
基于LightGBM 算法的页岩气储层甜点参数预测方法
2023-12-06 07:49:20闫建平钟光海丁明海罗光东
中国煤炭地质 2023年10期
肖 晓,闫建平,3*,郭 伟,钟光海,丁明海,罗光东
(1.西南石油大学计算机科学学院,四川成都 610500;2.西南石油大学地球科学与技术学院,四川成都 610500;3.天然气地质四川省重点实验室(西南石油大学),四川成都 610500;4.中国石油勘探开发研究院,北京 100083;5.中国石油西南油气田公司页岩气研究院,四川成都 610500;6.中国石油大庆油田公司钻探工程公司,黑龙江大庆 163712)
0 引言
页岩气具有典型的自生自储、原位饱和成藏的特征,赋存方式主要以吸附气和游离气为主[1]。页岩含有一定量的有机质,页岩气储层多属特低渗-超低渗致密储层,发育微米-纳米级孔隙[2]。孔隙度反映了天然气储集空间的多少,总有机碳含量(TOC)是评价页岩气储层生烃能力的重要指标[3],含气量是页岩气资源量预测和有利区优选的关键参数[4-6],含气量又主要分为吸附气量与游离气量[7-9],而吸附气量与游离气量的比例也关系到页岩气的开发方式。因而准确计算孔隙度(POR)、总有机碳含量(TOC)和含气量对页岩气勘探开发具有十分重要的意义。目前,国内外学者利用测井曲线数据计算页岩气储层甜点参数,主要采用了多元回归法、经验公式法等[10-14]。但由于页岩气储层矿物组分、物性、含气量、有机质含量及有机质成熟度等都具有较强的非均质性,孔隙度、有机碳含量和含气量等甜点参数也受构造作用、埋深等多种地质因素的影响,最终导致测井曲线与储层甜点参数之间不具备较好的线性关系,即往往是复杂的非线性关系。因而,利用多元回归方法和经验公式法往往计算精度不尽如意,或仅对特定地区或层位的应用效果较好,推广性较差。
1 方法与原理
LightGBM 是由微软公司在2017 年提出的一种基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的快速机器学习算法[23],原理与GBDT类似[24],是将当前决策树残差的近似值替换为损失函数负方向,依次来拟合新的决策树,每一次迭代都是在原来模型不变的基础上,通过新增一个函数到模型中,使预测值不断逼近真实值。由于LightGBM算法采用了选择最优分裂点的直方图算法、基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)和带有深度限制的按叶生长(Leaf-wise)策略,因此其可以兼顾分类和回归任务,且在不失模型准确率的同时,极大改善模型的训练速度和内存的占用。
(1)直方图算法
当使用梯度提升算法训练决策树时,需要在每个节点上选择最优的特征和分裂点来拆分数据。最常用的方法是遍历每个特征的每个可能的分裂点,计算每个分裂点的增益,然后选择增益最大的特征和分裂点。为了解决这个问题,LightGBM 使用了一种称为“直方图”的算法来加速特征选择过程(图1)。直方图算法的基本思想是将每个连续的特征值划分为一个有限数量的离散区间,每个区间被称为一个“直方图箱”(histogram bin)。
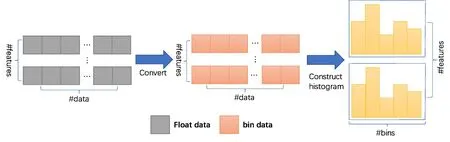
图1 LightGBM 中的直方图算法Figure 1 Histogram algorithm in LightGBM
在构建直方图时,LightGBM 首先计算每个箱子内的样本数量,然后计算每个箱子内的样本的一阶梯度和二阶梯度的统计信息,即平均一阶梯度、平均二阶梯度、梯度平方和、二阶梯度平方和。这些统计信息可以有效地近似每个箱子内的样本分布。由于LightGBM 使用梯度提升算法训练模型,它只需要计算样本的一阶和二阶导数,即梯度和二阶梯度,而不需要计算高阶导数。这使得统计信息的计算非常高效。在使用直方图算法构建决策树时,LightGBM 会遍历每个特征的每个箱子,并计算选择该箱子作为分裂点的增益[25]。选择最优分裂点的过程是基于两个原则:增益最大化和最小数据遍历。LightGBM 使用一种称为“ 近似贪心”(approximate greedy)的算法,从每个特征的候选集中选择最优的分裂点。使用直方图算法,LightGBM可以显著加速决策树的训练过程,同时保持高精度的模型质量。
(2)基于梯度的单边采样(GOSS)
GOSS是LightGBM 中一种用于加速梯度提升决策树训练过程的样本采样算法,且通过样本权重上的优化,可以实现不降低模型精度的情况下,显著减少训练时间。
GOSS 算法将数据集分为两个部分:一个高梯度样本集和一个低梯度样本集。GOSS 保留高梯度样本集中所有的样本权重,并使用一些规则来选择低梯度样本集中的一部分样本,并减少其权重。GOSS分为两个阶段[20]。
第一阶段,计算每个样本的梯度,并将样本按梯度大小降序排列,得到梯度从大到小的样本序列。
在第三个学习阶段当中,学生可以学习解决人类反复劳动的程序编程,通过设计一个重复的机器人动作从而减轻人们的劳动负担,比如可以设计机器人去进行迷宫试验,设计机器人前进的方向和距离,减轻人工的投入。
第二阶段,从梯度较小的样本中选择一部分样本进行采样,删除一些样本或减少其权重,以便使梯度较小的样本占整个数据集的比例尽可能小,同时保留重要的梯度较小的样本。
具体地说,GOSS算法会将梯度较小的样本分为多个组,每个组的大小取决于每个样本的梯度大小和一个超参数,该超参数控制了保留梯度较小的样本的比例。对于每个组,GOSS会计算一个重要性分数,用于指示该组中样本的贡献大小。GOSS会选择重要性分数高的组,并保留组中所有样本的权重。对于重要性分数低的组,GOSS会根据梯度值的大小选择一定比例的样本进行保留。通过这种方式,GOSS可以保留重要的梯度较小的样本,同时减少对模型贡献相对较小的样本,从而加速模型训练。
(3)带有深度限制的按叶子生长(Leaf-wise)策略
按层生长(Level-wise)和按叶子生长(Leafwise)是两种常用的决策树生长策略(图2)。它们的主要区别在于决策树的分裂方式和生长顺序。按层生长策略会按照从上到下、从左到右的顺序逐层分裂,每一层都会同时处理完所有节点。这种方式通常可以保证生成相对平衡的决策树。
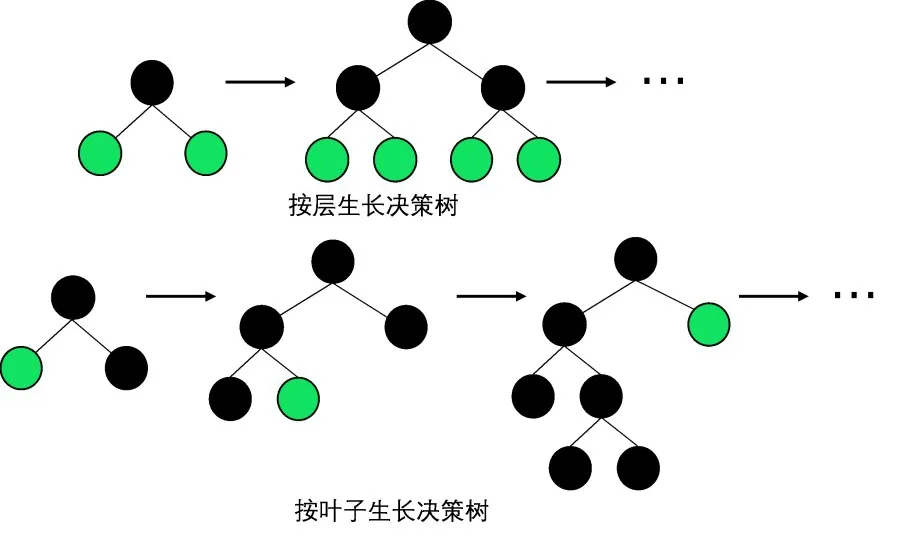
图2 决策树生长策略比较Figure 2 Comparison of decision tree growth strategies
与传统的按层生长策略不同,按叶子生长策略不需要为每层节点分配固定的数量,而是可以根据数据的复杂度和分布动态地生成不同数量的节点,并会优先生长增益最大的节点,因此也被称为“最大增益优先”(Max-Deep)策略[23]。相比于按层生长策略,按叶子生长策略可以更快地生长出更深的树,并在保持模型精度的同时减少内存开销。
LightGBM 算法能够在保持精度不变的同时,快速地构建回归树,它通过选择最佳的测井特征来分裂节点,并且通过调整不同梯度的采样比例来提高弱学习器的多样性,从而增强模型对于未参与训练的页岩气井的泛化能力。同时,它还通过限制树的最大深度来防止过拟合,确保训练的高效性。
2 基于LightGBM算法的储层参数模型构建
2.1 数据来源
本文实验数据来源于川南LZ 地区HX03、LX05、LX06、LX07 及LX08 共5 口具有岩心测试数据的页岩气井,其中HX03、LX05、LX06、LX074口井的样本数据(表1)用于建立页岩气储层甜点参数预测模型,LX08 井作为验证井不参与模型训练,用于检验模型泛化能力。数据样本包括GR、KTh、Th/K、Th/U、U、Th、K、AC、DEN和CNL共10条测井曲线,以及岩心测试的POR、TOC、吸附气量、游离气量和总含气量,将这些数据按照7∶3 随机划分为训练集和测试集开展模型构建工作。限于篇幅,本文以TOC(总有机碳含量)回归模型为例,从其训练集中随机抽取部分样本数据如表2所示。
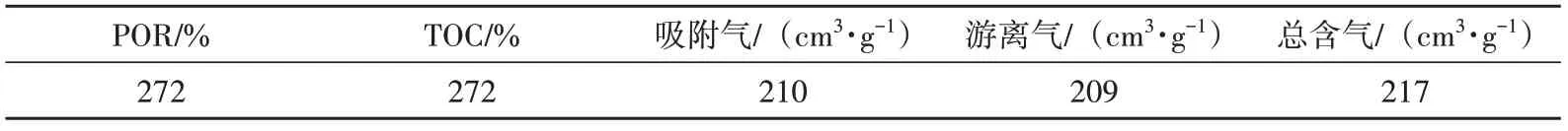
表1 样本数据个数Table 1 Number of sample data
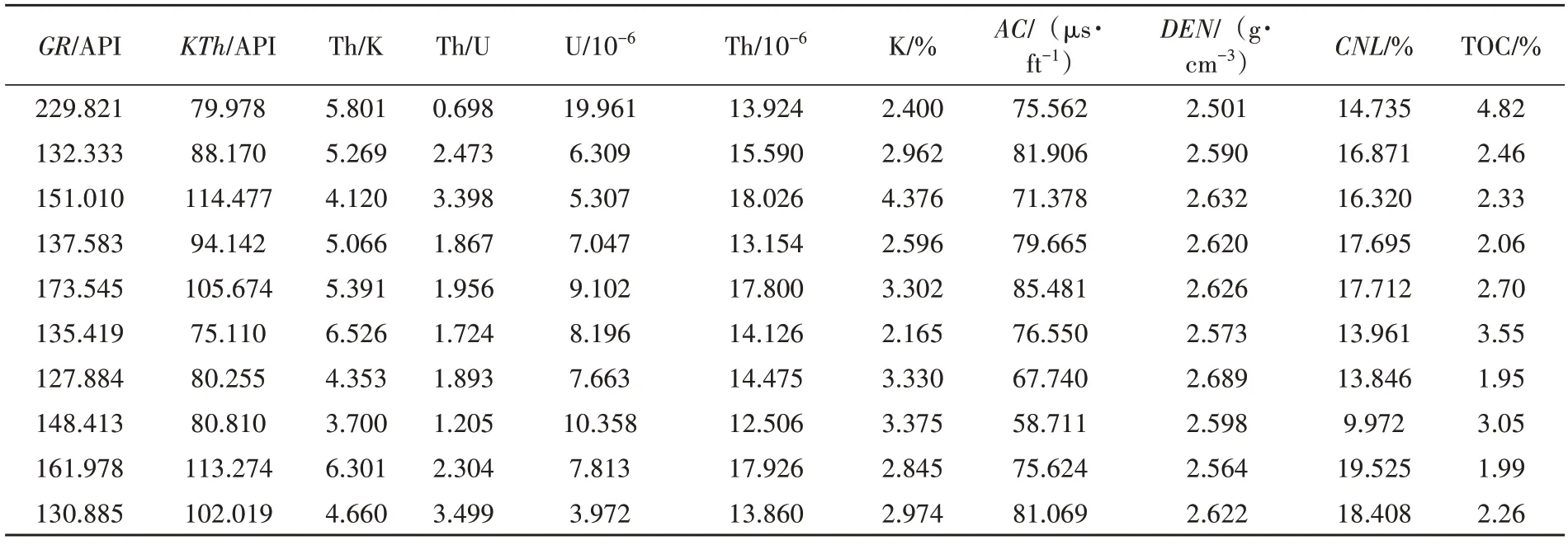
表2 训练集部分样本数据(TOC回归模型)Table 2 Partial sample data of training set(TOC regression model)
2.2 构建基于LightGBM 算法的页岩气储层甜点参数模型
采用LightGBM 算法中的回归方法对页岩气储层各甜点参数进行预测。由于LightGBM 回归算法能够输出各个特征因子的重要程度,因此可以确定不同测井曲线对目标储层甜点参数的贡献率。为了实现这一目的,需要将10条测井曲线作为模型输入的基础指标,当然需要保障这10条测井曲线的数据质量(如没有扩径影响等),相对应的目标储层甜点参数作为输出预测变量,分析测井曲线与目标储层甜点参数之间的非线性关系。
在LightGBM 算法中,回归树的构建过程使用特征的直方图寻找最优的特征分裂点,这一过程中只关心特征取值的顺序,不受单调变换的影响,也不需要对不同特征之间进行距离度量。因此LightGBM 算法不需要对数据进行归一化处理。通过LightGBM 回归算法计算得到的各个目标储层甜点参数的评价指标贡献率及排序如图3所示。
图3 表明:以TOC 回归模型为例,10 项基础评价指标贡献率之和为1,其中贡献率超过0.1 的指标有5 项,分别为AC(0.138)、Th/K(0.132)、DEN(0.117)、GR(0.106)和CNL(0.104)。其中,AC贡献率最高,说明该研究区域内TOC 与其联系最为密切。相对应的,贡献率在0.1 以下的指标也有5 项,分别为U(0.096)、Th(0.093)、KTh(0.075)、K(0.07)和Th/U(0.069),Th/U 贡献率最低,这仅说明在该研究区域内这些指标因素与TOC的联系较弱。
递归特征消除(Recursive Feature Elimination,RFE)是一种特征选择算法,它通过多次训练模型并逐步消除对模型贡献最小的特征,以实现特征选择的目的,得到的甜点参数模型精度随特征个数变化见图4。图4b 显示TOC 回归模型在选择6 个特征时,达到了最高精度0.701 8,即选择了TOC 回归模型贡献率排序(图3b)中前6 个属性:AC、Th/K、DEN、GR、CNL、U,同时删除贡献率较低的Th、KTh、K、Th/U,从而确定了最优的TOC 回归模型评估指标体系。在这种情况下,模型输入的冗余特征最少,性能达到顶峰,预测结果最为精确。其它的页岩气储层甜点参数回归模型同理,最优特征子集的选择结果如表2所示。
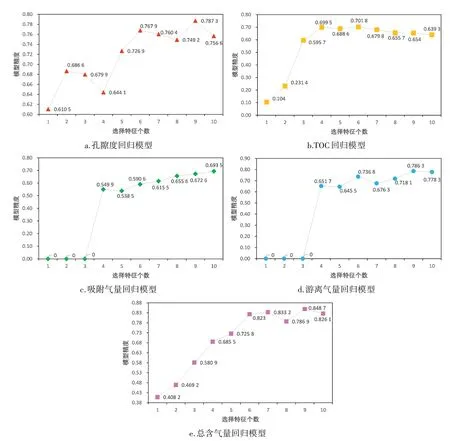
图4 各甜点参数模型精度随特征个数变化图Figure 4 Variation diagram of the model accuracy of each sweet spot parameter with the number of features
为了获得具有高精度的页岩气储层甜点参数预测模型,LightGBM 回归算法中对甜点参数预测模型建立的三种超参数值的设定十分关键。第一个是弱学习器个数(n_estimators),即模型中包含的决策树个数,作用是控制模型的复杂度和预测性能;第二个是学习率(learning_rate),即每次迭代更新的步长,作用是控制模型在更新过程中对上一轮迭代结果的影响程度;第三个是决策树的最大叶子节点数(num_leaves),即决策树最多拥有的叶子节点个数,作用是控制决策树的复杂度。
在弱学习器个数即决策树数量较少时,模型的拟合能力较弱,可能会欠拟合;而当决策树数量过多时,模型的拟合能力会变得过强,容易出现过拟合。较小的学习率会让模型更新时保留之前的结果,从而让模型更加平滑;而较大的学习率则会让模型更加关注当前的迭代结果,使得模型收敛速度加快,出现过拟合的情况。较大的num_leaves 可以让模型更加复杂,能够更好地拟合训练数据,当然也容易出现过拟合的情况;而较小的num_leaves 可以减小模型的复杂度,从而避免过拟合的情况,但可能无法完全拟合训练数据。因此,需要在合适的范围内调整n_estimators、learning_rate 和num_leaves的值,以取得最佳的性能。
带交叉验证的网格搜索(GridSearchCV)是一种超参数优化方法,通过指定超参数的候选值范围,遍历所有可能的超参数组合,并使用交叉验证来评估每个超参数组合的性能,优点是能够遍历所有可能的超参数组合,保证找到全局最优解。具体来说,网格搜索方法将每个超参数的候选值组成一个网格,然后在这个网格中搜索最优的超参数组合。对于每个超参数组合,网格搜索方法使用交叉验证来评估模型的性能。它将训练集分成若干份,每次使用其中的一份作为验证集,其余的作为训练集。然后对于每个超参数组合,计算模型在所有验证集上的平均性能指标。最终,网格搜索方法返回性能指标最优的超参数组合作为最终的模型超参数。
表3列出了建立页岩气储层不同甜点参数回归模型的最优特征子集、网格搜索范围及最佳超参数取值。
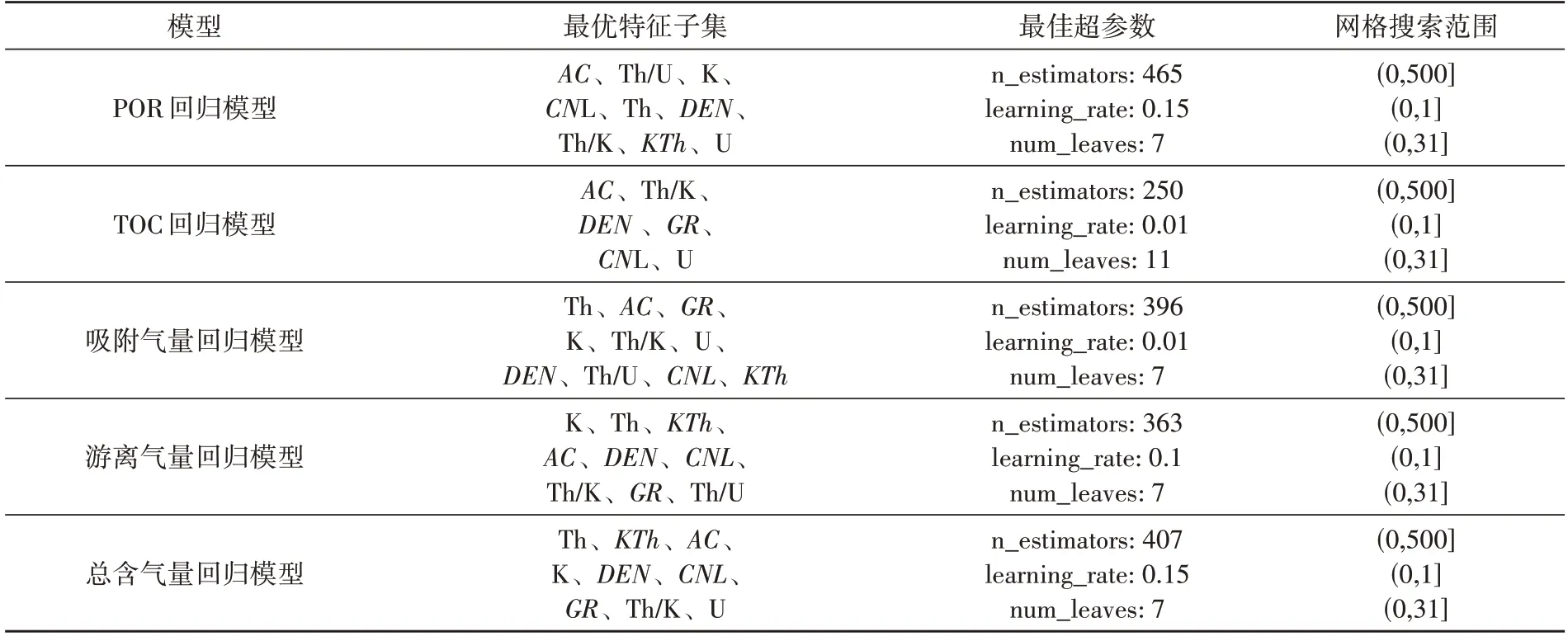
表3 不同模型最优特征子集、网格搜索范围及最佳超参数Table 3 Optimal feature subsets,Grid search ranges,and optimal hyperparameters of different models
3 页岩气储层甜点参数评价实例分析及应用
储层甜点参数在页岩气储层评价中扮演着重要角色,对于页岩气的勘探开发具有重要的指导作用。由于取心数据的获取成本较高,有效地利用已有的岩心测试数据来构建页岩气储层甜点参数预测模型是一种重要的手段。为了验证构建的页岩气储层甜点参数预测模型的应用效果,首先以作为参与训练集的LX06 井连续测井剖面中的POR、TOC、吸附气量、游离气量及总含气量为例,得到预测结果如图5 所示,并分析了预测结果与岩心测试数据之间的相关系数。从图6 中可以发现,LightGBM 回归模型预测的数据点绝大部分接近于45 度线,且预测结果与岩心测试值的相关系数均超过0.96,表明该模型预测页岩气储层甜点参数精度较高。
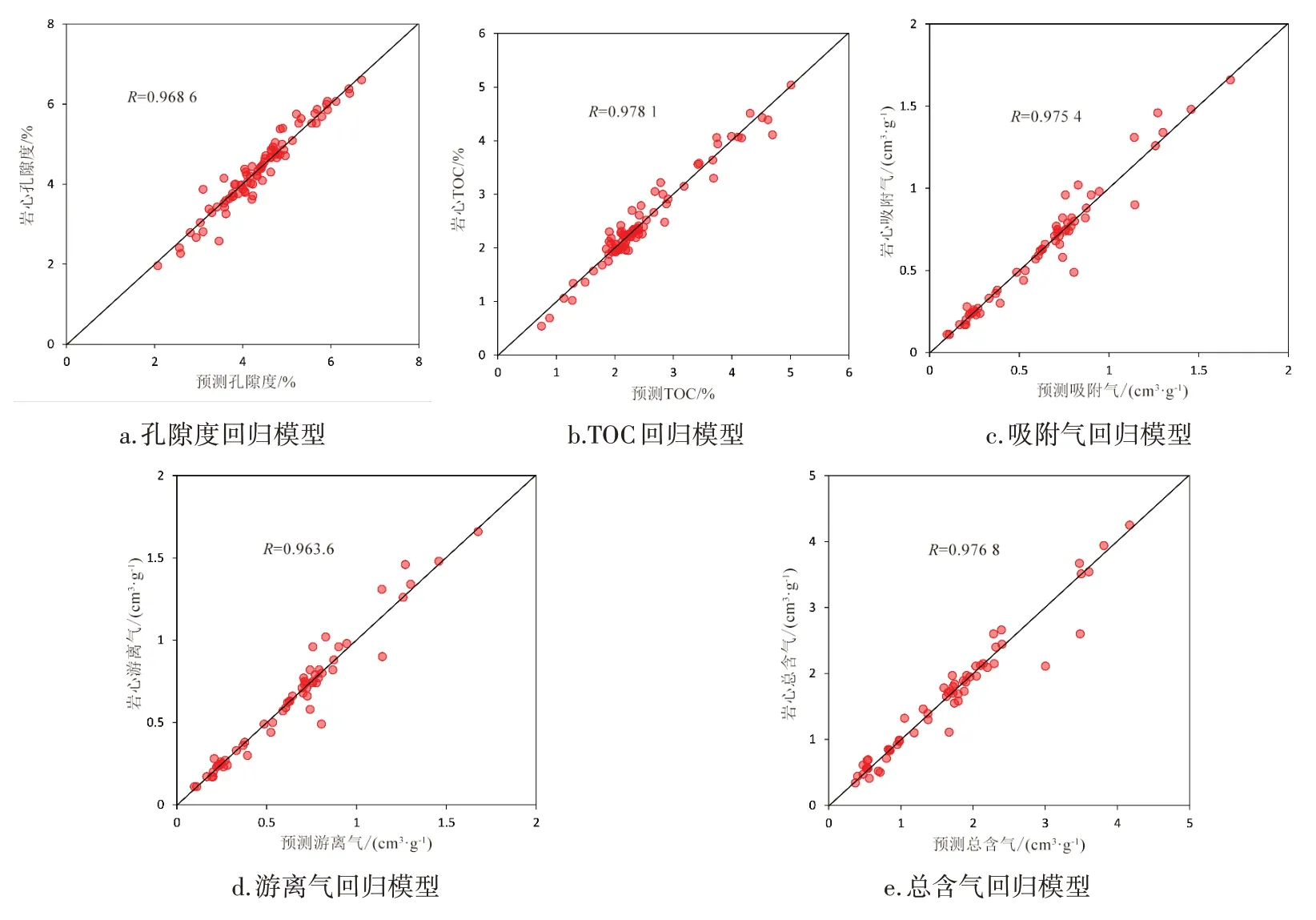
图6 LX06井甜点参数预测结果和岩心测试数据相关性分析Figure 6 Correlation analysis between prediction results of sweet spot parameters and core test data in Well LX06
作为参与训练集LX06 井的预测效果还不足以说明问题,进一步利用基于LightGBM 回归算法预测模型预测未参与页岩气储层甜点参数模型训练的LX08 页岩气井,该井的POR、TOC、吸附气量、游离气量和总含气量这5 项甜点参数,预测结果见图7,离散杆状数据与预测曲线吻合度较高,各项甜点参数预测结果与岩心测试结果的相关系数也均达到了0.9 以上(图8),说明基于LightGBM 回归算法模型可以准确地预测页岩气储层目标甜点参数。
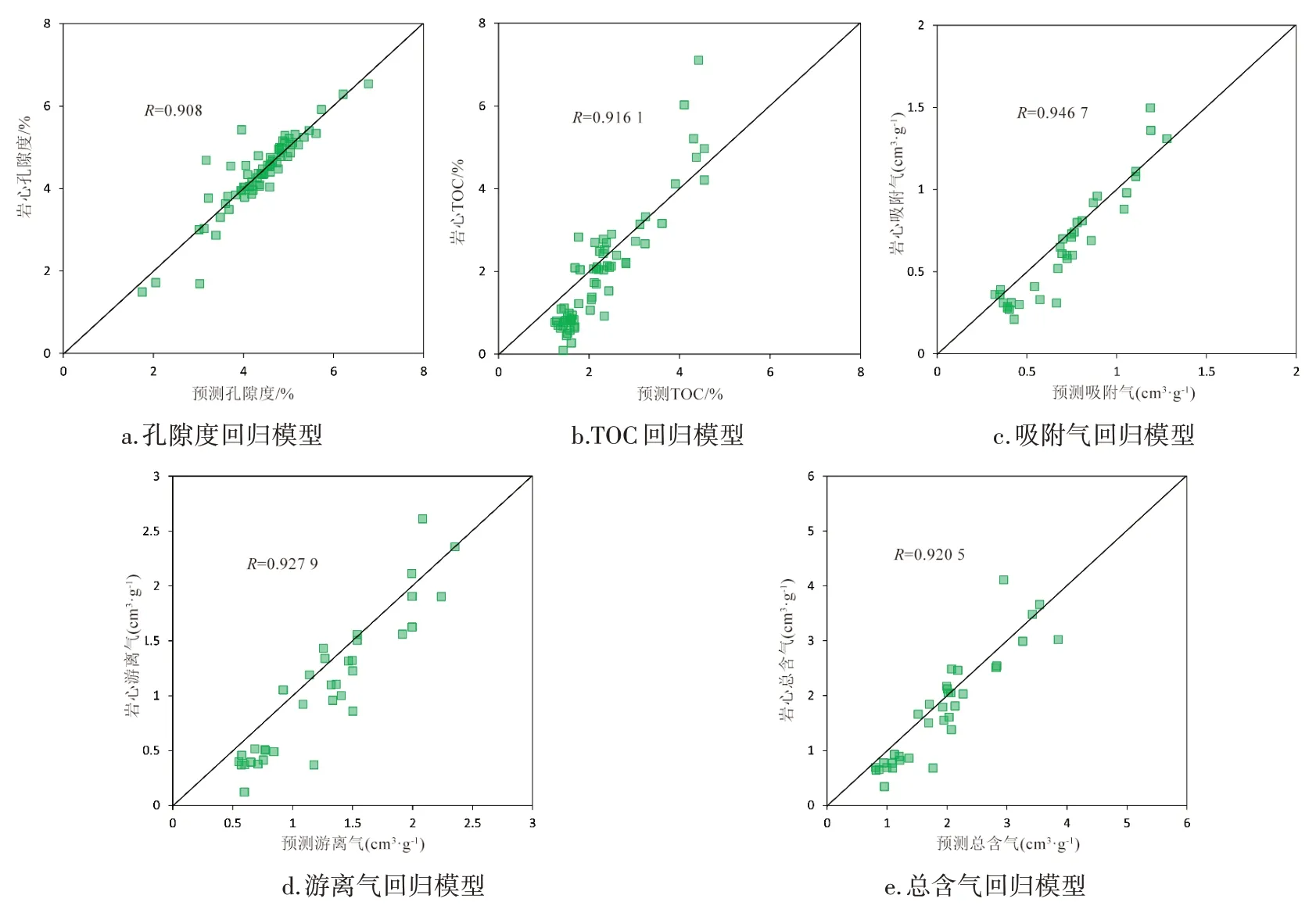
图8 LX08井甜点参数预测结果和岩心测试数据相关性分析Figure 8 Correlation analysis between prediction results of sweet spot parameters and core test data in Well LX08
与传统的多元回归、经验公式、岩石体积物理解释模型等相比,机器学习模型充分利用多元海量测井曲线的大数据特性,以及测井曲线数据和岩心样本测试数据的非线性关系来进行模型训练和预测,不需要太多考虑页岩气储层的地质差异性。本文采用的机器学习中基于LightGBM 回归算法的页岩气储层甜点参数预测模型可以很好地拟合多测井曲线变量与目标甜点参数之间的非线性关系,具有较强的泛化能力,是一种有效、低成本的预测方法。
4 结论
1)页岩气储层在矿物、有机质、物性及含气性等方面具有强的非均质性,甜点参数(孔隙度、TOC、含气量等)与测井曲线之间往往是复杂的非线性关系,多元回归法和经验公式法等常规方法难以精确计算页岩气储层的甜点参数。
2)LightGBM 机器学习回归算法具有训练效果好、不易过拟合及训练速度快等优点,在特征贡献度分析和递归特征消除算法确定甜点参数评价指标和带交叉验证的网格搜索确定最优模型超参数值的基础上,构建了基于LightGBM 回归算法的页岩气储层甜点参数预测模型。
3)运用基于LightGBM 回归算法的页岩气储层甜点参数预测模型,对川南LZ地区未参与模型训练的LX08 井进行甜点参数预测,预测结果与岩心实测值相关系数均达到0.9 以上,表明该方法具有较强的泛化能力,可有效预测复杂页岩气储层甜点参数,且成本低、可操作性强,易于推广。
猜你喜欢
小学生作文(低年级适用)(2023年4期)2023-04-25 02:58:54
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
儿童故事画报(2020年11期)2020-06-23 06:03:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
电子制作(2018年16期)2018-09-26 03:27:06
创新作文(小学版)(2018年4期)2018-07-06 08:16:02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
Coco薇(2016年2期)2016-03-22 16:58:16
