
基于双阶段混合模型的密封电池高精度空间定位
2023-12-04 02:38:30葛亚明
兵器装备工程学报 2023年11期
葛亚明,葛 旭
(1.哈尔滨工业大学(深圳) 实验与创新实践教育中心, 广东 深圳 518055; 2.哈尔滨工业大学(深圳) 机电工程与自动化学院, 广东 深圳 518055)
0 引言
电动汽车在过去几年的快速发展催生了用于汽车的高容量密封电池[1-2]。密封电池由电池仓、电池和电池盖组成,必须由焊接工人在流水线上焊接在一起才能投入使用。然而,焊接密封电池需要较高的专业技能,因此高级焊工的短缺成为了一个重大问题[3-4]。我们迫切需要开发一种焊接机器人来代替焊工执行焊接任务[5-7]。
在过去的研究中,机器人焊接技术主要分为2个领域:基于自定义传感器和传统算法的自动识别焊接方案[8-10]与基于深度学习的识别焊接[11-13]。然而,在实践中,通常存在2个问题,首先,很多基于自定义传感器和传统算法的技术对焊接环境的要求很高,当环境的光照和背景发生变化时,可能会导致算法失效[14];其次,基于深度学习的算法需要一个合理的模型来适应目标任务,如果模型参数数量过多或模型结构不合理,可能导致识别速度慢或检测性能差,不符合我们的技术工程要求[15-17]。因此,我们提出了一种新的识别方案来解决这2个问题,可以克服复杂环境的干扰,快速准确地识别目标[18]。
本文中提出了一种解决自动焊接问题的双阶段混合模型,将图像分割网络与传统图像处理算法结合,从而同时具有了深度学习的精度与传统算法的推理速度,能够满足实际场景需求。一方面,我们在第一阶段模型中提出了一种轻量级网络模型CA-UNet,可以在复杂环境中快速分割目标对象;另一方面,我们提出了一个基于融合算法的第二阶段模型,可根据CA-UNet输出的灰度图像快速建立从图像到机械臂焊接的空间路径映射。
1 实验设计思路
以实现密封电池轮廓空间定位[19]为目标,提出了端到端的双阶段混合模型,将获取原始图片到生成三维空间路径分为2个阶段分别进行。一阶段模型负责实现密封电池与背景的分割,二阶段模型负责根据分割图像建立空间焊接路径。
一阶段模型基于UNet图像分割网络做出改进,引入通道注意力(Channel Attention)模块[20],得到改进后的图像分割网络CA-UNet,然后通过训练数据集训练CA-UNet,得到合适的网络权重,进而在实验中成功地将密封电池与背景分离。
二阶段模型融合了多种算法,包括边缘提取[21],图像降噪,坐标变换,路径规划等,能够根据分割图像快速计算出密封电池空间轮廓。实验整体流程如图1所示。
2 双阶段模型建立
提出的双阶段混合模型方法的总体过程如图2所示。第一阶段模型去除图像失真并进行实例分割以确保分割精度;第二阶段模型负责建立从灰度图像到三维焊缝路径的映射,结合边缘提取、角点识别、坐标变换和路径规划等算法快速生成焊缝路径。双阶段混合模型方法是一种端到端的图像处理技术,可生成世界坐标系下的3D焊接路径,具有快速、准确和使用简单的优点。
2.1 图像去畸变
在确定了整体的算法流程之后,需要拍摄图片作为模型的输入,然而,在将图片输入模型之前,必须解决图像的失真问题。第一次使用的摄像机大多存在畸变现象,拍摄的图像会出现不同情况的失真,从而影响对密封电池的分割和定位,所以,需要去除图像的畸变。图3给出了去畸变前后图像的对比。
2.2 一阶段模型
UNet在很多图像分割任务中表现优异,但由于参数量较大,边缘设备无法负载该模型。因此,本文中提出了CA-UNet模型,它增加了通道注意力机制来缩放特征通道,显著减少模型参数量并提取更多有用的特征。特征图的最大通道数减少到512,相比UNet提升了模型的推理速度。
CA-UNet是一个典型的Encoder-Decoder结构的卷积神经网络。它通过下采样和上采样模块获取局部和全局特征,从而可以很好地学习目标的特征信息。 此外,CA-UNet通过在下采样和上采样过程中连接特征图来丰富通道信息,从而提取更多的特征。

图3 去畸变前后图像对比Fig.3 Contrast the original image with the dedistorted image
搭建的模型结构如图4所示。叠加的卷积层将增加特征图的通道数,以学习更深入的特征。其次,Max-Pooling算子会不断降低特征图的空间维度,以获得特征图上各个空间尺度的局部和全局特征。与UNet相比,激活函数选择LeakyReLU以确保不会出现梯度方向的锯齿问题,从而导致特征的丢失。在使用激活函数之前,对特征图使用批量归一化来提高网络的收敛速度。
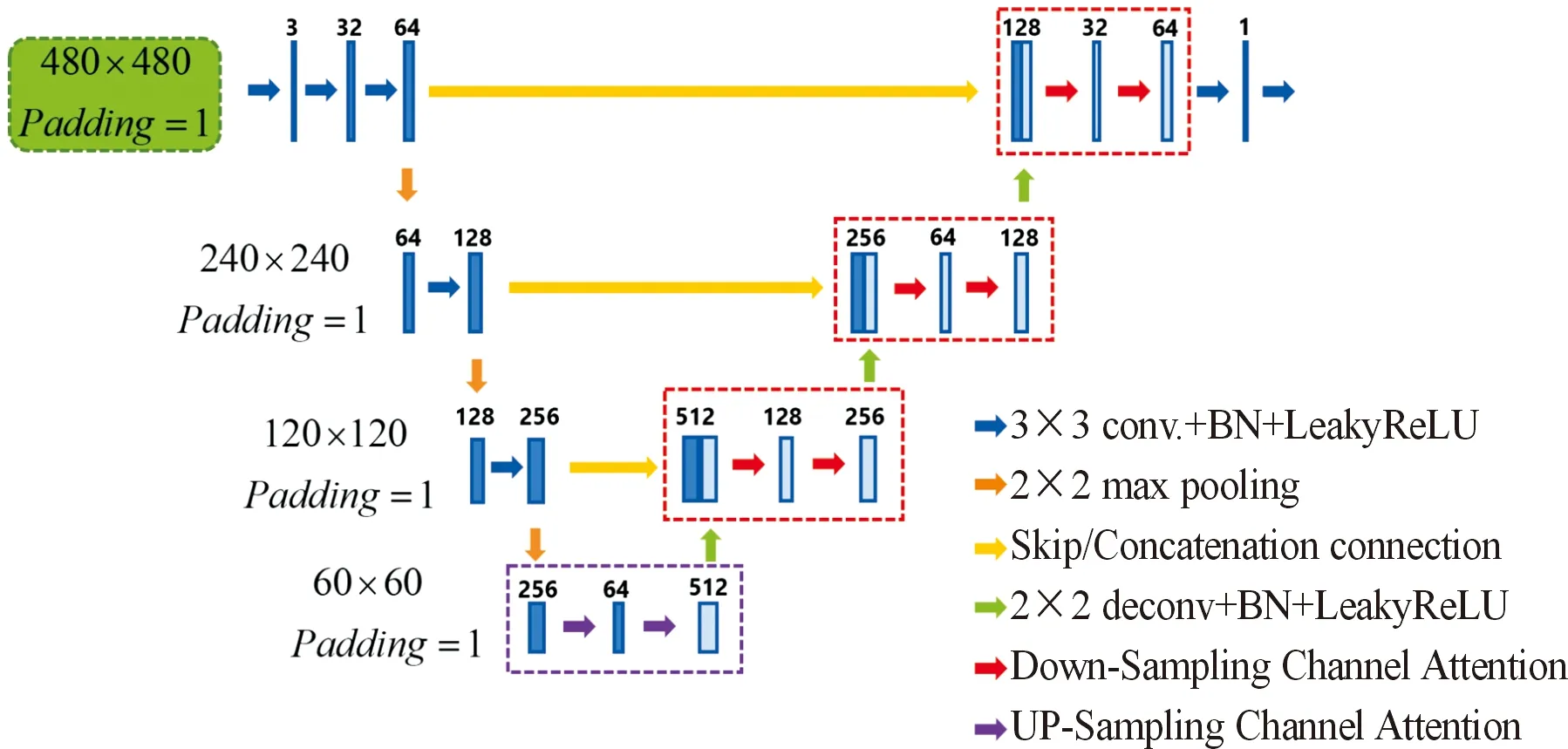
图4 CA-UNet的网络结构Fig.4 The overall structure of CA-UNet
在CA-UNet的后续结构中,可以看到反卷积算子和通道注意力(Channel Attention)[22]模块。反卷积算子允许我们对特征图进行上采样,以获得低分辨率但更深入特征的特征图,然后对高分辨率但不太深入的特征进行跳跃连接。最后将拼接后的特征图输入到Channel Attention模块中,进行特征通道压缩,以获得更多的特征信息。Channel Attention的机制如图5所示。特征通道通过1×1卷积进行缩减。下采样通道注意力模块首先将特征通道除以2r,然后乘以r将通道数量压缩到原始数量的一半。类似地,特征通道的数量可以增加到原来的两倍,即上采样通道注意力模块。用户可以根据结果的性能指定压缩或增强的特征通道数量。

图5 Channel Attention模块Fig.5 Channel Attention module
2.3 二阶段模型
CA-UNet完成对输入图像的预测后,会输出一张单通道灰度图。该图像中的白色区域表示检测到的密封电池,黑色表示不相关的背景。随后需要融合一些图像处理算法来实现密封电池的空间定位和路径规划。
二阶段模型整体由许多算法构成,包括形态学处理、边缘提取、角点识别、坐标变换、路径规划等。形态学处理是为了消除图像分割网络输出图像中的噪点,在保证边缘轮廓不变的情况下大幅降低图像的噪声。边缘提取和角点识别可以快速地定位密封电池,利用密封电池的矩形特征实现空间定位。在获取到密封电池在相机坐标系下的坐标后,利用相机坐标系与世界坐标系的变换得到密封电池在世界坐标系下的坐标,进而可以进行机械臂的路径规划。

图6 相机坐标系与世界坐标系Fig.6 Conversion of sealed cell pixel coordinates to world coordinates
需要通过外参标定来获得世界坐标系和相机坐标系的映射关系,从而能够在世界坐标系中定位密封电池。世界坐标系与相机坐标系的映射关系如图6所示。假设刀片电池上的某一个点在相机坐标系中的坐标为P(xBlade,yBlade,zBlade)简记为P(xB,yB,zB)那么从世界坐标系到相机坐标系的变换为

(1)
式(1)中:R为正交单位旋转矩阵;T为平移向量,可以从机械臂的参数中获得。对于QKM六轴机械臂,M1由以下公式求得:
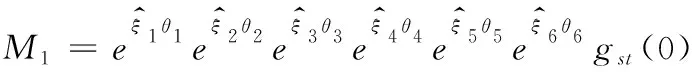
(2)

3 实验与分析
3.1 实验环境与数据集建立
为了验证所提出方法的有效性和鲁棒性,在车间环境中使用气焊机和QKM 六轴机器人进行实验。使用外部计算机来实现我们提出的方法并与机器人手臂进行通信以进行焊接。计算机的硬件环境为AMD Ryzen7 5800 CPU,NVIDIA GeForce RTX3060 GPU,以及16 GB RAM。
软件环境方面,CA-UNet网络采用开源深度学习框架Pytorch构建,CA-UNet实时运行环境为Ubuntu 20.04,在这台计算机上使用 CA-UNet模型进行模型部署,并与机械臂进行通信。
为了实现模型的训练和部署,首先需要建立密封电池在机械臂平台上的图片数据集。用机械臂搭载的摄像机在不同光照、不同角度下采集了约500张图片,随后使用图像增强,对图片随机组合使用裁剪、噪声、旋转、变化对比度等增强方法,最后得到约2 000张图片,构成总数据集。得到图片数据集后,按照训练集、验证集、测试集比例7∶2∶1来划分数据集。对于不同模型的对比训练部分,采用GPU服务器进行模型参数学习,其中服务器的CPU采用英特尔的i9-10900k,GPU为RTX 2080Ti。
3.2 表现评估
用于评估图像分割模型的可靠性和性能的方法通常复杂且多样。为了客观地评估我们提出的方法的有效性,分别考虑均交并比(MIoU)[23]和推理速度,并使用损失函数来优化我们的模型。另外,将应用CA-UNet和UNet的结果进行比较,以考察CA-UNet是否有性能提升。
选择的损失函数是带有logits损失函数的二元交叉熵。带有logits损失函数的二元交叉熵将 Sigmoid 层和 BCELoss 结合在一个类中。 它比使用简单的Sigmoid和BCELoss更稳定,因为通过将操作组合到一层,利用log-sum-exp技巧来实现数值稳定性。BCEWithLogitsLoss首先使用sigmoid函数对CA-UNet输出的每个像素值进行归一化,然后以0.5的阈值对像素进行分类,这比直接输出类别在数值上更加稳定。
BCE损失函数的表达式如下:
(1-yi)·log(1-p(yi))
(3)
式(3)中:yi为标签;p(yi)为模型输出的第i个点的预测概率。
使用MIoU作为评估指标,这是实例分割的标准指标,用于计算2个集合的交并比。其计算公式如下:
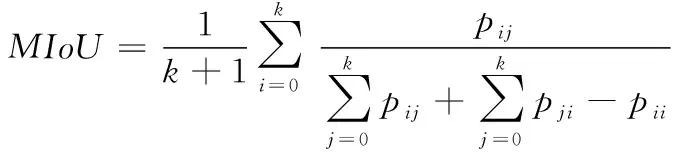
(4)
通过增加通道注意力机制等改进了UNet的网络结构,从而能够大幅增加模型推理速度,并保持较高的预测精度。将分别从预测1张图像、3张图像、5张图像和10张图像的时间来比较2个模型的推理速度。
3.3 结果分析
如图7所示,分别使用UNet和CA-UNet在密封电池数据集上进行训练,并将学习率设置为1e-4,同时选择Adam优化器。可以看到,随着训练步数的增加,2个网络的损失都会减少并最终收敛到一个值。 但UNet的损失值低于CA-UNet,因此UNet在测试集上的表现可能存在2种情况。在第一种情况下,UNet在测试集上表现更好,因为它具有更多的网络参数并学习更多的特征。第二种情况,UNet的冗余结构导致过拟合,导致在测试集上的性能比CA-UNet差。因此,要确定哪个网络表现更好,必须进行实际测试。

图7 UNet与CA-UNet在训练过程中的Loss变化情况Fig.7 Decline of loss function for UNet and CA-UNet model
随后在测试集上进行实验来验证这2个网络模型的预测精度。如图8所示。每一步都评估模型的MIoU。随着训练步数的增加,2个模型的 MIoU接近0.99,并且CA-UNet的MIoU略高于UNet,这表明即使我们的改进结构使用更少的模型参数,它仍然可以学到更多对目标有用的特征并抑制过度拟合。
最后本文分别对比了UNet和CA-UNet的预测精度和推理速度,如表1和表2所示。如表1所示,输入图像的长和宽均为480,损失函数平均值(Avg Loss)分别为-117和-102,CA-UNet在缩减了大量参数的情况下具有和UNet相近的预测精度。此外,如表2所示,CA-UNet在分割相同数量的图像时相比于UNet节省了大量时间,因为它使用了很多通道注意力模块,参数量实现了大幅缩减,从而提高了整个预测过程的速度。

图8 2种网络在训练过程中的MIoU变化情况Fig.8 MIoU accuracy for UNet and CA-UNet model

表1 UNet与CA-UNet的精度对比Table 1 Precision comparison between UNet and CA-UNet

表2 UNet与CA-UNet的推理速度对比Table 2 Comparison of reasoning speed between UNet and CA-UNet s
同时,在训练阶段,2种网络所花费的时间也有所不同,如表3所示。在前文环境配置中提到,使用了配备RTX 2080Ti的GPU服务器进行模型训练,由于CA-UNet显著降低了参数量,其训练所占用的显存和耗费时间也大幅降低。在训练过程中,不同模型统一使用大小为64的Batchsize。从表3中可以看出,对于训练30个epoch的模型,CA-UNet的花费仅为2.9 h,比UNet节省了约1.2 h;对于训练60个epoch的模型,CA-UNet比UNet节省了2.3 h。由此可以看出,随着训练轮次的增加,参数量更小的CA-UNet在训练时间方面有着更大的优势。
在不同的工作环境下进行了对比实验,以研究两阶段混合模型方法的实际影响,实验结果如图9所示。
比较实验中使用了4种不同的工作条件,准确地代表了具有不同光照和阴影的真实工作环境。具体工况分为正常工况,低光照工况,高光照工况以及高阴影工况。UNet与CA-UNet输出的分割图均有大量噪声,经过二阶段模型处理会基本消除掉噪声,也进一步验证了二阶段模型的必要性。与Ground Truth相比,双阶段模型输出结果的误差低于1.6%。第二阶段模型的算法补偿将输出结果的准确性大大提高,从而可以应用于焊接机器人的实际操作中。
4 结论
针对用于工业机器人焊接系统的密封电池自主识别和定位算法进行了研究,该算法可用于复杂的工作条件,并可推广到任何需要边缘焊接的物体。提出了一种双阶段混合模型方法,将任务拆解成两个阶段分别求解,实现端到端的图像处理方案,建立从原始图像到3D路径的完整映射。
双阶段混合模型方法经过实验验证取得了较好的效果,在克服环境干扰、提高推理速度、实现高精度识别等方面具有优异的性能。
猜你喜欢
今日农业(2022年14期)2022-09-15 01:43:28
军事文摘(2022年14期)2022-08-26 08:14:30
科学大众(2021年21期)2022-01-18 05:53:42
小学科学(学生版)(2021年12期)2021-12-31 03:22:18
经济技术协作信息(2018年15期)2019-01-23 07:05:26
经济技术协作信息(2018年20期)2019-01-19 02:56:40
中学生数理化·七年级数学人教版(2018年4期)2018-06-28 03:26:28
数学大世界(2018年1期)2018-04-12 05:39:03
中等数学(2017年2期)2017-06-01 12:21:50
设备管理与维修(2016年6期)2016-03-16 02:22:09
