
用于多目标双层优化的嵌套遗传算法——以混装线规划为例*
2023-12-13 11:25王丽娟彭精立
机电工程技术 2023年11期
张 炜,王丽娟,彭精立
(厦门城市职业学院智能制造学院,福建 厦门 361008)
0 引言
工程实践中的许多重要决策问题往往需要在不同的约束条件下同时处理多个相互冲突的目标。即多目标优化问题(Multi-objective Optimization Problem,MOP)[1-2]。MOP 的目标涉及相同或不同的一组决策变量,这些变量是相互约束的。由于每个目标的工程意义和尺寸不同,导致解决MOP存在一定的难度。
MOP 的目的是在优化目标之间进行权衡。传统的解决方案是将其转化为一个单一的目标问题。常见的方法有加权和法[3]、目标规划法[4]、e约束法等[5]。例如,张波等[6]提出了多规则融合算法,有效地表征了装配工艺和有限资源等刚性约束。通过航空发动机脉动式装配过程实例验证,证明了所提算法在随机扰动、反复迭代和群体计算等方面的优势。易建洋等[7]建立混装线平衡和物料配送联合优化数学模型。提出遗传算法在仿真软件里的应用仿真,并通过实例验证方法研究的有效性。针对订单分配与排序时存在的分配方案不合理、交期久等问题,以最小化最大完成时间和拖期时间为目标函数的订单分配和排序两级目标优化模型,利用基于参考点的快速非支配遗传算法优化求解得到优化方案[8]。针对MOP,没有单一的解决方案可以使所有目标同时达到最优。各类优化方法将不可避免地削弱一些目标。
因此,本文首先分析了多个目标之间的层次关系。将多目标转化为多个单目标函数进行分层优化,使得优化过程更符合实际情况。
MOP 可以通过双层编程来解决。双层规划广泛应用于工程设计[9]、经济管理和资源分配[10-12]。例如,Calvete和Gale[13]研究了上下两级线性分式的双层规划问题,并给出了相应的遗传算法。针对多条异构混装线之间加工能力、作业时间不等效的特征,提出面向柔性定制的并行不等效生产计划模型。提出一种结合Pareto 前沿解的改进遗传算法,采用小生境技术保证种群多样性[14]。Charnes 和Cooper[15]将多目标优化问题转化为两个线性规划问题。通过求解两个线性问题得到了相应分式规划的最优解。不同的算法与双层规划方法相结合促进了多目标优化问题的不断发展。本文以某混装线规划为例说明了双层规划的工程应用。针对该模型提出了一种嵌套遗传算法。
1 混装线平衡和排序
假设M系列产品需要在一个生产计划周期T内生产。每个型号的总产品需求为DM,m∈{1,2,…,m,…,M}。每个产品的每个任务的优先级关系是预定义的。在一定的优化条件下,需要确定所有产品的生产顺序。如果不同产品的总需求的最大公约数是g;最小生产周期单位为dm,可以表示为向量(d1,d2,…,dm,…,dM)。在计划周期时间内,只订购具有最小生产周期单元的产品,并重复g个过程。该规划包含两个问题:平衡和排序。
大多数关于混装线平衡的研究都是基于综合作业优先图,它将多个产品的负载平衡转化为单个产品的装配线平衡问题[16-17]。例如,吴永明等[18]针对产品需求多样化、工艺及设备动态变化,装配线平衡方案需不断调整,提出装配线演进平衡方法,通过改进粒子群优化算法进行优化,所提算法增加粒子的多样性和搜索能力,加快算法的搜索速度。以一个生产实例验证了该方法的有效性和可行性。
对于混装线排序问题,传统的策略是使用遗传算法[19]、蚁群算法[20]等。例如,江新利等[21]研究具备有限缓冲特征的两阶段排序问题,考虑生产系统的发泡设备约束,分别对预装线与发泡线模具排序进行研究,使二者尽量匹配,减少在制品库存数量。
混装线平衡是混装线排序的基础,排序的结果用于评估平衡的好坏。姜东等[22]针对混流装配线平衡排序优化问题,提出了一种多目标模拟退火算法。提出的模拟退火算法在初始化中将启发式任务分配规则融入平衡问题,根据产品投产需求随机生成产品序列;通过测试标准问题实验,对所提出的算法进行参数校验。
2 多目标双层优化模型
平衡与排序的优化设计问题本质上是一个双层规划问题[23]。基于双层规划模型的理论框架,可以建立问题的决策机制。
2.1 上层优化问题
模型的上层需要对产品族的任务分配做出决策,即在满足作业优先顺序的前提下,将产品族任务分配给工作站。评估的基本标准是工作站内部工作负载平衡、工作站之间工作负载平衡和动态平衡的综合利益。
混装线平衡。在混装线中,不同产品的类似任务可能具有不同的操作时间。产品的每个任务也可以有不同的操作时间。因此,当这些任务中的一些被分配给工作站时,工作站的工作负载时间可能达到给定的循环时间。因此,需要考虑每个工作站上不同产品的工作负载的平衡,以及不同工作站之间的工作负载平衡。所提出的工作站内部工作负载平衡和工作站之间工作负载平衡的目标分别用式(1)和式(2)表示。
式中:J1为工作站内部工作负载平衡;J2为工作站之间工作负载平衡;M为产品族混装线上生产的产品种类;m为产品族混装线上生产的第m种产品;i为产品族的第i个任务;S为产品族混装线的站点数量;j、k分别为产品族混装线上的第j、k个站点;Tmj、Tmk为第m种产品分配到j、k工作站的总工作时间;qm为第种产品需求百分比;tim为第m产品第i个任务的作业时间;Qim为加权系数;为分配到j站内的所有任务的加权平均作业时间。
2.2 下层优化问题
混装线排序。由于不同产品的类似任务的操作时间并不总是相同的,当这些任务分配到一个工作站时,不同的排产顺序会导致不同的等待时间。假设混装线上的工作站的工作时间是z工作站中最大的,则其他工作站必须等待工作站完成工作,然后才能整体移动。因此,在每个工作站中,每个工作站的工作时间与该状态下工作站的最大工作时间之间的平衡是需要考虑的目标函数。目标函数设置如式(3)所示。
式中:J3为每个工作站的工作时间与该状态下工作站的最大工作时间之间的平衡;tzk为z状态下k工作站分配到的任务的作业时间;maxtzk为z状态下的所有工作站分配到的任务的作业时间的最大值;d为产品族各产品需求最小比例集之和。
上层目标函数考虑了混装线的平衡和排序问题。本文以工作站内部工作负载平衡、工作站间工作负载平衡和动态平衡之间的最小乘积为上层目标函数,如式(4)所示。
模型的下层是混装线的投产排序决策。排序决定了每个工作站的负荷水平和材料需求的进度,这些都与成本有关。目标函数可以用式(3)来表示。
2.3 双层优化
基于以上对上下层目标需求的分析,可以建立混装线平衡和排序的两级优化模型:
3 嵌套遗传算法
问题的变量可以分为两部分:平衡决策变量和排序决策变量。每组平衡决策变量对应于一组最优排序决策变量。两组变量处于不同的层级。如果使用经典的遗传算法来求解,收敛速度会很慢,并且可能很难收敛到全局最优解。为了克服经典遗传算法的缺点,加快收敛速度,将染色体分为两段,分层次进行嵌套搜索。
3.1 平衡遗传算子设计
平衡遗传算子的设计主要包含以下4步。
(1)为了解决每个工作站中每个产品的任务分配,即求解变量Xijm以实现混装线平衡,本文采用了基于操作序列的表达式,并使用浮点编码方法。对于给定的产品m,任务i被分配给工作站j。所有任务形成一个任务序列,完成任务序列的工作站数量就是解决的问题代码,如图1所示。

图1 编码和解码
(2)初始化种群,即生成一系列符合条件的个体。由于混装线上同时生产m种不同的产品,因此需要将每种产品的所有操作任务分别分配到所有工作站。
(3)在选择操作中,使用最优保存策略和轮盘赌。最优保存策略将几个具有高度适应性的个体直接复制到下一代,而其他个体则使用轮盘选择。在轮盘赌方法中,每个个体进入下一代的概率等于其适应度值与该个体在整个种群中的适应度值之和的比率。本文使用目标函数F(Y,X)的倒数作为适应度函数。
(4)交叉和变异如图2 所示。采用两点交叉法,从选择操作产生的个体中选择两条染色体(如图2(a)所示),并在染色体上任意确定两个交叉点。两条染色体在交叉处被分成3 部分。父代1 染色体的中间染色体(3,6,2)按父代2 染色体(2,6,3)的顺序排列,形成新的子代1。类似地,父代2染色体的中间基因(7,4,6)按照父代1 染色体(4,6,7)的顺序排列,形成新的子代2。为了避免过早收敛和陷入局部最优,在满足优先级约束关系的前提下,采用了交叉变异方法。从种群中任意选择个体的任何染色体(任务)进行变异,在交换之后,它不会违反任务之间的关系(图2(b))。

图2 交叉和变异
3.2 排序遗传算子设计
排序遗传算子设计如下。
(1)在最小生产周期单元中,生产序列的编码采用浮点编码方式,如图3所示。

图3 排序的编码
(2)在种群初始化过程中,随机产生了一个具有个体数量P的排序种群。目标函数是适应度函数J3。本文仍然使用轮盘赌来选择和留住最优秀的个体。
(3)至于交叉,使用基于切割点随机交叉的方法从随机生成的排序群体中随机选择两个父代个体。选择一个染色体位置作为这两个个体的切割点,并将它们切割成前一部分和后一部分,如图4(a)所示。从父代2 中逐个搜索满足父代1 后端序列的染色体,并将其作为子代1 的后端。父代2 的剩余染色体被保留为子代1的早期染色体。

图4 排序群体的交叉和变异
关于突变,本文使用反转突变方法(图4(b)),在父代染色体上随机产生两个突变点,并反转中间部分的基因序列,以获得新一代染色体。
3.3 用于双层规划的嵌套遗传算法
针对上述双层优化解的直接求解方法,提出了一种嵌套遗传算法用以生成X和Y。该算法分为上层和下层,分别设计用于平衡和排序。具体流程如图5所示。

图5 嵌套遗传算法流程
步骤1:初始化种群,并根据上层变量大小随机生成种群个数N。
步骤2:确定种群是否满足上层约束条件,如果是,则将参数代入下层;如果没有,则将适应度设置为零,转移到步骤3。
步骤3:确定是否达到最大迭代次数,如果达到,记录最佳值,然后进入步骤4;如果没有,则进入排序、选择、交叉和突变的过程,然后转入步骤2;将上层可行个体引入下层,并初始化下层群体Y(X)。
步骤4:验证基础种群的可行性,如果可行,进行适应性评估;如果不可行,请将适应度设置为0。
步骤5:确定较低层次的种群是否达到最大迭代次数,如果达到,则记录最低个体和最优值;如果没有,则返回步骤4并重复,直到达到最大迭代次数。
步骤6:将下层的最优个体和最优值J3转移到上层,评估适合度值。
步骤7:确定种群是否达到了最大迭代次数,如果达到,则记录最优解和最优值;如果没有,则重复步骤3,直到达到最大迭代次数。
4 应用分析
以某客车焊接车间混焊接生产线生产的一系列A、B、C型客车为研究对象,客车产品族的综合作业优先图如图6所示。在生产计划周期内,3种产品的计划产量分别为DA=8、DB=12、DC=8。因此,在最小生产周期内,每种产品的需求分别为dA=DA/4=2,dB=DA/4=3,dC=DA/4=2。每个产品的任务时间如表1所示。
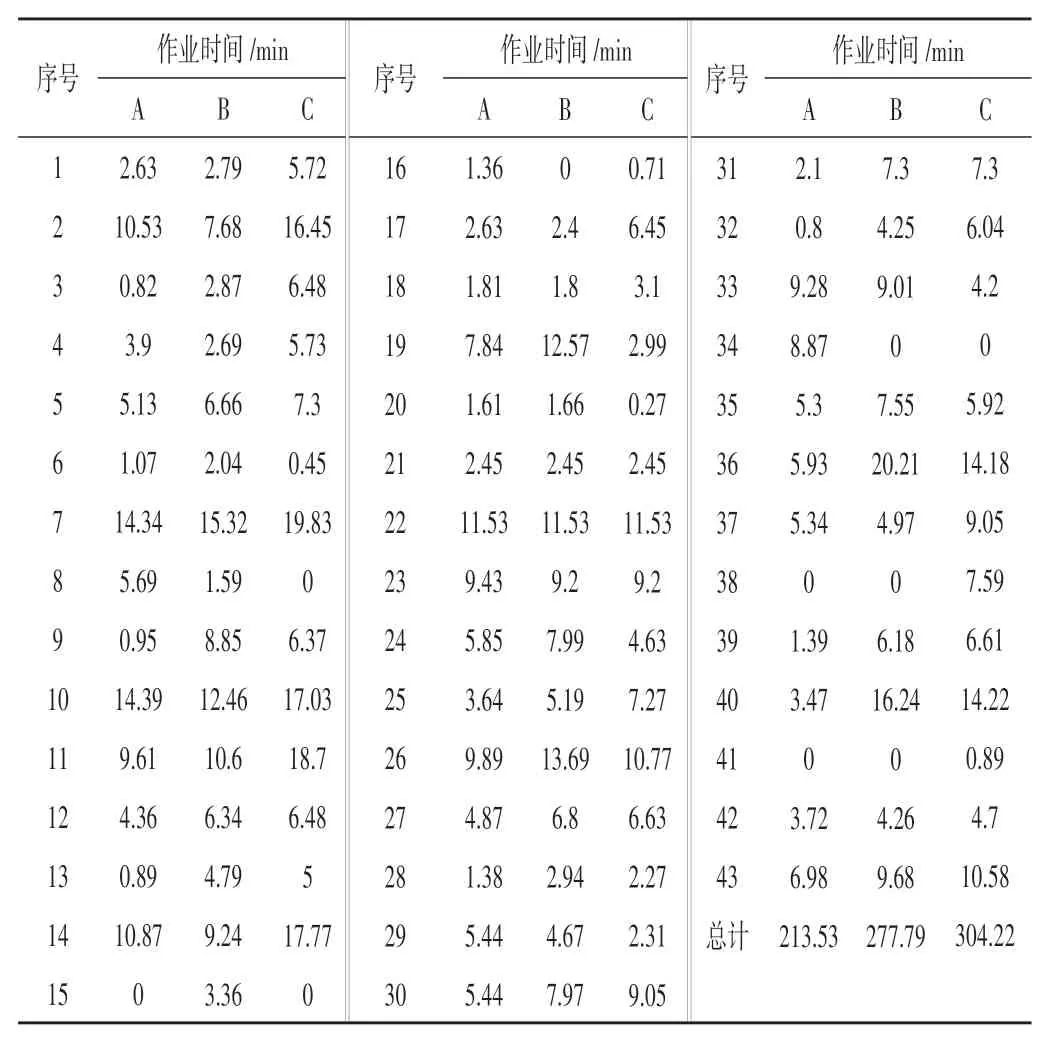
表1 产品族工序作业时间

图6 装配作业优先图
为了证明嵌套遗传算法的有效性,选择了传统的遗传算法和粒子群算法来解决上述问题。传统的遗传算法使用顺序优化方法来解决这个问题。首先,求解平衡的最优值。其次,在平衡的基础上,求解排序的最优值。另外,使用粒子群算法的“归一化”方法同时求解了J1J2J3。与嵌套遗传算法不同,在求解过程中没有交互过程,即平衡方案只对应于一个排序情况。
各种方法的混装线规划优化结果如表2 所示。从表中可以看出,除了目标函数J2之外,本文所提方法在每个指标上都优于其他算法。尽管顺序优化的求解方法在求解平衡时获得了更好的结果。然而,在排序问题的优化过程中,由于解域的限制,只能得到次优解。对于“归一化”的并行解决方案,即同时解决平衡和排序问题,这将导致优化结果的随机性。一般来说,嵌套遗传算法那的整体优化效果可以比其他3 种方法获得更好的结果。

表2 各算法优化结果对比
5 结束语
工程多目标优化问题属于NP难题,很难找到全局最优解。针对一般的多目标决策问题,本文分析总结了两级决策方法和归一化方法求解过程存在的缺陷,提出了一种嵌套遗传算法。将该方法和算法应用于混装线的平衡和排序。通过分别对装配任务和产品进行编码,使用嵌套遗传算法对平衡和排序进行优化。
以一个混合模型焊装生产线的平衡和排序问题为例,将所提算法和传统归一化方法、顺序优化方法进行对比,对比的结果表明,该算法可以获得令人满意的结果。多目标优化仍然是一个NP难题。如何找到一个更客观、更现实的优化目标,如何对其进行更合理的评估,并提出更有效的算法,还有待进一步探索。
猜你喜欢
大学教育科学(2022年6期)2022-12-06
——基于人力资本传递机制
贵州财经大学学报(2022年5期)2022-11-16
今日农业(2022年16期)2022-11-09
系统工程学报(2021年4期)2021-12-21
电脑报(2020年32期)2020-09-06
东北财经大学学报(2017年6期)2017-12-15
——基于子女数量基本确定的情形
中南财经政法大学学报(2017年1期)2017-02-08
计算机工程(2014年6期)2014-02-28
机电信息(2014年23期)2014-02-27
河南科技(2014年23期)2014-02-27
