
融合时序关系和上下文信息的时间动作检测方法
2024-01-01 00:00:00王猛杨观赐*
贵州大学学报(自然科学版) 2024年6期




文章编号10005269(2024)06007807
DOI:10.15958/j.cnki.gdxbzrb.2024.06.12
摘要:时间动作检测是视频理解领域中具有挑战性的任务。先前的时间动作检测模型主要关注视频帧的分类,而忽略视频帧之间的时序关系,导致时间动作检测模型的性能下降。为此,提出融合时序关系和上下文信息的时间动作检测方法(temporal action detection based on enhanced temporal relationship and context information,ETRD)。首先,设计了基于增强局部时序关系注意力机制的全局特征编码器,关注相邻帧的时序关系;其次,构建基于上下文信息的时序特征增强模块,融合上下文信息;最后,通过头部输出分类和回归结果。实验结果表明,所提出的ETRD模型在THUMOS14和ActivityNet1.3数据集上的平均mAP(mean average precision,平均精度均值)分别达到了67.5%和36.0%。相比于Actionformer模型的66.8%和35.6%,ETRD模型的平均mAP分别提升了0.7%和0.4%。利用视觉传感器,所提出的模型可检测出行为类别和持续时间。同时,结合心率等生理信号,可实现个体健康状态管理,为远程医疗、智能监控等提供了一种解决方案。
关键词:时间动作检测;时序关系;上下文信息;多头注意力机制;视频动作理解
中图分类号:TP18
文献标志码:A
当前,随着视频内容在互联网上的爆炸式增长,对视频进行深入理解和分析已成为计算机视觉领域的前沿课题。特别的是,时间动作检测的目的是在未修剪视频中定位动作实例的起止时刻并识别其类别,这对于实现高效视频理解非常重要。该技术在智能监控、运动性能分析、远程医疗康复等多个领域中有着广泛的应用潜力[1]。
为了寻求时间动作检测任务的最优解,学者们进行了相关研究。根据是否生成提案进行划分,时间动作检测方法主要分为一阶段和二阶段方法。
首先,二阶段检测方法是先生成动作提议,然后模型再进行分类和回归。为降低边界位置噪声,文献[2]提出了利用互补边界回归器和关系建模来生成时间建议的新框架,设计了基于嵌套跳跃连接的U形架构,捕获丰富的上下文信息。同时,为解决模型缺乏多层次位置感知的问题,文献[3]提出基于查询的增强位置感知网络,设计了时态位置感知编码器,对时态连续的位置感知上下文进行建模,重新感知查询内部和查询之间与位置相关的上下文信息。视频会存在很多无效帧以及背景帧,其会造成视频检测和定位困难。针对背景信息混淆的问题,文献[4]提出新颖的“特征分离+聚类+定位”迭代过程。为在检测效率和准确性之间实现良好的权衡,文献[5]提出了利用多尺度滑动窗口机制从粗到细的分层时间动作检测方法,提高检测的速度。黄金钾等[6]提出全局与局部相互感知的图网络检测方法,构建了整体关系图推理网络。然而,上述二阶段时间动作检测方法会忽略动作片段帧之间的时序关系,且对超参数较为敏感,泛化能力较差,不利于时间动作检测的应用与部署。
其次,一阶段方法直接在模型中进行分类和回归,输出视频的定位结果。文献[7]提出多时间尺度时空注意力模型,预测多个时间尺度的特征空间动作,解决单个时间尺度的特征信息不足的问题。胡聪等[8]提出基于注意力机制的动作检测模型,设计基于区分函数的优化模型,提高了模型的准确性。为解决背景帧与动作帧混淆的问题,文献[9]引入协同前背景和动作建模网络来抑制背景和歧义性背景帧,以实现精确的时序动作定位。王东祺等[10]提出全局时序关联时间动作检测方法,构建内部时序关系建模,从而缓解模型背景帧识别不准的问题。然而,上述一阶段方法受到卷积有限感知域的限制,导致上下文信息建模不足。同时,由于在时间上只能使用局部上下文来提取某时刻的边界信息,导致了长期行动被分裂和不准确行动等问题。
我们注意到韩岩奇等[11]提出融合多注意力特征的分类模型,设计特征提取网络以提高特征表现力。受此启发,本文提出了融合时序关系和上下文信息的时间动作检测模型,旨在更好地捕获视频数据中的时间上下文信息和相邻帧的时序关系。首先,设计增强局部时序关系的多头注意力机制,关注相邻帧之间的时序关系,促进全局特征信息交互。其次,设计基于上下文信息的时序特征增强模块,促进局部特征信息交互。最后,通过实验验证,表明所提出的模型在两个公开数据集上的平均精度均值(mean average precision,mAP)都得到了提升,有效检测出了行为的类别及持续时间,为后续个人健康状态管理提供行为数据支撑。
1融合时序关系和上下文信息的时间动作检测方法
在视频中,相邻帧之间存在着时序关系,不同帧的理解顺序导致视频内容理解偏差。正确理解时序关系和上下文信息建模可以帮助模型分析视频中的内容,从而提高模型的视频理解能力。因此,本文提出了融合时序关系和上下文信息的时间动作检测方法(temporal action detection based on enhanced temporal relationship and context information,ETRD)。ETRD模型总共包括全局特征编码器、时序特征增强模块及检测层3部分。
首先,模型采用双流I3D算法提取RGB视频和光流中的特征信息。其次,提出基于增强局部时序关系的多头注意力机制,分析相邻帧之间的时序关系。设计基于增强局部时序关系注意力机制的全局特征编码器,促进全局特征信息交互。再次,设计了基于上下文信息的时序特征增强模块,增强当前时序特征信息,获得丰富的特征信息。最后,采用金字塔网络提取多尺度特征信息并融合,得到包含上下文信息的特征向量矩阵。特征向量矩阵通过检测层中的头部输出分类和回归结果,结果包含实例的动作分类、开始边界以及结束边界。算法流程如算法1所示。
算法1融合时序关系和上下文信息的时间动作检测方法
输入视频X及光流XFlow,特征提取模型MF,动作检测模型Md,动作类别C,视频实例数N。
输出视频结果集合V{V1,…,Vm,…,VN}。
步骤1加载动作检测模型Md、特征提取模型MF、初始化学习率、帧数及动量等超参数。加载数据集的类别数C,视频实例数N。设定初始结果集合为V={},初始结果序列为VN={}。
步骤2加载视频X和光流XFlow,模型MF提取X和XFlow中的特征信息,得到空间特征矩阵Fs和运动特征矩阵Fm。
步骤3模型MF将特征矩阵Fs和Fm进行级联融合,得到特征矩阵F。
步骤4全局特征编码器Eg对特征矩阵F进行编码,得到全局特征信息交互的多尺度特征矩阵f{f1,…,fk}。
步骤5将特征矩阵f输入到时序特征增强模块Me,增强局部时序关系,得到特征矩阵xtem{xtem1,…,xtemk}。
步骤6金字塔网络对多尺度特征矩阵xtem进行线性运算,融合多尺度特征信息,得到特征矩阵xFusion。
步骤7采用head头部对特征矩阵xFusion进行分类和回归,输出Ccls和Creg,得到视频中第m实例的结果序列Vm{Ccls,tpres,tpree}。//m表示视频中第m动作实例,m为正整数。
步骤8如果m≤N,视频的结果集合V=V∪Vm,否则,跳转到步骤9。
步骤9输出视频结果集合V。
步骤1中初始化参数包括学习率r、动量设置为0.9、类别数C。加载动作检测模型Md、特征提取模型MF。其中:Md模型是本文所提出的动作检测模型;MF模型是双流I3D模型[12]、TSN模型[13]、Slowfast模型[14]。THUMOS14数据集上模型初始学习率设置为1e-4,类别数C为20;ActivityNet1.3数据集上设置为1e-3,类别数C为200。
步骤2中光流XFlow是通过特征提取模型MF对视频X处理得到。
步骤4中编码器Eg为基于增强局部时序关系注意力机制的全局特征编码器。详细结构见下文1.1部分。fk的下标k为金字塔网络的层数,本文模型默认设置为6。
步骤5中的特征增强模块Me为基于上下文信息的时序特征增强模块,详细结构见下文1.2部分。
步骤6中采用的金字塔网络为FPN金字塔网络[15]。线性运算指的是矩阵相加运算。
步骤7中头部包含分类和回归头部,均采用一维卷积实现。
步骤9输出视频结果集合V包含{V1,…,Vm,…,VN}。
1.1基于增强局部时序关系注意力机制的全局特征编码器
特征提取是时间动作检测方法的关键步骤,可以为模型提供高质量的视频特征。本文的特征提取模型采用的是在Kinetics数据集[12]上进行训练的双流I3D模型。视频特征提取模型I3D将视频X={xn}Tn=1提取特征信息,得到输入特征向量F={Fn}Tn=1∈RT×d。
双流I3D模型从视频中提取的特征信息只结合了局部时空信息,没有关注相邻帧之间的时序关系,造成了模型性能具有一定局限性。为此,本文提出基于增强局部时序关系注意力机制的全局特征编码器,促进相邻帧之间的特征信息交互。其核心在于增强局部时序关系的多头注意力机制(enhance local temporal relationships multi head attention mechanism,ELTR),它的架构如图1所示。
首先,特征矩阵F经过一维卷积分别得到特征矩阵q、k、v;其次,特征矩阵k与经过线性映射的k进行相加,增强k矩阵所携带的全局特征信息,得到丰富局部时序关系的k矩阵;最后,再与q进行矩阵内积运算,得到特征信息交互的A矩阵。如式(1)、(2)、(3)、(4)所示。
q=h1(F)(1)
k=h2(F)(2)
v=h3(F)(3)
A=softMax(q(k⊕L(k)))(4)
式中:h1、h2、h3分别代表着卷积核为3、步长为1的一维卷积;L代表着线性映射操作;softMax代表着归一化指数函数。之后,特征矩阵v与经过深度可分离卷积处理的矩阵v进行相加,增强v携带的局部特征信息,得到丰富全局特征信息的v矩阵,再与A矩阵进行矩阵内积运算,得到相邻帧之间时序关系信息的特征矩阵o。如式(5)所示。
o=Am(v⊕D(v))(5)
式中:D代表着卷积核为3的深度可分离卷积中的分组卷积;A代表着q和k相乘的特征信息交互矩阵;m代表着标准归一化操作。
接着,介绍由基于增强局部时序关系注意力机制组成的全局特征编码器。假设编码器的输入为I3D提取的特征F,经过本文提出的增强局部时序关系注意力机制处理,得到包含相邻帧之间时序关系的多尺度特征矩阵z。然后,经过多层感知机提取,得到携带时序信息特征的特征矩阵f{f1,…,fk}。如式(6)、(7)、(8)所示。
o,M=E(m1(F))(6)
z=xM+d1(o)(7)
f=z+d2(MLP(m2(z))M)(8)
式中:o为经过ELTR注意力机制处理后的特征矩阵;z为中间特征矩阵;f代表经过全局特征编码器处理后的特征矩阵;MLP代表多层感知机;E代表增强局部时序关系注意力机制;m1、m2代表标准归一化操作;d1、d2代表随机丢包操作;M代表掩码矩阵。
1.2基于上下文信息的时序特征增强模块
视频中的相邻帧之间包含着丰富的时序关系,正确分析相邻帧的时序关系并进行上下文信息建模有助于模型更好地理解视频内容。因此,本文设计基于上下文信息的时序特征增强模块(temporal feature enhancement module based on context information,TFEC),通过增强时序维度上的特征信息以聚合上下文信息,促进视频间上下文信息交互。
首先,特征向量矩阵f{f1,…,fk}经过线性下采样缩减通道数。有效的下采样帮助模型关注视频中的重要特征信息,从而促进特征信息交互。其次,经过平均池化操作得到相邻帧之间的时序关系信息。最后,经过线性上采样恢复原来的通道数,得到特征向量矩阵xtem{xtem1,…,xtemk}。如式(9)、(10)、(11)所示。
w=R(L(f))(9)
o=L(P(w))(10)
xtem=αL(o)+f(11)
式中:α为超参数,用于平衡局部特征信息,α通过2.3节中的实验1)来确定最优参数;R代表ReLU激活函数;P代表平均池化操作。
1.3损失函数
模型的损失函数包含分类损失和回归损失两部分。分类损失采用交叉熵损失,解决正负样本不均衡的问题,如式(12)所示。
ls=-ylog(p)-(1-y)log(1-p)(12)
式中:ls为分类损失;y为当前样本的标签,正样本为1,负样本为0;p为当前样本预测为正样本的概率,p∈[0,1]。
回归损失采用Generalized Intersection over Union损失,在训练过程中要避免梯度消失问题。如式(13)所示。
lr=1-B∩BuB∪Bu+c-(B∪Bu)c(13)
式中:lr为模型的回归损失;B和Bu分别为预测锚框和真实锚框;c为包含B和Bu的最小框。
最终,总损失函数如式(14)所示。
l=ls+βlr(14)
式中:l为模型的总损失函数;β为回归损失参数,用于平衡回归边界。
2实验结果与分析
2.1数据集与评价指标
为了评估所提出模型的有效性,本文模型在两个公开的基准数据集上进行实验。
首先,介绍训练和测试使用的两个基准数据集。THUMOS14数据集[16]总共包括20种动作类别,其中,有200个验证视频和213个测试视频,分别用于模型测试和训练。Activitynet1.3数据集[17]总共有200个类,20 000个视频。本文将Activitynet1.3数据集以2∶1∶1的比例划分,其中,训练视频10 024个,验证视频4 629个。模型在训练集上进行训练,在验证集上进行测试。
其次,介绍模型的评价指标。本文采用在不同时间窗口交并比(temporal intersection over union,tIoU)上的mAP来评价模型的性能。在给定tIoU阈值下,本文记录了所有动作类别的mAP,并进一步记录不同给定tIoU阈值下的平均mAP情况,以此来反映模型的有效性。
2.2实施细节
本文遵循Actionformer[18]中的部分实验参数设置,这些实验参数包括后处理阶段的非极大值抑制参数,特征提取和特征金字塔的层数,梯度裁剪技术等。模型参数在不同的数据集上略微不同。其中,THUMOS14数据集上的输入特征维度为2 304,约5 min的视频。epochs设置为50,初始学习率为1e-4,使用10帧/s的速度划分视频帧和光流,训练轮次设置为2,mAP评价指标中tIoU阈值为[0.3,0.1,0.7]。在ActivityNet1.3数据集上,模型初始学习率为1e-3,epochs设置为20,训练轮次设置为16,mAP评价指标中tIoU阈值为[0.5,0.05,0.95]。
模型在PyTorch1.12.0上实现。模型在Windows11系统上使用第十二代Gen Intel Core i512400F CPU和12 GB的RTX3060Ti GPU在python3.8环境下进行训练和测试。
2.3超参数选择和分析
为评估本文所提出模块的有效性,文中进行了实验,并遵循2.2节中的实验设置,在THUMOS14数据集上进行训练和测试。
1)时序特征增强模块α参数的选择
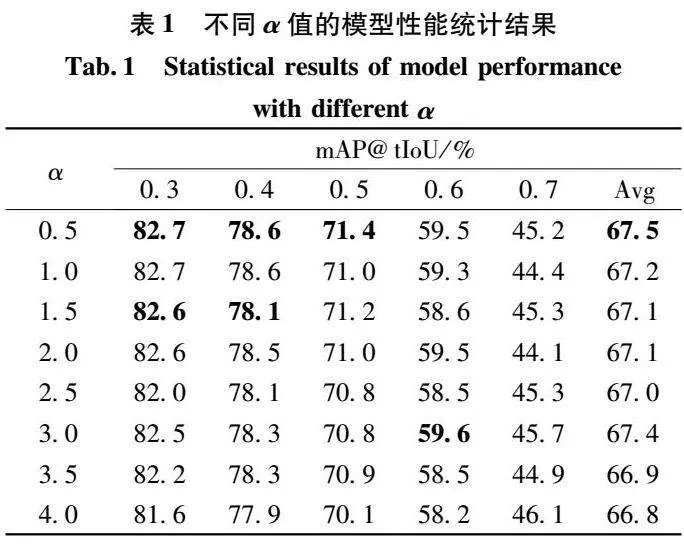
针对式(11)中的α参数,本文进行了实验验证,以找到最优的时间增强模块下采样参数。模型按照2.2中的实验参数设置,下采样率r参数初始设置为4。只改变α的取值,得到不同的模型。将模型在THUMOS14数据集上进行训练测试,得出表1中不同α值的模型性能统计结果。
观察表1中实验数据可知,当α为0.5时,模型的mAP@0.5为71.4%,在所有的α取值中为最优的。tIoU从0.3到0.7的平均mAP为67.5%,为模型的最优平均mAP。当α为1.0时,模型的mAP@0.5为71.0%,tIoU从0.3到0.7的平均mAP为67.2%。当α为3.0时,模型的mAP@0.5为70.8%,平均mAP为67.4%。当α为4.0时,模型的mAP@0.5为70.1%,平均mAP为66.8%。综上,在后续的实验模型中α值采用0.5。
2)不同模块的消融实验
为探索不同模块的有效性,下面进行实验验证。实验参数设置遵循2.2节以及2.3节中的模型最佳性能参数选择,加入模块或者不加入模块,形成不同的模型,在THUMOS14上进行训练和测试。表2为两个模块不同组合的模型性能统计结果。其中,1代表不加模块的基准模型,2为加入增强局部时序关系的多头注意力机制后形成的模型,3为加入时序特征增强模块后形成的模型,4为两个模块都加后形成的模型。
观察表2中的实验数据可知,从平均mAP的评价指标来看,模型1为66.8%,模型2为66.9%,模型3为67.2%,模型4为67.5%。可以看出加入局部时序增强注意力机制后,模型平均mAP提高了0.1%。当模型加入时序特征增强模块时,模型平均mAP提高了0.4%。当局部时序增强注意力机制和时序特征增强模块都加入时,模型平均mAP提高了0.7%。从mAP@0.4来看,模型1为77.8%,模型2为77.9%,模型3为78.8%,模型4为79.0%。可以看出加入局部时序增强注意力机制后,模型mAP@0.4提高了0.1%。当模型加入时序特征增强模块时,模型mAP@0.4提高了1.0%。当局部时序增强多头注意力机制和时序特征增强模块都加入时,模型mAP@0.4提高了1.2%。
2.4对比实验
为综合评估ETRD模型的有效性,本文将ETRD模型与代表性的模型进行对比。表3中对比方法的实验数据来源于原始论文中的实验数据。ETRD模型按照2.2和2.3节实验参数进行设置,在THUMOS14数据集和ActivityNet1.3数据集上进行训练和测试,得到表3不同模型的mAP性能指标统计结果。
观察表3的实验数据可知,从不同tIoU阈值的平均mAP上看,在THUMOS14数据集上tIoU阈值从0.3以0.1的步长到0.7,TadTR模型的值为46.6%,STCLNet模型的值为38.9%,SGCANet模型的值为36.7%,ELAN模型的值为57.0%。Actionformer模型的值为66.8%,本文所提出的ETRD模型的值为67.5%,比Actionformer模型高出了0.7%,优于所对比的代表性模型。在ActivityNet1.3数据集上tIoU阈值从0.5以0.05的步长到0.95,SSLM模型的值为24.7%,MSST模型的值为34.1%,Actionformer模型的值为35.6%。ETRD模型的值为36.0%,比Actionformer模型高出了0.4%。
从固定tIoU阈值的mAP上来看,在THUMOS14数据集上,对于mAP@0.5评价指标,TadTR模型的值为49.2%,ELAN模型的值为59.9%,Actionformer模型的值为71.0%,本文所提出的模型为72.0%,比Actionformer高出了1.0%,优于所比较的代表性的模型。在ActivityNet1.3数据集上,对于mAP@0.75评价指标,TadTR模型的值为32.6%,Actionformer模型的值为36.2%,SSLM模型的值为24.0%,ETRD模型的值为36.7%,比Actionformer模型高出了0.5%。
综上,ETRD模型取得了不错的性能。具体来说,在THUMOS14数据集上tIoU从0.3以0.1的步长到0.7的平均mAP为67.5%,在ActivityNet1.3数据集上tIoU从0.5以0.05的步长到0.95的平均mAP为36.0%。
3结论
目前,时间动作检测方法大多是对空间维度上的特征信息进行分类及回归边界。因此,本文构建融合时序关系和上下文信息的时间动作检测方法,分析相邻帧之间的时序关系,促进特征信息的交互。实验结果表明,相较于基准Actionformer模型,所提出的ETRD模型在THUMOS14和ActivityNet1.3数据集上均得到了提升。研究成果可以应用到智能监控、老人监护和远程医疗等领域。鉴于视频中存在语音数据或者文本数据,构建多模态数据融合的检测方法可以帮助模型更好地理解视频内容。
参考文献:
[1]陈纪铭, 陈利平. 一种优化FCN的视频异常行为检测定位方法[J]. 重庆邮电大学学报(自然科学版), 2021, 33(1): 126134.
[2] SU H S, GAN W H, WU W, et al. BSN++: Complementary boundary regressor with scalebalanced relation modeling for temporal action proposal generation[C/OL]//Proceedings of the AAAI conference on artificial intelligence (AAAI). 2021, 35(3): 26022610(20210518)[20240508]. https://ojs.aaai.org/index.php/AAAI/article/view/16363/16170.
[3] CHEN G, ZHENG Y D, CHEN Z, et al. ELAN: enhancing temporal action detection with location awareness[C]//2023 IEEE International Conference on Multimedia and Expo (ICME). Brisbane: IEEE, 2023: 10201025.
[4] LIU Y Y, ZHOU N, ZHANG F Y, et al. APSL: actionpositive separation learning for unsupervised temporal action localization[J]. Information Sciences, 2023, 630: 206221.
[5] ZHAO F, WANG W, WU Y, et al. A coarsetofine temporal action detection method combining light and heavy networks[J]. Multimedia Tools and Applications, 2023, 82(1): 879898.
[6] 黄金钾, 詹永照, 赵逸飞. 整体与局部相互感知的图网络时序动作检测[J]. 江苏大学学报(自然科学版), 2024, 45(1): 6776.
[7] GAO Z, CUI X L, ZHUO T, et al. A multitemporal scale and spatialtemporal transformer network for temporal action localization[J]. IEEE Transactions on HumanMachine Systems, 2023, 53(3): 569580.
[8] 胡聪, 华钢. 基于注意力机制的弱监督动作定位方法[J]. 计算机应用, 2022, 42(3): 960967.
[9] MONIRUZZAMAN M, YIN Z Z. Collaborative foreground, background, and action modeling network for weakly supervised temporal action localization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(11): 69396951.
[10]王东祺, 赵旭. 类别敏感的全局时序关联视频动作检测[J]. 中国图象图形学报, 2022, 27(12): 35663580.
[11]韩岩奇,苟光磊,李小菲,等.融合多粒度注意力特征的小样本分类模型[J/OL].计算机应用研究,17(20240104) [20240508]. https://doi.org/10.19734/j.issn.10013695.2023.09.0513.
[12]CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Hawaii: IEEE, 2017: 62996308.
[13]WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks for action recognition in videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 41(11): 27402755.
[14]FEICHTENHOFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul: IEEE, 2019: 62016210.
[15]LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 936944.
[16]IDREES H, ZAMIR A R, JIANG Y G, et al. The THUMOS challenge on action recognition for videos “in the wild”[J]. Computer Vision and Image Understanding, 2017, 155: 123.
[17]HEILBRON F C, ESCORCIA V, GHANEM B, et al. ActivityNet: a largescale video benchmark for human activity understanding[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston: IEEE, 2015: 961970.
[18]ZHANG C L, WU J, LI Y. Actionformer: localizing moments of actions with transformers[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 492510.
[19]LIU X L, WANG Q M, HU Y, et al. Endtoend temporal action detection with transformer[J]. IEEE Transactions on Image Processing, 2022, 31: 54275441.
[20]HUANG J, ZHAO P, WANG G Q, et al. Selfattentionbased long temporal sequence modeling method for temporal action detection[J/OL]. Neurocomputing,2023,554(20231014)[20240508]. https://www.sciencedirect.com/science/article/pii/S0925231223007403.
[21]FU J, GAO J Y, XU C S. Semantic and temporal contextual correlation learning for weaklysupervised temporal action localization[J/OL]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2023:116(20230619)[20240508]. https://ieeexplore.ieee.org/document/10155179.
[22]LI B R, PAN Y F, LIU R X, et al. Separately guided contextaware network for weakly supervised temporal action detection[J]. Neural Processing Letters, 2023, 55(5): 62696288.
[23]LI P, CAO J C, YUAN L, et al. Truncated attentionaware proposal networks with multiscale dilation for temporal action detection[J/OL]. Pattern Recognition,2023,142(20230516)[20240508]. https://www.sciencedirect.com/science/article/pii/S0031320323003825.
(责任编辑:曾晶)
Abstract:
Temporal action detection is a challenging task in the field of video understanding. Previous temporal action detection models mainly focus on the classification of video frames, while ignoring the temporal relationship between video frames, which leads to the performance degradation of temporal action detection models. To this end, a temporal action detection method based on enhanced temporal relationship and context information (ETRD) is proposed. First, a global feature encoder based on enhanced local temporal relationship attention mechanism is designed to focus on the temporal relationship between adjacent frames. Second, a temporal feature enhancement module based on context information is constructed to fuse context information. Finally, the classification and regression results are output through the head. Experimental results show that the proposed ETRD model achieves an average mAP of 67.5% and 36.0% on the THUMOS14 and ActivityNet1.3 datasets, respectively. Compared with the 66.8% and 35.6% of the Actionformer model, the average mAP of the ETRD model is improved by 0.7% and 0.4%, respectively. Using visual sensors, the proposed model can detect the behavior category and duration. At the same time, combined with physiological signals such as heart rate, individual health status management can be achieved. Thus, a solution for telemedicine or intelligent monitoring, etc. will be provided.
Key words:
temporal action detection;temporal relationship;context information;multi head attention mechanism;video action understanding
收稿日期:20240517
基金项目:国家自然科学基金资助项目(62163007,62373116);贵州省科技计划项目(黔科合平台人才[2020]60072,黔科合支撑[2023]一般118)
作者简介:王猛(1998—),男,在读硕士,研究方向:自主智能系统与机器人,Email:wm30252021@163.com.
*通讯作者:杨观赐,Email:gcyang@gzu.edu.cn.
