
人工智能在飞机颠簸预报中的应用进展及未来趋势展望
2024-01-01 03:04朱玉祥刘海文万文龙姜晓飞尕藏程林
大气科学学报 2023年6期
朱玉祥,刘海文,万文龙,姜晓飞,尕藏程林
① 中国气象局 气象干部培训学院,北京 100081;
② 中国民航大学,天津 300300;
③ 东营市气象局,山东 东营 257091
飞机颠簸,是指水平尺度介于100 m~1 km的大气湍流所导致的飞机飞行中突然出现的忽上忽下、左右摇晃及机身震颤等现象,也称为飞机尺度湍流(Sharman and Lane,2016)。飞机在航路上飞行时遇到颠簸而产生的机体摇晃和震颤,对飞机的安全会产生影响,严重时甚至会导致人员伤害和财产损失(Williams and Joshi,2013;申艳玲等,2017)。胡伯彦等(2022)对东亚地区晴空湍流的变化趋势进行了预估,指出未来东亚地区垂直风切变作用的增强可能是引起晴空湍流增多的重要原因之一。Prosser et al.(2023)的研究表明,受气候变化的影响,晴空湍流有增加的趋势。这意味着未来乘坐飞机时可能会遇到更多的强烈颠簸。因此,对飞机颠簸的预报具有十分重要的意义和价值。最近几年,人工智能(AI)技术在天气预报和气候预测中的应用取得了迅速发展,并且有多篇综述性论文对其进行了介绍(杨淑贤等,2022;杨绚等,2022)。但目前为止,尚未见到人工智能在飞机颠簸预报中应用的综述性论文,这不利于该领域相关科研和业务的深入开展。
因此,本文将对飞机颠簸的预报方法进行回顾,特别是人工智能(AI)方法在飞机颠簸预报中的最新应用。在此基础上,归纳总结AI方法在飞机湍流预报中存在的主要问题和解决思路。
1 预报方法
飞机颠簸来自大气中的湍流,其产生的原因有很多,最常见的是由风的垂直切变和气流的变形引起的晴空湍流(Sharman and Lane,2016)。根据物理机理,可以将湍流分为3种类型:晴空湍流、对流湍流、山地波湍流(Storer et al.,2019)。其中晴空湍流是由6 000 m以上自由大气中的小尺度湍流涡流(100~2 000 m)直接产生的,与对流云(不包括非对流卷云)无关(Chambers,1955)。
飞机颠簸发生的范围往往是区域性的,其水平范围可以从几千米到几百千米。在高空槽脊、切变线、锋区的弯曲部分及急流两侧容易发生颠簸。飞机颠簸和大气湍流多发生在具有以下特性的区域:1)风的垂直切变区;2)风的水平切变区;3)流场的辐合或辐散区;4)流场的水平变形区;5)流场变化的不连续区;6)强的水平温度梯度区(干全等,2002)。
飞机颠簸的预报方法大致可以分为两类:一类是通过对天气环流形势、气象环境因子和气象要素进行总结得到的物理特征做预报,这类方法称为定性预报;另一类是通过高分辨率的数值模式,以及在数值模式预报基础上的数值产品释用做预报,这类方法称为定量预报(李耀东等,1997;干全等,2002;Kim et al.,2011,2018;黄仪方和马婷,2012;Pearson and Sharman,2017;Sharman and Pearson,2017;Storer et al.,2019;杨波等,2021;闫文辉等,2022;蔡雪薇等,2023)。图1是这两类飞机颠簸预报方法的示意图,其中数值产品的释用分为动力释用和统计释用,机器学习释用可以归类为统计释用。
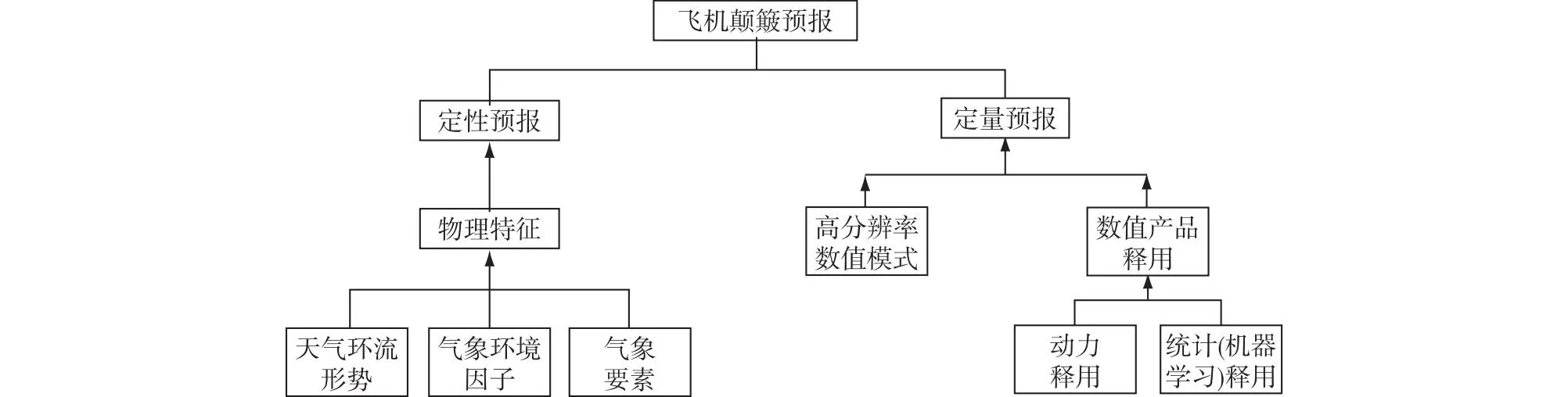
图1 飞机颠簸预报分类Fig.1 Classification of aircraft turbulence forecast
预报员基于卫星、雷达等数据进行经验外推做2 h以内的临近预报,是航空气象预报业务的常用方法,这种预报也可以归为定性预报。对于民用航空运营来说,为了合理地计划与调整在有限空域中航班的空中流量和飞机起降,需要航空公司、机场和空管动态地把握分钟和小时时间分辨率的天气信息。因此重要天气预报的实时化、准确化和定量化对于民航运营极其重要。这种民航空运业务的要求,已经超过了人工定性经验加外推式预报的极限(周斌斌等,2016)。
随着计算机能力的提高和卫星、雷达等更多观测数据在数值模式中的同化应用,数值预报取得了迅速的发展。当今发达国家的航空气象业务预报,都是在数值模式和数值模式后处理产品的基础上开展的,而飞机颠簸预报的主流趋势也是建立在数值预报基础之上的定量预报(李耀东等,1997;Gill and Buchanan,2014;周斌斌等,2016;朱玉祥等,2016)。
数值天气预报(Numerical Weather Prediction,NWP)是对“临近预报”时间范围(即0~2 h)以外航空湍流发生和时空分布进行预报的主要手段。NWP是指根据已知的控制大气演化的数学和物理规律,对一组离散方程在时间上进行数值积分,从而预报大气的未来状态(Kalnay,2002)。最终的NWP预报是一个三维大气状态的集合,包括风速、气压、湿度、位势高度和水汽含量等变量,并在预报期内的指定时间点输出预报结果。由于数值预报方程组不存在解析解,所以在进行NWP计算时,需要将预报区域离散化到网格框中。对于大多数实时的实际业务应用,这些网格框的水平间距的量级为100~101km。例如,全球NWP模式(覆盖整个地球)通常水平网格间距为10~30 km(Bauer et al.,2015),而许多区域(只覆盖全球的一部分区域)数值天气预报模式只在几千米的水平网格距上运算(Benjamin et al.,2018)。相比之下,这种水平网格间距比航空湍流的尺度要大得多(Lindborg,1999),并且航空湍流可能在几秒钟内发生,这意味着实时运行的NWP模式将无法完全分辨直接导致航空湍流的大气环流特征。为了克服这些局限性,形式为“湍流诊断量”或“指数”的解决方案已经被开发出来。“湍流诊断量”或“指数”是由代表大尺度大气环境的NWP预报变量导出的物理量,这些物理量是通过推测或经验确定的,与航空湍流的发生有关。例如,Ellrod-Knapp湍流指数是一种著名的、被广泛使用的湍流诊断方法;它是根据Kelvin-Helmholtz不稳定理论,基于风场的变形和垂直切变所导致的湍流生成而定义的(Ellrod and Knapp,1992)。多年来,对航空湍流背后不同物理机制的考虑产生了许多湍流诊断公式(Dutton,1980)。
NCEP采用单模式和多模式集合所做的美国颠簸预报采用的是Ellrod方法,英国气象局做的全球预报采用的也是Ellrod方法,该方法通过计算风场的切变和变形来诊断颠簸的弱、中和强三个等级(Ellrod and Knapp,1992;Turp et al.,2006)。NCAR发展了一种综合性的颠簸诊断方法(Graphical Turbulence Guidance,GTG)(Sharman et al.,2006;Sharman and Lane,2016),该方法不是用一种方法来诊断湍流,而是对12种湍流诊断方法进行权重集合,这种权重集合可以提高预报的准确率和信心(用概率给出)。比如,如果12种湍流诊断方法中有10种预报会出现强湍流,则强湍流出现的概率为10/12=83%。
2 人工智能在飞机颠簸预报中的应用
2.1 人工智能、机器学习、深度学习三者的关系
人工智能是指通过计算机复现人类的智能。一般认为,1956年夏天在达特茅斯学院召开的会议(Dartmouth Conference)是人工智能的起源。当然,关于人工智能方面的研究更早就开始了。1950年,图灵发表了一篇划时代的论文,文中预言了创造出真正具有智能的机器的可能性(Turing,1950)。由于注意到“智能”这一概念难以确切定义,所以他提出了著名的图灵测试:如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么就可以称这台机器具有智能。这一简化的定义使得图灵能够令人信服地说明“思考的机器”是可能的。
人工智能问世60多年来,在语音识别、图形处理、机器翻译、智能搜索等很多领域都得到了广泛的应用(张钹等,2020;吴焦苏和李真真,2022a,b)。在气象领域,人工智能也取得了一系列创新性成果和应用尝试(Shi et al.,2017;Ham et al.,2019;贺圣平等,2021;黄亮等,2022;雷蕾等,2022;刘泉宏等,2022;谢文鸿等,2022;杨淑贤等,2022;Bi et al.,2023;Ham et al.,2023;Zhang et al.,2023)。
机器学习使用计算机从数据中学习规律,是人工智能领域最能体现智能的一个分支学科(周志华,2022)。机器学习的主要算法包括:线性回归、决策树、集成学习(Boosting、Bagging、随机森林等)、神经网络、支持向量机、贝叶斯分类器、聚类、主成分分析、奇异值分解等。机器学习也被称统计学习(李航,2019)。机器学习在飞机湍流预报中也得到了应用,并且取得了相对较好的效果(Hon et al.,2020;Muoz-Esparza et al.,2020)。
21世纪以来,深度学习从各种机器学习算法中脱颖而出。深度学习的概念源于人工神经网络的研究,含多个隐含层的多层感知器就是一种深度学习结构,深度学习也属于机器学习。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习的研究动机源自建立模拟人脑进行分析学习的神经网络,它试图模仿人脑的机制来对数据进行学习和解释。深度学习是目前科学界研究最为活跃的领域,新方法新进展层出不穷。常见的深度学习算法包括:卷积神经网络(Convolutional Neural Networks,CNN)、长短期记忆网络(Long Short Term Memory Networks,LSTM)、递归神经网络(Recurrent Neural Networks,RNN)、生成对抗网络(Generative Adversarial Networks,GAN)、多层感知机(Multilayer Perceptrons,MLP)、自组织映射神经网络(Self Organizing Maps,SOM)、深度信念网络(Deep Belief Networks,DBN)等。Hinton and Salakhutdinov(2006)提出了深度信念网络,并运用反向传播算法成功地训练了一个具有多个隐含层的神经网络,这种算法能够为多层联合训练过程找到一个好的初始值,甚至可以训练全连接结构的神经网络,突破了此前只能训练深度卷积神经网络(DCNN)或深度循环神经网络(DRNN)这类特殊结构的神经网络的局限性,使训练一般的深度神经网络变得具有可行性,为工业界大规模应用深度学习做好了准备。这标志着深度学习进入了一个新时代。Hinton由于在深度学习领域的杰出贡献,被称为“深度学习之父”。深度学习具体的技术细节可参考Ian et al.(2016)。现在大家谈到的人工智能算法,往往指的就是深度学习。
综上可见,深度学习是机器学习的一个子集,而机器学习又是人工智能的一个子集,即:深度学习<机器学习<人工智能。图2为它们之间关系的示意图。
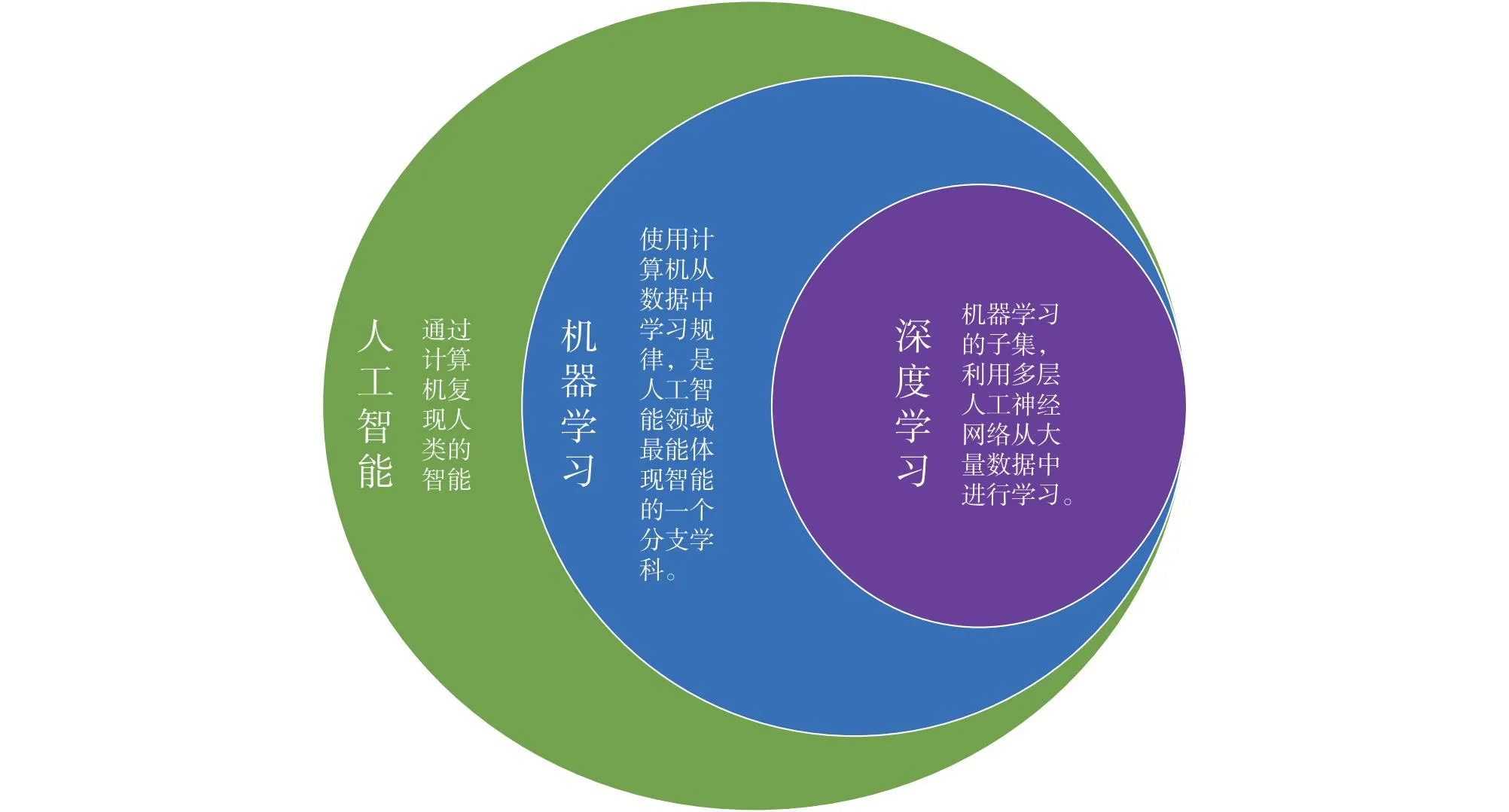
图2 人工智能、机器学习、深度学习之间关系的示意图Fig.2 Schematic diagram of relationship among artificial intelligence,machine learning,and deep learning
2.2 浅层学习与深度学习的区别
浅层学习和深度学习通常都是基于人工神经网络(ANN)开展的,二者之间的区别如图3所示。与深度学习(图3b)相对应的是浅层学习(图3a)。浅层学习中间的隐层只有一层,而深度学习中间的隐层可以有多层。当然,这只是二者之间关系的一个简单的示意图,现在深度学习算法的变种有很多,构造也十分复杂。
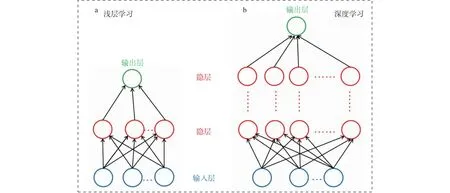
图3 浅层学习(a)与深度学习(b)的对比示意图Fig.3 Contrast diagram between (a) shallow learning and (b) deep learning
人工神经网络(ANN)是20世纪80年代人工智能领域兴起的研究热点,它对人大脑的神经元网络进行抽象,建立某种数学模型,按不同的方式组成不同的网络。人工神经网络是一种数学上的运算模型,由大量的节点(或称神经元)之间相互连接而构成(图3)。每个节点代表一种特定的输出函数,称为激活函数。每两个节点之间的连接都代表通过该连接的信号的加权值(称为权重),这相当于人工神经网络的记忆。网络的输出值取决于网络的连接方式、权重值和激活函数。网络自身可以是对某种算法或函数的逼近,也可以是一种逻辑策略的表达。20世纪80年代中期,误差反向传播算法(Error Back Propagation Training,简称BP算法)的提出(Rumelhart et al.,1986),系统解决了多层神经网络隐含层连接权重的学习问题。Robert(1989)成功证明了多层感知机(是ANN的一种,结构类似于图3a)的万能逼近定理,即对于任何闭区间内的一个连续函数,都可以用含有一个隐含层的BP网络来逼近。这一理论上的证明,极大地鼓舞了当时神经网络的研究人员,使得ANN风靡一时。
但20世纪90年代BP算法被指出存在梯度消失问题,即在误差梯度反向传递的过程中,后层梯度以乘法方式叠加到前层,误差梯度传到前层时几乎为0,在更新权值的时候,由于误差梯度太小,导致权值更新很小,因此无法对前层的参数进行有效的学习。这是使用sigmoid激活函数的一大弊端。这一时期,符号学习中的决策树、支持向量机(SVM)等算法被提出并被广泛应用,特别是在处理线性分类的问题上取得了当时最好的成绩,而ANN的研究则陷入了低谷。
不过,多伦多大学的Hinton教授并未放弃ANN的研究。功夫不负有心人,Hinton and Salakhutdinov(2006)提出了利用RBM编码的深层神经网络(深度学习),该方法基于样本数据,通过一定的训练方法得到了包含多个层级的深度网络结构。传统的神经网络随机初始化网络中的权值,导致网络容易收敛到局部最小值,为了解决这一问题,Hinton and Salakhutdinov(2006)提出使用无监督预训练方法优化网络权值的初值,然后再进行权值的微调。这使得深层神经网络变得实用起来,从此拉开了深度学习大发展的序幕。2012年10月,Hinton教授和他的两个学生采用深层的卷积神经网络模型在著名的ImageNet大规模视觉识别挑战赛上取得了当时世界上的最好成绩,这使得对于图像识别的研究工作前进了一大步,也把深度学习的应用推向了一个新高度。
对于浅层模型来说,需要依靠人工经验来抽取样本的特征(对于天气预报和气候预测问题来说,就是预报因子),模型的输入是这些已经选取好的特征,模型只用来负责分类和预测。在浅层模型中,最重要的工作往往不是模型的构建而是特征的选取,这样就需要花费大量的精力用来进行特征的开发和筛选,这限制了浅层模型的应用效果。而深度学习采取的是端到端(输入端到输出端)的学习方法,从输入端经过卷积、池化、反向传播等操作后可以得到原始数据的特征表达,基于这种特征表达,可以对原始数据进行识别与分类,在这个过程中,并没有将学习任务分成一段一段的子任务进行分析和处理。可见,相对于浅层学习,深度学习采取了完全不同的处理手段,它是从输入端输入数据,然后传到中间层,通过层层抽象的方法直接得到输入数据的特征表达,进而对这种特征表达进行分析与处理,因此它是一种端到端的学习方法,具有明显的优势。
2.3 机器学习算法在飞机颠簸预报中的应用
根据学习方式,机器学习可以分为监督学习算法、非监督学习和强化学习算法(杜智涛等,2021)。气象问题大多都是分类问题和回归问题,常用的是监督学习算法,包括:多元线性回归、逻辑回归(LR)、随机森林(RF)、支持向量机(SVM)、XGboost、人工神经网络(ANN)、深度学习(DL)等(朱玉祥等,2017;周志华,2022)。
机器学习在气象领域中得到了广泛应用,代表性工作有:雷暴预报(Williams et al.,2008)、中尺度对流系统预报(Ahijevych et al.,2016)、对流风实时预报(Lagerquist et al.,2017)、冰雹预报(Gagne et al.,2017a;Burke et al.,2020)、太阳辐照度预报(Gagne et al.,2017b)、2 m温度的集合预报后处理(Rasp and Lerch,2018)、极端降水预报(Herman and Schumacher,2018)、实时风暴预报(McGovern et al.,2019)、风功率预报(Kosovic et al.,2020)和恶劣天气预报(Hill et al.,2020)。图4是与数值天气预报相关的机器学习文章的统计结果,可见使用最多的是深度学习(DL)方法。
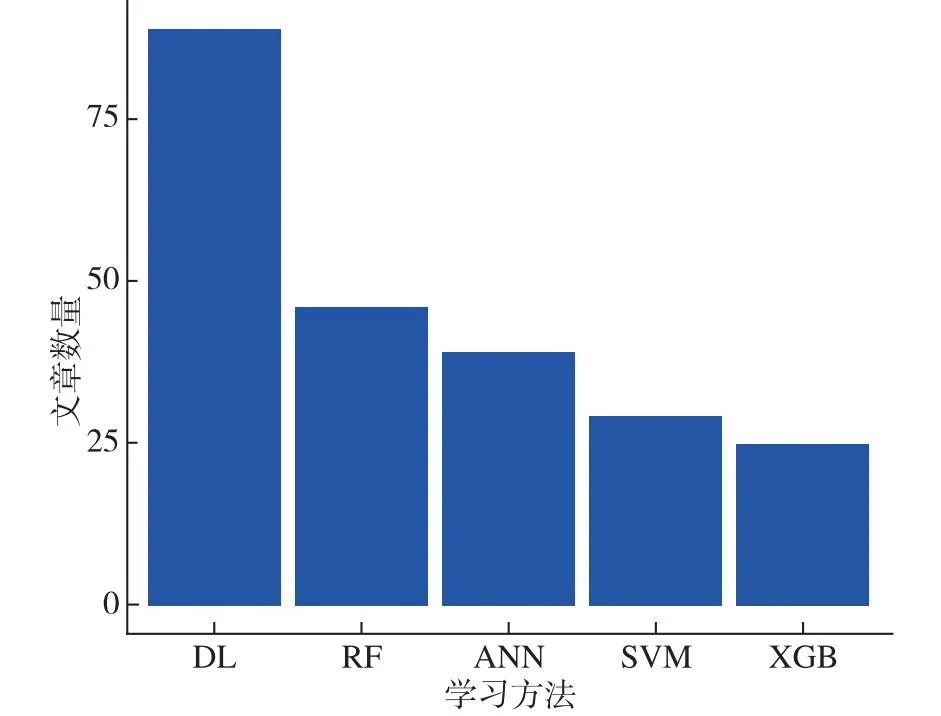
图4 与数值天气预报相关的机器学习文章统计(引自Bochenek and Ustrnul(2022))Fig.4 Statistics of machine learning articles related to numerical weather prediction(from Bochenek and Ustrnul(2022))
机器学习在飞机颠簸预报中应用的代表性文献主要有如下一些。
由于数值天气预报(NWP)模式不能明确预报飞机尺度的湍流,Abernethy et al.(2008)使用支持向量机和逻辑回归算法来捕捉大尺度大气条件与湍流之间的关系,并应用于晴空湍流预报,结果表明该算法可以应用于实时预报湍流预报系统。
Williams(2014)基于来自商用飞机的客观湍流报告和模式预报数据,采用随机森林算法构建适合空中交通管理人员、调度员和飞行员使用的湍流预报,该算法于2014年在美国国家气象局航空气象中心得到应用。
Hon et al.(2020)应用XGboost算法,通过一个NWP模式生成的一组传统“湍流指数”的优化组合,生成了有技巧的航空湍流预报。经过1 a时间,对16 000多架飞机飞行员报告的验证表明,基于机器学习的多指数共识(MIC)在亚太地区表现出一致的优越性能,与单独考虑湍流指数相比,技巧评分的中值提高了3%~17%。
Emara et al.(2021)将分类和回归监督机器学习模型与从6 000次常规航班收集的飞行运营质量保证数据结合使用,来估计未来时段内的EDR以及湍流严重程度。为此,他们收集和分析了航空公司日常运营中遇到不同程度湍流的数据。结果表明,在遇到湍流事件前10 s左右,模型能够很好地预测EDR和湍流严重程度。该模型可以获得对未来可能发生的湍流事件的近乎连续的预测,并为飞行员和空乘人员建立了早期预警系统的能力。
可能是由于受到湍流数据在时间和空间覆盖范围上的限制,或者受到学识所限,深度学习在飞机颠簸预报中应用的文献尚未见到。
2.4 基于深度学习的大模型
目前的数值预报模式,时空分辨率越来越高,参数化方案越来越精细,致使模式越来越复杂。而数值模式越复杂,就意味着要搜集更多气象数据,进行更大量的计算,这对算力的消耗非常大。如 0.25°×0.25°精度的未来10 d数值预报,需在超过3 000个节点的超级计算机上花费数小时,这让数值预报的预测速度难以进一步提升(Bi et al.,2023)。而飞机湍流预报更是需要十分精细的时空分辨率,采用数值模式开展飞机湍流预报,对计算资源的花费更高。
AI预报的出现,给天气预报带来了新思路。AI擅长拟合未知的复杂数据关系,它不需要熟知大气运动中的物理原理,只需要用深度学习的方法拟合气象数据中的关系,就能做天气预报。数值预报无法给出分钟级的气象预报,而AI方法拟合雷达回波、卫星遥感及台站观测等数据的能力,超过了光流法等外插方法,这使AI方法能更快(甚至在几秒钟内)做出天气预报。
谷歌公司首次引入注意力机制,发展了“MetNet”系列预报模型,该模型输入雷达和卫星等观测数据,可以预报出降水的概率分布;该模型实现了1 km空间分辨率、2 min时间分辨率的12 h时效降水预报,回报性能超过了NOAA的高分辨率快速更新天气模式(HRRR)(Espeholt et al.,2021)。英伟达公司凭借其强大的算力资源,构建了“FourCastNet”全球预报模型,其预报性能与欧洲中期天气预报中心(ECMWF)的综合预报系统(IFS)相当(Pathak et al.,2022)。
华为开发的盘古气象大模型提供的Z500五天预报均方根误差为296.7,显著低于之前最好的数值预报方法(均方根误差为333.7)和AI方法(均方根误差为462.5)。在保持精度的同时,盘古气象大模型也有着无可比拟的预报速度:在一张V100显卡上只需要1.4 s就能完成24 h的全球气象预报,相比传统数值预报提速10 000倍以上(Bi et al.,2023)。
复旦大学人工智能创新与产业研究院联合大气与海洋科学系发布了伏羲气象大模型(https://arxiv.org/pdf/2306.12873.pdf)。该模型利用AI算法实现未来15 d的全球天气预报,在15 d预报中具有与ECMWF集合平均(EM)相当的预报性能。伏羲超过了ECMWF高分辨率预报(HRES)的预报技巧时效,将Z500的预报时效从9.25 d延长到10.5 d,将2 m温度的预报时效从10 d延长到14.5 d。
清华大学软件学院王建民、龙明盛团队提出了极端降水临近预报大模型,将数据驱动与物理驱动两大科学范式紧密结合,显著提高了千米尺度下0~3 h极端降水的预报能力,在全国62位气象预报专家的过程检验中大幅领先国际上的同类方法。目前该大模型已经在国家气象中心短临预报业务平台(SWAN 3.0)部署上线,将为全国极端降水天气短临预报业务提供支撑(Zhang et al.,2023)。
这些气象大模型的开发和业务化运行,给飞机湍流预报奠定了基础;基于这些大模型的输出结果,飞机湍流预报可得实现。
3 未来应用趋势展望
未来的人工智能必将从通用大模型发展到行业或专业大模型,AI技术为提升飞机颠簸预报能力提供了难得的机遇。虽然国内外对AI技术(主要是其中的子集机器学习)在飞机颠簸中的预报进行了大量研究,但还存在以下几个值得重点关注的问题:
1)飞机实况数据的开放共享以及多源湍流数据的融合构建问题。比如,AMDAR(Aircraft Meteorological Data Relay)数据是通过民航班机的自动观测仪器观测得到的气象信息,主要包括:观测时的经度、纬度、飞行高度、气温、风向、风速、导出等效垂直风速DEVG、湍流耗散率EDR、飞机结冰程度等。其中DEVG和EDR可以作为飞机颠簸程度的指标,在AI模型的训练中特别有用。但目前,该数据并未开放共享,这给飞机颠簸预报的研究带来了很大的困难。当然,基于这些飞机观测数据,融合飞行员话音报(PIPEPs)、卫星、雷达等多源数据做出一套时空覆盖完整的EDR数据,对于相关科研和业务的开展具有重要意义。深度学习在数据插补和多源数据融合中正在发挥越来越大的作用,比如Ma et al.(2023)采用深度学习方法建立了一套1979年以来北极地区1°×1°格点月平均地表气温资料和2010年之后的北极地区日平均温度资料,这为在数据稀疏的北极地区开展科学研究奠定了坚实的数据基础。
2)以深度学习为代表的大模型和以传统的统计学习或机器学习为代表的小模型之间的关系,以及深度学习的可解释性问题。现在的研究大多数都表明深度学习模型具有优势,但深度学习是有代价的,需要足够多和足够精确的数据以及昂贵的计算资源。当数据和计算资源都受限时,传统的统计学习或机器学习可能更实用。开展飞机颠簸预报研究,能拿到的飞机观测数据往往只是航路上的,时间也只是飞机飞行时才有,这时采用统计学习或机器学习的小模型可能更实用。对于构建飞机颠簸预报模型来说,可解释性也是一个十分重要的问题,相比于参数数量十分庞大的深度学习大模型,传统的统计模型在可解释性方面具有明显优势。
3)基于集合预报的概率预报值得深入研究。湍流的高瞬态和局地性意味着飞机颠簸的确定性预报十分困难。从概率论的观点来看,飞机颠簸是随机变量,因此只有采用概率分布才能对其进行准确的描述。相对于单一预报,集合预报或集成预报具有明显的优势。无论是深度学习还是传统的统计学习,集合预报的表现往往都比单一预报更好,其原因可能是每个单独的模型或成员擅长捕捉不同的模态,将它们的预报结果结合起来,可以识别复杂的模态,因而能够取得更好的预报效果。由于飞机湍流的尺度小,单一模式或方法的不确定性往往更大。因此,基于集合预报或集成预报,开展飞机湍流的概率预报极具实用价值。而更节省计算机机时的人工智能大模型为开展飞机湍流的概率预报提供了便利条件。
4 结论与讨论
湍流是飞机飞行过程中遇到的一种影响巨大的灾害性天气,其准确预报对于减轻灾害影响具有十分重要的意义。但由于受计算机资源和数值模式发展水平的限制,数值模式目前尚无法直接模拟出湍流涡旋,所以湍流预报的准确率离防灾减灾需求还存在不小差距,人工智能技术的发展为开展更加深入的研究并用来提高飞机颠簸的预报准确率提供了条件。
相比传统的数值模式,气象AI大模型大大节省了计算机时,这为开展高精度的湍流预报提供了新的机遇和条件。目前的人工智能技术在气象预报和湍流预报中的应用,大都是基于历史数据的关系拟合,本质上属于统计学习的范畴。目前的深度学习技术,说到底就是对由人工神经元网络构成的非线性函数在大数据上所做的拟合,这种学习行为使得它在应用的普适性上有很大的优势,满足了我们让机器“做得多”的要求,但是其结果的可靠性和合理性无法得到完备的验证,这是因为我们尚无法理解深度学习结果生成的逻辑,无法完美解释学习的认知行为。
人工智能自诞生以来,在其发展历程中,一直存在两种相互竞争的范式,即符号主义与联接主义。符号主义认为人工智能起源于数理逻辑,旨在用数学和物理学中的逻辑符号来表达思维的形成,通过大量的“如果(if)-就(then)”规则进行定义,产生像人一样的推理和决策。符号主义强调思维过程的逻辑性,侧重于推理和解决问题的思路。联结主义又称仿生学派或生理学派,其主要原理为神经网络及神经网络间的连接机制与学习算法。它通过模拟人类大脑的神经系统来实现学习。联结主义认为知识和技能的获取是通过对大量数据进行学习来实现的。
符号主义和联结主义几乎同时起步,但20 世纪80 年代之前符号主义一直占据主导地位,而20 世纪90 年代之后联接主义逐步发展起来,进入21 世纪后更是迎来了发展的高潮,大有替代符号主义之势。张钹等(2020)称符号主义为第一代AI,称联接主义为第二代AI,将要发展的AI 称为第三代AI。第一代AI是知识驱动的,即利用知识、算法、算力3个要素构造AI。第二代AI是数据驱动的,即利用数据、算法、算力3个要素构造AI。
20世纪80年代我国就开始了气象人工智能的研究和业务尝试,包括专家系统、人工神经元网络、智能数据库、天气过程的计算机理解和仿真、卫星云图的分析识别等方面(王耀生,1994)。气象领域大量的观测、分析、再分析等数据为建立人工智能大模型提供了条件和便利,这可能也是目前气象领域AI大模型如雨后春笋般不断涌现的一个原因(Bi et al.,2023;Zhang et al.,2023)。但目前人工智能在气象领域的应用,基本上还是属于第二代AI。张钹等(2020)认为符号主义和联接主义两种范式只是从不同的侧面模拟人类的心智(或大脑),具有各自的片面性,依靠单个范式不可能触及人类真正的智能;他提出第三代人工智能的发展路径是融合第一代的知识驱动和第二代的数据驱动的人工智能,同时利用知识、数据、算法和算力4个要素,建立新的可解释和鲁棒性的AI理论与方法,发展安全、可信、可靠和可扩展的AI技术。基于这种思想,我们对气象领域的第一代和第二代人工智能进行了归纳,并提出了气象领域第三代人工智能的发展思路(图5)。

图5 气象领域三代人工智能的发展路径Fig.5 Development path of the third generation of artificial intelligence in the field of meteorology
对于气象领域来说,“知识”可以是物理机理,也可以是预报员的经验,或者是天气学、气候学等方面的基本原理。气象第一代人工智能是采用数理逻辑、归纳、类比等算法,基于“知识”自动形成推理原则,代表应用为气象专家系统、气象智能数据库。多元线性回归、SVM、决策树、随机森林等算法,可以归为第一代人工智能算法。气象第二代人工智能主要采用ANN、深度学习等算法,基于模式数据和观测数据做天气预报和气候预测,代表应用为华为的盘古气象大模型。气象领域未来的第三代人工智能可能要以深度学习为主,融合数理逻辑推理算法,同时基于“知识”和“数据”,即把联结主义学派和符号主义学派的优势结合起来,开展天气预报和气候预测工作。当然,气象第三代人工智能需要具有更高的预报准确率,具有自学习、自适应(比如适应由于气候变化导致的气象数据规律的变化等)等特点,同时在机理上具有较好的可解释性。
对于气象预报和飞机湍流预报来说,把基于数据驱动的人工智能与以牛顿力学为基础的物理定律相融合,是增强气象大模型或湍流预报大模型的可解释性、鲁棒性并且提高预报准确率的重要途径。对于在业务上开展概率预报来说,人工智能大模型节省计算机时的优越性更是具有重要的实用价值。
致谢:国家气象中心蔡雪薇高工对本文提出了建设性意见,在此致以最诚挚的感谢!
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09
作文周刊·小学一年级版(2022年24期)2022-06-18
中学生数理化·高一版(2021年11期)2021-09-05
内蒙古气象(2021年2期)2021-07-01
中国特种设备安全(2018年10期)2018-12-18
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
焊接(2016年2期)2016-02-27
教育科学论坛(2014年6期)2014-03-01
教育科学论坛(2014年4期)2014-03-01
