
基于深度学习的施工安全隐患整改智能推荐系统
2023-12-01 02:53:54刘震赵嵩杨涛蔡太伟
大数据 2023年6期
刘震,赵嵩,杨涛,蔡太伟
1.广东粤海珠三角供水有限公司,广东 广州 511455;
2.云南大学信息学院,云南 昆明 650504;
3.深圳市科荣软件股份有限公司,广东 深圳 518063;
4.华南师范大学华南先进光电子研究院,广东 广州 510006
0 引言
随着信息技术的不断发展,水利工程建设安全管理正向信息化和智能化转型[1]。施工安全隐患的排查治理是工程建设中安全管理的重要手段。随着信息化系统的普及与应用,人工排查、手动录入的施工安全隐患管理在排查过程中积累了大量非结构化的安全隐患文本数据,但这些数据尚未得到充分利用。因此,利用人工智能从海量的历史数据中挖掘出隐藏信息和潜在规律,从而促进水利工程建设由信息化模式向智能化模式发展[2],对于提高施工安全隐患的排查治理效率具有重要的现实意义。
目前,不少学者对安全隐患文本数据的挖掘展开了研究。例如:刘梅等[3]利用相关性检验挖掘安全隐患特征之间的关联;谭章禄等[4]利用狄利克雷分配模型挖掘煤矿安全隐患,揭示了生产单位、责任主题与隐患致因之间的关系;陈述等[5]通过短语提取技术揭示了安全隐患时空分布特征;林旭杰等[6]采用Apriori关联算法挖掘煤矿安全隐患之间的关联规则;Le等[7]、Jatnika等[8]将深度学习的方法运用到提高建筑工程术语语义相似度计算的准确性上,为隐患文本知识挖掘增加了可信度。为了从历史案例中挖掘出有用的信息和经验,1995年Kumar[9]首次将案例推理技术应用到工程设计领域,为案例推理技术在各种工程领域的应用提供了理论基础。例如:郑霞忠等[10]通过融合案例推理与深度学习的方法,结合历史安全隐患数据来辅助隐患治理方案的制订;原江涛等[11]基于案例推理技术,提出了一种煤矿安全隐患排查治理信息系统并应用于实际生产;夏登友等[12]利用情景元技术对案例进行描述和表示,提出了一种基于规则的推理方法,并实现了一个应急决策支持系统,对相关领域的应急决策提供了有效的帮助。
综上所述,以往的研究大多聚焦于隐患问题的智能分类和隐患问题关联规则的挖掘,忽略了历史隐患案例中潜藏的信息。为了充分挖掘安全隐患历史案例中的有用信息和经验,本文从历史案例视角对施工安全隐患进行分析,帮助安全管理者深入探析隐患事件发生的特征和规律,并根据相似的隐患案例制订有效的隐患预防措施,从而降低类似隐患的发生概率。类似的视角还包括事故因素分析和风险评估等。为此,本文结合文本特征提取、关联规则挖掘和文本相似度计算等方法,提出了施工安全隐患整改智能推荐系统。该方法融合SSM算法和Doc2Vec模型来优化检索推荐过程,并在检索阶段分析相关历史案例信息。计算隐患描述之间的相似度时,考虑了上下文逻辑和短文本语义特征。最后,参考相似度最大的历史案例,将检索出的整改措施作为当前隐患问题的推荐整改方案。
1 数据来源与预处理
1.1 数据来源
以珠江三角洲水资源配置工程为研究对象,在该工程的建设过程中,安全检查单位每月对其负责的施工标段进行安全检查,检查过程中检查人员发现施工现场存在安全隐患问题,并指示施工单位在规定的期限内进行整改,之后将检查和整改记录上传到安全管理信息系统。本文的研究数据来源于从安全管理系统中获取到的2019—2023年期间80 953条安全隐患原始数据,其中,将2019—2022年期间的65 714条数据作为历史案例数据,2022—2023年期间的15 239条数据作为测试数据。每条安全隐患数据主要包含标段、隐患描述、隐患类型、整改措施和检查日期等字段,前4个字段均为非结构化的文本数据。其中,隐患类型分为环境隐患、人的不安全行为、管理隐患、设备设施及物料隐患4类。部分安全隐患记录见表1。

表1 部分安全隐患记录
1.2 预处理
为了获得有效的施工安全隐患数据,本文结合工程施工安全隐患的判定标准等相关规范,手动对数据进行了处理。首先,人工记录的数据可能存在含有主观推断的信息、缺失值、异常值等数据,因此,手动剔除上述信息以获得有效的安全隐患数据。其次,针对水利工程施工安全领域的特点,构建了该领域的安全隐患字典用于辅助分词,包括手动添加专有名词到自定义词典,例如“高处坠落”“电气安全”“脚手架”等。这能够完善分词效果,有效避免术语被错误分开或合并的情况发生,从而提高数据处理和分析的精确度。再次,采用哈工大停用词表,并将不规范的关键词、无意义的词添加到停用词表中,用于去除隐患问题描述文本中的停用词,例如空格、标点符号等影响文本处理与分析的无效信息。最后,采用了Jieba分词对隐患问题描述文本进行分词。
2 研究方法
2.1 基于TF-IDF算法的隐患特征提取
词频-逆向文档频率(term frequency–inverse document frequency,TF-IDF)是一种常用的文本特征提取算法。TFIDF算法可以提取出文档中的关键词,评估提取出的关键词在文档集合中的重要程度。关键词的重要程度与该关键词在文档中的出现频率(term frequency,TF)成正比。TF的计算方式如式(1)。
其中,ni,j是安全隐患词语i在安全隐患文档j中出现的次数,分母则表示安全隐患文档中所有词汇出现的次数总和。关键词的重要程度与该词在文档集合中出现的频率(inverse document frequency,IDF)成反比。IDF值计算方式如式(2)。
其中,|D|表示语料库中的文档总数,dj表示文档样本,|{j:ti∈dj}|表示包含词语ti的文档数目。将关键词的TF值和IDF值进行乘积,得到该词的TF-IDF值,该值越大表示该关键词在文档中的重要程度越高[13]。文本特征选择还有互信息算法、信息增益算法、卡方检验算法等[14]。在本文的研究数据中,每条数据通常只包含很少的关键词,数据非常稀疏,故采用TF-IDF算法来提取安全隐患中的关键词作为隐患特征。
2.2 基于深度学习的施工安全隐患整改智能推荐系统
在隐患排查治理中,安全隐患具有高复发性,因此,可以借助历史安全隐患治理方案,缩短查询隐患相关知识的时间,及时制订隐患整改措施。除此之外,安全隐患之间还具有相关性,一个隐患的发生往往可能导致其他隐患的出现。在复用历史安全隐患治理经验的同时,可挖掘出与当前隐患关联的一系列安全隐患问题并给出整改措施,从而提高隐患治理的效率,实现无隐患早防控、有隐患早发现和早治理的目标。为此提出了基于深度学习的施工安全隐患整改智能推荐系统,系统框架如图1所示。
在对施工安全隐患整改智能推荐系统的研究中,面临整体数据规模大且存在较多稀疏数据的挑战。当入库一条安全隐患时,首先,采用TF-IDF算法提取出隐患的特征,每个隐患特征都包括一个或多个安全隐患,每个安全隐患至少归类到一个隐患特征中。其次,采用FP-Growth算法从频繁项集列表中挖掘出与当前安全隐患特征相关联的频繁项(安全隐患特征集),再将这些安全隐患特征下的安全隐患案例作为当前安全隐患潜在的预警信息。然后,利用SSM算法对当前入库的安全隐患与数据库中的历史安全隐患案例进行初步匹配,得到粗糙的相似案例集合,进一步采用Doc2Vec模型来计算当前安全隐患与相似案例集合中每一条安全隐患的相似度。最后,合并相似度最高的安全隐患案例与关联的安全隐患案例,将其推荐为当前安全隐患的整改方案。
2.2.1 基于FP-Growth算法的隐患关联规则挖掘
关联规则是一种描述不同项集之间关联关系的表达式,通常采用X→Y的形式表示,其中X和Y是不相交的项集。常用的关联规则挖掘算法包括Apriori算法、FP-Growth算法等。Apriori算法需要生成大量的候选集,在处理大规模数据时会非常耗时间和空间。而FP-Growth算法通过压缩数据、构建FP树去除了生成候选集的过程,大大减少了时间和空间的消耗。因此,本文采用FP-Growth算法挖掘安全隐患之间的关联规则,从而建立频繁项集列表。
FP-Growth算法主要分为两个步骤:构建FP树和基于FP树生成频繁项集[15]。FP树是一种基于频繁模式挖掘的数据结构,用于高效地存储和查找数据集中的频繁项集。FP树由一个根节点和多个项节点组成,每个项节点表示一个频繁项,每个节点包括一个计数器和指向相同项节点的链表指针。构建FP树的过程如下:遍历数据集统计每个项的支持度计数,根据支持度计数构建项头表;按照支持度降序遍历数据集,将事务中的每个项按顺序加入根节点;为每个节点创建一个初始值为1的计数器,如果该节点存在项节点,则计数器加1,以此递归地构建FP树。基于FP树生成频繁项集的过程如下:从根节点开始,依次遍历每个频繁项的链表,生成以该项为结尾的频繁项集;采用递归方法,在每个以该项为结尾的前缀路径上构建条件模式基,从而继续生成更长的频繁项集。
2.2.2 SSM算法
SSM算法[16]的原理是通过计算两个序列之间的最长公共子序列(longest common subsequence,LCS)的长度来计算两个序列的相似度。假设两个序列分别为X和Y,LCS(X,Y)的长度为len(LCS(X,Y)),那么它们的相似度计算如式(3)。
与SSM算法类似的算法还有编辑距离算法、Jaccard相似度算法和余弦相似度算法等。相比于编辑距离算法[17]和Jaccard相似度算法[18],SSM算法可以处理不同长度的序列。在施工安全隐患数据中,往往会存在序列长度不同的隐患数据。如果使用编辑距离算法和Jaccard相似度算法,则需要对数据进行维度对齐,这样会导致部分信息丢失。与余弦相似度算法相比,SSM算法考虑了序列中元素的顺序,能够发现相同子序列的位置和顺序。综上所述,SSM算法在文本相似度匹配、序列相似度匹配方面表现更优。因此,本研究利用SSM算法对当前入库的安全隐患与数据库中的历史安全隐患案例进行初步匹配,得到粗糙的相似案例集合。
2.2.3 基于Doc2Vec模型计算文本相似度
Doc2Vec[19]是一种深度学习模型,用于将一个文档表示为固定长度的向量,它是Word2Vec模型[20-21]的扩展。Word2Vec模型可以将单个单词表示为向量,而Doc2Vec在训练模型时不仅考虑了每个单词的上下文信息,还考虑了整个文档的语境,为每个文档生成一个唯一的向量表示。Doc2Vec有两种算法,分别是分布记忆(distributed memory,DM)算法和分布词袋(distributed bag of words,DBOW)算法。DM算法将文档的向量作为额外的输入传递给模型,然后预测文档中的单词,其结构如图2所示。
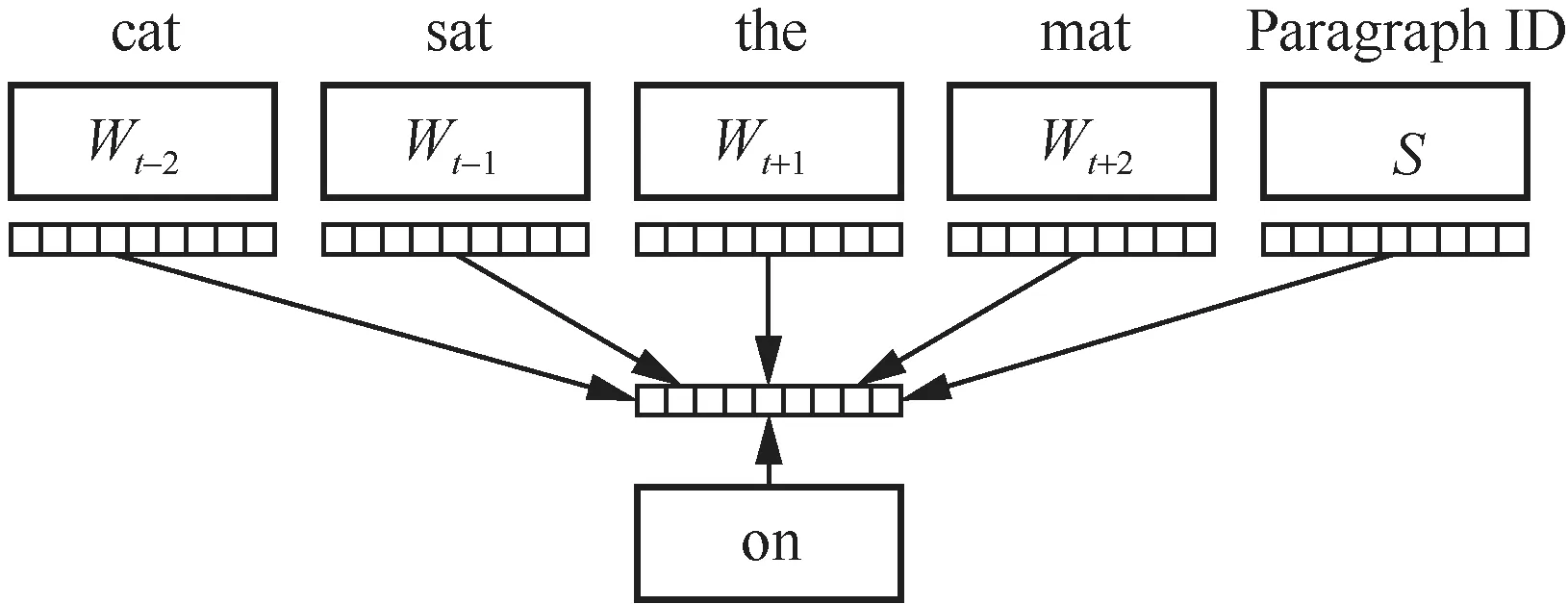
图2 DM 算法结构
DBOW算法结构如图3所示。在DBOW算法中,每个句子都被视为一个“袋子”,每个单词的顺序被忽略,每个单词都被独立地考虑。而该模型的目标是在不考虑上下文的情况下,根据整个句子预测中心词。相比DM算法,DBOW算法更简单和快速,通常适用于文本分类等任务,而DM模型则更适合语义相关性和相似性的建模任务。本文使用Doc2Vec模型中的DM算法来计算当前安全隐患与经过SSM算法匹配得到的粗糙相似案例集合中每一条安全隐患的相似度。在这个过程中,Doc2Vec模型首先会将相似案例集合中的每条安全隐患都转化为唯一的向量表示,通过计算它们之间的向量余弦相似度来衡量它们之间的相似度。
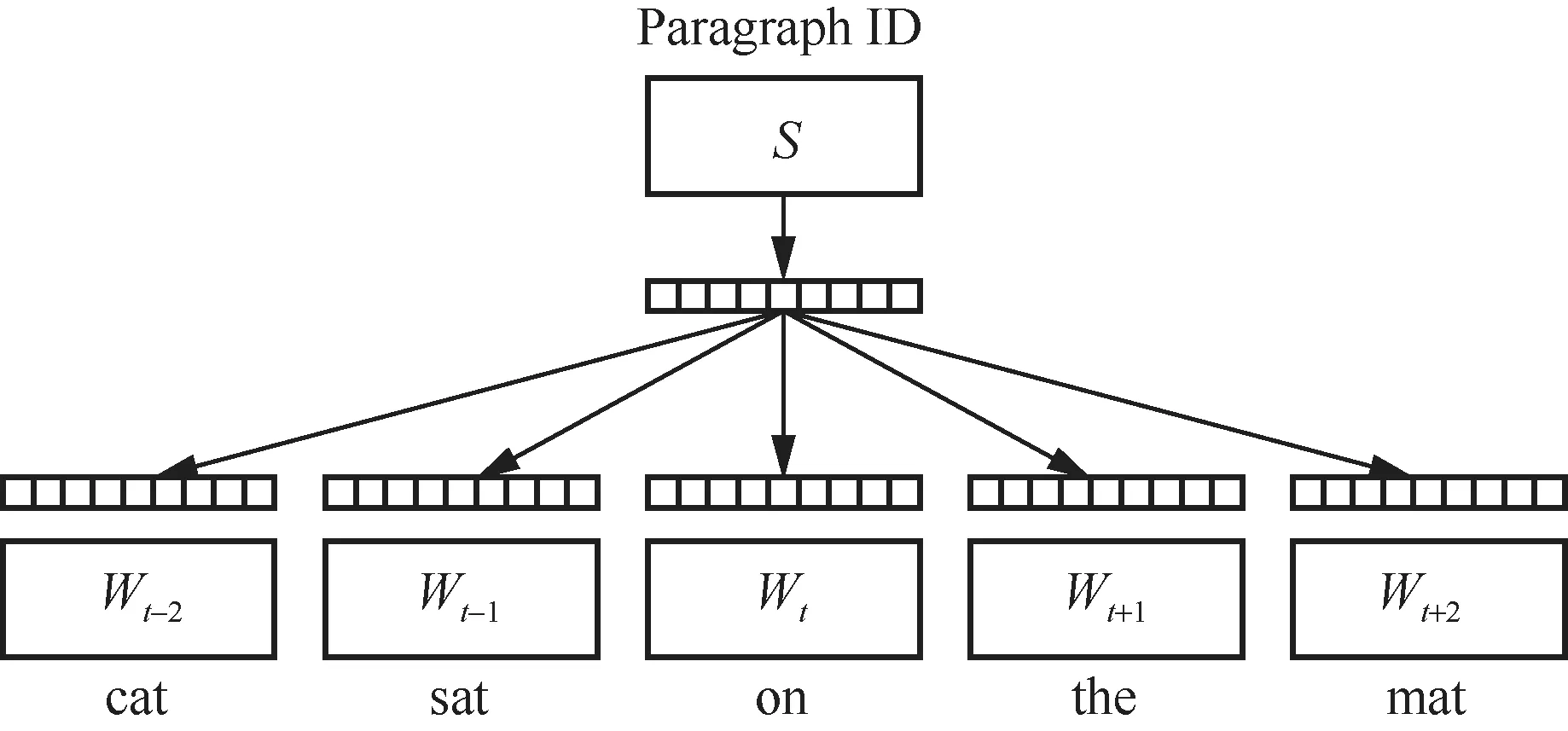
图3 DBOW模型结构
3 结果分析
各施工标段安全隐患的数量分布如图4所示。由图可知,B3、B4、C1是安全隐患高发的3个标段,因此,选用这3个标段的数据进行隐患特征挖掘与可视化。
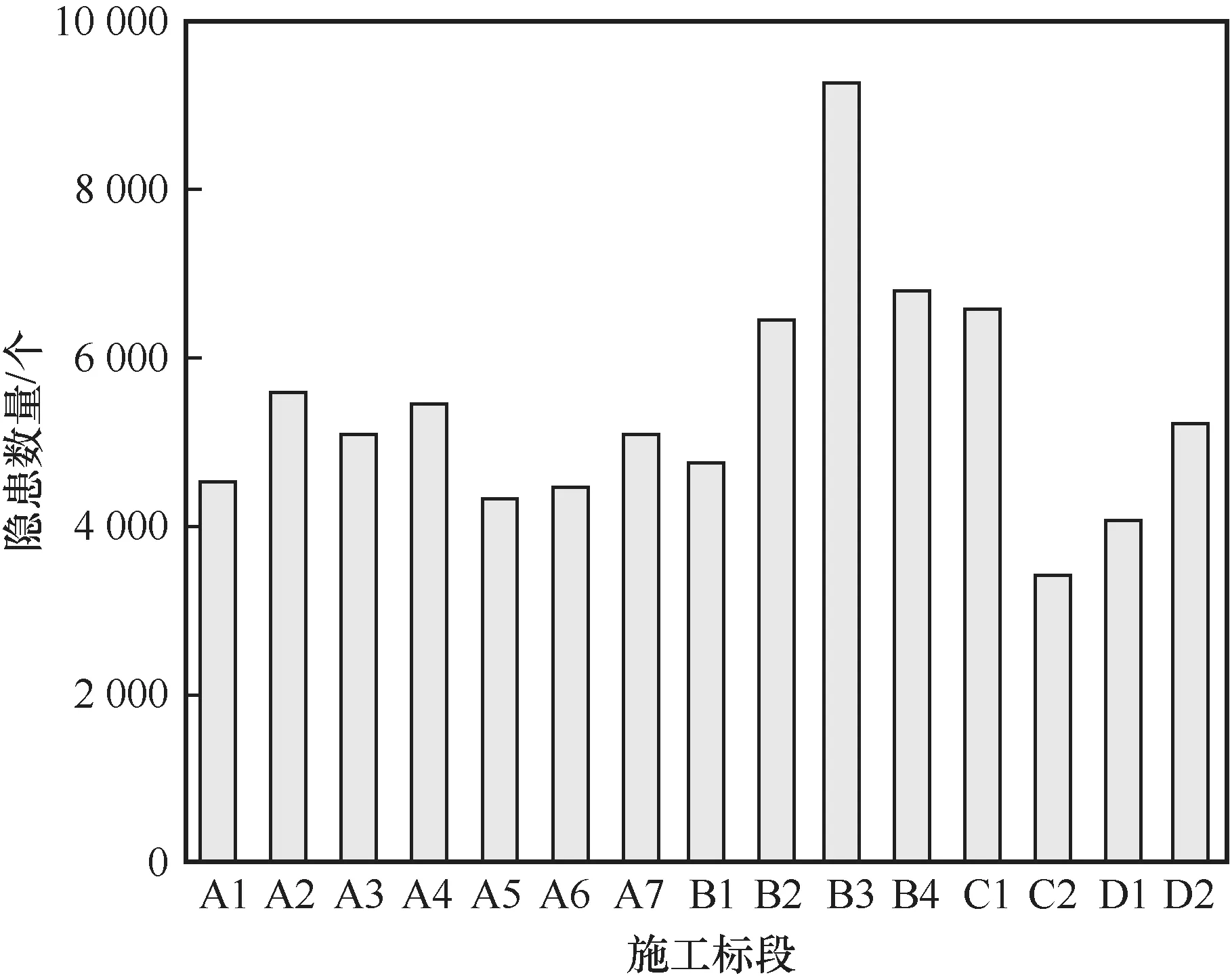
图4 各个施工标段隐患的数量分布
3.1 隐患特征分析
利用B3、B4和C1这3个标段的安全隐患数据来绘制桑基图[22]。首先,将每个标段的所有安全隐患数据作为一个文档,采用TF-IDF算法提取每个文档的关键词,选择TF-IDF值较大的前几个关键词作为对应施工标段的安全隐患特征;其次,利用RAWGraphs2.0软件绘制施工标段-隐患类型桑基图,如图5所示。该桑基图从左至右依次表示施工标段、隐患特征和隐患类型,每个节点的宽度表示该隐患特征TF-IDF值大小,节点之间的分支代表信息的流动,分支的宽度则反映了信息流量的大小。从桑基图中可以直观地了解到不同的施工标段各自存在的主要安全隐患问题特征。竖向分析显示,配电箱、灭火器和钢筋加工棚这3个隐患特征对应的节点宽度最大,说明各标段发生与这3个特征有关的安全隐患最多。而从横向角度来看,这3个特征词包含的信息流宽度最大,这表明与它们有关的隐患问题发生的频率最高。从施工标段的角度来看,B3和B4标段易发生与配电箱和灭火器相关的隐患,C1标段易发生与隧洞和钢筋加工棚相关的隐患。
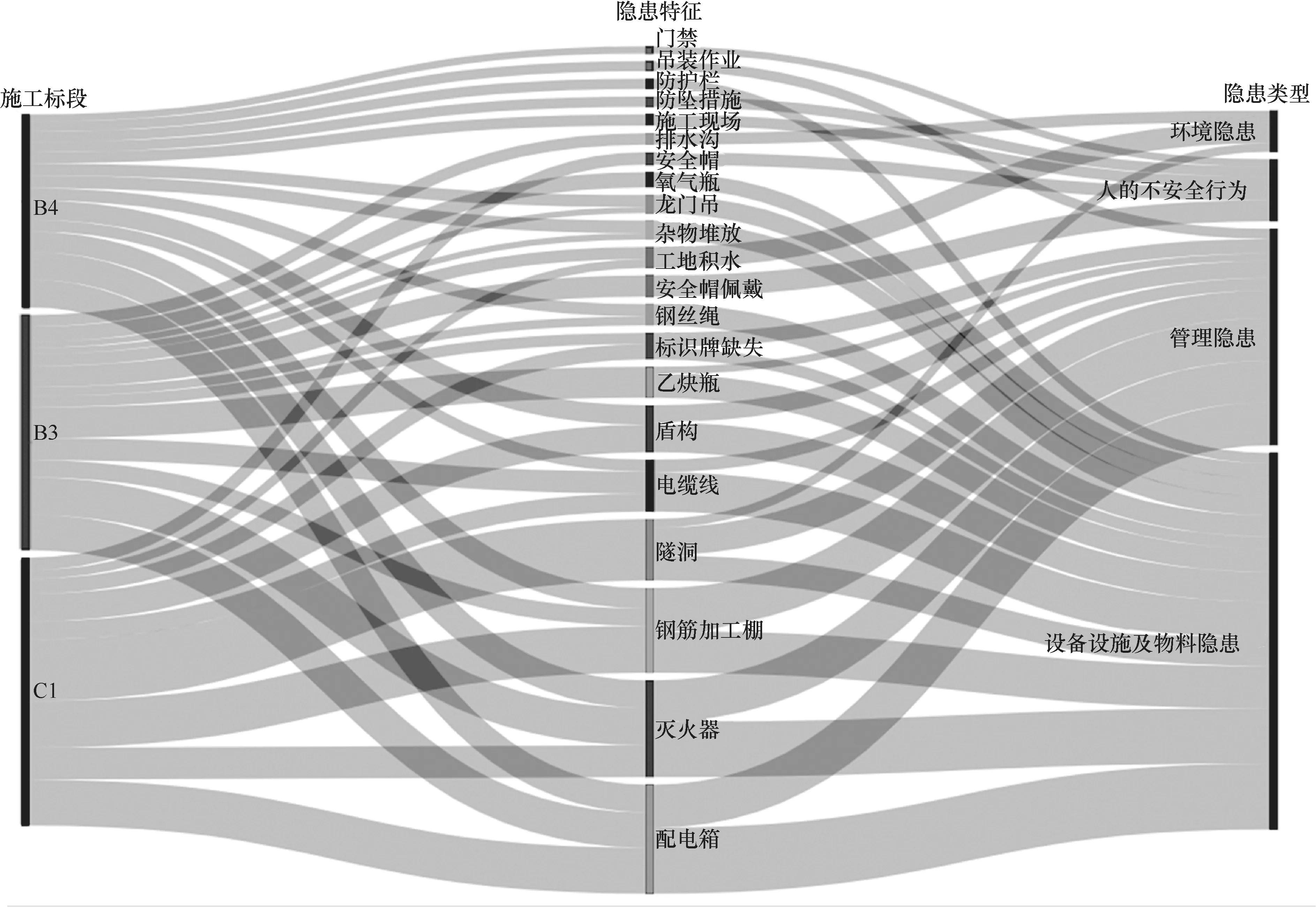
图5 施工标段-隐患类型桑基图
3.2 安全隐患整改推荐结果分析
3.2.1 关联规则挖掘结果分析
在分析当前隐患问题时,首先采用TF-IDF算法对当前隐患数据进行特征提取,其次根据FP-Growth算法挖掘关联规则,置信度的阈值为0.5,支持度的阈值为0.002,再经过人工筛选,最终得到了7 688条关联规则。部分关联规则见表2。以第一条关联规则为例,它表示当配电箱出现时,通常会伴随着“不规范”“灭火器”“接线”这3个事务;支持度为0.0031,说明同时包含“配电箱”“不规范”“灭火器”和“接线”的事务数比较少;置信度为0.75,意味着当一条安全隐患记录中出现了配电箱时,有75%的概率出现“不规范”“灭火器”“接线”这3个事务。
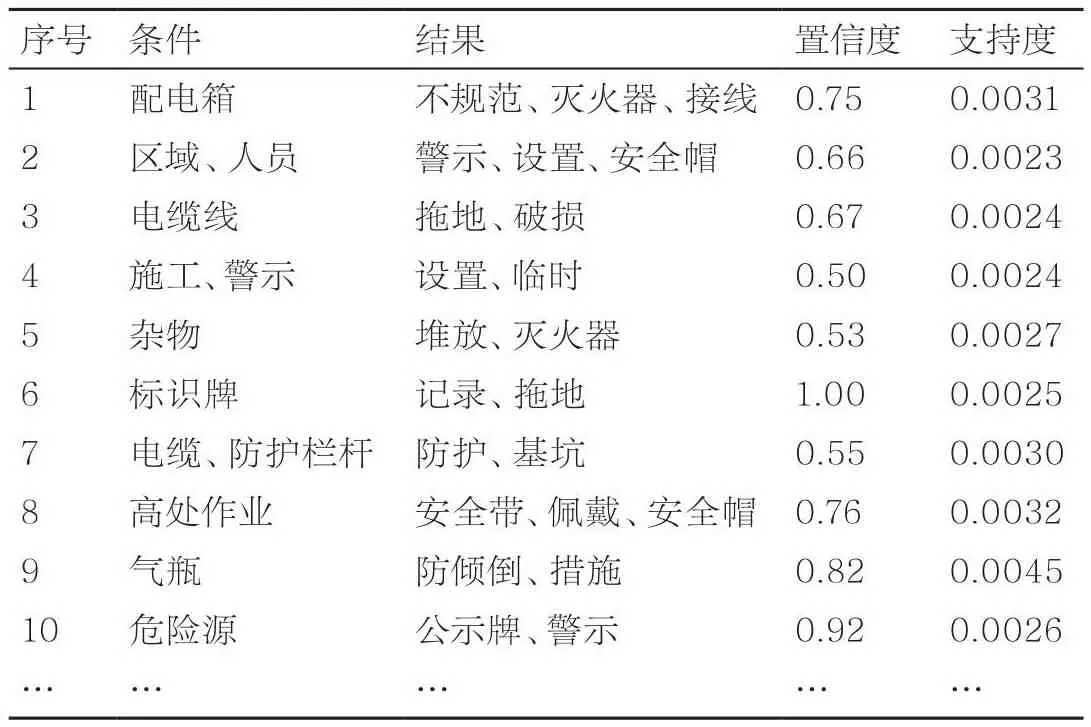
表2 部分关联规则
如图6所示,当安全检查人员发现并记录隐患后,通过TF-IDF提取隐患的特征,得到“安全距离”“防护措施”等安全隐患特征。以“安全距离”这一特征为例,通过关联规则得到“警示”“设置”“标识牌”等频繁项集。再以“警示”这一频繁项为例,能够匹配到相似的安全隐患问题描述,并且检索出对应的整改方案。
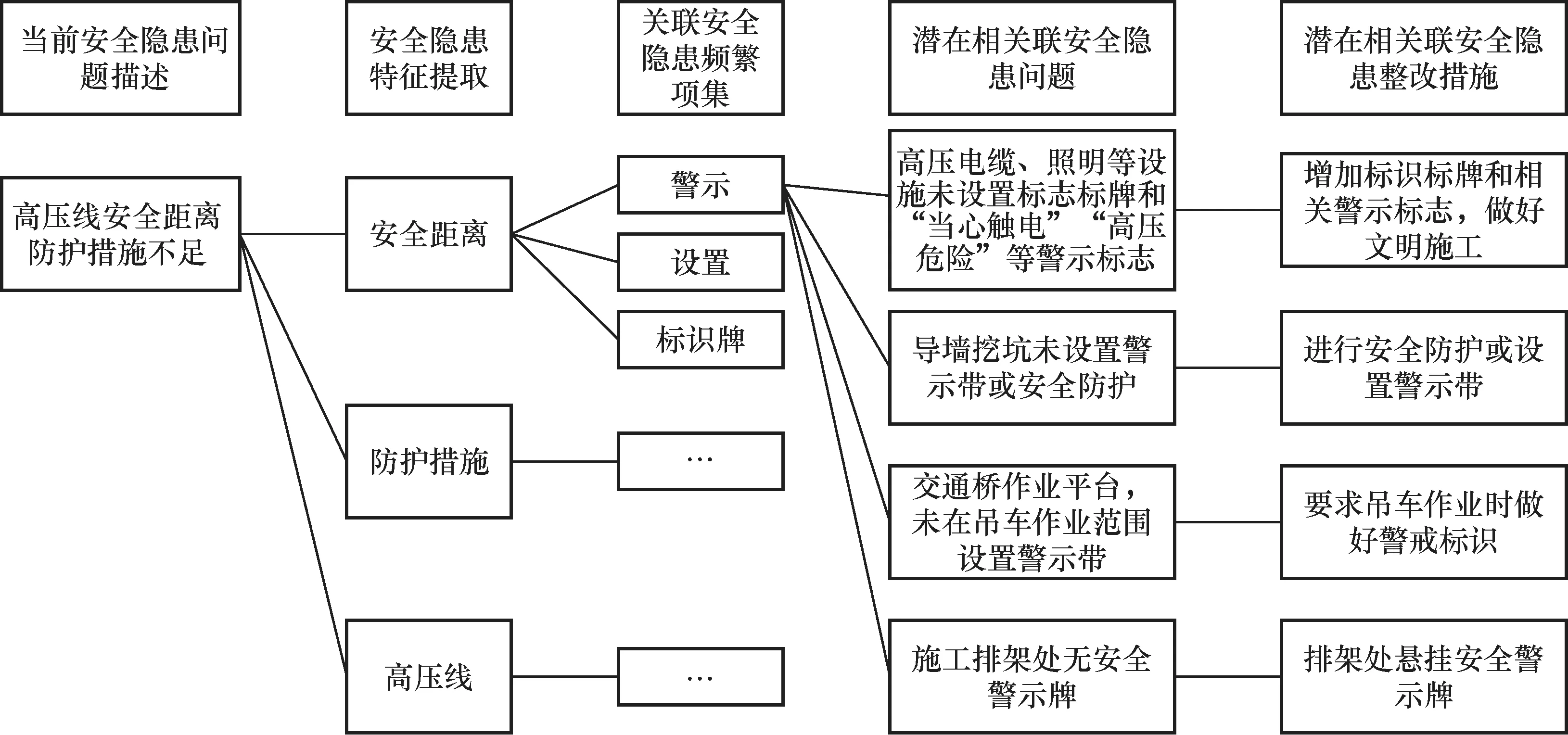
图6 关联规则分析
3.2.2 相似度计算实验分析
从2022—2023年期间的测试数据中,分别从环境隐患、人的不安全行为、管理隐患、设备设施及物料隐患这4个类型中依次随机抽取300条作为隐患问题描述测试样本。为了使抽取的样本更具有代表性,抽取的样本涵盖了水利工程建设中的8种不同作业内容,如图7所示。
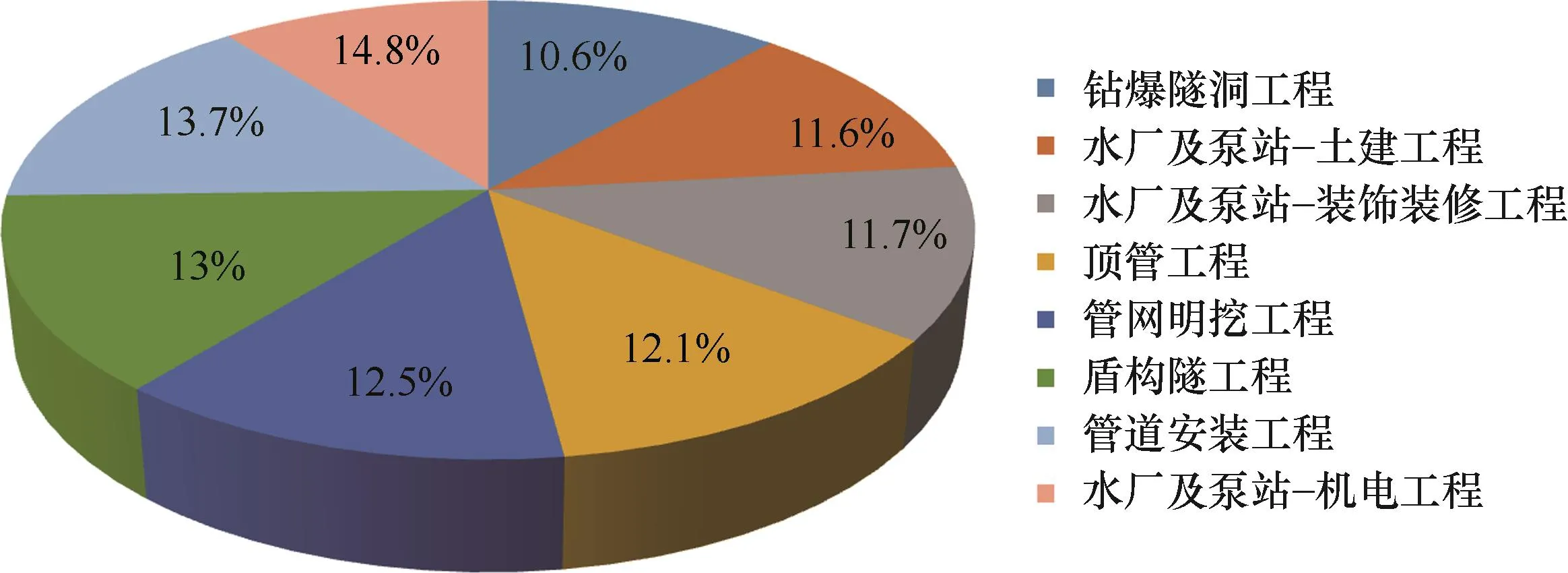
图7 不同作业内容测试样本占比
将从各个安全隐患类型中抽取出来的1 200条测试样本分别通过SSM算法匹配到对应的案例集,再通过Doc2Vec模型计算案例集中的安全隐患与当前隐患的相似度[23],最终综合准确率为0.869。部分安全隐患相似度匹配样例见表3。
为了进一步验证该推荐系统的有效性,将上述系统推荐的整改措施与安全管理者制定的整改措施进行对比[24],推荐准确率采用Doc2Vec模型计算的文本相似度,安全隐患整改推荐系统的综合准确率为0.914。见表4,本文提出的施工安全隐患智能推荐系统得到的安全隐患整改措施与安全管理者制订的安全隐患整改措施一致性较强,该推荐系统能较为准确地匹配出当前安全隐患的整改措施。

表4 部分安全隐患整改措施推荐准确率
本文针对同一输入,对比分析分别采用SSM、Doc2Vec、SSM+Doc2Vec这3种模型得到的相似度排名前5条的安全隐患,各模型效果见表5。以输入“焊工棚二氧化碳气瓶无防护棚、无防倾倒措施”为例,SSM模型注意到了“无防倾倒措施”“二氧化碳”“气瓶”等特征词,模型表现一般;在Doc2Vec模型中,“防护棚”这一特征词的权重较大,模型匹配效果最差;SSM+Doc2Vec模型首先经过SSM筛选出相似度排名前1 000的安全隐患,再利用Doc2Vec模型将这1 000条安全隐患转化为唯一的向量表示,最后计算这些向量余弦相似度来衡量它们之间的相似度,该模型同时注意到了“焊工棚”“无防倾倒措施”“二氧化碳”“气瓶”等特征词,不仅降低了模型的计算量,而且保留了关键的隐患特征词,故其综合表现最好。
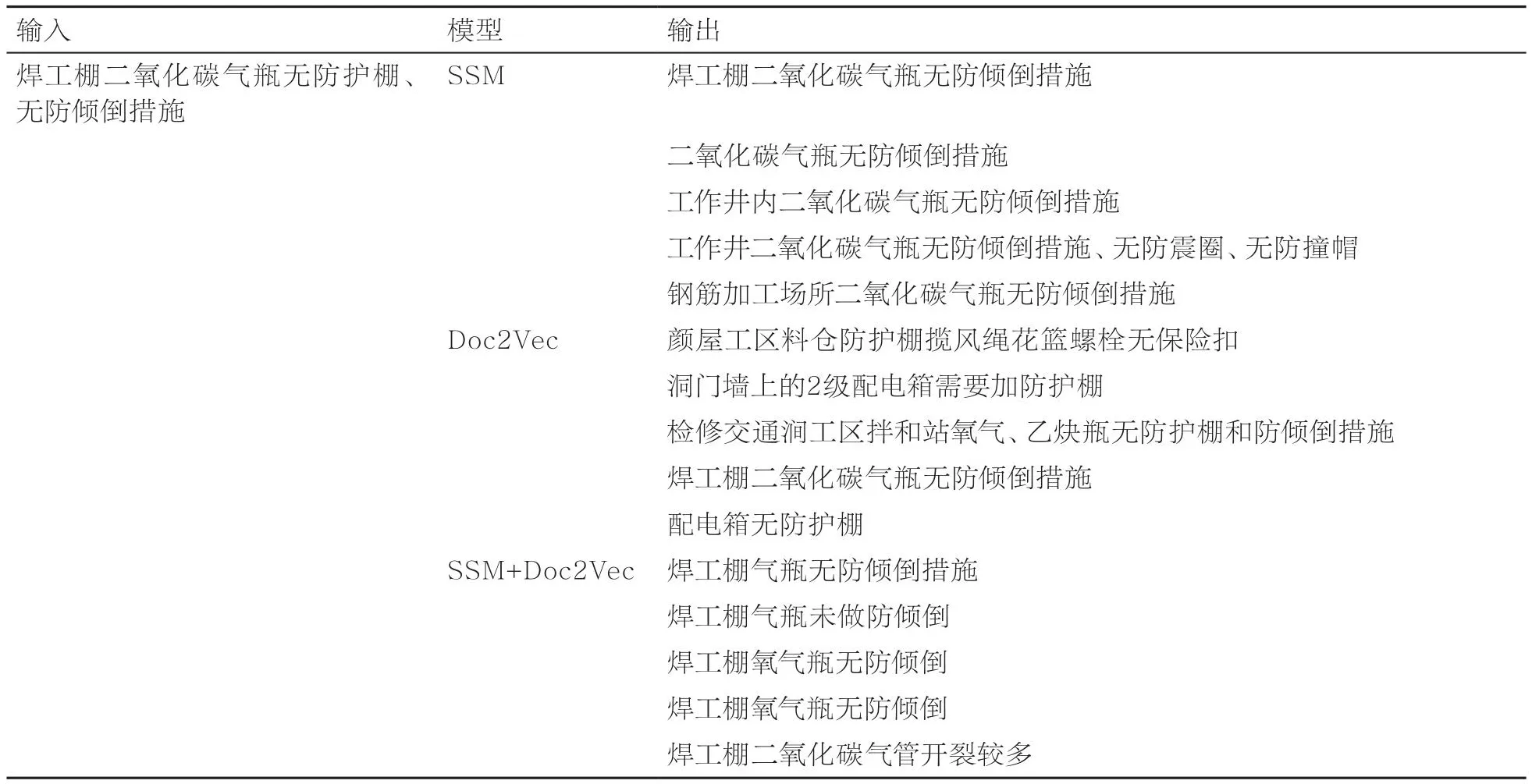
表5 各模型效果对比表(部分)
在从测试数据中随机采样得到的1 200个测试样本上,采用Doc2Vec模型计算文本的相似度,各模型的综合准确率见表6。SSM+Doc2Vec比SSM高0.032,比Doc2Vec高0.056。因此,本文提出的SSM+Doc2Vec模型在水利工程施工安全隐患文本上的表现优于单独采用SSM算法和Doc2Vec的方法。

表6 各模型综合准确率
3.2.3 算法性能对比与分析
为了进一步验证算法的优越性,采用相同的数据集并配置相同的实验环境,将本文提出的方法与文献[10]提出的基于Word2Vec计算目标案例与历史案例相似度的方法进行对比。结果表示,本文提出的方法在安全隐患整改推荐上的综合准确率达到0.869,优于文献[10]取得的0.802。当数据整体规模大且存在较多稀疏数据时,本文提出的方法采用SSM+Doc2Vec模型,可以更全面地挖掘案例描述的语义信息,在安全隐患整改推荐中能够提供更加准确的结果。
综上所述,基于深度学习的施工安全隐患整改智能推荐系统从多个方面提高了智能推荐方案的准确率和速度。首先,采用TF-IDF算法和FP-Growth算法提取和挖掘安全隐患的关联规则,可以更加准确地找到与当前安全隐患相关联的案例,从而提高了整改方案的完整性。其次,利用SSM算法初步匹配历史案例和当前入库案例,减少了后续模型的计算量,提高了系统的运行效率。最后,采用Doc2Vec模型计算当前安全隐患与相似案例集合中每一条安全隐患的相似度,推荐最符合当前情况的整改方案,辅助安全管理人员在隐患管理工作中更好地进行决策。
4 结束语
本文构建了基于深度学习的施工安全隐患整改智能推荐系统。首先,基于TFIDF算法进行安全隐患特征提取,并通过桑基图可视化安全隐患特征。其次,通过SSM算法对当前入库的安全隐患与数据库中的历史安全隐患案例进行初步匹配,得到粗糙的相似案例集合。然后,采用Doc2Vec模型计算当前安全隐患与相似案例集合中每一条安全隐患的相似度,合并相似度最高的安全隐患案例与关联的安全隐患案例,将其推荐为当前安全隐患的整改方案。本文在复用历史隐患治理经验的同时,挖掘出历史隐患数据中存在的关联规则,为安全隐患的排查治理提供了更全面的视角。验证结果表明,本文方法在安全患整改智能推荐任务上表现出色,能够快速、准确地为当前安全隐患问题推荐整改方案。在未来的工作中,将进一步完善安全隐患关联规则库和隐患整改推荐的方案。
猜你喜欢
江苏安全生产(2022年9期)2022-11-02 07:01:28
江苏安全生产(2022年8期)2022-11-01 09:15:20
大众科学(2022年8期)2022-08-26 08:58:38
江苏安全生产(2022年6期)2022-07-29 01:22:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
信息安全研究(2016年4期)2016-12-01 06:06:54
中国交通信息化(2016年10期)2016-01-29 02:56:07
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
铁路技术创新(2015年3期)2015-12-21 12:55:52
中国水利(2015年12期)2015-02-28 15:14:02
