
基于Swin Transformer的知识蒸馏模型在垃圾分类上的应用
2023-12-07 12:11杜峰付天生
电脑知识与技术 2023年30期
杜峰,付天生
(福建理工大学,福建 福州 350118)
0 引言
随着经济发展,中国的城市化进程也在提速,在城市化的过程中,环境恶化问题需要提前防范,其中城镇生活垃圾泛滥成灾则是当中比较严峻的环境问题之一。目前垃圾处理的主要方法是填埋和焚烧。对于垃圾填埋处理,若没有经过提前分类流程,不仅浪费更多的土地资源,而且会使得处理费用大增,更糟糕的是塑料垃圾、有害金属垃圾进行填埋处理不仅长期难以降解,还会污染土地,使大量土地无法耕种,另外,填埋的有害垃圾还会污染地下水资源,给整个社会带来健康隐患。对于焚烧处理方法,如果有害垃圾不进行分类处理,则会增加大量的碳排量和废气,同时伴随严重的空气污染,对垃圾进行分类处理是解决城市化环境问题的必要手段,对城市垃圾分类回收将是未来的发展趋势。
近几年,我国部分城市把生活垃圾必须进行分类作为规定,并且国家也开始从试点城市向周边更多城市推广垃圾分类做法。垃圾分类的规定自推行以来,效果不佳。究其原因,问题主要出在生活垃圾分类操作中的实际人工成本较大,并且即使居民愿意投入时间精力,依旧有许多人不能准确地区分各种生活垃圾的类别,生活垃圾的实际分类准确率不太理想。
在科技的发展过程中,人工智能技术突飞猛进,使用计算机技术解决社会生产过程中遇到的实际问题做法越来越得到各界的重视。比如,计算机视觉相关技术在许多领域如人脸识别[1]、车辆检测[2]、智慧医疗[3]等许多行业都取得了不可忽视的成绩,因此在垃圾分类问题上使用计算机视觉方法将是一个值得考虑和选择的方案。将计算机视觉方法运用到生活中的垃圾分类问题上,将大大改善当前的垃圾分类人工成本过高和人工分类准确率有限的问题。
计算机视觉的发展可以分为基于统计学和基于深度学习两个阶段。早期基于统计学的计算机视觉主要研究图像分类问题。传统图像分类算法[4]一般包含特征提取、特征构造、分类器设计3个阶段。这种传统算法是基于简单统计学特征对图像数据进行提取,使用统计学方法进行降维压缩等特征处理操作,再使用经典的统计分类模型作为相应的分类器进行图像分类判断。这类基于统计学的算法要求投入大量的人工成本进行特征提取,并且最终的模型稳定性较差。随着人工智能研究的深入和计算机运算性能的发展,基于深度学习的计算机视觉算法也得到了长足进步。基于深度学习的图像分类方法通常是使用算法对图像自动提取特征,并在同一个算法框架中使用提取的特征对图像进行分类,得到完全从训练数据中学习图像的层级结构性特征。其中最具代表性的是卷积神经网络[5](Convolution Neural Network,CNN) ,相较早期的基于统计学方法的算法,卷积神经网络更擅长在图像中提取关键特征,这种特征提取操作是自动提取的,并且因为没有引入人为因素偏差模型也有更强的稳定性。在CNN模型中,越深层的网络通常包含越抽象的高级特征,越深层的网络越能表现图像主题语义,从而获得更强大的识别能力。
在2012年,Hinton提出了基于CNN结构的AlexNet[6]深度模型,并以15.4%的低失误率成为当年 ILSVRC算法比赛的冠军。AlexNet的成功则论证了基于CNN 的深度学习网络在图像分类的有效性。在此之后,不断有学者对深度学习结构进行创新,包括随后发展起来的VGG[7]、GoogleNet[8]、ResNet[9]、DenseNet[10]等深度学习网络也在图像分类上取得了优秀的成绩。基于大量的深度学习算法,计算机视觉方法在人脸识别、智慧医疗等领域得到了广泛的应用,并取得了良好的效果,然而,随着应用处理的图像质量和尺寸的不断提升,基于CNN结构的深度学习的网络需要堆叠大量的层数才能较好地感知图像的整体特征,然而大量层数堆叠也给基于CNN的深度学习网络带来了参数过多、预测性能下降、运算时间过长等问题。
基于此缺点,学者提出了基于transformer 的图像分类方法ViT[11](Vision Transformer) ,此方法只需少数几层就可以获得需要大量堆叠层数的CNN 全局的感受野。基于Transformer 的网络结构拥有较好的并行运算性质,此类结构可以更好地利用GPU、TPU 之类的硬件进行加速运算。然而基于Transformer 的网络结构的self-attention计算机制会导致较大的计算资源和存储资源占用问题,因此原始的ViT 模型无法很好地应用在大图像处理问题上。有学者则针对ViT的不足进行改进,提出了Swin Transformer[12]模型。此模型利用了移动窗口的原理大大降低了self-attention计算开销,能较好地处理高质量大尺寸图像,此模型一经提出,就受到了学术界和工业界的广泛欢迎。为了探究深度学习在高质量大尺寸图像处理上的应用,本文将预训练Swin Transformer模型用于垃圾分类问题中,使用实际垃圾图像数据对模型进行迁移学习训练。为了进一步提升模型的实际部署应用性能,本文在训练好的基础Swin Transformer 模型上使用知识蒸馏方法Knowledge Distillation[13]对模型进行压缩,进一步减小模型的体积,加快模型的计算效率,提高了模型的实用性。
1 算法介绍
1.1 ResNet模型
图像处理中的CNN 结构主要就是通过一个个由卷积核组成的filter,不断地在图像上提取特征,随着层数的堆叠可以获得从局部特征到总体的特征,从而实现图像识别等功能。卷积神经网络CNN 通常包括独有的卷积层和池化层以及全连接层的输入和输出层,相对全连接层,卷积层具有参数量更少的特性。卷积神经网络在图像识别、语义分割、图像分类、图像检索等领域都有较为成功的应用,这主要得益于其自动提取图像特征、自动更新、共享权值的特性。CNN网络的底层提取的特征主要包括通用的色彩、纹理特征提取,以及一些图像数据都有的共性特征。在深度CNN 模型中,随着层数的堆叠,模型特征的表达能力越来越强,这使得越顶层则越能适应特定任务。AlexNet 是深度CNN 的开山之作,后续学者提出了VGG 模型,然而随着模型深度的增加,模型会出现性能退化的问题,即增加模型的层数换来的是更差的性能表现。从实证角度看,神经网络的深度和层数对模型的性能异常重要。随着网络深度的加深,更加复杂的特征模式可以被模型提取出来。因此,理论上随着模型深度增加模型可以取得更好的性能。然而,许多实验却又表明深度网络存在退化问题(Degradation problem) ,即随着网络深度增加,模型性能出现饱和或者下降。针对深度网络性能退化问题,学者在AlexNet 的基础上提出了深度残差网络(Deep residual network, ResNet) 。
ResNet 的架构借鉴了VGG 网络架构,是在VGG基础上进行了改进,并设计了短路机制,加入了残差模块,如图1所示。从图1可以看到,ResNet模型相比以往的网络,每两个相邻层间加入了短路机制,从而形成了残差学习。实验结果表明,这种短路机制可以很好地解决深度网络中的退化问题。相较于VGG 网络,ResNet在结构上的区别主要为ResNet直接使用了步长大于1的卷积操作,这种操作能起到特征压缩的作用,另外还使用了global-average-pooling 层代替全连接层。ResNet 的一个重要设计原则是:当feature map大小缩小为原来的1/2时,feature map的通道数增加一倍,这保持了模型的特征表达能力。
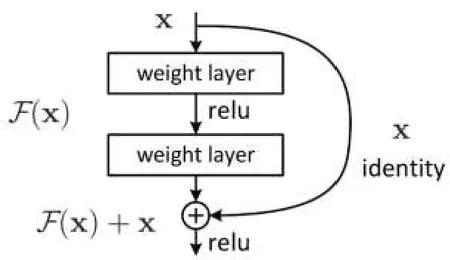
图1 残差网络模块
1.2 Vision Transformer模型
自深度学习大为流行以来,CNN一直是计算机视觉领域的主流模型,而且取得了很好的效果,与此同时, Transformer 结构则在NLP 取得了突破性的进展,并且基于Transformer 结构的GPT 和Bert 的大语言类模型在工业界得到了广泛应用。近年来,越来越多的学者不断研究如何在NLP 之外领域复制Transformer在NLP 上的成功。在2020 年,Google 提出了ViT[11](Vision Transformer) , 直接将Transformer 应用在图像分类问题上。
ViT 模型先把图像分成固定大小的patchs,类似于NLP 的词嵌入向量化做法,ViT 通过线性变换对每个图像patchs进行patch-embedding向量编码。接着,将图像的patch-embedding送入Transformer Enconding模块中进行特征提取。最后,连接全连接层作为分类器进行图像分类,具体的ViT模型原理如图2所示。
继ViT 之后,基于Transformer 结构的模型开始在CV 领域大放异彩,其中包括应用于图像分类的Swin Transformer,目标检测的DETR,语义分割的SETR 等模型。
在计算机视觉问题上, Transformer 结构的核心Self-Attention 计算机制的优势是可以获得图像序列的long-range 信息而不是像CNN 结构要通过不断堆积层数来获取更大的感受野。更好的long-range特征提取意味着在高质量大尺寸图像问题上能获得更好的表现,然而ViT 的Self-Attention 计算机制也带来了计算开销过大的问题,模型还需要进一步被完善。
1.3 Swin Transformer模型
基于Transformer 结构的ViT 模型主要存在不同场景的大尺寸图像表现不稳定和高质量大尺寸图像的全局自注意力机制的计算导致计算开销较大两大问题。针对这两个问题,Liu[12]提出了一种滑窗操作的层级架构模型Swin Transformer。传统的Transformer都是基于全局来计算Self-Attention的,因此,随着图片尺寸的增大,注意力的计算复杂度将十分高。而Swin Transformer则将注意力的计算限制在每个窗口内(Window Attention) ,进而减少了计算量。Swin Transformer中滑动窗口包括不重叠的Local-Window,和重叠的 Cross-Window。将自注意力计算限制在一个窗口中,一方面能引入类似CNN网络的局部性,另一方面能大大减小计算开销。图3 左侧是Swin Transformer 模型的Window-Attention 示意图,右侧是VIT 模型的全局Self-Attention示意图。
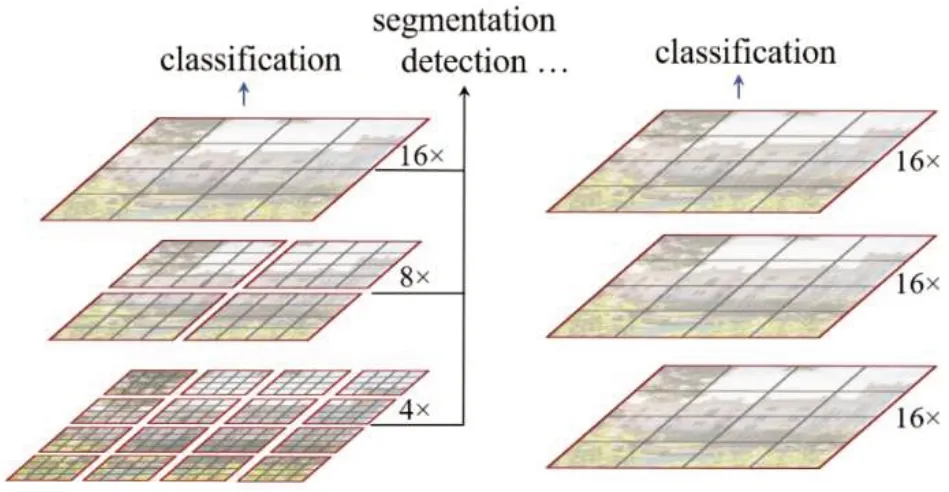
图3 两种注意力机制的对比
Window-Attention是在每个窗口内分别计算注意力,但是为了更好地和其他Window进行信息交互,扩大模型感受野,Swin Transformer 还引入了Shifted-Window操作,具体操作如图4所示。
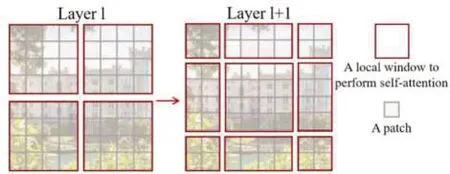
图4 Shifted-Window操作
图4左边是没有重叠的Window-Attention,而右边则是将窗口进行移位的Shift-Window-Attention。可以看到移位后的窗口包含了原本相邻窗口的元素,即两层之间的不同窗口可以交换特征信息,其中Encoder 的倒数第一层使用的是全局注意力机制,经过计算全局注意力后,模型可以获得图像整体的特征,模型最后一层则接入全连接层作为分类器进行图像分类。
其中,本文使用的基础Swin Transformer模型架构图如图5所示,模型可分为4个阶段,每个阶段又包含若干个Swin Transformer 模块,每个模块都进行Shift-Window-Attention 计算。在最后一个模块中,图形特征的维度缩小为原来的1/32,通道数扩大为原来的8倍。
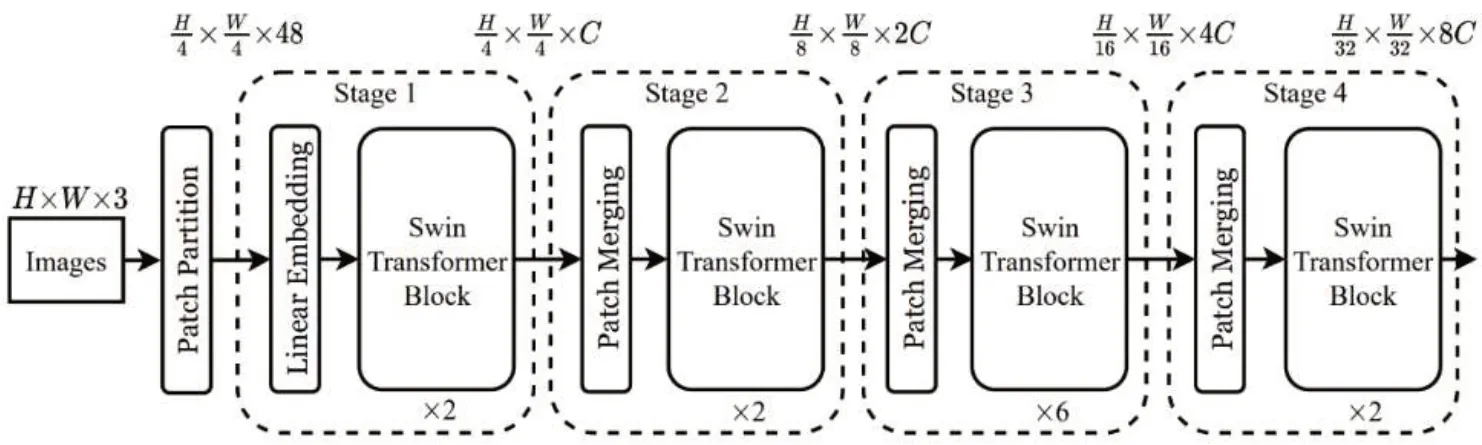
图5 Swin Transformer模型架构
1.4 知识蒸馏
在深度模型流行的当下,大模型虽然具有更强的性能,但是也要求计算机具有较高的计算性能。然而在实际应用中,客户端的计算性能有限,通常无法承载大模型的推理过程,一般的做法是对训练好的大模型进行压缩,以减少其对设备性能的要求。
其中,知识蒸馏Knowledge Distillation[13](KD) ,是一种表现优越的模型压缩方法,主要基于“教师-学生”的训练方法。并且因为其简单有效,无论在学术界还是工业界都受到了广泛应用。从字面意义上理解,知识蒸馏就是要将知识(Knowledge)从已经训练好的大模型中提取出来,并压缩蒸馏(Distill)到学生小模型中,知识蒸馏训练方法的流程图如图6所示。
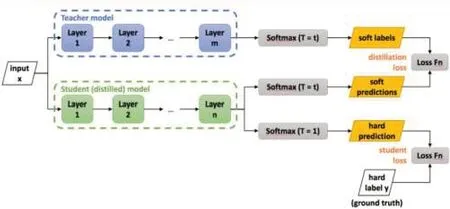
图6 知识蒸馏示意图
在知识蒸馏中,由于已经有了一个泛化能力较强的教师网络Teacher model,使用Teacher model 来蒸馏训练学生网络Student model 时,可以直接让Student model去学习Teacher model的泛化能力。一个直接且高效的泛化能力迁移的方法就是使用Softmax 层输出的类别概率来作为Soft-Target。
相较于真实标签只有正例信息的Hard-Target,模型的Softmax 层的输出同时包含了正例和负标签。而负标签带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(Hard-Target)中,所有负标签都被统一对待,信息是不完整的,也就是说,KD 的训练方式使得每个样本给Student model带来的信息量大于传统的训练方式。
2 实验和结果分析
2.1 实验数据
本文使用的数据来源于华为云垃圾分类图像公开数据集,其中数据包含可回收物、厨余垃圾、有害垃圾和其他垃圾4大分类,每大类别又有细分类别,共有40 个细分垃圾类别,一共有14 402 张带标签的图片。本文实验按4:1 的数据比例划分为训练集和测试集,即11 522 张图像作为训练数据,2 880 张图像作为测试集数据。
2.2 图像数据处理
原始数据中每个图像的大小并不统一,本实验对所有图片进行重采样操作调整每张图片的尺寸为224×224。另外,为了增加模型的稳健性,本实验和其他主流计算机视觉模型训练流程一样,使用了剪裁、翻转、缩放、融合等数据增强操作。
2.3 实验环境
本文的实验硬件环境为:Intel Xeon 12 核CPU,GPU 为NVIDIA A100,内存大小为32GB。其中软件环境为Python-3.7,深度学习框架为百度的 Paddle-Paddle-2.4.0,GPU加速驱动为cuDNN-8.2。
2.4 图像数据处理
2.5 实验结果及分析
本实验的主要研究模型是基础Swin Transformer模型(swin_base) ,并且实验还选取了4 个主流计算机视觉模型进行性能对比,对比模型包括GoogLeNet、ResNet50、ResNet101、VGG11。为了保持可比性,各个模型的训练参数设置和Swin Transformer 模型的训练参数设置保持一致,具体取值如表1所示。另外,在实验的最后还加入知识蒸馏训练学习对swin_base 模型进行压缩,最终得到压缩后的模型swin_distill。图7~图10展示了不同模型的训练收敛情况以及模型在测试集上的性能表现。
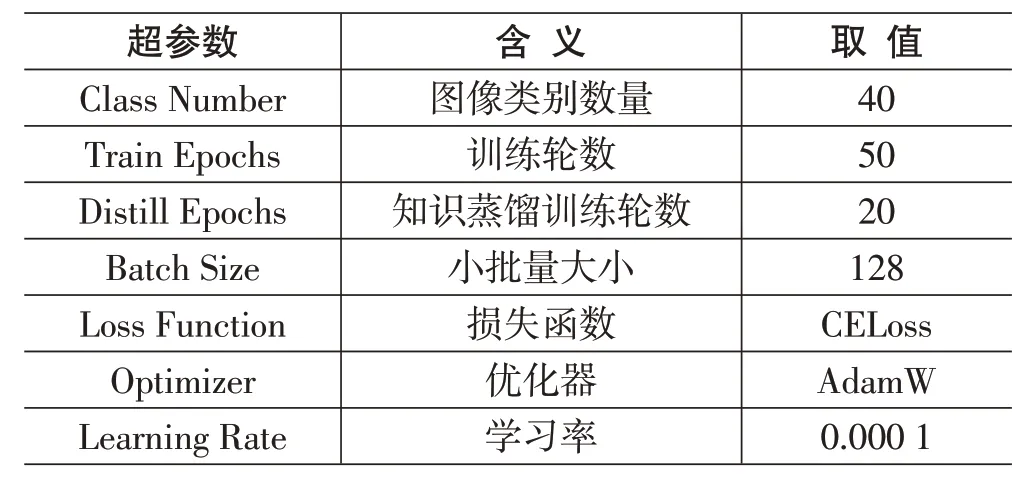
表1 实验的超参数说明
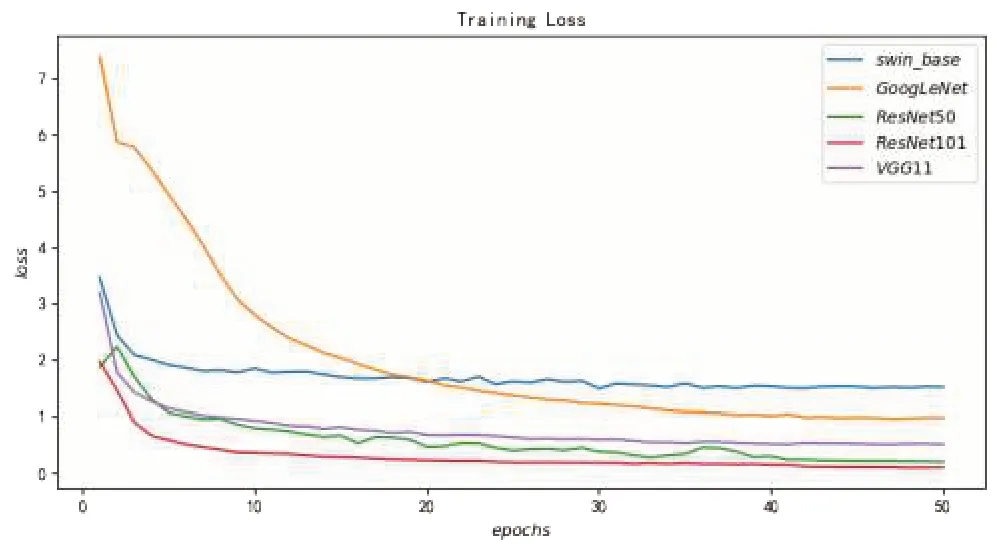
图7 各个模型的训练误差收敛情况
从图7看到,经过50 个轮次的迭代训练,所有模型的训练损失都收敛到了一个较低的水平,说明所有模型都得到了充分的训练,并都达到了各自的最优水平。
图8则从侧面进一步说明,经过50个轮次的迭代训练,所有模型都得到了充分的训练,并能在测试集上表现出最优水平。
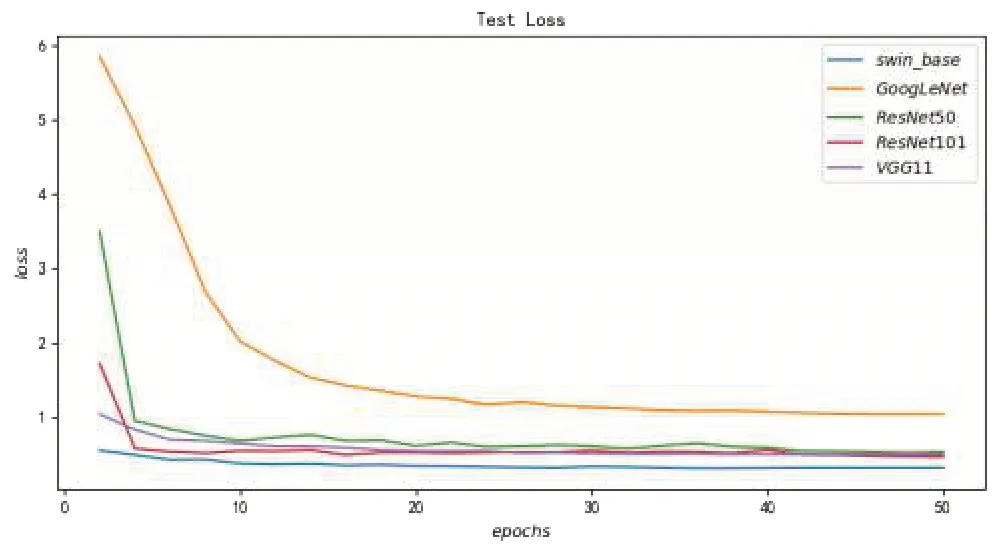
图8 各个模型在测试集的损失表现
从图9可以看出,swin_base模型在测试集数据的准确率最高,表现最好,并且和其他模型保持了较大的优势差,说明实验中的swin_base 模型的性能最好,这验证了基于Transformer 结构的深度学习模型更擅长处理高质量大尺寸的图像数据。
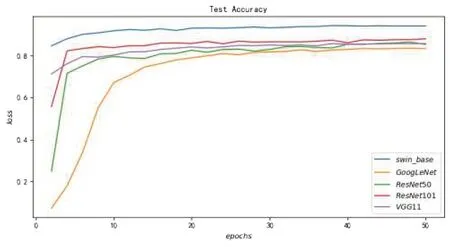
图9 各个模型在测试集的准确率表现
从图10 可以看出,学生模型swin_distill 只经过20个训练轮次就收敛在较高的准确率,说明知识蒸馏训练方法引入了信息含量更丰富的Soft-Target 可以大大减少学生模型训练过程的训练次数。知识蒸馏训练方法不仅能训练出高性能的学生模型,还能大量地减少训练开销。
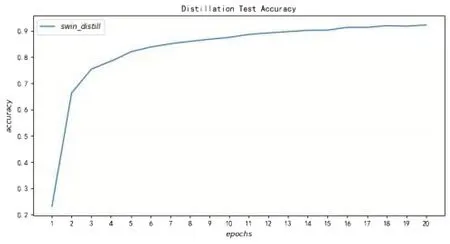
图10 知识蒸馏学生模型在测试集的准确率表现
表2 是各模型性能表现和模型大小的横向比较。从表2 可以看到,swin_base 模型的准确率为0.944,表现最优,而基于CNN结构的4个深度学习模型准确率都没有超过0.88,和swin_base 模型存在较大的落差。在模型大小上,swin_base 模型相比基于CNN 结构的模型并没有优势,但是经过知识蒸馏训练压缩后的swin_distill 模型在体积上相较swin_base 模型则存在巨大的改进,模型压缩后参数量把基础模型缩小为原来的1/3,并且依旧保持了较高的准确率。因为swin_distill 模型体积相对较小并且准确率相对较高,所以swin_distill 模型更适合在垃圾图像分类实际应用中进行部署。
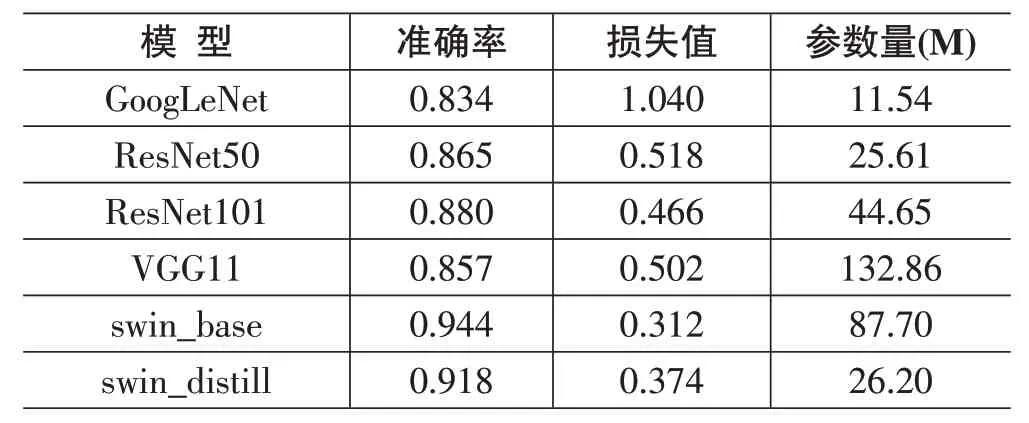
表2 各模型性能表现和模型大小
3 结论
本文以垃圾图像分类问题作为研究导向,使用实际数据对多个深度学习模型进行了比较分析。可以发现,包含着更丰富的信息大尺寸垃圾图像在图像分类模型上确实表现更优。主流的基于CNN 的深度学习模型虽然在小尺寸图像上表现不错,但是难以从大尺寸图片中提取长序列特征。
最终经过实验检验,本文设计的基于Swin Transformer模型的算法框架不仅很好地解决了长序列特征提取问题,还通过知识蒸馏方法解决了大模型在实际应用中体积过大难以部署的问题。本文的基础Swin Transformer 模型准确率达到94.4%,大大优于基于CNN结构的模型,说明基于Transformer结构的深度学习模型在处理大尺寸图像上具有较大的优势。而针对实际应用的知识蒸馏方法可以大大减小模型的体积并且保持较高的预测性能。最终实验结果表明本文设计的基于Transformer 架构的Swin Transformer 的模型能较好地应用在大尺寸图像分类问题中,并且基于Swin Transformer 的知识蒸馏模型能很好地在垃圾分类问题上得到应用,从而助力国家的环境治理进程。
猜你喜欢
科普童话·学霸日记(2021年2期)2021-09-05
数学小灵通(1-2年级)(2021年4期)2021-06-09
医学食疗与健康(2021年27期)2021-05-13
当代陕西(2019年24期)2020-01-18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
小太阳画报(2018年10期)2018-05-14
作文周刊·小学一年级版(2016年36期)2017-03-03
