用产生气态氮损失随温度的升高而增加,减少了土壤TN 的积累,导致不同海拔条件下TN 含量存在差异。降水量随海拔的升高而上升,致使土壤水分含量增加,厌氧条件下微生物分解能力降低,有利于氮素积累。坡向主要制约土壤水热条件,进而对TN 含量产生影响[28]。在北半球,南坡比北坡受到更多的太阳辐射,植被蒸腾作用强烈,因此南坡水分蒸发快,土壤水分少,植被覆盖性差,土壤氮素积累较少,同时南坡的强烈光照使土壤温度较高,土壤TN 的矿化速率加快,不利于氮素积累。响应曲线显示,旺业甸实验林场土壤TN 随坡向的增加呈现出先减小后增加的变化趋势,这是因为随着坡向值的增加,坡向由正北方向沿顺时针再次返回到正北方向。
地理坐标对土壤TN 也有一定的影响,y 坐标与土壤TN 呈负相关,表明研究区南部的土壤TN 含量比研究区北部的要高。响应曲线则表现出随y 坐标的增大,土壤TN 先迅速下降,再表现出有波动的缓慢下降趋势,这与该地区复杂的地形有关。研究区南部为高海拔地区,基本不含居民区,而随着纬度的增加,地域逐渐开阔,密集的居民区也增加了人为因素对土壤TN 的影响,土壤TN 的变化范围也随之扩大。
一般情况下,在小尺度上,大生物气候因素对土壤属性空间变异的影响基本一致,但由于研究区内海拔梯度陡峭,在短距离内形成了温度和湿度等非生物因素梯度导致研究区生态系统更容易受到气候因素的影响[29]。年平均降水量对土壤TN 的空间分布具有较强的影响,本研究区年平均降水量的极差高达105 mm,差异明显,降水丰富将有效增加土壤含水量,进而增加土壤TN 的积累。研究区年平均气温的极差为3.9 ℃,差异较小,对于土壤TN 含量的空间分布的影响较弱。
在本研究中,生物变量对土壤TN 的影响仅次于地形变量。NDVI 数据表征植被生长状况和植被覆盖度等植被活动[30-31]。Pearson 相关分析结果表示,土壤TN 与NDVI 呈显著的负相关关系,这与前人的研究结果不一致[32],究其原因可能是研究区为小尺度的林场,有林地面积超过83%,人工林和天然林面积相近,而人工林林分密度大,郁闭度大,因此具有较高的NDVI。Chen 等[33]研究指出树木多样性与土壤N 积累具有正相关关系。以自然更新为主的天然林群落结构复杂,具有丰富的枯落物,枯落物直接归还的有机质多,有利于土壤氮素积累,因此,天然林土壤TN 含量高于人工林,NDVI 高的地区土壤TN 低。
RF 模型在0~10 cm 土层深度精度指标值均优于10~30、30~50 cm 土层深度。模型对土壤属性空间分布的预测精度主要受环境的复杂性、土壤属性的空间变异性和模型的预测性能的影响[34]。人为活动会在土壤表层产生相对均匀的环境,同时本研究最终选定的用于与土壤TN 建立关系的环境协变量大多数是从地表收集的,这些因素有助于提高模型在0~10 cm 土层深度的预测精度。在一般情况下,深层土壤环境复杂,模型的预测性能较低。土壤属性在垂直梯度上的分布及环境因素对其控制性影响仍是土壤学研究的重点,故应加强对深层土壤环境的研究并提高深层土壤属性的预测精度。
本研究在构建土壤TN 含量的预测模型时,在环境协变量的选择上未包含对土壤TN 含量影响较强的土壤其他属性(pH、有机质、速效钾等),土壤数据多是通过不同制图方法获取,本身存在误差和不确定性,进而可能影响土壤TN 含量预测的准确性;在土壤TN 制图时未考虑人为因素的影响,林场的业务涉及森林经营、种苗培育、木材生产和旅游开发等人类活动,而本研究选取的环境协变量多为自然因素,缺乏能很好表征人为因素的变量,未来若可以将林场经营模式、采伐强度等因素纳入模型中,可进一步完善林场土壤属性预测模型;研究区内天然林土壤TN 明显高于人工林,若后期能获取该林场林分类型数据,设置哑变量结合其他环境变量数据进行模型建模,可能会在一定程度上提高模型预测效果和精度。
(责任编辑:葛晓霞)
猜你喜欢
南水北调与水利科技(2017年1期)2017-02-27 00:07:43
中国人口·资源与环境(2016年11期)2017-02-17 09:19:45
安徽农学通报(2016年24期)2017-01-12 21:15:16
绿色科技(2016年20期)2016-12-27 17:34:13
中国民族民间医药·上半月(2016年10期)2016-11-19 11:41:11
科技视界(2016年18期)2016-11-03 23:51:58
中国科技博览(2016年22期)2016-11-01 16:58:26
科技视界(2016年13期)2016-06-13 08:06:36
湖北农业科学(2015年16期)2015-10-28 21:29:11
湖北农业科学(2015年17期)2015-10-09 21:20:25
