
机器学习预测校级计算教学平台作业运行时间研究
2023-12-01 03:44:14于潇雪韦建文张战炳高亦沁林新华周衍晓
软件导刊 2023年11期
于潇雪,韦建文,张战炳,高亦沁,林新华,周 云,周衍晓
(1.上海交通大学 网络信息中心,上海 200240;2.上海擎云物联网股份有限公司,上海 200070)
0 引言
当今数字时代,计算对各领域发挥着颠覆性作用。尤其是ChatGPT 火爆全球之后,更是带动了新一轮算力需求增长,因而亟须培养大批量计算人才以应对不断增长的需求。上海交通大学积极探索计算人才培养新模式,提出“将计算深度融入专业课教学”的理念,并基于校内强大的算力基座研发校级计算教学平台,支撑计算课程的线上线下混合式教学和大规模虚拟仿真实验教学,让学生有机会在专业实践中按需学习计算并且用计算解决科研和应用领域的复杂专业问题。
作业调度系统是上海交通大学校级计算教学平台的核心系统之一,它根据算法预测的作业运行时间安排队列执行顺序,预测准确性影响调度合理性,进而影响平台整体利用率。机器学习方法能在海量数据中挖掘输入与输出的复杂映射关系,在预测作业运行时间任务中被广泛采用。但是,在实际应用时,如何收集算例数据、选用什么样的预测方法、选用哪些作业特征、有哪些机器学习技巧可以使用、针对仅有小样本的训练集如何提高预测准确度,仍是亟待解决的问题。
基于以上挑战,本文设计和实现了一套基于深度学习方法的作业运行时间预测方法,在预测高斯(Gaussian09)程序运行时间上取得了比现有工作更好的作业运行时间预测结果。这套方法在特征提取上结合应用无关特征和应用相关特征,并借助深度学习的模型迁移特性,在小样本数据集上也获得了较好的预测精度。本文主要贡献如下:①使用卷积神经网络提取通用作业特征,使用库伦矩阵提取高斯作业相关特征,两种特征融合后,在深度人工神经网络上获得了超过现有工作的预测精度;②针对小数据集,采用领域自适应的方法,将预测模型以较小代价迁移到小数据集上,显著降低了数据收集负担,提高了模型适用范围;③模型部署在校级计算教学平台作业调度系统上,在实际环境中验证了这套作业运行预测方法的可行性。
1 相关工作
1.1 基于机器学习方法的作业运行时间预测
作业运行时间预测是一个复杂的非线性问题,机器学习方法在解决此类问题上具有优势。文献[1]提出一种具有时间嵌入的Transformer 模型,基于用户历史作业日志数据提取作业时序特征、资源特征和用户聚类特征,以此预测作业运行时间。文献[2]采用KNN 算法,通过历史数据训练K-D 树,获取新提交作业与历史作业之间的相似距离,实现作业运行时间的预测。文献[3]以用户作业脚本为输入,对比了多种机器学习算法的预测效果,结果表明决策树优于其他算法,其准确率达到73%。文献[4]以VASP 作业为例,提出一种基于RBF 网络和朴素贝叶斯分类的混合预测方法,取得了良好的预测效果。文献[5]针对高斯应用程序,提取算例特征,使用线性回归、深度神经网络等方法预测作业运行时间。此外,文献[6]通过仿真实验说明,调度系统受作业运行时间的准确性影响较大,相比使用粗略运行时间估计,基于较准确的作业运行时间预测作出的作业排布,吞吐量提高了25%。
1.2 用于作业运行时间预测的特征提取
以上预测算法都使用CPU、内存、用户名等特征,需要人工设计和调整。为了降低特征工程在机器学习任务中的工作量,一些以深度人工神经网络为基础的自动特征提取方法被提出。文献[7]系统梳理了预测作业运行时间所需的作业特征、资源特征、聚类特征以及相应的机器学习方法。文献[8]以作业脚本作为输入,使用卷积神经网络提取字符一级的特征后作为人工神经网络输入,进行作业运行时间预测。文献[9]指出卷积神经网络因其优异的局部空间特征提取能力,在日志分析、文本情感分析等任务中常常作为特征提取工具。文献[10]回顾了机器学习技术在预测材料特性、设计新材料上的应用,提出了多种表征材料结构的方法。文献[11]指出作业路径是预测作业运行时间的重要特征,对其进行特征聚类处理后,输入支持向量回归、决策树和随机森林模型,可提升预测准确率。
1.3 模型在小样本数据集上的准确度提升
增大数据集是提高模型准确度的有效方法之一。文献[12]指出当数据获取条件受限时,可采用数据增强(Data Augmentation)方法。数据增强变化已有样本,生成新的与现实基本一致的训练样本。在图片分类任务中,数据增强方法有剪切、旋转、缩放、增加亮度等。文献[13]在样本数较少的类别上插值采样,将各类别样本数扩充到近似程度,避免了样本数不均造成的预测误差。文献[14]保留了在ImageNet 数据集上训练出的特征提取网络,替换最后的输出层后使用少量皮肤病相关照片进行微调,在样本量较少的皮肤病数据集上也获得了较好的识别效果。文献[15]在输入层将不同数据集归一到同一概率分布,从而使用同一个模型预测不同集群的作业运行时间。
2 校级计算教学平台
计算的快速发展对人才培养提出了更高要求,让学生在实战中运用所学知识技能解决真实问题是培养计算人才的重要途径。为此,上海交通大学秉持“应用为王、服务至上、简洁高效、安全运行”的宗旨,依托校内强大的算力基座打造了校级计算教学平台。
如图1 所示,算力基座自2013 年开始建设,采用异构设计理念,建设了云计算、人工智能计算和超级计算三类基座,为教学提供先进的CPU 和GPU 计算资源。在此之上,搭建了校级计算教学平台,一站式提供课程所需计算软件、实验环境和教学资源,支撑课堂直播、实验实训、作业考试、在线测评等全过程计算教学。平台目前已服务全校25 个院系,每学期使用师生数超3 000 人,涵盖人工智能、计算物理、计算化学、计算材料、生物信息、工程实践等众多领域。
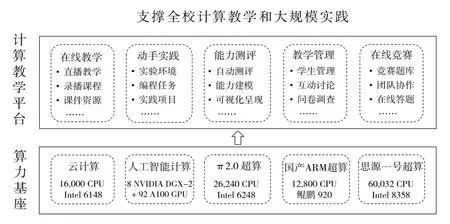
Fig.1 Architecture of university-level computing learning plarform图1 校级计算教学平台架构
3 用于高斯作业运行时间预测的深度学习模型
3.1 任务定义与方法
本文以高斯(Gaussian09)程序为例,实现调度系统中针对高斯作业的运行时间预测模块。原因在于高斯作为计算化学领域广泛应用的软件之一,在平台上首批运行至今,具有一定代表性;高斯程序在平台上使用负载占比较大,预测高斯作业运行时间,能够优化资源调度,提升平台利用率。
用户在使用高斯软件时,需要提交两个文件:一个是与计算资源(CPU、内存等)相关的SLURM 作业脚本,另一个是与高斯计算程序相关的算例输入文件。作业调度系统收到请求后,根据计算资源需求和算例文件,预测同一个作业在不同集群上的运行时间,再根据预设的调度策略,如最短时间、最低价格等,将作业调度到合适的集群上排队。最后待作业结束后,收集信息录入作业样本库。
高斯程序运行时,从算例文件读取模型参数和算法需求,然后构建仿真体系模型,通过迭代方法求解体系的薛定谔方程,得到体系稳态能量。高斯作业的运行时间由计算设备的运行速度,以及所要计算的问题决定。使用机器学习算法预测高斯作业的运行时间,需要将“高斯计算任务”转换成数值特征、选择合适的预测方法、处理小样本和数据分布不均的问题。
3.2 基于卷积神经网络的作业运行时间预测方法
本文借鉴文献[5]和文献[16]提取特征的思路,使用卷积神经网络提取作业的一般特征,并加入表征分子体系的库伦范数F。作业运行时间预测方法选用与CNN 天然集成的深度人工网络,并通过超参数搜索、数据增广等技巧提高准确率。
3.2.1 基于CNN的作业文本特征提取
本文使用卷积神经网络自动提取作业的通用特征,经过拼接、分词、词嵌入、截断变换得到词向量矩阵,经过卷积神经网络处理后得到特征向量用于运行时间预测。
如图2 所示,在通用作业特征提取中,作业脚本文件与高斯输入文件首先会被拼接成单行文本,然后对得到的单行文本进行一定的清洗:不同于普通文本存在大量的停用词、时态等冗余信息,作业脚本与输入文件的文本多是有用信息。因此,清洗主要是去除一些无实际意义的分隔符号,如括号等,保留具有有效信息的单词。之后,再将词语序列的每个元素通过Word2vec[17]转换为长度为8 的向量。

Fig.2 Schematic diagram of feature extraction based on convolutional neural network图2 基于卷积神经网络的特征提取示意图
由于不同作业脚本与输入文件提取得到的输入向量长度不尽相同,故本文在统计所有文本长度后选取了合适的位置将向量进行了截断。由于作业脚本长度大多相近,因此截断位置主要考量的是作业输入文件。而作业输入由两部分组成:第一段为作业运行时所需内容;第二段为分子结构,也即每个原子对应的笛卡尔坐标。而前一段对作业如何执行起指导作用,因此需要尽可能保留。因此,本文计算了所有算例输入文件第一段文本的最大长度,在该位置对向量进行截断。
3.2.2 使用库伦矩阵F范数的分子体系嵌入
高斯软件求解的是输入原子体系的最小能量状态,如何数值化地表征原子体系是提高预测准确度的关键。现有预测方法只采用了体系的局部特征,如“原子数”“质子总数”等,难以刻画体系的整体特性。
针对高斯的特征提取方法描述原子体系,本文借鉴其中的“库伦矩阵”,用以表征高斯作业算例中的体系结构。文献[18]实现了一个提取和转换库伦矩阵的Python 扩展库,本文使用这个库提取算例的库伦矩阵范数F。文献[5]使用库伦矩阵作为输入,它表征了原子核之间的经典相互作用,准确预测了原子材料的材料特性,验证了库伦矩阵的有效性。为更好地表征原子体系,本文使用库伦矩阵的F 范数整体表征原子体系。库伦矩阵是一个对称矩阵,表示了体系中原子的两两距离和质子数关系。但由于库伦矩阵的大小随体系大小而变,二维矩阵不易嵌入一维特征向量中,因此本文改用库伦矩阵的F 范数表征原子体系。尽管只用一个浮点数表征分子体系会损失大量信息,但在一定程度上体现了分子结构体系的空间特征。
式(1)中,对角线元素可以视作一个原子与其自身的相互作用,它也是对带有Z 个原子核电荷的原子能的多项式近似。而非对角线上的元素表示原子核i与原子核j之间的库伦排斥力。库伦矩阵M 的F 范数定义见式(2),其中p、q表示库伦矩阵的横向和纵向维度。
3.2.3 基于深度人工神经网络的作业运行时间预测
本文使用深度人工神经网络(Deep Neural Networks,DNN)作为预测高斯作业运行时间的算法。具体地,在神经网络输出方面,本文令输出层具有2 880 个神经元,每个神经元分别代表0~2 880 min。本文对作业运行时间的预测不是传统的回归问题,而是转换为粗粒度的分类问题进行处理。
对于从输入文件文本映射得到的一维向量而言,本文进一步采用100 个大小为3×8 的卷积核对其进行遍历,其中8 表示Word2vec 转换得到的词向量维数。这样做确保了卷积核与词向量的宽度一致,从而使卷积得到不同的完整单词之间的局部关系,这是因为对单个单词的词向量做切分没有实际意义,而使用该卷积神经网络可以利用网络中诸多隐含层中的神经元自动提取更高维度、更重要的特征。相比之下,朴素的机器学习方法如KNN、随机森林等方法则无法从文本中构建特征并用于分析。使用这种方法的优点在于无需针对应用进行人工的特征提取。后者需要使用基于正则的分割、数据清洗等方法才能得到模型所需要的特征数据,且在不同应用间不具有普适性。而基于文本映射以及1D-CNN 的方法能够自动提取特征,且适用于不同应用。在经过卷积后,本文得到了一系列新的列向量,为了压缩过多信息,使用最大池化层提取卷积得到最关键信息,然后将更新的列向量连接至全连接层以及最后2 880个神经元的Softmax 层进行分类。
3.3 深度人工神经网络下的模型迁移
计算环境的差异会导致同一个高斯算例运行时间的差异,这种在数据分布上的差异,最终会导致基于某个集群数据集训练好的模型,在另一个集群上预测准确率骤降。然而,在新数据集上从零开始训练一个模型,会遇到数据收集和参数调优等难题,模型迁移(Model Transfer)方法[19]提供了一种复用预训练模型的方法以解决这些问题。所谓模型迁移,指源域与目标域的特征、输出值相同,但其特征的分布不同。其中,源域指现有数据集,而目标域指待迁移的数据集。在实现方法上,大致可分为“输入自适应”和“输出自适应”,前者保持模型输出层不变,对输入数据做变换,使其概率分布统一到模型训练所用的数据上;后者保持输入层不变,调整模型输出层参数,让输出层适配新数据集概率分布。
本文在深度神经网络模型上采用“输出自适应”方法,原理如图3 所示。由于模型前3 层为一般特征,而之后的层为针对数据集的表示层,因此可以固定前3 层,并在新数据集上重新训练并微调后面数层,从而仅需收集少量数据就能达到较好的预测准确度。

Fig.3 Theory of output adaption图3 输出自适应原理
3.4 其他提升性能的数据处理技巧
(1)数据增强。在预测高斯作业运行时间的任务中,受限于作业质量和系统权限,能用于模型训练的作业样本数远小于当前主流模型的规模,只有几千个样本点。高斯作为一个OpenMP 并行作业,在一个计算节点多核运行时具有超过90%的并行效率,提高一个算例所用的核心数,大致能等比例地缩短该算例的运行时间。基于这样的观察,本文对一个使用N 核心、运行时间为T 的算例做变换,生成4 个训练算例,其核心数和运行时间分别是:(N/4,4T)、(N/2,2T)、(2N、T/2)和(4N,T/4)。
(2)超参数搜索。求解机器学习模型的过程通常是搜索经验损失函数极小点的过程,模型超参数的设置对能否搜索到极小点具有重要影响,需尝试多组不同的超参数。
对于深度神经网络,可调整的超参数主要有:网络深度、每层的神经元数量、学习率等。这些因素影响模型的泛化能力和收敛速度。由于训练时间长、搜索空间大,本文采用贝叶斯方法搜索最佳模型设置。在搜索过程中,优化目标变成以超参数为变量的损失函数,贝叶斯函数以高斯过程对其建模,引导搜索过程向最优超参数收敛。
对于梯度提升决策树,可调整的超参数主要有:最大子树深度、子树数量、孩子节点中最小的样本权重和、子样本的比例、学习率等。这些参数会影响模型泛化能力、贪心算法保守程度、权重调整幅度等重要因素。本文采取的策略是固定其他超参数,遍历某组超参数,重复以上步骤直至模型达到最优。
4 实验结果与分析
4.1 实验环境
本文实验均在Intel Xeon Gold 6248平台上完成。支持向量机(SVM)、决策树(DT)和深度人工神经网络模型分别使用scikit-learn、XGBoost和TensorFlow 实现。
4.2 高斯作业样本数据集
本文使用的高斯作业样本来自集群A(数据集A)、集群B(数据集B)和集群C(数据集C)。这3个集群分别建设于2019 年、2017 年、2018 年采购,因而单节点性能有较为显著的差异。作业样本去掉了因故障终止、超过2 天计算不收敛的算例。此外,本文使用数据增强方法,扩充3 个原始数据集,得到用于训练的增强数据集。各数据集大小如表1所示。
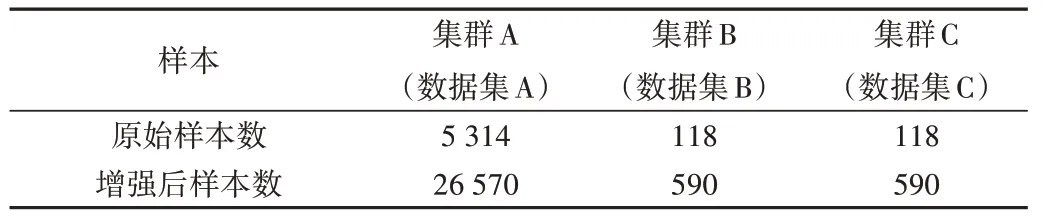
Table 1 Three datasets of Gaussian09 jobs表1 3个高斯作业样本数据集
4.3 算法准确度度量标准
本文参考文献[20],使用“平均相对百分比误差”(Mean Relative Percentage Error,MRPE)度量模型准确度。MRPE 是“单次预测相对准确度”的算术平均值,数值越高,模型在数据集上的整体预测结果越接近真实值。相比另一个常用的度量指标“平均绝对百分比误差”(Mean Absolute Percentage Error,MAPE),MRPE 具有如下优点:数值保持在0-1 区间、易于解释和对比性能、能处理预测结果为0或无穷大的极端情况。其公式如下:
式(3)中,下标i表示第i个数据点,pred 表示模型预测的作业运行时间,true 表示作业实际运行时间,∈为平滑项。
4.4 实验流程
在评估算法准确度的实验中,本文通过组合机器学习算法和可用特征集评估机器学习方法对准确度的影响,使用的是样本数较多的数据集A。其中,3 种机器学习算法使用传统特征作为对比基线。DNN 方法额外使用CNN 特征和库伦矩阵范数特征的组合,以评估新特征的有效性。从头开始训练,与使用迁移学习算法的精度进行比较。
在评估模型迁移实验中,评估迁移学习算法对于小样本数据集的有效性。模型基线设定为SVM、DT 和DNN 在小样本数据集上直接训练出来的模型,接着基于数据集A模型,保留特征提取层训练出来的参数,在数据集B 和数据集C 上微调并迁移输出层,并对比这两组模型的效果。
在评估算法耗时实验中,比较所用算法的训练和推理耗时,以评估模型是否适合部署在生产环境中。
在所有实验中,都使用了进行数据增强的数据集,并将数据增强后的样本集,按照0.95∶0.05 划分为训练集和测试集,分别输入指定模型中进行训练。测试集用于评模型准确度,不用于模型训练。采用SVM、DT、DNN 3 种机器学习方法训练,比较训练时间、推理时间和模型精准度。
4.5 评估算法准确度
3 种机器学习算法及其变种在数据集A 上的性能如图4 所示。在使用相同特征进行训练时,SVM、DT 和DNN 的效果相仿,分别为66.32%、71.87%、69.59%,DT 在三者中具有微弱优势。加入CNN 提取特征和库伦矩阵F 范数特征后,模型效果得到了有效提高。CNN 提取的特征将DNN方法的MRPE 提升了13.36%,而加入了库伦矩阵的F 范数特征后,模型的MRPE 进一步提升了7.656%。最终,DNN-3模型的MRPE 达到84.93%,证明了两种方法的有效性。
对于CNN 特征提取的有效性,分析原因如下:原始文本特征大量出现次数很少的文本,例如迭代方法中存在许多仅使用过数次的方法。传统编码方法使用one-hot 对这类特征编码时会导致特征矩阵非常稀疏,使得训练时很难收敛到一个最优值。而CNN 提取该类型文本特征时得到的特征尺寸是可控的,同时兼顾了传统方法得到的文本特征,因此效果更好。
4.6 评估模型迁移
各SVM、DT 和DNN 算法变种在样本总数较少的数据集B 和C 上的精准度如图5、图6所示。
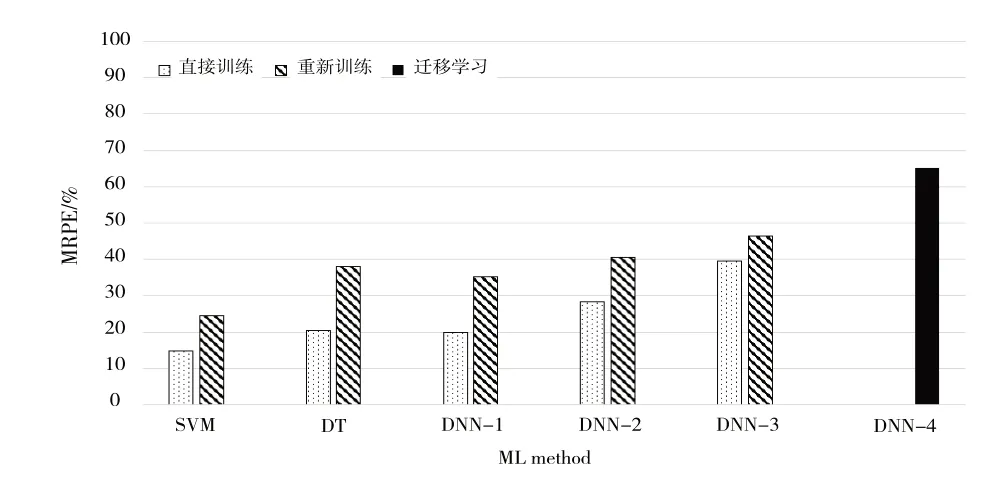
Fig.5 Different models’ MRPE performance on dataset B(higher is better)图5 不同模型在数据集B上的MPRE值(越高越好)

Fig.6 Different models’MRPE performance on dataset C(higher is better)图6 不同方法在数据集C上的MPRE值(越高越好)
首先,对于“从零开始”训练模型的算法,SVM、DT、DNN-1 在小样本数据集上的精准度不佳,未超过38%。CNN 提取特征和加入库伦矩阵对精准度的影响与上文观察到的一致,前者作用更显著。其次,对于“直接使用”预训练模型的5 个机器学习模型(SVM、DT、DNN-1、DNN-2、DNN-3),准确度相比“从零开始”训练的模型不升反降,说明由于数据分布差异,在一个数据集上训练出来的模型通常不能直接用于另一个数据集推理。最后,采用“模型迁移”方法微调的算法DNN-4 在两个小数据集上都获得了比其他算法更高的准确度,分别达65.2%、63.3%,证明了模型迁移方法的有效性。
4.7 评估算法训练与推理耗时
在实际部署模型时,算法训练时间会影响模型重训练频度,推理时间会影响模型响应速度。算法训练和推理时间大致与算法复杂度保持一致,在生产环境部署算法时,需要考虑处理时间的硬性限制。几种机器学习算法在数据集A 上的训练时间和推理时间如表2 所示,算法的变种不影响整体训练和推理时间,因此采用最基本的算法。
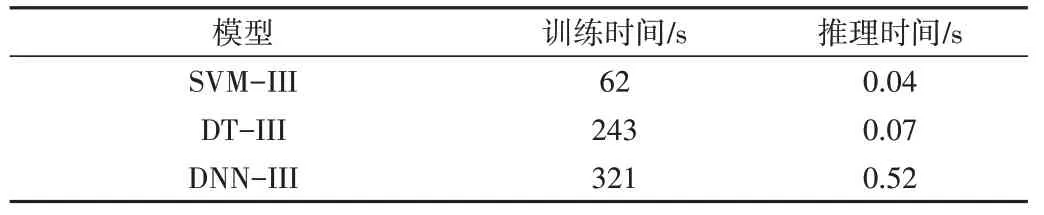
Table 2 Horizontal comparison of 5 models表2 5种模型横向比较
对于模型训练,SVM 最快,DT 次之,DNN 最慢。上述算法的训练时间都不超过10 min,能够满足每隔半小时重新训练一次模型的需求。对于模型推理,耗时从小到大依次是:SVM、GBDT 和DNN。其中,DNN 算法推理时间高于0.5 s,结合生产环境集群作业接收经验(约每秒收到一个新作业),DNN 足以处理高斯作业预测,但扩展到预测每一个作业的运行时间,会成为整个作业调度系统的瓶颈。
5 结语
本文在上海交通大学校级计算教学平台作业调度系统的基础上,实现了一套用于收集特定应用算例的系统,基于该系统收集的高斯作业算例,以及相同算例在其他集群上的运行结果,评估了不同机器学习方法结合不同的特征提取方式对于预测高斯作业运行时间的适用性,并探讨了提高小样本数据集预测准确度的方法。
最终发现,梯度提升决策树方法和深度神经网络方法优于传统的支持向量机方法;使用Text-CNN 对文本提取特征优于提取单词并做one-hot 编码;在模型中加入表示原子体系的表征后准确度明显提高,相比使用原始特征作为输入的DNN,使用Text-CNN 提取文本特征加上库伦矩阵F 范数作为输入特征的MRPE 提升了22.04%;对于小样本数据集,采用模型迁移的方法复用预训练模型,能有效提高模型准确度。下一步,尝试将这套方法用于高斯之外的科学应用,为高效率智能化的集群作业调度提供依据。
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
车主之友(2023年2期)2023-05-22 02:53:20
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
黑龙江史志(2014年1期)2014-11-11 03:30:19
中外书摘(2014年9期)2014-09-18 09:57:34
