
基于深度学习的遥感图像语义分割技术研究与应用
2023-12-14 15:12:52朱锦钊
价值工程 2023年34期
朱锦钊
(广州方图科技有限公司,广州 510000)
0 引言
遥感图像语义分割在地理信息系统、环境监测、城市规划等领域具有广泛应用。准确的语义分割是实现这些应用的关键。DeepLab v3+是一种领先的语义分割网络,但它仍然需要改进以应对遥感图像的挑战。本研究旨在通过引入多尺度融合策略和深度可分离卷积,提高DeepLab v3+网络的性能,从而更好地应用于遥感图像分割。
1 基于改进的DeepLab v3+的遥感图像语义分割方法
本研究聚焦于改进的DeepLab v3+网络在遥感图像语义分割中的应用,通过深度学习技术提高遥感图像的语义分割精度。DeepLab 系列网络一直在语义分割领域表现卓越,而DeepLab v3+作为其新一代版本,通过引入更多的解码结构,旨在更好地融合高层和低层特征。在遥感图像领域,精确的语义分割对于地图制图、环境监测等应用具有重要意义。
DeepLab v3+通过引入空洞卷积,有效地扩大了感受野,提高了网络对图像的理解能力。同时,网络结构中的编码-解码形式有助于提取关键特征并将结果恢复到原始图像大小。网络模型主干网络是DeepLab v3+的核心部分,它采用串行的空洞卷积以增强特征提取能力。同时,主干网络的输出被分为两部分,一部分进入解码器用于恢复特征到原始图像大小,另一部分进行并行的空洞卷积来提取特征信息。这两个部分的特征经过合并后,经过双线性插值操作,最终进行像素点分类,实现了遥感图像的语义分割[1]。
2 基础网络选取及优化
2.1 深度可分离卷积
深度可分离卷积的结构包括一个3×3 的卷积层,用于数据集的特征提取,但其通道数仅有一层。在此卷积层中,卷积核会遍历输入张量的每个通道,生成相应数量的输出通道。接着,通过1×1 的卷积核来调整通道数的厚度。这种结构的优势在于降低了计算和内存的消耗,从而使网络训练更加高效。
例如,考虑一个传统的3×3 卷积层,其输入通道为32,输出通道为64。这将需要大约18432 个参数。然而,通过应用深度可分离卷积,首先用32 个3×3 的卷积核遍历32 个通道,生成32 个特征图。然后,使用64 个1×1 的卷积核遍历这32 个特征图,只需要2336 个参数。这大大减少了模型的参数数量,加快了运行速度[2]。
2.2 基础网络介绍
在本文中,介绍了所选用的基础网络——Xception65,该网络是深度学习领域的一项重要成果。Xception 网络结构包括逐通道卷积和逐点卷积两部分。首先,逐通道卷积对每个通道进行单独卷积操作,生成相应数量的输出通道。然后,逐点卷积(1×1 卷积)用于调整通道数,实现数据降维,从而减少计算量和参数数量。
在本文的遥感图像处理中,鉴于图像分辨率较高,采用了数据处理方法,包括添加噪声、翻转等,以扩充数据集的大小。此外,为了适应模型训练的需要,对输入图像进行了统一裁剪,将其尺寸调整为256×256[3]。
2.3 基础网络优化
对于处理高分辨率的遥感图像,神经网络的层数通常需要相对较深。然而,深层次网络存在一个常见问题,即梯度消失,这会导致学习停滞。为了解决这个问题,本文提出了将中间流模块之间的连接方式改进为密集连接。密集连接的原理很简单:对于网络中的每一层,前面层的所有特征映射都被用作输入,而自身的特征映射也被传递给后续层。这种连接方式显著提高了网络在每一层中提取语义信息和传递梯度的效率,使网络能够更好地提取特征信息。与传统的一层层下采样的卷积网络不同,密集连接改变了信息传递方式,同时传递了有效信息。改进原理如图1所示。

图1 中间流改进原理图
综上所述,通过引入密集连接方式,中间流模块的性能得到了显著提升,网络能够更好地处理高分辨率遥感图像,提高了特征的提取效率和网络的性能,特别是在深度监督和参数数量方面带来了优势。这一改进方法对于提高遥感图像分割等任务的准确性和鲁棒性具有重要意义[4]。
3 引入多尺度融合策略的优化
尽管DeepLab v3+网络在处理遥感图像分割方面表现出了出色的性能,但仍然存在一些不足之处。这些网络中的特征响应相对较弱。卷积神经网络在逐层处理图像时,面临一个重要问题,即如何更有效地利用特征信息。在网络训练初期,低层网络具有高分辨率的图像,强调几何信息,但在处理语义信息方面较弱。随着训练的进行,图像分辨率降低,几何信息减少,但语义信息的提取能力增强。高层次的特征对于分割大目标非常有效,而浅层特征适合处理小目标。然而,当图像的分辨率非常低时,对小目标的分割能力就会受到影响。DeepLab v3+的基础结构只融合了1/4 和1/16 尺度的特征,难以准确分割一些中等尺寸的目标。此外,深层网络中经过多次卷积操作,导致小目标的细节信息几乎被忽略。
因此,本文通过反复的实验,提出了引入逐层融合多尺度策略,这一策略通过多尺度融合改进了网络结构,如图2 所示。在这种策略下,语义信息和几何信息可以分别融合,极大地改善了深层和浅层网络训练中存在的问题。这一策略对于保持物体边缘的完整性以及捕获细节信息具有显著的作用,从而提高了遥感图像分割任务的性能[5]。
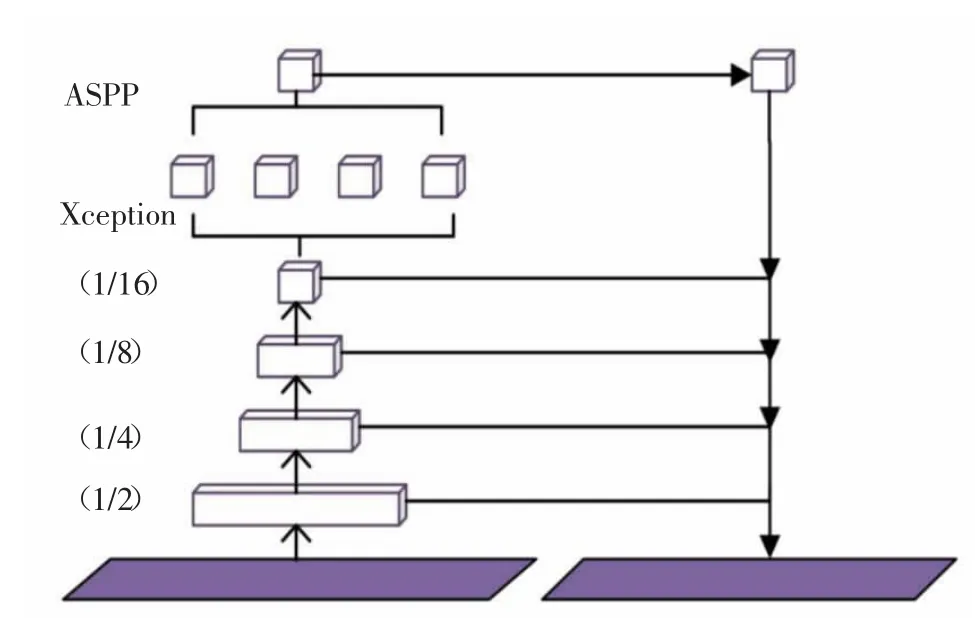
图2 引入多尺度融合策略优化后的网络结构图
4 应用分析
4.1 某地区区域分割图像训练策略
某地区遥感图像预处理:由于遥感图像数据集的特殊性,首先需要将其转换为RGB 三通道图像。由于本文所使用的遥感图像数据集分辨率较高,无法直接输入到网络进行训练,因此对本地区数据集进行了裁剪操作,将本地区的图像裁剪为256×256 像素大小。
基本参数设置:初始学习率设置为2e-4,训练次数均设置为50000 次,并采用Adam 策略来进行模型训练。
评价指标:本文采用了mIOU(平均交并比)和mPA(平均像素准确性)这两个评价指标。mIOU 指标常用于衡量模型的预测性能,它反映了数据集中像素标注值和模型预测值之间相同区域的平均比例,即正确预测的像素在总像素数中所占的百分比。而mPA 是每个类别的正确像素占比的平均值,也是分割任务中的一项常见评价指标。较高的mIOU 和mPA 值表示模型的分割性能更好。此外,还会统计每个模型生成一幅预测图像所需的平均时间,以比较它们的分割速度,进一步评估它们的性能。
某地区遥感图像对比: 在相同的环境下,本文对比了改进前后的网络模型的分割性能。分别进行了四种不同的对比实验,包括DeepLab v3+、改进后的DeepLab v3+、具有多尺度融合策略的DeepLab v3+,以及改进后并带有多尺度融合策略的DeepLab v3+。这些实验的评判标准是基于DeepLab v3+在Vaihingen 数据集和Potsdam 数据集上的分割结果。
4.2 Vaihingen 数据集上的应用结果
输入图像的分辨率为256×256,而各个模型的batch_size 均设置为16。经过基础网络改进和引入多尺度融合策略的网络模型,均在不同程度上改善了分割性能。特别是,经过基础网络改进并引入多尺度融合策略的改进模型,在一定程度上表现出更好的分割效果,尽管预测时间有所增加。但考虑到准确度的提升,这种时间增加可以被接受。图3 展示了在Vaihingen 数据集上,改进前后模型的可视化分割结果。
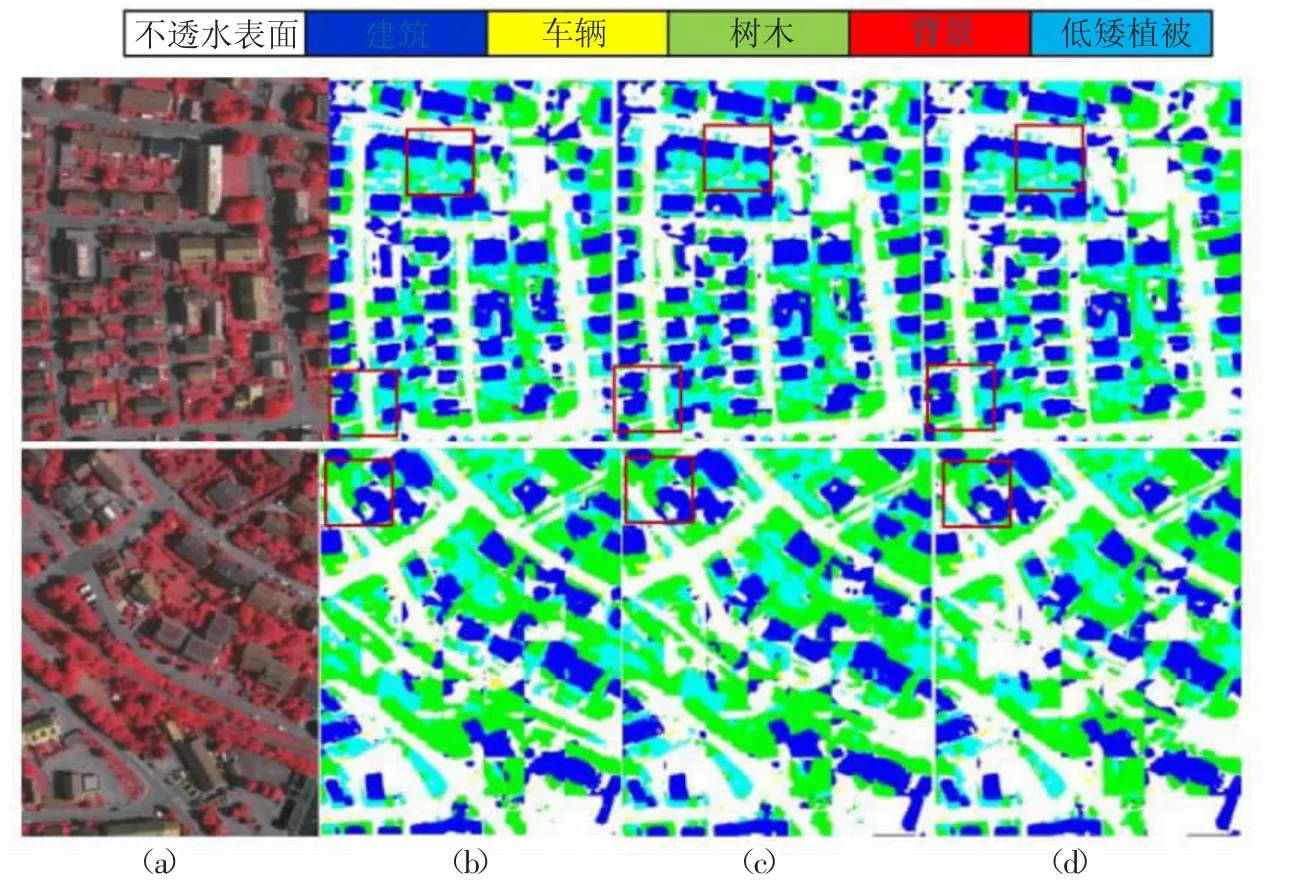
图3 改进前后模型在Vaihingen 数据集上的可视化分割对比图
梯度损失是分割网络模型性能的一个重要指标,从图4 中改进前后模型在Vaihingen 数据集上的Loss 值的变化曲线可以看出,改进后的模型性能更佳。
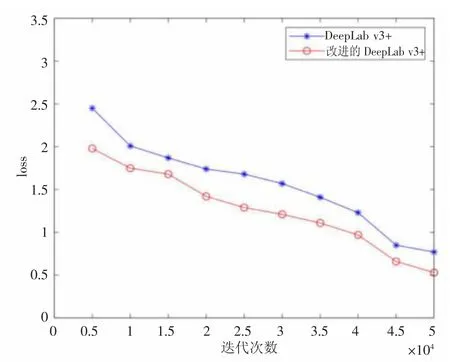
图4 改进前后模型在Vaihingen 数据集上的Loss 值变化曲线
SegNet、U-Net、DeepLab v3+都是常用的语义分割网络模型。分析这些网络结构可以得出,增大感受也有助于提高每一类的分割准确度。
本文提出的基础网络优化和引入多尺度融合策略的DeepLab v3+网络模型在Vaihingen 数据集上表现出更高的分割准确度。改进后的网络模型的mIOU 值比原始的DeepLab v3+提高了4.90%。这进一步验证了基础网络优化和多尺度策略的引入,有助于更好地捕获边界信息,从而获得更强的特征响应。
4.3 Potsdam 数据集上的应用结果
在Potsdam 数据集上,将某地区各个的batch_size 值设置为16,输入图像分辨率为256×256,统计各个区域网络在不同策略下的分割结果,以确定对改进模型的有效性。
在Potsdam 数据集上,引入多尺度融合策略相较于原始的DeepLab v3+区域模型,也可以显著提升分割区域的精度。此外,区域基础网络改进相对于引入多尺度融合策略,mIOU 值和mPA 值也有显著的提升。这进一步证明了本文提出的方法的有效性,以及改进后区域模型的更好分割性能。
各个区域在数据集上的训练后的预测图像如图5 所示。从图中所框出的部分可以看出,引入了两种策略或者单独引入一种策略相对于DeepLab v3+区域模型,在分割效果上均有显著提升。同时,引入了两种策略的区域模型对细节信息的分割也更为完整。
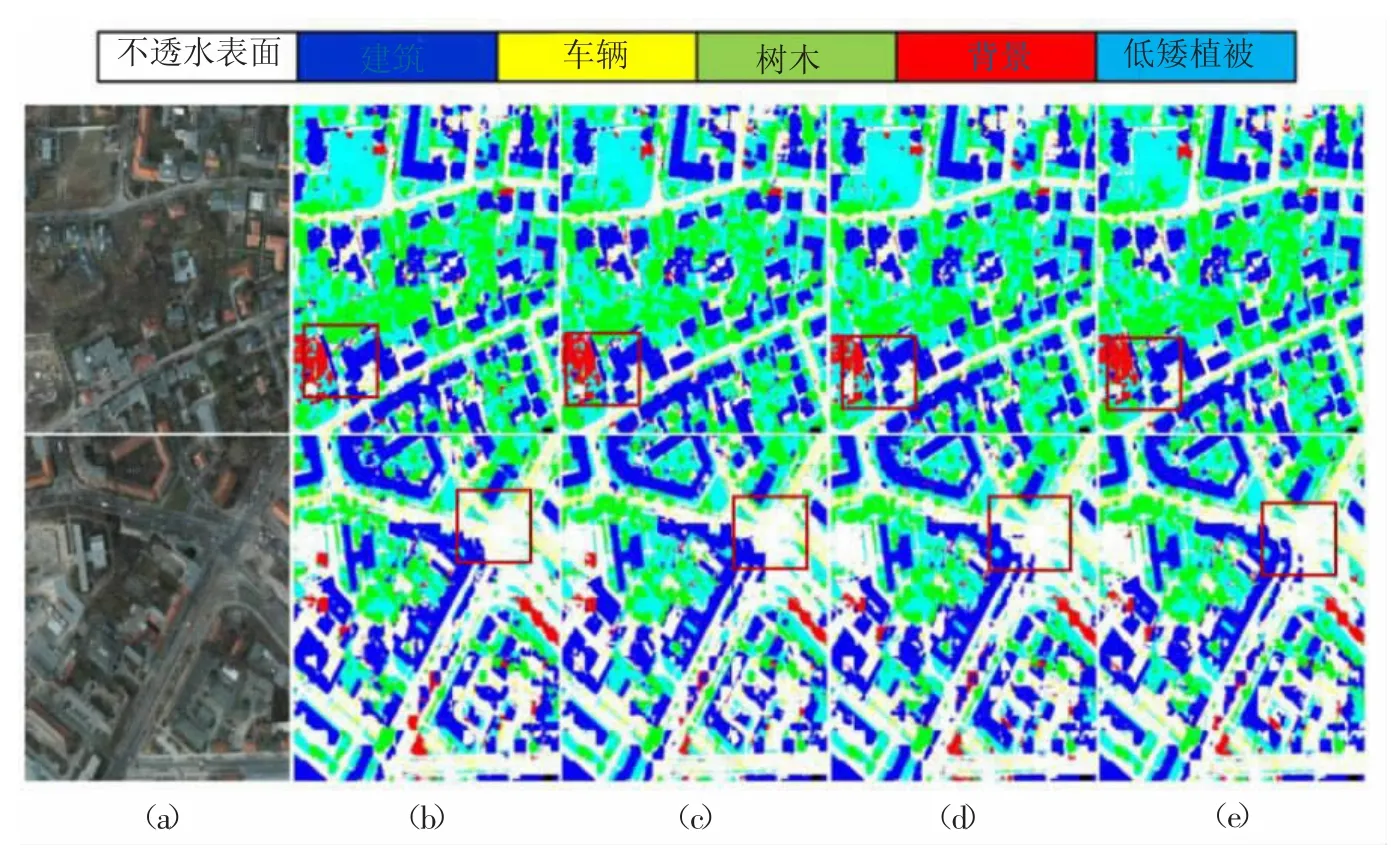
图5 改善前后区域模型在Potsdam 数据集上的可视化分割对比图
图6 中,可以通过改进前后区域模型在Potsdam 数据集上的Loss 值的变化曲线来进行定量分析,结果表明梯度下降更为稳定,改进后的区域模型性能更佳。
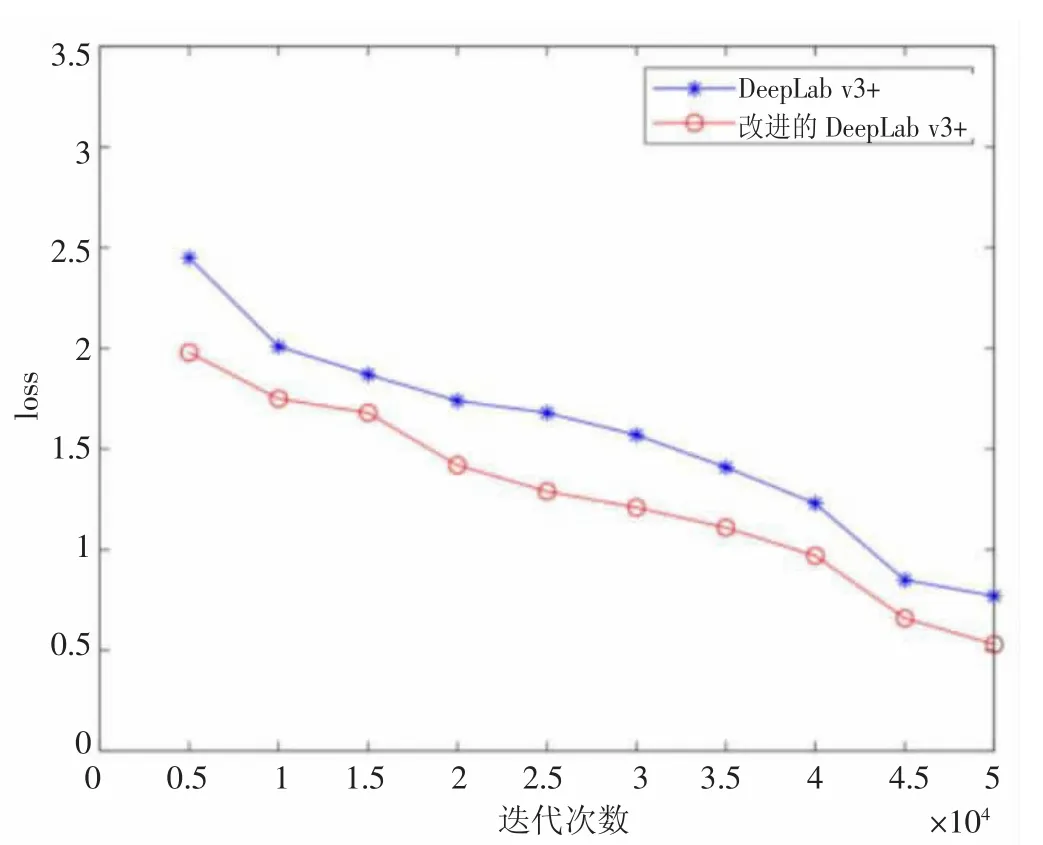
图6 改进前后区域模型在Potsdam 数据集上的Loss 值变化曲线
对比了SegNet、U-Net、DeepLab v3+以及改进后区域模型在Potsdam 数据集上的分割准确度。从应用结果可以看出,本文提出的改进区域模型表现出更高的分割准确度。
通过比较改进前后区域模型在Vaihingen 和Potsdam 数据集上的实验结果,可以得出深度可分离卷积的优越性以及密集连接对于充分利用各特征响应,从而提高网络训练性能的重要性。
5 结束语
本研究通过引入多尺度融合策略、深度可分离卷积和密集连接,显著改进了DeepLab v3+网络的性能,使其在遥感图像语义分割中表现出更高的准确度和鲁棒性。这对于解决遥感图像处理中的复杂任务具有重要意义。我们的研究为遥感图像分割领域的进一步发展提供了有力支持,有望在地图制图、环境监测等应用中产生积极的影响。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
开放教育研究(2020年2期)2020-03-31 01:54:14
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
太空探索(2016年5期)2016-07-12 15:17:55
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
时代英语·高三(2014年5期)2014-08-26 17:01:17
新课程学习·中(2013年3期)2013-06-14 05:55:20
