
以关联推荐算法指导卷烟品牌精准培育的方法探析
2023-12-15 05:59:48刘燕张琼吕佳敏谢莹陈辉郑培
中国市场 2023年35期
刘燕 张琼 吕佳敏 谢莹 陈辉 郑培



摘 要:烟草行业拥抱数字化,如何利用海量卷烟数据更好地为卷烟品牌培育赋能,成为烟草行业的工作重点。大数据算法的发展与应用,让精准营销变得更有科学依据,助力精准品牌培育。因此,文章以湖南省衡阳县辖区在销的卷烟品牌为研究对象,通过收集卷烟品牌主客观指标数据,采用协同过滤模型和K-means聚类等算法进行分析,旨在探索基于关联推荐算法的卷烟品牌精准培育方法,形成一套可移植的方法论,助力新卷烟品牌实现更好的品牌培育效果。
关键词:关联推荐;精准营销;K-means聚类;品牌培育
中图分类号:F274文献标识码:A文章编号:1005-6432(2023)35-0123-04
DOI:10.13939/j.cnki.zgsc.2023.35.123
1 引言
2023年全國烟草半年工作会议作出不断深化改革创新、持续增强发展动能的部署,要求充分发挥品牌带动发展作用。而烟草行业数字化的海量烟草数据资源尚未得到充分发掘利用,如何利用卷烟数据更好地为卷烟品牌培育赋能,成为烟草行业工作重点。
文章以湖南省衡阳县辖区在销的卷烟品牌为研究对象,通过收集卷烟品牌主客观指标数据,借助K-means聚类、协同过滤等关联推荐算法,分析出不同卷烟品牌之间的关联程度,形成以畅销烟为品牌定点的关联推荐列表,为新卷烟品牌培养提供更具针对性和高效性的关联推荐方法论指导。
2 指标选取与数据收集
2.1 主客观指标选择与调研
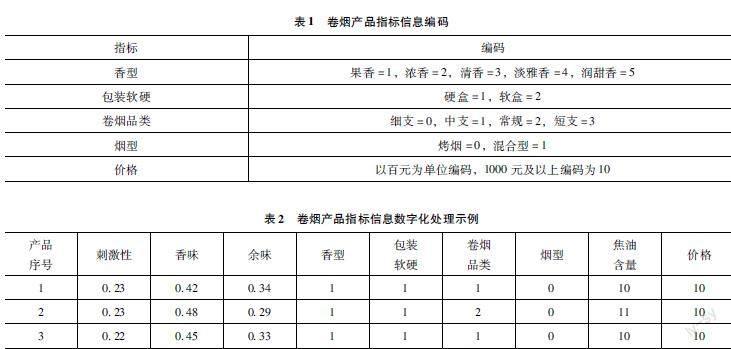
文章基于深入访谈,在深入洞察卷烟市场信息后,总结归纳出14个卷烟品牌主客观指标并形成调研表进行指标调研,其中包括包装软硬、卷烟规格、价类等11个客观指标。另依据《卷烟感官技术要求》,选取了刺激性、香味以及余味3个主观指标,采用5级量表进行指标评分。
客观指标由衡阳市烟草公司衡阳县分公司客户服务分部工作人员调取内部官方指标数据,进行分类填写汇总。主观指标由代表性零售商组织进行卷烟品吸并进行填写,上报后统一汇总。
2.2 数据收集基本情况
衡阳县域内在销卷烟品规共179种,其中,国产卷烟170种,进口卷烟9种。国产卷烟中,湖南省内烟有30种,余下140种为国产省外烟,保证了衡阳县卷烟市场的品牌多样性。根据衡阳县2023年1月至5月各卷烟品牌总销额和总销量统计结果可知,衡阳县卷烟市场呈现出明显的品牌偏向性,以芙蓉王(硬)为代表的芙蓉王系列、白沙系列与双喜系列在衡阳县卷烟市场占据着绝对的市场龙头地位。如图1和图2所示。
3 关联推荐模型分析
3.1 协同过滤模型
协同过滤(collaborative filtering,CF)算法是一类用于推荐系统的算法。而基于项目的协同过滤算法(CF)以项目作为标准来思考问题,算法本体根据用户行为来判定项目间的相似度。文章选用卷烟品牌主客观指标作为数据基础,既有卷烟产品本身的特征,也有用户评价赋予的特征,因此选用基于物品的协同过滤算法以及CF算法进行数据分析。
3.1.1 特征提取及数据处理
文章结合深入访谈结果和市场卷烟消费者看重指标,最终选取了九项指标进行协同过滤分析。主观指标具体评分由调研数据加权平均得出,焦油含量取mg/支,对其余的客观指标见表1所示的卷烟产品指标信息编码表进行编码转化,得到如表2所示的标准化指标数据。
图1 2023年1月至5月总销售额TOP20卷烟产品(元)
图2 2023年1月至5月总销售量TOP20卷烟产品(条)
计算卷烟产品相似度,采用的是余弦相似度公式:
similarityi,j=∑u∈Uijrui·ruj ∑u∈Uijr2ui· ∑u∈Uijr2uj(1)
其中,Uij表示对物品i和j都有评分的用户集合,rui表示用户u对物品i的评分。
生成推荐列表呈现的推荐分数是基于卷烟产品相似度的加权平均推荐分数:
r^uj=∑i∈Iusimilarity(i,j)·rui∑i∈Iusimilarity(i,j)(2)
其中,Iu表示用户u已评分的物品集合。
3.1.2 分析结果展示
文章采用Python设计卷烟产品的协同过滤分析程序,进行各个卷烟产品之间的相似性计算,并生成卷烟产品的相似性矩阵。文章选取衡阳县域王牌产品芙蓉王(硬)作为示例产品进行关联推荐分析。当输入芙蓉王(硬)进行推荐产品的相似度查询,可以得到程序推荐的相似产品列表,如表3所示。
3.2 K-means聚类模型
K-means算法是一种常见的聚类分析方法,旨在将相似的数据点分配到预先定义的K个簇中。
一般采用欧氏距离来表示样本之间的相似度关系。距离公式如下所示:
du,v=∑|ui-v|(3)
其中,ui表示数据成员,v表示k个簇的中心。
文章同时采用K-means算法,对卷烟品牌主客观指标数据进行聚类分析,以得出关联推荐分析结果,同时辅助验证协同过滤分析模型给出的结果可靠性。
3.2.1 数据处理
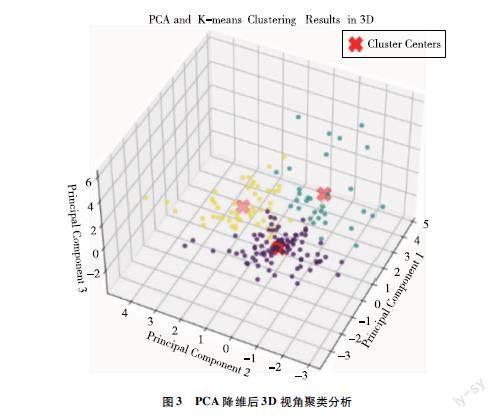
文章通过肘部法(elbow method),得出合适的聚类数量为3,其后文章采用了主成分分析(PCA)方法,将原始数据的多维特征空间降维到三维空间,评价指标Silhouette Score为0.347,Davies-Bouldin Index为1.080,Calinski-Harabasz Index为79.867,说明聚类结果在这三个指标下都表现良好,降维聚类后的结果如图3所示。
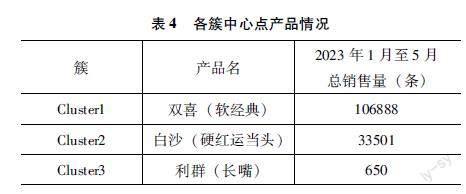
通过对每个簇心进行进一步分析,识别出簇心代表性产品,并从中获得有关产品特征和市场定位的洞察,如表4所示。
3.2.2 基于K-means聚类的产品培育建议
文章基于相似度关联推荐的逻辑,选取市场表现较好的簇心产品作为代表性产品,而培育产品则是簇心周围距离最近的产品群,梳理总结得出三大类可用于指导衡阳县实施精准卷烟品牌培育的产品培育对照表,部分对照表如表5所示。
3.3 K-means與CF算法结合推荐
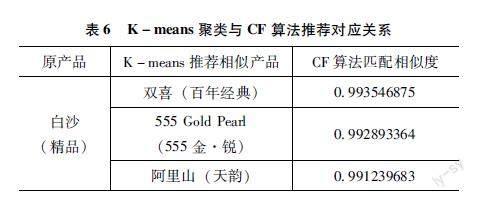
协同过滤模型与K-means聚类模型在指导卷烟品牌精准培育的关联推荐结果方面,分析预测是否一致,文章对这两种算法结果进行了对照检验,随机抽取白烟(精品)作为验证目标产品,在CF算法中输入白沙(精品)作为相似性产品的对照产品,生成的相似性矩阵和推荐列表进行比对后可以发现,基本上两者的推荐产品都实现了重合,且相似度都能够达到98%。因此从另一个方面验证了两种推荐算法的可靠性,对应关系如表6所示。
4 以关联推荐算法指导卷烟品牌精准培育的方法探析
文章探索了两种关联推荐算法在卷烟品牌精准培育上的指导路径,结果验证均可行。无论是协同过滤模型还是K-means聚类模型都可以基于产品指标数据算出产品之间的相似性,从而指导关联推荐的营销策略组合选择,如可以基于产品相似度指数给出以老带新的模版化的陈列组合方式选择。
卷烟企业想要基于关联推荐算法实施卷烟品牌精准培育,可以将两种推荐算法并入一套程序,先后输出聚类结果和基于物品的协同推荐,采用云数据库协同更新,帮助烟草专卖局统一获取和更新原烟草产品特性矩阵,包括增减烟草产品、修改特性值、增加其余客观指标以帮助更好地分析产品相关性。经销商也可以通过程序录入新产品的主观指标反馈,从而更好地扩充修正原产品评价矩阵内的数据内容,实现系统迭代更新。
参考文献:
[1]郑阳洋.基于大数据时代的卷烟精准营销模式研究[J].财经界,2021(30):49-50.
[2]唐明翔. 深化“数据营销” 探索“科学管理之路”——卷烟品牌精准培育体系构建[C]//广西壮族自治区烟草公司柳州市公司.广西壮族自治区烟草公司柳州市公司2020年学术论文汇编,2020:208-214.
[3]王雄峰. 衡阳市烟草公司省外卷烟品牌培育研究[D].衡阳:南华大学,2020.
[4]罗登山.解析GB 5606.4-2005《卷烟感官技术要求》[J].烟草科技,2005(9):47-48.
[5]徐翔宇,刘建明.基于多层次项目相似度的协同过滤推荐算法[J].计算机科学,2016,43(10):262-265,291.
[6]韩琮师. K-means聚类算法优化及其在电商平台精准营销中的应用研究[D].青岛:山东科技大学,2020.
[7]梁子敬,贺帅,李洋,等.烟草品牌培育的现状及对策研究[J].品牌与标准化,2021(5):14-15.
[8]马骏珍. 基于数据挖掘的卷烟品牌培育“三找”新方法实践与探索[C]//中国烟草学会.中国烟草2013年学术年会论文集,2013:324-328.
猜你喜欢
现代商贸工业(2017年2期)2017-03-28 12:29:33
科技资讯(2016年25期)2016-12-27 18:38:16
海峡科技与产业(2016年11期)2016-12-26 18:13:16
商情(2016年43期)2016-12-23 14:26:47
中国科技博览(2016年25期)2016-12-20 20:02:30
广西教育·C版(2016年10期)2016-12-07 06:00:53
商业经济研究(2016年15期)2016-10-24 13:42:18
中国市场(2016年35期)2016-10-19 02:16:47
今传媒(2016年9期)2016-10-15 22:08:05
出版广角(2016年6期)2016-08-04 16:36:38
